 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Complement Sparsification: Low-Overhead Model Pruning for Federated Learning
Mar 10, 2023
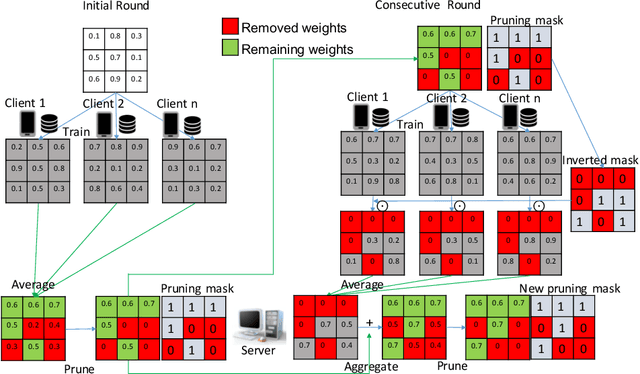
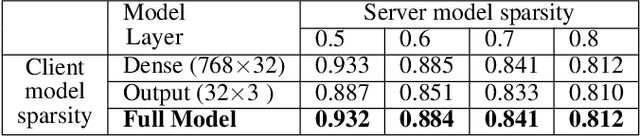
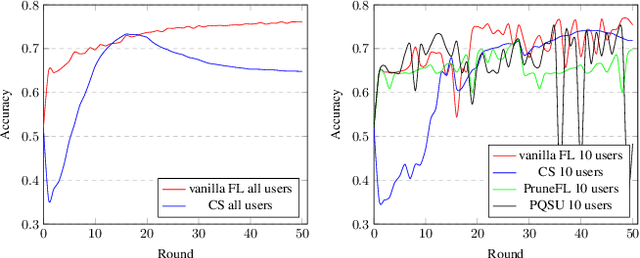
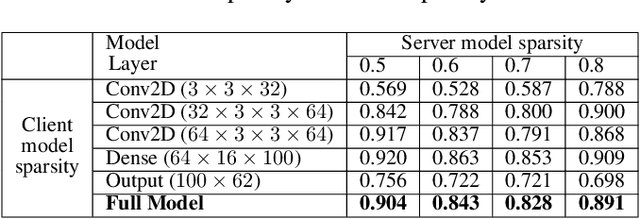
Federated Learning (FL) is a privacy-preserving distributed deep learning paradigm that involves substantial communication and computation effort, which is a problem for resource-constrained mobile and IoT devices. Model pruning/sparsification develops sparse models that could solve this problem, but existing sparsification solutions cannot satisfy at the same time the requirements for low bidirectional communication overhead between the server and the clients, low computation overhead at the clients, and good model accuracy, under the FL assumption that the server does not have access to raw data to fine-tune the pruned models. We propose Complement Sparsification (CS), a pruning mechanism that satisfies all these requirements through a complementary and collaborative pruning done at the server and the clients. At each round, CS creates a global sparse model that contains the weights that capture the general data distribution of all clients, while the clients create local sparse models with the weights pruned from the global model to capture the local trends. For improved model performance, these two types of complementary sparse models are aggregated into a dense model in each round, which is subsequently pruned in an iterative process. CS requires little computation overhead on the top of vanilla FL for both the server and the clients. We demonstrate that CS is an approximation of vanilla FL and, thus, its models perform well. We evaluate CS experimentally with two popular FL benchmark datasets. CS achieves substantial reduction in bidirectional communication, while achieving performance comparable with vanilla FL. In addition, CS outperforms baseline pruning mechanisms for FL.
