 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
LFACon: Introducing Anglewise Attention to No-Reference Quality Assessment in Light Field Space
Mar 20, 2023
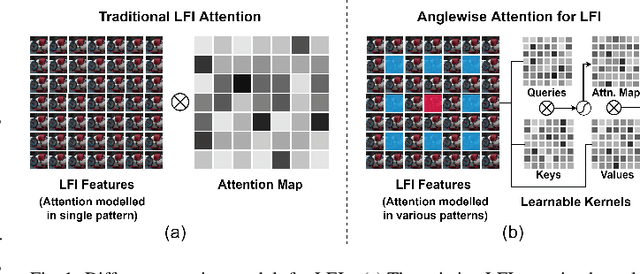
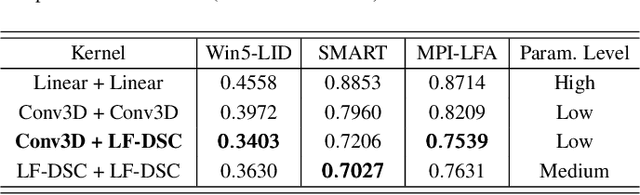
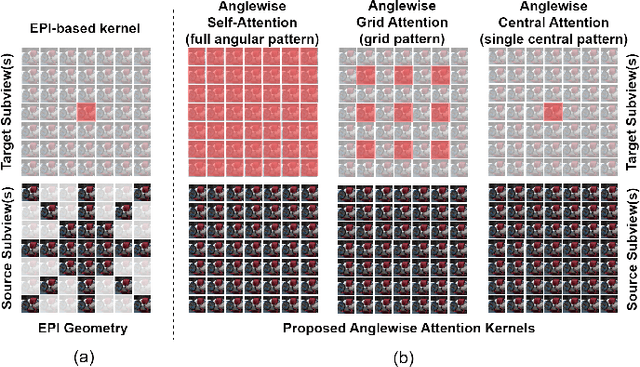
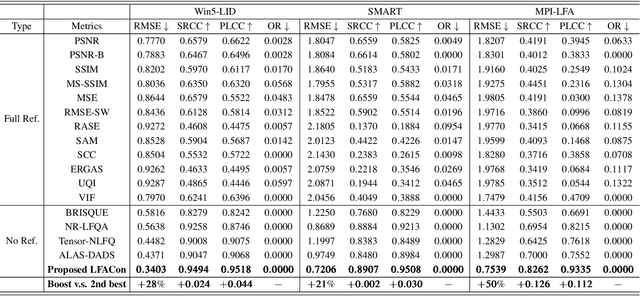
Light field imaging can capture both the intensity information and the direction information of light rays. It naturally enables a six-degrees-of-freedom viewing experience and deep user engagement in virtual reality. Compared to 2D image assessment, light field image quality assessment (LFIQA) needs to consider not only the image quality in the spatial domain but also the quality consistency in the angular domain. However, there is a lack of metrics to effectively reflect the angular consistency and thus the angular quality of a light field image (LFI). Furthermore, the existing LFIQA metrics suffer from high computational costs due to the excessive data volume of LFIs. In this paper, we propose a novel concept of "anglewise attention" by introducing a multihead self-attention mechanism to the angular domain of an LFI. This mechanism better reflects the LFI quality. In particular, we propose three new attention kernels, including anglewise self-attention, anglewise grid attention, and anglewise central attention. These attention kernels can realize angular self-attention, extract multiangled features globally or selectively, and reduce the computational cost of feature extraction. By effectively incorporating the proposed kernels, we further propose our light field attentional convolutional neural network (LFACon) as an LFIQA metric. Our experimental results show that the proposed LFACon metric significantly outperforms the state-of-the-art LFIQA metrics. For the majority of distortion types, LFACon attains the best performance with lower complexity and less computational time.
