 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
DeepCDCL: An CDCL-based Neural Network Verification Framework
Mar 12, 2024
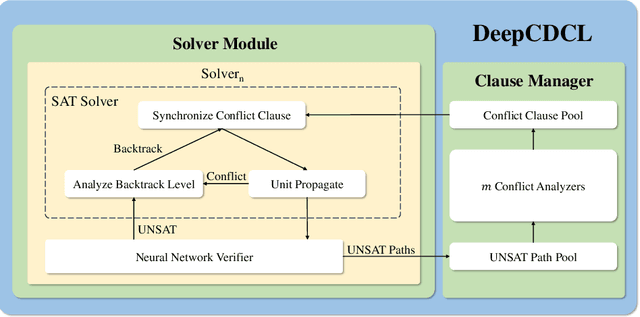
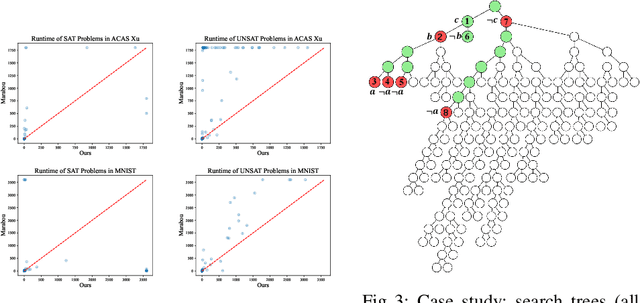
Neural networks in safety-critical applications face increasing safety and security concerns due to their susceptibility to little disturbance. In this paper, we propose DeepCDCL, a novel neural network verification framework based on the Conflict-Driven Clause Learning (CDCL) algorithm. We introduce an asynchronous clause learning and management structure, reducing redundant time consumption compared to the direct application of the CDCL framework. Furthermore, we also provide a detailed evaluation of the performance of our approach on the ACAS Xu and MNIST datasets, showing that a significant speed-up is achieved in most cases.
Unsupervised Contrastive Learning for Robust RF Device Fingerprinting Under Time-Domain Shift
Mar 06, 2024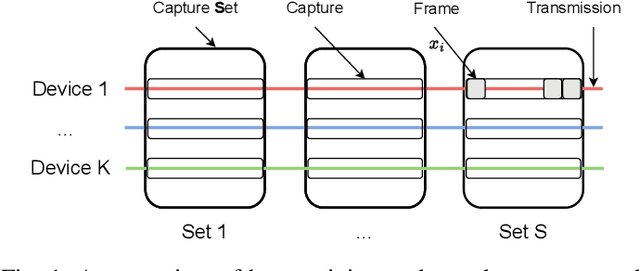
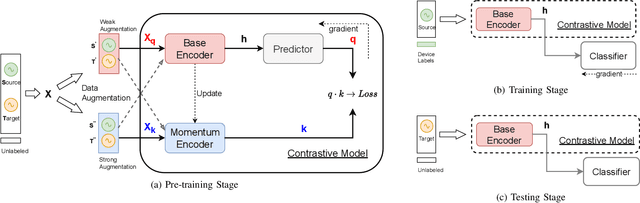
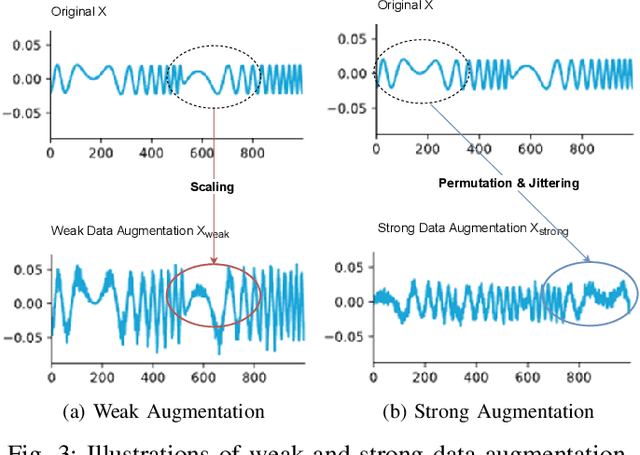
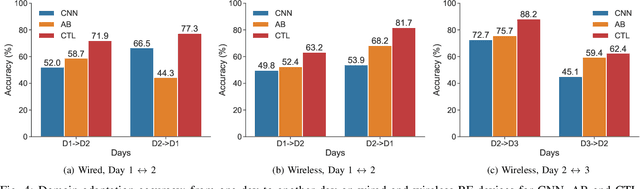
Radio Frequency (RF) device fingerprinting has been recognized as a potential technology for enabling automated wireless device identification and classification. However, it faces a key challenge due to the domain shift that could arise from variations in the channel conditions and environmental settings, potentially degrading the accuracy of RF-based device classification when testing and training data is collected in different domains. This paper introduces a novel solution that leverages contrastive learning to mitigate this domain shift problem. Contrastive learning, a state-of-the-art self-supervised learning approach from deep learning, learns a distance metric such that positive pairs are closer (i.e. more