 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Distributed Adaptive Norm Estimation for Blind System Identification in Wireless Sensor Networks
Mar 01, 2023
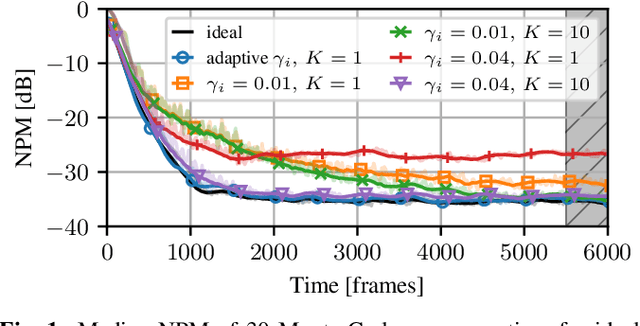

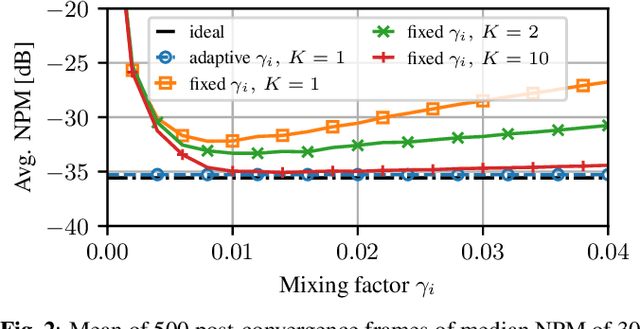
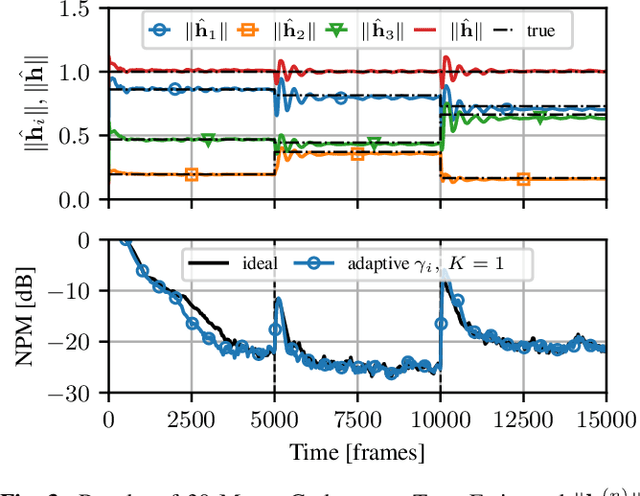
Distributed signal-processing algorithms in (wireless) sensor networks often aim to decentralize processing tasks to reduce communication cost and computational complexity or avoid reliance on a single device (i.e., fusion center) for processing. In this contribution, we extend a distributed adaptive algorithm for blind system identification that relies on the estimation of a stacked network-wide consensus vector at each node, the computation of which requires either broadcasting or relaying of node-specific values (i.e., local vector norms) to all other nodes. The extended algorithm employs a distributed-averaging-based scheme to estimate the network-wide consensus norm value by only using the local vector norm provided by neighboring sensor nodes. We introduce an adaptive mixing factor between instantaneous and recursive estimates of these norms for adaptivity in a time-varying system. Simulation results show that the extension provides estimation results close to the optimal fully-connected-network or broadcasting case while reducing inter-node transmission significantly.
