 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Channel Estimation for Underwater Visible Light Communication: A Sparse Learning Perspective
Mar 13, 2023
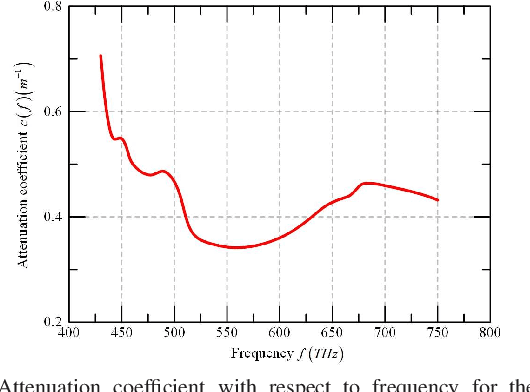
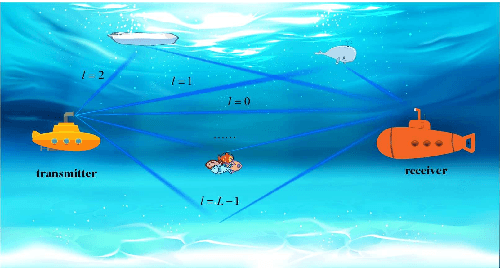
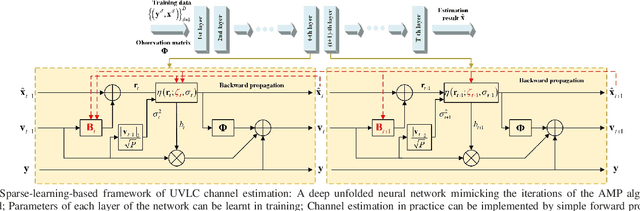
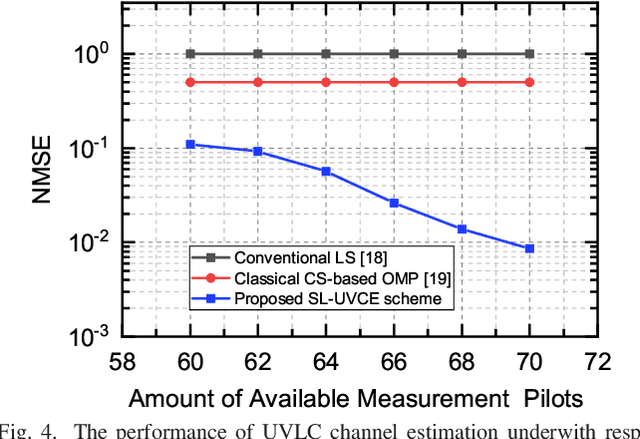
The underwater propagation environment for visible light signals is affected by complex factors such as absorption, shadowing, and reflection, making it very challengeable to achieve effective underwater visible light communication (UVLC) channel estimation. It is difficult for the UVLC channel to be sparse represented in the time and frequency domains, which limits the chance of using sparse signal processing techniques to achieve better performance of channel estimation. To this end, a compressed sensing (CS) based framework is established in this paper by fully exploiting the sparsity of the underwater visible light channel in the distance domain of the propagation links. In order to solve the sparse recovery problem and achieve more accurate UVLC channel estimation, a sparse learning based underwater visible light channel estimation (SL-UVCE) scheme is proposed. Specifically, a deep-unfolding neural network mimicking the classical iterative sparse recovery algorithm of approximate message passing (AMP) is employed, which decomposes the iterations of AMP into a series of layers with different learnable parameters. Compared with the existing non-CS-based and CS-based schemes, the proposed scheme shows better performance of accuracy in channel estimation, especially in severe conditions such as insufficient measurement pilots and large number of multipath components.
