 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
LMPDNet: TOF-PET list-mode image reconstruction using model-based deep learning method
Feb 21, 2023
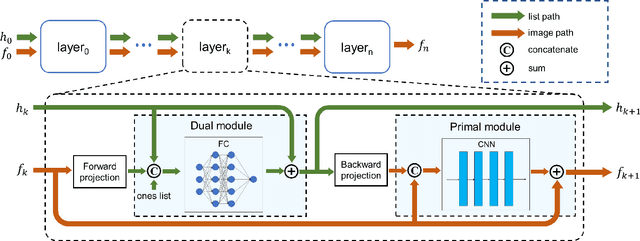
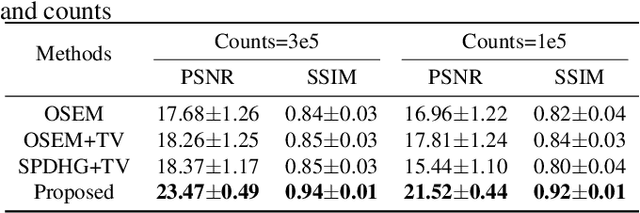
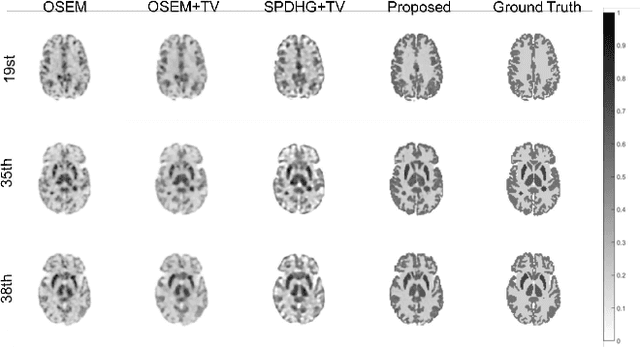
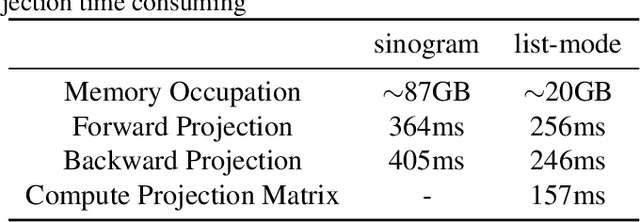
The integration of Time-of-Flight (TOF) information in the reconstruction process of Positron Emission Tomography (PET) yields improved image properties. However, implementing the cutting-edge model-based deep learning methods for TOF-PET reconstruction is challenging due to the substantial memory requirements. In this study, we present a novel model-based deep learning approach, LMPDNet, for TOF-PET reconstruction from list-mode data. We address the issue of real-time parallel computation of the projection matrix for list-mode data, and propose an iterative model-based module that utilizes a dedicated network model for list-mode data. Our experimental results indicate that the proposed LMPDNet outperforms traditional iteration-based TOF-PET list-mode reconstruction algorithms. Additionally, we compare the spatial and temporal consumption of list-mode data and sinogram data in model-based deep learning methods, demonstrating the superiority of list-mode data in model-based TOF-PET reconstruction.
