 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Risk Classification of Brain Metastases via Radiomics, Delta-Radiomics and Machine Learning
Feb 17, 2023
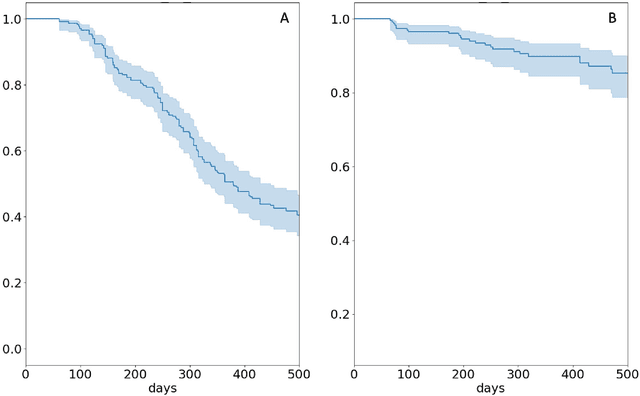

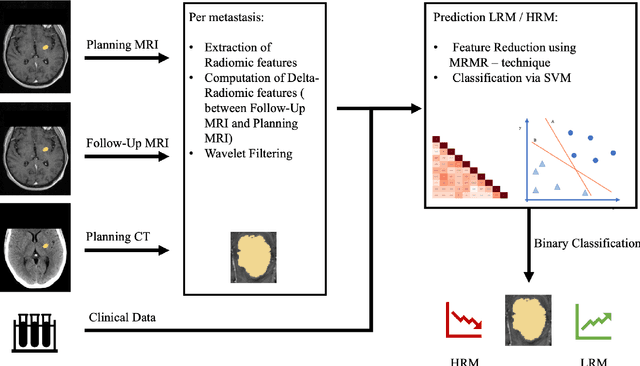
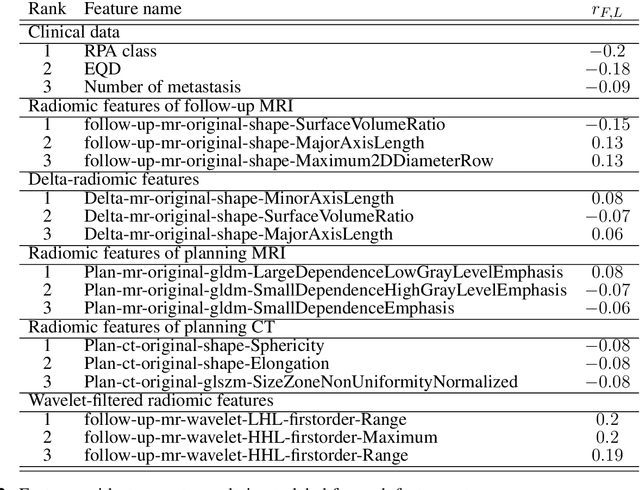
Stereotactic radiotherapy (SRT) is one of the most important treatment for patients with brain metastases (BM). Conventionally, following SRT patients are monitored by serial imaging and receive salvage treatments in case of significant tumor growth. We hypothesized that using radiomics and machine learning (ML), metastases at high risk for subsequent progression could be identified during follow-up prior to the onset of significant tumor growth, enabling personalized follow-up intervals and early selection for salvage treatment. All experiments are performed on a dataset from clinical routine of the Radiation Oncology department of the University Hospital Erlangen (UKER). The classification is realized via the maximum-relevance minimal-redundancy (MRMR) technique and support vector machines (SVM). The pipeline leads to a classification with a mean area under the curve (AUC) score of 0.83 in internal cross-validation and allows a division of the cohort into two subcohorts that differ significantly in their median time to progression (low-risk metastasis (LRM): 17.3 months, high-risk metastasis (HRM): 9.6 months, p < 0.01). The classification performance is especially enhanced by the analysis of medical images from different points in time (AUC 0.53 -> AUC 0.74). The results indicate that risk stratification of BM based on radiomics and machine learning during post-SRT follow-up is possible with good accuracy and should be further pursued to personalize and improve post-SRT follow-up.
