 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Incorporating Human Path Preferences in Robot Navigation with Minimal Interventions
Mar 06, 2023
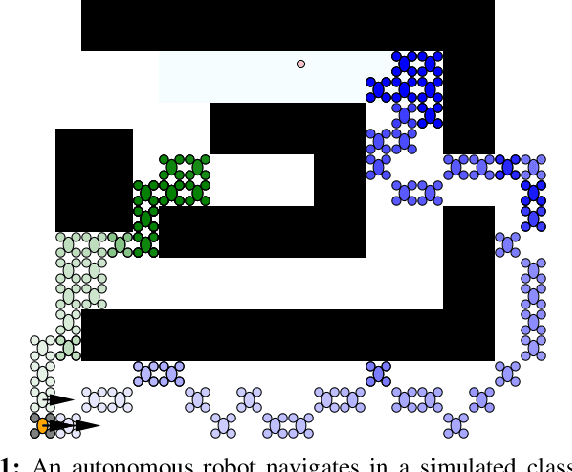
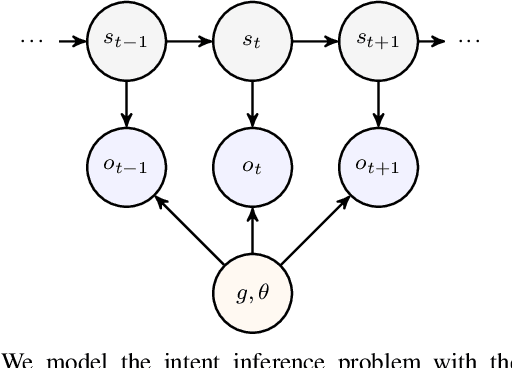
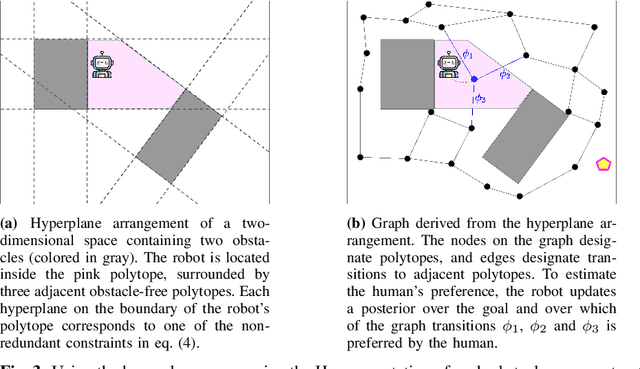
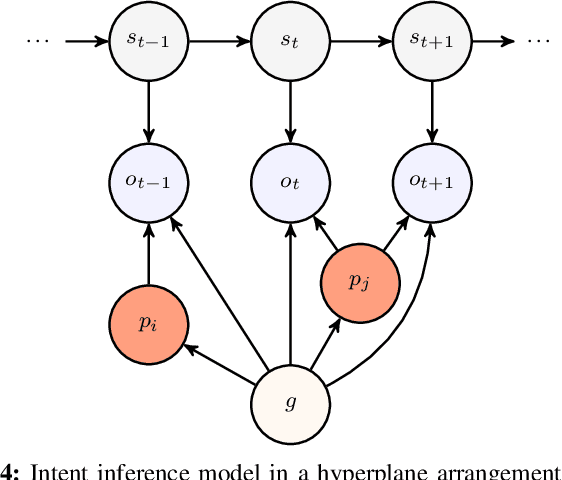
Robots that can effectively understand human intentions from actions are crucial for successful human-robot collaboration. In this work, we address the challenge of a robot navigating towards an unknown goal while also accounting for a human's preference for a particular path in the presence of obstacles. This problem is particularly challenging when both the goal and path preference are unknown a priori. To overcome this challenge, we propose a method for encoding and inferring path preference online using a partitioning of the space into polytopes. Our approach enables joint inference over the goal and path preference using a stochastic observation model for the human. We evaluate our method on an unknown-goal navigation problem with sparse human interventions, and find that it outperforms baseline approaches as the human's inputs become increasingly sparse. We find that the time required to update the robot's belief does not increase with the complexity of the environment, which makes our method suitable for online applications.