Impact-Invariant Control: Maximizing Control Authority During Impacts
Mar 01, 2023
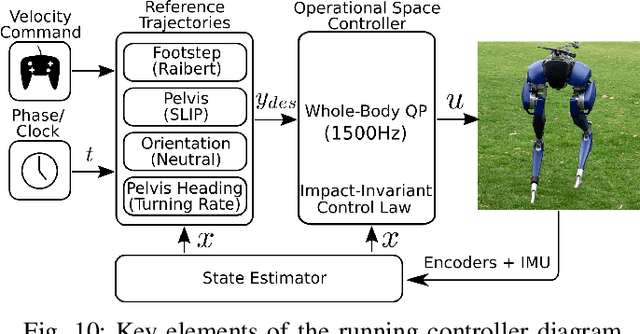
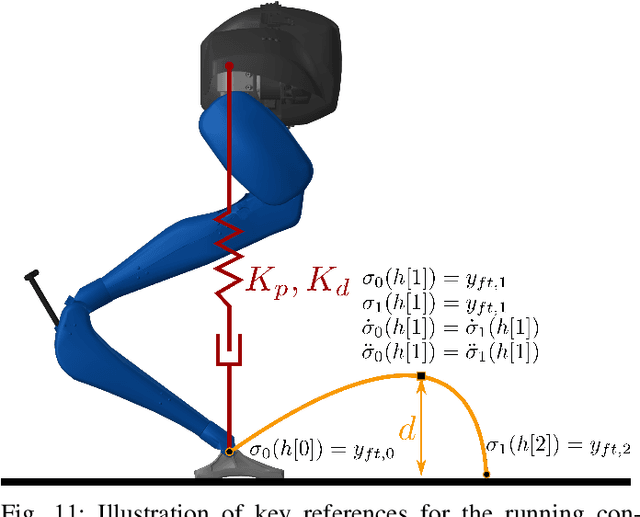
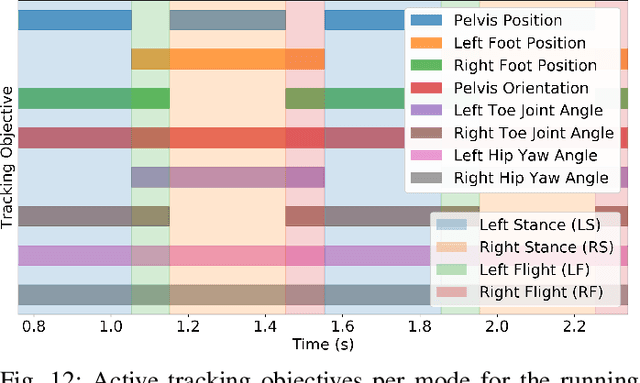
When legged robots impact their environment, they undergo large changes in their velocities in a short amount of time. Measuring and applying feedback to these velocities is challenging, further complicated by uncertainty in the impact model and impact timing. This work proposes a general framework for adapting feedback control during impact by projecting the control objectives to a subspace that is invariant to the impact event. The resultant controller is robust to uncertainties in the impact event while maintaining maximum control authority over the impact-invariant subspace. We demonstrate the improved performance of the projection over other commonly used heuristics on a walking controller for a planar five-link-biped. The projection is also applied to jumping, box jumping on to a platform 0.4 m tall, and running controllers for the compliant 3D bipedal robot, Cassie. The modification is easily applied to these various controllers and is a critical component to deploying on the physical robot.
Long-Term Modeling of Financial Machine Learning for Active Portfolio Management
Jan 29, 2023In the practical business of asset management by investment trusts and the like, the general practice is to manage over the medium to long term owing to the burden of operations and increase in transaction costs with the increase in turnover ratio. However, when machine learning is used to construct a management model, the number of learning data decreases with the increase in the long-term time scale; this causes a decline in the learning precision. Accordingly, in this study, data augmentation was applied by the combined use of not only the time scales of the target tasks but also the learning data of shorter term time scales, demonstrating that degradation of the generalization performance can be inhibited even if the target tasks of machine learning have long-term time scales. Moreover, as an illustration of how this data augmentation can be applied, we conducted portfolio management in which machine learning of a multifactor model was done by an autoencoder and mispricing was used from the estimated theoretical values. The effectiveness could be confirmed in not only the stock market but also the FX market, and a general-purpose management model could be constructed in various financial markets.