Semiparametric Language Models Are Scalable Continual Learners
Mar 02, 2023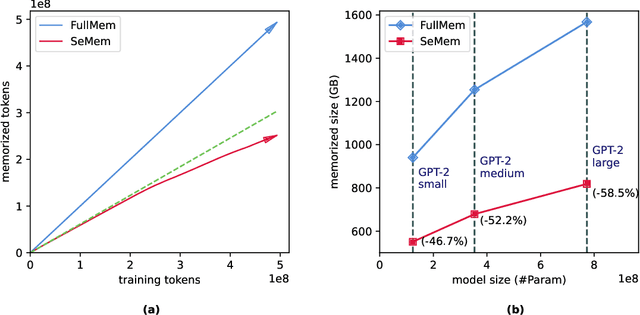

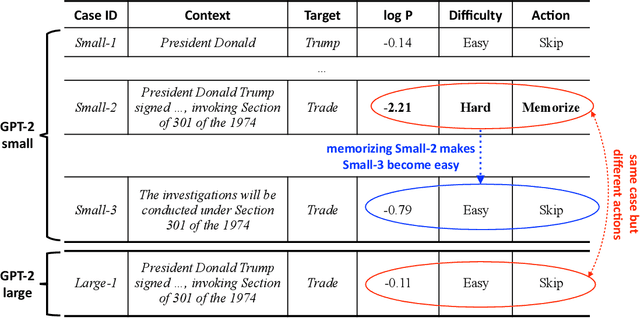

Semiparametric language models (LMs) have shown promise in continuously learning from new text data by combining a parameterized neural LM with a growable non-parametric memory for memorizing new content. However, conventional semiparametric LMs will finally become prohibitive for computing and storing if they are applied to continual learning over streaming data, because the non-parametric memory grows linearly with the amount of data they learn from over time. To address the issue of scalability, we present a simple and intuitive approach called Selective Memorization (SeMem), which only memorizes difficult samples that the model is likely to struggle with. We demonstrate that SeMem improves the scalability of semiparametric LMs for continual learning over streaming data in two ways: (1) data-wise scalability: as the model becomes stronger through continual learning, it will encounter fewer difficult cases that need to be memorized, causing the growth of the non-parametric memory to slow down over time rather than growing at a linear rate with the size of training data; (2) model-wise scalability: SeMem allows a larger model to memorize fewer samples than its smaller counterpart because it is rarer for a larger model to encounter incomprehensible cases, resulting in a non-parametric memory that does not scale linearly with model size. We conduct extensive experiments in language modeling and downstream tasks to test SeMem's results, showing SeMem enables a semiparametric LM to be a scalable continual learner with little forgetting.
Expert-Free Online Transfer Learning in Multi-Agent Reinforcement Learning
Mar 02, 2023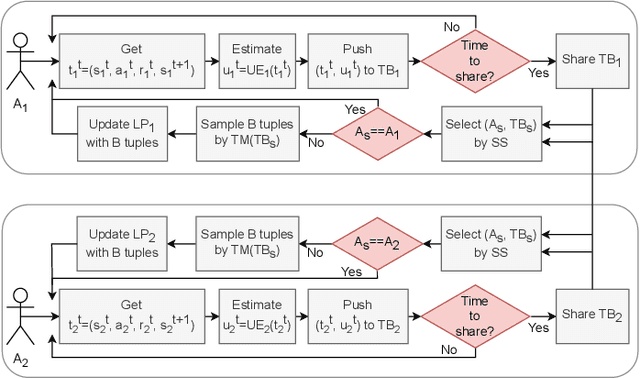
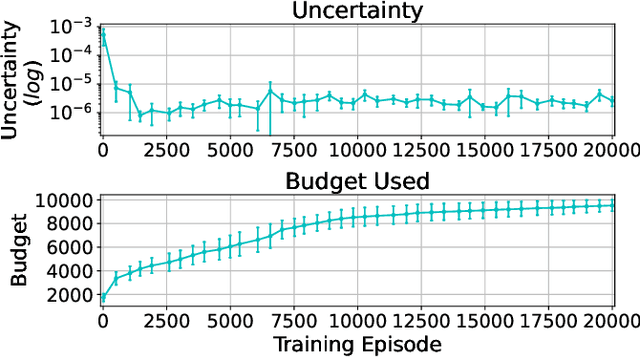
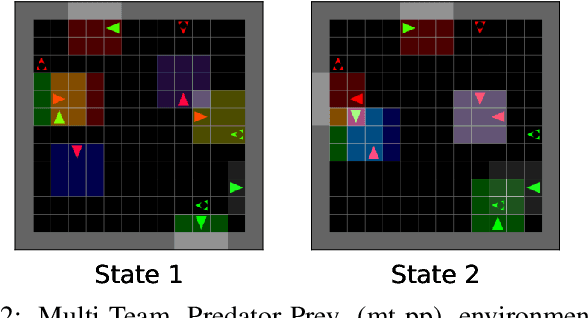
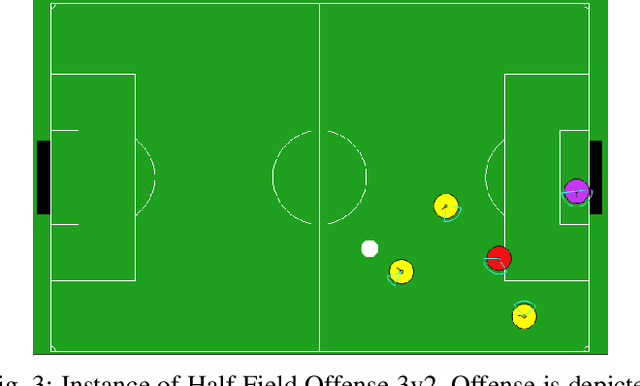
Transfer learning in Reinforcement Learning (RL) has been widely studied to overcome training issues of Deep-RL, i.e., exploration cost, data availability and convergence time, by introducing a way to enhance training phase with external knowledge. Generally, knowledge is transferred from expert-agents to novices. While this fixes the issue for a novice agent, a good understanding of the task on expert agent is required for such transfer to be effective. As an alternative, in this paper we propose Expert-Free Online Transfer Learning (EF-OnTL), an