 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Fast Blind Audio Copy-Move Detection and Localization Using Local Feature Tensors in Noise
Feb 15, 2023
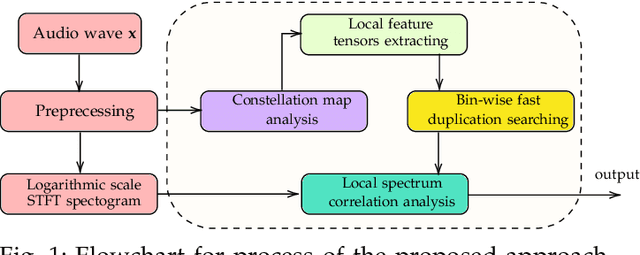
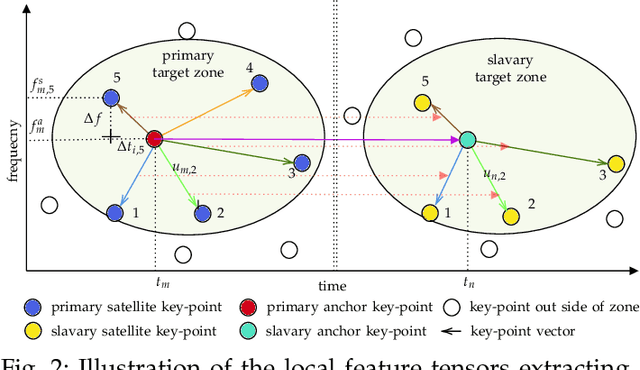
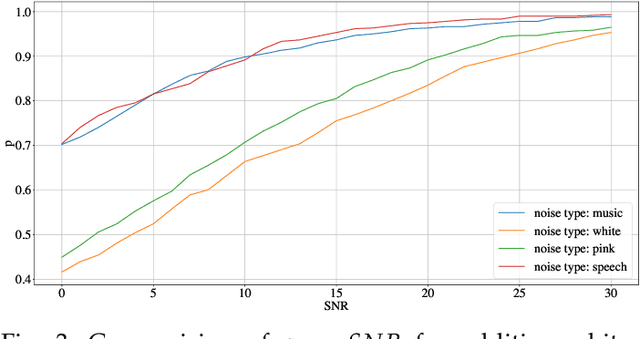
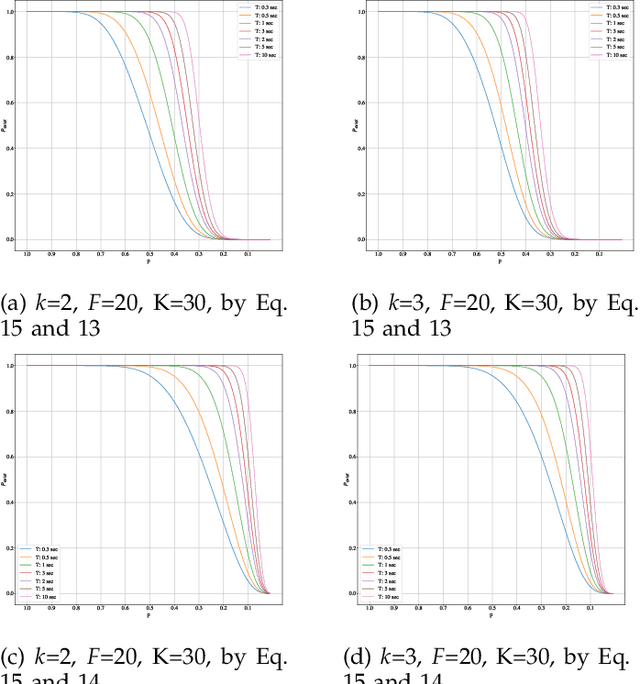
The increasing availability of audio editing software altering digital audios and their ease of use allows create forgeries at low cost. A copy-move forgery (CMF) is one of easiest and popular audio forgeries, which created by copying and pasting audio segments within the same audio, and potentially post-processing it. Three main approaches to audio copy-move detection exist nowadays: samples/frames comparison, acoustic features coherence searching and dynamic time warping. But these approaches will suffer from computational complexity and/or sensitive to noise and post-processing. In this paper, we propose a new local feature tensors-based copy-move detection algorithm that can be applied to transformed duplicates detection and localization problem to a special locality sensitive hash like procedure. The experimental results with massive online real-time audios datasets reveal that the proposed technique effectively determines and locating copy-move forgeries even on a forged speech segment are as short as fractional second. This method is also computational efficient and robust against the audios processed with severe nonlinear transformation, such as resampling, filtering, jsittering, compression and cropping, even contaminated with background noise and music. Hence, the proposed technique provides an efficient and reliable way of copy-move forgery detection that increases the credibility of audio in practical forensics applications
Super-Resolution Neural Operator
Mar 05, 2023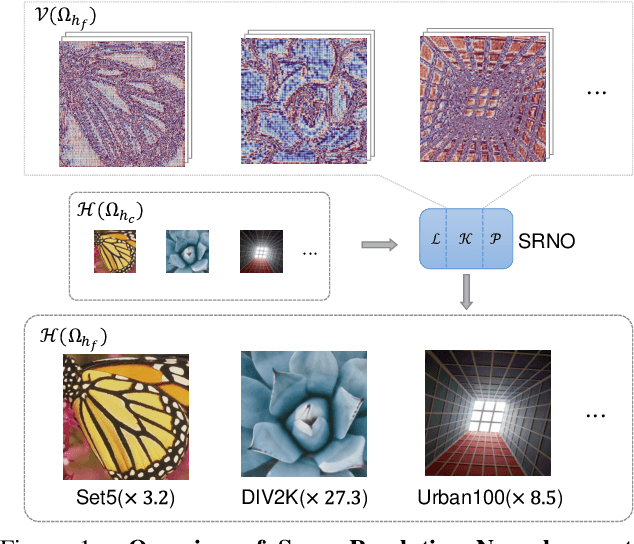
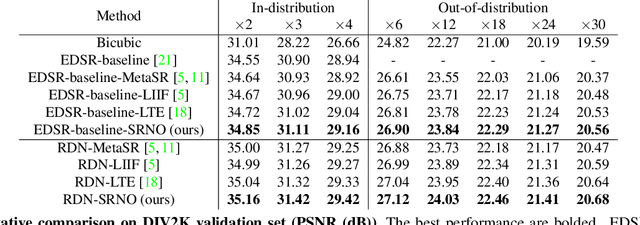

