 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Reinforcement Learning Aided Sequential Optimization for Unsignalized Intersection Management of Robot Traffic
Feb 10, 2023
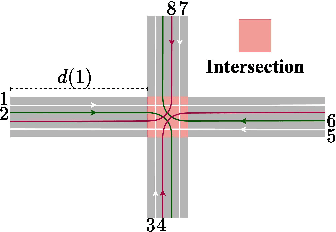

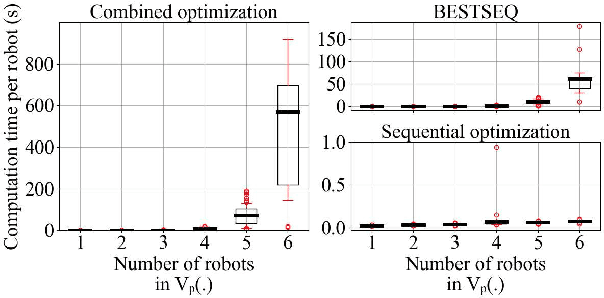
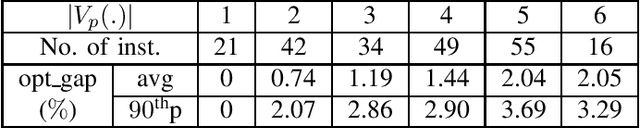
We consider the problem of optimal unsignalized intersection management for continual streams of randomly arriving robots. This problem involves solving many instances of a mixed integer program, for which the computation time using a naive optimization algorithm scales exponentially with the number of robots and lanes. Hence, such an approach is not suitable for real-time implementation. In this paper, we propose a solution framework that combines learning and sequential optimization. In particular, we propose an algorithm for learning a policy that given the traffic state information, determines the crossing order of the robots. Then, we optimize the trajectories of the robots sequentially according to that crossing order. The proposed algorithm learns a shared policy that can be deployed in a distributed manner. We validate the performance of this approach using extensive simulations. Our approach, on average, significantly outperforms the heuristics from the literature and gives near-optimal solutions. We also show through simulations that the computation time for our approach scales linearly with the number of robots.
Quickest Change Detection in Statistically Periodic Processes with Unknown Post-Change Distribution
Mar 06, 2023

Algorithms are developed for the quickest detection of a change in statistically periodic processes. These are processes in which the statistical properties are nonstationary but repeat after a fixed time interval. It is assumed that the pre-change law is known to the decision maker but the post-change law is unknown. In this framework, three families of problems are studied: robust quickest change detection, joint quickest change detection and classification, and multislot quickest change detection. In the multislot problem, the exact slot within a period where a change may occur is unknown. Algorithms are proposed for each problem, and either exact optimality or asymptotic optimal in the low false alarm regime is proved for each of them. The developed algorithms are then used for anomaly detection in traffic data and arrhythmia detection and identification in electrocardiogram (ECG) data. The effectiveness of the algorithms is also demonstrated on simulated data.