A Composite T60 Regression and Classification Approach for Speech Dereverberation
Feb 09, 2023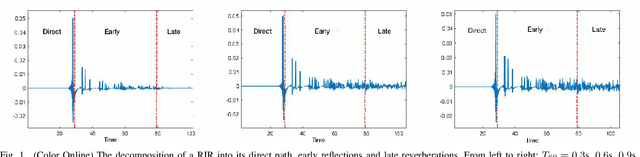
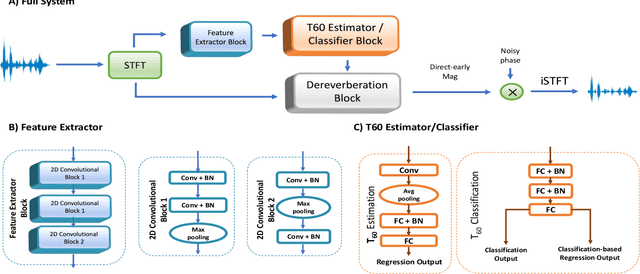
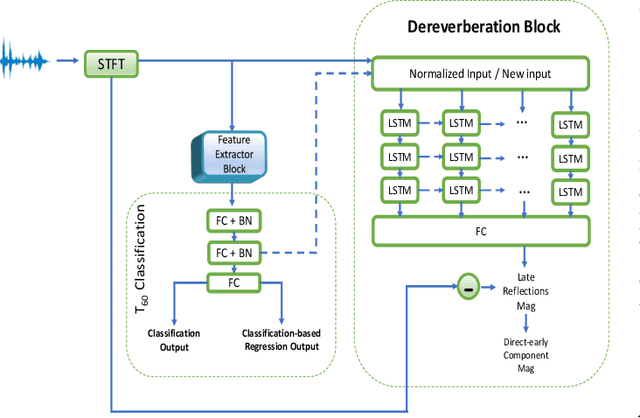
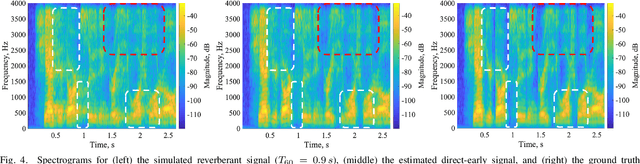
Dereverberation is often performed directly on the reverberant audio signal, without knowledge of the acoustic environment. Reverberation time, T60, however, is an essential acoustic factor that reflects how reverberation may impact a signal. In this work, we propose to perform dereverberation while leveraging key acoustic information from the environment. More specifically, we develop a joint learning approach that uses a composite T60 module and a separate dereverberation module to simultaneously perform reverberation time estimation and dereverberation. The reverberation time module provides key features to the dereverberation module during fine tuning. We evaluate our approach in simulated and real environments, and compare against several approaches. The results show that this composite framework improves performance in environments.
Synthetic ECG Signal Generation using Probabilistic Diffusion Models
Mar 04, 2023

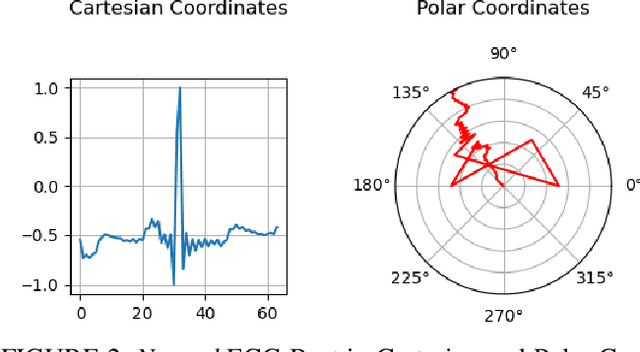
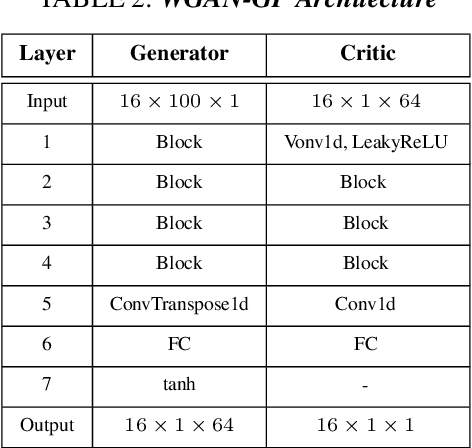
Deep learning image processing models have had remarkable success in recent years in generating high quality images. Particularly, the Improved Denoising Diffusion Probabilistic Models (DDPM) have shown superiority in image quality to the state-of-the-art generative models, which motivated us to investigate its capability in generation of the synthetic electrocardiogram (ECG) signals. In this work, synthetic ECG signals are generated by the Improved DDPM and by the Wasserstein GAN with Gradient Penalty (WGANGP) models and then compared. To this end, we devise a pipeline to utilize DDPM in its original 2D form. First, the 1D ECG time series data are embedded into the 2D space, for which we employed the Gramian Angular Summation/Difference Fields (GASF/GADF) as well as Markov Transition Fields (MTF) to generate three 2D matrices from each ECG time series that, which when put together, form a 3-channel 2D datum. Then 2D DDPM is used to generate 2D 3-channel synthetic ECG images. The 1D ECG signals are created by de-embedding the 2D generated image files back into the 1D space. This work focuses on unconditional models and the generation of only Normal ECG signals, where the Normal class from the MIT BIH Arrhythmia dataset is used as the training phase. The quality, distribution, and the authenticity of the generated ECG signals by each model are compared. Our results show that, in the proposed pipeline, the WGAN-GP model is superior to DDPM by far in all the considered metrics consistently.
