 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Time-domain Classification of the Brain Reward System: Analysis of Natural- and Drug-Reward Driven Local Field Potential Signals in Hippocampus and Nucleus Accumbens
Nov 15, 2022

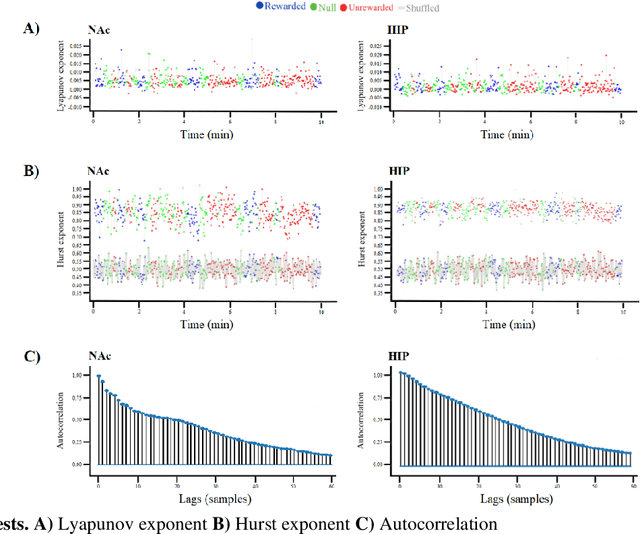
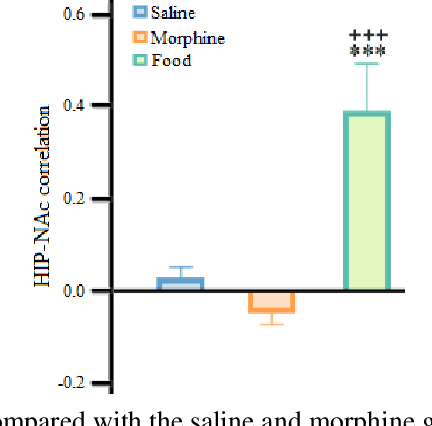
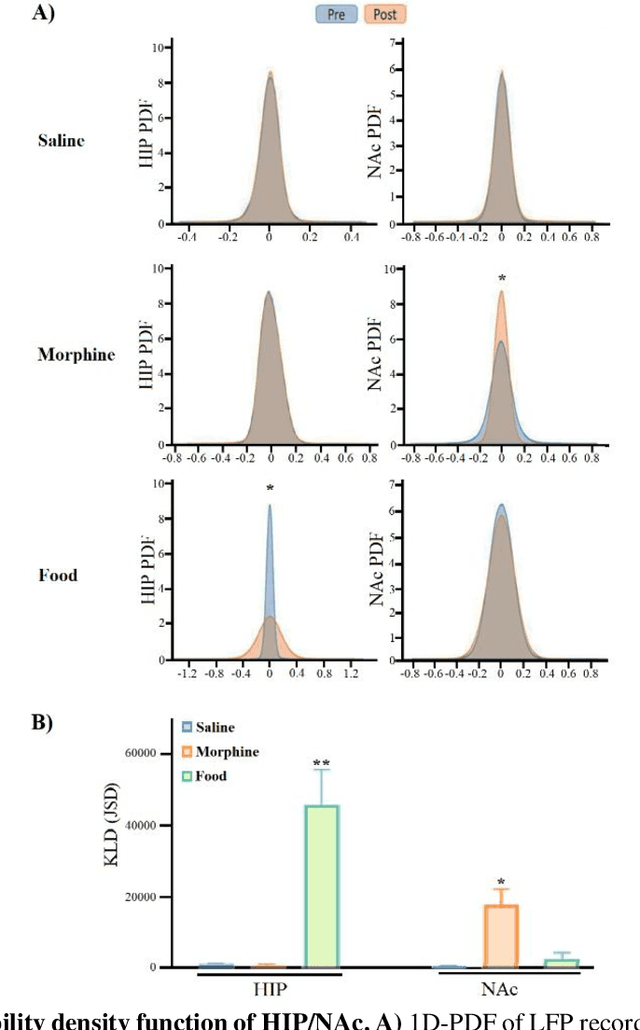
Addiction is a major public health concern characterized by compulsive reward-seeking behavior. The excitatory glutamatergic signals from the hippocampus (HIP) to the Nucleus accumbens (NAc) mediate learned behavior in addiction. Limited comparative studies have investigated the neural pathways activated by natural and unnatural reward sources. This study has evaluated neural activities in HIP and NAc associated with food (natural) and morphine (drug) reward sources using local field potential (LFP). We developed novel approaches to classify LFP signals into the source of reward and recorded regions by considering the time-domain feature of these signals. Proposed methods included a validation step of the LFP signals using autocorrelation, Lyapunov exponent and Hurst exponent to assess the meaningful stability of these signals (lack of chaos). By utilizing the probability density function (PDF) of LFP signals and applying Kullback-Leibler divergence (KLD), data were classified to the source of the reward. Also, HIP and NAc regions were visually separated and classified using the symmetrized dot pattern technique, which can be applied in real-time to ensure the deep brain region of interest is being targeted accurately during LFP recording. We believe our method provides a computationally light and fast, real-time signal analysis approach with real-world implementation.