High-throughput Generative Inference of Large Language Models with a Single GPU
Mar 13, 2023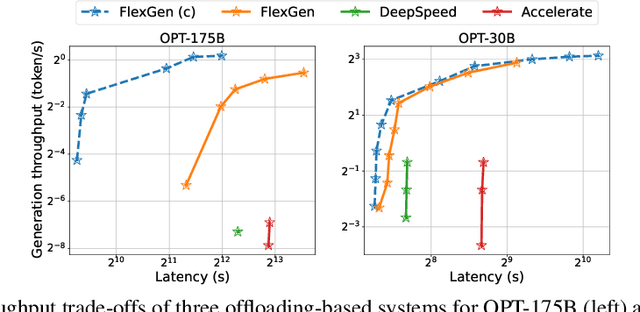

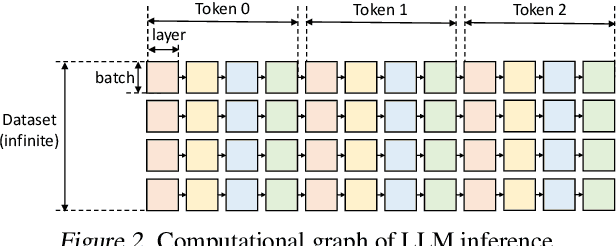
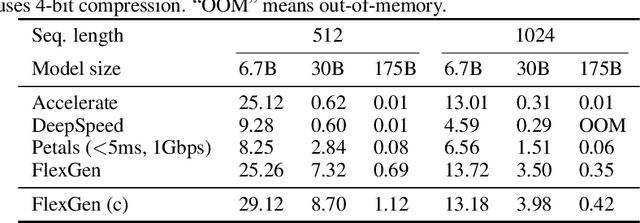
The high computational and memory requirements of large language model (LLM) inference traditionally make it feasible only with multiple high-end accelerators. Motivated by the emerging demand for latency-insensitive tasks with batched processing, this paper initiates the study of high-throughput LLM inference using limited resources, such as a single commodity GPU. We present FlexGen, a high-throughput generation engine for running LLMs with limited GPU memory. FlexGen can be flexibly configured under various hardware resource constraints by aggregating memory and computation from the GPU, CPU, and disk. Through a linear programming optimizer, it searches for efficient patterns to store and access tensors. FlexGen further compresses these weights and the attention cache to 4 bits with negligible accuracy loss. These techniques enable FlexGen to have a larger space of batch size choices and thus significantly increase maximum throughput. As a result, when running OPT-175B on a single 16GB GPU, FlexGen achieves significantly higher throughput compared to state-of-the-art offloading systems, reaching a generation throughput of 1 token/s for the first time with an effective batch size of 144. On the HELM benchmark, FlexGen can benchmark a 30B model with a 16GB GPU on 7 representative sub-scenarios in 21 hours. The code is available at https://github.com/FMInference/FlexGen
Guiding the Guidance: A Comparative Analysis of User Guidance Signals for Interactive Segmentation of Volumetric Images
Mar 13, 2023
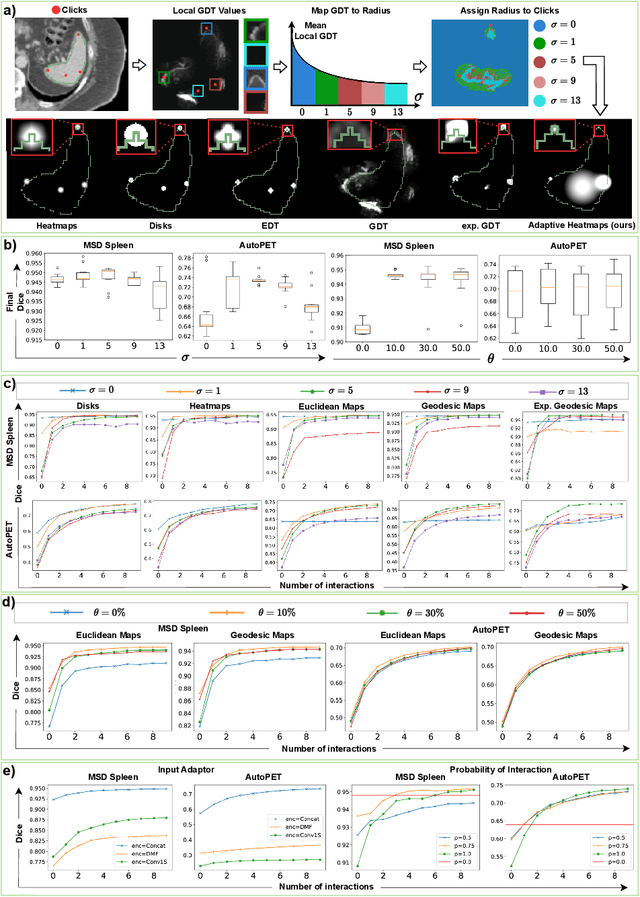

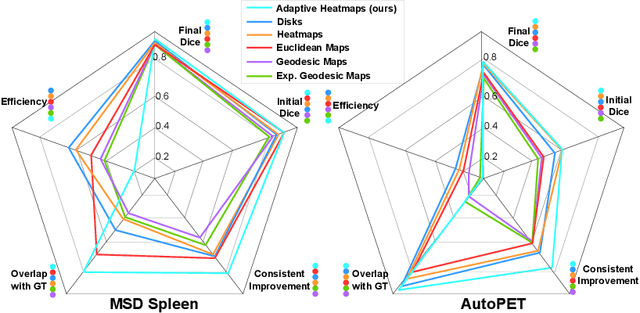