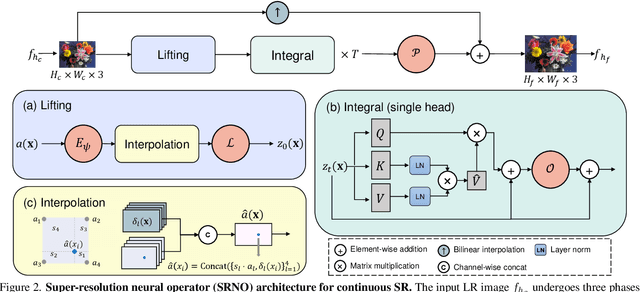
We propose Super-resolution Neural Operator (SRNO), a deep operator learning framework that can resolve high-resolution (HR) images at arbitrary scales from the low-resolution (LR) counterparts. Treating the LR-HR image pairs as continuous functions approximated with different grid sizes, SRNO learns the mapping between the corresponding function spaces. From the perspective of approximation theory, SRNO first embeds the LR input into a higher-dimensional latent representation space, trying to capture sufficient basis functions, and then iteratively approximates the implicit image function with a kernel integral mechanism, followed by a final dimensionality reduction step to generate the RGB representation at the target coordinates. The key characteristics distinguishing SRNO from prior continuous SR works are: 1) the kernel integral in each layer is efficiently implemented via the Galerkin-type attention, which possesses non-local properties in the spatial domain and therefore benefits the grid-free continuum; and 2) the multilayer attention architecture allows for the dynamic latent basis update, which is crucial for SR problems to "hallucinate" high-frequency information from the LR image. Experiments show that SRNO outperforms existing continuous SR methods in terms of both accuracy and running time. Our code is at https://github.com/2y7c3/Super-Resolution-Neural-Operator
On the Statistical Benefits of Temporal Difference Learning
Jan 30, 2023
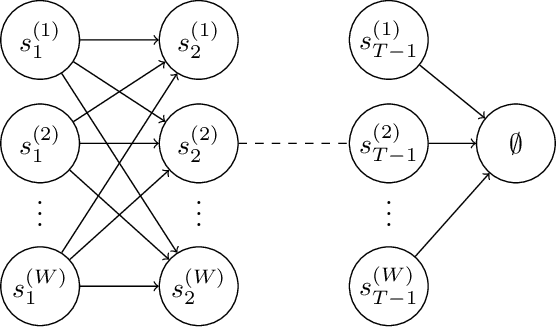
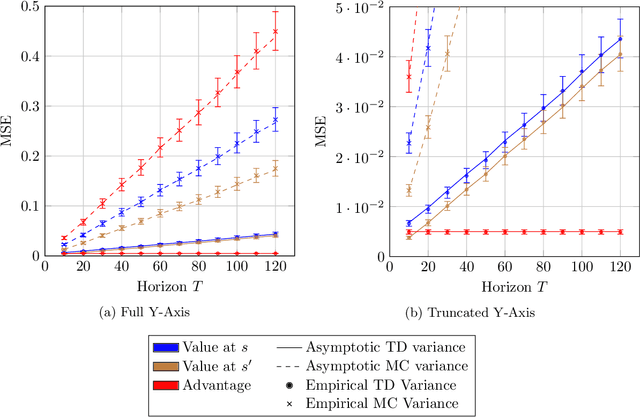
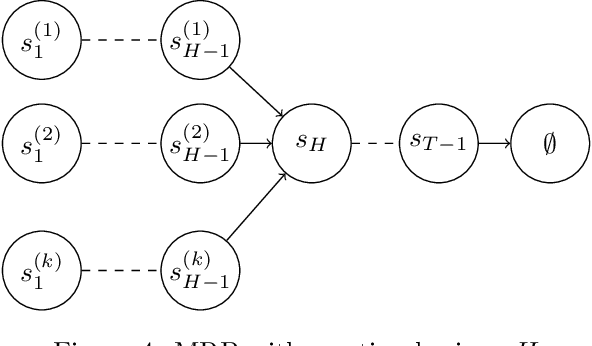