algorithm that enables expert-free real-time dynamic transfer learning in multi-agent system. No dedicated expert exists, and transfer source agent and knowledge to be transferred are dynamically selected at each transfer step based on agents' performance and uncertainty. To improve uncertainty estimation, we also propose State Action Reward Next-State Random Network Distillation (sars-RND), an extension of RND that estimates uncertainty from RL agent-environment interaction. We demonstrate EF-OnTL effectiveness against a no-transfer scenario and advice-based baselines, with and without expert agents, in three benchmark tasks: Cart-Pole, a grid-based Multi-Team Predator-Prey (mt-pp) and Half Field Offense (HFO). Our results show that EF-OnTL achieve overall comparable performance when compared against advice-based baselines while not requiring any external input nor threshold tuning. EF-OnTL outperforms no-transfer with an improvement related to the complexity of the task addressed.
Physical Adversarial Attacks on Deep Neural Networks for Traffic Sign Recognition: A Feasibility Study
Feb 27, 2023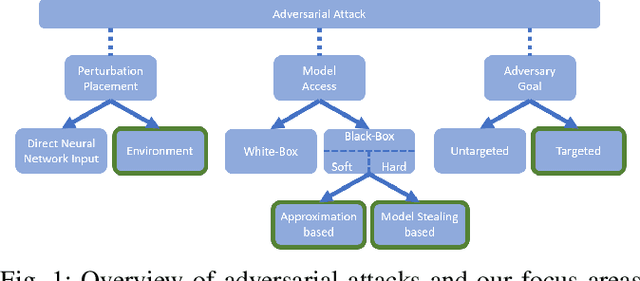
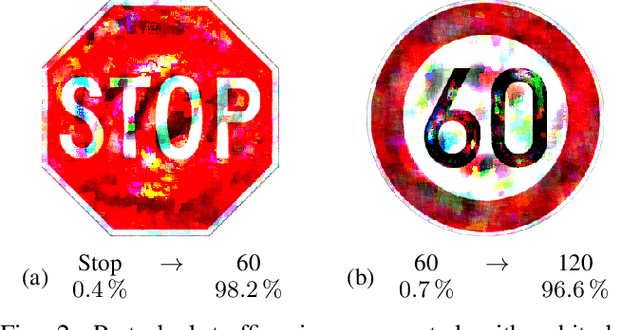

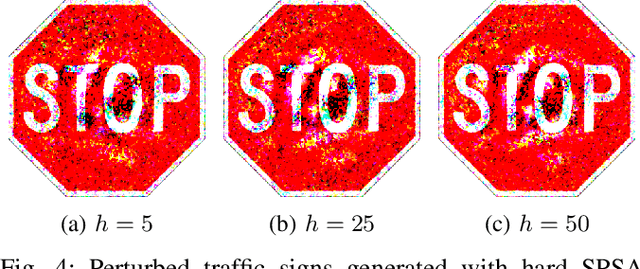
Deep Neural Networks (DNNs) are increasingly applied in the real world in safety critical applications like advanced driver assistance systems. An example for such use case is represented by traffic sign recognition systems. At the same time, it is known that current DNNs can be fooled by adversarial attacks, which raises safety concerns if those attacks can be applied under realistic conditions. In this work we apply different black-box attack methods to generate perturbations that are applied in the physical environment and can be used to fool systems under different environmental conditions. To the best of our knowledge we are the first to combine a general framework for physical attacks with different black-box attack methods and study the impact of the different methods on the success rate of the attack under the same setting. We show that reliable physical adversarial attacks can be performed with different methods and that it is also possible to reduce the perceptibility of the resulting perturbations. The findings highlight the need for viable defenses of a DNN even in the black-box case, but at the same time form the basis for securing a DNN with methods like adversarial training which utilizes adversarial attacks to augment the original training data.