Interactive segmentation reduces the annotation time of medical images and allows annotators to iteratively refine labels with corrective interactions, such as clicks. While existing interactive models transform clicks into user guidance signals, which are combined with images to form (image, guidance) pairs, the question of how to best represent the guidance has not been fully explored. To address this, we conduct a comparative study of existing guidance signals by training interactive models with different signals and parameter settings to identify crucial parameters for the model's design. Based on our findings, we design a guidance signal that retains the benefits of other signals while addressing their limitations. We propose an adaptive Gaussian heatmaps guidance signal that utilizes the geodesic distance transform to dynamically adapt the radius of each heatmap when encoding clicks. We conduct our study on the MSD Spleen and the AutoPET datasets to explore the segmentation of both anatomy (spleen) and pathology (tumor lesions). Our results show that choosing the guidance signal is crucial for interactive segmentation as we improve the performance by 14% Dice with our adaptive heatmaps on the challenging AutoPET dataset when compared to non-interactive models. This brings interactive models one step closer to deployment on clinical workflows. We will make our code publically available.
End-to-end Deformable Attention Graph Neural Network for Single-view Liver Mesh Reconstruction
Mar 13, 2023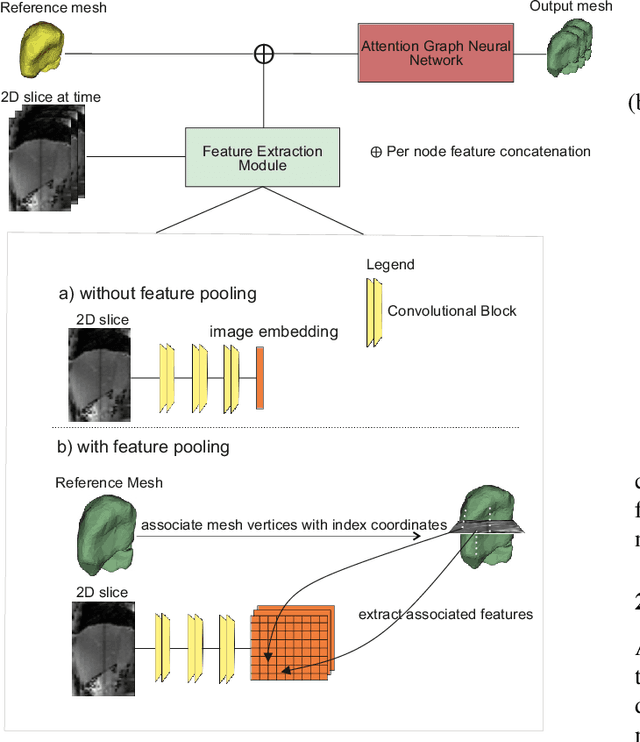
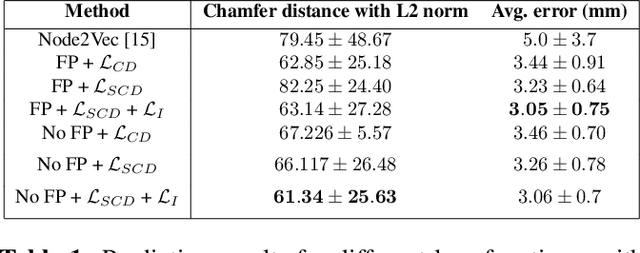
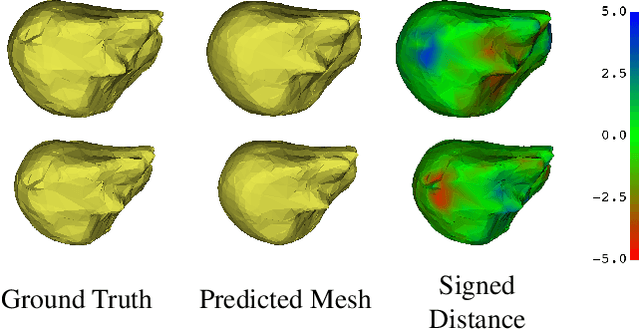
Intensity modulated radiotherapy (IMRT) is one of the most common modalities for treating cancer patients. One of the biggest challenges is precise treatment delivery that accounts for varying motion patterns originating from free-breathing. Currently, image-guided solutions for IMRT is limited to 2D guidance due to the complexity of 3D tracking solutions. We propose a novel end-to-end attention graph neural network model that generates in real-time a triangular shape of