 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Better Fit: Accommodate Variations in Clothing Types for Virtual Try-on
Mar 13, 2024
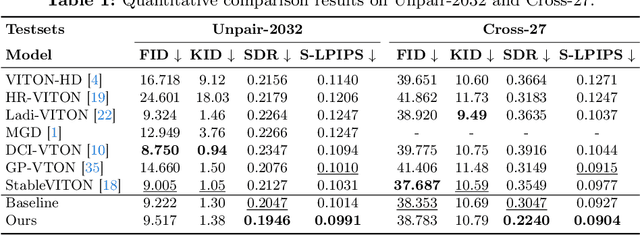
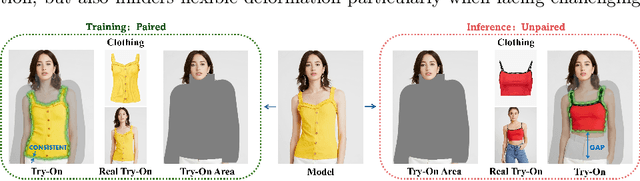
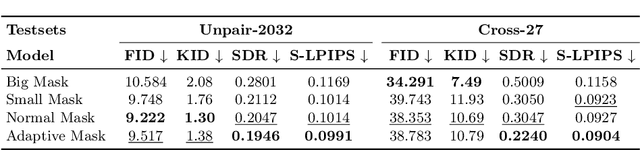
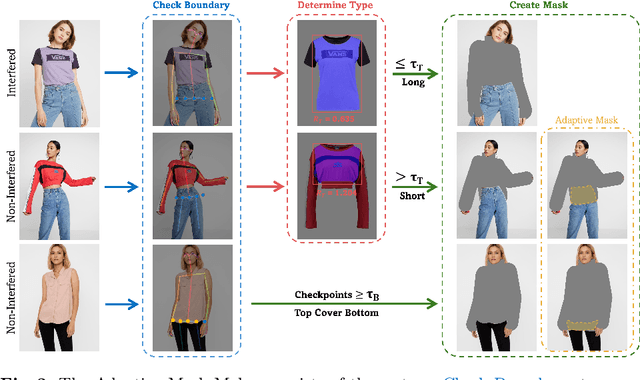
Image-based virtual try-on aims to transfer target in-shop clothing to a dressed model image, the objectives of which are totally taking off original clothing while preserving the contents outside of the try-on area, naturally wearing target clothing and correctly inpainting the gap between target clothing and original clothing. Tremendous efforts have been made to facilitate this popular research area, but cannot keep the type of target clothing with the try-on area affected by original clothing. In this paper, we focus on the unpaired virtual try-on situation where target clothing and original clothing on the model are different, i.e., the practical scenario. To break the correlation between the try-on area and the original clothing and make the model learn the correct information to inpaint, we propose an adaptive mask training paradigm that dynamically adjusts training masks. It not only improves the alignment and fit of clothing but also significantly enhances the fidelity of virtual try-on experience. Furthermore, we for the first time propose two metrics for unpaired try-on evaluation, the Semantic-Densepose-Ratio (SDR) and Skeleton-LPIPS (S-LPIPS), to evaluate the correctness of clothing type and the accuracy of clothing texture. For unpaired try-on validation, we construct a comprehensive cross-try-on benchmark (Cross-27) with distinctive clothing items and model physiques, covering a broad try-on scenarios. Experiments demonstrate the effectiveness of the proposed methods, contributing to the advancement of virtual try-on technology and offering new insights and tools for future research in the field. The code, model and benchmark will be publicly released.