Automated Ventricle Parcellation and Evan's Ratio Computation in Pre- and Post-Surgical Ventriculomegaly
Mar 06, 2023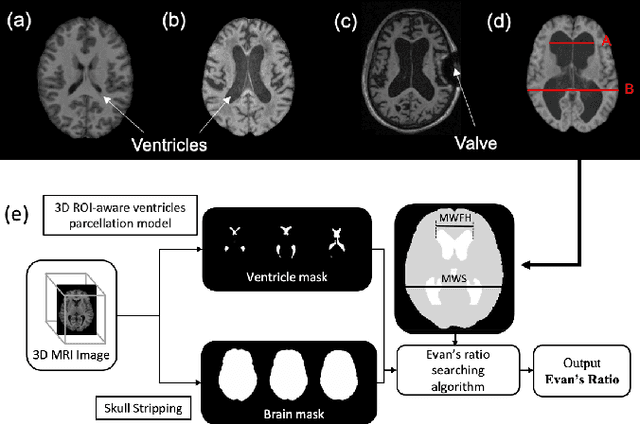
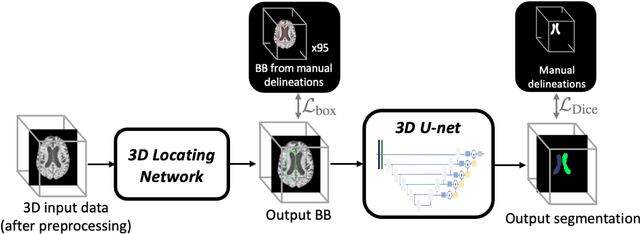
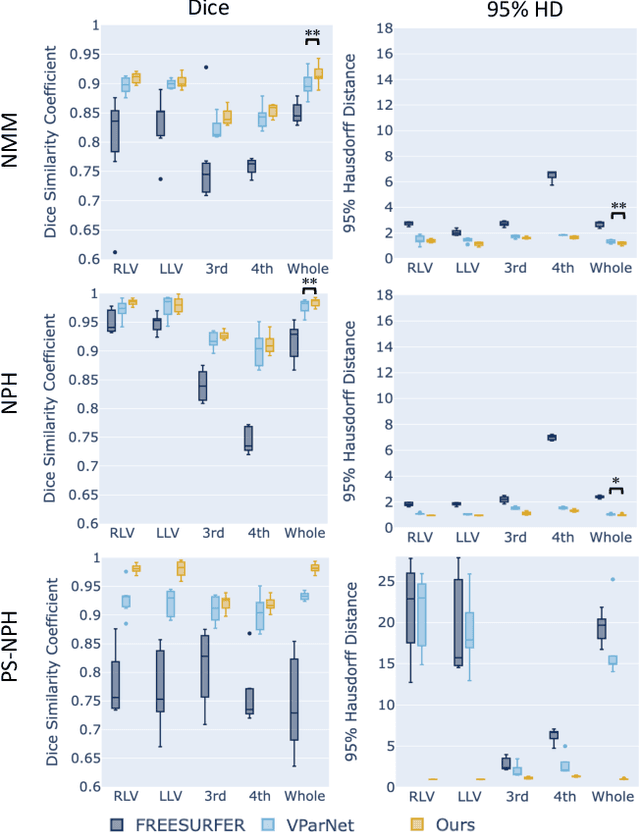
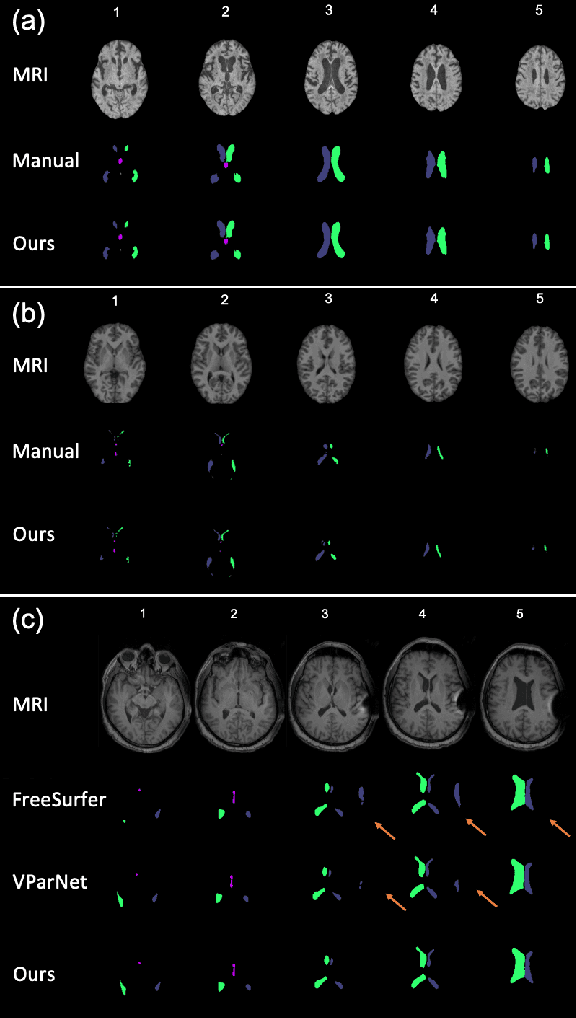
Normal pressure hydrocephalus~(NPH) is a brain disorder associated with enlarged ventricles and multiple cognitive and motor symptoms. The degree of ventricular enlargement can be measured using magnetic resonance images~(MRIs) and characterized quantitatively using the Evan's ratio (ER). Automatic computation of ER is desired to avoid the extra time and variations associated with manual measurements on MRI. Because shunt surgery is often used to treat NPH, it is necessary that this process be robust to image artifacts caused by the shunt and related implants. In this paper, we propose a 3D regions-of-interest aware (ROI-aware) network for segmenting the ventricles. The method achieves state-of-the-art performance on both pre-surgery MRIs and post-surgery MRIs with artifacts. Based on our segmentation results, we also describe an automated approach to compute ER from these results. Experimental results on multiple datasets demonstrate the potential of the proposed method to assist clinicians in the diagnosis and management of NPH.
Efficiently Training Vision Transformers on Structural MRI Scans for Alzheimer's Disease Detection
Mar 14, 2023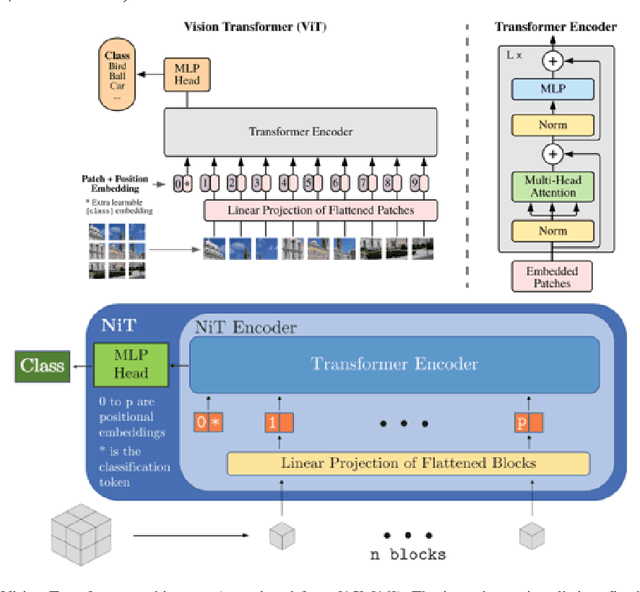
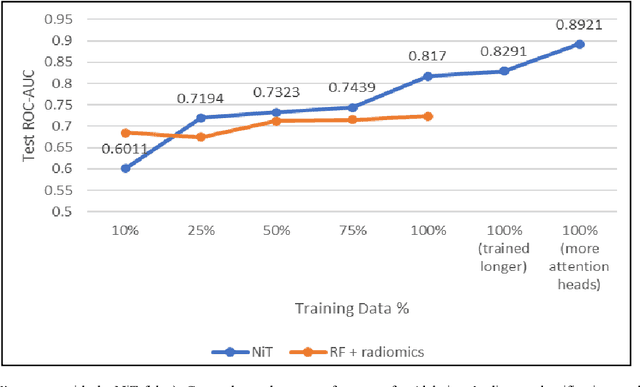
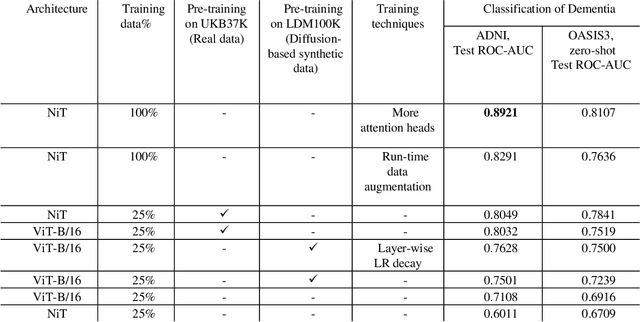
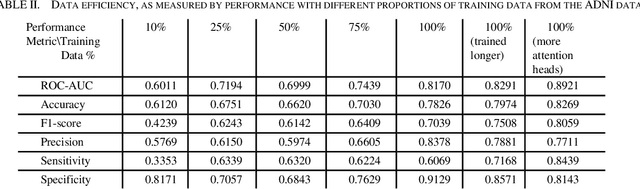
Neuroimaging of large populations is valuable to identify factors that promote or resist brain disease, and to assist diagnosis, subtyping, and prognosis. Data-driven models such as convolutional neural networks (CNNs) have increasingly been applied to brain images to perform diagnostic and prognostic tasks by learning robust features. Vision transformers (ViT) - a new class of deep learning architectures - have emerged in recent years as an alternative to CNNs for several computer vision applications. Here we tested variants of the ViT architecture