Linked Data Science Powered by Knowledge Graphs
Mar 09, 2023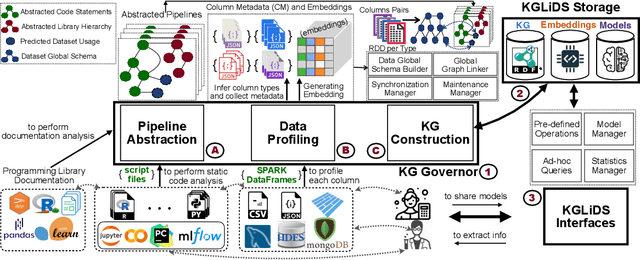
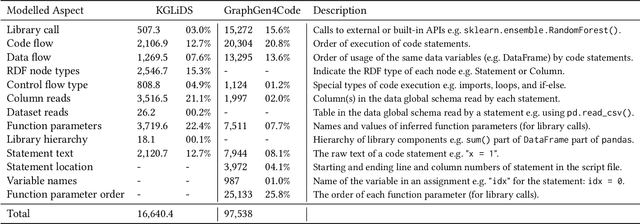
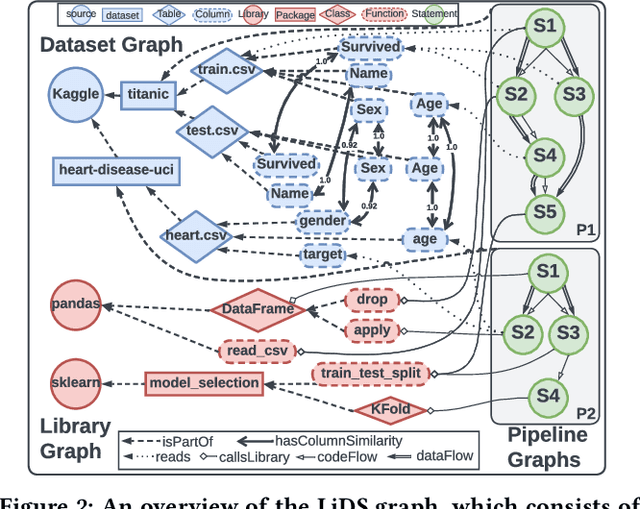
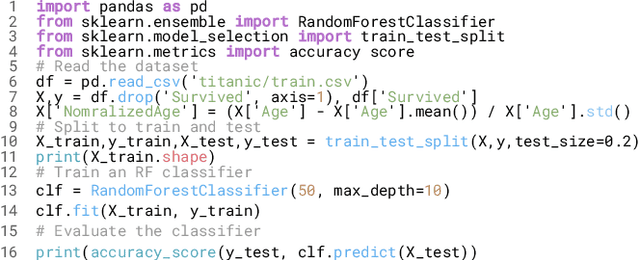
In recent years, we have witnessed a growing interest in data science not only from academia but particularly from companies investing in data science platforms to analyze large amounts of data. In this process, a myriad of data science artifacts, such as datasets and pipeline scripts, are created. Yet, there has so far been no systematic attempt to holistically exploit the collected knowledge and experiences that are implicitly contained in the specification of these pipelines, e.g., compatible datasets, cleansing steps, ML algorithms, parameters, etc. Instead, data scientists still spend a considerable amount of their time trying to recover relevant information and experiences from colleagues, trial and error, lengthy exploration, etc. In this paper, we, therefore, propose a scalable system (KGLiDS) that employs machine learning to extract the semantics of data science pipelines and captures them in a knowledge graph, which can then be exploited to assist data scientists in various ways. This abstraction is the key to enabling Linked Data Science since it allows us to share the essence of pipelines between platforms, companies, and institutions without revealing critical internal information and instead focusing on the semantics of what is being processed and how. Our comprehensive evaluation uses thousands of datasets and more than thirteen thousand pipeline scripts extracted from data discovery benchmarks and the Kaggle portal and shows that KGLiDS significantly outperforms state-of-the-art systems on related tasks, such as dataset recommendation and pipeline classification.
