 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Posterior Estimation Using Deep Learning: A Simulation Study of Compartmental Modeling in Dynamic PET
Mar 17, 2023
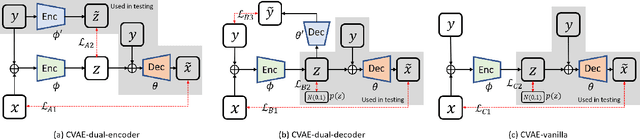
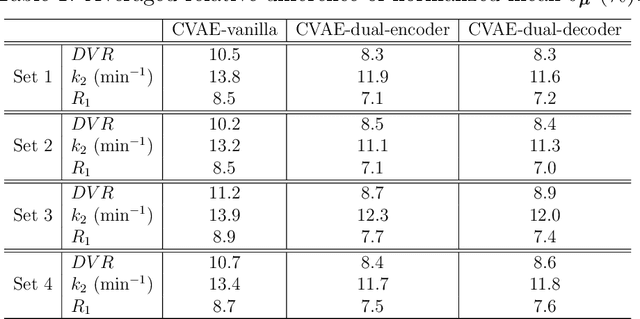
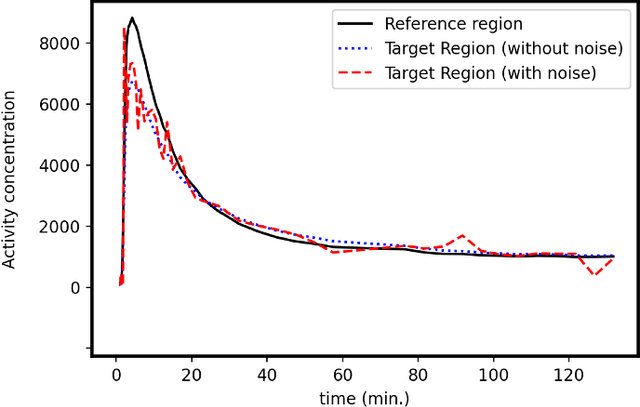
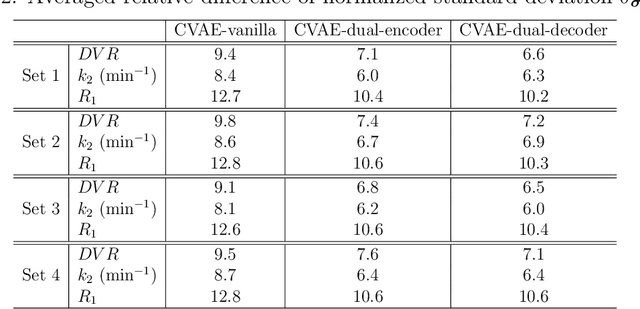
Background: In medical imaging, images are usually treated as deterministic, while their uncertainties are largely underexplored. Purpose: This work aims at using deep learning to efficiently estimate posterior distributions of imaging parameters, which in turn can be used to derive the most probable parameters as well as their uncertainties. Methods: Our deep learning-based approaches are based on a variational Bayesian inference framework, which is implemented using two different deep neural networks based on conditional variational auto-encoder (CVAE), CVAE-dual-encoder and CVAE-dual-decoder. The conventional CVAE framework, i.e., CVAE-vanilla, can be regarded as a simplified case of these two neural networks. We applied these approaches to a simulation study of dynamic brain PET imaging using a reference region-based kinetic model. Results: In the simulation study, we estimated posterior distributions of PET kinetic parameters given a measurement of time-activity curve. Our proposed CVAE-dual-encoder and CVAE-dual-decoder yield results that are in good agreement with the asymptotically unbiased posterior distributions sampled by Markov Chain Monte Carlo (MCMC). The CVAE-vanilla can also be used for estimating posterior distributions, although it has an inferior performance to both CVAE-dual-encoder and CVAE-dual-decoder. Conclusions: We have evaluated the performance of our deep learning approaches for estimating posterior distributions in dynamic brain PET. Our deep learning approaches yield posterior distributions, which are in good agreement with unbiased distributions estimated by MCMC. All these neural networks have different characteristics and can be chosen by the user for specific applications. The proposed methods are general and can be adapted to other problems.
