 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Clinically Feasible Diffusion Reconstruction for Highly-Accelerated Cardiac Cine MRI
Mar 13, 2024
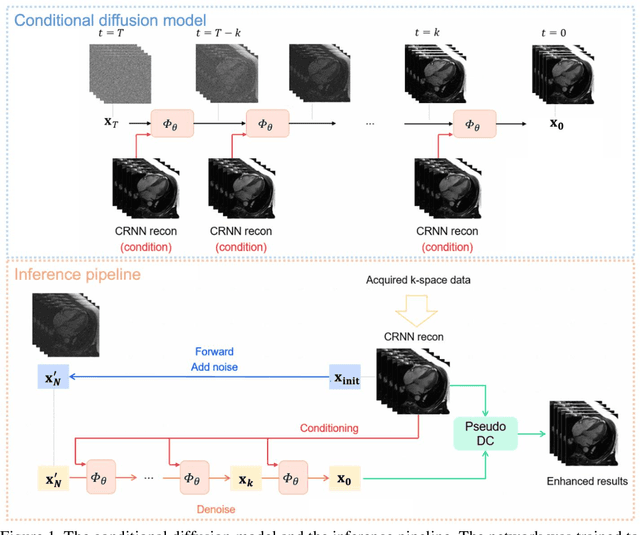
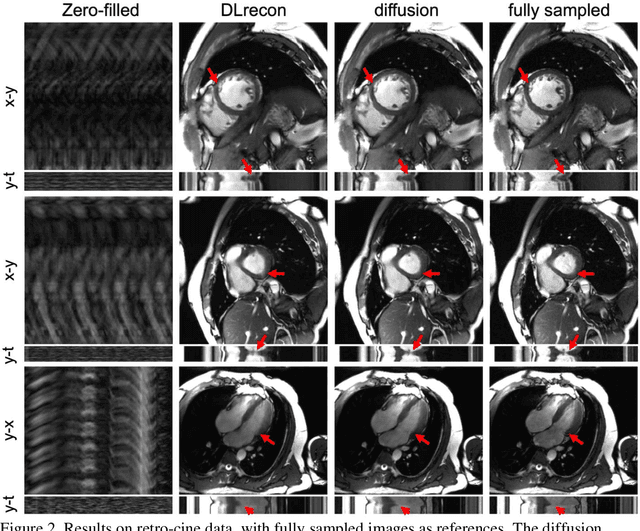
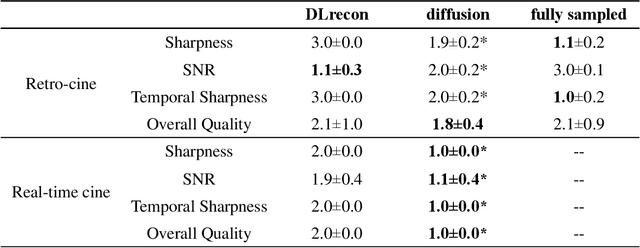
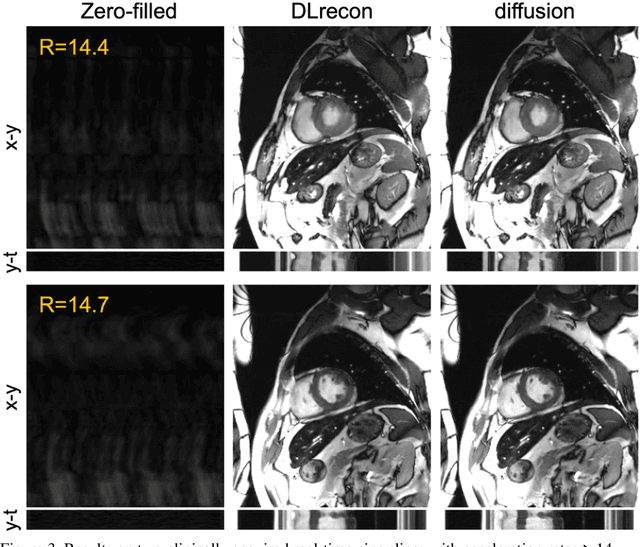
The currently limited quality of accelerated cardiac cine reconstruction may potentially be improved by the emerging diffusion models, but the clinically unacceptable long processing time poses a challenge. We aim to develop a clinically feasible diffusion-model-based reconstruction pipeline to improve the image quality of cine MRI. A multi-in multi-out diffusion enhancement model together with fast inference strategies were developed to be used in conjunction with a reconstruction model. The diffusion reconstruction reduced spatial and temporal blurring in prospectively undersampled clinical data, as validated by experts inspection. The 1.5s per video processing time enabled the approach to be applied in clinical scenarios.