for a range of desired neuroimaging downstream tasks based on difficulty, in this case for sex and Alzheimer's disease (AD) classification based on 3D brain MRI. In our experiments, two vision transformer architecture variants achieved an AUC of 0.987 for sex and 0.892 for AD classification, respectively. We independently evaluated our models on data from two benchmark AD datasets. We achieved a performance boost of 5% and 9-10% upon fine-tuning vision transformer models pre-trained on synthetic (generated by a latent diffusion model) and real MRI scans, respectively. Our main contributions include testing the effects of different ViT training strategies including pre-training, data augmentation and learning rate warm-ups followed by annealing, as pertaining to the neuroimaging domain. These techniques are essential for training ViT-like models for neuroimaging applications where training data is usually limited. We also analyzed the effect of the amount of training data utilized on the test-time performance of the ViT via data-model scaling curves.
Object Detection During Newborn Resuscitation Activities
Mar 14, 2023
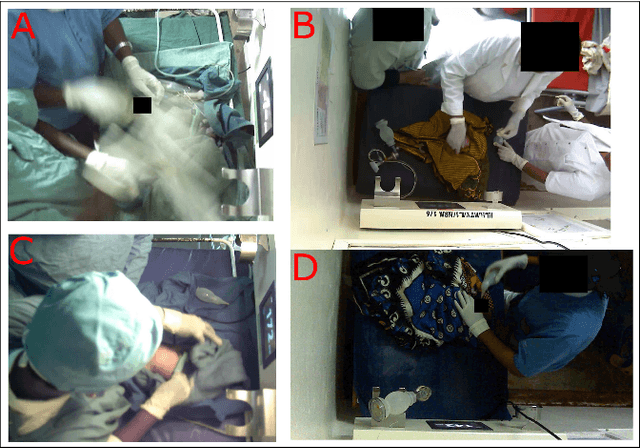
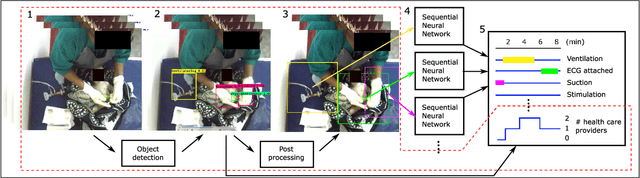
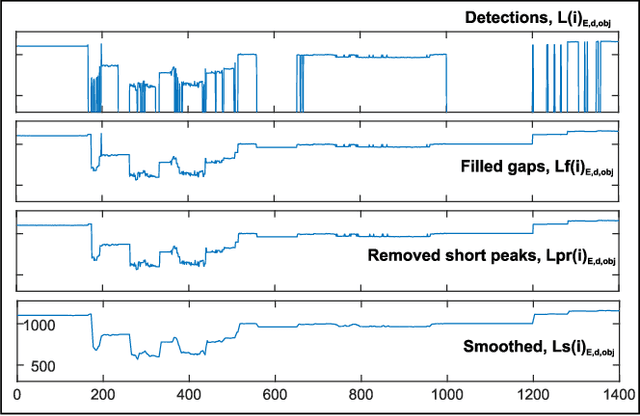
Birth asphyxia is a major newborn mortality problem in low-resource countries. International guideline provides treatment recommendations; however, the importance and effect of the different treatments are not fully explored. The available data is collected in Tanzania, during newborn resuscitation, for analysis of the resuscitation activities and the response of the newborn. An important step in the analysis is to create activity timelines of the episodes, where activities include ventilation, suction, stimulation etc. Methods: The available recordings are noisy real-world videos with large variations. We propose a two-step process in order to detect activities possibly overlapping in time. The first step is to detect and track the relevant objects, like bag-mask resuscitator, heart rate sensors etc., and the second step is to use this information to recognize the resuscitation activities. The