Convolutional Neural Networks as 2-D systems
Mar 06, 2023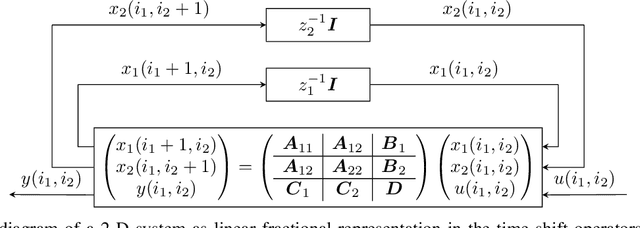
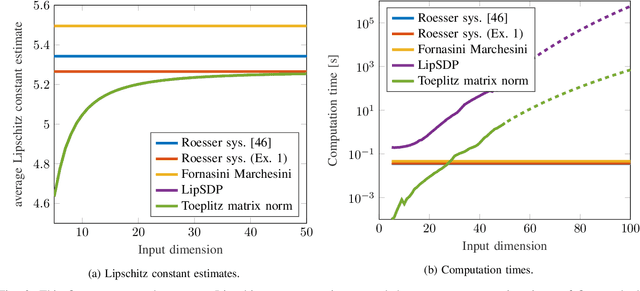
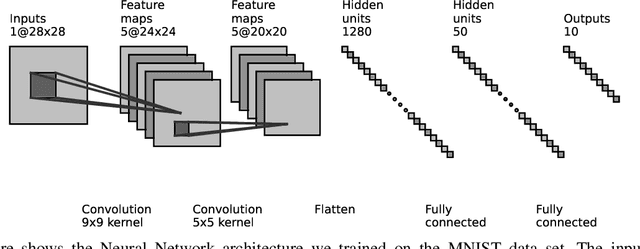
This paper introduces a novel representation of convolutional Neural Networks (CNNs) in terms of 2-D dynamical systems. To this end, the usual description of convolutional layers with convolution kernels, i.e., the impulse responses of linear filters, is realized in state space as a linear time-invariant 2-D system. The overall convolutional Neural Network composed of convolutional layers and nonlinear activation functions is then viewed as a 2-D version of a Lur'e system, i.e., a linear dynamical system interconnected with static nonlinear components. One benefit of this 2-D Lur'e system perspective on CNNs is that we can use robust control theory much more efficiently for Lipschitz constant estimation than previously possible.
Automated Graph Genetic Algorithm based Puzzle Validation for Faster Game Desig
Feb 17, 2023
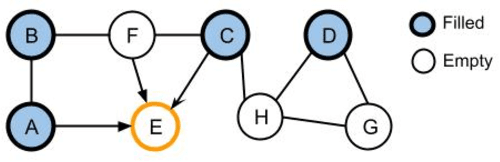
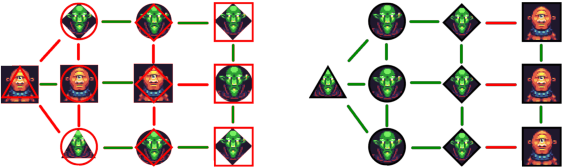
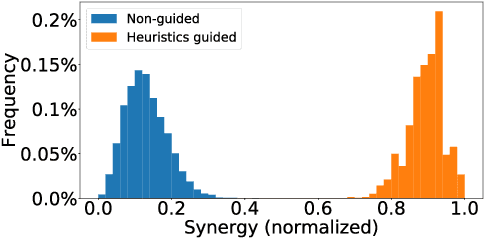
Many games are reliant on creating new and engaging content constantly to maintain the interest of their player-base. One such example are puzzle games, in such it is common to have a recurrent need to create new puzzles. Creating new puzzles requires guaranteeing that they are solvable and interesting to players, both of which require significant time from the designers. Automatic validation of puzzles provides designers with a significant time saving and potential boost in quality. Automation allows puzzle designers to estimate different properties, increase the variety of constraints, and even personalize puzzles to specific players. Puzzles often have a large design space, which renders exhaustive search approaches infeasible, if they require significant time. Specifically, those puzzles can be formulated as quadratic combinatorial optimization problems. This paper presents an evolutionary algorithm, empowered by expert-knowledge informed heuristics, for solving logical puzzles in video games efficiently, leading to a more efficient design process. We discuss multiple variations of hybrid genetic approaches for constraint satisfaction problems that allow us to find a diverse set of near-optimal solutions for puzzles. We demonstrate our approach on a fantasy Party Building Puzzle game, and discuss how it can be applied more broadly to other puzzles to guide designers in their creative process.