Iterative Convex Optimization for Model Predictive Control with Discrete-Time High-Order Control Barrier Functions
Oct 09, 2022
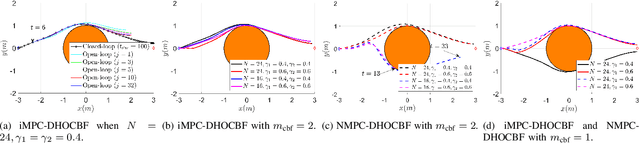
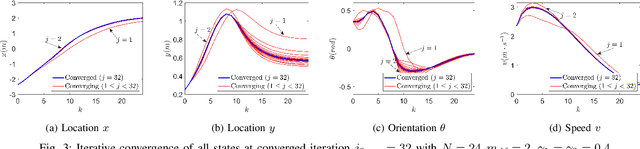
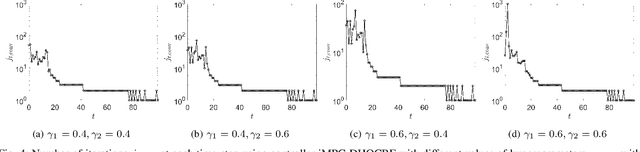
Safety is one of the fundamental challenges in control theory. Recently, multi-step optimal control problems for discrete-time dynamical systems were formulated to enforce stability, while subject to input constraints as well as safety-critical requirements using discrete-time control barrier functions within a model predictive control (MPC) framework. Existing work usually focus on the feasibility or the safety for the optimization problem, and the majority of the existing work restrict the discussions to relative-degree one for control barrier function. Additionally, the real-time computation is challenging when a large horizon is considered in the MPC problem for relative-degree one or high-order control barrier functions. In this paper, we propose a framework that solves the safety-critical MPC problem in an iterative optimization, which is applicable for any relative-degree control barrier functions. In the proposed formulation, the nonlinear system dynamics as well as the safety constraints modeled as discrete-time high-order control barrier functions (DHOCBF) are linearized at each time step. Our formulation is generally valid for any control barrier function with an arbitrary relative-degree. The advantages of fast computational performance with safety guarantee are analyzed and validated with numerical results.
GridCLIP: One-Stage Object Detection by Grid-Level CLIP Representation Learning
Mar 16, 2023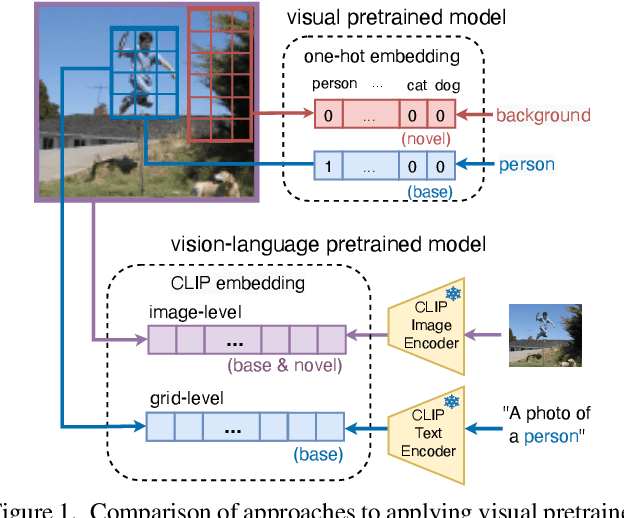
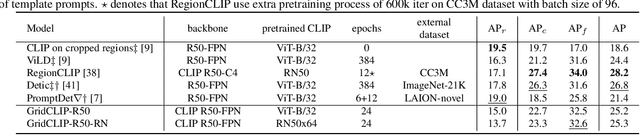
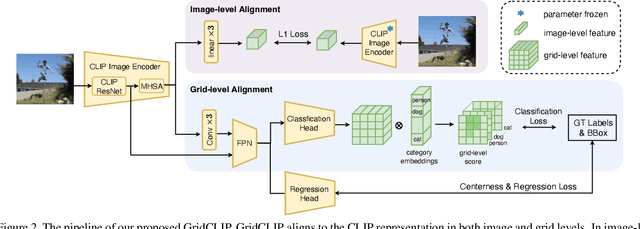

A vision-language foundation model pretrained on very large-scale image-text paired data has the potential to provide generalizable knowledge representation for downstream visual recognition and detection tasks, especially on supplementing the undersampled categories in downstream model training. Recent studies utilizing CLIP for object detection have shown that a two-stage detector design typically outperforms a one-stage detector, while requiring more expensive training resources and longer inference time. In this work, we propose a one-stage detector GridCLIP that narrows its performance gap to those of two-stage detectors, with approximately 43 and 5 times faster than its two-stage counterpart (ViLD) in the training and test process respectively. GridCLIP learns grid-level representations to adapt to the intrinsic principle of one-stage detection learning by expanding the conventional CLIP image-text holistic mapping to a more fine-grained, grid-text alignment. This differs from the region-text mapping in two-stage detectors that apply CLIP directly by treating regions as images. Specifically, GridCLIP performs Grid-level Alignment to adapt the CLIP image-level representations to grid-level representations by aligning to CLIP category representations to learn the annotated (especially frequent) categories. To learn generalizable visual representations of broader categories, especially undersampled ones, we perform Image-level Alignment during training to propagate broad pre-learned categories in the CLIP image encoder from the image-level to the grid-level representations. Experiments show that the learned CLIP-based grid-level representations boost the performance of undersampled (infrequent and novel) categories, reaching comparable detection performance on the LVIS benchmark.