topic of this paper is the first step, and the object detection and tracking are based on convolutional neural networks followed by post processing. Results: The performance of the object detection during activities were 96.97 % (ventilations), 100 % (attaching/removing heart rate sensor) and 75 % (suction) on a test set of 20 videos. The system also estimate the number of health care providers present with a performance of 71.16 %. Conclusion: The proposed object detection and tracking system provides promising results in noisy newborn resuscitation videos. Significance: This is the first step in a thorough analysis of newborn resuscitation episodes, which could provide important insight about the importance and effect of different newborn resuscitation activities
* 8 pages
Calibrated Teacher for Sparsely Annotated Object Detection
Mar 14, 2023
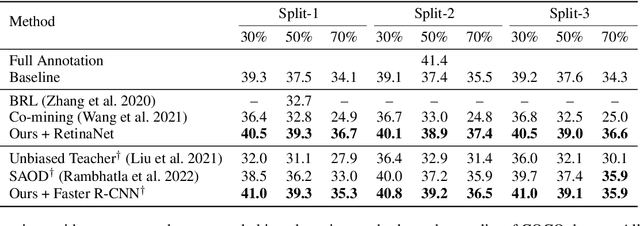
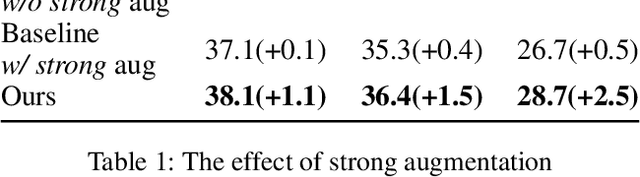
Fully supervised object detection requires training images in which all instances are annotated. This is actually impractical due to the high labor and time costs and the unavoidable missing annotations. As a result, the incomplete annotation in each image could provide misleading supervision and harm the training. Recent works on sparsely annotated object detection alleviate this problem by generating pseudo labels for the missing annotations. Such a mechanism is sensitive to the threshold of the pseudo label score. However, the effective threshold is different in different training stages and among different object detectors. Therefore, the current methods with fixed thresholds have sub-optimal performance, and are difficult to be applied to other detectors. In order to resolve this obstacle, we propose a Calibrated Teacher, of which the confidence estimation of the prediction is well calibrated to match its real precision. In this way, different detectors in different training stages would share a similar distribution of the output confidence, so that multiple detectors could share the same fixed threshold and achieve better performance. Furthermore, we present a simple but effective Focal IoU