Learning Differential Operators for Interpretable Time Series Modeling
Sep 03, 2022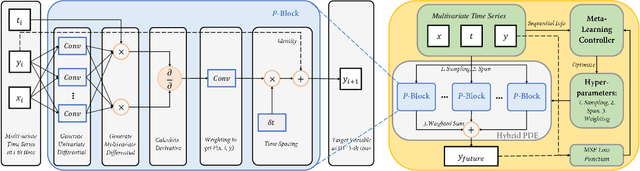


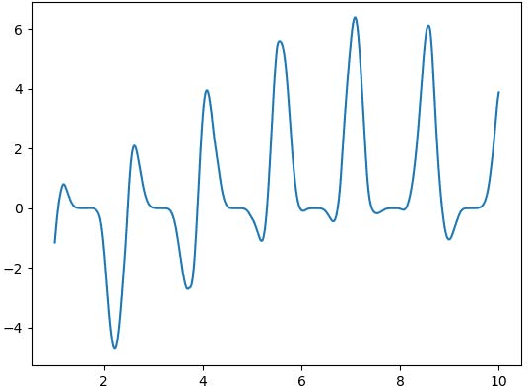
Modeling sequential patterns from data is at the core of various time series forecasting tasks. Deep learning models have greatly outperformed many traditional models, but these black-box models generally lack explainability in prediction and decision making. To reveal the underlying trend with understandable mathematical expressions, scientists and economists tend to use partial differential equations (PDEs) to explain the highly nonlinear dynamics of sequential patterns. However, it usually requires domain expert knowledge and a series of simplified assumptions, which is not always practical and can deviate from the ever-changing world. Is it possible to learn the differential relations from data dynamically to explain the time-evolving dynamics? In this work, we propose an learning framework that can automatically obtain interpretable PDE models from sequential data. Particularly, this framework is comprised of learnable differential blocks, named $P$-blocks, which is proved to be able to approximate any time-evolving complex continuous functions in theory. Moreover, to capture the dynamics shift, this framework introduces a meta-learning controller to dynamically optimize the hyper-parameters of a hybrid PDE model. Extensive experiments on times series forecasting of financial, engineering, and health data show that our model can provide valuable interpretability and achieve comparable performance to state-of-the-art models. From empirical studies, we find that learning a few differential operators may capture the major trend of sequential dynamics without massive computational complexity.