Full-Body Cardiovascular Sensing with Remote Photoplethysmography
Mar 16, 2023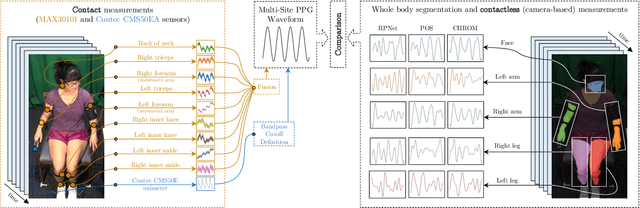


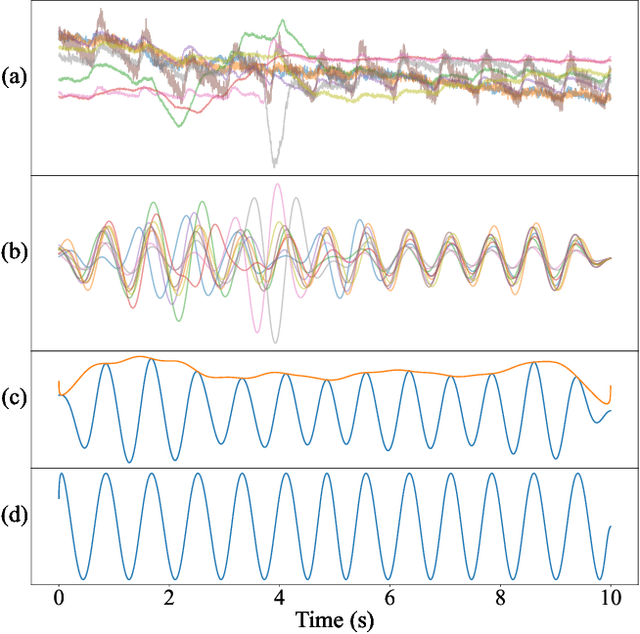
Remote photoplethysmography (rPPG) allows for noncontact monitoring of blood volume changes from a camera by detecting minor fluctuations in reflected light. Prior applications of rPPG focused on face videos. In this paper we explored the feasibility of rPPG from non-face body regions such as the arms, legs, and hands. We collected a new dataset titled Multi-Site Physiological Monitoring (MSPM), which will be released with this paper. The dataset consists of 90 frames per second video of exposed arms, legs, and face, along with 10 synchronized PPG recordings. We performed baseline heart rate estimation experiments from non-face regions with several state-of-the-art rPPG approaches, including chrominance-based (CHROM), plane-orthogonal-to-skin (POS) and RemotePulseNet (RPNet). To our knowledge, this is the first evaluation of the fidelity of rPPG signals simultaneously obtained from multiple regions of a human body. Our experiments showed that skin pixels from arms, legs, and hands are all potential sources of the blood volume pulse. The best-performing approach, POS, achieved a mean absolute error peaking at 7.11 beats per minute from non-facial body parts compared to 1.38 beats per minute from the face. Additionally, we performed experiments on pulse transit time (PTT) from both the contact PPG and rPPG signals. We found that remote PTT is possible with moderately high frame rate video when distal locations on the body are visible. These findings and the supporting dataset should facilitate new research on non-face rPPG and monitoring blood flow dynamics over the whole body with a camera.
