 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Analyzing Deep Learning Representations of Point Clouds for Real-Time In-Vehicle LiDAR Perception
Nov 02, 2022
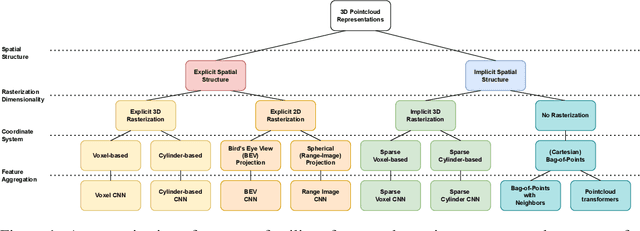

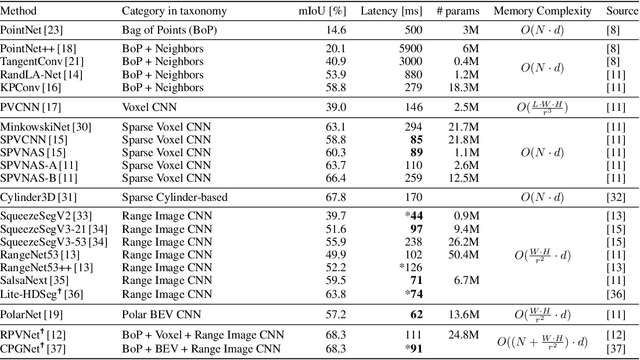
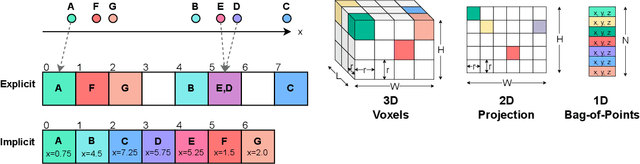
LiDAR sensors are an integral part of modern autonomous vehicles as they provide an accurate, high-resolution 3D representation of the vehicle's surroundings. However, it is computationally difficult to make use of the ever-increasing amounts of data from multiple high-resolution LiDAR sensors. As frame-rates, point cloud sizes and sensor resolutions increase, real-time processing of these point clouds must still extract semantics from this increasingly precise picture of the vehicle's environment. One deciding factor of the run-time performance and accuracy of deep neural networks operating on these point clouds is the underlying data representation and the way it is computed. In this work, we examine the relationship between the computational representations used in neural networks and their performance characteristics. To this end, we propose a novel computational taxonomy of LiDAR point cloud representations used in modern deep neural networks for 3D point cloud processing. Using this taxonomy, we perform a structured analysis of different families of approaches. Thereby, we uncover common advantages and limitations in terms of computational efficiency, memory requirements, and representational capacity as measured by semantic segmentation performance. Finally, we provide some insights and guidance for future developments in neural point cloud processing methods.
Restoration-Degradation Beyond Linear Diffusions: A Non-Asymptotic Analysis For DDIM-Type Samplers
Mar 06, 2023We develop a framework for non-asymptotic analysis of deterministic samplers used for diffusion generative modeling. Several recent works have analyzed stochastic samplers using tools like Girsanov's theorem and a chain rule variant of the interpolation argument. Unfortunately, these techniques give vacuous bounds when applied to deterministic samplers. We give a new operational interpretation for deterministic sampling by showing that one step along the probability flow ODE can be expressed as two steps: 1) a restoration step that runs gradient ascent on the conditional log-likelihood at some infinitesimally previous time, and 2) a degradation step that runs the forward process using noise pointing back towards the current iterate. This perspective allows us to extend denoising diffusion implicit models to general, non-linear forward processes. We then develop the first polynomial convergence bounds for these samplers under mild conditions on the data distribution.