MetaSplit: Meta-Split Network for Limited-Stock Product Recommendation
Mar 13, 2024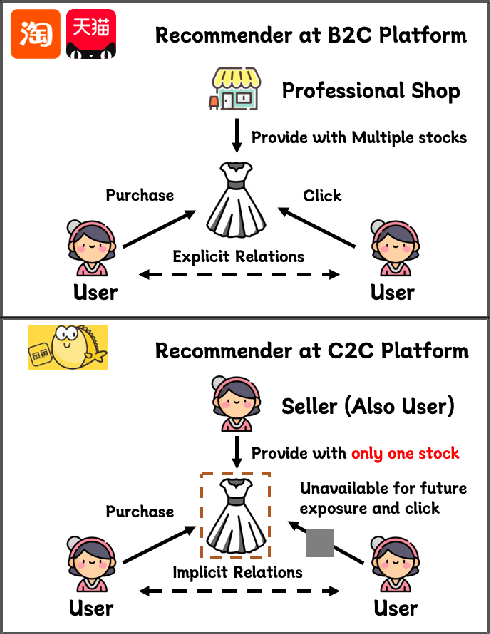
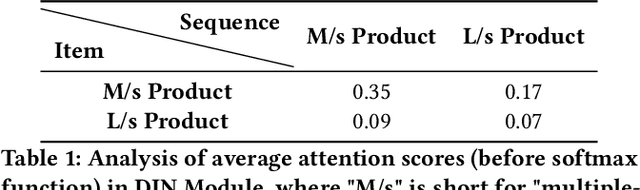
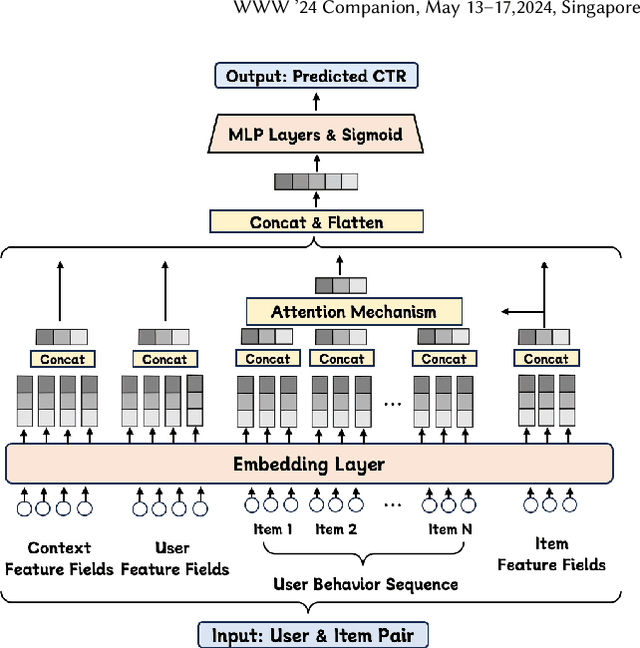
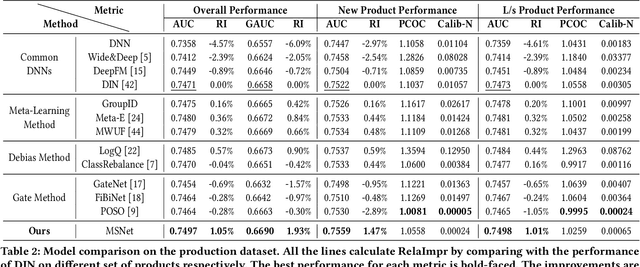
Compared to business-to-consumer (B2C) e-commerce systems, consumer-to-consumer (C2C) e-commerce platforms usually encounter the limited-stock problem, that is, a product can only be sold one time in a C2C system. This poses several unique challenges for click-through rate (CTR) prediction. Due to limited user interactions for each product (i.e. item), the corresponding item embedding in the CTR model may not easily converge. This makes the conventional sequence modeling based approaches cannot effectively utilize user history information since historical user behaviors contain a mixture of items with different volume of stocks. Particularly, the attention mechanism in a sequence model tends to assign higher score to products with more accumulated user interactions, making limited-stock products being ignored and contribute less to the final output. To this end, we propose the Meta-Split Network (MSNet) to split user history sequence regarding to the volume of stock for each product, and adopt differentiated modeling approaches for different sequences. As for the limited-stock products, a meta-learning approach is applied to address the problem of inconvergence, which is achieved by designing meta scaling and shifting networks with ID and side information. In addition, traditional approach can hardly update item embedding once the product is consumed. Thereby, we propose an auxiliary loss that makes the parameters updatable even when the product is no longer in distribution. To the best of our knowledge, this is the first solution addressing the recommendation of limited-stock product. Experimental results on the production dataset and online A/B testing demonstrate the effectiveness of our proposed method.