the liver based on a reference segmentation obtained at the preoperative phase and a 2D MRI coronal slice taken during the treatment. Graph neural networks work directly with graph data and can capture hidden patterns in non-Euclidean domains. Furthermore, contrary to existing methods, it produces the shape entirely in a mesh structure and correctly infers mesh shape and position based on a surrogate image. We define two on-the-fly approaches to make the correspondence of liver mesh vertices with 2D images obtained during treatment. Furthermore, we introduce a novel task-specific identity loss to constrain the deformation of the liver in the graph neural network to limit phenomenons such as flying vertices or mesh holes. The proposed method achieves results with an average error of 3.06 +- 0.7 mm and Chamfer distance with L2 norm of 63.14 +- 27.28.
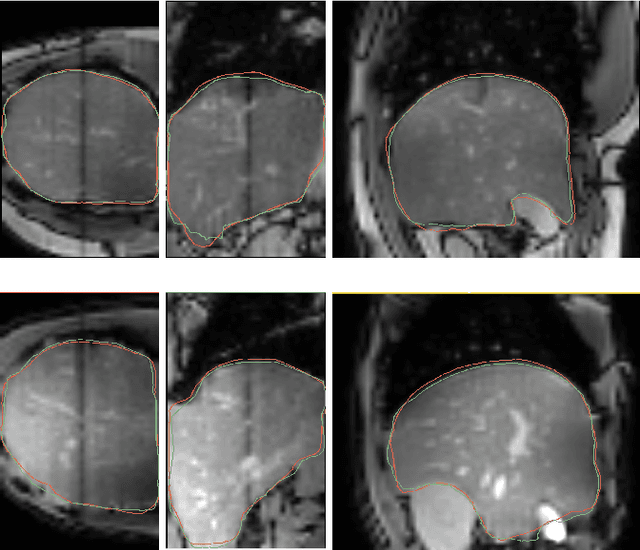
AGTGAN: Unpaired Image Translation for Photographic Ancient Character Generation
Mar 13, 2023
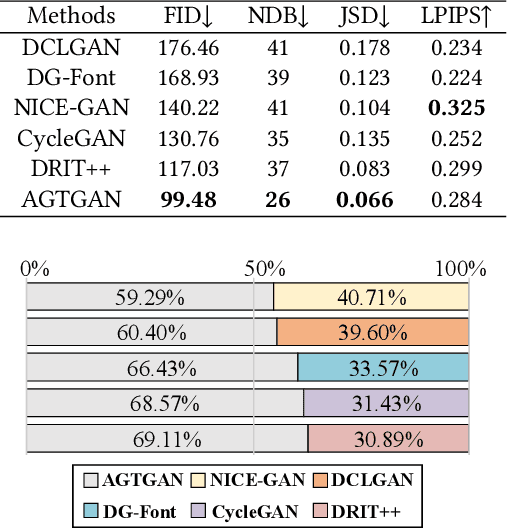

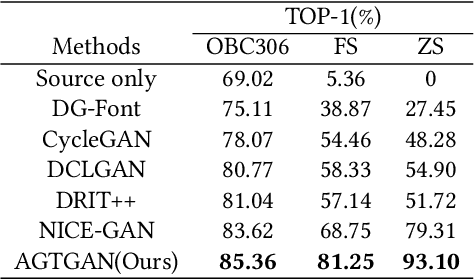
The study of ancient writings has great value for archaeology and philology. Essential forms of material are photographic characters, but manual photographic character recognition is extremely time-consuming and expertise-dependent. Automatic classification is therefore greatly desired. However, the current performance is limited due to the lack of annotated data. Data generation is an inexpensive but useful solution for data scarcity. Nevertheless, the diverse glyph shapes and complex background textures of photographic ancient characters make the generation task difficult, leading to the unsatisfactory results of existing methods. In this paper, we propose an unsupervised generative adversarial network called AGTGAN. By the explicit global and local glyph shape style modeling followed by the stroke-aware texture transfer, as well as an associate adversarial learning mechanism, our