Efficient subtyping of ovarian cancer histopathology whole slide images using active sampling in multiple instance learning
Feb 17, 2023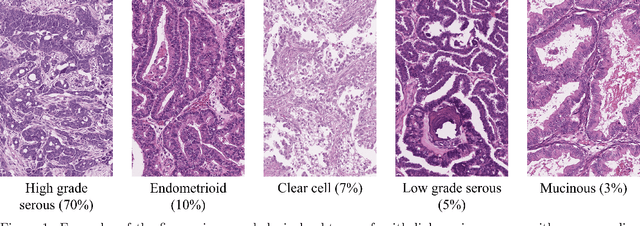

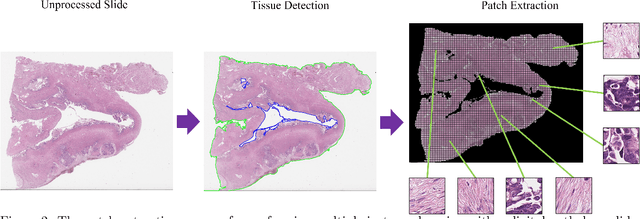
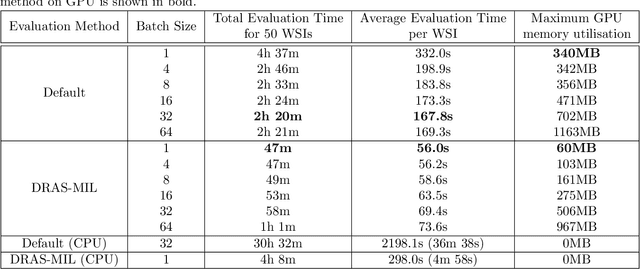
Weakly-supervised classification of histopathology slides is a computationally intensive task, with a typical whole slide image (WSI) containing billions of pixels to process. We propose Discriminative Region Active Sampling for Multiple Instance Learning (DRAS-MIL), a computationally efficient slide classification method using attention scores to focus sampling on highly discriminative regions. We apply this to the diagnosis of ovarian cancer histological subtypes, which is an essential part of the patient care pathway as different subtypes have different genetic and molecular profiles, treatment options, and patient outcomes. We use a dataset of 714 WSIs acquired from 147 epithelial ovarian cancer patients at Leeds Teaching Hospitals NHS Trust to distinguish the most common subtype, high-grade serous carcinoma, from the other four subtypes (low-grade serous, endometrioid, clear cell, and mucinous carcinomas) combined. We demonstrate that DRAS-MIL can achieve similar classification performance to exhaustive slide analysis, with a 3-fold cross-validated AUC of 0.8679 compared to 0.8781 with standard attention-based MIL classification. Our approach uses at most 18% as much memory as the standard approach, while taking 33% of the time when evaluating on a GPU and only 14% on a CPU alone. Reducing prediction time and memory requirements may benefit clinical deployment and the democratisation of AI, reducing the extent to which computational hardware limits end-user adoption.
Learning Deep Semantics for Test Completion
Mar 07, 2023
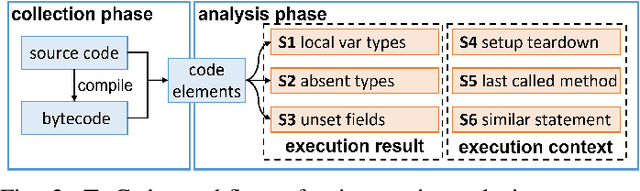
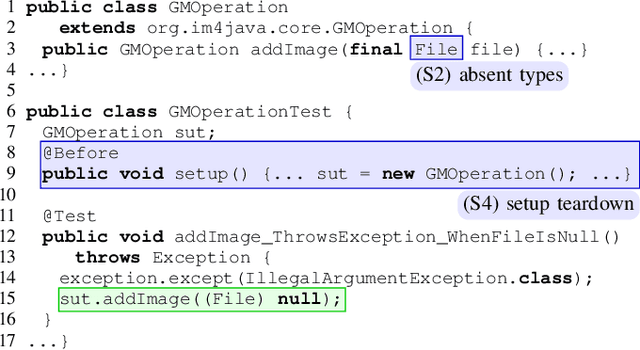
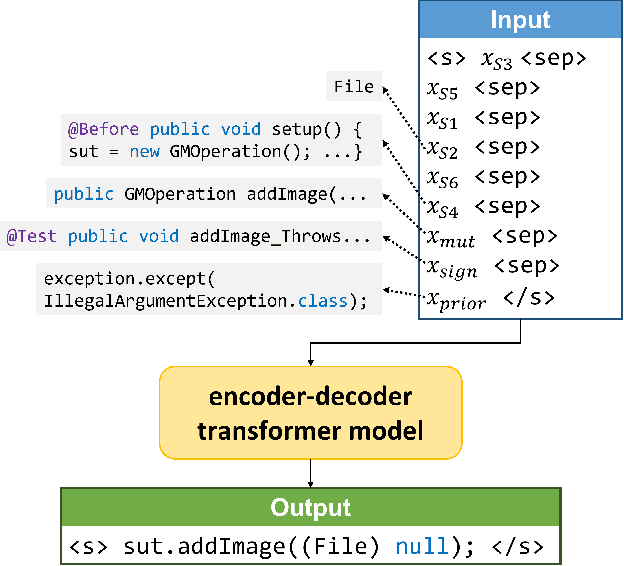
Writing tests is a time-consuming yet essential task during software development. We propose to leverage recent advances in deep learning for text and code generation to assist developers in writing tests. We formalize the novel task of test completion to automatically complete the next statement in a test method based on the context of prior statements and the code under