Efficient Global Navigational Planning in 3D Structures based on Point Cloud Tomography
Mar 12, 2024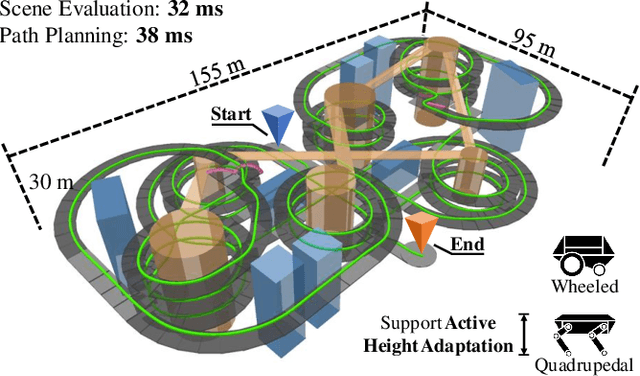
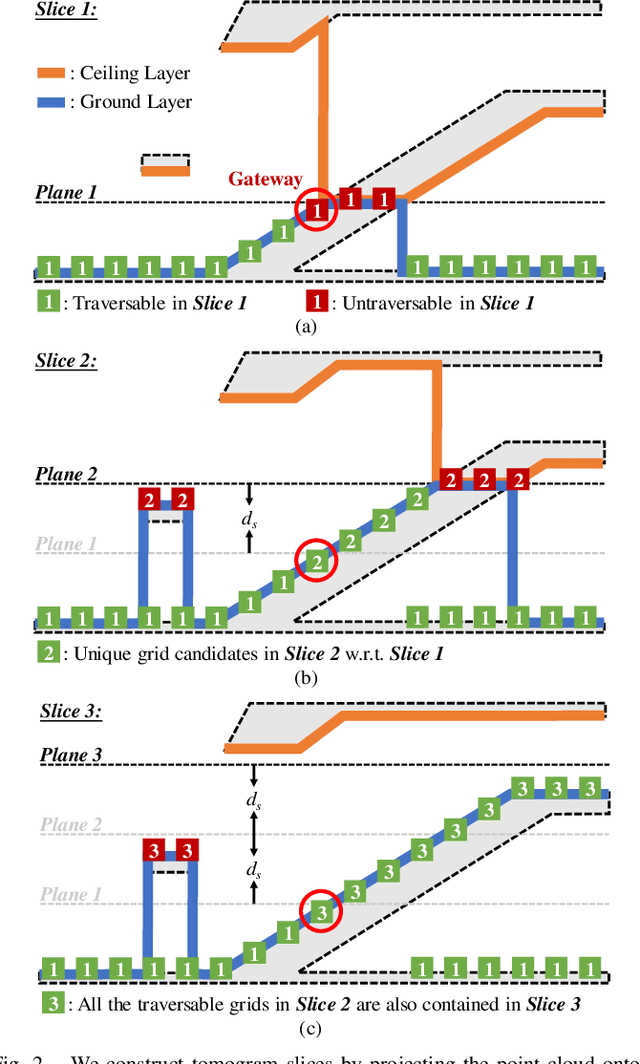
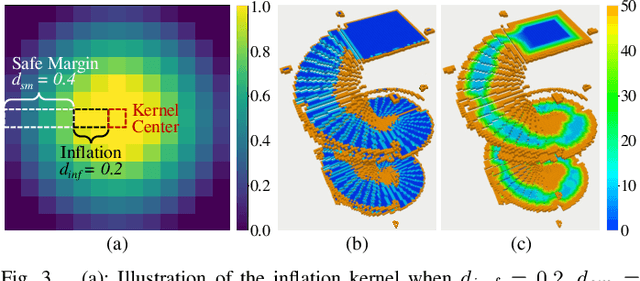
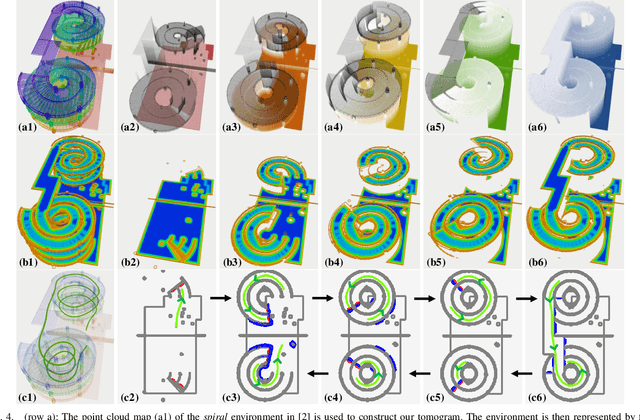
Navigation in complex 3D scenarios requires appropriate environment representation for efficient scene understanding and trajectory generation. We propose a highly efficient and extensible global navigation framework based on a tomographic understanding of the environment to navigate ground robots in multi-layer structures. Our approach generates tomogram slices using the point cloud map to encode the geometric structure as ground and ceiling elevations. Then it evaluates the scene traversability considering the robot's motion capabilities. Both the tomogram construction and the scene evaluation are accelerated through parallel computation. Our approach further alleviates the trajectory generation complexity compared with planning in 3D spaces directly. It generates 3D trajectories by searching through multiple tomogram slices and separately adjusts the robot height to avoid overhangs. We evaluate our framework in various simulation scenarios and further test it in the real world on a quadrupedal robot. Our approach reduces the scene evaluation time by 3 orders of magnitude and improves the path planning speed by 3 times compared with existing approaches, demonstrating highly efficient global navigation in various complex 3D environments. The code is available at: https://github.com/byangw/PCT_planner.
