 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
3D Harmonic Loss: Towards Task-consistent and Time-friendly 3D Object Detection on Edge for Intelligent Transportation System
Nov 07, 2022
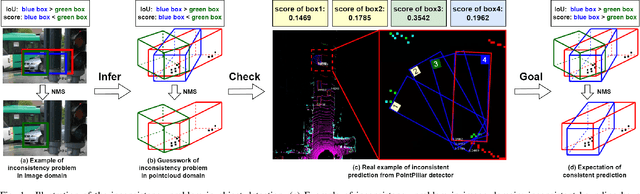

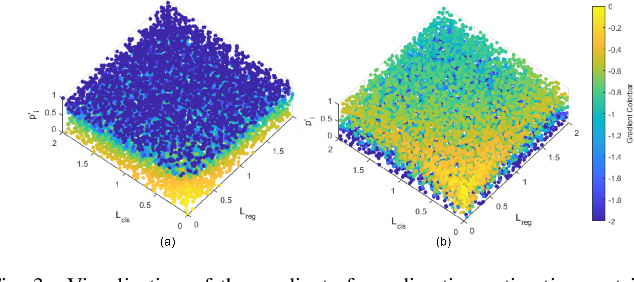
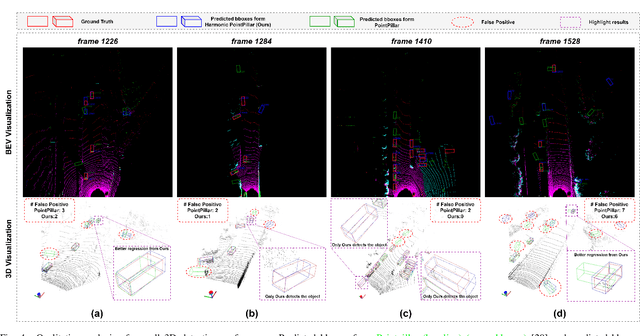
Edge computing-based 3D perception has received attention in intelligent transportation systems (ITS) because real-time monitoring of traffic candidates potentially strengthens Vehicle-to-Everything (V2X) orchestration. Thanks to the capability of precisely measuring the depth information on surroundings from LiDAR, the increasing studies focus on lidar-based 3D detection, which significantly promotes the development of 3D perception. Few methods met the real-time requirement of edge deployment because of high computation-intensive operations. Moreover, an inconsistency problem of object detection remains uncovered in the pointcloud domain due to large sparsity. This paper thoroughly analyses this problem, comprehensively roused by recent works on determining inconsistency problems in the image specialisation. Therefore, we proposed a 3D harmonic loss function to relieve the pointcloud based inconsistent predictions. Moreover, the feasibility of 3D harmonic loss is demonstrated from a mathematical optimization perspective. The KITTI dataset and DAIR-V2X-I dataset are used for simulations, and our proposed method considerably improves the performance than benchmark models. Further, the simulative deployment on an edge device (Jetson Xavier TX) validates our proposed model's efficiency. Our code is open-source and publicly available.