Contrastive Representation Learning for Acoustic Parameter Estimation
Feb 22, 2023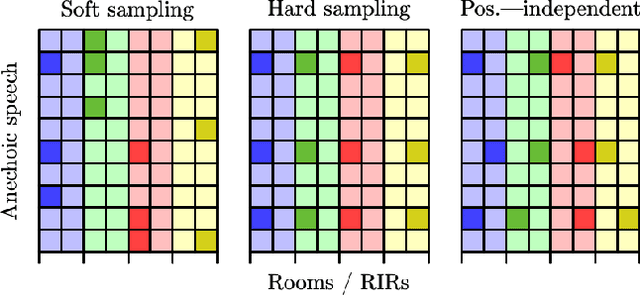


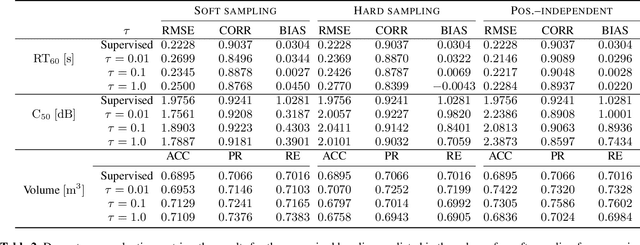
A study is presented in which a contrastive learning approach is used to extract low-dimensional representations of the acoustic environment from single-channel, reverberant speech signals. Convolution of room impulse responses (RIRs) with anechoic source signals is leveraged as a data augmentation technique that offers considerable flexibility in the design of the upstream task. We evaluate the embeddings across three different downstream tasks, which include the regression of acoustic parameters reverberation time RT60 and clarity index C50, and the classification into small and large rooms. We demonstrate that the learned representations generalize well to unseen data and achieve similar performance compared to a fully supervised baseline.
Learning-Based Adaptive User Selection in Millimeter Wave Hybrid Beamforming Systems
Feb 16, 2023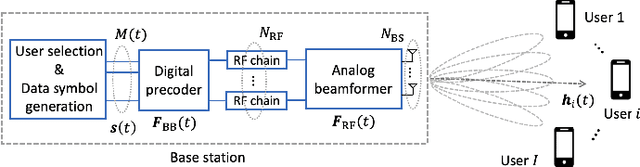
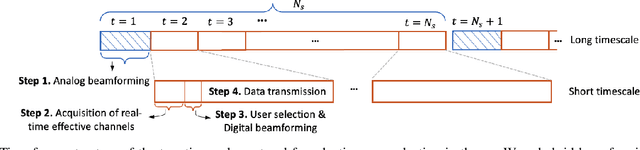
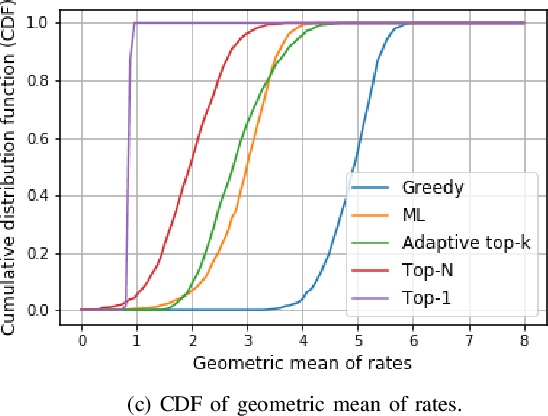
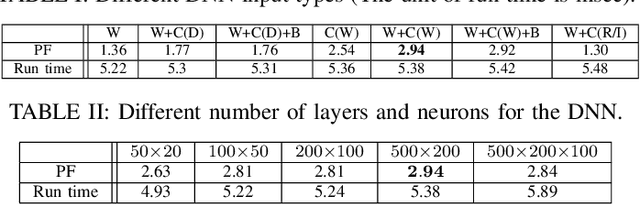
We consider a multi-user hybrid beamforming system, where the multiplexing gain is limited by the small number of RF chains employed at the base station (BS). To allow greater freedom for maximizing the multiplexing gain, it is better if the BS selects and serves some of the users at each scheduling instant, rather than serving all the users all the time. We adopt a two-timescale protocol that takes into account the mmWave characteristics, where at the long timescale an analog beam is chosen for each user, and at the short timescale users are selected for transmission based on the chosen analog beams. The goal of the user selection is to maximize the traditional Proportional Fair (PF) metric. However, this maximization is non-trivial due to interference between the analog beams for selected users. We first define a greedy algorithm and a "top-k" algorithm, and then propose a machine learning (ML)-based user selection algorithm to provide an efficient trade-off between the PF performance and the computation time. Throughout simulations, we analyze the performance of the ML-based algorithms under various metrics, and show that it gives an efficient trade-off in performance as compared to counterparts.