Rethinking the Effect of Data Augmentation in Adversarial Contrastive Learning
Mar 03, 2023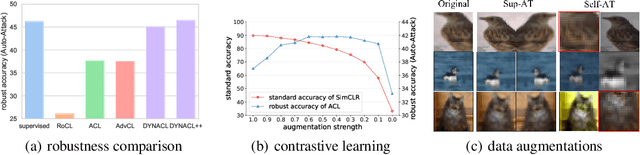
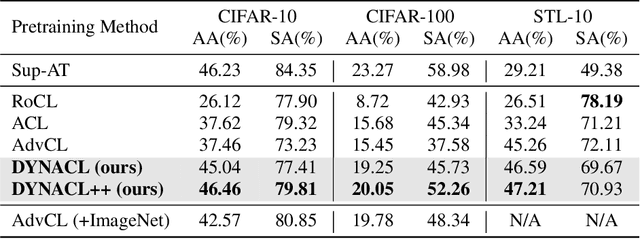
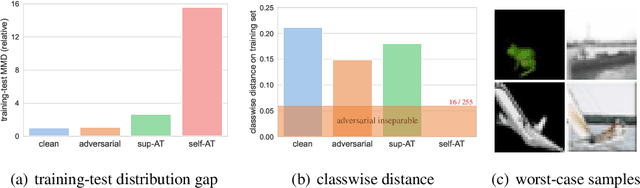
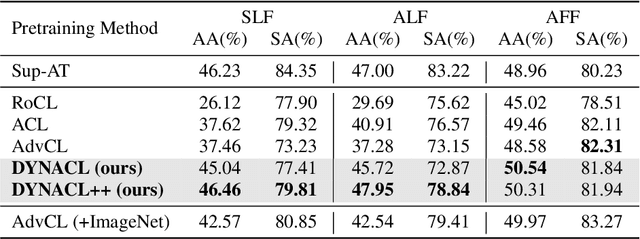
Recent works have shown that self-supervised learning can achieve remarkable robustness when integrated with adversarial training (AT). However, the robustness gap between supervised AT (sup-AT) and self-supervised AT (self-AT) remains significant. Motivated by this observation, we revisit existing self-AT methods and discover an inherent dilemma that affects self-AT robustness: either strong or weak data augmentations are harmful to self-AT, and a medium strength is insufficient to bridge the gap. To resolve this dilemma, we propose a simple remedy named DYNACL (Dynamic Adversarial Contrastive Learning). In particular, we propose an augmentation schedule that gradually anneals from a strong augmentation to a weak one to benefit from both extreme cases. Besides, we adopt a fast post-processing stage for adapting it to downstream tasks. Through extensive experiments, we show that DYNACL can improve state-of-the-art self-AT robustness by 8.84% under Auto-Attack on the CIFAR-10 dataset, and can even outperform vanilla supervised adversarial training for the first time. Our code is available at \url{https://github.com/PKU-ML/DYNACL}.
Spectrogram Inversion for Audio Source Separation via Consistency, Mixing, and Magnitude Constraints
Mar 03, 2023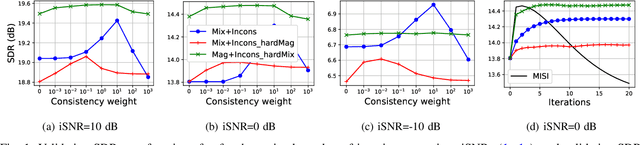
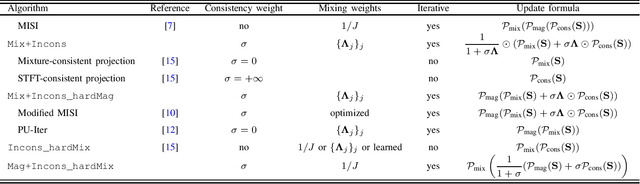
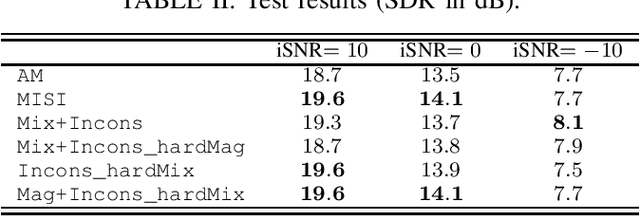
Audio source separation is often achieved by estimating the magnitude spectrogram of each source, and then applying a phase recovery (or spectrogram inversion) algorithm to retrieve time-domain signals. Typically, spectrogram inversion is treated as an optimization problem involving one or several terms in order to promote estimates that comply with a consistency property, a mixing constraint, and/or a target magnitude objective. Nonetheless, it is still unclear which set of constraints and problem formulation is the most appropriate in practice. In this paper, we design a general framework for deriving spectrogram inversion algorithm, which is based on formulating optimization problems by combining these objectives either as soft penalties or hard constraints. We solve these by means of algorithms that perform alternating projections on the subsets corresponding to each objective/constraint. Our framework encompasses existing techniques from the literature as well as novel algorithms. We investigate the potential of these approaches for a speech enhancement task. In particular, one of our novel algorithms outperforms other approaches in a realistic setting where the magnitudes are estimated beforehand using a neural network.