Online Continuous Hyperparameter Optimization for Contextual Bandits
Feb 18, 2023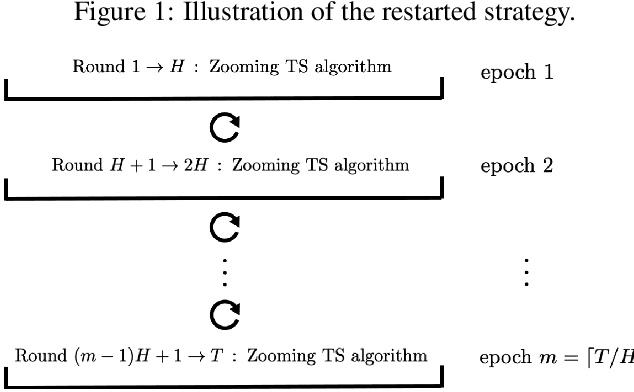
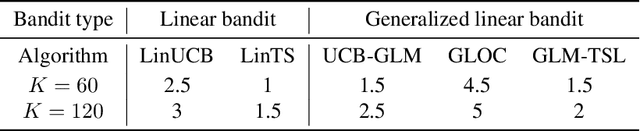
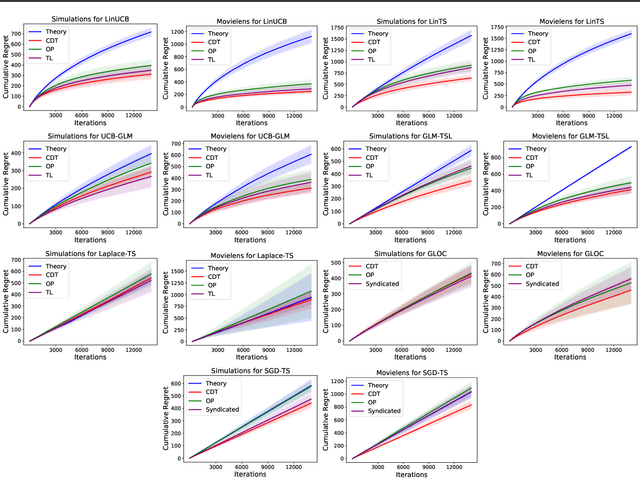
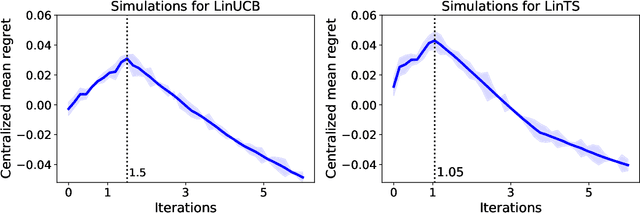
In stochastic contextual bandit problems, an agent sequentially makes actions from a time-dependent action set based on past experience to minimize the cumulative regret. Like many other machine learning algorithms, the performance of bandits heavily depends on their multiple hyperparameters, and theoretically derived parameter values may lead to unsatisfactory results in practice. Moreover, it is infeasible to use offline tuning methods like cross validation to choose hyperparameters under the bandit environment, as the decisions should be made in real time. To address this challenge, we propose the first online continuous hyperparameter tuning framework for contextual bandits to learn the optimal parameter configuration within a search space on the fly. Specifically, we use a double-layer bandit framework named CDT (Continuous Dynamic Tuning) and formulate the hyperparameter optimization as a non-stationary continuum-armed bandit, where each arm represents a combination of hyperparameters, and the corresponding reward is the algorithmic result. For the top layer, we propose the Zooming TS algorithm that utilizes Thompson Sampling (TS) for exploration and a restart technique to get around the switching environment. The proposed CDT framework can be easily used to tune contextual bandit algorithms without any pre-specified candidate set for hyperparameters. We further show that it could achieve sublinear regret in theory and performs consistently better on both synthetic and real datasets in practice.