test. We develop TeCo -- a deep learning model using code semantics for test completion. The key insight underlying TeCo is that predicting the next statement in a test method requires reasoning about code execution, which is hard to do with only syntax-level data that existing code completion models use. TeCo extracts and uses six kinds of code semantics data, including the execution result of prior statements and the execution context of the test method. To provide a testbed for this new task, as well as to evaluate TeCo, we collect a corpus of 130,934 test methods from 1,270 open-source Java projects. Our results show that TeCo achieves an exact-match accuracy of 18, which is 29% higher than the best baseline using syntax-level data only. When measuring functional correctness of generated next statement, TeCo can generate runnable code in 29% of the cases compared to 18% obtained by the best baseline. Moreover, TeCo is significantly better than prior work on test oracle generation.
Amplitude-Varying Perturbation for Balancing Privacy and Utility in Federated Learning
Mar 07, 2023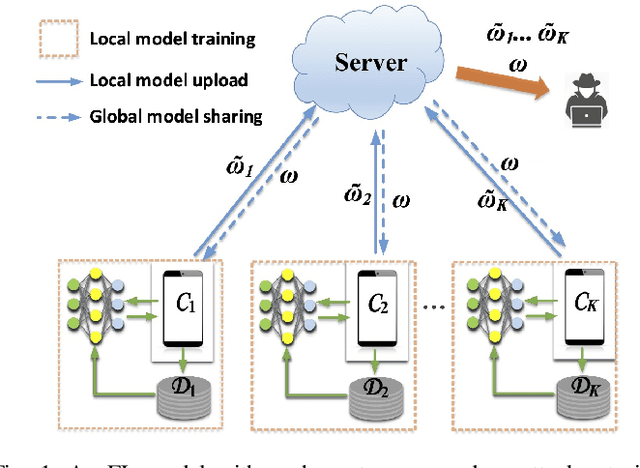
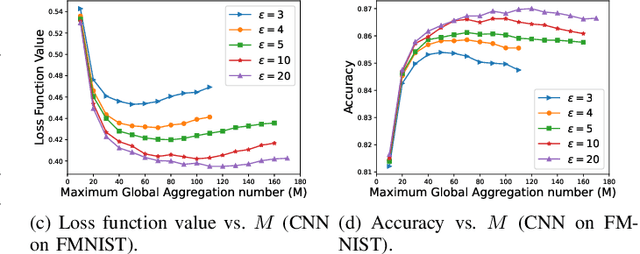
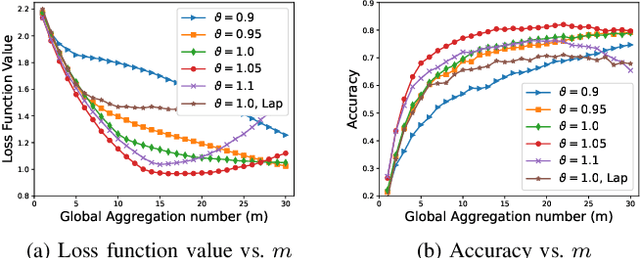
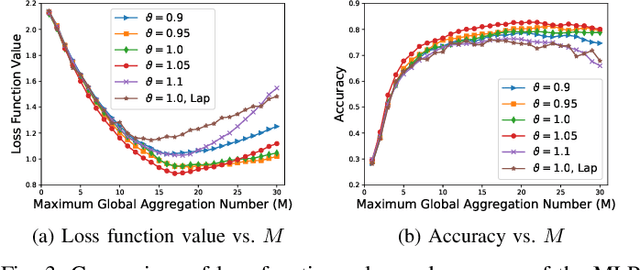
While preserving the privacy of federated learning (FL), differential privacy (DP) inevitably degrades the utility (i.e., accuracy) of FL due to model perturbations caused by DP noise added to model updates. Existing studies have considered exclusively noise with persistent root-mean-square amplitude and overlooked an opportunity of adjusting the amplitudes to alleviate the adverse effects of the noise. This paper presents a new DP perturbation mechanism with a time-varying noise amplitude to protect the privacy of FL and retain the capability of adjusting the learning performance. Specifically, we propose a geometric series form for the noise amplitude and reveal analytically the dependence of the series on the number of global aggregations and the $(\epsilon,\delta)$-DP requirement. We derive an online refinement of the series to prevent FL from premature convergence resulting from excessive perturbation noise. Another important aspect is an upper bound developed for the loss function of a multi-layer perceptron (MLP) trained by FL running