A Convergent Single-Loop Algorithm for Relaxation of Gromov-Wasserstein in Graph Data
Mar 12, 2023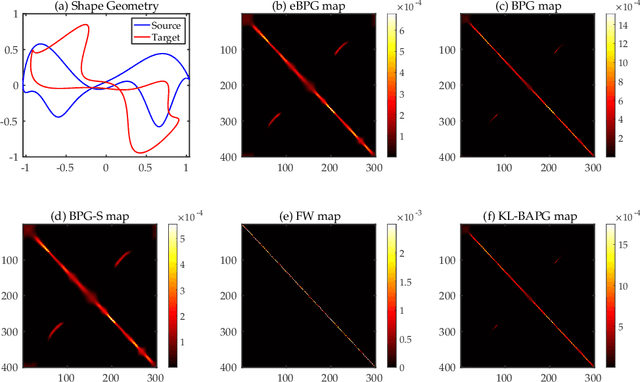
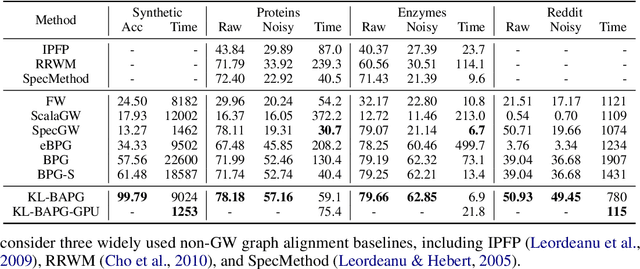
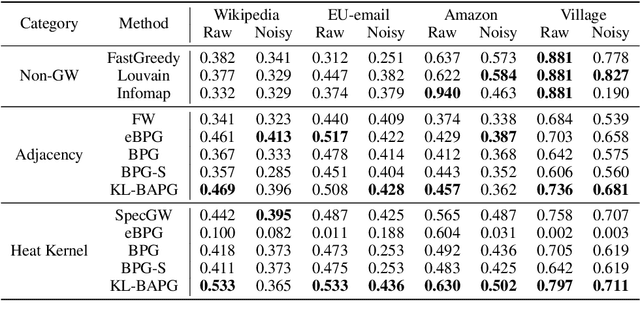
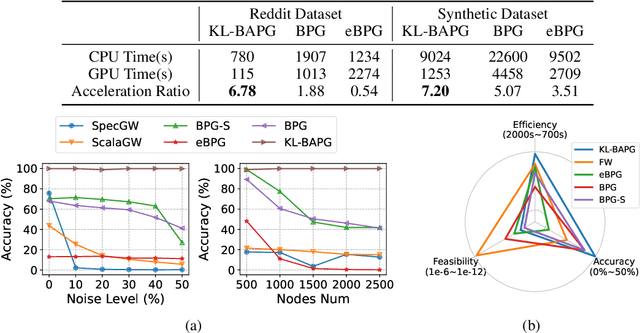
In this work, we present the Bregman Alternating Projected Gradient (BAPG) method, a single-loop algorithm that offers an approximate solution to the Gromov-Wasserstein (GW) distance. We introduce a novel relaxation technique that balances accuracy and computational efficiency, albeit with some compromises in the feasibility of the coupling map. Our analysis is based on the observation that the GW problem satisfies the Luo-Tseng error bound condition, which relates to estimating the distance of a point to the critical point set of the GW problem based on the optimality residual. This observation allows us to provide an approximation bound for the distance between the fixed-point set of BAPG and the critical point set of GW. Moreover, under a mild technical assumption, we can show that BAPG converges to its fixed point set. The effectiveness of BAPG has been validated through comprehensive numerical experiments in graph alignment and partition tasks, where it outperforms existing methods in terms of both solution quality and wall-clock time.