Linearized Integrated Microwave Photonic Circuit for Filtering and Phase Shifting
Feb 26, 2023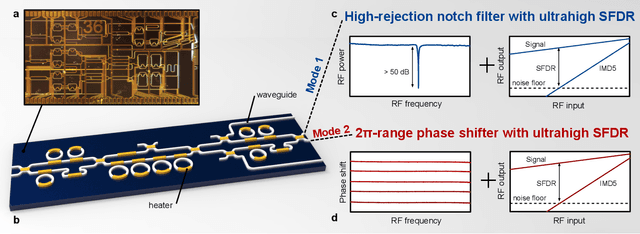
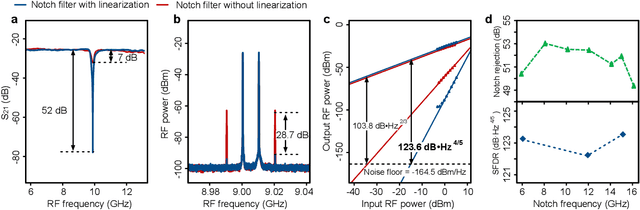
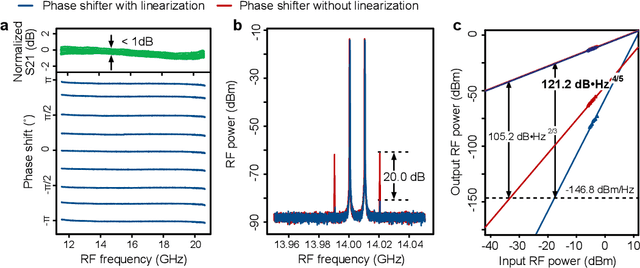
Photonic integration, advanced functionality, reconfigurability, and high RF performance are key features in integrated microwave photonic systems that are still difficult to achieve simultaneously. In this work, we demonstrate an integrated microwave photonic circuit that can be reconfigured for two distinct RF functions, namely, a tunable notch filter and a phase shifter. We achieved $>$50dB high-extinction notch filtering over 6-16 GHz and 2$\pi$ continuously tunable phase shifting over 12-20 GHz frequencies. At the same time, we implemented an on-chip linearization technique to achieve a spurious-free dynamic range of more than 120$\rm{dB}\cdot \rm{Hz}^{4/5}$ for both functions. Our work combines multi-functionality and linearization in one photonic integrated circuit, and paves the way to reconfigurable RF photonic front-ends with very high performance.
A comparative study of human inverse kinematics techniques for lower limbs
Feb 21, 2023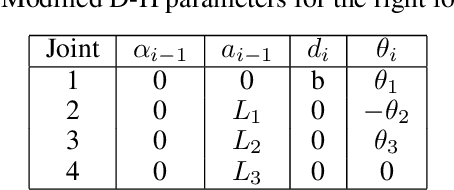
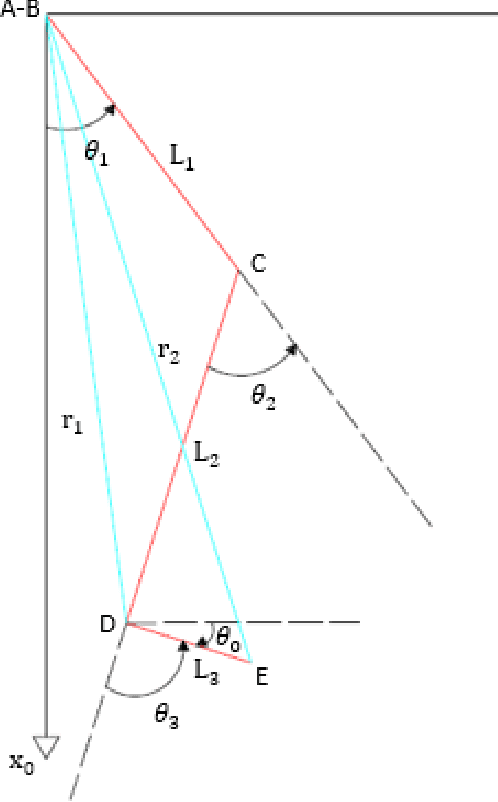

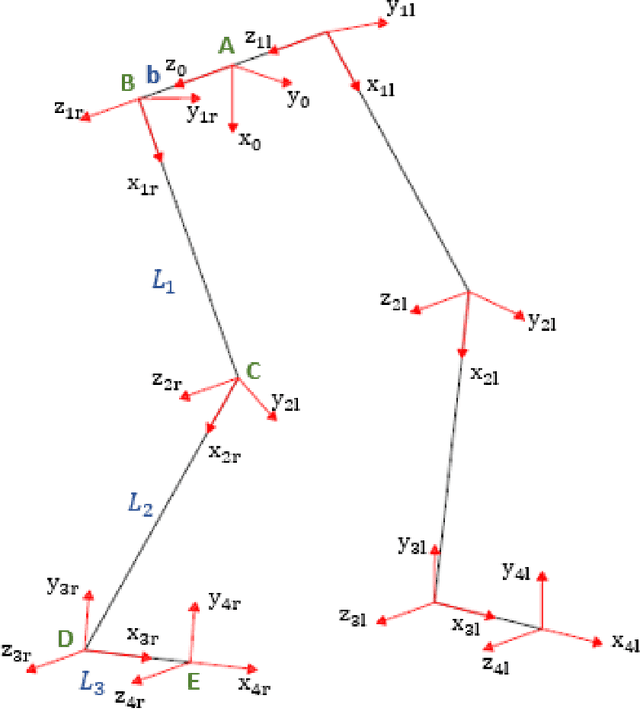
Inverse Kinematics (IK) has been an active research topic and many methods have been introduced to provide a fast and accurate solution. However, high computational cost and the generation of unrealistic positions constitute the weak points in most existing IK methods. In this paper, a comparative study was established to analyze the performance of popular IK techniques applied to the human leg. The objective is to determine the most efficient method in terms of computation time and to reach the desired position with a realistic human posture while respecting the range of motion and joint comfort zones of every joint.