SuperTran: Reference Based Video Transformer for Enhancing Low Bitrate Streams in Real Time
Nov 22, 2022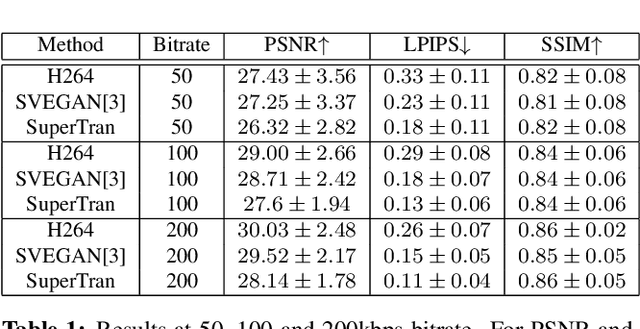
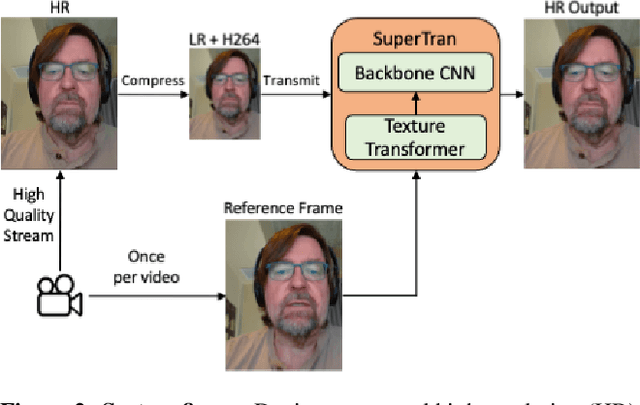
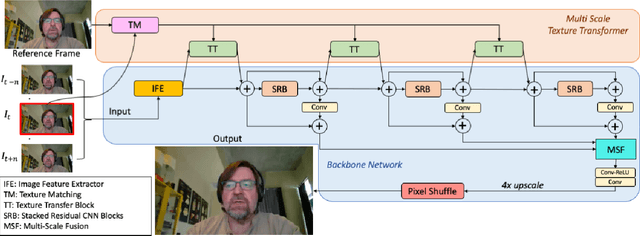
This work focuses on low bitrate video streaming scenarios (e.g. 50 - 200Kbps) where the video quality is severely compromised. We present a family of novel deep generative models for enhancing perceptual video quality of such streams by performing super-resolution while also removing compression artifacts. Our model, which we call SuperTran, consumes as input a single high-quality, high-resolution reference images in addition to the low-quality, low-resolution video stream. The model thus learns how to borrow or copy visual elements like textures from the reference image and fill in the remaining details from the low resolution stream in order to produce perceptually enhanced output video. The reference frame can be sent once at the start of the video session or be retrieved from a gallery. Importantly, the resulting output has substantially better detail than what has been otherwise possible with methods that only use a low resolution input such as the SuperVEGAN method. SuperTran works in real-time (up to 30 frames/sec) on the cloud alongside standard pipelines.