Is it worth it? An experimental comparison of six deep- and classical machine learning methods for unsupervised anomaly detection in time series
Dec 21, 2022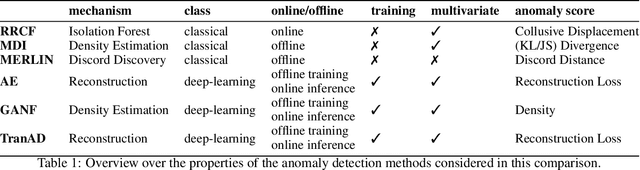
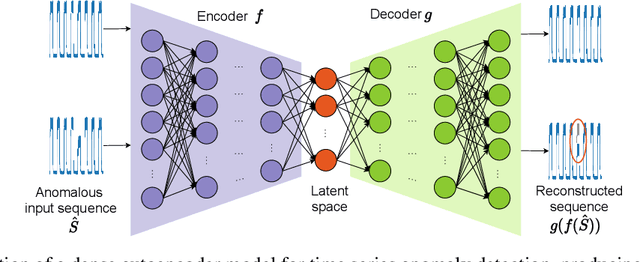
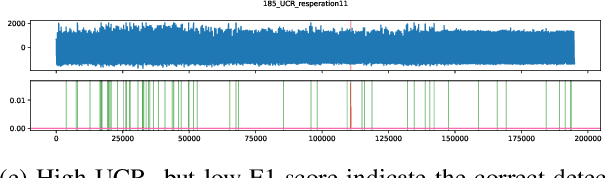

The detection of anomalies in time series data is crucial in a wide range of applications, such as system monitoring, health care or cyber security. While the vast number of available methods makes selecting the right method for a certain application hard enough, different methods have different strengths, e.g. regarding the type of anomalies they are able to find. In this work, we compare six unsupervised anomaly detection methods with different complexities to answer the questions: Are the more complex methods usually performing better? And are there specific anomaly types that those method are tailored to? The comparison is done on the UCR anomaly archive, a recent benchmark dataset for anomaly detection. We compare the six methods by analyzing the experimental results on a dataset- and anomaly type level after tuning the necessary hyperparameter for each method. Additionally we examine the ability of individual methods to incorporate prior knowledge about the anomalies and analyse the differences of point-wise and sequence wise features. We show with broad experiments, that the classical machine learning methods show a superior performance compared to the deep learning methods across a wide range of anomaly types.
Adaptive Multi-source Predictor for Zero-shot Video Object Segmentation
Mar 18, 2023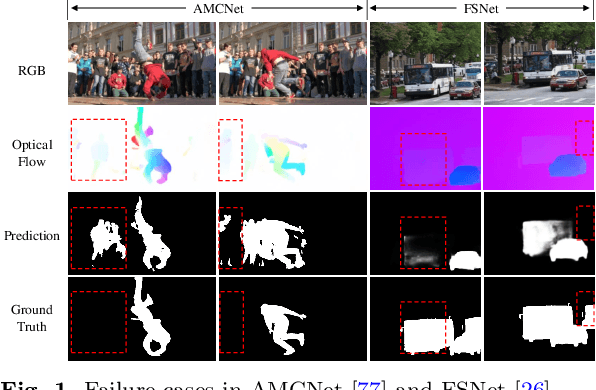


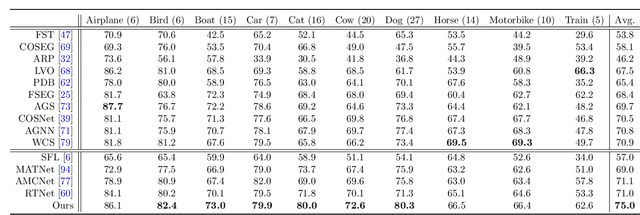
Both static and moving objects usually exist in real-life videos. Most video object segmentation methods only focus on exacting and exploiting motion cues to perceive moving objects. Once faced with static objects frames, moving object predictors may predict failed results caused by uncertain motion information, such as low-quality optical flow maps. Besides, many sources such as RGB, depth, optical flow and static saliency can provide useful information about the objects. However, existing approaches only utilize the RGB or RGB and optical flow. In this paper, we propose a novel adaptive multi-source predictor for zero-shot video object segmentation. In the static object predictor, the RGB source is converted to depth and static saliency sources, simultaneously. In the moving object predictor, we propose the multi-source fusion structure. First, the spatial importance of each source is highlighted with the help of the interoceptive spatial attention module (ISAM). Second, the motion-enhanced module (MEM) is designed to generate pure foreground motion attention for improving both static and moving features used in the decoder. Furthermore, we design a feature purification module (FPM) to filter the inter-source incompatible features. By the ISAM, MEM and FPM, the multi-source features are effectively fused. In addition, we put forward an adaptive predictor fusion network (APF) to evaluate the quality of optical flow and fuse the predictions from the static object predictor and the moving object predictor in order to prevent over-reliance on the failed results caused by low-quality optical flow maps. Experiments show that the proposed model outperforms the state-of-the-art methods on three challenging ZVOS benchmarks. And, the static object predictor can precisely predicts a high-quality depth map and static saliency map at the same time.