Deep Neural Network Architecture Search for Accurate Visual Pose Estimation aboard Nano-UAVs
Mar 03, 2023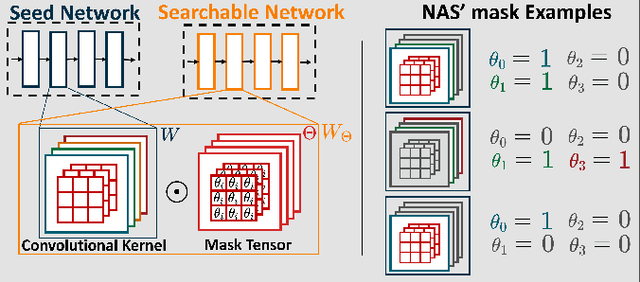
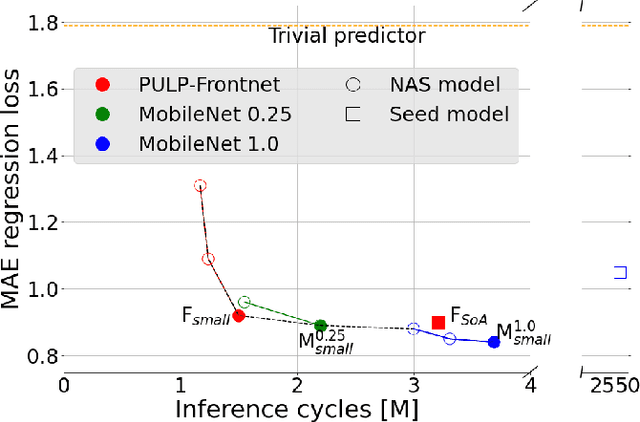
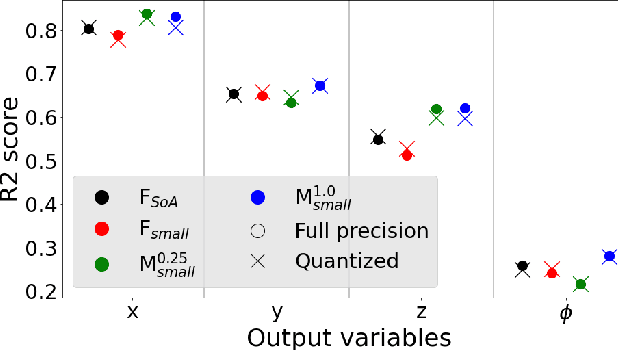
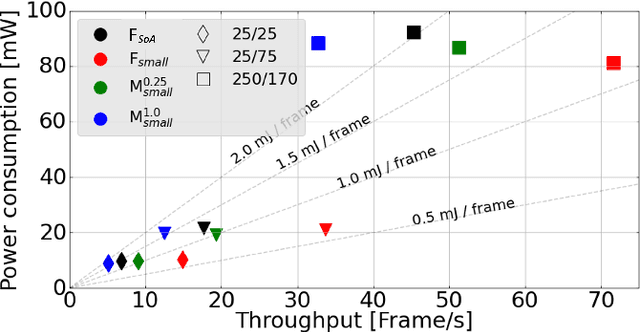
Miniaturized autonomous unmanned aerial vehicles (UAVs) are an emerging and trending topic. With their form factor as big as the palm of one hand, they can reach spots otherwise inaccessible to bigger robots and safely operate in human surroundings. The simple electronics aboard such robots (sub-100mW) make them particularly cheap and attractive but pose significant challenges in enabling onboard sophisticated intelligence. In this work, we leverage a novel neural architecture search (NAS) technique to automatically identify several Pareto-optimal convolutional neural networks (CNNs) for a visual pose estimation task. Our work demonstrates how real-life and field-tested robotics applications can concretely leverage NAS technologies to automatically and efficiently optimize CNNs for the specific hardware constraints of small UAVs. We deploy several NAS-optimized CNNs and run them in closed-loop aboard a 27-g Crazyflie nano-UAV equipped with a parallel ultra-low power System-on-Chip. Our results improve the State-of-the-Art by reducing the in-field control error of 32% while achieving a real-time onboard inference-rate of ~10Hz@10mW and ~50Hz@90mW.