similar) in the learned metric space than negative pairs. When applied to RF fingerprinting, our model treats RF signals from the same transmission as positive pairs and those from different transmissions as negative pairs. Through experiments on wireless and wired RF datasets collected over several days, we demonstrate that our contrastive learning approach captures domain-invariant features, diminishing the effects of domain-specific variations. Our results show large and consistent improvements in accuracy (10.8\% to 27.8\%) over baseline models, thus underscoring the effectiveness of contrastive learning in improving device classification under domain shift.
Physics-Informed Deep Learning for Motion-Corrected Reconstruction of Quantitative Brain MRI
Mar 13, 2024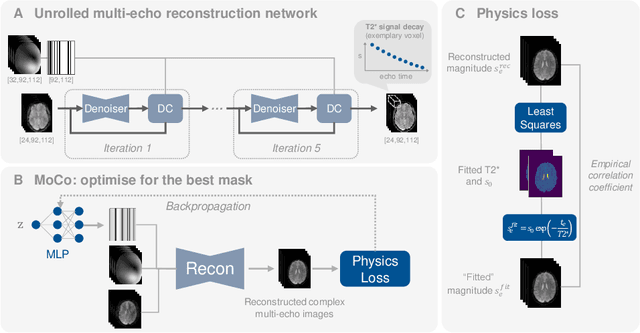

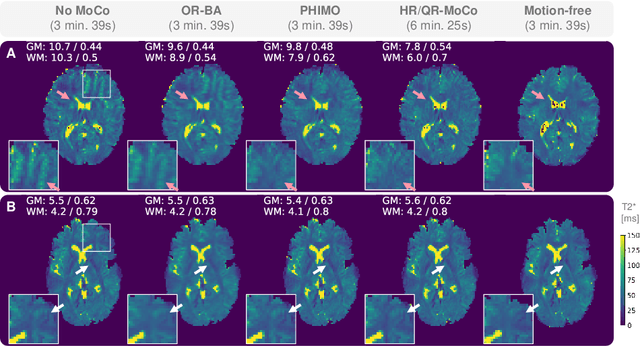
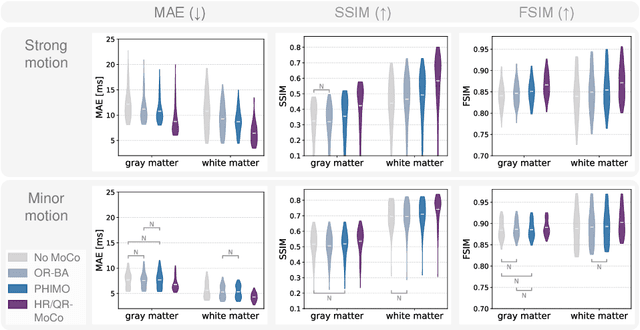
We propose PHIMO, a physics-informed learning-based motion correction method tailored to quantitative MRI. PHIMO leverages information from the signal evolution to exclude motion-corrupted k-space lines from a data-consistent reconstruction. We demonstrate the potential of PHIMO for the application of T2* quantification from gradient echo MRI, which is particularly sensitive to motion due to its sensitivity to magnetic field inhomogeneities. A state-of-the-art technique for motion correction requires redundant acquisition of the k-space center, prolonging the acquisition. We show that PHIMO can detect and exclude intra-scan motion events and, thus, correct for severe motion artifacts. PHIMO approaches the performance of the state-of-the-art motion correction method, while substantially reducing the acquisition time by over 40%, facilitating clinical applicability. Our code is available at https://github.com/HannahEichhorn/PHIMO.