Improving the Intent Classification accuracy in Noisy Environment
Mar 12, 2023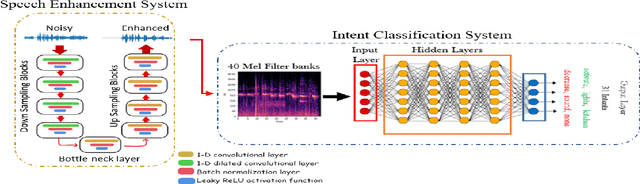

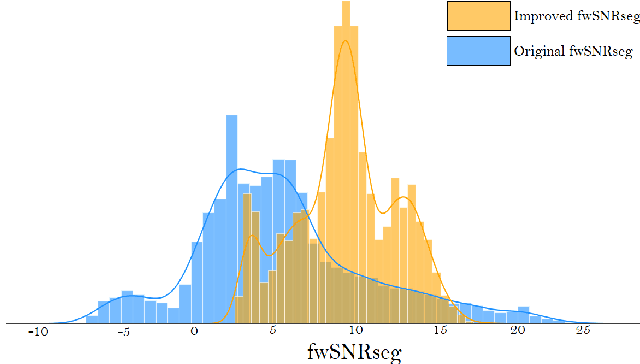
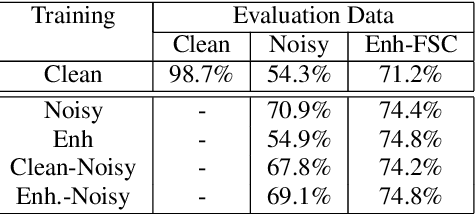
Intent classification is a fundamental task in the spoken language understanding field that has recently gained the attention of the scientific community, mainly because of the feasibility of approaching it with end-to-end neural models. In this way, avoiding using intermediate steps, i.e. automatic speech recognition, is possible, thus the propagation of errors due to background noise, spontaneous speech, speaking styles of users, etc. Towards the development of solutions applicable in real scenarios, it is interesting to investigate how environmental noise and related noise reduction techniques to address the intent classification task with end-to-end neural models. In this paper, we experiment with a noisy version of the fluent speech command data set, combining the intent classifier with a time-domain speech enhancement solution based on Wave-U-Net and considering different training strategies. Experimental results reveal that, for this task, the use of speech enhancement greatly improves the classification accuracy in noisy conditions, in particular when the classification model is trained on enhanced signals.
Sliced-Wasserstein on Symmetric Positive Definite Matrices for M/EEG Signals
Mar 10, 2023
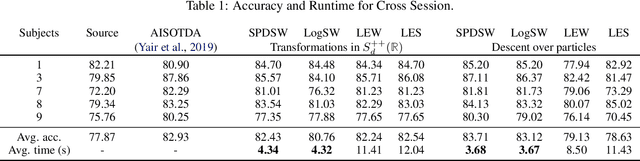
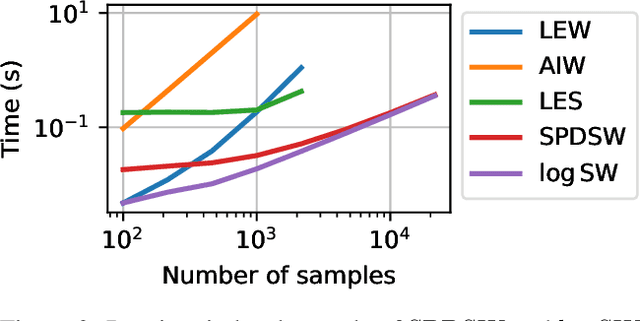
When dealing with electro or magnetoencephalography records, many supervised prediction tasks are solved by working with covariance matrices to summarize the signals. Learning with these matrices requires using Riemanian geometry to account for their structure. In this paper, we propose a new method to deal with distributions of covariance matrices and demonstrate its computational efficiency on M/EEG multivariate time series. More specifically, we define a Sliced-Wasserstein distance between measures of symmetric positive definite matrices that comes with strong theoretical guarantees. Then, we take advantage of its properties and kernel methods to apply this distance to brain-age prediction from MEG data and compare it to state-of-the-art algorithms based on Riemannian geometry. Finally, we show that it is an efficient surrogate to the Wasserstein distance in domain adaptation for Brain Computer Interface applications.