Bridging the Gap between ANNs and SNNs by Calibrating Offset Spikes
Feb 21, 2023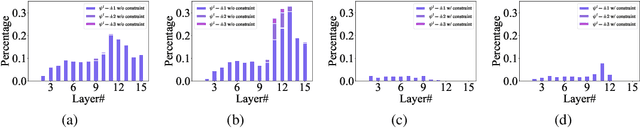
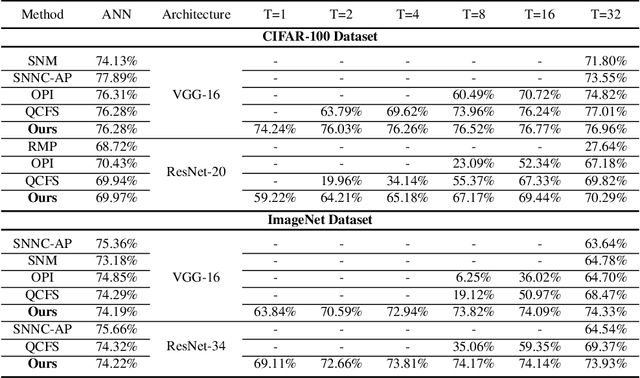

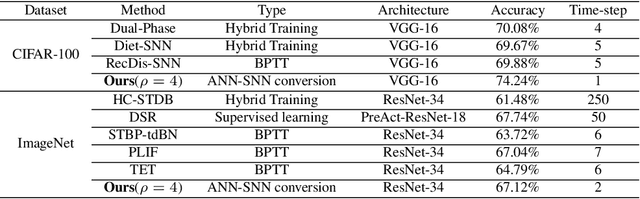
Spiking Neural Networks (SNNs) have attracted great attention due to their distinctive characteristics of low power consumption and temporal information processing. ANN-SNN conversion, as the most commonly used training method for applying SNNs, can ensure that converted SNNs achieve comparable performance to ANNs on large-scale datasets. However, the performance degrades severely under low quantities of time-steps, which hampers the practical applications of SNNs to neuromorphic chips. In this paper, instead of evaluating different conversion errors and then eliminating these errors, we define an offset spike to measure the degree of deviation between actual and desired SNN firing rates. We perform a detailed analysis of offset spike and note that the firing of one additional (or one less) spike is the main cause of conversion errors. Based on this, we propose an optimization strategy based on shifting the initial membrane potential and we theoretically prove the corresponding optimal shifting distance for calibrating the spike. In addition, we also note that our method has a unique iterative property that enables further reduction of conversion errors. The experimental results show that our proposed method achieves state-of-the-art performance on CIFAR-10, CIFAR-100, and ImageNet datasets. For example, we reach a top-1 accuracy of 67.12% on ImageNet when using 6 time-steps. To the best of our knowledge, this is the first time an ANN-SNN conversion has been shown to simultaneously achieve high accuracy and ultralow latency on complex datasets. Code is available at https://github.com/hzc1208/ANN2SNN_COS.
Super-Resolution Information Enhancement For Crowd Counting
Mar 13, 2023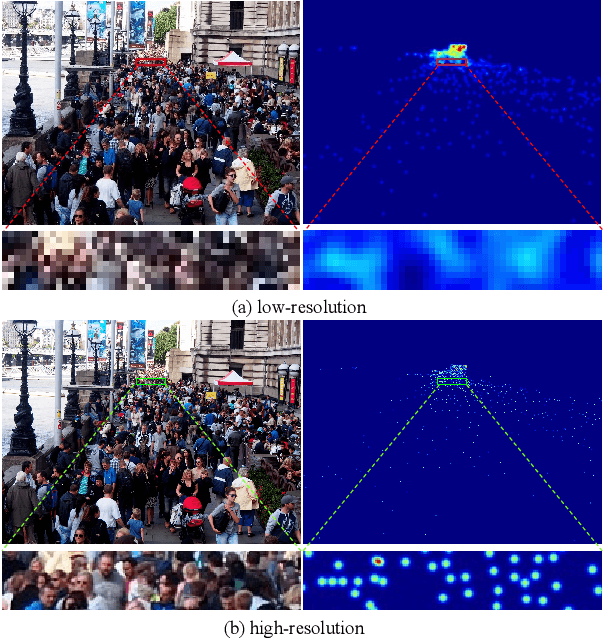
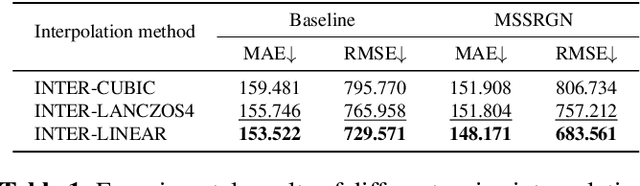
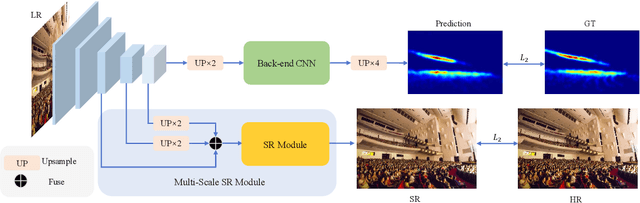
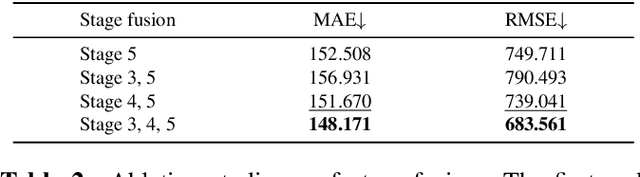