Given a dataset on actions and resulting long-term rewards, a direct estimation approach fits value functions that minimize prediction error on the training data. Temporal difference learning (TD) methods instead fit value functions by minimizing the degree of temporal inconsistency between estimates made at successive time-steps. Focusing on finite state Markov chains, we provide a crisp asymptotic theory of the statistical advantages of this approach. First, we show that an intuitive inverse trajectory pooling coefficient completely characterizes the percent reduction in mean-squared error of value estimates. Depending on problem structure, the reduction could be enormous or nonexistent. Next, we prove that there can be dramatic improvements in estimates of the difference in value-to-go for two states: TD's errors are bounded in terms of a novel measure - the problem's trajectory crossing time - which can be much smaller than the problem's time horizon.
Robust Budget Pacing with a Single Sample
Feb 03, 2023Major Internet advertising platforms offer budget pacing tools as a standard service for advertisers to manage their ad campaigns. Given the inherent non-stationarity in an advertiser's value and also competing advertisers' values over time, a commonly used approach is to learn a target expenditure plan that specifies a target spend as a function of time, and then run a controller that tracks this plan. This raises the question: how many historical samples are required to learn a good expenditure plan? We study this question by considering an advertiser repeatedly participating in $T$ second-price auctions, where the tuple of her value and the highest competing bid is drawn from an unknown time-varying distribution. The advertiser seeks to maximize her total utility subject to her budget constraint. Prior work has shown the sufficiency of $T\log T$ samples per distribution to achieve the optimal $O(\sqrt{T})$-regret. We dramatically improve this state-of-the-art and show that just one sample per distribution is enough to achieve the near-optimal $\tilde O(\sqrt{T})$-regret, while still being robust to noise in the sampling distributions.