Weight (FIoU) for the classification loss. FIoU aims at reducing the loss weight of false negative samples caused by the missing annotation, and thus works as the complement of the teacher-student paradigm. Extensive experiments show that our methods set new state-of-the-art under all different sparse settings in COCO. Code will be available at https://github.com/Whileherham/CalibratedTeacher.
OVRL-V2: A simple state-of-art baseline for ImageNav and ObjectNav
Mar 14, 2023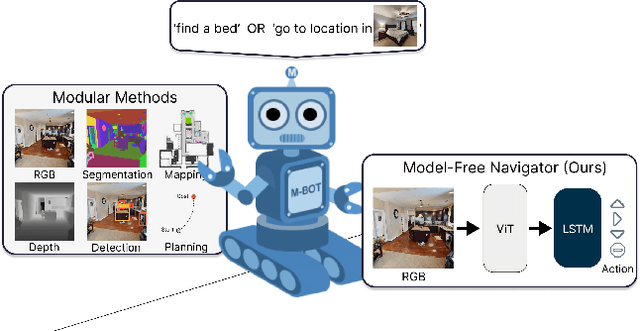



We present a single neural network architecture composed of task-agnostic components (ViTs, convolutions, and LSTMs) that achieves state-of-art results on both the ImageNav ("go to location in <this picture>") and ObjectNav ("find a chair") tasks without any task-specific modules like object detection, segmentation, mapping, or planning modules. Such general-purpose methods offer advantages of simplicity in design, positive scaling with available compute, and versatile applicability to multiple tasks. Our work builds upon the recent success of self-supervised learning (SSL) for pre-training vision transformers (ViT). However, while the training recipes for convolutional networks are mature and robust, the recipes for ViTs are contingent and brittle, and in the case of ViTs for visual navigation, yet to be fully discovered. Specifically, we find that vanilla ViTs do not outperform ResNets on visual navigation. We propose the use of a compression layer operating over ViT patch representations to preserve spatial information along with policy training improvements. These improvements allow us to demonstrate positive scaling laws for the first time in visual navigation tasks. Consequently, our model advances state-of-the-art performance on ImageNav from 54.2% to 82.0% success and performs competitively against concurrent state-of-art on ObjectNav with success rate of 64.0% vs. 65.0%. Overall, this work does not present a fundamentally new approach, but rather recommendations for training a general-purpose architecture that achieves state-of-art performance today and could serve as a strong baseline for future methods.