Forecasting COVID-19 Case Counts Based on 2020 Ontario Data
Mar 18, 2023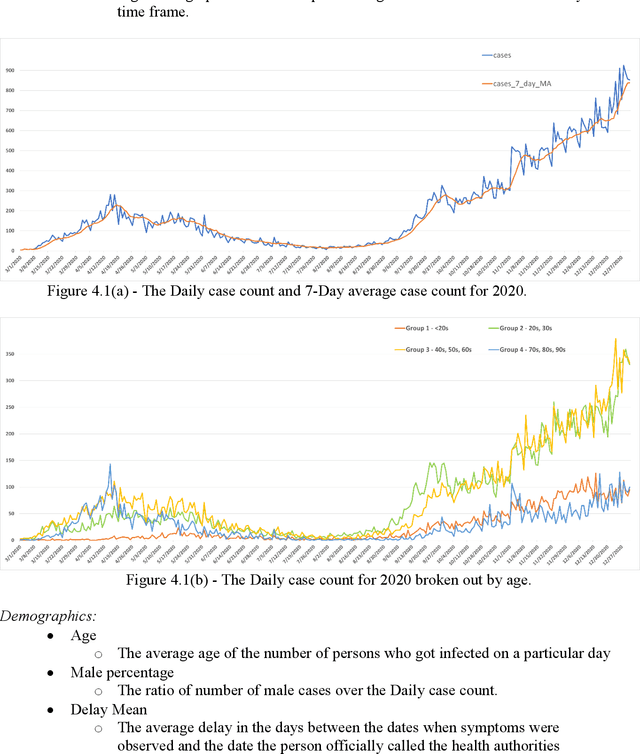
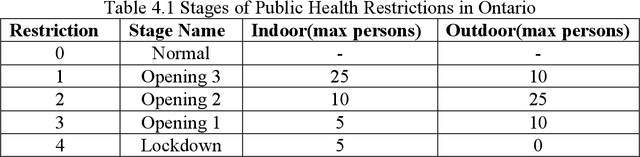
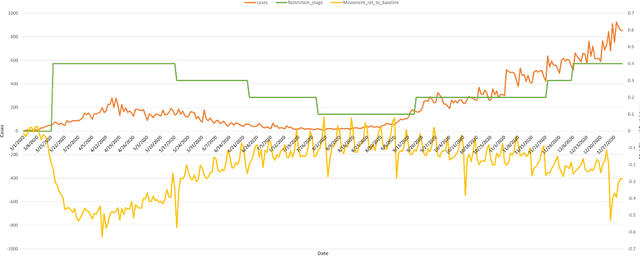
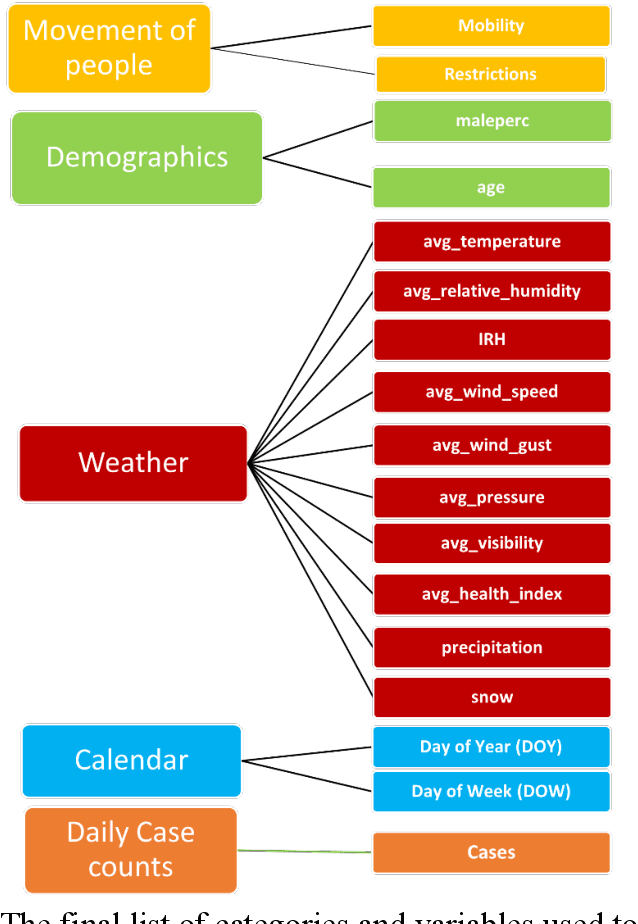
Objective: To develop machine learning models that can predict the number of COVID-19 cases per day given the last 14 days of environmental and mobility data. Approach: COVID-19 data from four counties around Toronto, Ontario, were used. Data were prepared into daily records containing the number of new COVID case counts, patient demographic data, outdoor weather variables, indoor environment factors, and human movement based on cell mobility and public health restrictions. This data was analyzed to determine the most important variables and their interactions. Predictive models were developed using CNN and LSTM deep neural network approaches. A 5-fold chronological cross-validation approach used these methods to develop predictive models using data from Mar 1 to Oct 14 2020, and test them on data covering Oct 15 to Dec 24 2020. Results: The best LSTM models forecasted tomorrow's daily COVID case counts with 90.7% accuracy, and the 7-day rolling average COVID case counts with 98.1% accuracy using independent test data. The best models to forecast the next 7 days of daily COVID case counts did so with 79.4% accuracy over all days. Models forecasting the 7-day rolling average case counts had a mean accuracy of 83.6% on the same test set. Conclusions: Our findings point to the importance of indoor humidity for the transmission of a virus such as COVID-19. During the coldest portions of the year, when humans spend greater amounts of time indoors or in vehicles, air quality drops within buildings, most significantly indoor relative humidity levels. Moderate to high indoor temperatures coupled with low IRH (below 20%) create conditions where viral transmission is more likely because water vapour ejected from an infected person's mouth can remain longer in the air because of evaporation and dry skin conditions, particularly in a recipient's airway, promotes transmission.