Data-Efficient Learning of Natural Language to Linear Temporal Logic Translators for Robot Task Specification
Mar 09, 2023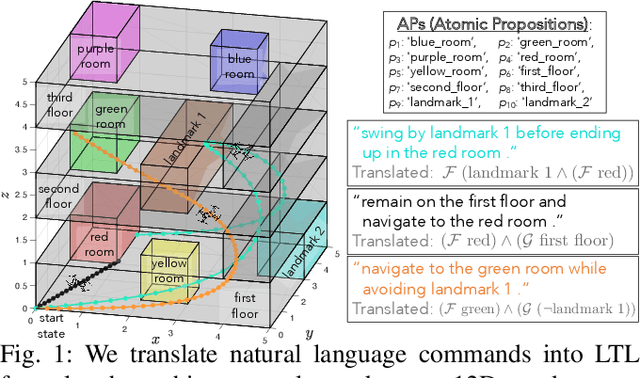
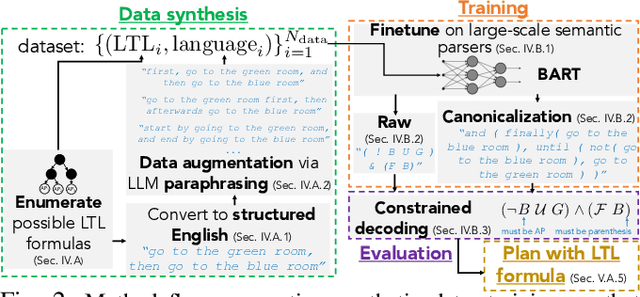
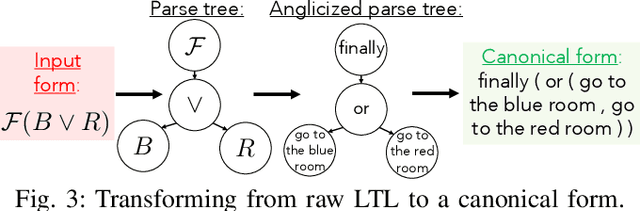

To make robots accessible to a broad audience, it is critical to endow them with the ability to take universal modes of communication, like commands given in natural language, and extract a concrete desired task specification, defined using a formal language like linear temporal logic (LTL). In this paper, we present a learning-based approach for translating from natural language commands to LTL specifications with very limited human-labeled training data. This is in stark contrast to existing natural-language to LTL translators, which require large human-labeled datasets, often in the form of labeled pairs of LTL formulas and natural language commands, to train the translator. To reduce reliance on human data, our approach generates a large synthetic training dataset through algorithmic generation of LTL formulas, conversion to structured English, and then exploiting the paraphrasing capabilities of modern large language models (LLMs) to synthesize a diverse corpus of natural language commands corresponding to the LTL formulas. We use this generated data to finetune an LLM and apply a constrained decoding procedure at inference time to ensure the returned LTL formula is syntactically correct. We evaluate our approach on three existing LTL/natural language datasets and show that we can translate natural language commands at 75\% accuracy with far less human data ($\le$12 annotations). Moreover, when training on large human-annotated datasets, our method achieves higher test accuracy (95\% on average) than prior work. Finally, we show the translated formulas can be used to plan long-horizon, multi-stage tasks on a 12D quadrotor.