Time-lapse image classification using a diffractive neural network
Aug 23, 2022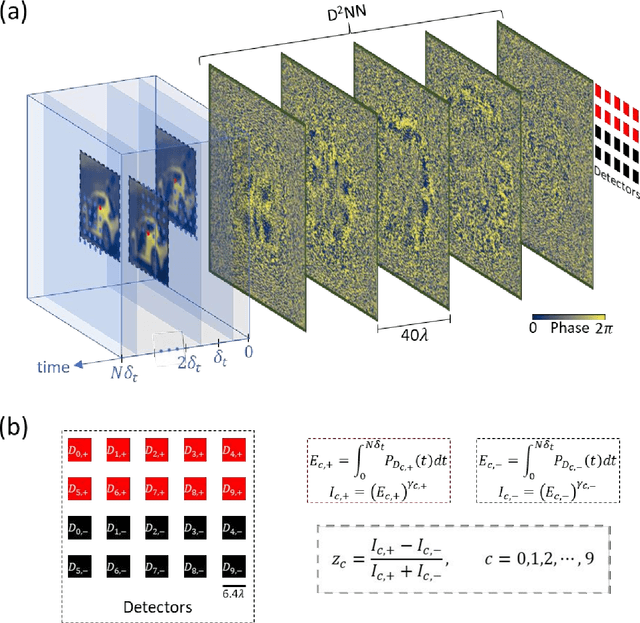
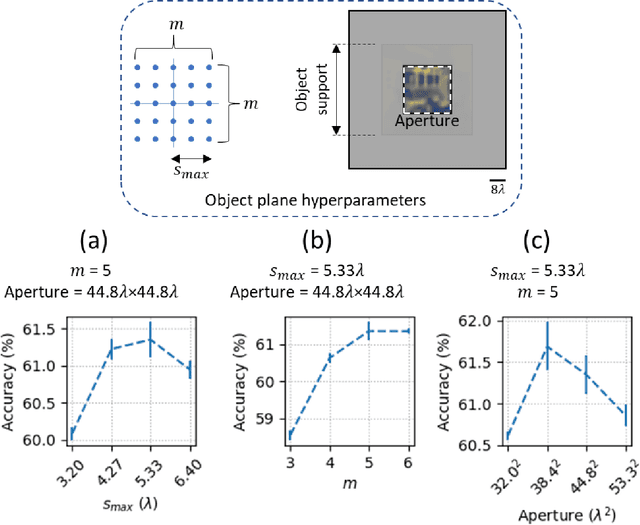
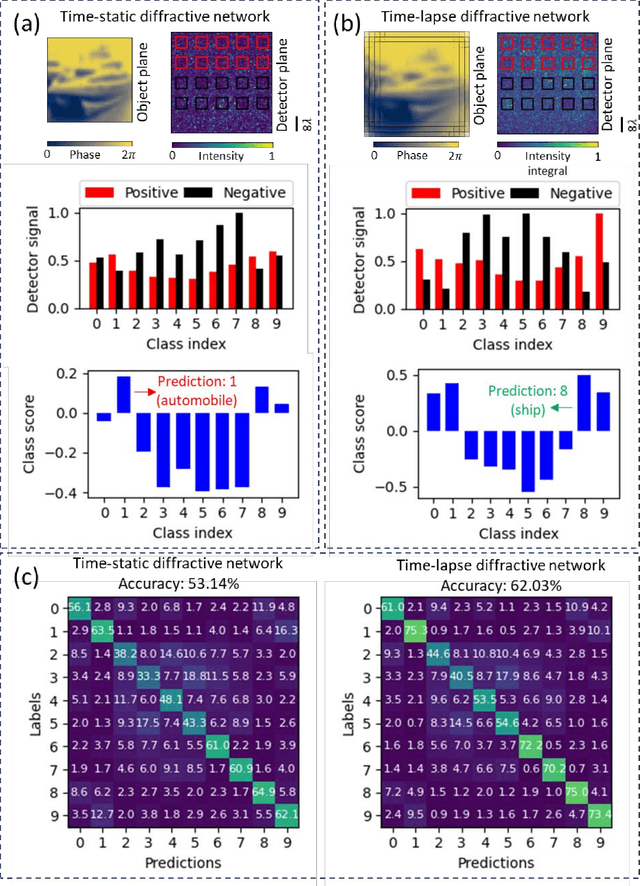
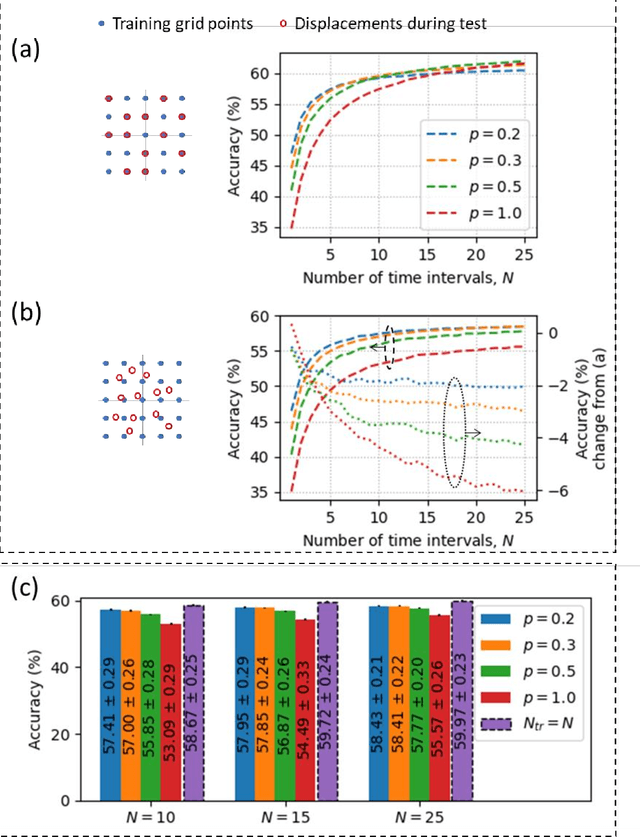
Diffractive deep neural networks (D2NNs) define an all-optical computing framework comprised of spatially engineered passive surfaces that collectively process optical input information by modulating the amplitude and/or the phase of the propagating light. Diffractive optical networks complete their computational tasks at the speed of light propagation through a thin diffractive volume, without any external computing power while exploiting the massive parallelism of optics. Diffractive networks were demonstrated to achieve all-optical classification of objects and perform universal linear transformations. Here we demonstrate, for the first time, a "time-lapse" image classification scheme using a diffractive network, significantly advancing its classification accuracy and generalization performance on complex input objects by using the lateral movements of the input objects and/or the diffractive network, relative to each other. In a different context, such relative movements of the objects and/or the camera are routinely being used for image super-resolution applications; inspired by their success, we designed a time-lapse diffractive network to benefit from the complementary information content created by controlled or random lateral shifts. We numerically explored the design space and performance limits of time-lapse diffractive networks, revealing a blind testing accuracy