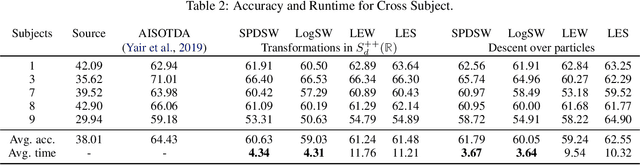
GECCO: Geometrically-Conditioned Point Diffusion Models
Mar 10, 2023
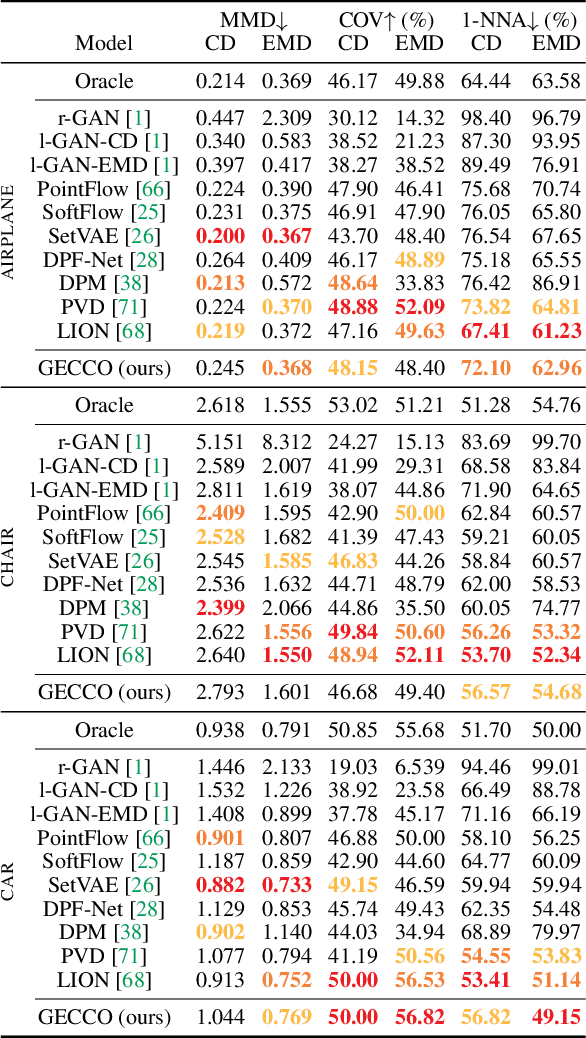
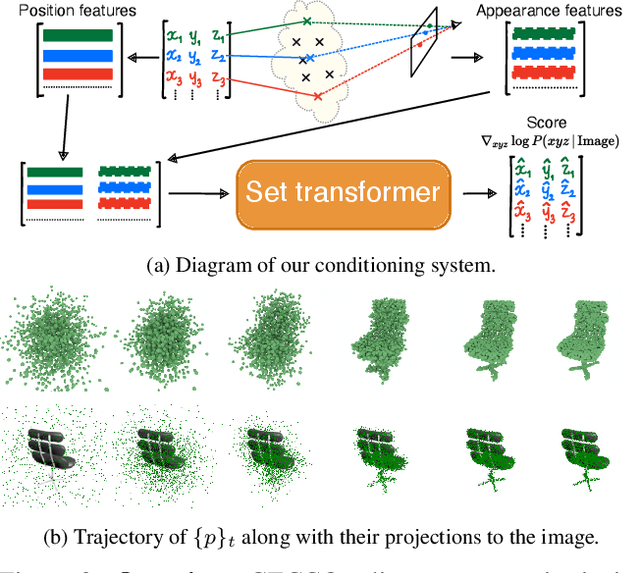
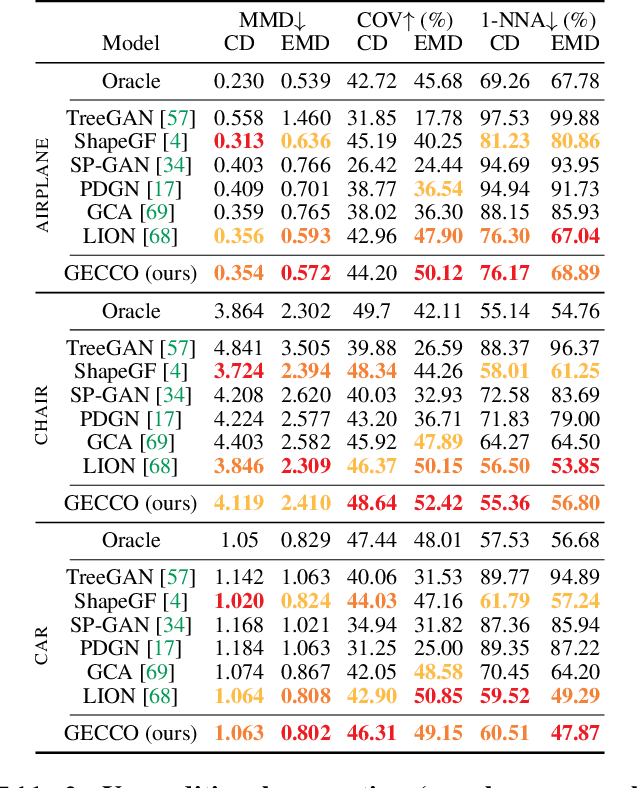
Diffusion models generating images conditionally on text, such as Dall-E 2 and Stable Diffusion, have recently made a splash far beyond the computer vision community. Here, we tackle the related problem of generating point clouds, both unconditionally, and conditionally with images. For the latter, we introduce a novel geometrically-motivated conditioning scheme based on projecting sparse image features into the point cloud and attaching them to each individual point, at every step in the denoising process. This approach improves geometric consistency and yields greater fidelity than current methods relying on unstructured, global latent codes. Additionally, we show how to apply recent continuous-time diffusion schemes. Our method performs on par or above the state of art on conditional and unconditional experiments on synthetic data, while being faster, lighter, and delivering tractable likelihoods. We show it can also scale to diverse indoors scenes.