Physics-Informed Neural Network for Volumetric Sound field Reconstruction of Speech Signals
Mar 14, 2024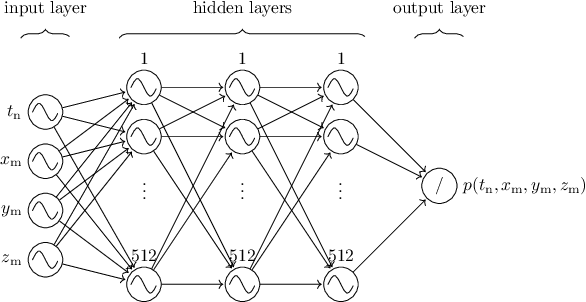
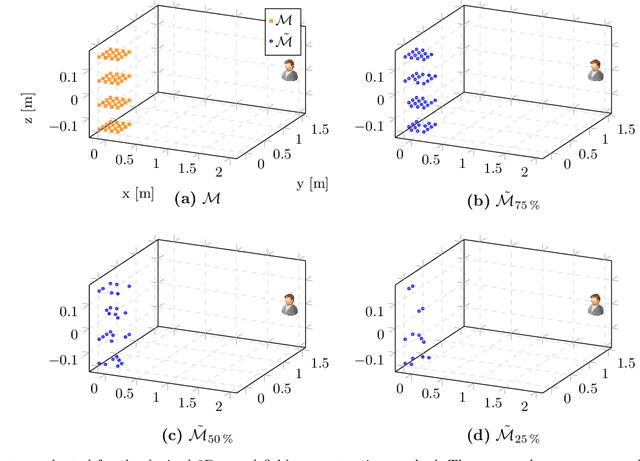
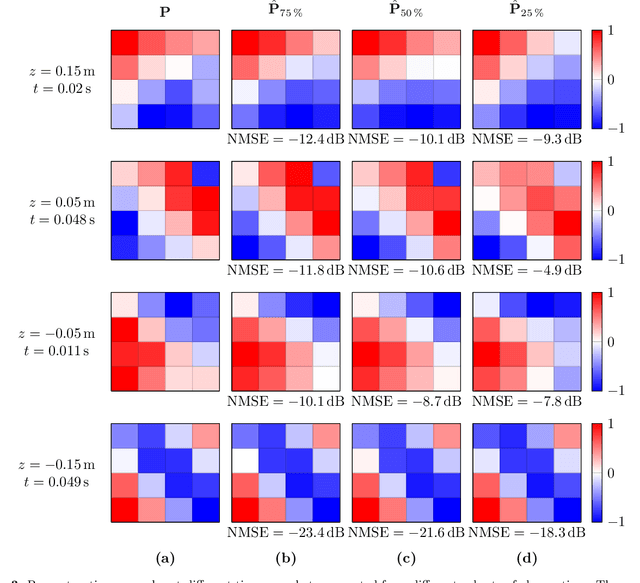
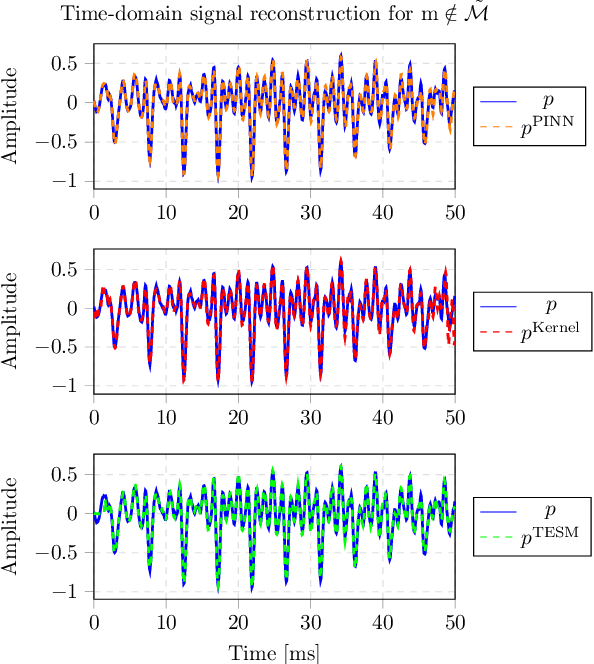
Recent developments in acoustic signal processing have seen the integration of deep learning methodologies, alongside the continued prominence of classical wave expansion-based approaches, particularly in sound field reconstruction. Physics-Informed Neural Networks (PINNs) have emerged as a novel framework, bridging the gap between data-driven and model-based techniques for addressing physical phenomena governed by partial differential equations. This paper introduces a PINN-based approach for the recovery of arbitrary volumetric acoustic fields. The network incorporates the wave equation to impose a regularization on signal reconstruction in the time domain. This methodology enables the network to learn the underlying physics of sound propagation and allows for the complete characterization of the sound field based on a limited set of observations. The proposed method's efficacy is validated through experiments involving speech signals in a real-world environment, considering varying numbers of available measurements. Moreover, a comparative analysis is undertaken against state-of-the-art frequency-domain and time-domain reconstruction methods from existing literature, highlighting the increased accuracy across the various measurement configurations.