the new DP mechanism. Accordingly, the optimal number of global aggregations is obtained, balancing the learning and privacy. Extensive experiments are conducted using MLP, supporting vector machine, and convolutional neural network models on four public datasets. The contribution of the new DP mechanism to the convergence and accuracy of privacy-preserving FL is corroborated, compared to the state-of-the-art Gaussian noise mechanism with a persistent noise amplitude.
Hybrid quantum-classical convolutional neural network for phytoplankton classification
Mar 07, 2023
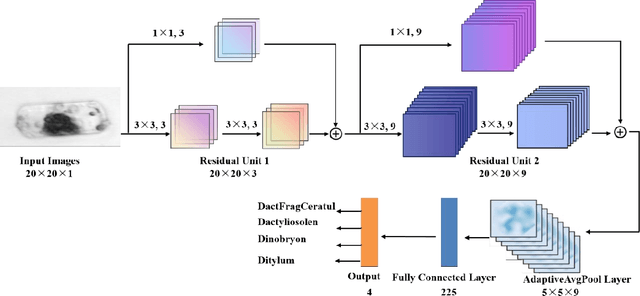
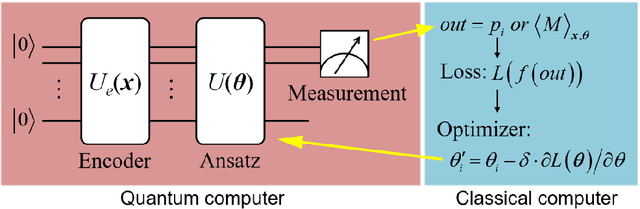
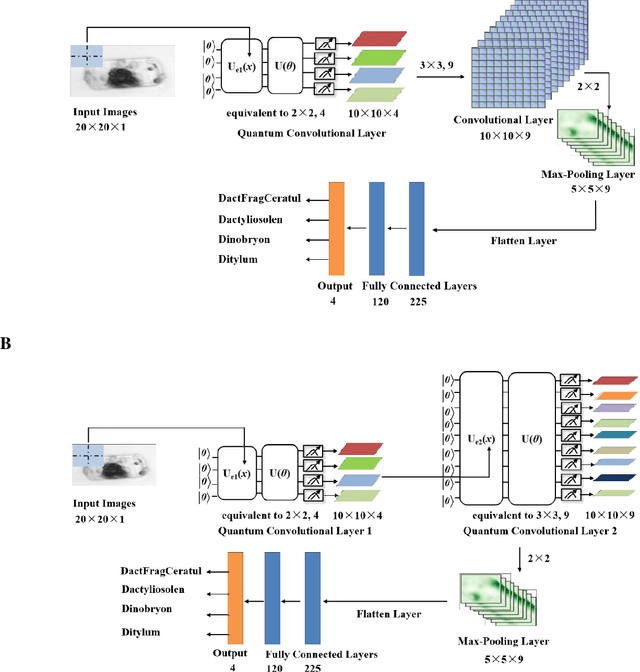
The taxonomic composition and abundance of phytoplankton, having direct impact on marine ecosystem dynamic and global environment change, are listed as essential ocean variables. Phytoplankton classification is very crucial for Phytoplankton analysis, but it is very difficult because of the huge amount and tiny volume of Phytoplankton. Machine learning is the principle way of performing phytoplankton image classification automatically. When carrying out large-scale research on the marine phytoplankton, the volume of data increases overwhelmingly and more powerful computational resources are required for the success of machine learning algorithms. Recently, quantum machine learning has emerged as the potential solution for large-scale data processing by harnessing the exponentially computational power of quantum computer. Here, for the first time, we demonstrate the feasibility of quantum deep neural networks for phytoplankton classification. Hybrid quantum-classical convolutional and residual neural networks are developed based on the classical architectures. These models make a proper balance between the limited function of the current quantum devices and the large size of phytoplankton images, which make it possible to perform phytoplankton classification on the near-term quantum computers. Better performance is obtained by the quantum-enhanced models against the classical counterparts. In particular, quantum models converge much faster than classical ones. The present quantum models are versatile, and can be applied for various tasks of image classification in the field of marine science.