Machine learning for discovering laws of nature
Mar 18, 2023A microscopic particle obeys the principles of quantum mechanics -- so where is the sharp boundary between the macroscopic and microscopic worlds? It was this "interpretation problem" that prompted Schr\"odinger to propose his famous thought experiment (a cat that is simultaneously both dead and alive) and sparked a great debate about the quantum measurement problem, and there is still no satisfactory answer yet. This is precisely the inadequacy of rigorous mathematical models in describing the laws of nature. We propose a computational model to describe and understand the laws of nature based on Darwin's natural selection. In fact, whether it's a macro particle, a micro electron or a security, they can all be considered as an entity, the change of this entity over time can be described by a data series composed of states and values. An observer can learn from this data series to construct theories (usually consisting of functions and differential equations). We don't model with the usual functions or differential equations, but with a state Decision Tree (determines the state of an entity) and a value Function Tree (determines the distance between two points of an entity). A state Decision Tree and a value Function Tree together can reconstruct an entity's trajectory and make predictions about its future trajectory. Our proposed algorithmic model discovers laws of nature by only learning observed historical data (sequential measurement of observables) based on maximizing the observer's expected value. There is no differential equation in our model; our model has an emphasis on machine learning, where the observer builds up his/her experience by being rewarded or punished for each decision he/she makes, and eventually leads to rediscovering Newton's law, the Born rule (quantum mechanics) and the efficient market hypothesis (financial market).