of 62.03% on the optical classification of objects from the CIFAR-10 dataset. This constitutes the highest inference accuracy achieved so far using a single diffractive network on the CIFAR-10 dataset. Time-lapse diffractive networks will be broadly useful for the spatio-temporal analysis of input signals using all-optical processors.
Market-Aware Models for Efficient Cross-Market Recommendation
Feb 14, 2023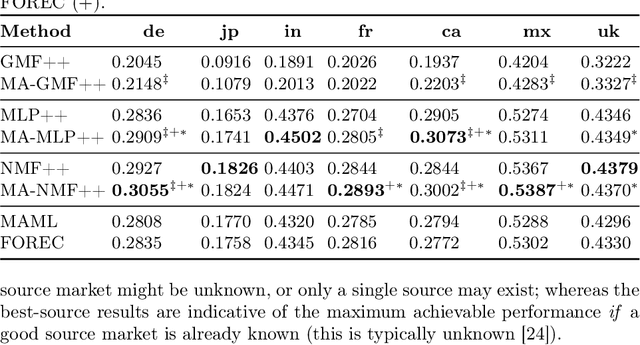
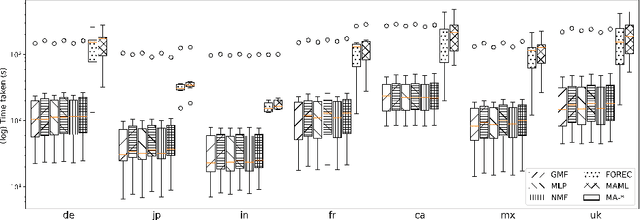
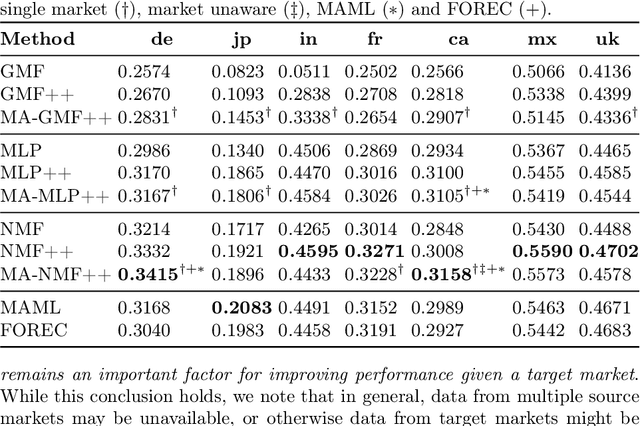
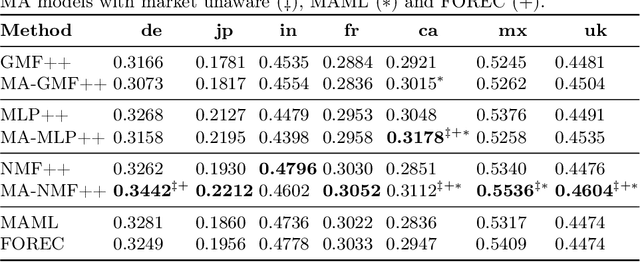
We consider the cross-market recommendation (CMR) task, which involves recommendation in a low-resource target market using data from a richer, auxiliary source market. Prior work in CMR utilised meta-learning to improve recommendation performance in target markets; meta-learning however can be complex and resource intensive. In this paper, we propose market-aware (MA) models, which directly model a market via market embeddings instead of meta-learning across markets. These embeddings transform item representations into market-specific representations. Our experiments highlight the effectiveness and efficiency of MA models both in a pairwise setting with a single target-source market, as well as a global model trained on all markets in unison. In the former pairwise setting, MA models on average outperform market-unaware models in 85% of cases on nDCG@10, while being time-efficient - compared to meta-learning models, MA models require only 15% of the training time. In the global setting, MA models outperform market-unaware models consistently for some markets, while outperforming meta-learning-based methods for all but one market. We conclude that MA models are an efficient and effective alternative to meta-learning, especially in the global setting.