Localization in Digital Twin MIMO Networks: A Case for Massive Fingerprinting
Mar 14, 2024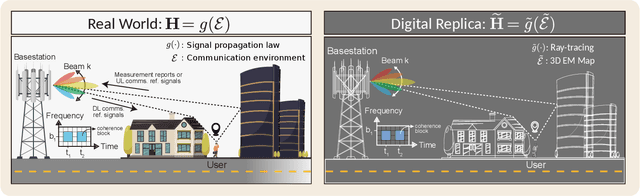
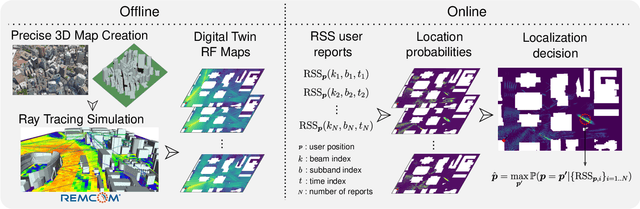
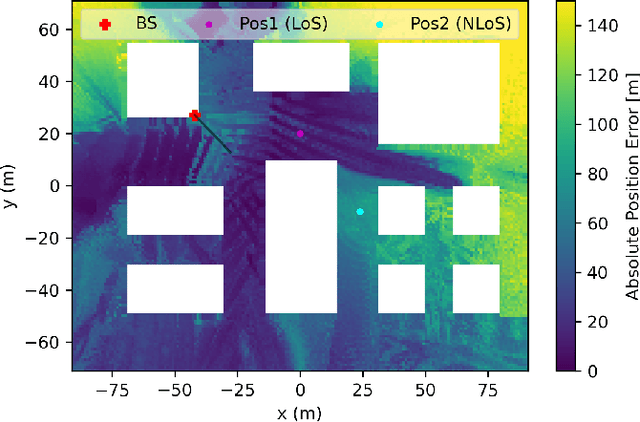
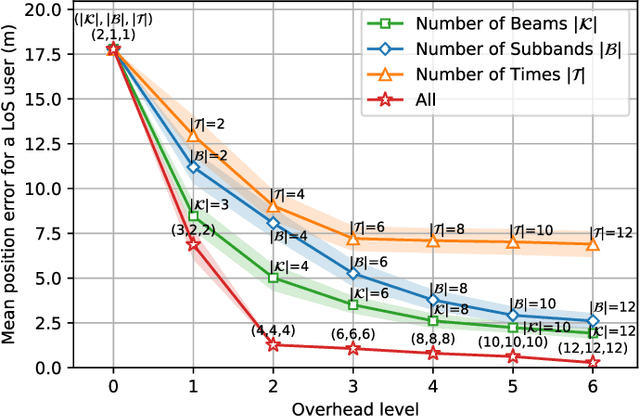
Localization in outdoor wireless systems typically requires transmitting specific reference signals to estimate distance (trilateration methods) or angle (triangulation methods). These cause overhead on communication, need a LoS link to work well, and require multiple base stations, often imposing synchronization or specific hardware requirements. Fingerprinting has none of these drawbacks, but building its database requires high human effort to collect real-world measurements. For a long time, this issue limited the size of databases and thus their performance. This work proposes significantly reducing human effort in building fingerprinting databases by populating them with \textit{digital twin RF maps}. These RF maps are built from ray-tracing simulations on a digital replica of the environment across several frequency bands and beamforming configurations. Online user fingerprints are then matched against this spatial database. The approach was evaluated with practical simulations using realistic propagation models and user measurements. Our experiments show sub-meter localization errors on a NLoS location 95\% of the time using sensible user measurement report sizes. Results highlight the promising potential of the proposed digital twin approach for ubiquitous wide-area 6G localization.