FaceXHuBERT: Text-less Speech-driven E(X)pressive 3D Facial Animation Synthesis Using Self-Supervised Speech Representation Learning
Mar 09, 2023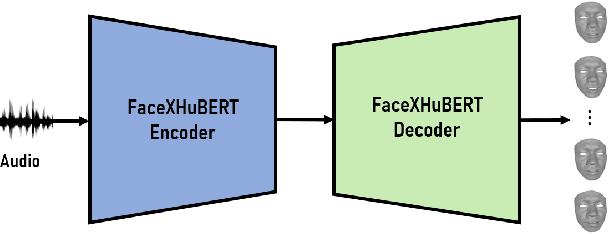
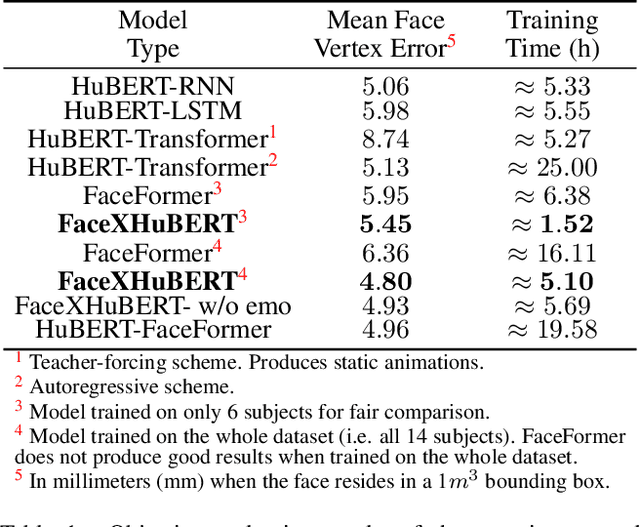
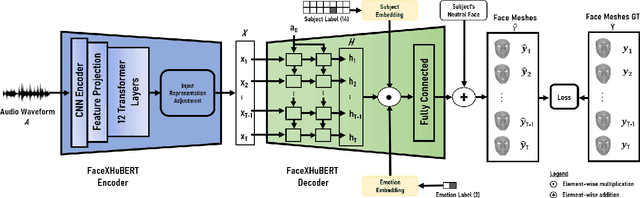

This paper presents FaceXHuBERT, a text-less speech-driven 3D facial animation generation method that allows to capture personalized and subtle cues in speech (e.g. identity, emotion and hesitation). It is also very robust to background noise and can handle audio recorded in a variety of situations (e.g. multiple people speaking). Recent approaches employ end-to-end deep learning taking into account both audio and text as input to generate facial animation for the whole face. However, scarcity of publicly available expressive audio-3D facial animation datasets poses a major bottleneck. The resulting animations still have issues regarding accurate lip-synching, expressivity, person-specific information and generalizability. We effectively employ self-supervised pretrained HuBERT model in the training process that allows us to incorporate both lexical and non-lexical information in the audio without using a large lexicon. Additionally, guiding the training with a binary emotion condition and speaker identity distinguishes the tiniest subtle facial motion. We carried out extensive objective and subjective evaluation in comparison to ground-truth and state-of-the-art work. A perceptual user study demonstrates that our approach produces superior results with respect to the realism of the animation 78% of the time in comparison to the state-of-the-art. In addition, our method is 4 times faster eliminating the use of complex sequential models such as transformers. We strongly recommend watching the supplementary video before reading the paper. We also provide the implementation and evaluation codes with a GitHub repository link.
