 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Towards Real-Time Text2Video via CLIP-Guided, Pixel-Level Optimization
Oct 23, 2022



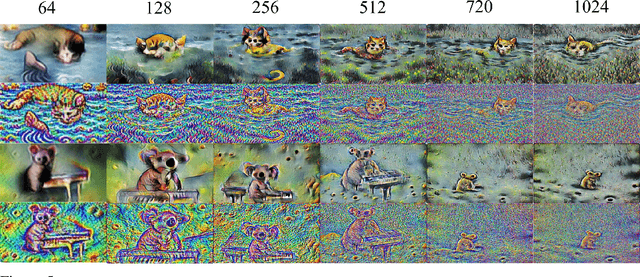
We introduce an approach to generating videos based on a series of given language descriptions. Frames of the video are generated sequentially and optimized by guidance from the CLIP image-text encoder; iterating through language descriptions, weighting the current description higher than others. As opposed to optimizing through an image generator model itself, which tends to be computationally heavy, the proposed approach computes the CLIP loss directly at the pixel level, achieving general content at a speed suitable for near real-time systems. The approach can generate videos in up to 720p resolution, variable frame-rates, and arbitrary aspect ratios at a rate of 1-2 frames per second. Please visit our website to view videos and access our open-source code: https://pschaldenbrand.github.io/text2video/ .
Robust real-time imaging through flexible multimode fibers
Oct 25, 2022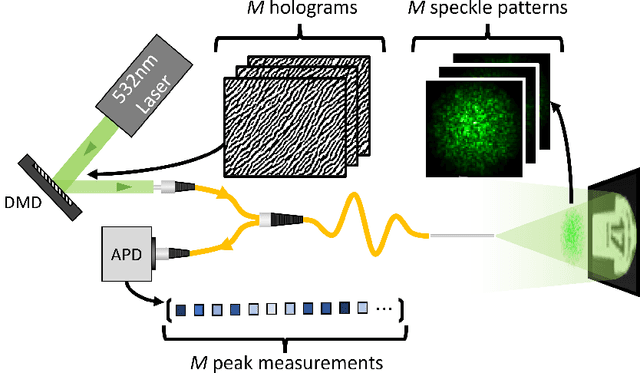
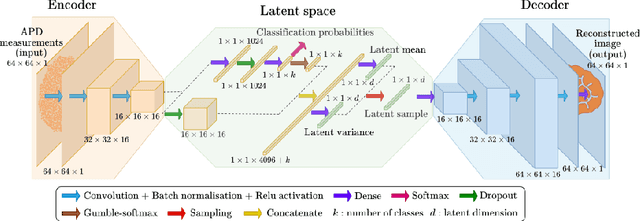
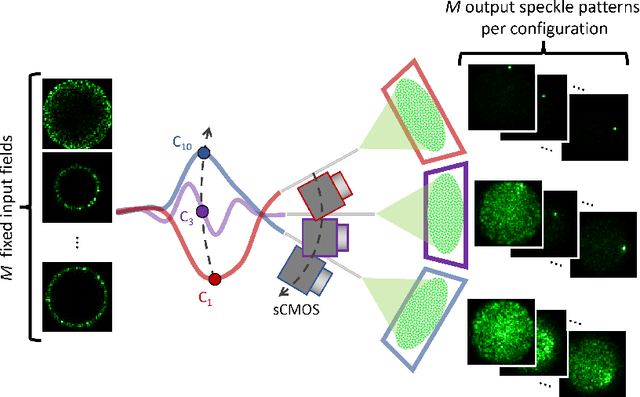
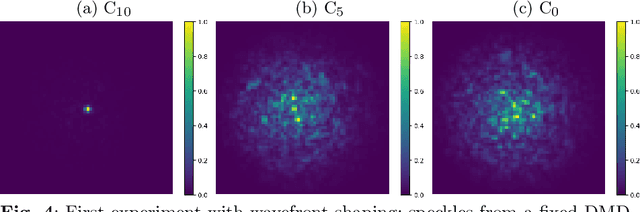
Conventional endoscopes comprise a bundle of optical fibers, associating one fiber for each pixel in the image. In principle, this can be reduced to a single multimode optical fiber (MMF), the width of a human hair, with one fiber spatial-mode per image pixel. However, images transmitted through a MMF emerge as unrecognisable speckle patterns due to dispersion and coupling between the spatial modes of the fiber. Furthermore, speckle patterns change as the fiber undergoes bending, making the use of MMFs in flexible imaging applications even more complicated. In this paper, we propose a real-time imaging system using flexible MMFs, but which is robust to bending. Our approach does not require access or feedback signal from the distal end of the fiber during imaging. We leverage a variational autoencoder (VAE) to reconstruct and classify images from the speckles and show that these images can still be recovered when the bend configuration of the fiber is changed to one that was not part of the training set. We utilize a MMF $300$ mm long with a 50 $\mu$m core for imaging $10\times 10$ cm objects placed approximately at $20$ cm from the fiber and the system can deal with a change in fiber bend of 50$^\circ$ and range of movement of 8 cm.