Learning efficient backprojections across cortical hierarchies in real time
Dec 20, 2022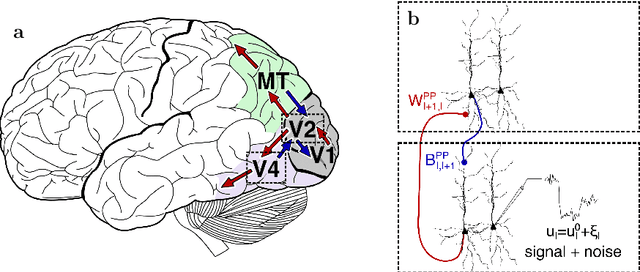
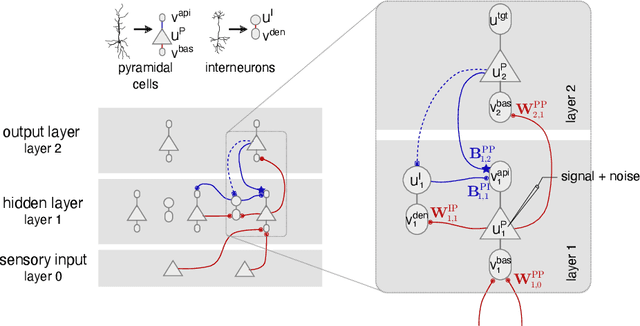
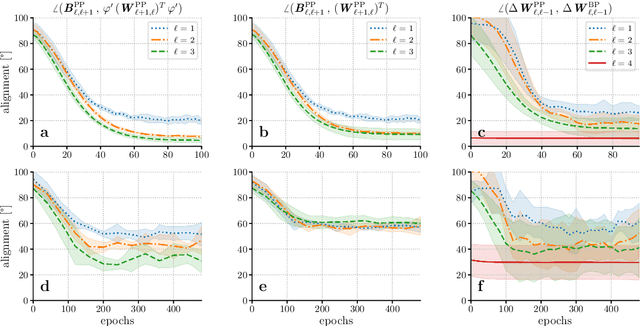
Models of sensory processing and learning in the cortex need to efficiently assign credit to synapses in all areas. In deep learning, a known solution is error backpropagation, which however requires biologically implausible weight transport from feed-forward to feedback paths. We introduce Phaseless Alignment Learning (PAL), a bio-plausible method to learn efficient feedback weights in layered cortical hierarchies. This is achieved by exploiting the noise naturally found in biophysical systems as an additional carrier of information. In our dynamical system, all weights are learned simultaneously with always-on plasticity and using only information locally available to the synapses. Our method is completely phase-free (no forward and backward passes or phased learning) and allows for efficient error propagation across multi-layer cortical hierarchies, while maintaining biologically plausible signal transport and learning. Our method is applicable to a wide class of models and improves on previously known biologically plausible ways of credit assignment: compared to random synaptic feedback, it can solve complex tasks with less neurons and learn more useful latent representations. We demonstrate this on various classification tasks using a cortical microcircuit model with prospective coding.