cito: An R package for training neural networks using torch
Mar 16, 2023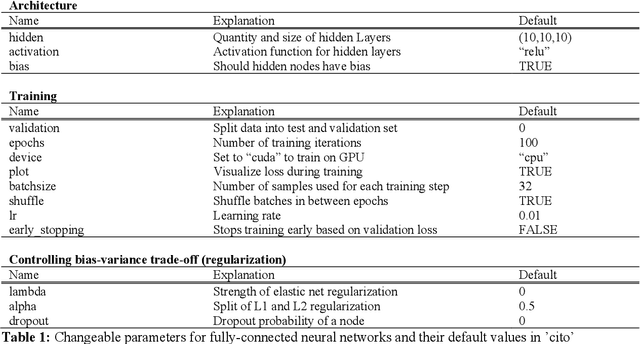
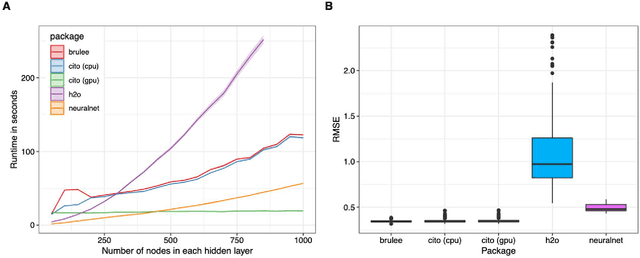
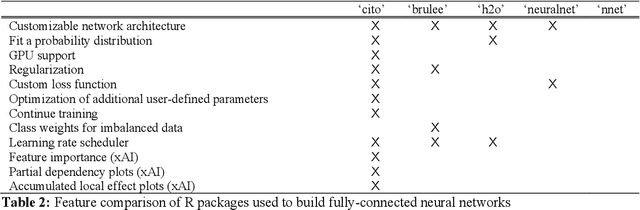

1. Deep neural networks (DNN) have become a central class of algorithms for regression and classification tasks. Although some packages exist that allow users to specify DNN in R, those are rather limited in their functionality. Most current deep learning applications therefore rely on one of the major deep learning frameworks, PyTorch or TensorFlow, to build and train DNN. However, using these frameworks requires substantially more training and time than comparable regression or machine learning packages in the R environment. 2. Here, we present cito, an user-friendly R package for deep learning. cito allows R users to specify deep neural networks in the familiar formula syntax used by most modeling functions in R. In the background, cito uses torch to fit the models, taking advantage of all the numerical optimizations of the torch library, including the ability to switch between training models on CPUs or GPUs. Moreover, cito includes many user-friendly functions for predictions and an explainable Artificial Intelligence (xAI) pipeline for the fitted models. 3. We showcase a typical analysis pipeline using cito, including its built-in xAI features to explore the trained DNN, by building a species distribution model of the African elephant. 4. In conclusion, cito provides a user-friendly R framework to specify, deploy and interpret deep neural networks based on torch. The current stable CRAN version mainly supports fully connected DNNs, but it is planned that future versions will also include CNNs and RNNs.
Web and Mobile Platforms for Managing Elections based on IoT And Machine Learning Algorithms
Mar 16, 2023The global pandemic situation has severely affected all countries. As a result, almost all countries had to adjust to online technologies to continue their processes. In addition, Sri Lanka is yearly spending ten billion on elections. We have examined a proper way of minimizing the cost of hosting these events online. To solve the existing problems and increase the time potency and cost reduction we have used IoT and ML-based technologies. IoT-based data will identify, register, and be used to secure from fraud, while ML algorithms manipulate the election data and produce winning predictions, weather-based voters attendance, and election violence. All the data will be saved in cloud computing and a standard database to store and access the data. This study mainly focuses on four aspects of an E-voting system. The most frequent problems across the world in E-voting are the security, accuracy, and reliability of the systems. E-government systems must be secured against various cyber-attacks and ensure that only authorized users can access valuable, and sometimes sensitive information. Being able to access a system without passwords but using biometric details has been there for a while now, however, our proposed system has a different approach to taking the credentials, processing, and combining the images, reformatting and producing the output, and tracking. In addition, we ensure to enhance e-voting safety. While ML-based algorithms use different data sets and provide predictions in advance.
ChatGPT Participates in a Computer Science Exam
Mar 08, 2023


We asked ChatGPT to participate in an undergraduate computer science exam on ''Algorithms and Data Structures''. We evaluated the program on the entire exam as posed to the students. We hand-copied its answers onto an exam sheet, which was subsequently graded in a blind setup alongside those of 200 participating students. We find that ChatGPT narrowly passed the exam, obtaining 20.5 out of 40 points. This impressive performance indicates that ChatGPT can indeed succeed in challenging tasks like university exams. At the same time, the tasks in our exam are structurally similar to those on other exams, solved homework problems, and teaching materials that can be found online. Therefore, it would be premature to conclude from this experiment that ChatGPT has any understanding of computer science. The transcript of our conversation with ChatGPT is available at \url{https://github.com/tml-tuebingen/chatgpt-algorithm-exam}, and the entire graded exam is in the appendix of this paper.