Online Re-Planning and Adaptive Parameter Update for Multi-Agent Path Finding with Stochastic Travel Times
Feb 03, 2023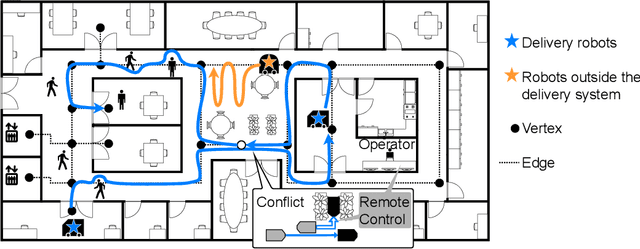
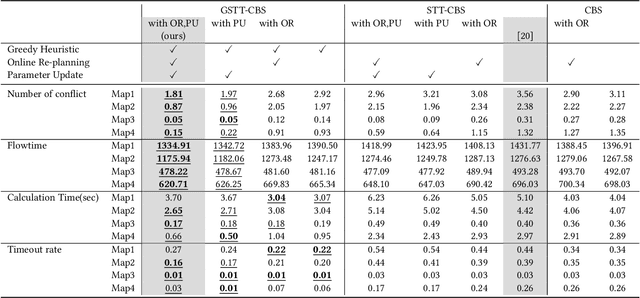
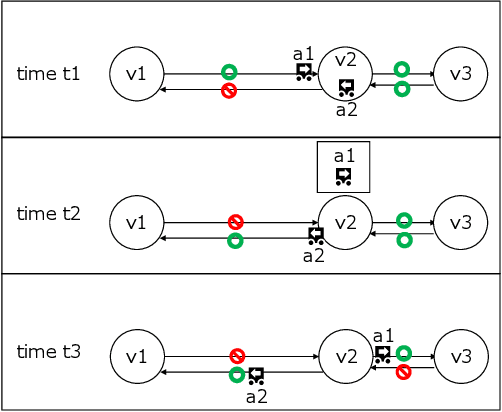
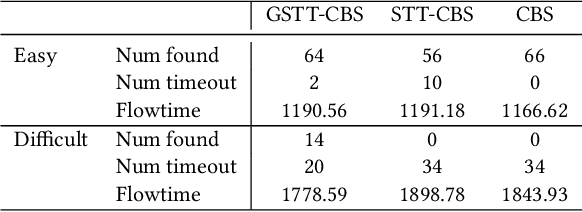
This study explores the problem of Multi-Agent Path Finding with continuous and stochastic travel times whose probability distribution is unknown. Our purpose is to manage a group of automated robots that provide package delivery services in a building where pedestrians and a wide variety of robots coexist, such as delivery services in office buildings, hospitals, and apartments. It is often the case with these real-world applications that the time required for the robots to traverse a corridor takes a continuous value and is randomly distributed, and the prior knowledge of the probability distribution of the travel time is limited. Multi-Agent Path Finding has been widely studied and applied to robot management systems; however, automating the robot operation in such environments remains difficult. We propose 1) online re-planning to update the action plan of robots while it is executed, and 2) parameter update to estimate the probability distribution of travel time using Bayesian inference as the delay is observed. We use a greedy heuristic to obtain solutions in a limited computation time. Through simulations, we empirically compare the performance of our method to those of existing methods in terms of the conflict probability and the actual travel time of robots. The simulation results indicate that the proposed method can find travel paths with at least 50% fewer conflicts and a shorter actual total travel time than existing methods. The proposed method requires a small number of trials to achieve the performance because the parameter update is prioritized on the important edges for path planning, thereby satisfying the requirements of quick implementation of robust planning of automated delivery services.