Smartphone region-wise image indoor localization using deep learning for indoor tourist attraction
Mar 12, 2024
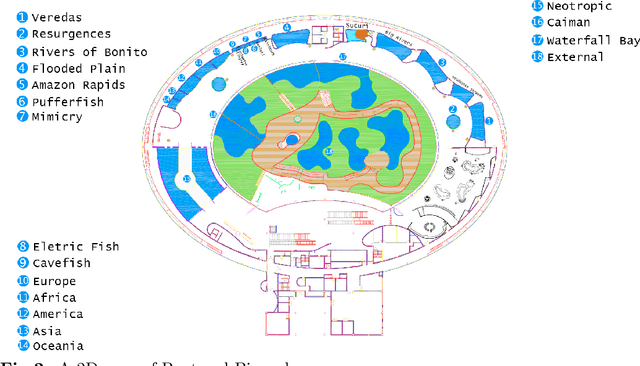
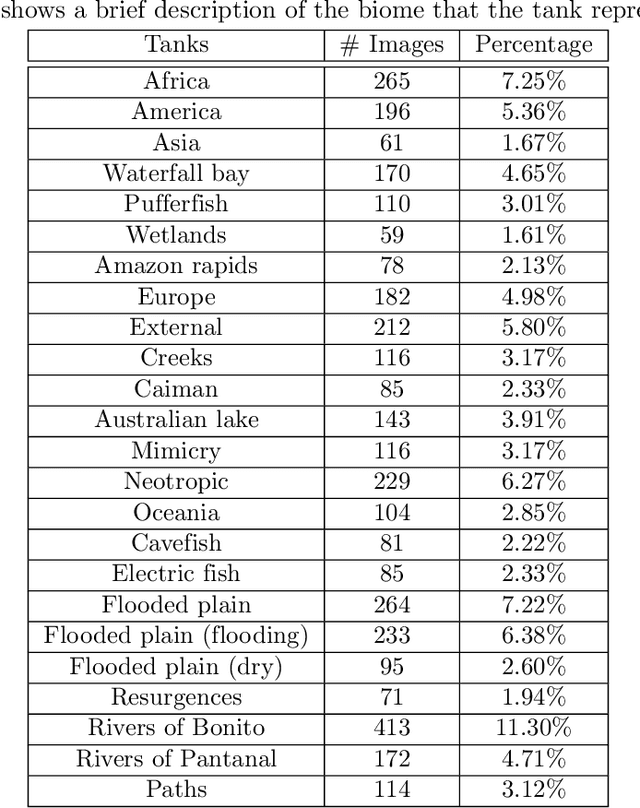
Smart indoor tourist attractions, such as smart museums and aquariums, usually require a significant investment in indoor localization devices. The smartphone Global Positional Systems use is unsuitable for scenarios where dense materials such as concrete and metal block weaken the GPS signals, which is the most common scenario in an indoor tourist attraction. Deep learning makes it possible to perform region-wise indoor localization using smartphone images. This approach does not require any investment in infrastructure, reducing the cost and time to turn museums and aquariums into smart museums or smart aquariums. This paper proposes using deep learning algorithms to classify locations using smartphone camera images for indoor tourism attractions. We evaluate our proposal in a real-world scenario in Brazil. We extensively collect images from ten different smartphones to classify biome-themed fish tanks inside the Pantanal Biopark, creating a new dataset of 3654 images. We tested seven state-of-the-art neural networks, three being transformer-based, achieving precision around 90% on average and recall and f-score around 89% on average. The results indicate good feasibility of the proposal in a most indoor tourist attractions.