Review of Time Series Forecasting Methods and Their Applications to Particle Accelerators
Sep 21, 2022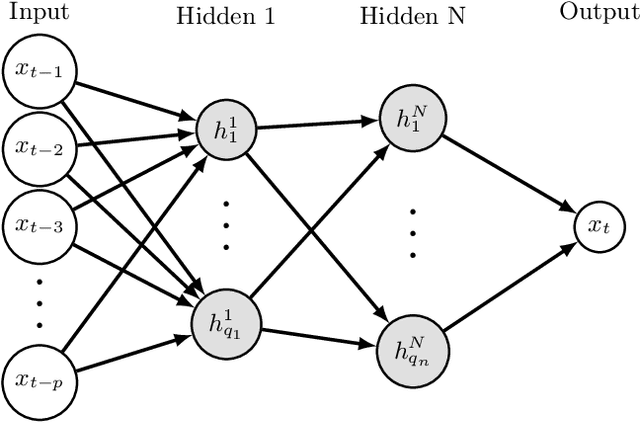
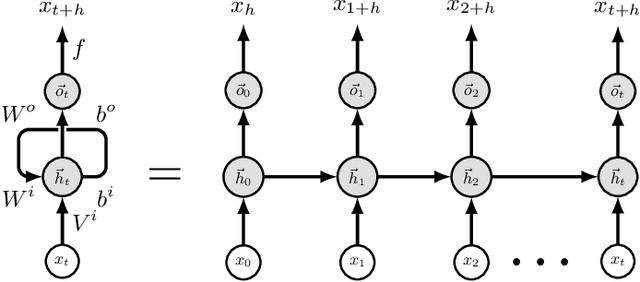
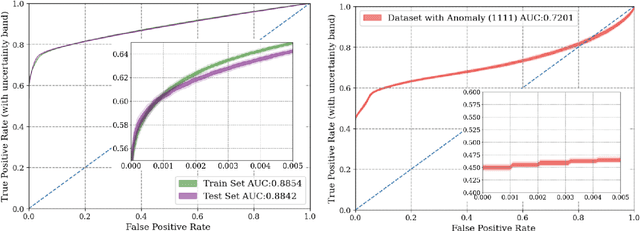
Particle accelerators are complex facilities that produce large amounts of structured data and have clear optimization goals as well as precisely defined control requirements. As such they are naturally amenable to data-driven research methodologies. The data from sensors and monitors inside the accelerator form multivariate time series. With fast pre-emptive approaches being highly preferred in accelerator control and diagnostics, the application of data-driven time series forecasting methods is particularly promising. This review formulates the time series forecasting problem and summarizes existing models with applications in various scientific areas. Several current and future attempts in the field of particle accelerators are introduced. The application of time series forecasting to particle accelerators has shown encouraging results and the promise for broader use, and existing problems such as data consistency and compatibility have started to be addressed.
Interpretable Deep Learning for Forecasting Online Advertising Costs: Insights from the Competitive Bidding Landscape
Feb 11, 2023
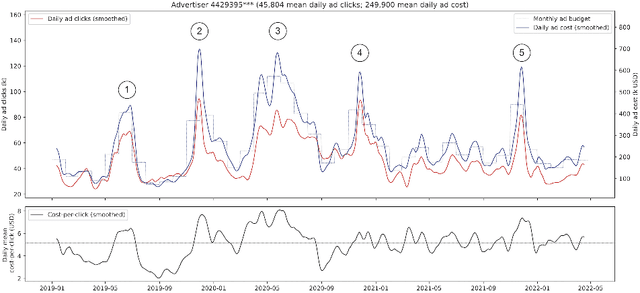
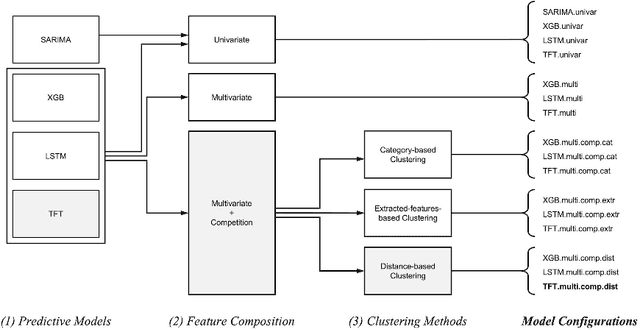
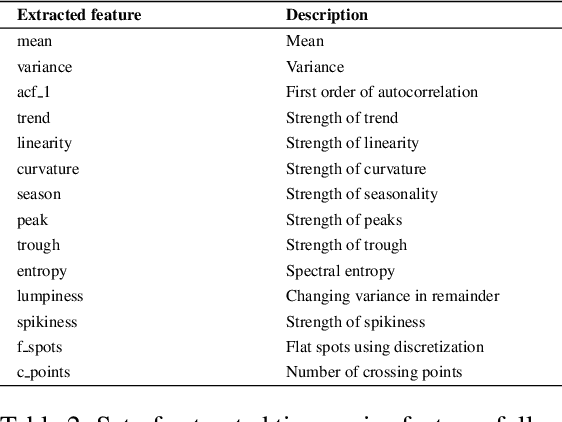
As advertisers increasingly shift their budgets toward digital advertising, forecasting advertising costs is essential for making budget plans to optimize marketing campaign returns. In this paper, we perform a comprehensive study using a variety of time-series forecasting methods to predict daily average cost-per-click (CPC) in the online advertising market. We show that forecasting advertising costs would benefit from multivariate models using covariates from competitors' CPC development identified through time-series clustering. We further interpret the results by analyzing feature importance and temporal attention. Finally, we show that our approach has several advantages over models that individual advertisers might build based solely on their collected data.