Rethinking the Effect of Data Augmentation in Adversarial Contrastive Learning
Mar 03, 2023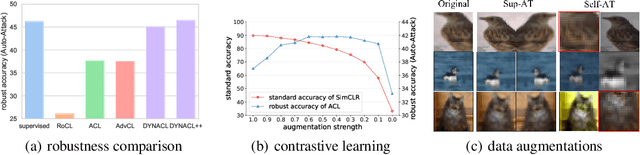
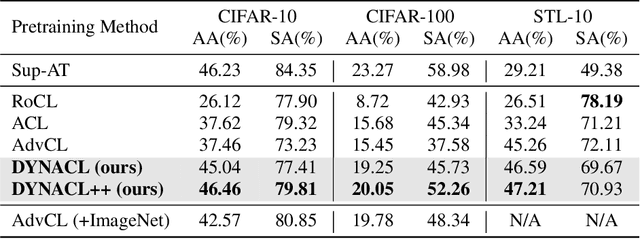
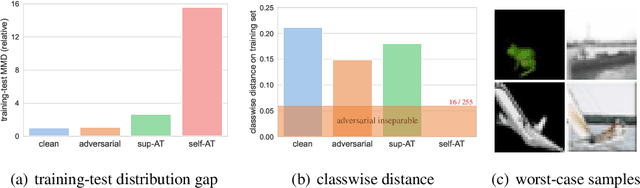
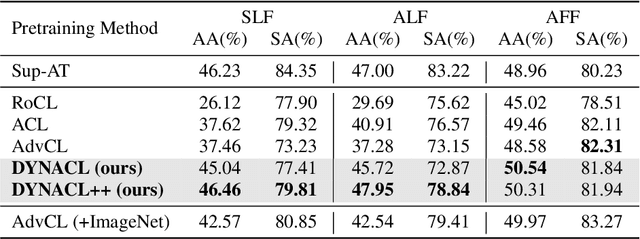
Recent works have shown that self-supervised learning can achieve remarkable robustness when integrated with adversarial training (AT). However, the robustness gap between supervised AT (sup-AT) and self-supervised AT (self-AT) remains significant. Motivated by this observation, we revisit existing self-AT methods and discover an inherent dilemma that affects self-AT robustness: either strong or weak data augmentations are harmful to self-AT, and a medium strength is insufficient to bridge the gap. To resolve this dilemma, we propose a simple remedy named DYNACL (Dynamic Adversarial Contrastive Learning). In particular, we propose an augmentation schedule that gradually anneals from a strong augmentation to a weak one to benefit from both extreme cases. Besides, we adopt a fast post-processing stage for adapting it to downstream tasks. Through extensive experiments, we show that DYNACL can improve state-of-the-art self-AT robustness by 8.84% under Auto-Attack on the CIFAR-10 dataset, and can even outperform vanilla supervised adversarial training for the first time. Our code is available at \url{https://github.com/PKU-ML/DYNACL}.