GETNext: Trajectory Flow Map Enhanced Transformer for Next POI Recommendation
Mar 03, 2023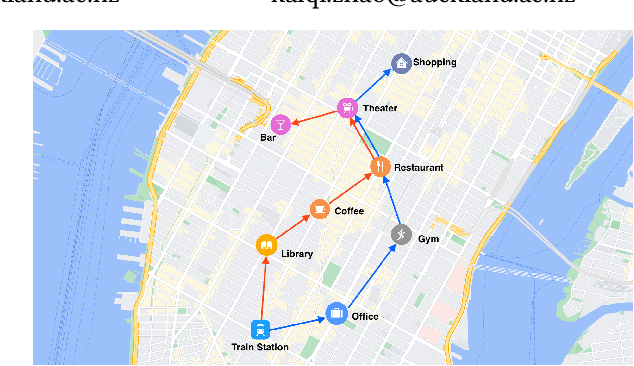
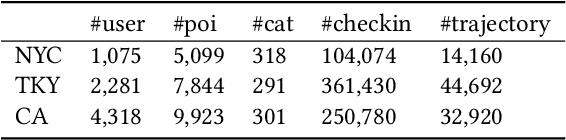
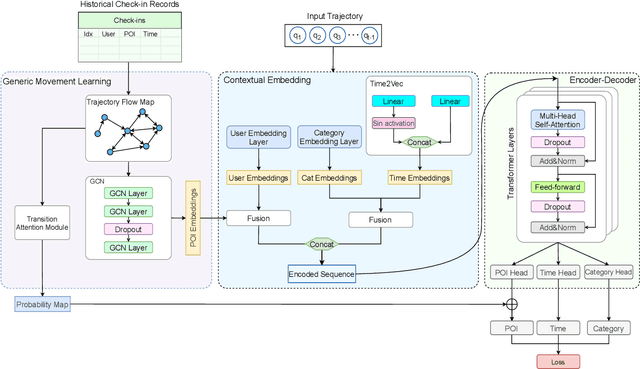
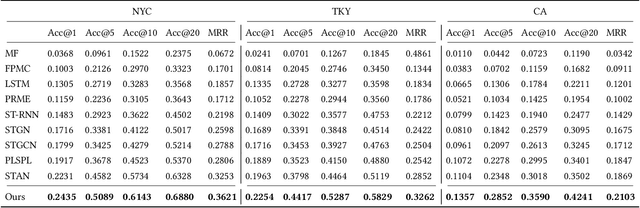
Next POI recommendation intends to forecast users' immediate future movements given their current status and historical information, yielding great values for both users and service providers. However, this problem is perceptibly complex because various data trends need to be considered together. This includes the spatial locations, temporal contexts, user's preferences, etc. Most existing studies view the next POI recommendation as a sequence prediction problem while omitting the collaborative signals from other users. Instead, we propose a user-agnostic global trajectory flow map and a novel Graph Enhanced Transformer model (GETNext) to better exploit the extensive collaborative signals for a more accurate next POI prediction, and alleviate the cold start problem in the meantime. GETNext incorporates the global transition patterns, user's general preference, spatio-temporal context, and time-aware category embeddings together into a transformer model to make the prediction of user's future moves. With this design, our model outperforms the state-of-the-art methods with a large margin and also sheds light on the cold start challenges within the spatio-temporal involved recommendation problems.
When does Privileged Information Explain Away Label Noise?