Scalable End-to-End ML Platforms: from AutoML to Self-serve
Mar 04, 2023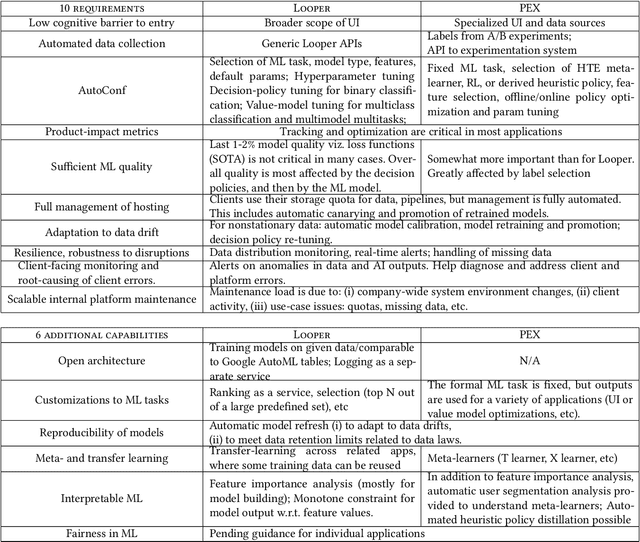
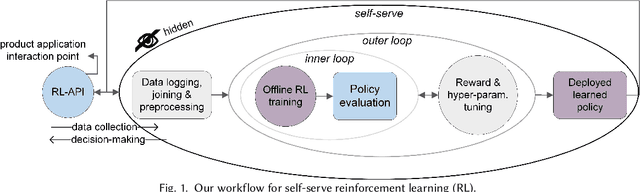
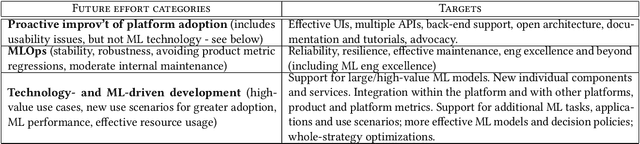
ML platforms help enable intelligent data-driven applications and maintain them with limited engineering effort. Upon sufficiently broad adoption, such platforms reach economies of scale that bring greater component reuse while improving efficiency of system development and maintenance. For an end-to-end ML platform with broad adoption, scaling relies on pervasive ML automation and system integration to reach the quality we term self-serve that we define with ten requirements and six optional capabilities. With this in mind, we identify long-term goals for platform development, discuss related tradeoffs and future work. Our reasoning is illustrated on two commercially-deployed end-to-end ML platforms that host hundreds of real-time use cases -- one general-purpose and one specialized.