Automatic summarisation of Instagram social network posts Combining semantic and statistical approaches
Mar 14, 2023
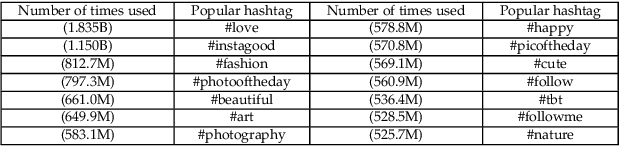
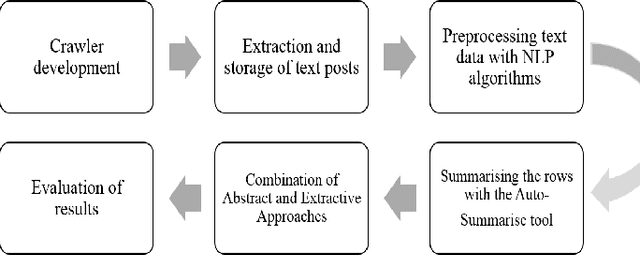
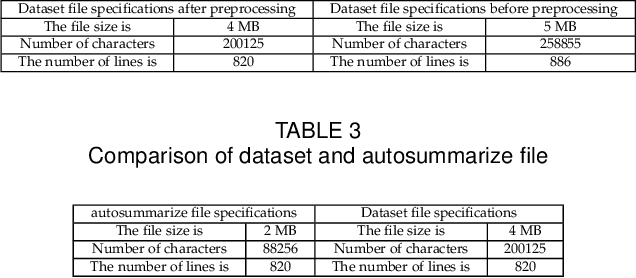
The proliferation of data and text documents such as articles, web pages, books, social network posts, etc. on the Internet has created a fundamental challenge in various fields of text processing under the title of "automatic text summarisation". Manual processing and summarisation of large volumes of textual data is a very difficult, expensive, time-consuming and impossible process for human users. Text summarisation systems are divided into extractive and abstract categories. In the extractive summarisation method, the final summary of a text document is extracted from the important sentences of the same document without any modification. In this method, it is possible to repeat a series of sentences and to interfere with pronouns. However, in the abstract summarisation method, the final summary of a textual document is extracted from the meaning and significance of the sentences and words of the same document or other documents. Many of the works carried out have used extraction methods or abstracts to summarise the collection of web documents, each of which has advantages and disadvantages in the results obtained in terms of similarity or size. In this work, a crawler has been developed to extract popular text posts from the Instagram social network with appropriate preprocessing, and a set of extraction and abstraction algorithms have been combined to show how each of the abstraction algorithms can be used. Observations made on 820 popular text posts on the social network Instagram show the accuracy (80%) of the proposed system.
Symbolic Synthesis of Neural Networks
Mar 14, 2023
Neural networks adapt very well to distributed and continuous representations, but struggle to generalize from small amounts of data. Symbolic systems commonly achieve data efficient generalization by exploiting modularity to benefit from local and discrete features of a representation. These features allow symbolic programs to be improved one module at a time and to experience combinatorial growth in the values they can successfully process. However, it is difficult to design a component that can be used to form symbolic abstractions and which is adequately overparametrized to learn arbitrary high-dimensional transformations. I present Graph-based Symbolically Synthesized Neural Networks (G-SSNNs), a class of neural modules that operate on representations modified with synthesized symbolic programs to include a fixed set of local and discrete features. I demonstrate that the choice of injected features within a G-SSNN module modulates the data efficiency and generalization of baseline neural models, creating predictable patterns of both heightened and curtailed generalization. By training G-SSNNs, we also derive information about desirable semantics of symbolic programs without manual engineering. This information is compact and amenable to abstraction, but can also be flexibly recontextualized for other high-dimensional settings. In future work, I will investigate data efficient generalization and the transferability of learned symbolic representations in more complex G-SSNN designs based on more complex classes of symbolic programs. Experimental code and data are available at https://github.com/shlomenu/symbolically_synthesized_networks .