Mar 03, 2023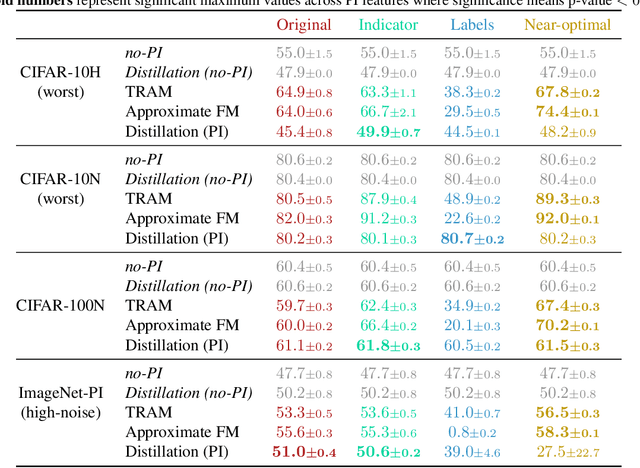
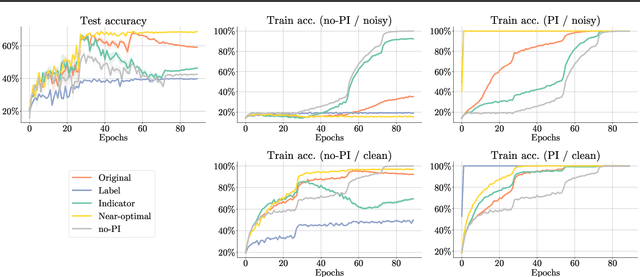
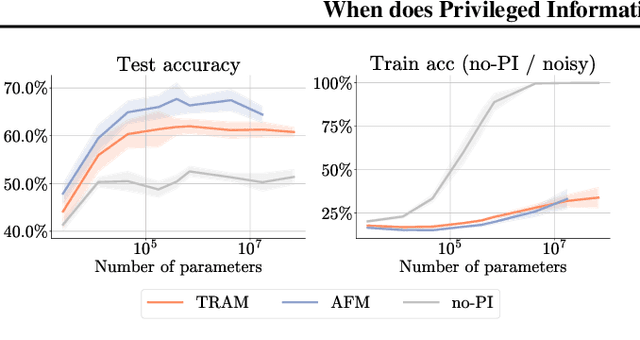

Leveraging privileged information (PI), or features available during training but not at test time, has recently been shown to be an effective method for addressing label noise. However, the reasons for its effectiveness are not well understood. In this study, we investigate the role played by different properties of the PI in explaining away label noise. Through experiments on multiple datasets with real PI (CIFAR-N/H) and a new large-scale benchmark ImageNet-PI, we find that PI is most helpful when it allows networks to easily distinguish clean from noisy data, while enabling a learning shortcut to memorize the noisy examples. Interestingly, when PI becomes too predictive of the target label, PI methods often perform worse than their no-PI baselines. Based on these findings, we propose several enhancements to the state-of-the-art PI methods and demonstrate the potential of PI as a means of tackling label noise. Finally, we show how we can easily combine the resulting PI approaches with existing no-PI techniques designed to deal with label noise.
Linearized Integrated Microwave Photonic Circuit for Filtering and Phase Shifting
Feb 26, 2023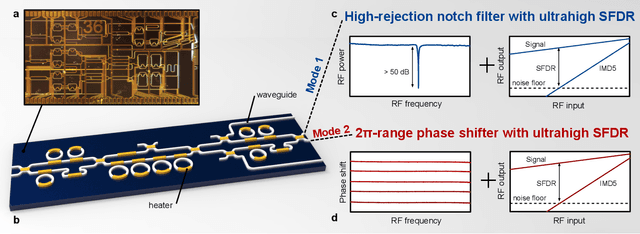
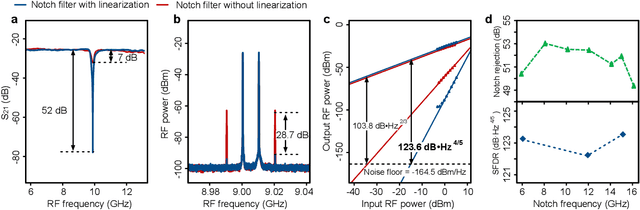
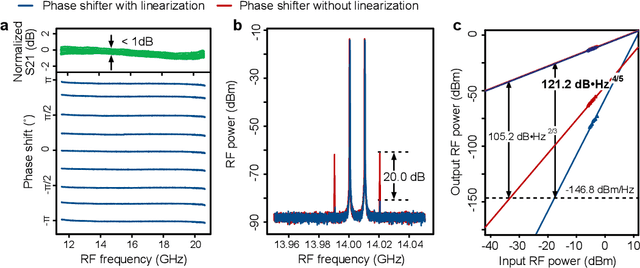
Photonic integration, advanced functionality, reconfigurability, and high RF performance are key features in integrated microwave photonic systems that are still difficult to achieve simultaneously. In this work, we demonstrate an integrated microwave photonic circuit that can be reconfigured for two distinct RF functions, namely, a tunable notch filter and a phase shifter. We achieved $>$50dB high-extinction notch filtering over 6-16 GHz and 2$\pi$ continuously tunable phase shifting over 12-20 GHz frequencies. At the same time, we implemented an on-chip linearization technique to achieve a spurious-free dynamic range of more than 120$\rm{dB}\cdot \rm{Hz}^{4/5}$ for both functions. Our work combines multi-functionality and linearization in one photonic integrated circuit, and paves the way to reconfigurable RF photonic front-ends with very high performance.