FishNet: Deep Neural Networks for Low-Cost Fish Stock Estimation
Mar 16, 2024

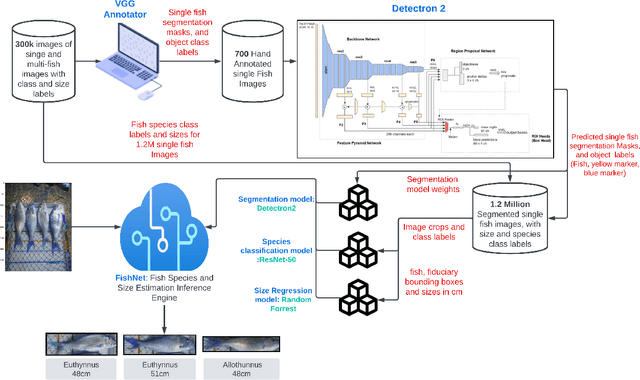

Fish stock assessment often involves manual fish counting by taxonomy specialists, which is both time-consuming and costly. We propose an automated computer vision system that performs both taxonomic classification and fish size estimation from images taken with a low-cost digital camera. The system first performs object detection and segmentation using a Mask R-CNN to identify individual fish from images containing multiple fish, possibly consisting of different species. Then each fish species is classified and the predicted length using separate machine learning models. These models are trained on a dataset of 50,000 hand-annotated images containing 163 different fish species, ranging in length from 10cm to 250cm. Evaluated on held-out test data, our system achieves a $92\%$ intersection over union on the fish segmentation task, a $89\%$ top-1 classification accuracy on single fish species classification, and a $2.3$~cm mean error on the fish length estimation task.
Reliable uncertainty with cheaper neural network ensembles: a case study in industrial parts classification
Mar 15, 2024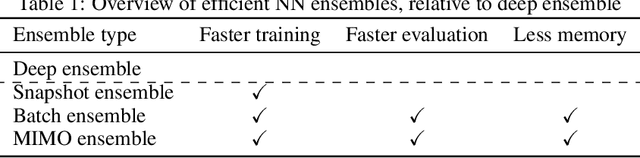
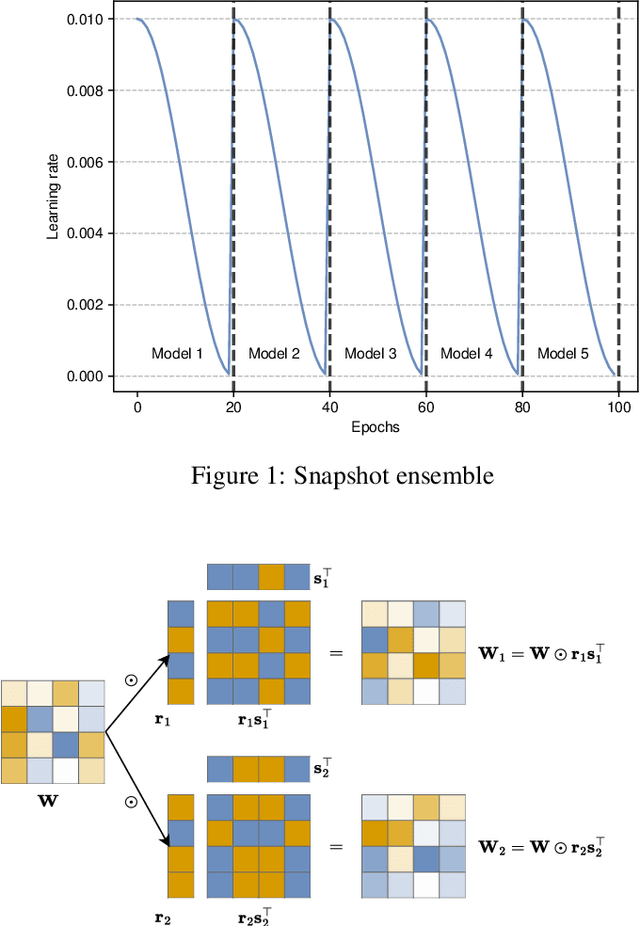
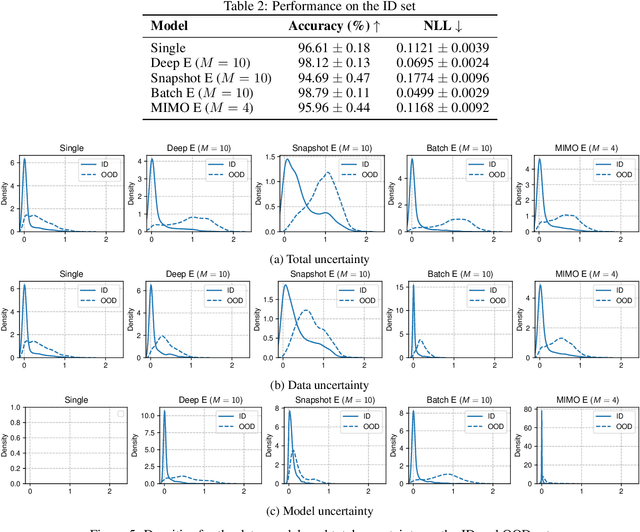
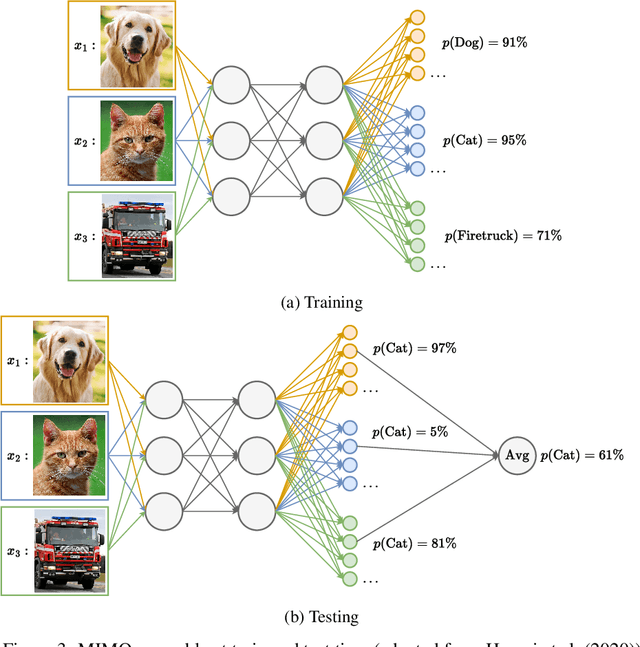