AdapterSoup: Weight Averaging to Improve Generalization of Pretrained Language Models
Feb 14, 2023


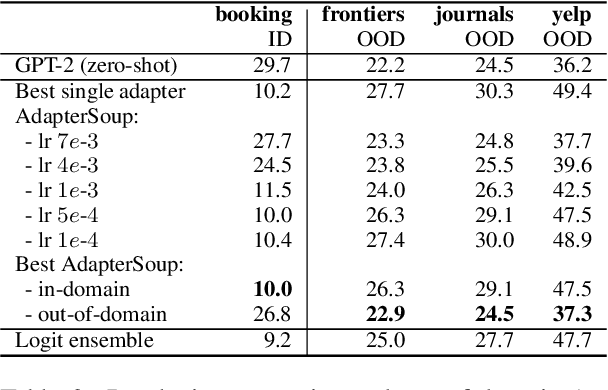
Pretrained language models (PLMs) are trained on massive corpora, but often need to specialize to specific domains. A parameter-efficient adaptation method suggests training an adapter for each domain on the task of language modeling. This leads to good in-domain scores but can be impractical for domain- or resource-restricted settings. A solution is to use a related-domain adapter for the novel domain at test time. In this paper, we introduce AdapterSoup, an approach that performs weight-space averaging of adapters trained on different domains. Our approach is embarrassingly parallel: first, we train a set of domain-specific adapters; then, for each novel domain, we determine which adapters should be averaged at test time. We present extensive experiments showing that AdapterSoup consistently improves performance to new domains without extra training. We also explore weight averaging of adapters trained on the same domain with different hyper-parameters, and show that it preserves the performance of a PLM on new domains while obtaining strong in-domain results. We explore various approaches for choosing which adapters to combine, such as text clustering and semantic similarity. We find that using clustering leads to the most competitive results on novel domains.