Crowd counting is a challenging task due to the heavy occlusions, scales, and density variations. Existing methods handle these challenges effectively while ignoring low-resolution (LR) circumstances. The LR circumstances weaken the counting performance deeply for two crucial reasons: 1) limited detail information; 2) overlapping head regions accumulate in density maps and result in extreme ground-truth values. An intuitive solution is to employ super-resolution (SR) pre-processes for the input LR images. However, it complicates the inference steps and thus limits application potentials when requiring real-time. We propose a more elegant method termed Multi-Scale Super-Resolution Module (MSSRM). It guides the network to estimate the lost de tails and enhances the detailed information in the feature space. Noteworthy that the MSSRM is plug-in plug-out and deals with the LR problems with no inference cost. As the proposed method requires SR labels, we further propose a Super-Resolution Crowd Counting dataset (SR-Crowd). Extensive experiments on three datasets demonstrate the superiority of our method. The code will be available at https://github.com/PRIS-CV/MSSRM.git.
Erasing Concepts from Diffusion Models
Mar 13, 2023
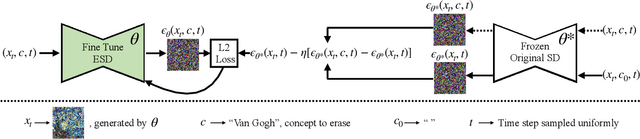
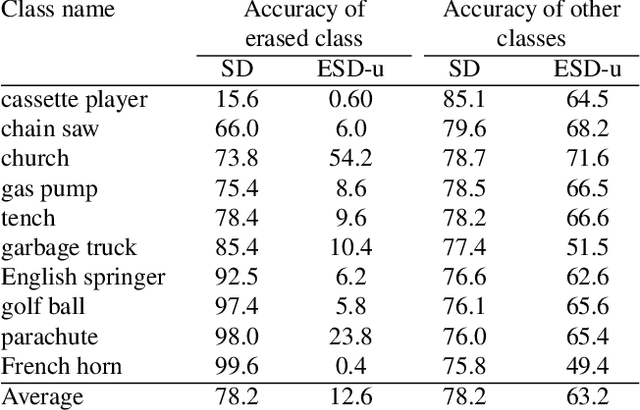

Motivated by recent advancements in text-to-image diffusion, we study erasure of specific concepts from the model's weights. While Stable Diffusion has shown promise in producing explicit or realistic artwork, it has raised concerns regarding its potential for misuse. We propose a fine-tuning method that can erase a visual concept from a pre-trained diffusion model, given only the name of the style and using negative guidance as a teacher. We benchmark our method against previous approaches that remove sexually explicit content and demonstrate its effectiveness, performing on par with Safe Latent Diffusion and censored training. To evaluate artistic style removal, we conduct experiments erasing five modern artists from the network and conduct a user study to assess the human perception of the removed styles. Unlike previous methods, our approach can remove concepts from a diffusion model permanently rather than modifying the output at the inference time, so it cannot be circumvented even if a user has access to model weights. Our code, data, and results are available at https://erasing.baulab.info/