Token Alignment via Character Matching for Subword Completion
Mar 13, 2024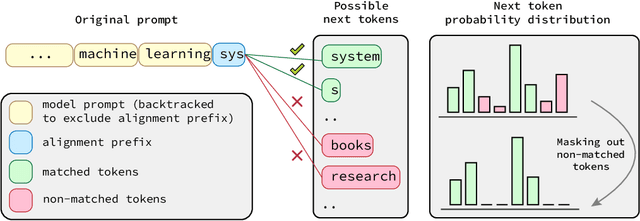
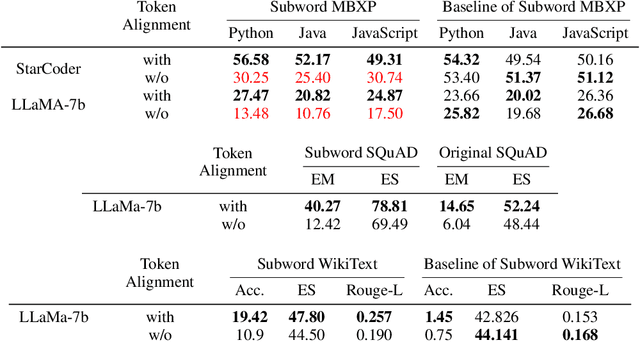

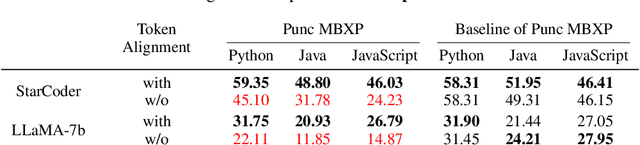
Generative models, widely utilized in various applications, can often struggle with prompts corresponding to partial tokens. This struggle stems from tokenization, where partial tokens fall out of distribution during inference, leading to incorrect or nonsensical outputs. This paper examines a technique to alleviate the tokenization artifact on text completion in generative models, maintaining performance even in regular non-subword cases. The method, termed token alignment, involves backtracking to the last complete tokens and ensuring the model's generation aligns with the prompt. This approach showcases marked improvement across many partial token scenarios, including nuanced cases like space-prefix and partial indentation, with only a minor time increase. The technique and analysis detailed in this paper contribute to the continuous advancement of generative models in handling partial inputs, bearing relevance for applications like code completion and text autocompletion.