GeoLCR: Attention-based Geometric Loop Closure and Registration
Mar 04, 2023
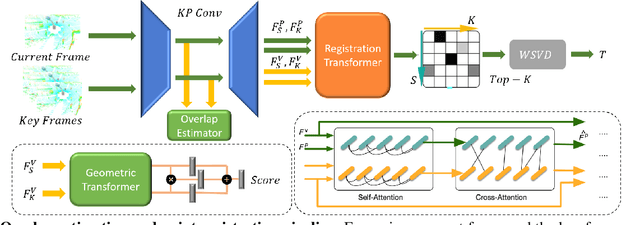
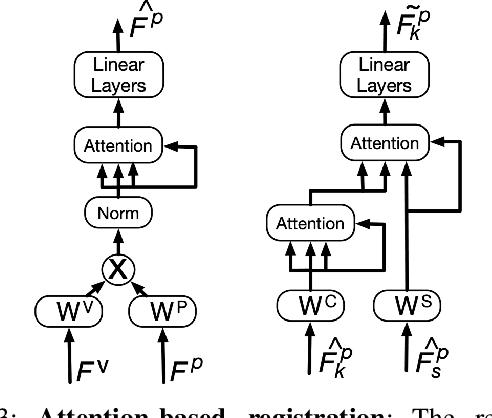
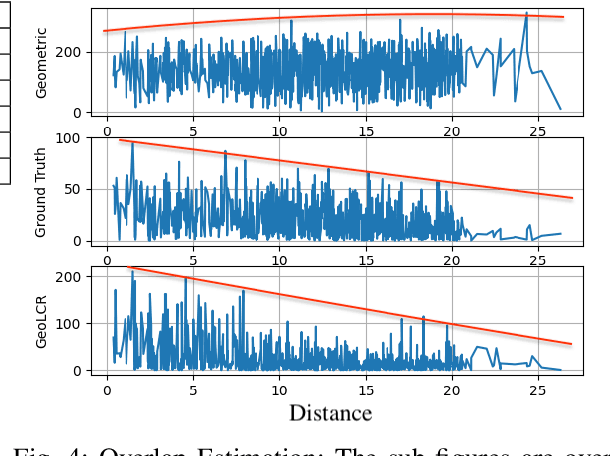
We present a novel algorithm for learning-based loop-closure for SLAM (simultaneous localization and mapping) applications. Our approach is designed for general 3D point cloud data, including those from lidar, and is used to prevent accumulated drift over time for autonomous driving. We voxelize the point clouds into coarse voxels and calculate the overlap to estimate if the vehicle drives in a loop. We perform point-level registration to compute the current pose accurately. We have evaluated our approach on well-known datasets KITTI, KITTI-360, Nuscenes, Complex Urban, NCLT, and MulRan. We show at most 2 times improvement in accuracy estimation of translation and rotation. On some challenging sequences, our method is the first approach that can obtain a 100% success rate.
Drugs Resistance Analysis from Scarce Health Records via Multi-task Graph Representation
Feb 22, 2023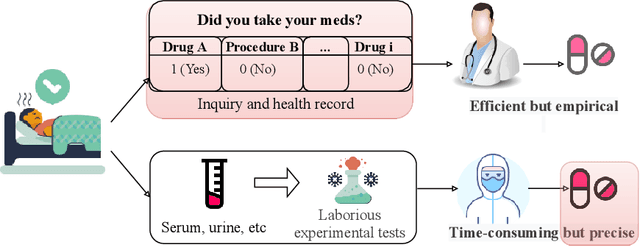

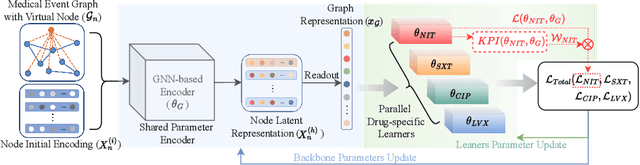

Clinicians prescribe antibiotics by looking at the patient's health record with an experienced eye. However, the therapy might be rendered futile if the patient has drug resistance. Determining drug resistance requires time-consuming laboratory-level testing while applying clinicians' heuristics in an automated way is difficult due to the categorical or binary medical events that constitute health records. In this paper, we propose a novel framework for rapid clinical intervention by viewing health records as graphs whose nodes are mapped from medical events and edges as correspondence between events in given a time window. A novel graph-based model is then proposed to extract informative features and yield automated drug resistance analysis from those high-dimensional and scarce graphs. The proposed method integrates multi-task learning into a common feature extracting graph encoder for simultaneous analyses of multiple drugs as well as stabilizing learning. On a massive dataset comprising over 110,000 patients with urinary tract infections, we verify the proposed method is capable of attaining superior performance on the drug resistance prediction problem. Furthermore, automated drug recommendations resemblant to laboratory-level testing can also be made based on the model resistance analysis.