Deep Generative Fixed-filter Active Noise Control
Mar 10, 2023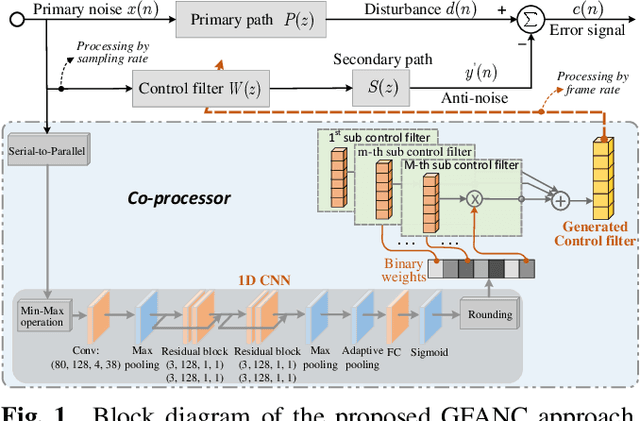
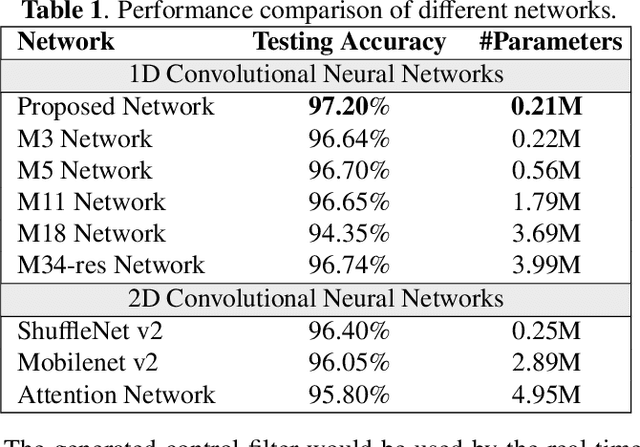
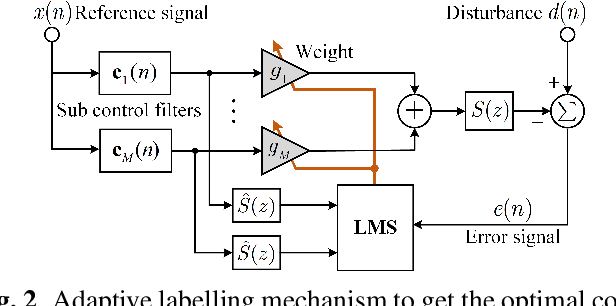
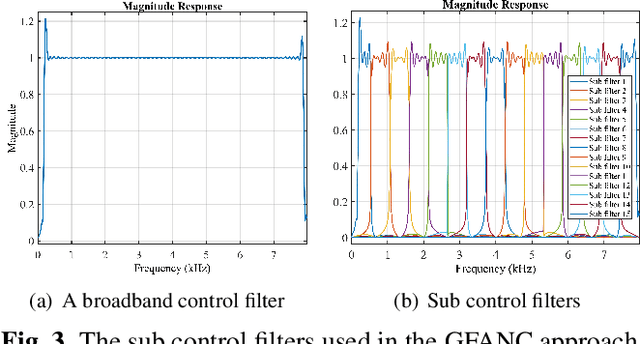
Due to the slow convergence and poor tracking ability, conventional LMS-based adaptive algorithms are less capable of handling dynamic noises. Selective fixed-filter active noise control (SFANC) can significantly reduce response time by selecting appropriate pre-trained control filters for different noises. Nonetheless, the limited number of pre-trained control filters may affect noise reduction performance, especially when the incoming noise differs much from the initial noises during pre-training. Therefore, a generative fixed-filter active noise control (GFANC) method is proposed in this paper to overcome the limitation. Based on deep learning and a perfect-reconstruction filter bank, the GFANC method only requires a few prior data (one pre-trained broadband control filter) to automatically generate suitable control filters for various noises. The efficacy of the GFANC method is demonstrated by numerical simulations on real-recorded noises.
On Neural Architectures for Deep Learning-based Source Separation of Co-Channel OFDM Signals