Log Summarisation for Defect Evolution Analysis
Mar 13, 2024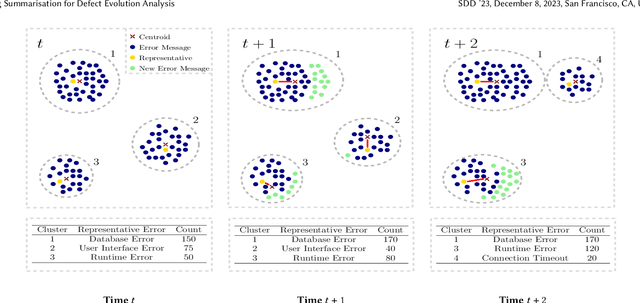
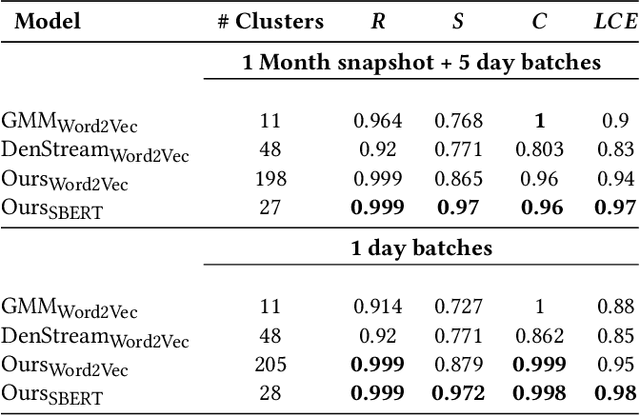
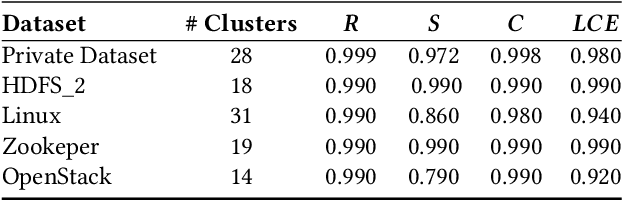
Log analysis and monitoring are essential aspects in software maintenance and identifying defects. In particular, the temporal nature and vast size of log data leads to an interesting and important research question: How can logs be summarised and monitored over time? While this has been a fundamental topic of research in the software engineering community, work has typically focused on heuristic-, syntax-, or static-based methods. In this work, we suggest an online semantic-based clustering approach to error logs that dynamically updates the log clusters to enable monitoring code error life-cycles. We also introduce a novel metric to evaluate the performance of temporal log clusters. We test our system and evaluation metric with an industrial dataset and find that our solution outperforms similar systems. We hope that our work encourages further temporal exploration in defect datasets.
Multi-Fidelity Bayesian Optimization With Across-Task Transferable Max-Value Entropy Search
Mar 14, 2024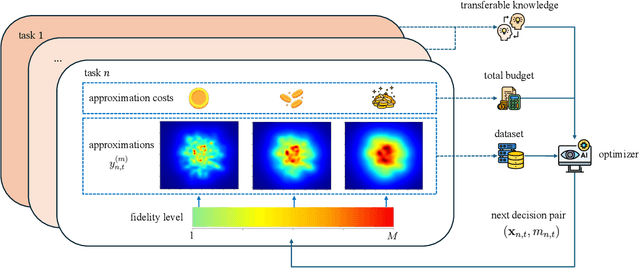
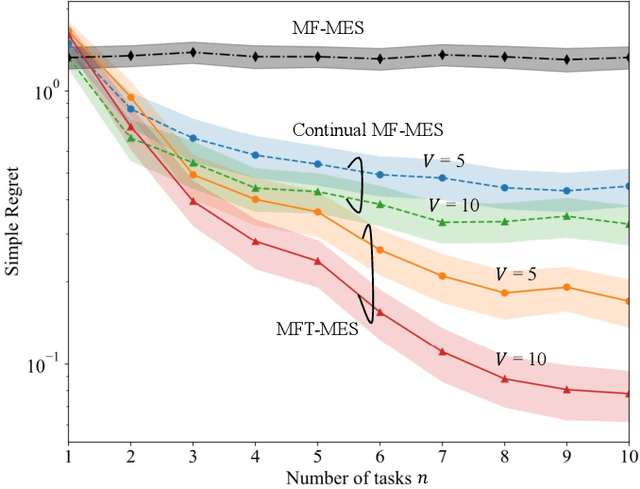
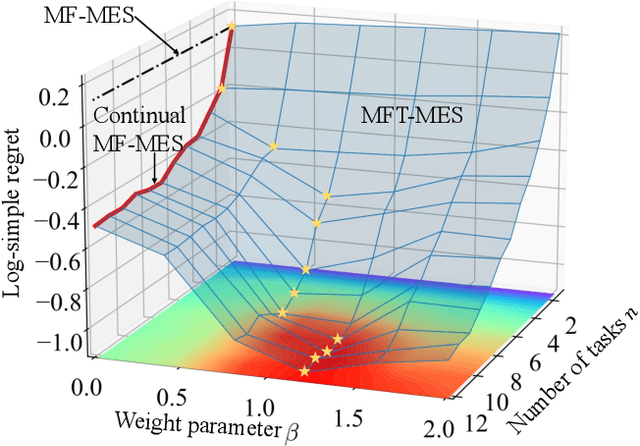
In many applications, ranging from logistics to engineering, a designer is faced with a sequence of optimization tasks for which the objectives are in the form of black-box functions that are costly to evaluate. For example, the designer may need to tune the hyperparameters of neural network models for different learning tasks over time. Rather than evaluating the objective function for each candidate solution, the designer may have access to approximations of the objective functions, for which higher-fidelity evaluations entail a larger cost. Existing multi-fidelity black-box optimization strategies select candidate solutions and fidelity levels with the goal of maximizing the information accrued about the optimal value or solution for the current task. Assuming that successive optimization tasks are related, this paper introduces a novel information-theoretic acquisition function that balances the need to acquire information about the current task with the goal of collecting information transferable to future tasks. The proposed method includes shared inter-task latent variables, which are transferred across tasks by implementing particle-based variational Bayesian updates. Experimental results across synthetic and real-world examples reveal that the proposed provident acquisition strategy that caters to future tasks can significantly improve the optimization efficiency as soon as a sufficient number of tasks is processed.