Analyzing Deep Learning Representations of Point Clouds for Real-Time In-Vehicle LiDAR Perception
Nov 02, 2022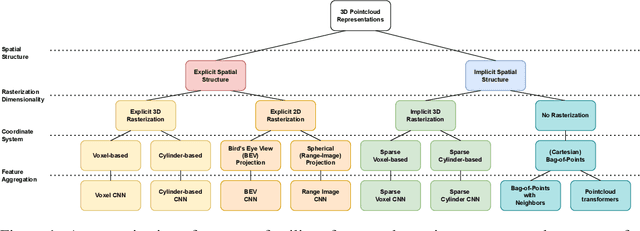

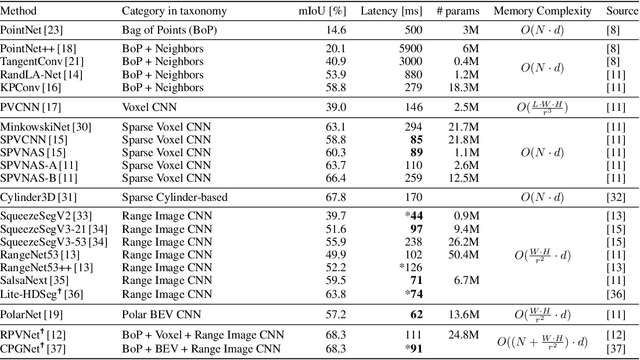
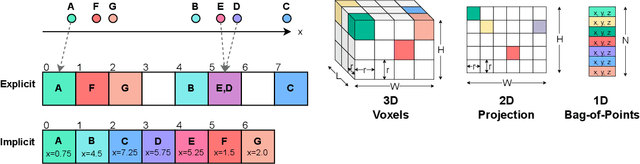
LiDAR sensors are an integral part of modern autonomous vehicles as they provide an accurate, high-resolution 3D representation of the vehicle's surroundings. However, it is computationally difficult to make use of the ever-increasing amounts of data from multiple high-resolution LiDAR sensors. As frame-rates, point cloud sizes and sensor resolutions increase, real-time processing of these point clouds must still extract semantics from this increasingly precise picture of the vehicle's environment. One deciding factor of the run-time performance and accuracy of deep neural networks operating on these point clouds is the underlying data representation and the way it is computed. In this work, we examine the relationship between the computational representations used in neural networks and their performance characteristics. To this end, we propose a novel computational taxonomy of LiDAR point cloud representations used in modern deep neural networks for 3D point cloud processing. Using this taxonomy, we perform a structured analysis of different families of approaches. Thereby, we uncover common advantages and limitations in terms of computational efficiency, memory requirements, and representational capacity as measured by semantic segmentation performance. Finally, we provide some insights and guidance for future developments in neural point cloud processing methods.
Direct Robot Configuration Space Construction using Convolutional Encoder-Decoders
Mar 10, 2023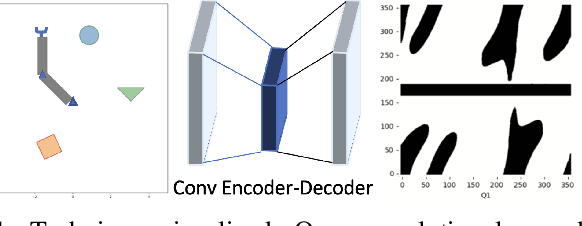
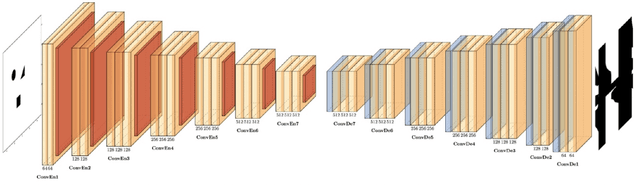
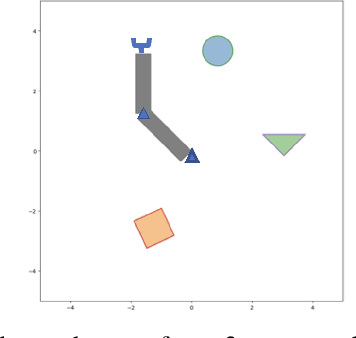
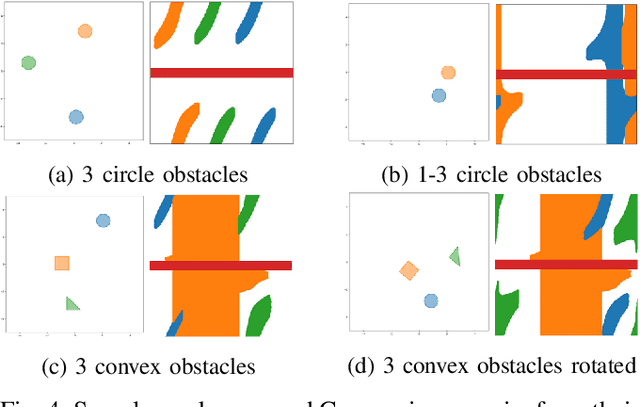
Intelligent robots must be able to perform safe and efficient motion planning in their environments. Central to modern motion planning is the configuration space. Configuration spaces define the set of configurations of a robot that result in collisions with obstacles in the workspace, C-clsn, and the set of configurations that do not, C-free. Modern approaches to motion planning first compute the configuration space and then perform motion planning using the calculated configuration space. Real-time motion planning requires accurate and efficient construction of configuration spaces. We are the first to apply a convolutional encoder-decoder framework for calculating highly accurate approximations to configuration spaces. Our model achieves an average 97.5% F1-score for predicting C-free and C-clsn for 2-D robotic workspaces with a dual-arm robot. Our method limits undetected collisions to less than 2.5% on robotic workspaces that involve translation, rotation, and removal of obstacles. Our model learns highly transferable features between robotic workspaces, requiring little to no fine-tuning to adapt to new transformations of obstacles in the workspace.