method can generate characters with diverse glyphs and realistic textures. We evaluate our approach on the photographic ancient character datasets, e.g., OBC306 and CSDD. Our method outperforms the state-of-the-art approaches in various metrics and performs much better in terms of the diversity and authenticity of generated samples. With our generated images, experiments on the largest photographic oracle bone character dataset show that our method can achieve a significant increase in classification accuracy, up to 16.34%.
Optimising Human-Machine Collaboration for Efficient High-Precision Information Extraction from Text Documents
Feb 18, 2023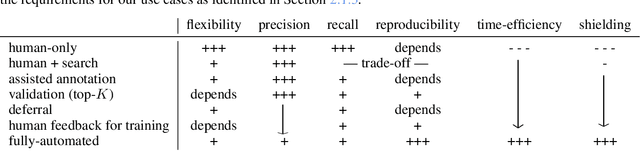
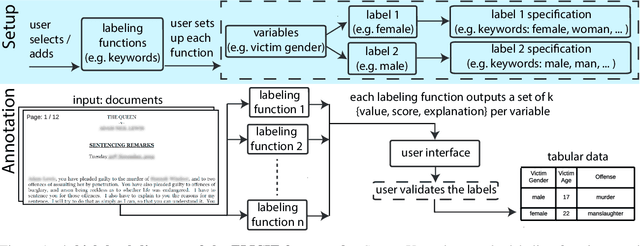
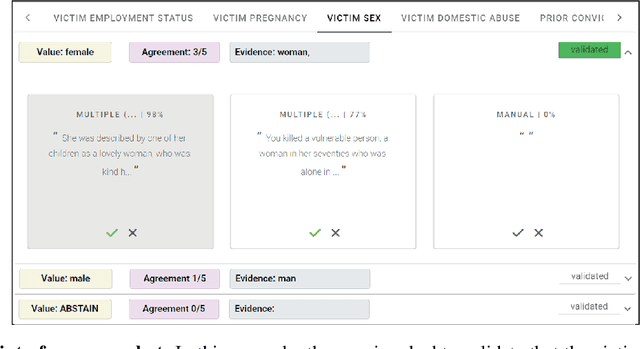
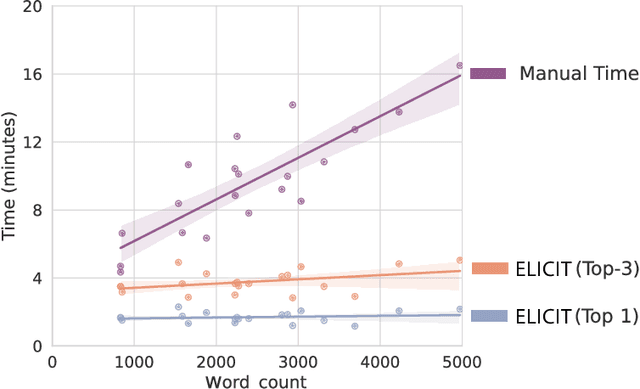
While humans can extract information from unstructured text with high precision and recall, this is often too time-consuming to be practical. Automated approaches, on the other hand, produce nearly-immediate results, but may not be reliable enough for high-stakes applications where precision is essential. In this work, we consider the benefits and drawbacks of various human-only, human-machine, and machine-only information extraction approaches. We argue for the utility of a human-in-the-loop approach in applications where high precision is required, but purely manual extraction is infeasible. We present a framework and an accompanying tool for information extraction using weak-supervision labelling with human validation. We demonstrate our approach on three criminal justice datasets. We find that the combination of computer speed and human understanding yields precision comparable to manual annotation while requiring only a fraction of time, and significantly outperforms fully automated baselines in terms of precision.
Online Re-Planning and Adaptive Parameter Update for Multi-Agent Path Finding with Stochastic Travel Times