Optimizing Energy-Harvesting Hybrid VLC/RF Networks with Random Receiver Orientation
Feb 06, 2023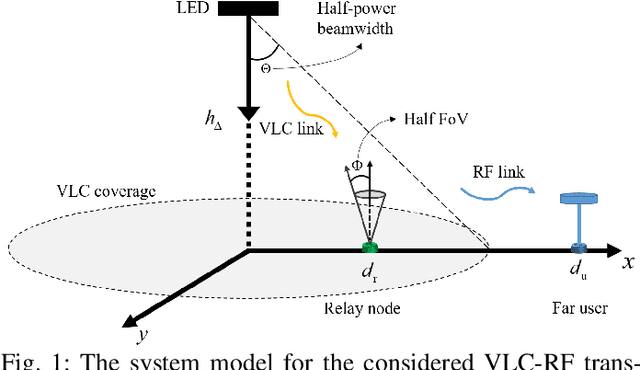
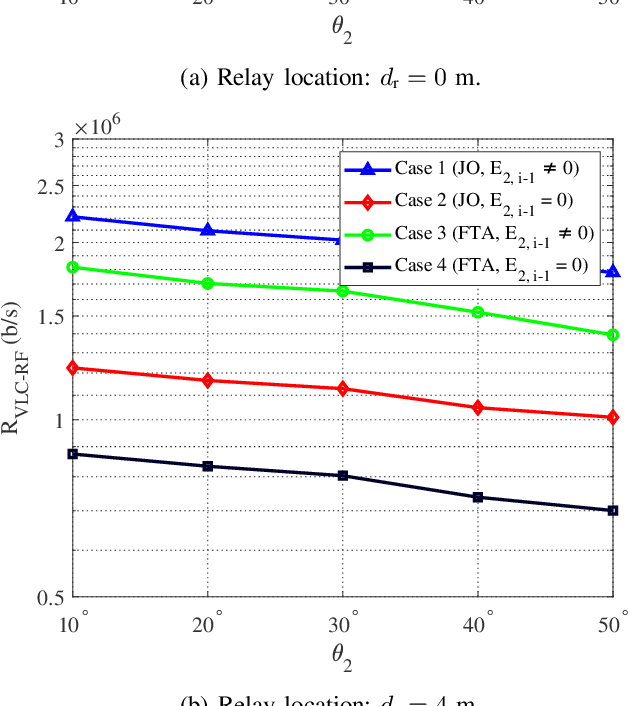
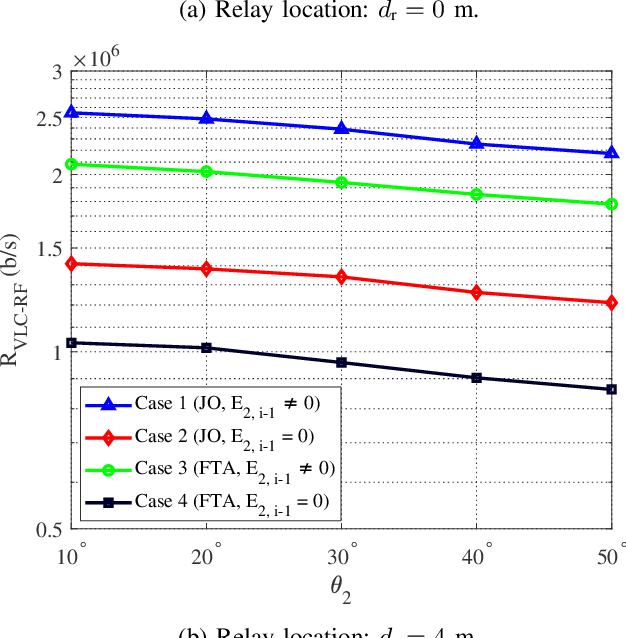
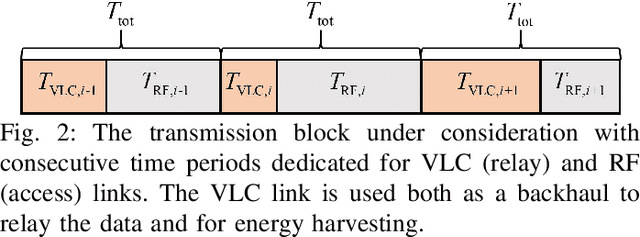
In this paper, we consider an indoor hybrid visible light communication (VLC) and radio frequency (RF) communication scenario with two-hop downlink transmission. The LED carries both data and energy in the first phase, VLC, to an energy harvester relay node, which then uses the harvested energy to re-transmit the decoded information to the RF user in the second phase, RF communication. The direct current (DC) bias and the assigned time duration for VLC transmission are taken into account as design parameters. The optimization problem is formulated to maximize the data rate with the assumption of decode-and-forward relaying for fixed receiver orientation. The non-convex optimization is split into two sub-problems and solved cyclically. It optimizes the data rate by solving two sub-problems: fixing time duration for VLC link to solve DC bias and fixing DC bias to solve time duration. The effect of random receiver orientation on the data rate is also studied, and closed-form expressions for both VLC and RF data rates are derived. The optimization is solved through an exhaustive search, and the results show that a higher data rate can be achieved by solving the joint problem of DC bias and time duration compared to solely optimizing the DC bias.