GETNext: Trajectory Flow Map Enhanced Transformer for Next POI Recommendation
Mar 03, 2023
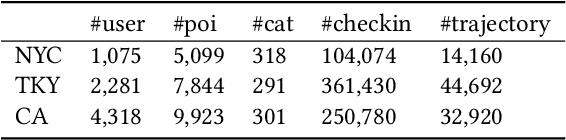
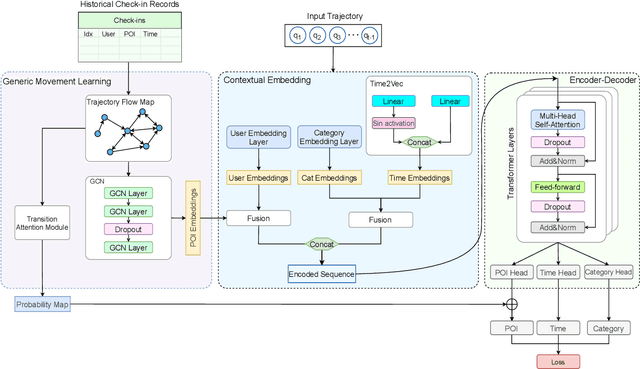
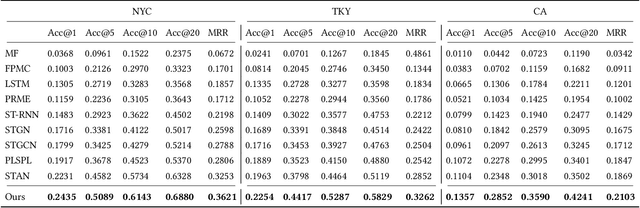
Next POI recommendation intends to forecast users' immediate future movements given their current status and historical information, yielding great values for both users and service providers. However, this problem is perceptibly complex because various data trends need to be considered together. This includes the spatial locations, temporal contexts, user's preferences, etc. Most existing studies view the next POI recommendation as a sequence prediction problem while omitting the collaborative signals from other users. Instead, we propose a user-agnostic global trajectory flow map and a novel Graph Enhanced Transformer model (GETNext) to better exploit the extensive collaborative signals for a more accurate next POI prediction, and alleviate the cold start problem in the meantime. GETNext incorporates the global transition patterns, user's general preference, spatio-temporal context, and time-aware category embeddings together into a transformer model to make the prediction of user's future moves. With this design, our model outperforms the state-of-the-art methods with a large margin and also sheds light on the cold start challenges within the spatio-temporal involved recommendation problems.
When does Privileged Information Explain Away Label Noise?
Mar 03, 2023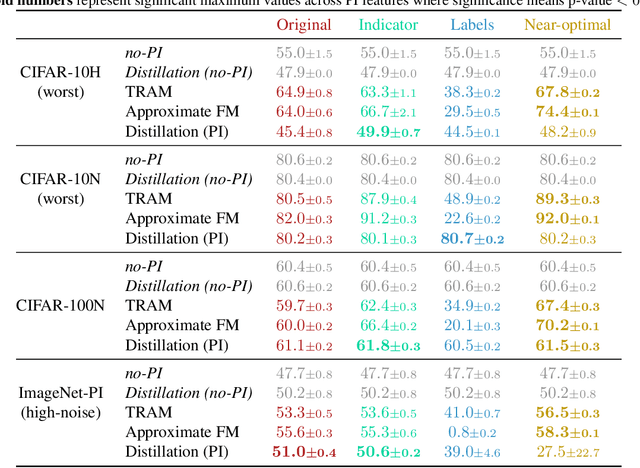
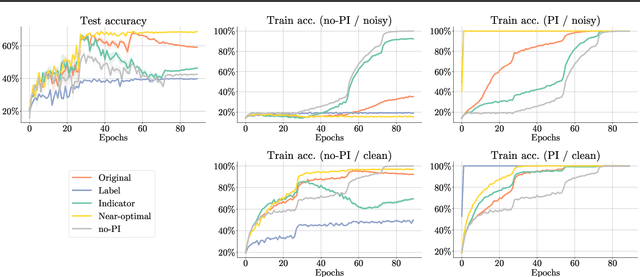
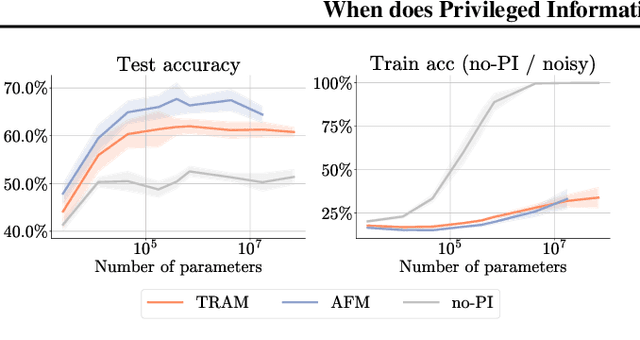

Leveraging privileged information (PI), or features available during training but not at test time, has recently been shown to be an effective method for addressing label noise. However, the reasons for its effectiveness are not well understood. In this study, we investigate the role played by different properties of the PI in explaining away label noise. Through experiments on multiple datasets with real PI (CIFAR-N/H) and a new large-scale benchmark