Federated Reinforcement Learning for Real-Time Electric Vehicle Charging and Discharging Control
Oct 04, 2022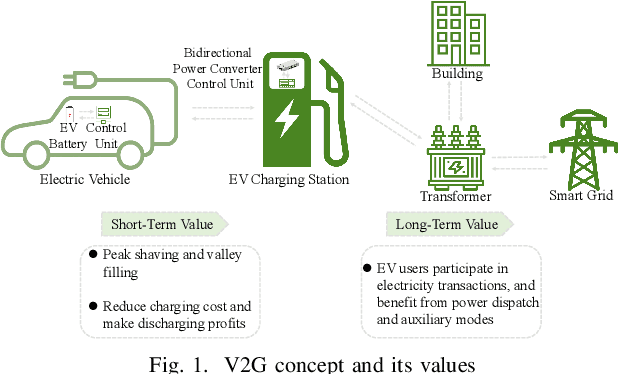
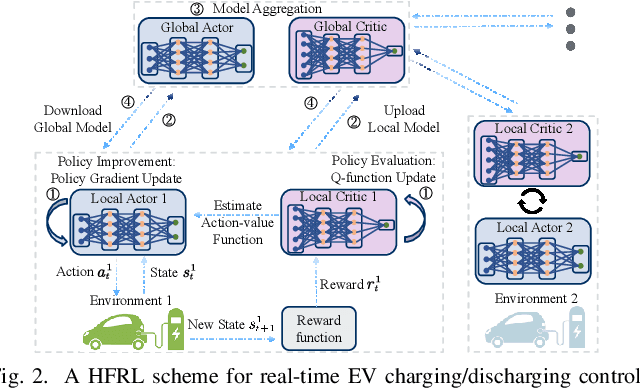
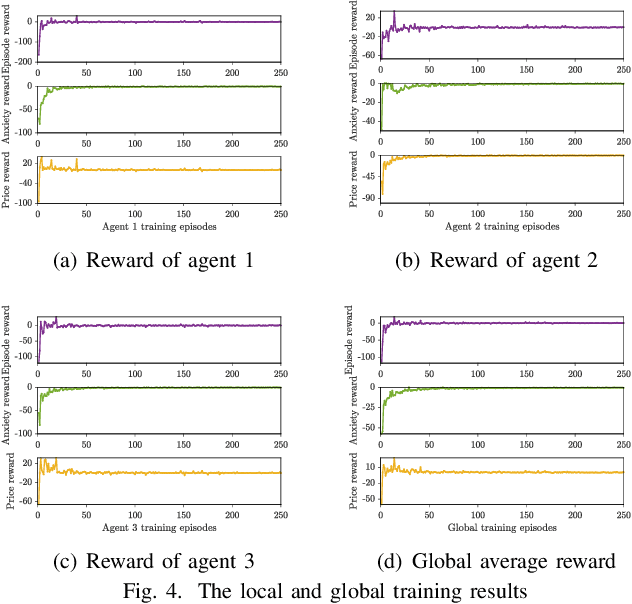
With the recent advances in mobile energy storage technologies, electric vehicles (EVs) have become a crucial part of smart grids. When EVs participate in the demand response program, the charging cost can be significantly reduced by taking full advantage of the real-time pricing signals. However, many stochastic factors exist in the dynamic environment, bringing significant challenges to design an optimal charging/discharging control strategy. This paper develops an optimal EV charging/discharging control strategy for different EV users under dynamic environments to maximize EV users' benefits. We first formulate this problem as a Markov decision process (MDP). Then we consider EV users with different behaviors as agents in different environments. Furthermore, a horizontal federated reinforcement learning (HFRL)-based method is proposed to fit various users' behaviors and dynamic environments. This approach can learn an optimal charging/discharging control strategy without sharing users' profiles. Simulation results illustrate that the proposed real-time EV charging/discharging control strategy can perform well among various stochastic factors.
MulBot: Unsupervised Bot Detection Based on Multivariate Time Series
Sep 21, 2022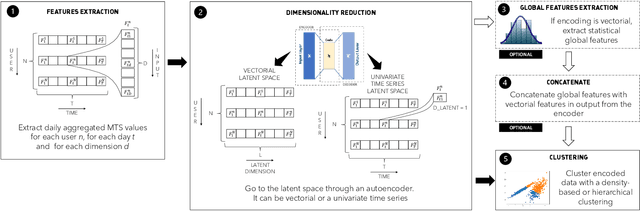


Online social networks are actively involved in the removal of malicious social bots due to their role in the spread of low quality information. However, most of the existing bot detectors are supervised classifiers incapable of capturing the evolving behavior of sophisticated bots. Here we propose MulBot, an unsupervised bot detector based on multivariate time series (MTS). For the first time, we exploit multidimensional temporal features extracted from user timelines. We manage the multidimensionality with an LSTM autoencoder, which projects the MTS in a suitable latent space. Then, we perform a clustering step on this encoded representation to identify dense groups of very similar users -- a known sign of automation. Finally, we perform a binary classification task achieving f1-score $= 0.99$, outperforming state-of-the-art methods (f1-score $\le 0.97$). Not only does MulBot achieve excellent results in the binary classification task, but we also demonstrate its strengths in a novel and practically-relevant task: detecting and separating different botnets. In this multi-class classification task we achieve f1-score $= 0.96$. We conclude by estimating the importance of the different features used in our model and by evaluating MulBot's capability to generalize to new unseen bots, thus proposing a solution to the generalization deficiencies of supervised bot detectors.