Hidden Knowledge: Mathematical Methods for the Extraction of the Fingerprint of Medieval Paper from Digital Images
Mar 07, 2023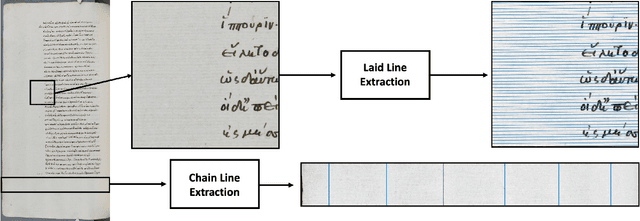



Medieval paper, a handmade product, is made with a mould which leaves an indelible imprint on the sheet of paper. This imprint includes chain lines, laid lines and watermarks which are often visible on the sheet. Extracting these features allows the identification of paper stock and gives information about chronology, localisation and movement of books and people. Most computational work for feature extraction of paper analysis has so far focused on radiography or transmitted light images. While these imaging methods provide clear visualisation for the features of interest, they are expensive and time consuming in their acquisition and not feasible for smaller institutions. However, reflected light images of medieval paper manuscripts are abundant and possibly cheaper in their acquisition. In this paper, we propose algorithms to detect and extract the laid and chain lines from reflected light images. We tackle the main drawback of reflected light images, that is, the low contrast attenuation of lines and intensity jumps due to noise and degradation, by employing the spectral total variation decomposition and develop methods for subsequent line extraction. Our results clearly demonstrate the feasibility of using reflected light images in paper analysis. This work enables the feature extraction for paper manuscripts that have otherwise not been analysed due to a lack of appropriate images. We also open the door for paper stock identification at scale.
Proactive Prioritization of App Issues via Contrastive Learning
Mar 12, 2023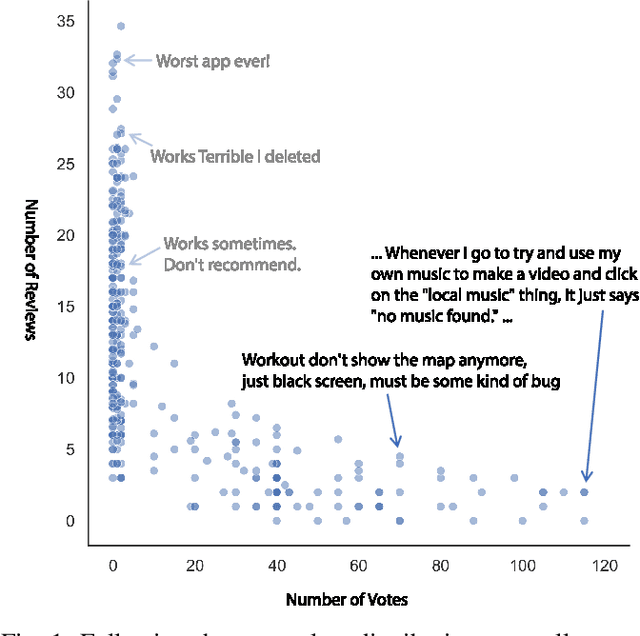
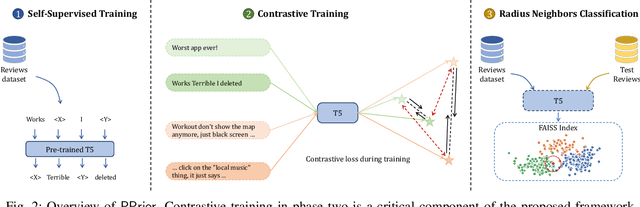
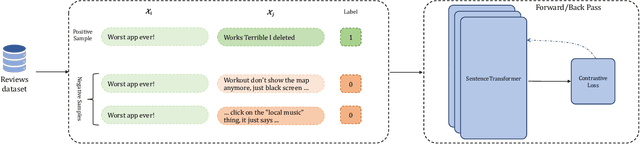
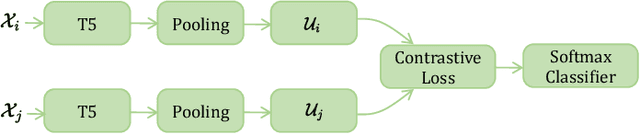
Mobile app stores produce a tremendous amount of data in the form of user reviews, which is a huge source of user requirements and sentiments; such reviews allow app developers to proactively address issues in their apps. However, only a small number of reviews capture common issues and sentiments which creates a need for automatically identifying prominent reviews. Unfortunately, most existing work in text ranking and popularity prediction focuses on social contexts where other signals are available, which renders such works ineffective in the