In operations research (OR), predictive models often encounter out-of-distribution (OOD) scenarios where the data distribution differs from the training data distribution. In recent years, neural networks (NNs) are gaining traction in OR for their exceptional performance in fields such as image classification. However, NNs tend to make confident yet incorrect predictions when confronted with OOD data. Uncertainty estimation offers a solution to overconfident models, communicating when the output should (not) be trusted. Hence, reliable uncertainty quantification in NNs is crucial in the OR domain. Deep ensembles, composed of multiple independent NNs, have emerged as a promising approach, offering not only strong predictive accuracy but also reliable uncertainty estimation. However, their deployment is challenging due to substantial computational demands. Recent fundamental research has proposed more efficient NN ensembles, namely the snapshot, batch, and multi-input multi-output ensemble. This study is the first to provide a comprehensive comparison of a single NN, a deep ensemble, and the three efficient NN ensembles. In addition, we propose a Diversity Quality metric to quantify the ensembles' performance on the in-distribution and OOD sets in one single metric. The OR case study discusses industrial parts classification to identify and manage spare parts, important for timely maintenance of industrial plants. The results highlight the batch ensemble as a cost-effective and competitive alternative to the deep ensemble. It outperforms the deep ensemble in both uncertainty and accuracy while exhibiting a training time speedup of 7x, a test time speedup of 8x, and 9x memory savings.