Asymptotically Near-Optimal Hybrid Beamforming for mmWave IRS-Aided MIMO Systems
Mar 14, 2024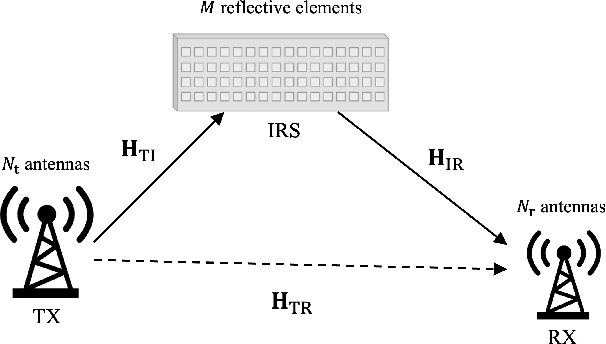
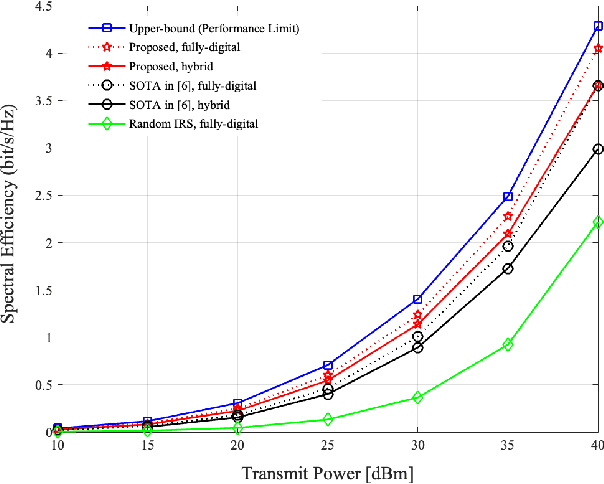
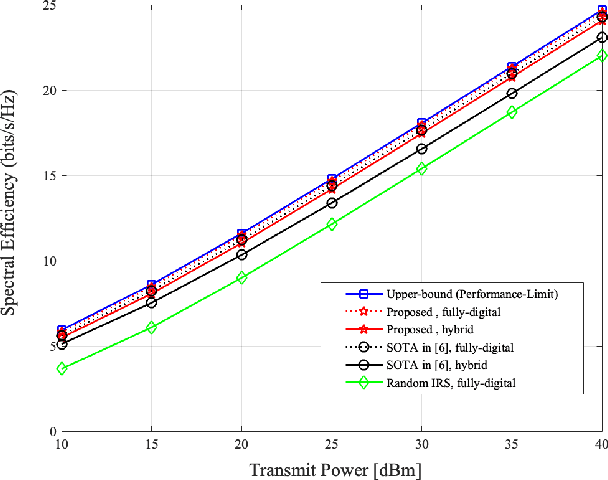
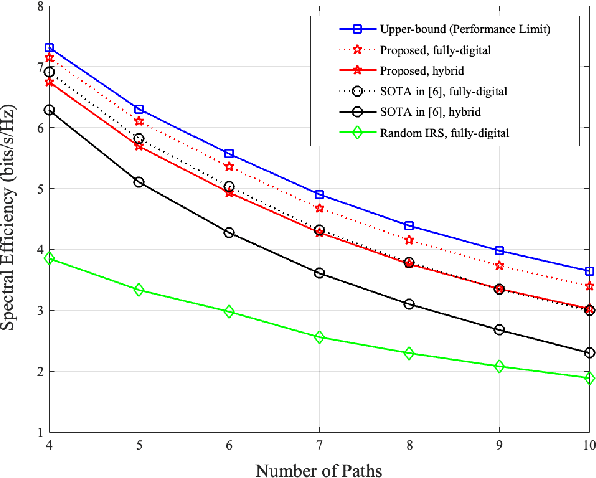
Hybrid beamforming is an emerging technology for massive multiple-input multiple-output (MIMO) systems due to the advantages of lower complexity, cost, and power consumption. Recently, intelligent reflection surface (IRS) has been proposed as the cost-effective technique for robust millimeter-wave (mmWave) MIMO systems. Thus, it is required to jointly optimize a reflection vector and hybrid beamforming matrices for IRS-aided mmWave MIMO systems. Due to the lack of RF chain in the IRS, it is unavailable to acquire the TX-IRS and IRS-RX channels separately. Instead, there are efficient methods to estimate the so-called effective (or cascaded) channel in literature. We for the first time derive the near-optimal solution of the aforementioned joint optimization only using the effective channel. Based on our theoretical analysis, we develop the practical reflection vector and hybrid beamforming matrices by projecting the asymptotic solution into the modulus constraint. Via simulations, it is demonstrated that the proposed construction can outperform the state-of-the-art (SOTA) method, where the latter even requires the knowledge of the TX-IRS ad IRS-RX channels separately. Furthermore, our construction can provide the robustness for channel estimation errors, which is inevitable for practical massive MIMO systems.