Feb 03, 2023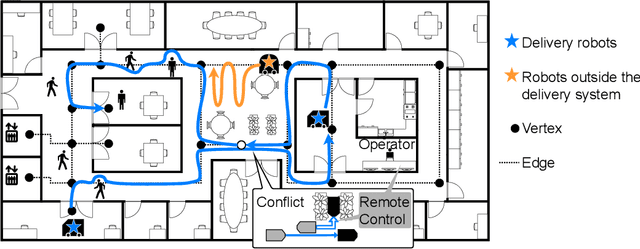
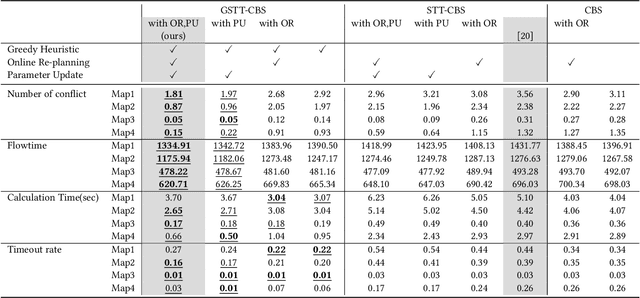
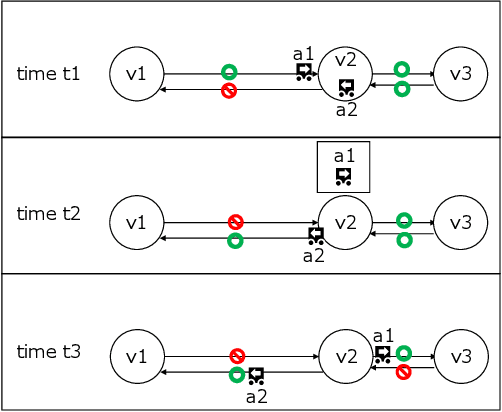
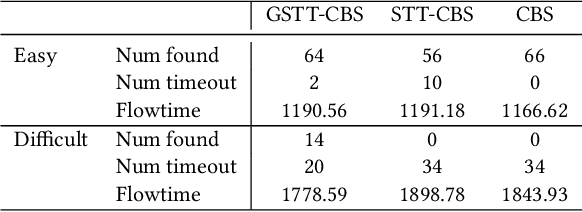
This study explores the problem of Multi-Agent Path Finding with continuous and stochastic travel times whose probability distribution is unknown. Our purpose is to manage a group of automated robots that provide package delivery services in a building where pedestrians and a wide variety of robots coexist, such as delivery services in office buildings, hospitals, and apartments. It is often the case with these real-world applications that the time required for the robots to traverse a corridor takes a continuous value and is randomly distributed, and the prior knowledge of the probability distribution of the travel time is limited. Multi-Agent Path Finding has been widely studied and applied to robot management systems; however, automating the robot operation in such environments remains difficult. We propose 1) online re-planning to update the action plan of robots while it is executed, and 2) parameter update to estimate the probability distribution of travel time using Bayesian inference as the delay is observed. We use a greedy heuristic to obtain solutions in a limited computation time. Through simulations, we empirically compare the performance of our method to those of existing methods in terms of the conflict probability and the actual travel time of robots. The simulation results indicate that the proposed method can find travel paths with at least 50% fewer conflicts and a shorter actual total travel time than existing methods. The proposed method requires a small number of trials to achieve the performance because the parameter update is prioritized on the important edges for path planning, thereby satisfying the requirements of quick implementation of robust planning of automated delivery services.
Just-In-Time Learning for Operational Risk Assessment in Power Grids