Force Feedback Control For Dexterous Robotic Hands Using Conditional Postural Synergies
Mar 10, 2023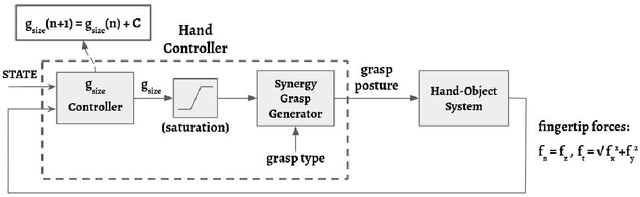
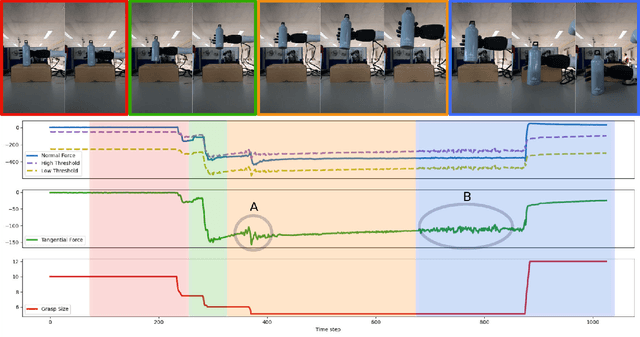


We present a force feedback controller for a dexterous robotic hand equipped with force sensors on its fingertips. Our controller uses the conditional postural synergies framework to generate the grasp postures, i.e. the finger configuration of the robot, at each time step based on forces measured on the robot's fingertips. Using this framework we are able to control the hand during different grasp types using only one variable, the grasp size, which we define as the distance between the tip of the thumb and the index finger. Instead of controlling the finger limbs independently, our controller generates control signals for all the hand joints in a (low-dimensional) shared space (i.e. synergy space). In addition, our approach is modular, which allows to execute various types of precision grips, by changing the synergy space according to the type of grasp. We show that our controller is able to lift objects of various weights and materials, adjust the grasp configuration during changes in the object's weight, and perform object placements and object handovers.
Adaptive Weight Assignment Scheme For Multi-task Learning
Mar 10, 2023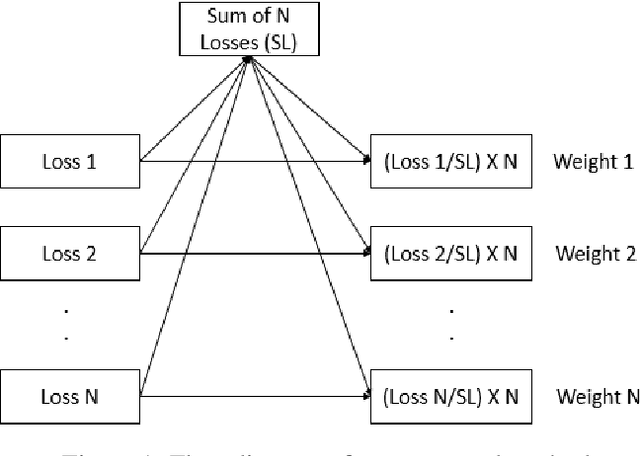
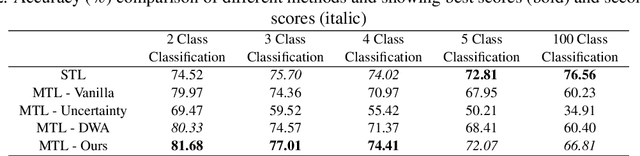
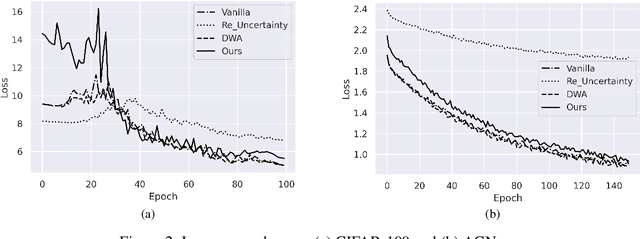
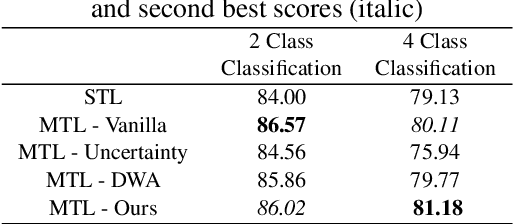
Deep learning based models are used regularly in every applications nowadays. Generally we train a single model on a single task. However, we can train multiple tasks on a single model under multi-task learning settings. This provides us many benefits like lesser training time, training a single model for multiple tasks, reducing overfitting, improving performances etc. To train a model in multi-task learning settings we need to sum the loss values from different tasks. In vanilla multi-task learning settings we assign