A Survey on Federated Learning in Intelligent Transportation Systems
Mar 14, 2024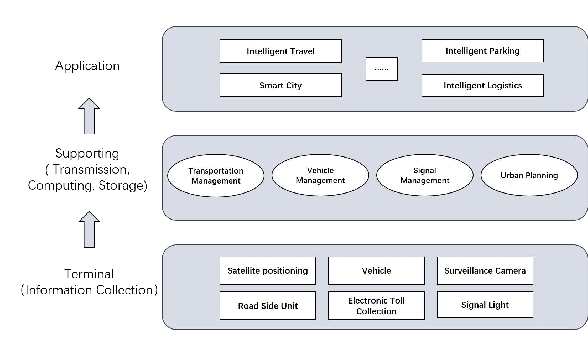
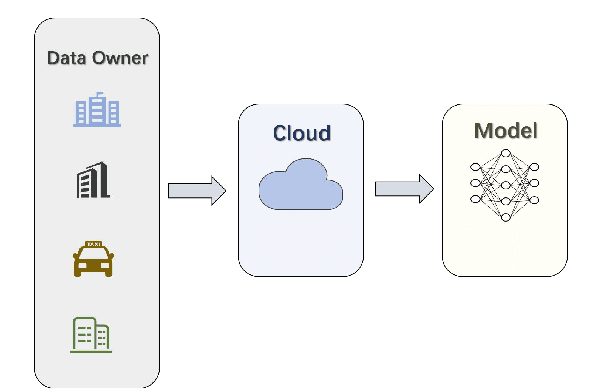
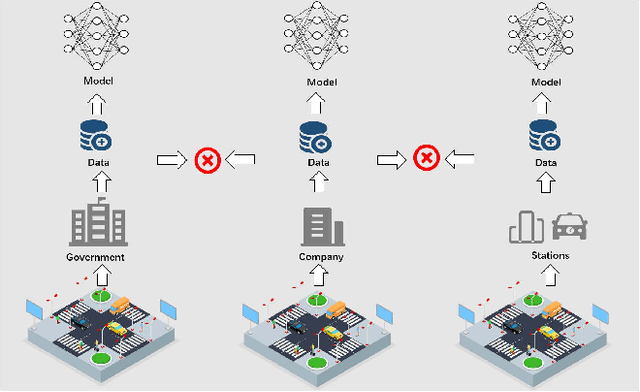
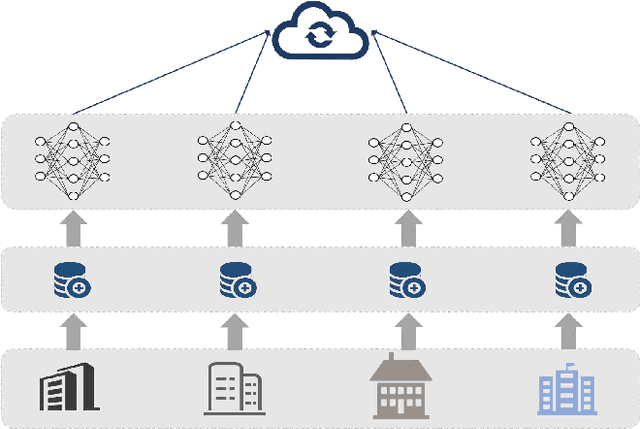
The development of Intelligent Transportation System (ITS) has brought about comprehensive urban traffic information that not only provides convenience to urban residents in their daily lives but also enhances the efficiency of urban road usage, leading to a more harmonious and sustainable urban life. Typical scenarios in ITS mainly include traffic flow prediction, traffic target recognition, and vehicular edge computing. However, most current ITS applications rely on a centralized training approach where users upload source data to a cloud server with high computing power for management and centralized training. This approach has limitations such as poor real-time performance, data silos, and difficulty in guaranteeing data privacy. To address these limitations, federated learning (FL) has been proposed as a promising solution. In this paper, we present a comprehensive review of the application of FL in ITS, with a particular focus on three key scenarios: traffic flow prediction, traffic target recognition, and vehicular edge computing. For each scenario, we provide an in-depth analysis of its key characteristics, current challenges, and specific manners in which FL is leveraged. Moreover, we discuss the benefits that FL can offer as a potential solution to the limitations of the centralized training approach currently used in ITS applications.