Sep 26, 2022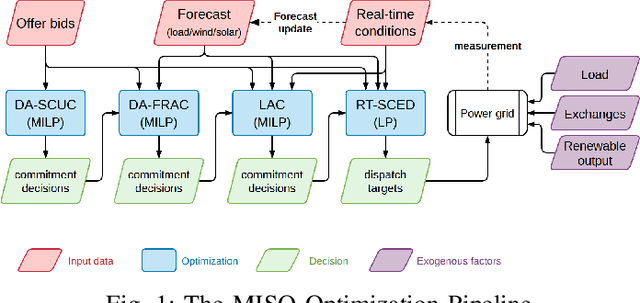
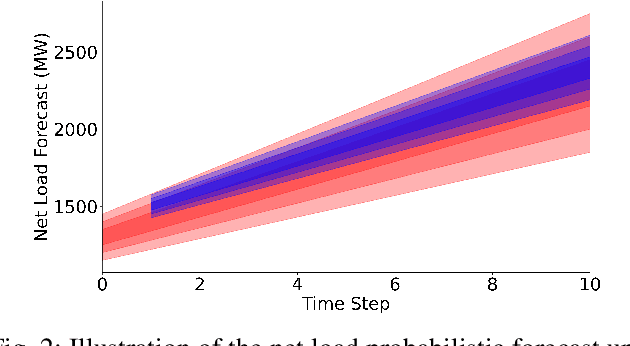
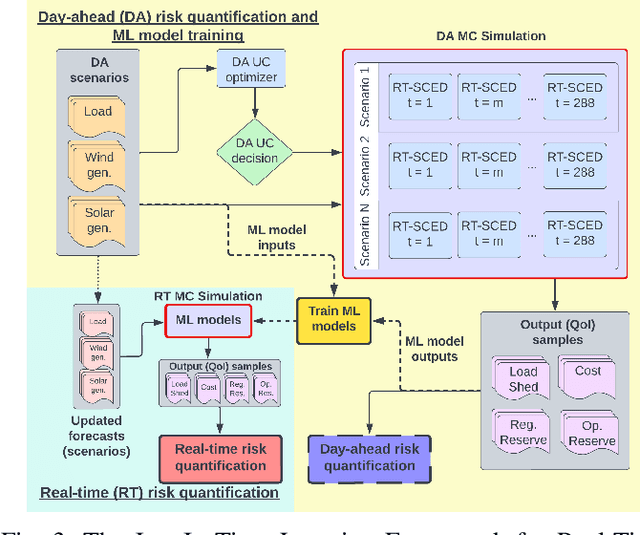
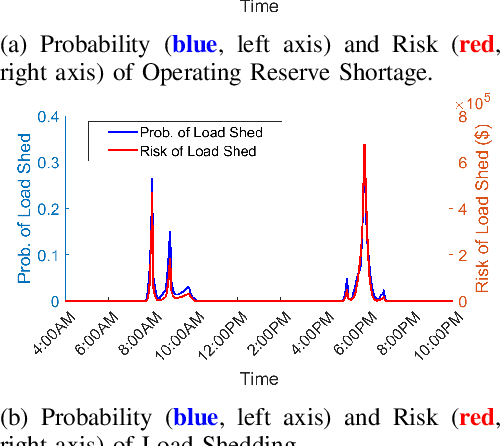
In a grid with a significant share of renewable generation, operators will need additional tools to evaluate the operational risk due to the increased volatility in load and generation. The computational requirements of the forward uncertainty propagation problem, which must solve numerous security-constrained economic dispatch (SCED) optimizations, is a major barrier for such real-time risk assessment. This paper proposes a Just-In-Time Risk Assessment Learning Framework (JITRALF) as an alternative. JITRALF trains risk surrogates, one for each hour in the day, using Machine Learning (ML) to predict the quantities needed to estimate risk, without explicitly solving the SCED problem. This significantly reduces the computational burden of the forward uncertainty propagation and allows for fast, real-time risk estimation. The paper also proposes a novel, asymmetric loss function and shows that models trained using the asymmetric loss perform better than those using symmetric loss functions. JITRALF is evaluated on the French transmission system for assessing the risk of insufficient operating reserves, the risk of load shedding, and the expected operating cost.
Excess risk bound for deep learning under weak dependence
Feb 15, 2023This paper considers deep neural networks for learning weakly dependent processes in a general framework that includes, for instance, regression estimation, time series prediction, time series classification. The $\psi$-weak dependence structure considered is quite large and covers other conditions such as mixing, association,$\ldots$ Firstly, the approximation of smooth functions by deep neural networks with a broad class of activation functions is considered. We derive the required depth, width and sparsity of a deep neural network to