A Survey of IMU Based Cross-Modal Transfer Learning in Human Activity Recognition
Mar 17, 2024Despite living in a multi-sensory world, most AI models are limited to textual and visual understanding of human motion and behavior. In fact, full situational awareness of human motion could best be understood through a combination of sensors. In this survey we investigate how knowledge can be transferred and utilized amongst modalities for Human Activity/Action Recognition (HAR), i.e. cross-modality transfer learning. We motivate the importance and potential of IMU data and its applicability in cross-modality learning as well as the importance of studying the HAR problem. We categorize HAR related tasks by time and abstractness and then compare various types of multimodal HAR datasets. We also distinguish and expound on many related but inconsistently used terms in the literature, such as transfer learning, domain adaptation, representation learning, sensor fusion, and multimodal learning, and describe how cross-modal learning fits with all these concepts. We then review the literature in IMU-based cross-modal transfer for HAR. The two main approaches for cross-modal transfer are instance-based transfer, where instances of one modality are mapped to another (e.g. knowledge is transferred in the input space), or feature-based transfer, where the model relates the modalities in an intermediate latent space (e.g. knowledge is transferred in the feature space). Finally, we discuss future research directions and applications in cross-modal HAR.
Multi-Objective Evolutionary Neural Architecture Search for Recurrent Neural Networks
Mar 17, 2024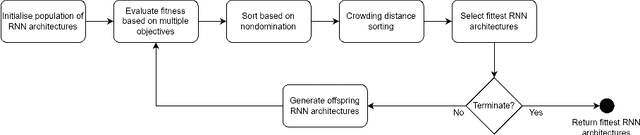
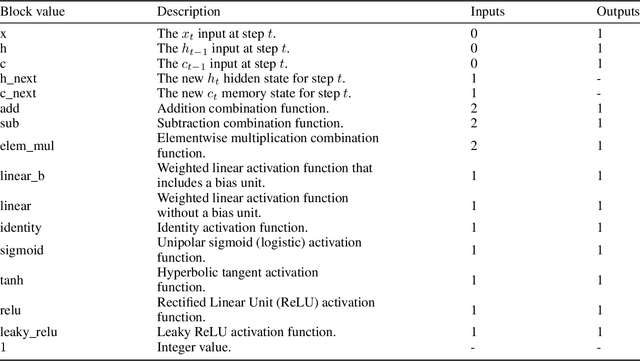
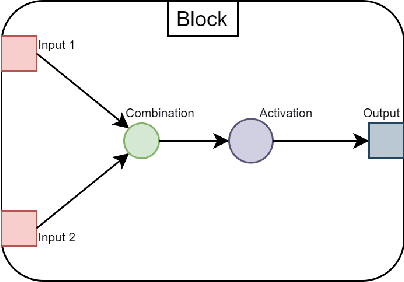
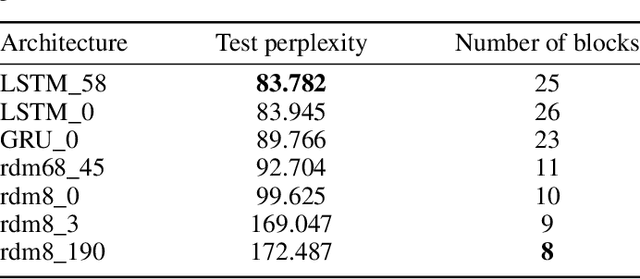
Artificial neural network (NN) architecture design is a nontrivial and time-consuming task that often requires a high level of human expertise. Neural architecture search (NAS) serves to automate the design of NN architectures and has proven to be successful in automatically finding NN architectures that outperform those manually designed by human experts. NN architecture performance can be quantified based on multiple objectives, which include model accuracy and some NN architecture complexity objectives, among others. The majority of modern NAS methods that consider multiple objectives for NN architecture performance evaluation are concerned with automated feed forward NN architecture design, which leaves multi-objective automated recurrent neural network (RNN) architecture design unexplored. RNNs are important for modeling sequential datasets, and prominent within the natural language processing domain. It is often the case in real world implementations of machine learning and NNs that a reasonable trade-off is accepted for marginally reduced model accuracy in favour of lower computational resources demanded by the model. This paper proposes a multi-objective evolutionary algorithm-based RNN architecture search method. The proposed method relies on approximate network morphisms for RNN architecture complexity optimisation during evolution. The results show that the proposed method is capable of finding novel RNN architectures with comparable performance to state-of-the-art manually designed RNN architectures, but with reduced computational demand.