context of app reviews. In this work, we propose a new framework, PPrior, that enables proactive prioritization of app issues through identifying prominent reviews (ones predicted to receive a large number of votes in a given time window). Predicting highly-voted reviews is challenging given that, unlike social posts, social network features of users are not available. Moreover, there is an issue of class imbalance, since a large number of user reviews receive little to no votes. PPrior employs a pre-trained T5 model and works in three phases. Phase one adapts the pre-trained T5 model to the user reviews data in a self-supervised fashion. In phase two, we leverage contrastive training to learn a generic and task-independent representation of user reviews. Phase three uses radius neighbors classifier t o m ake t he final predictions. This phase also uses FAISS index for scalability and efficient search. To conduct extensive experiments, we acquired a large dataset of over 2.1 million user reviews from Google Play. Our experimental results demonstrate the effectiveness of the proposed framework when compared against several state-of-the-art approaches. Moreover, the accuracy of PPrior in predicting prominent reviews is comparable to that of experienced app developers.
Heart Murmur and Abnormal PCG Detection via Wavelet Scattering Transform & a 1D-CNN
Mar 12, 2023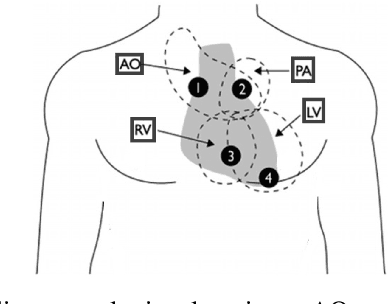
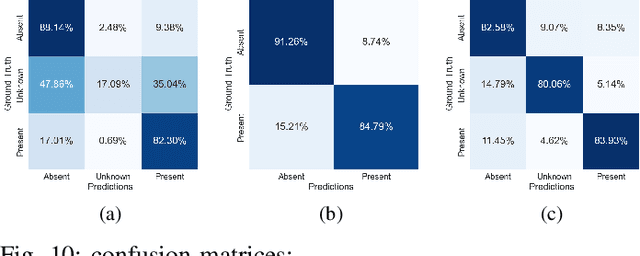
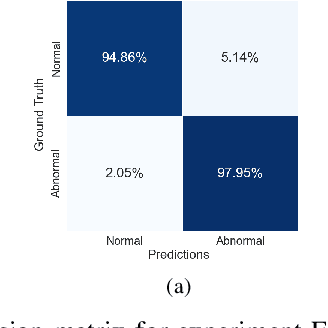
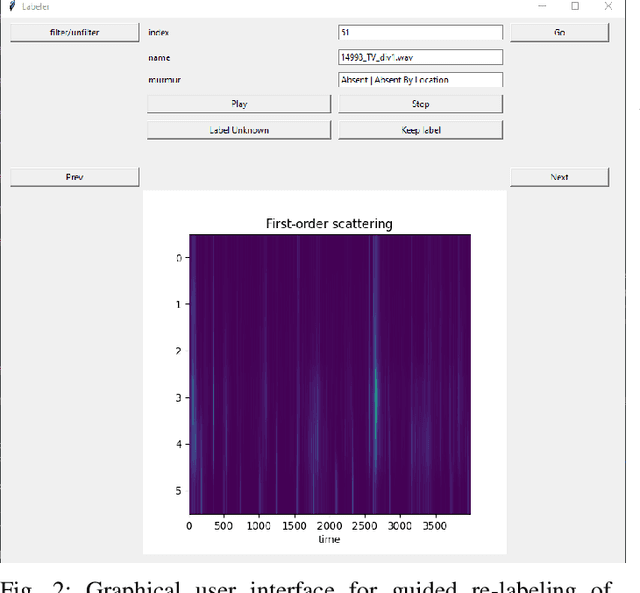
This work leverages deep learning (DL) techniques in order to do automatic and accurate heart murmur detection from phonocardiogram (PCG) recordings. Two public PCG datasets (CirCor Digiscope 2022 dataset and PCG 2016 dataset) from Physionet online database are utilized to train and test three custom neural networks (NN): a 1D convolutional neural network (CNN), a long short-term memory (LSTM) recurrent neural network (RNN), and a convolutional RNN (C-RNN). Under our proposed method, we first do pre-processing on both datasets in order to prepare the data for the NNs. Key pre-processing steps include the following: denoising, segmentation, re-labeling of noise-only segments, data normalization, and time-frequency analysis of the PCG segments using wavelet scattering transform. To evaluate the performance of the three NNs we have implemented, we conduct four experiments, first