DALSA: Domain Adaptation for Supervised Learning From Sparsely Annotated MR Images
Mar 12, 2024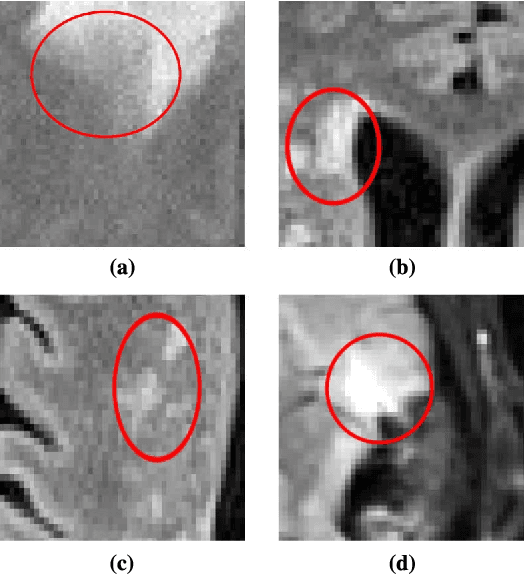
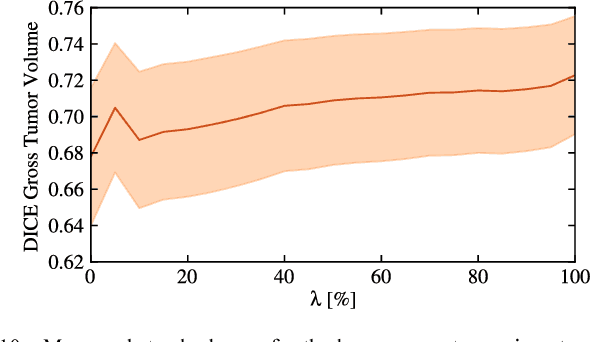
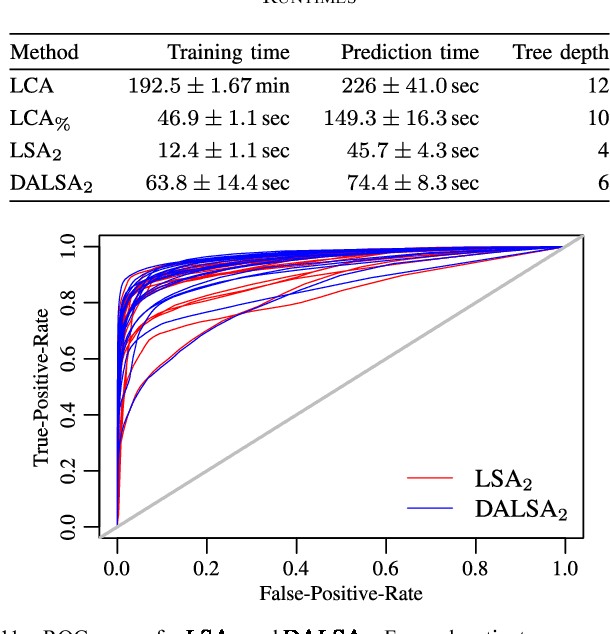
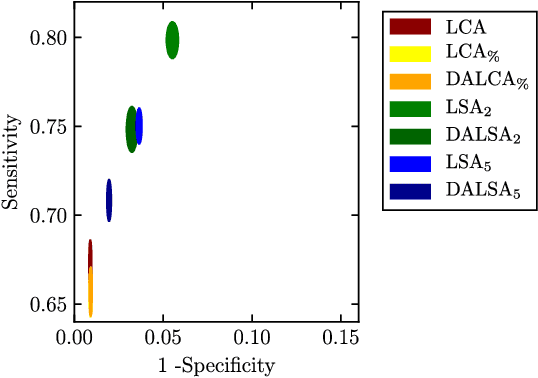
We propose a new method that employs transfer learning techniques to effectively correct sampling selection errors introduced by sparse annotations during supervised learning for automated tumor segmentation. The practicality of current learning-based automated tissue classification approaches is severely impeded by their dependency on manually segmented training databases that need to be recreated for each scenario of application, site, or acquisition setup. The comprehensive annotation of reference datasets can be highly labor-intensive, complex, and error-prone. The proposed method derives high-quality classifiers for the different tissue classes from sparse and unambiguous annotations and employs domain adaptation techniques for effectively correcting sampling selection errors introduced by the sparse sampling. The new approach is validated on labeled, multi-modal MR images of 19 patients with malignant gliomas and by comparative analysis on the BraTS 2013 challenge data sets. Compared to training on fully labeled data, we reduced the time for labeling and training by a factor greater than 70 and 180 respectively without sacrificing accuracy. This dramatically eases the establishment and constant extension of large annotated databases in various scenarios and imaging setups and thus represents an important step towards practical applicability of learning-based approaches in tissue classification.