Socially Integrated Navigation: A Social Acting Robot with Deep Reinforcement Learning
Mar 14, 2024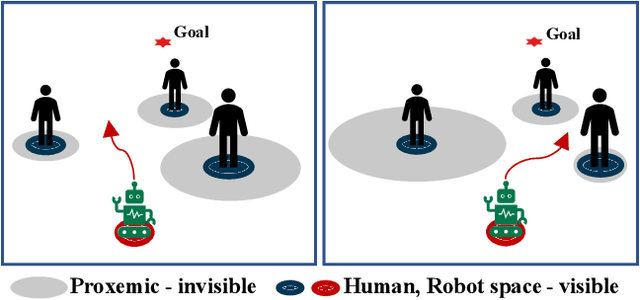
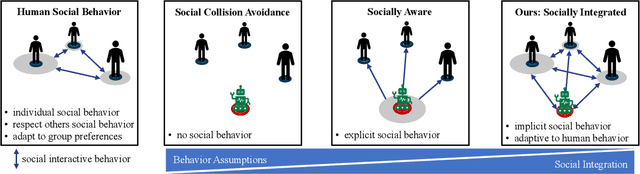
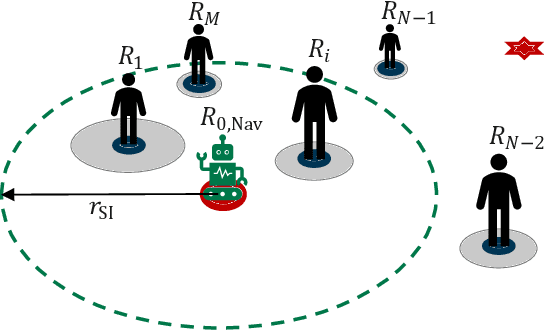

Mobile robots are being used on a large scale in various crowded situations and become part of our society. The socially acceptable navigation behavior of a mobile robot with individual human consideration is an essential requirement for scalable applications and human acceptance. Deep Reinforcement Learning (DRL) approaches are recently used to learn a robot's navigation policy and to model the complex interactions between robots and humans. We propose to divide existing DRL-based navigation approaches based on the robot's exhibited social behavior and distinguish between social collision avoidance with a lack of social behavior and socially aware approaches with explicit predefined social behavior. In addition, we propose a novel socially integrated navigation approach where the robot's social behavior is adaptive and emerges from the interaction with humans. The formulation of our approach is derived from a sociological definition, which states that social acting is oriented toward the acting of others. The DRL policy is trained in an environment where other agents interact socially integrated and reward the robot's behavior individually. The simulation results indicate that the proposed socially integrated navigation approach outperforms a socially aware approach in terms of distance traveled, time to completion, and negative impact on all agents within the environment.