On the Benefits of Biophysical Synapses
Mar 08, 2023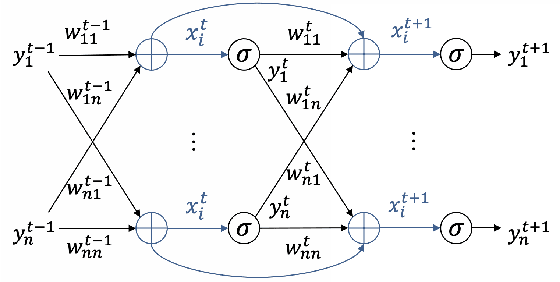
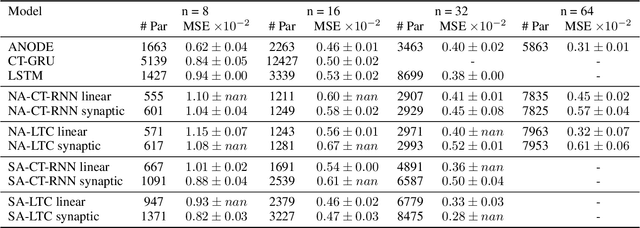
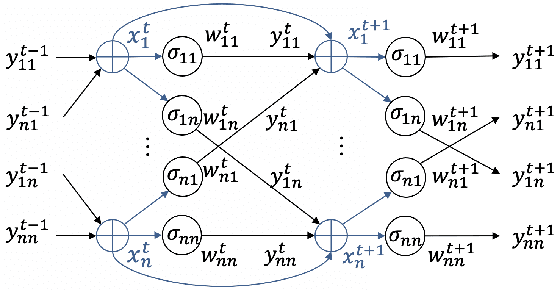
The approximation capability of ANNs and their RNN instantiations, is strongly correlated with the number of parameters packed into these networks. However, the complexity barrier for human understanding, is arguably related to the number of neurons and synapses in the networks, and to the associated nonlinear transformations. In this paper we show that the use of biophysical synapses, as found in LTCs, have two main benefits. First, they allow to pack more parameters for a given number of neurons and synapses. Second, they allow to formulate the nonlinear-network transformation, as a linear system with state-dependent coefficients. Both increase interpretability, as for a given task, they allow to learn a system linear in its input features, that is smaller in size compared to the state of the art. We substantiate the above claims on various time-series prediction tasks, but we believe that our results are applicable to any feedforward or recurrent ANN.
In Search of Deep Learning Architectures for Load Forecasting: A Comparative Analysis and the Impact of the Covid-19 Pandemic on Model Performance
Feb 25, 2023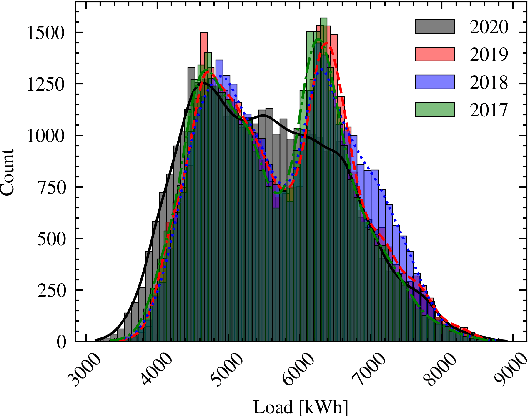
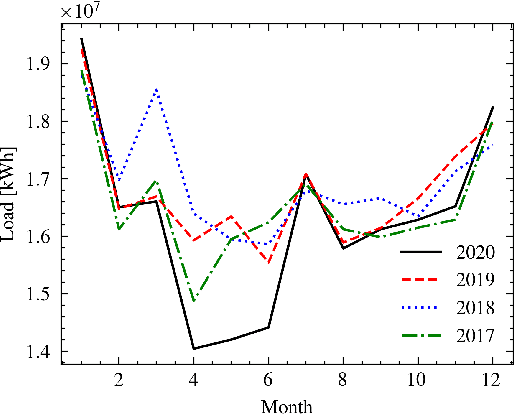
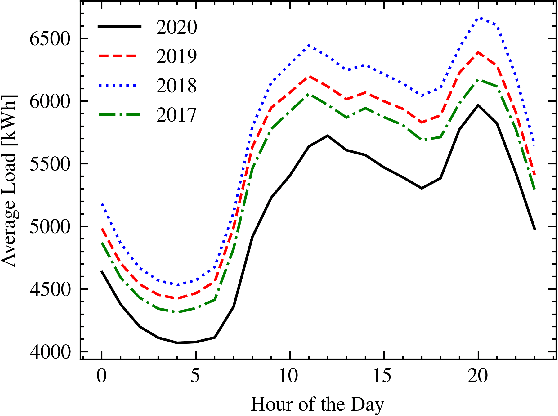
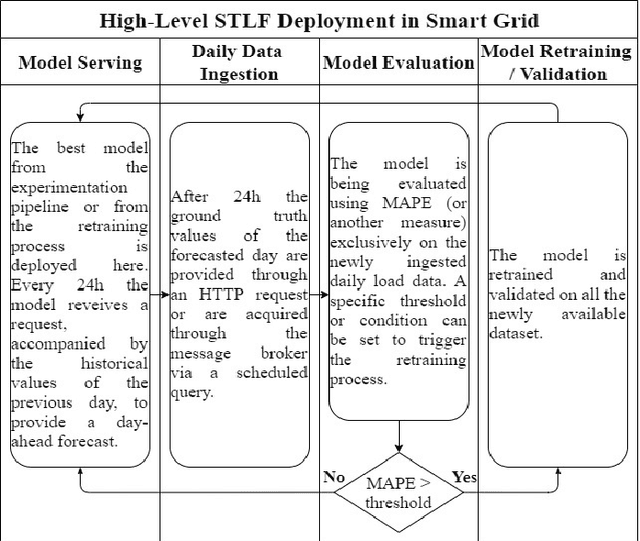
In power grids, short-term load forecasting (STLF) is crucial as it contributes to the optimization of their reliability, emissions, and costs, while it enables the participation of energy companies in the energy market. STLF is a challenging task, due to the complex demand of active and reactive power from multiple types of electrical loads and their dependence on numerous exogenous variables. Amongst them, special circumstances, such as the COVID-19 pandemic, can often be the reason behind distribution shifts of load series. This work conducts a comparative study of Deep Learning (DL) architectures, namely