Adaptive time series forecasting with markovian variance switching
Feb 22, 2024Adaptive time series forecasting is essential for prediction under regime changes. Several classical methods assume linear Gaussian state space model (LGSSM) with variances constant in time. However, there are many real-world processes that cannot be captured by such models. We consider a state-space model with Markov switching variances. Such dynamical systems are usually intractable because of their computational complexity increasing exponentially with time; Variational Bayes (VB) techniques have been applied to this problem. In this paper, we propose a new way of estimating variances based on online learning theory; we adapt expert aggregation methods to learn the variances over time. We apply the proposed method to synthetic data and to the problem of electricity load forecasting. We show that this method is robust to misspecification and outperforms traditional expert aggregation.
Resilient Fleet Management for Energy-Aware Intra-Factory Logistics
Mar 16, 2024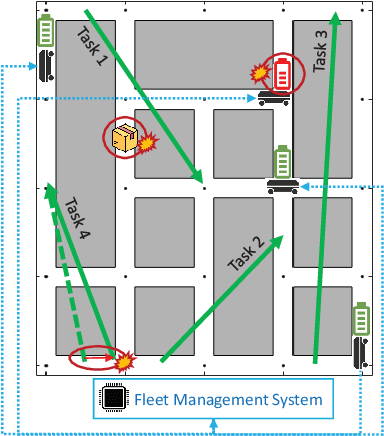
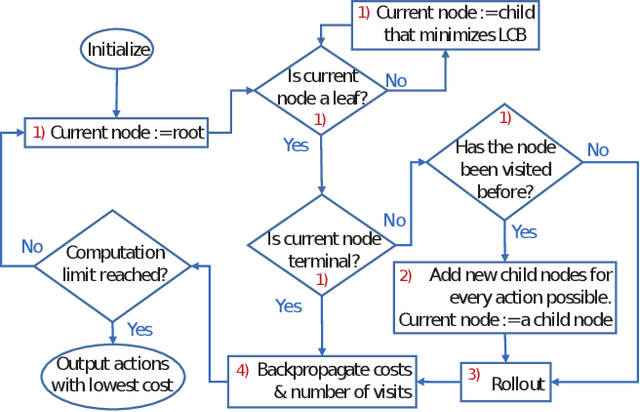
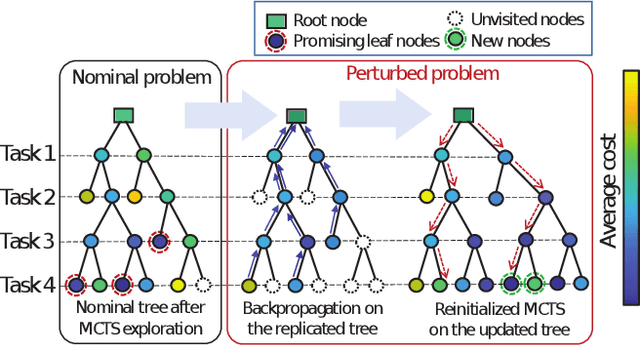
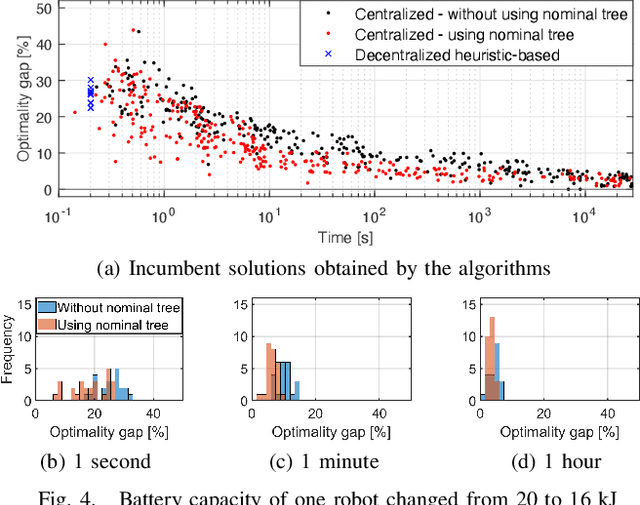
This paper presents a novel fleet management strategy for battery-powered robot fleets tasked with intra-factory logistics in an autonomous manufacturing facility. In this environment, repetitive material handling operations are subject to real-world uncertainties such as blocked passages, and equipment or robot malfunctions. In such cases, centralized approaches enhance resilience by immediately adjusting the task allocation between the robots. To overcome the computational expense, a two-step methodology is proposed where the nominal problem is solved a priori using a Monte Carlo Tree Search algorithm for task allocation, resulting in a nominal search tree. When a disruption occurs, the nominal search tree is rapidly updated a posteriori with costs to the new problem while simultaneously generating feasible solutions. Computational experiments prove the real-time capability of the proposed algorithm for various scenarios and compare it with the case where the search tree is not used and the decentralized approach that does not attempt task reassignment.