Multiscale Non-stationary Causal Structure Learning from Time Series Data
Aug 31, 2022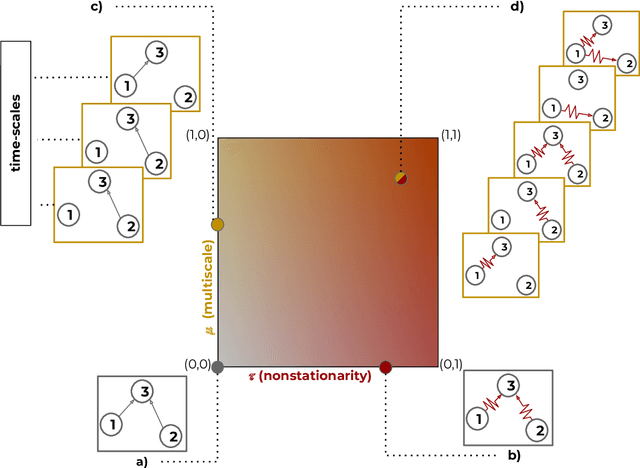
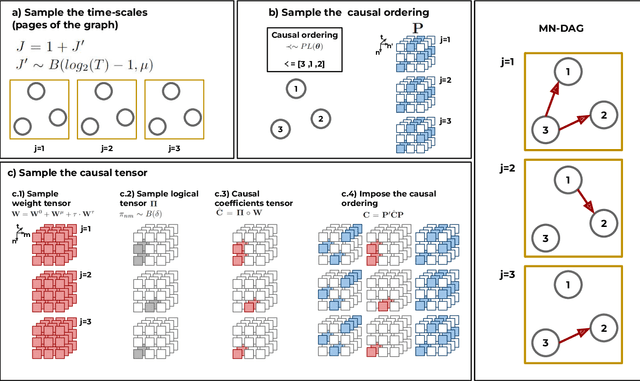
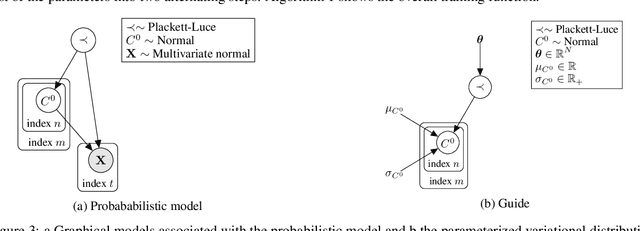
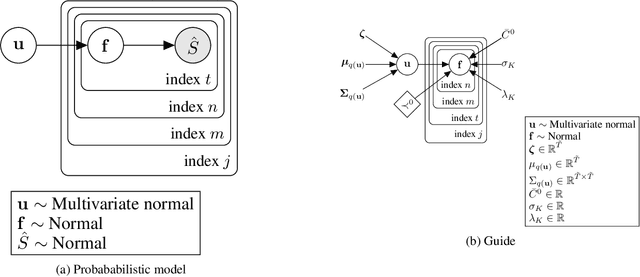
This paper introduces a new type of causal structure, namely multiscale non-stationary directed acyclic graph (MN-DAG), that generalizes DAGs to the time-frequency domain. Our contribution is twofold. First, by leveraging results from spectral and causality theories, we expose a novel probabilistic generative model, which allows to sample an MN-DAG according to user-specified priors concerning the time-dependence and multiscale properties of the causal graph. Second, we devise a Bayesian method for the estimation of MN-DAGs, by means of stochastic variational inference (SVI), called Multiscale Non-Stationary Causal Structure Learner (MN-CASTLE). In addition to direct observations, MN-CASTLE exploits information from the decomposition of the total power spectrum of time series over different time resolutions. In our experiments, we first use the proposed model to generate synthetic data according to a latent MN-DAG, showing that the data generated reproduces well-known features of time series in different domains. Then we compare our learning method MN-CASTLE against baseline models on synthetic data generated with different multiscale and non-stationary settings, confirming the good performance of MN-CASTLE. Finally, we show some insights derived from the application of MN-CASTLE to study the causal structure of 7 global equity markets during the Covid-19 pandemic.