Classifying the evolution of COVID-19 severity on patients with combined dynamic Bayesian networks and neural networks
Mar 10, 2023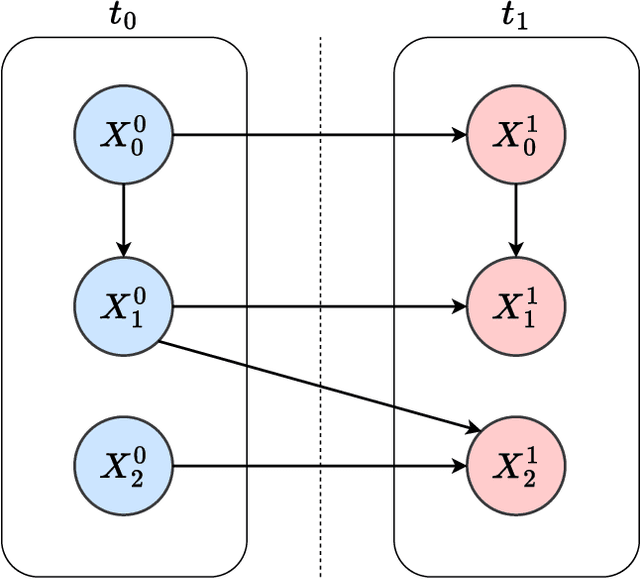
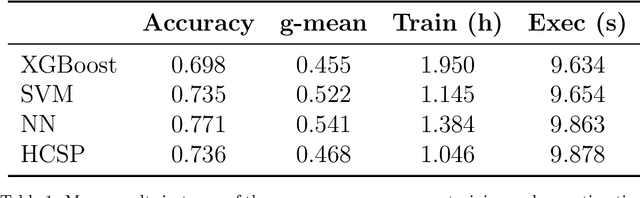
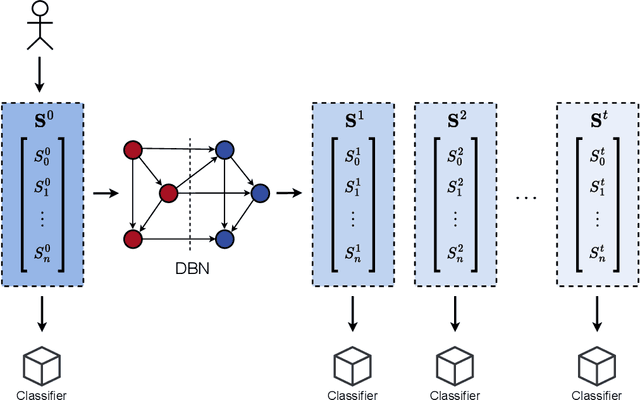
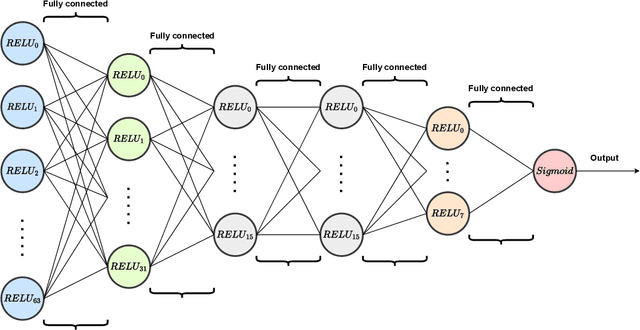
When we face patients arriving to a hospital suffering from the effects of some illness, one of the main problems we can encounter is evaluating whether or not said patients are going to require intensive care in the near future. This intensive care requires allotting valuable and scarce resources, and knowing beforehand the severity of a patients illness can improve both its treatment and the organization of resources. We illustrate this issue in a dataset consistent of Spanish COVID-19 patients from the sixth epidemic wave where we label patients as critical when they either had to enter the intensive care unit or passed away. We then combine the use of dynamic Bayesian networks, to forecast the vital signs and the blood analysis results of patients over the next 40 hours, and neural networks, to evaluate the severity of a patients disease in that interval of time. Our empirical results show that the transposition of the current state of a patient to future values with the DBN for its subsequent use in classification obtains better the accuracy and g-mean score than a direct application with a classifier.