Phase transition for detecting a small community in a large network
Mar 09, 2023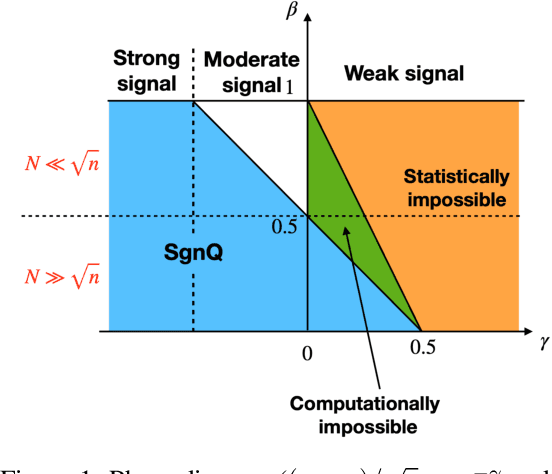
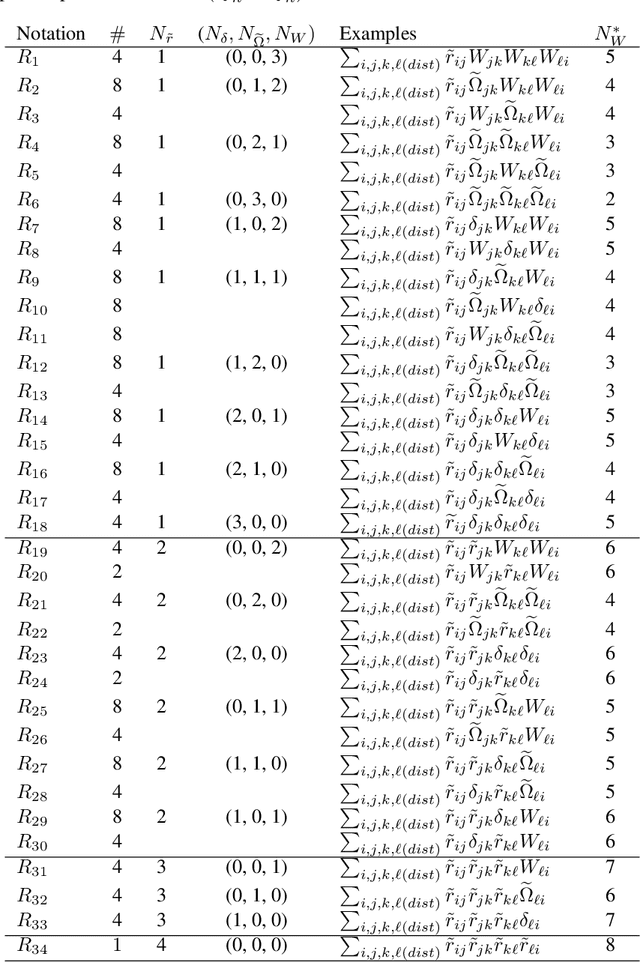
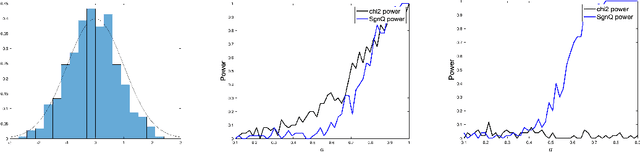
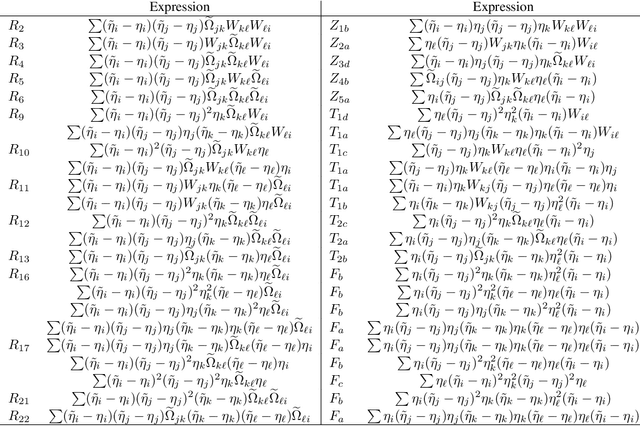
How to detect a small community in a large network is an interesting problem, including clique detection as a special case, where a naive degree-based $\chi^2$-test was shown to be powerful in the presence of an Erd\H{o}s-Renyi background. Using Sinkhorn's theorem, we show that the signal captured by the $\chi^2$-test may be a modeling artifact, and it may disappear once we replace the Erd\H{o}s-Renyi model by a broader network model. We show that the recent SgnQ test is more appropriate for such a setting. The test is optimal in detecting communities with sizes comparable to the whole network, but has never been studied for our setting, which is substantially different and more challenging. Using a degree-corrected block model (DCBM), we establish phase transitions of this testing problem concerning the size of the small community and the edge densities in small and large communities. When the size of the small community is larger than $\sqrt{n}$, the SgnQ test is optimal for it attains the computational lower bound (CLB), the information lower bound for methods allowing polynomial computation time. When the size of the small community is smaller than $\sqrt{n}$, we establish the parameter regime where the SgnQ test has full power and make some conjectures of the CLB. We also study the classical information lower bound (LB) and show that there is always a gap between the CLB and LB in our range of interest.