Online Continuous Hyperparameter Optimization for Contextual Bandits
Feb 18, 2023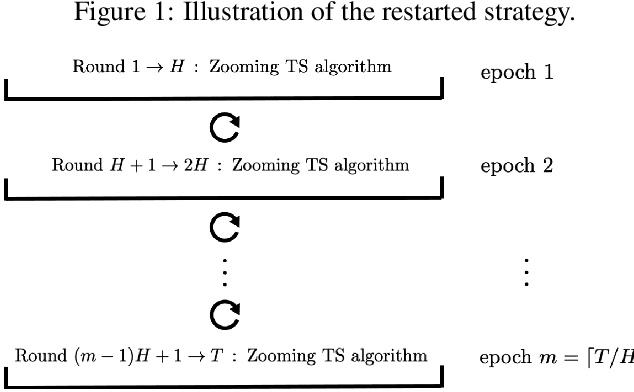
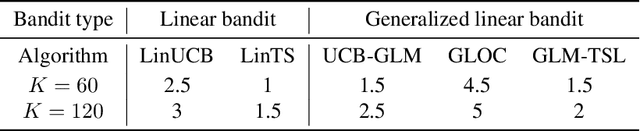
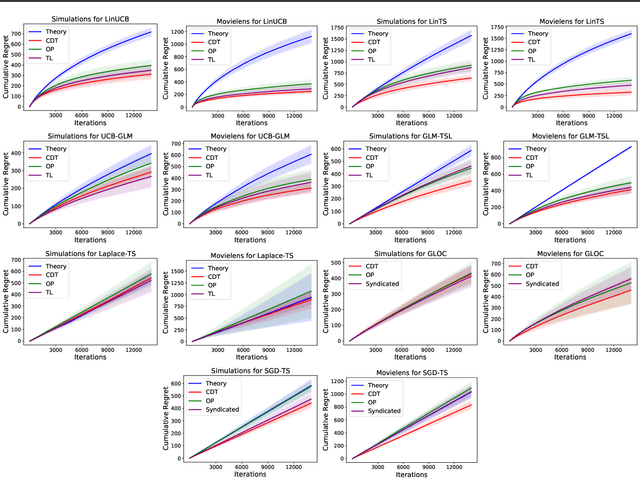
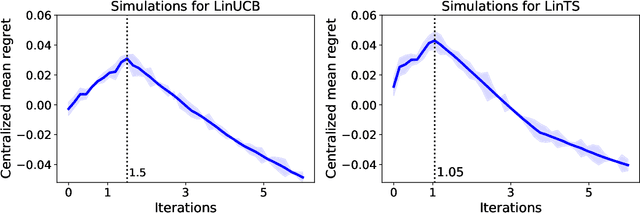
In stochastic contextual bandit problems, an agent sequentially makes actions from a time-dependent action set based on past experience to minimize the cumulative regret. Like many other machine learning algorithms, the performance of bandits heavily depends on their multiple hyperparameters, and theoretically derived parameter values may lead to unsatisfactory results in practice. Moreover, it is infeasible to use offline tuning methods like cross validation to choose hyperparameters under the bandit environment, as the decisions should be made in real time. To address this challenge, we propose the first online continuous hyperparameter tuning framework for contextual bandits to learn the optimal parameter configuration within a search space on the fly. Specifically, we use a double-layer bandit framework named CDT (Continuous Dynamic Tuning) and formulate the hyperparameter optimization as a non-stationary continuum-armed bandit, where each arm represents a combination of hyperparameters, and the corresponding reward is the algorithmic result. For the top layer, we propose the Zooming TS algorithm that utilizes Thompson Sampling (TS) for exploration and a restart technique to get around the switching environment. The proposed CDT framework can be easily used to tune contextual bandit algorithms without any pre-specified candidate set for hyperparameters. We further show that it could achieve sublinear regret in theory and performs consistently better on both synthetic and real datasets in practice.