Score Matching via Differentiable Physics
Jan 24, 2023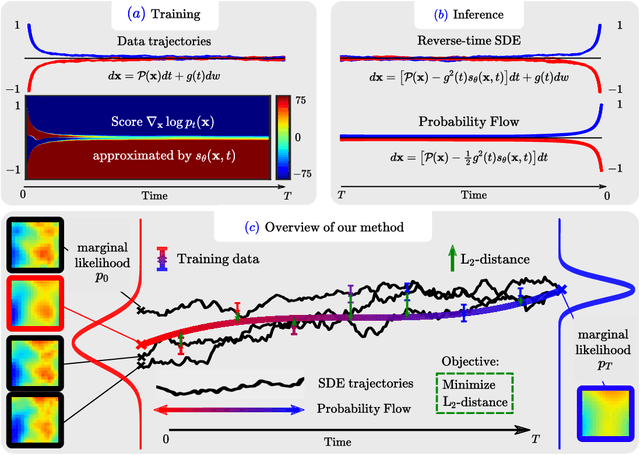
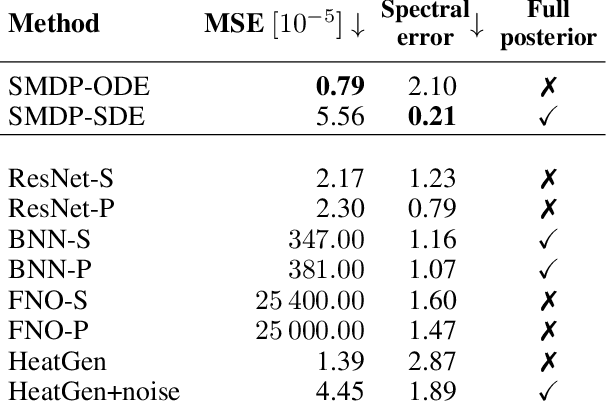
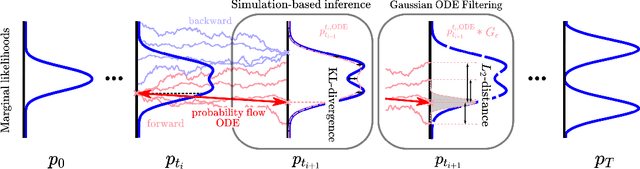
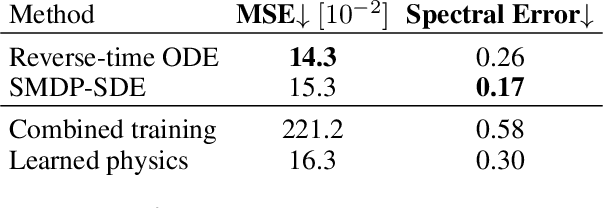
Diffusion models based on stochastic differential equations (SDEs) gradually perturb a data distribution $p(\mathbf{x})$ over time by adding noise to it. A neural network is trained to approximate the score $\nabla_\mathbf{x} \log p_t(\mathbf{x})$ at time $t$, which can be used to reverse the corruption process. In this paper, we focus on learning the score field that is associated with the time evolution according to a physics operator in the presence of natural non-deterministic physical processes like diffusion. A decisive difference to previous methods is that the SDE underlying our approach transforms the state of a physical system to another state at a later time. For that purpose, we replace the drift of the underlying SDE formulation with a differentiable simulator or a neural network approximation of the physics. We propose different training strategies based on the so-called probability flow ODE to fit a training set of simulation trajectories and discuss their relation to the score matching objective. For inference, we sample plausible trajectories that evolve towards a given end state using the reverse-time SDE and demonstrate the competitiveness of our approach for different challenging inverse problems.