SparseLIF: High-Performance Sparse LiDAR-Camera Fusion for 3D Object Detection
Mar 12, 2024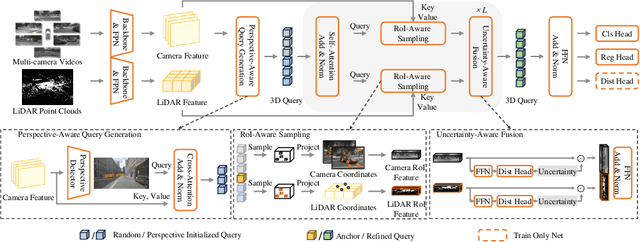
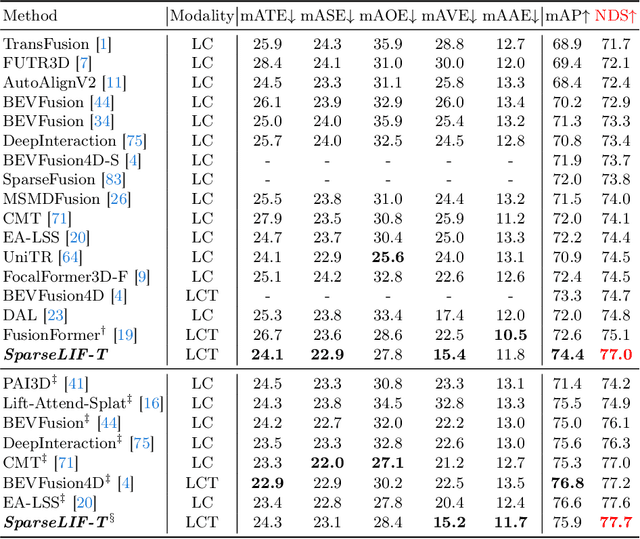
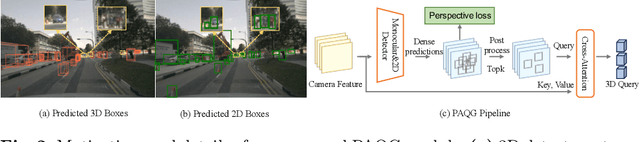
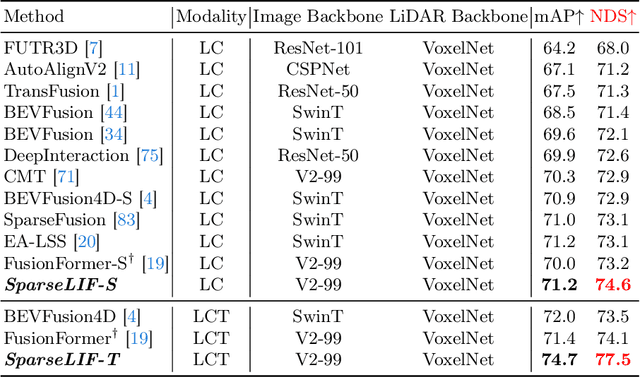
Sparse 3D detectors have received significant attention since the query-based paradigm embraces low latency without explicit dense BEV feature construction. However, these detectors achieve worse performance than their dense counterparts. In this paper, we find the key to bridging the performance gap is to enhance the awareness of rich representations in two modalities. Here, we present a high-performance fully sparse detector for end-to-end multi-modality 3D object detection. The detector, termed SparseLIF, contains three key designs, which are (1) Perspective-Aware Query Generation (PAQG) to generate high-quality 3D queries with perspective priors, (2) RoI-Aware Sampling (RIAS) to further refine prior queries by sampling RoI features from each modality, (3) Uncertainty-Aware Fusion (UAF) to precisely quantify the uncertainty of each sensor modality and adaptively conduct final multi-modality fusion, thus achieving great robustness against sensor noises. By the time of submission (2024/03/08), SparseLIF achieves state-of-the-art performance on the nuScenes dataset, ranking 1st on both validation set and test benchmark, outperforming all state-of-the-art 3D object detectors by a notable margin. The source code will be released upon acceptance.