From Time Series to Networks in R with the ts2net Package
Aug 20, 2022
Network science established itself as a prominent tool for modeling time series and complex systems. This modeling process consists of transforming a set or a single time series into a network. Nodes may represent complete time series, segments, or single values, while links define associations or similarities between the represented parts. R is one of the main programming languages used in data science, statistics, and machine learning, with many packages available. However, no single package provides the necessary methods to transform time series into networks. This paper presents ts2net, an R package for modeling one or multiple time series into networks. The package provides the time series distance functions that can be easily computed in parallel and in supercomputers to process larger data sets and methods to transform distance matrices into networks. Ts2net also provides methods to transform a single time series into a network, such as recurrence networks, visibility graphs, and transition networks. Together with other packages, ts2net permits using network science and graph mining tools to extract information from time series.
Improving the Timing Resolution of Positron Emission Tomography Detectors using Boosted Learning -- A Residual Physics Approach
Feb 03, 2023
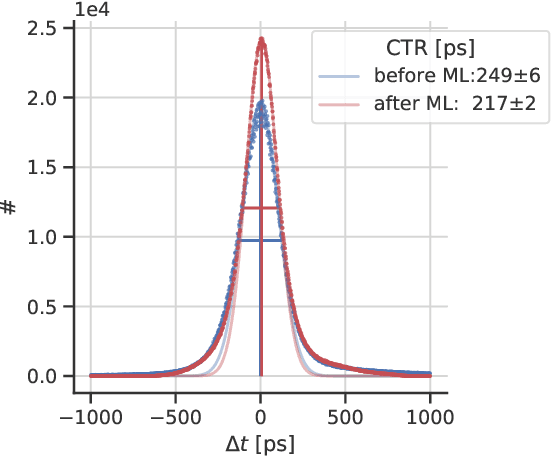
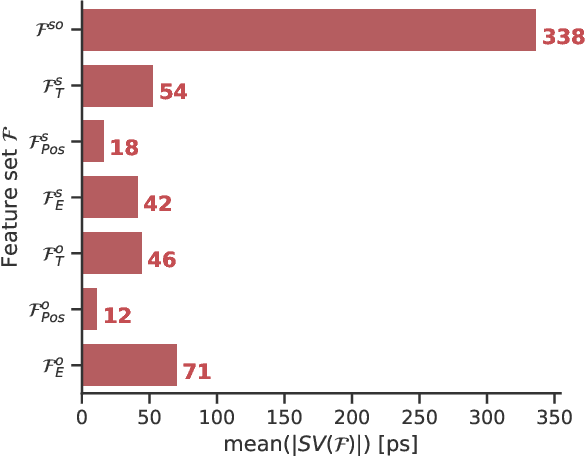
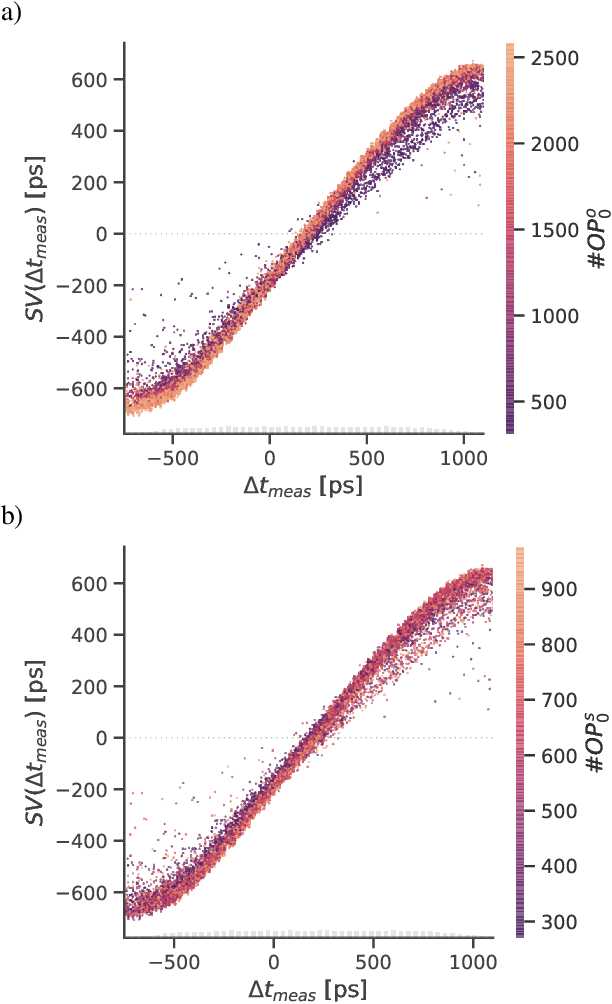