GaussianImage: 1000 FPS Image Representation and Compression by 2D Gaussian Splatting
Mar 14, 2024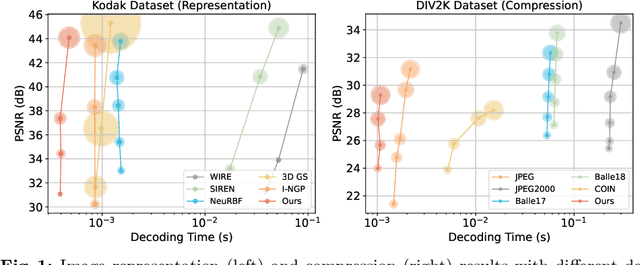
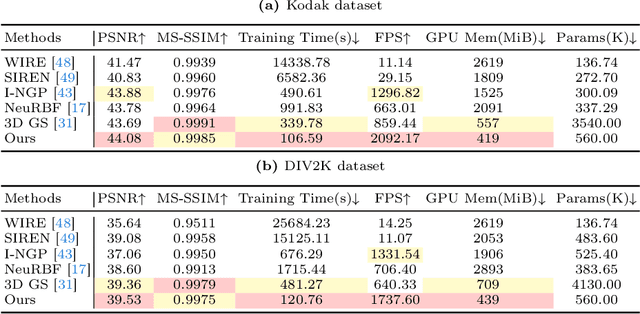

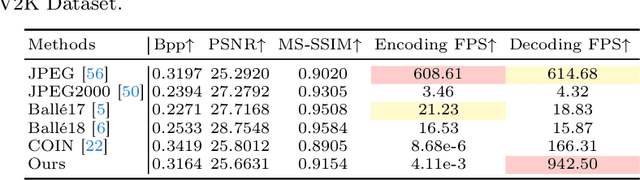
Implicit neural representations (INRs) recently achieved great success in image representation and compression, offering high visual quality and fast rendering speeds with 10-1000 FPS, assuming sufficient GPU resources are available. However, this requirement often hinders their use on low-end devices with limited memory. In response, we propose a groundbreaking paradigm of image representation and compression by 2D Gaussian Splatting, named GaussianImage. We first introduce 2D Gaussian to represent the image, where each Gaussian has 8 parameters including position, covariance and color. Subsequently, we unveil a novel rendering algorithm based on accumulated summation. Remarkably, our method with a minimum of 3$\times$ lower GPU memory usage and 5$\times$ faster fitting time not only rivals INRs (e.g., WIRE, I-NGP) in representation performance, but also delivers a faster rendering speed of 1500-2000 FPS regardless of parameter size. Furthermore, we integrate existing vector quantization technique to build an image codec. Experimental results demonstrate that our codec attains rate-distortion performance comparable to compression-based INRs such as COIN and COIN++, while facilitating decoding speeds of approximately 1000 FPS. Additionally, preliminary proof of concept shows that our codec surpasses COIN and COIN++ in performance when using partial bits-back coding.