Pre-Trained Language Models Represent Some Geographic Populations Better Than Others
Mar 16, 2024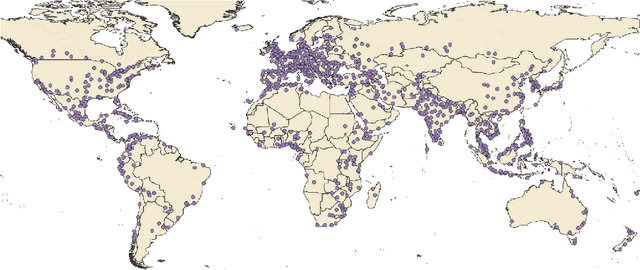
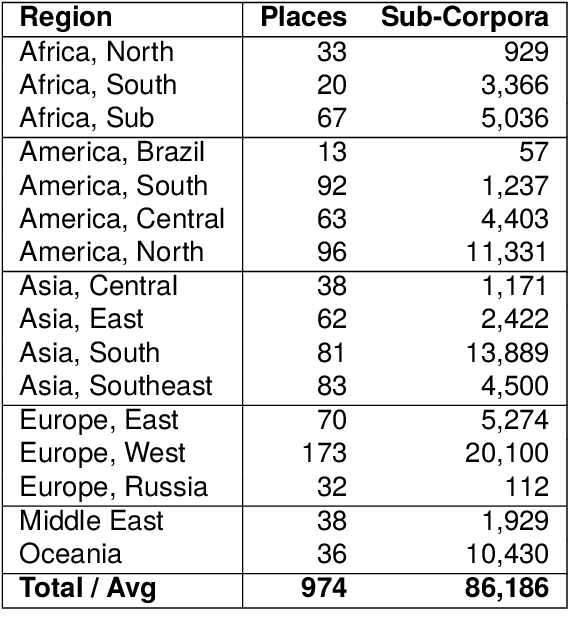
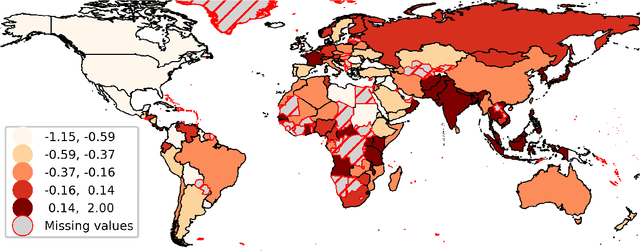
This paper measures the skew in how well two families of LLMs represent diverse geographic populations. A spatial probing task is used with geo-referenced corpora to measure the degree to which pre-trained language models from the OPT and BLOOM series represent diverse populations around the world. Results show that these models perform much better for some populations than others. In particular, populations across the US and the UK are represented quite well while those in South and Southeast Asia are poorly represented. Analysis shows that both families of models largely share the same skew across populations. At the same time, this skew cannot be fully explained by sociolinguistic factors, economic factors, or geographic factors. The basic conclusion from this analysis is that pre-trained models do not equally represent the world's population: there is a strong skew towards specific geographic populations. This finding challenges the idea that a single model can be used for all populations.