Neural Basis Expansion Analysis Time Series Forecasting (N-BEATS), Long Short-Term Memory (LSTM), and Temporal Convolutional Networks (TCN), with respect to forecasting accuracy and training sustainability, meanwhile examining their out-of-distribution generalization capabilities during the COVID-19 pandemic era. A Pattern Sequence Forecasting (PSF) model is used as baseline. The case study focuses on day-ahead forecasts for the Portuguese national 15-minute resolution net load time series. The results can be leveraged by energy companies and network operators (i) to reinforce their forecasting toolkit with state-of-the-art DL models; (ii) to become aware of the serious consequences of crisis events on model performance; (iii) as a high-level model evaluation, deployment, and sustainability guide within a smart grid context.
Hyperdimensional Computing with Spiking-Phasor Neurons
Feb 28, 2023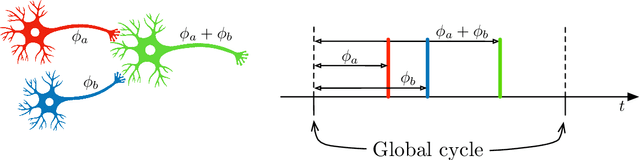
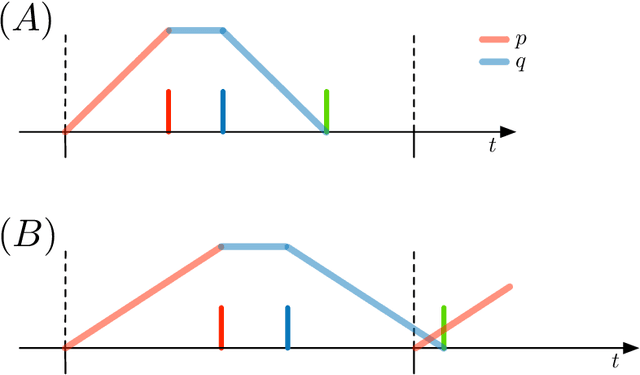
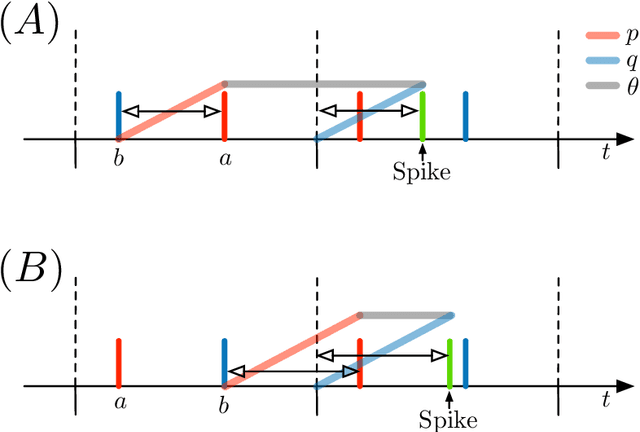
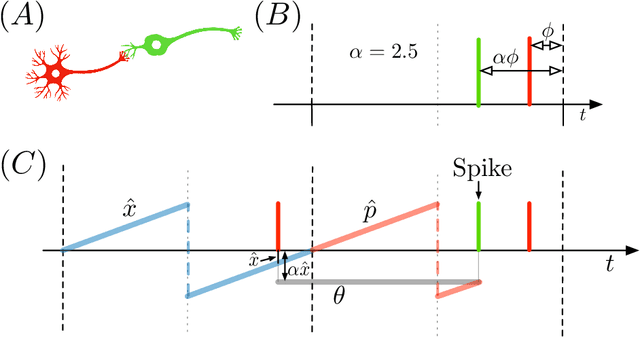
Vector Symbolic Architectures (VSAs) are a powerful framework for representing compositional reasoning. They lend themselves to neural-network implementations, allowing us to create neural networks that can perform cognitive functions, like spatial reasoning, arithmetic, symbol binding, and logic. But the vectors involved can be quite large, hence the alternative label Hyperdimensional (HD) computing. Advances in neuromorphic hardware hold the promise of reducing the running time and energy footprint of neural networks by orders of magnitude. In this paper, we extend some pioneering work to run VSA algorithms on a substrate of spiking neurons that could be run efficiently on neuromorphic hardware.
Approach to Learning Generalized Audio Representation Through Batch Embedding Covariance Regularization and Constant-Q Transforms
Mar 07, 2023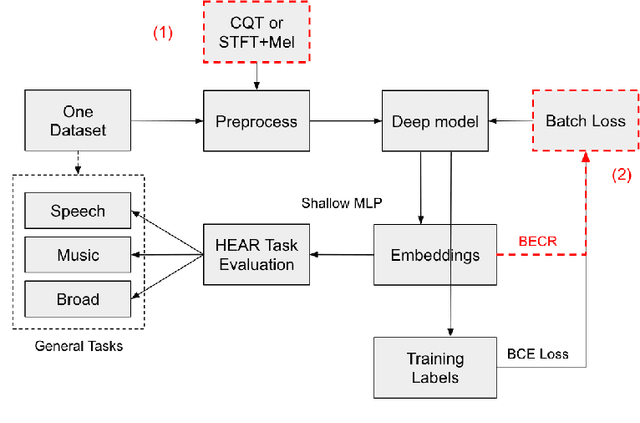
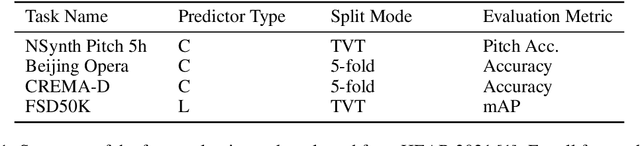