equal weights but since not all tasks are of similar difficulty we need to allocate more weight to tasks which are more difficult. Also improper weight assignment reduces the performance of the model. We propose a simple weight assignment scheme in this paper which improves the performance of the model and puts more emphasis on difficult tasks. We tested our methods performance on both image and textual data and also compared performance against two popular weight assignment methods. Empirical results suggest that our proposed method achieves better results compared to other popular methods.
DP-Fast MH: Private, Fast, and Accurate Metropolis-Hastings for Large-Scale Bayesian Inference
Mar 10, 2023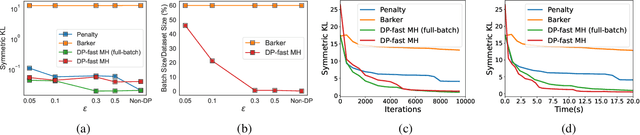
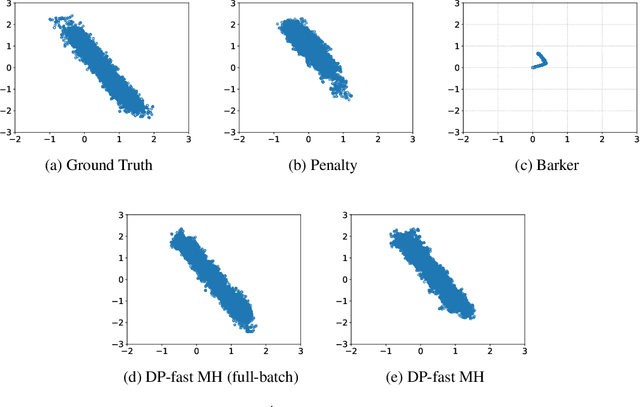
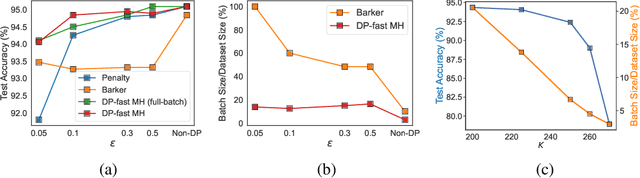
Bayesian inference provides a principled framework for learning from complex data and reasoning under uncertainty. It has been widely applied in machine learning tasks such as medical diagnosis, drug design, and policymaking. In these common applications, the data can be highly sensitive. Differential privacy (DP) offers data analysis tools with powerful worst-case privacy guarantees and has been developed as the leading approach in privacy-preserving data analysis. In this paper, we study Metropolis-Hastings (MH), one of the most fundamental MCMC methods, for large-scale Bayesian inference under differential privacy. While most existing private MCMC algorithms sacrifice accuracy and efficiency to obtain privacy, we provide the first exact and fast DP MH algorithm, using only a minibatch of data in most iterations. We further reveal, for the first time, a three-way trade-off among privacy, scalability (i.e. the batch size), and efficiency (i.e. the convergence rate), theoretically characterizing how privacy affects the utility and computational cost in Bayesian inference. We empirically demonstrate the effectiveness and efficiency of our algorithm in various experiments.