ImageNet-PI, we find that PI is most helpful when it allows networks to easily distinguish clean from noisy data, while enabling a learning shortcut to memorize the noisy examples. Interestingly, when PI becomes too predictive of the target label, PI methods often perform worse than their no-PI baselines. Based on these findings, we propose several enhancements to the state-of-the-art PI methods and demonstrate the potential of PI as a means of tackling label noise. Finally, we show how we can easily combine the resulting PI approaches with existing no-PI techniques designed to deal with label noise.
Spectrogram Inversion for Audio Source Separation via Consistency, Mixing, and Magnitude Constraints
Mar 03, 2023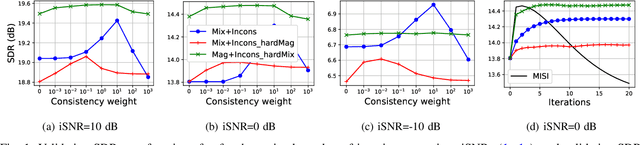
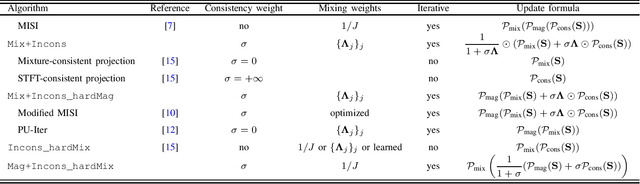
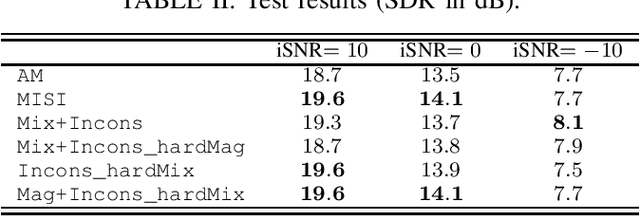
Audio source separation is often achieved by estimating the magnitude spectrogram of each source, and then applying a phase recovery (or spectrogram inversion) algorithm to retrieve time-domain signals. Typically, spectrogram inversion is treated as an optimization problem involving one or several terms in order to promote estimates that comply with a consistency property, a mixing constraint, and/or a target magnitude objective. Nonetheless, it is still unclear which set of constraints and problem formulation is the most appropriate in practice. In this paper, we design a general framework for deriving spectrogram inversion algorithm, which is based on formulating optimization problems by combining these objectives either as soft penalties or hard constraints. We solve these by means of algorithms that perform alternating projections on the subsets corresponding to each objective/constraint. Our framework encompasses existing techniques from the literature as well as novel algorithms. We investigate the potential of these approaches for a speech enhancement task. In particular, one of our novel algorithms outperforms other approaches in a realistic setting where the magnitudes are estimated beforehand using a neural network.