three using PCG 2022 dataset, and fourth using PCG 2016 dataset. It turns out that our custom 1D-CNN outperforms other two NNs (LSTM- RNN and C-RNN) as well as the state-of-the-art. Specifically, for experiment E1 (murmur detection using original PCG 2022 dataset), our 1D-CNN model achieves an accuracy of 82.28%, weighted accuracy of 83.81%, F1-score of 65.79%, and and area under receive operating charactertic (AUROC) curve of 90.79%. For experiment E2 (mumur detection using PCG 2022 dataset with unknown class removed), our 1D-CNN model achieves an accuracy of 87.05%, F1-score of 87.72%, and AUROC of 94.4%. For experiment E3 (murmur detection using PCG 2022 dataset with re-labeling of segments), our 1D-CNN model achieves an accuracy of 82.86%, weighted accuracy of 86.30%, F1-score of 81.87%, and AUROC of 93.45%. For experiment E4 (abnormal PCG detection using PCG 2016 dataset), our 1D-CNN model achieves an accuracy of 96.30%, F1-score of 96.29% and AUROC of 98.17%.
Vehicle Fault-Tolerant Robust Power Transmission Line Inspection Planning
Feb 02, 2023
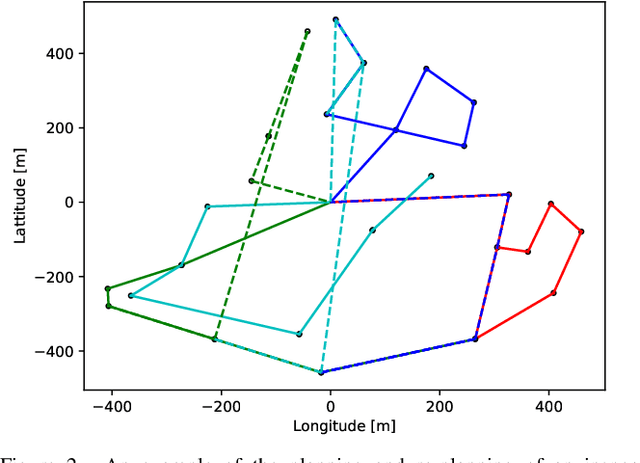
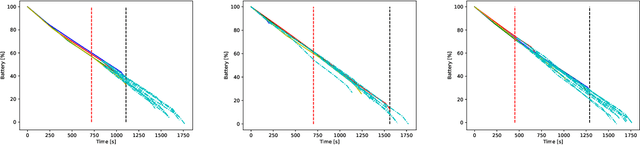
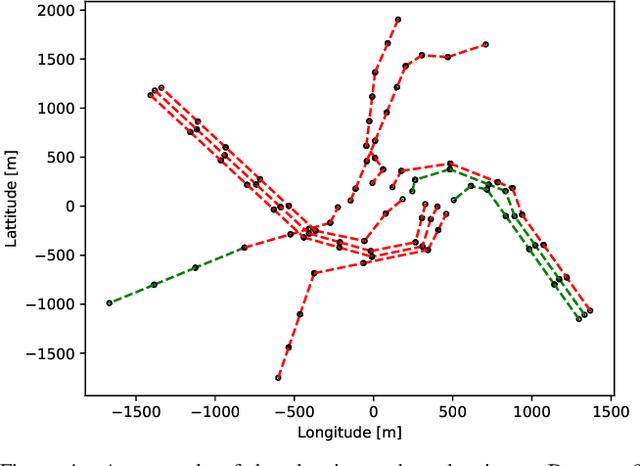
This paper concerns fault-tolerant power transmission line inspection planning as a generalization of the multiple traveling salesmen problem. The addressed inspection planning problem is formulated as a single-depot multiple-vehicle scenario, where the inspection vehicles are constrained by the battery budget limiting their inspection time. The inspection vehicle is assumed to be an autonomous multi-copter with a wide range of possible flight speeds influencing battery consumption. The inspection plan is represented by multiple routes for vehicles providing full coverage over inspection target power lines. On an inspection vehicle mission interruption, which might happen at any time during the execution of the inspection plan, the inspection is re-planned using the remaining vehicles and their remaining battery budgets. Robustness is introduced by choosing a suitable cost function for the initial plan that maximizes the time window for successful re-planning. It enables the remaining vehicles to successfully finish all the inspection targets using their respective remaining battery budgets. A combinatorial metaheuristic algorithm with various cost functions is used for planning and fast re-planning during the inspection.