EnergyShield: Provably-Safe Offloading of Neural Network Controllers for Energy Efficiency
Feb 13, 2023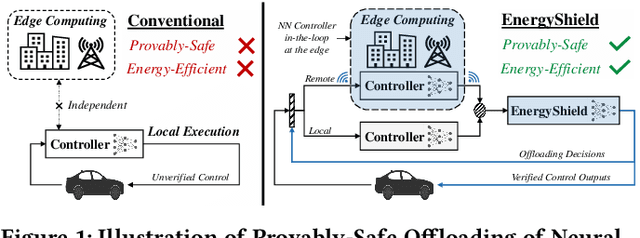
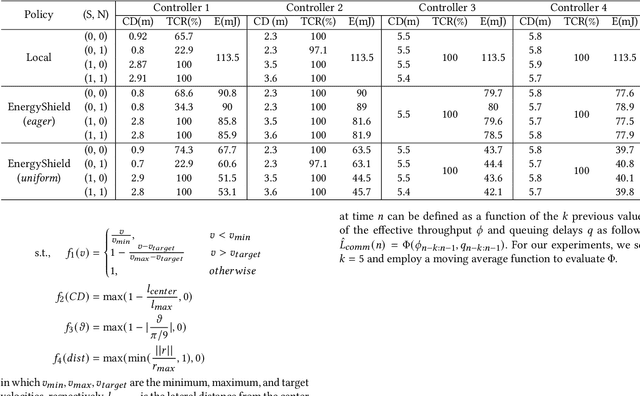
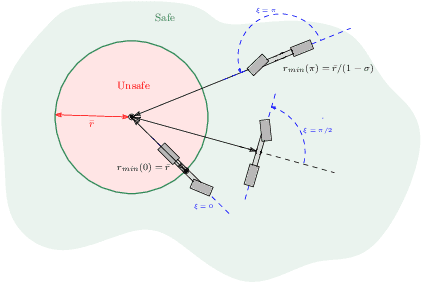
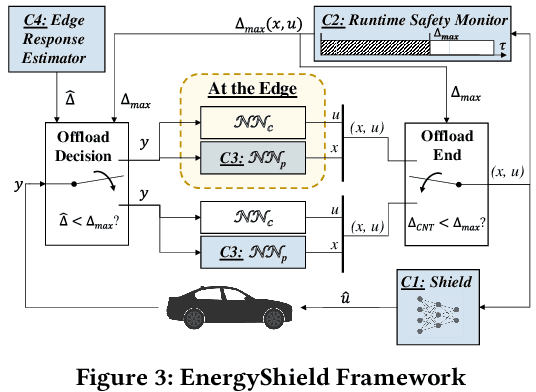
To mitigate the high energy demand of Neural Network (NN) based Autonomous Driving Systems (ADSs), we consider the problem of offloading NN controllers from the ADS to nearby edge-computing infrastructure, but in such a way that formal vehicle safety properties are guaranteed. In particular, we propose the EnergyShield framework, which repurposes a controller ''shield'' as a low-power runtime safety monitor for the ADS vehicle. Specifically, the shield in EnergyShield provides not only safety interventions but also a formal, state-based quantification of the tolerable edge response time before vehicle safety is compromised. Using EnergyShield, an ADS can then save energy by wirelessly offloading NN computations to edge computers, while still maintaining a formal guarantee of safety until it receives a response (on-vehicle hardware provides a just-in-time fail safe). To validate the benefits of EnergyShield, we implemented and tested it in the Carla simulation environment. Our results show that EnergyShield maintains safe vehicle operation while providing significant energy savings compared to on-vehicle NN evaluation: from 24% to 54% less energy across a range of wireless conditions and edge delays.