Artificial intelligence is finding its way into medical imaging, usually focusing on image reconstruction or enhancing analytical reconstructed images. However, optimizations along the complete processing chain, from detecting signals to computing data, enable significant improvements. Thus, we present an approach toward detector optimization using boosted learning by exploiting the concept of residual physics. In our work, we improve the coincidence time resolution (CTR) of positron emission tomography (PET) detectors. PET enables imaging of metabolic processes by detecting {\gamma}-photons with scintillation detectors. Current research exploits light-sharing detectors, where the scintillation light is distributed over and digitized by an array of readout channels. While these detectors demonstrate excellent performance parameters, e.g., regarding spatial resolution, extracting precise timing information for time-of-flight (TOF) becomes more challenging due to deteriorating effects called time skews. Conventional correction methods mainly rely on analytical formulations, theoretically capable of covering all time skew effects, e.g., caused by signal runtimes or physical effects. However, additional effects are involved for light-sharing detectors, so finding suitable analytical formulations can become arbitrarily complicated. The residual physics-based strategy uses gradient tree boosting (GTB) and a physics-informed data generation mimicking an actual imaging process by shifting a radiation source. We used clinically relevant detectors with a height of 19 mm, coupled to digital photosensor arrays. All trained models improved the CTR significantly. Using the best model, we achieved CTRs down to 198 ps (185 ps) for energies ranging from 300 keV to 700 keV (450 keV to 550 keV).