* Copyright 2022 IEEE. Personal use of this material is permitted. Permission from IEEE must be obtained for all other uses, in any current or future media, including reprinting/republishing this material for advertising or promotional purposes, creating new collective works, for resale or redistribution to servers or lists, or reuse of any copyrighted component of this work in other works
SDYN-GANs: Adversarial Learning Methods for Multistep Generative Models for General Order Stochastic Dynamics
Feb 07, 2023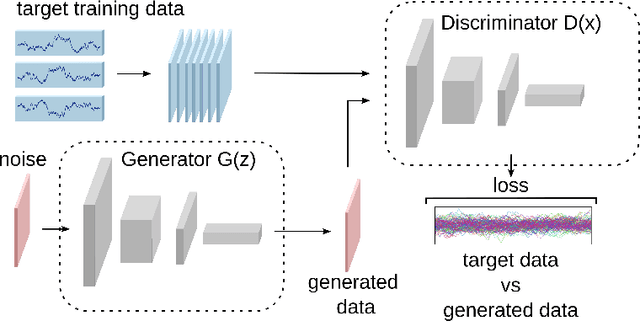
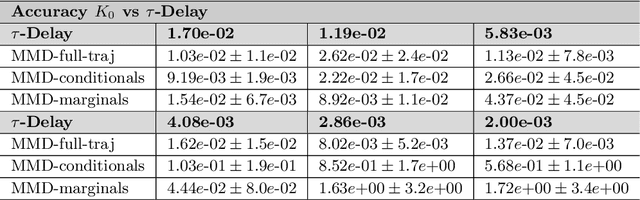
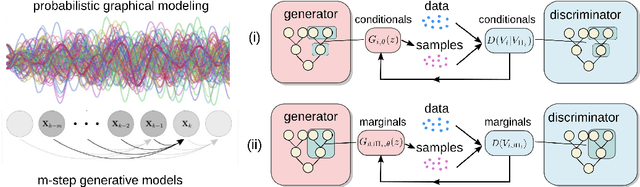
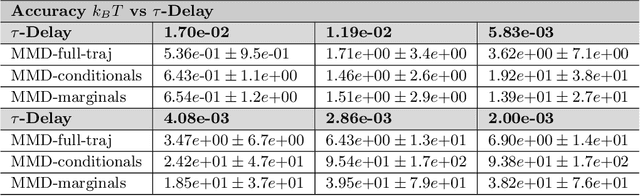
We introduce adversarial learning methods for data-driven generative modeling of the dynamics of $n^{th}$-order stochastic systems. Our approach builds on Generative Adversarial Networks (GANs) with generative model classes based on stable $m$-step stochastic numerical integrators. We introduce different formulations and training methods for learning models of stochastic dynamics based on observation of trajectory samples. We develop approaches using discriminators based on Maximum Mean Discrepancy (MMD), training protocols using conditional and marginal distributions, and methods for learning dynamic responses over different time-scales. We show how our approaches can be used for modeling physical systems to learn force-laws, damping coefficients, and noise-related parameters. The adversarial learning approaches provide methods for obtaining stable generative models for dynamic tasks including long-time prediction and developing simulations for stochastic systems.