General-purpose embedding is highly desirable for few-shot even zero-shot learning in many application scenarios, including audio tasks. In order to understand representations better, we conducted a thorough error analysis and visualization of HEAR 2021 submission results. Inspired by the analysis, this work experiments with different front-end audio preprocessing methods, including Constant-Q Transform (CQT) and Short-time Fourier transform (STFT), and proposes a Batch Embedding Covariance Regularization (BECR) term to uncover a more holistic simulation of the frequency information received by the human auditory system. We tested the models on the suite of HEAR 2021 tasks, which encompass a broad category of tasks. Preliminary results show (1) the proposed BECR can incur a more dispersed embedding on the test set, (2) BECR improves the PaSST model without extra computation complexity, and (3) STFT preprocessing outperforms CQT in all tasks we tested. Github:https://github.com/ankitshah009/general_audio_embedding_hear_2021
Bias, diversity, and challenges to fairness in classification and automated text analysis. From libraries to AI and back
Mar 07, 2023Libraries are increasingly relying on computational methods, including methods from Artificial Intelligence (AI). This increasing usage raises concerns about the risks of AI that are currently broadly discussed in scientific literature, the media and law-making. In this article we investigate the risks surrounding bias and unfairness in AI usage in classification and automated text analysis within the context of library applications. We describe examples that show how the library community has been aware of such risks for a long time, and how it has developed and deployed countermeasures. We take a closer look at the notion of '(un)fairness' in relation to the notion of 'diversity', and we investigate a formalisation of diversity that models both inclusion and distribution. We argue that many of the unfairness problems of automated content analysis can also be regarded through the lens of diversity and the countermeasures taken to enhance diversity.