Doppler-Resilient Universal Filtered MultiCarrier (DR-UFMC): A Beyond-OTFS Modulation
Feb 18, 2023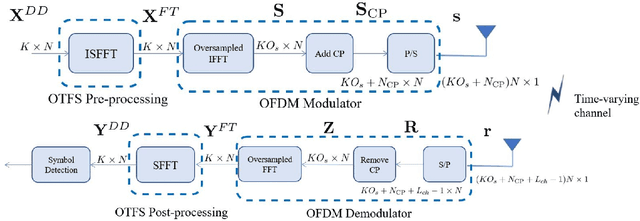
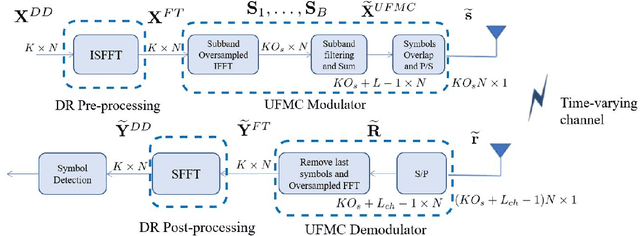
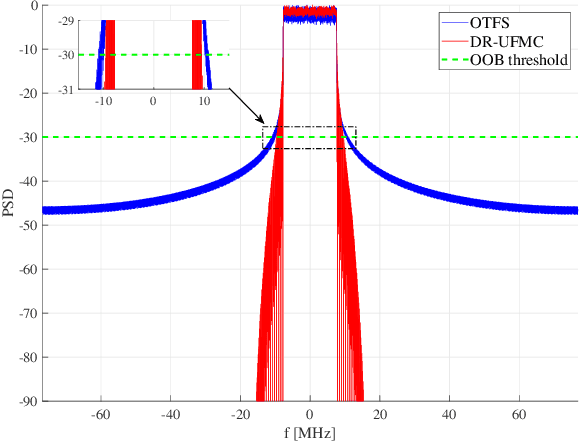
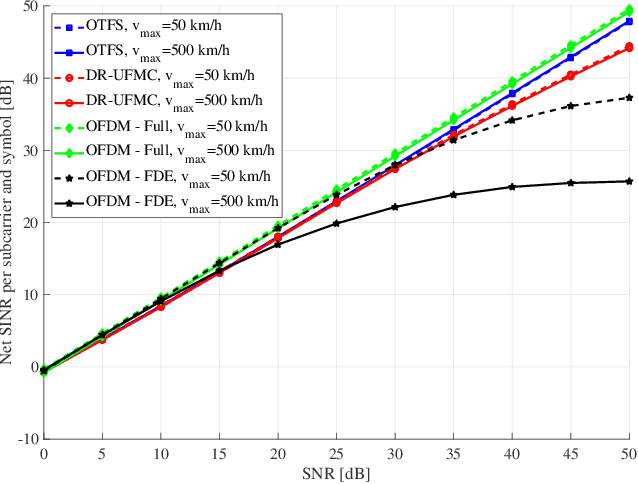
In the past few years, some alternatives to the Orthogonal Frequency Division Multiplexing (OFDM) modulation have been considered to improve its spectral containment and its performance level in the presence of heavy Doppler shifts. This paper examines a novel modulation, named Doppler-Resilient Universal Filtered MultiCarrier (DR-UFMC), which has the objective of combining the advantages provided by the Universal Filtered MultiCarrier (UFMC) modulation (i.e., better spectral containment), with those of the Orthogonal Time Frequency Space (OTFS) modulation (i.e., better performance in time-varying environments). The paper contains the mathematical model and detailed transceiver block scheme of the newly described modulation, along with a numerical analysis contrasting DR-UFMC against OTFS, OFDM with one-tap frequency domain equalization (FDE), and OFDM with multicarrier multisymbol linear MMSE processing. Results clearly show the superiority, with respect to the cited benchmarks, of the newly proposed modulation in terms of achievable spectral efficiency. Interestingly, it is also seen that OFDM, when considered in conjunction with multicarrier multisymbol linear minimum mean squares error (MMSE) processing, performs slightly better than OTFS in terms of achievable spectral efficiency.