Deep Neural Network Architecture Search for Accurate Visual Pose Estimation aboard Nano-UAVs
Mar 03, 2023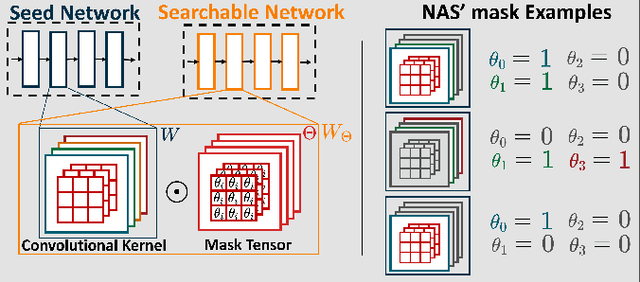
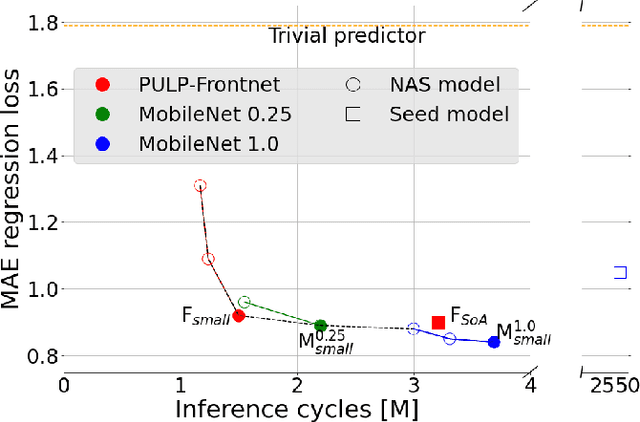
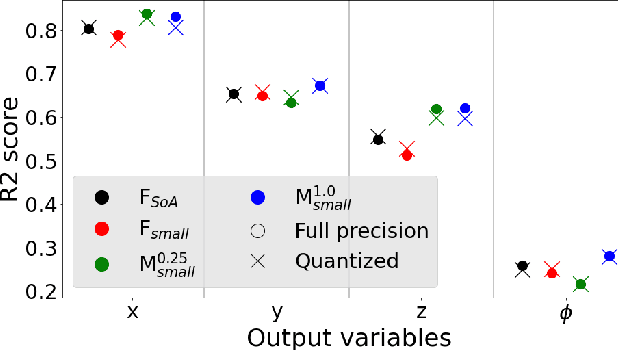
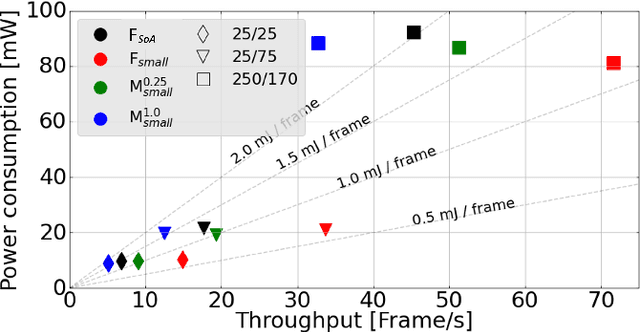
Miniaturized autonomous unmanned aerial vehicles (UAVs) are an emerging and trending topic. With their form factor as big as the palm of one hand, they can reach spots otherwise inaccessible to bigger robots and safely operate in human surroundings. The simple electronics aboard such robots (sub-100mW) make them particularly cheap and attractive but pose significant challenges in enabling onboard sophisticated intelligence. In this work, we leverage a novel neural architecture search (NAS) technique to automatically identify several Pareto-optimal convolutional neural networks (CNNs) for a visual pose estimation task. Our work demonstrates how real-life and field-tested robotics applications can concretely leverage NAS technologies to automatically and efficiently optimize CNNs for the specific hardware constraints of small UAVs. We deploy several NAS-optimized CNNs and run them in closed-loop aboard a 27-g Crazyflie nano-UAV equipped with a parallel ultra-low power System-on-Chip. Our results improve the State-of-the-Art by reducing the in-field control error of 32% while achieving a real-time onboard inference-rate of ~10Hz@10mW and ~50Hz@90mW.