Prediction of a T-cell/MHC-I-based immune profile for colorectal liver metastases from CT images using ensemble learning
Mar 06, 2023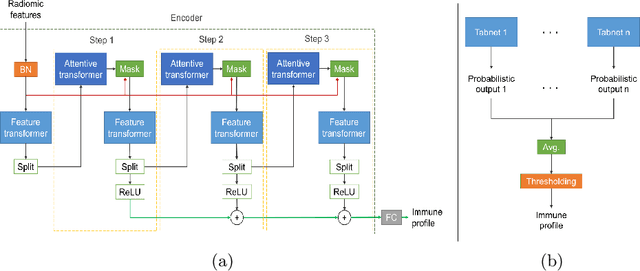
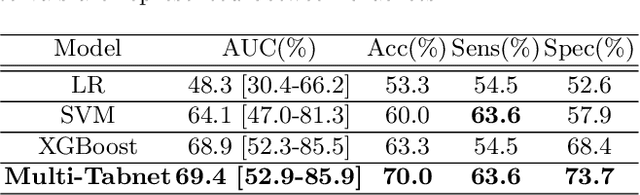
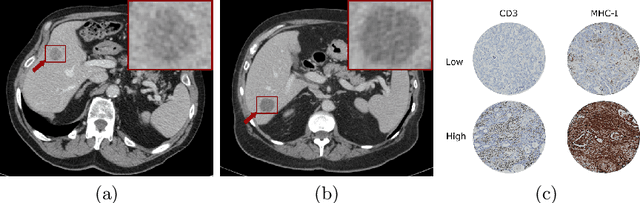
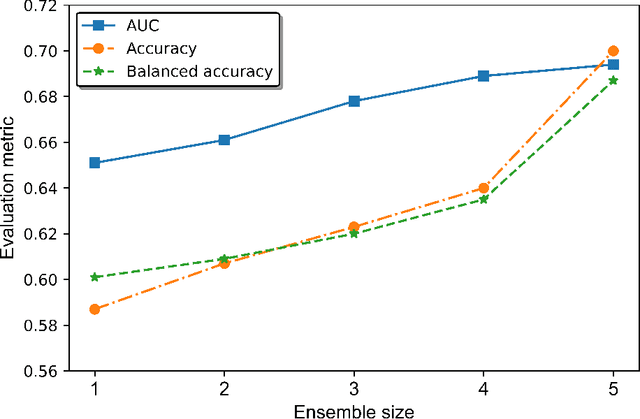
Colorectal cancer liver metastases (CLM) are the most common type of distant metastases originating from the abdomen and are characterized by a high recurrence rate after curative resection. It has been previously reported that CLM presenting a low cluster of differentiation 3 (CD3) positive T-cell infiltration density concurrent with a high major histocompatibility complex class I (MHC-I) expression were associated with poor clinical outcomes. In this study, we attempt to noninvasively predict whether a CLM exhibit the CD3LowMHCHigh immunological profile using preoperative CT images. To this end, we propose an ensemble network combining multiple Attentive Interpretable Tabular learning (TabNet) models, trained using CT-derived radiomic features. A total of 160 CLM were included in this study and randomly divided between a training set (n=130) and a hold-out test set (n=30). The proposed model yielded good prediction performance on the test set with an accuracy of 70.0% [95% confidence interval 53.6%-86.4%] and an area under the curve of 69.4% [52.9%-85.9%]. It also outperformed other off-the-shelf machine learning models. We finally demonstrated that the predicted immune profile was associated with a shorter disease-specific survival (p = .023) and time-to-recurrence (p = .020), showing the value of assessing the immune response.
A Survey on Incremental Update for Neural Recommender Systems
Mar 06, 2023Recommender Systems (RS) aim to provide personalized suggestions of items for users against consumer over-choice. Although extensive research has been conducted to address different aspects and challenges of RS, there still exists a gap between academic research and industrial applications. Specifically, most of the existing models still work in an offline manner, in which the recommender is trained on a large static training set and evaluated on a very restrictive testing set in a one-time process. RS will stay unchanged until the next batch retrain is performed. We frame such RS as Batch Update Recommender Systems (BURS). In reality, they have to face the challenges where RS are expected to be instantly updated with new data streaming in, and generate updated recommendations for current user activities based on the newly arrived data. We frame such RS as Incremental Update Recommender Systems (IURS). In this article, we offer a systematic survey of incremental update for neural recommender systems. We begin the survey by introducing key concepts and formulating the task of IURS. We then illustrate the challenges in IURS compared with traditional BURS. Afterwards, we detail the introduction of existing literature and evaluation issues. We conclude the survey by outlining some prominent open research issues in this area.