Mar 11, 2023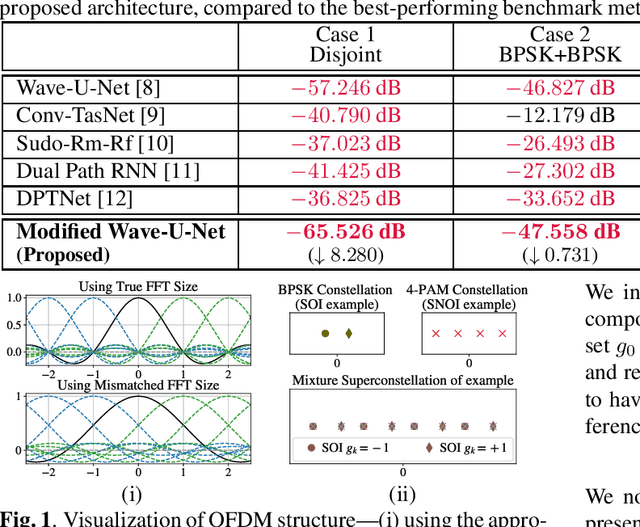
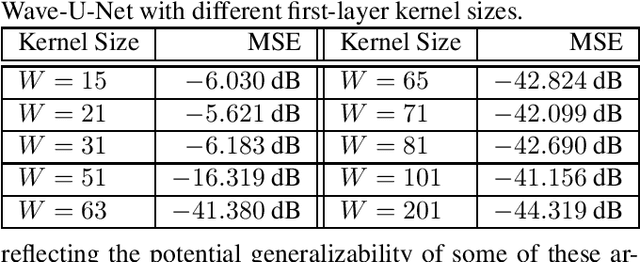
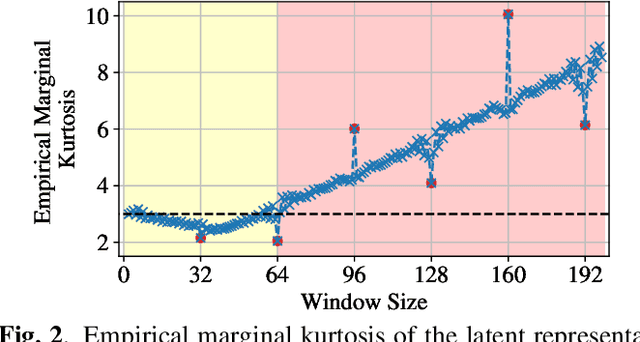
We study the single-channel source separation problem involving orthogonal frequency-division multiplexing (OFDM) signals, which are ubiquitous in many modern-day digital communication systems. Related efforts have been pursued in monaural source separation, where state-of-the-art neural architectures have been adopted to train an end-to-end separator for audio signals (as 1-dimensional time series). In this work, through a prototype problem based on the OFDM source model, we assess -- and question -- the efficacy of using audio-oriented neural architectures in separating signals based on features pertinent to communication waveforms. Perhaps surprisingly, we demonstrate that in some configurations, where perfect separation is theoretically attainable, these audio-oriented neural architectures perform poorly in separating co-channel OFDM waveforms. Yet, we propose critical domain-informed modifications to the network parameterization, based on insights from OFDM structures, that can confer about 30 dB improvement in performance.