An unsupervised learning approach for predicting wind farm power and downstream wakes using weather patterns
Feb 12, 2023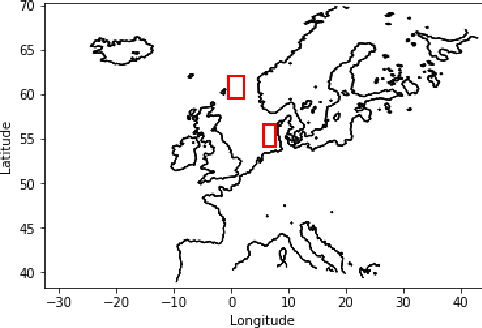
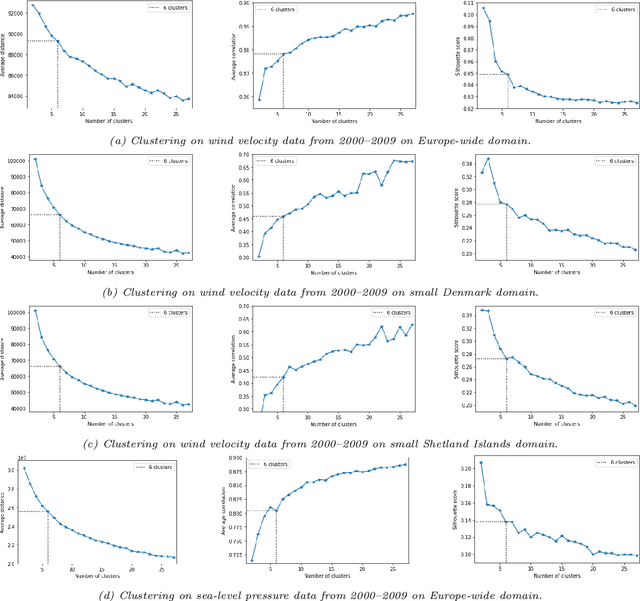
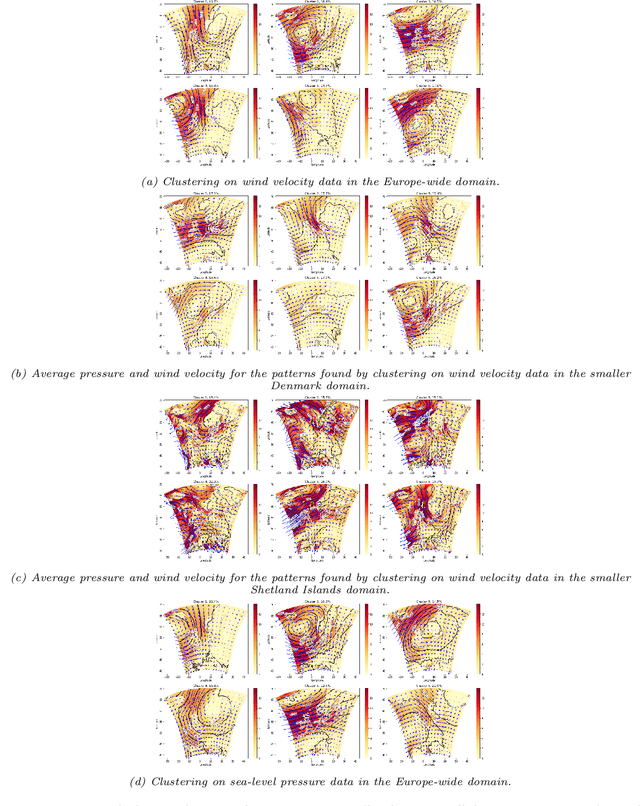
Wind energy resource assessment typically requires numerical models, but such models are too computationally intensive to consider multi-year timescales. Increasingly, unsupervised machine learning techniques are used to identify a small number of representative weather patterns to simulate long-term behaviour. Here we develop a novel wind energy workflow that for the first time combines weather patterns derived from unsupervised clustering techniques with numerical weather prediction models (here WRF) to obtain efficient and accurate long-term predictions of power and downstream wakes from an entire wind farm. We use ERA5 reanalysis data clustering not only on low altitude pressure but also, for the first time, on the more relevant variable of wind velocity. We also compare the use of large-scale and local-scale domains for clustering. A WRF simulation is run at each of the cluster centres and the results are aggregated using a novel post-processing technique. By applying our workflow to two different regions, we show that our long-term predictions agree with those from a year of WRF simulations but require less than 2% of the computational time. The most accurate results are obtained when clustering on wind velocity. Moreover, clustering over the Europe-wide domain is sufficient for predicting wind farm power output, but downstream wake predictions benefit from the use of smaller domains. Finally, we show that these downstream wakes can affect the local weather patterns. Our approach facilitates multi-year predictions of power output and downstream farm wakes, by providing a fast, accurate and flexible methodology that is applicable to any global region. Moreover, these accurate long-term predictions of downstream wakes provide the first tool to help mitigate the effects of wind energy loss downstream of wind farms, since they can be used to determine optimum wind farm locations.