The Hypervolume Indicator Hessian Matrix: Analytical Expression, Computational Time Complexity, and Sparsity
Nov 15, 2022

The problem of approximating the Pareto front of a multiobjective optimization problem can be reformulated as the problem of finding a set that maximizes the hypervolume indicator. This paper establishes the analytical expression of the Hessian matrix of the mapping from a (fixed size) collection of $n$ points in the $d$-dimensional decision space (or $m$ dimensional objective space) to the scalar hypervolume indicator value. To define the Hessian matrix, the input set is vectorized, and the matrix is derived by analytical differentiation of the mapping from a vectorized set to the hypervolume indicator. The Hessian matrix plays a crucial role in second-order methods, such as the Newton-Raphson optimization method, and it can be used for the verification of local optimal sets. So far, the full analytical expression was only established and analyzed for the relatively simple bi-objective case. This paper will derive the full expression for arbitrary dimensions ($m\geq2$ objective functions). For the practically important three-dimensional case, we also provide an asymptotically efficient algorithm with time complexity in $O(n\log n)$ for the exact computation of the Hessian Matrix' non-zero entries. We establish a sharp bound of $12m-6$ for the number of non-zero entries. Also, for the general $m$-dimensional case, a compact recursive analytical expression is established, and its algorithmic implementation is discussed. Also, for the general case, some sparsity results can be established; these results are implied by the recursive expression. To validate and illustrate the analytically derived algorithms and results, we provide a few numerical examples using Python and Mathematica implementations. Open-source implementations of the algorithms and testing data are made available as a supplement to this paper.
Concept Learning for Interpretable Multi-Agent Reinforcement Learning
Feb 23, 2023
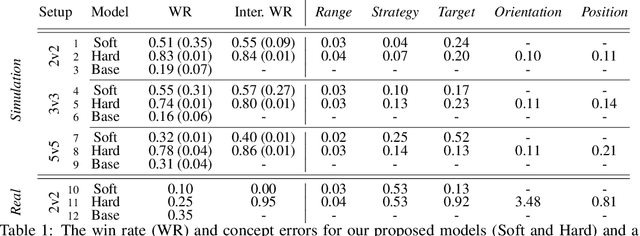
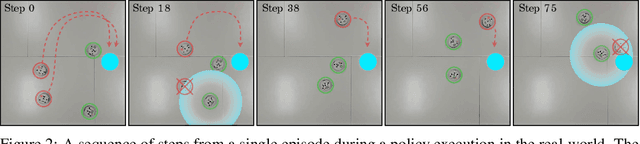
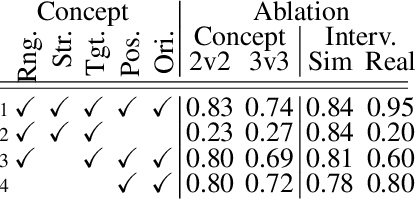
Multi-agent robotic systems are increasingly operating in real-world environments in close proximity to humans, yet are largely controlled by policy models with inscrutable deep neural network representations. We introduce a method for incorporating interpretable concepts from a domain expert into models trained through multi-agent reinforcement learning, by requiring the model to first predict such concepts then utilize them for decision making. This allows an expert to both reason about the resulting concept policy models in terms of these high-level concepts at run-time, as well as intervene and correct mispredictions to improve performance. We show that this yields improved interpretability and training stability, with benefits to policy performance and sample efficiency in a simulated and real-world cooperative-competitive multi-agent game.