approximate any H\"{o}lder smooth function, defined on any compact set $\mx$. Secondly, we establish a bound of the excess risk for the learning of weakly dependent observations by deep neural networks. When the target function is sufficiently smooth, this bound is close to the usual $\mathcal{O}(n^{-1/2})$.
A New Policy Iteration Algorithm For Reinforcement Learning in Zero-Sum Markov Games
Mar 17, 2023Many model-based reinforcement learning (RL) algorithms can be viewed as having two phases that are iteratively implemented: a learning phase where the model is approximately learned and a planning phase where the learned model is used to derive a policy. In the case of standard MDPs, the learning problem can be solved using either value iteration or policy iteration. However, in the case of zero-sum Markov games, there is no efficient policy iteration algorithm; e.g., it has been shown in Hansen et al. (2013) that one has to solve Omega(1/(1-alpha)) MDPs, where alpha is the discount factor, to implement the only known convergent version of policy iteration. Another algorithm for Markov zero-sum games, called naive policy iteration, is easy to implement but is only provably convergent under very restrictive assumptions. Prior attempts to fix naive policy iteration algorithm have several limitations. Here, we show that a simple variant of naive policy iteration for games converges, and converges exponentially fast. The only addition we propose to naive policy iteration is the use of lookahead in the policy improvement phase. This is appealing because lookahead is anyway often used in RL for games. We further show that lookahead can be implemented efficiently in linear Markov games, which are the counterpart of the linear MDPs and have been the subject of much attention recently. We then consider multi-agent reinforcement learning which uses our algorithm in the planning phases, and provide sample and time complexity bounds for such an algorithm.