A Flexible Cell Classification for ML Projects in Jupyter Notebooks
Mar 12, 2024
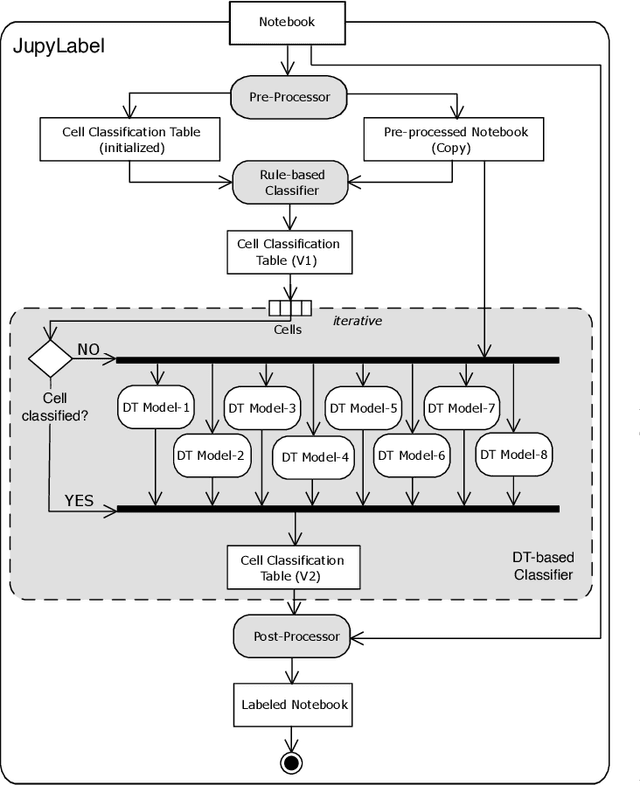
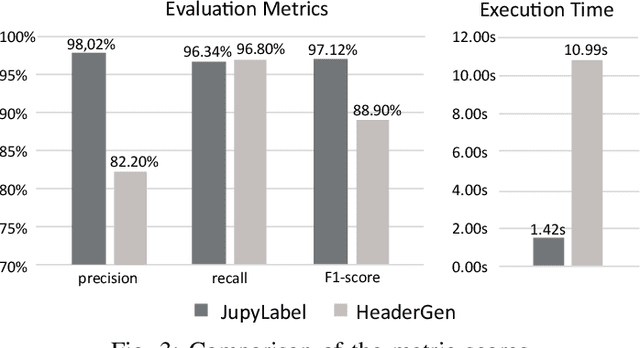
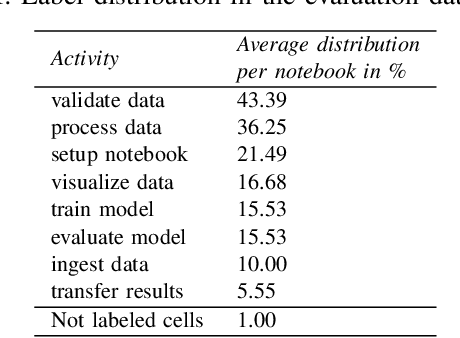
Jupyter Notebook is an interactive development environment commonly used for rapid experimentation of machine learning (ML) solutions. Describing the ML activities performed along code cells improves the readability and understanding of Notebooks. Manual annotation of code cells is time-consuming and error-prone. Therefore, tools have been developed that classify the cells of a notebook concerning the ML activity performed in them. However, the current tools are not flexible, as they work based on look-up tables that have been created, which map function calls of commonly used ML libraries to ML activities. These tables must be manually adjusted to account for new or changed libraries. This paper presents a more flexible approach to cell classification based on a hybrid classification approach that combines a rule-based and a decision tree classifier. We discuss the design rationales and describe the developed classifiers in detail. We implemented the new flexible cell classification approach in a tool called JupyLabel. Its evaluation and the obtained metric scores regarding precision, recall, and F1-score are discussed. Additionally, we compared JupyLabel with HeaderGen, an existing cell classification tool. We were able to show that the presented flexible cell classification approach outperforms this tool significantly.