Driver Drowsiness Detection System: An Approach By Machine Learning Application
Mar 11, 2023The majority of human deaths and injuries are caused by traffic accidents. A million people worldwide die each year due to traffic accident injuries, consistent with the World Health Organization. Drivers who do not receive enough sleep, rest, or who feel weary may fall asleep behind the wheel, endangering both themselves and other road users. The research on road accidents specified that major road accidents occur due to drowsiness while driving. These days, it is observed that tired driving is the main reason to occur drowsiness. Now, drowsiness becomes the main principle for to increase in the number of road accidents. This becomes a major issue in a world which is very important to resolve as soon as possible. The predominant goal of all devices is to improve the performance to detect drowsiness in real time. Many devices were developed to detect drowsiness, which depend on different artificial intelligence algorithms. So, our research is also related to driver drowsiness detection which can identify the drowsiness of a driver by identifying the face and then followed by eye tracking. The extracted eye image is matched with the dataset by the system. With the help of the dataset, the system detected that if eyes were close for a certain range, it could ring an alarm to alert the driver and if the eyes were open after the alert, then it could continue tracking. If the eyes were open then the score that we set decreased and if the eyes were closed then the score increased. This paper focus to resolve the problem of drowsiness detection with an accuracy of 80% and helps to reduce road accidents.
EEP-3DQA: Efficient and Effective Projection-based 3D Model Quality Assessment
Feb 17, 2023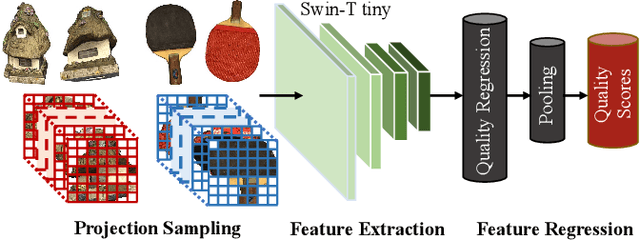
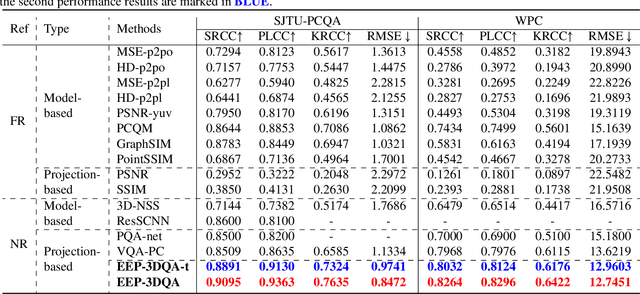

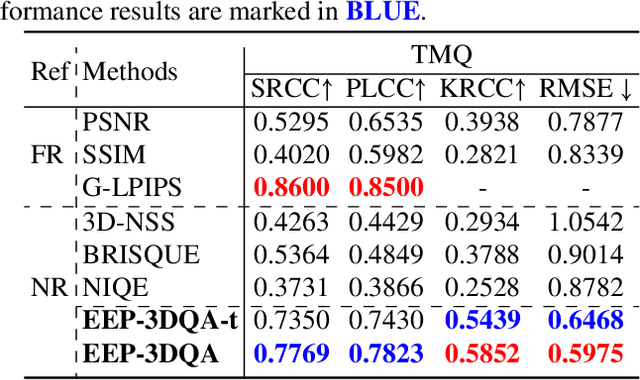
Currently, great numbers of efforts have been put into improving the effectiveness of 3D model quality assessment (3DQA) methods. However, little attention has been paid to the computational costs and inference time, which is also important for practical applications. Unlike 2D media, 3D models are represented by more complicated and irregular digital formats, such as point cloud and mesh. Thus it is normally difficult to perform an efficient module to extract quality-aware features of 3D models. In this paper, we address this problem from the aspect of projection-based 3DQA and develop a no-reference (NR) \underline{E}fficient and \underline{E}ffective \underline{P}rojection-based \underline{3D} Model \underline{Q}uality \underline{A}ssessment (\textbf{EEP-3DQA}) method. The input projection images of EEP-3DQA are randomly sampled from the six perpendicular viewpoints of the 3D model and are further spatially downsampled by the grid-mini patch sampling strategy. Further, the lightweight Swin-Transformer tiny is utilized as the backbone to extract the quality-aware features. Finally, the proposed EEP-3DQA and EEP-3DQA-t (tiny version) achieve the best performance than the existing state-of-the-art NR-3DQA methods and even outperforms most full-reference (FR) 3DQA methods on the point cloud and mesh quality assessment databases while consuming less inference time than the compared 3DQA methods.