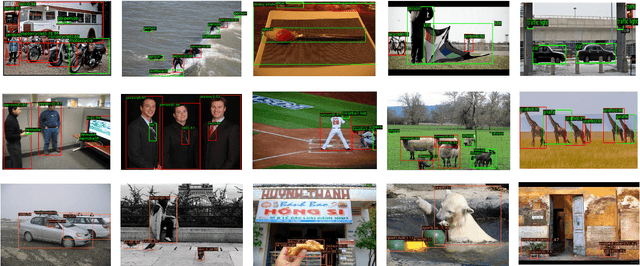
Memory-aided Contrastive Consensus Learning for Co-salient Object Detection
Mar 11, 2023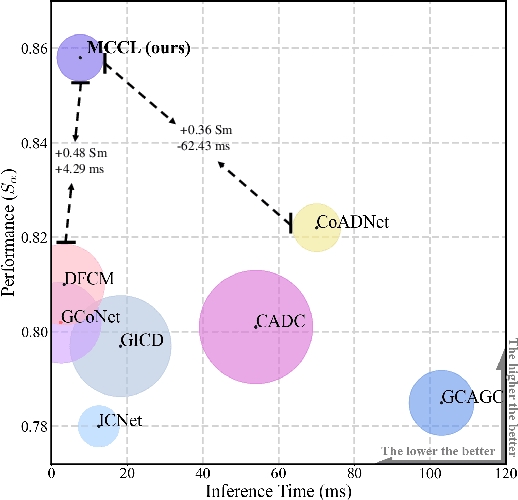
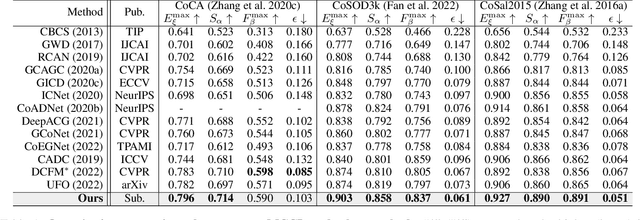
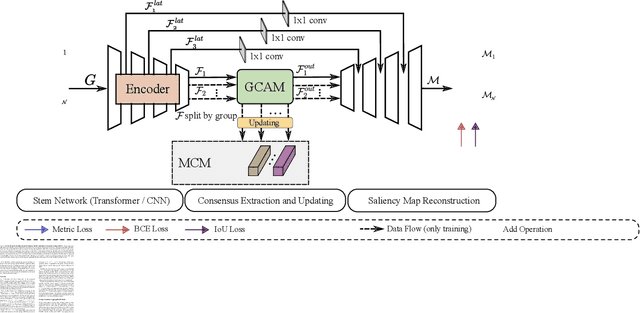

Co-Salient Object Detection (CoSOD) aims at detecting common salient objects within a group of relevant source images. Most of the latest works employ the attention mechanism for finding common objects. To achieve accurate CoSOD results with high-quality maps and high efficiency, we propose a novel Memory-aided Contrastive Consensus Learning (MCCL) framework, which is capable of effectively detecting co-salient objects in real time (~150 fps). To learn better group consensus, we propose the Group Consensus Aggregation Module (GCAM) to abstract the common features of each image group; meanwhile, to make the consensus representation more discriminative, we introduce the Memory-based Contrastive Module (MCM), which saves and updates the consensus of images from different groups in a queue of memories. Finally, to improve the quality and integrity of the predicted maps, we develop an Adversarial Integrity Learning (AIL) strategy to make the segmented regions more likely composed of complete objects with less surrounding noise. Extensive experiments on all the latest CoSOD benchmarks demonstrate that our lite MCCL outperforms 13 cutting-edge models, achieving the new state of the art (~5.9% and ~6.2% improvement in S-measure on CoSOD3k and CoSal2015, respectively). Our source codes, saliency maps, and online demos are publicly available at https://github.com/ZhengPeng7/MCCL.