Towards Meaningful Anomaly Detection: The Effect of Counterfactual Explanations on the Investigation of Anomalies in Multivariate Time Series
Feb 07, 2023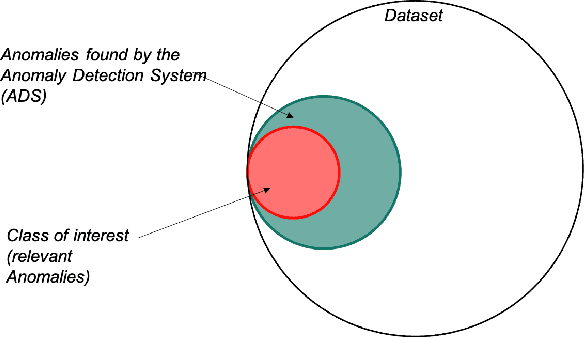
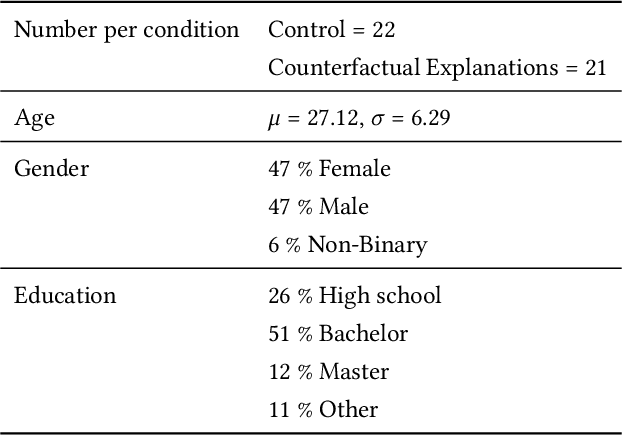
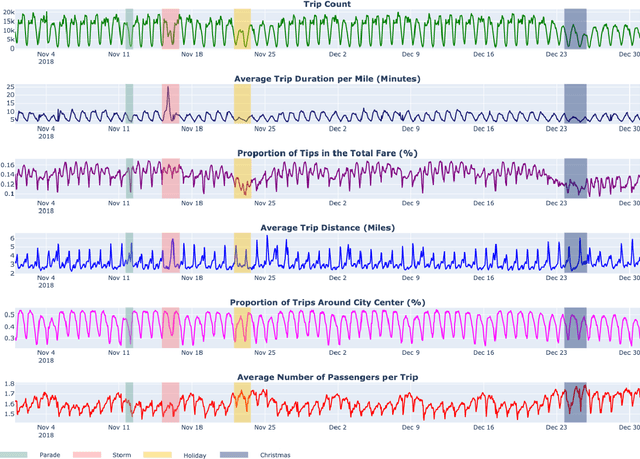
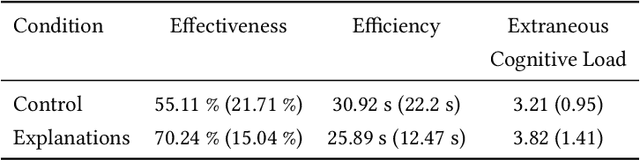
Detecting rare events is essential in various fields, e.g., in cyber security or maintenance. Often, human experts are supported by anomaly detection systems as continuously monitoring the data is an error-prone and tedious task. However, among the anomalies detected may be events that are rare, e.g., a planned shutdown of a machine, but are not the actual event of interest, e.g., breakdowns of a machine. Therefore, human experts are needed to validate whether the detected anomalies are relevant. We propose to support this anomaly investigation by providing explanations of anomaly detection. Related work only focuses on the technical implementation of explainable anomaly detection and neglects the subsequent human anomaly investigation. To address this research gap, we conduct a behavioral experiment using records of taxi rides in New York City as a testbed. Participants are asked to differentiate extreme weather events from other anomalous events such as holidays or sporting events. Our results show that providing counterfactual explanations do improve the investigation of anomalies, indicating potential for explainable anomaly detection in general.