Time Series Forecasting with LLMs: Understanding and Enhancing Model Capabilities
Feb 19, 2024Large language models (LLMs) have been applied in many fields with rapid development in recent years. As a classic machine learning task, time series forecasting has recently received a boost from LLMs. However, there is a research gap in the LLMs' preferences in this field. In this paper, by comparing LLMs with traditional models, many properties of LLMs in time series prediction are found. For example, our study shows that LLMs excel in predicting time series with clear patterns and trends but face challenges with datasets lacking periodicity. We explain our findings through designing prompts to require LLMs to tell the period of the datasets. In addition, the input strategy is investigated, and it is found that incorporating external knowledge and adopting natural language paraphrases positively affects the predictive performance of LLMs for time series. Overall, this study contributes to insight into the advantages and limitations of LLMs in time series forecasting under different conditions.
Pfeed: Generating near real-time personalized feeds using precomputed embedding similarities
Feb 25, 2024In personalized recommender systems, embeddings are often used to encode customer actions and items, and retrieval is then performed in the embedding space using approximate nearest neighbor search. However, this approach can lead to two challenges: 1) user embeddings can restrict the diversity of interests captured and 2) the need to keep them up-to-date requires an expensive, real-time infrastructure. In this paper, we propose a method that overcomes these challenges in a practical, industrial setting. The method dynamically updates customer profiles and composes a feed every two minutes, employing precomputed embeddings and their respective similarities. We tested and deployed this method to personalise promotional items at Bol, one of the largest e-commerce platforms of the Netherlands and Belgium. The method enhanced customer engagement and experience, leading to a significant 4.9% uplift in conversions.
ED-Copilot: Reduce Emergency Department Wait Time with Language Model Diagnostic Assistance
Feb 21, 2024In the emergency department (ED), patients undergo triage and multiple laboratory tests before diagnosis. This process is time-consuming, and causes ED crowding which significantly impacts patient mortality, medical errors, staff burnout, etc. This work proposes (time) cost-effective diagnostic assistance that explores the potential of artificial intelligence (AI) systems in assisting ED clinicians to make time-efficient and accurate diagnoses. Using publicly available patient data, we collaborate with ED clinicians to curate MIMIC-ED-Assist, a benchmark that measures the ability of AI systems in suggesting laboratory tests that minimize ED wait times, while correctly predicting critical outcomes such as death. We develop ED-Copilot which sequentially suggests patient-specific laboratory tests and makes diagnostic predictions. ED-Copilot uses a pre-trained bio-medical language model to encode patient information and reinforcement learning to minimize ED wait time and maximize prediction accuracy of critical outcomes. On MIMIC-ED-Assist, ED-Copilot improves prediction accuracy over baselines while halving average wait time from four hours to two hours. Ablation studies demonstrate the importance of model scale and use of a bio-medical language model. Further analyses reveal the necessity of personalized laboratory test suggestions for diagnosing patients with severe cases, as well as the potential of ED-Copilot in providing ED clinicians with informative laboratory test recommendations. Our code is available at https://github.com/cxcscmu/ED-Copilot.