Diffusion Policy: Visuomotor Policy Learning via Action Diffusion
Mar 10, 2023
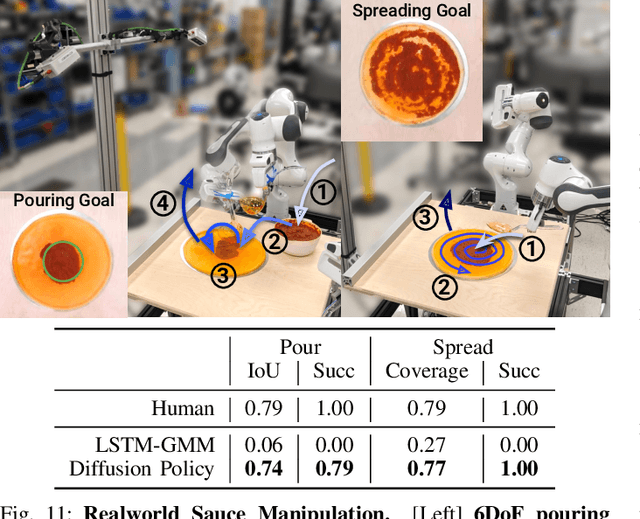
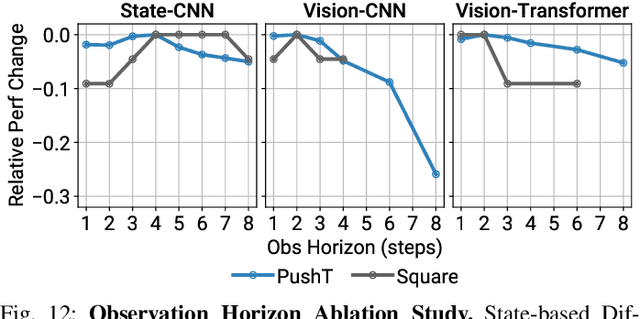
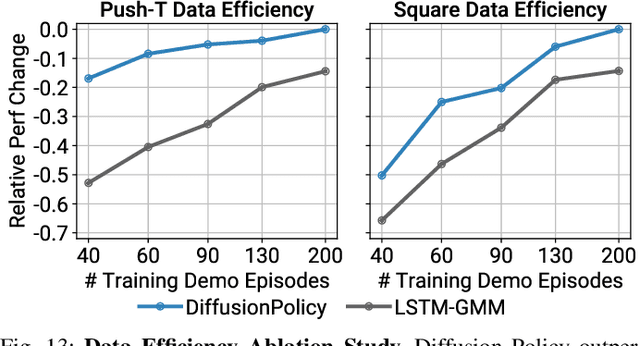
This paper introduces Diffusion Policy, a new way of generating robot behavior by representing a robot's visuomotor policy as a conditional denoising diffusion process. We benchmark Diffusion Policy across 11 different tasks from 4 different robot manipulation benchmarks and find that it consistently outperforms existing state-of-the-art robot learning methods with an average improvement of 46.9%. Diffusion Policy learns the gradient of the action-distribution score function and iteratively optimizes with respect to this gradient field during inference via a series of stochastic Langevin dynamics steps. We find that the diffusion formulation yields powerful advantages when used for robot policies, including gracefully handling multimodal action distributions, being suitable for high-dimensional action spaces, and exhibiting impressive training stability. To fully unlock the potential of diffusion models for visuomotor policy learning on physical robots, this paper presents a set of key technical contributions including the incorporation of receding horizon control, visual conditioning, and the time-series diffusion transformer. We hope this work will help motivate a new generation of policy learning techniques that are able to leverage the powerful generative modeling capabilities of diffusion models. Code, data, and training details will be publicly available.