A Dynamic Temporal Self-attention Graph Convolutional Network for Traffic Prediction
Feb 21, 2023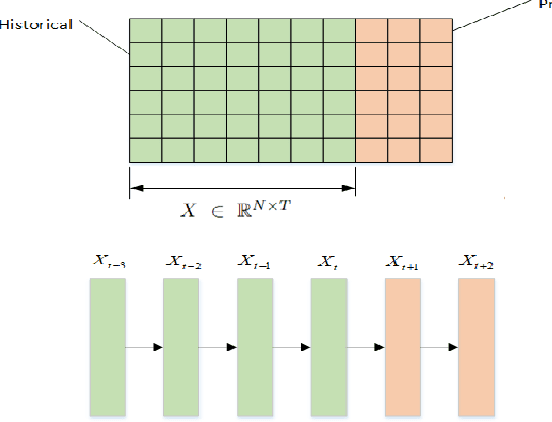
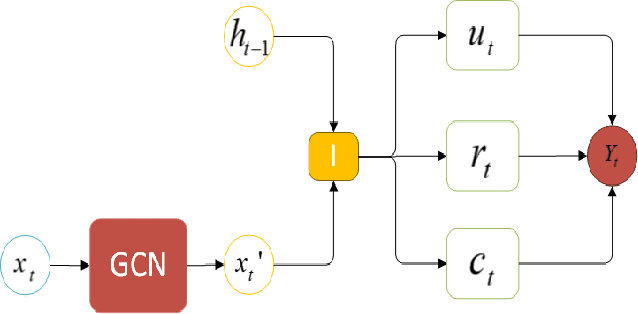
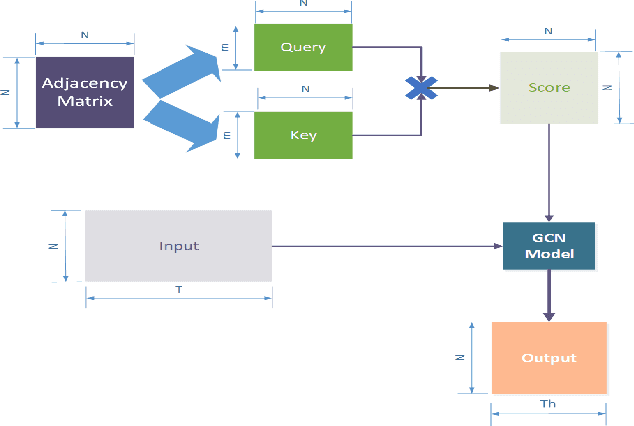
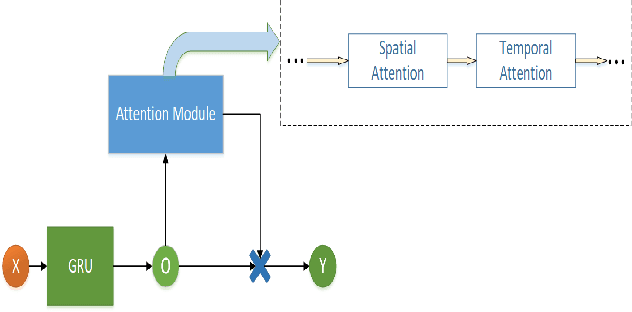
Accurate traffic prediction in real time plays an important role in Intelligent Transportation System (ITS) and travel navigation guidance. There have been many attempts to predict short-term traffic status which consider the spatial and temporal dependencies of traffic information such as temporal graph convolutional network (T-GCN) model and convolutional long short-term memory (Conv-LSTM) model. However, most existing methods use simple adjacent matrix consisting of 0 and 1 to capture the spatial dependence which can not meticulously describe the urban road network topological structure and the law of dynamic change with time. In order to tackle the problem, this paper proposes a dynamic temporal self-attention graph convolutional network (DT-SGN) model which considers the adjacent matrix as a trainable attention score matrix and adapts network parameters to different inputs. Specially, self-attention graph convolutional network (SGN) is chosen to capture the spatial dependence and the dynamic gated recurrent unit (Dynamic-GRU) is chosen to capture temporal dependence and learn dynamic changes of input data. Experiments demonstrate the superiority of our method over state-of-art model-driven model and data-driven models on real-world traffic datasets.
Fuzziness-tuned: Improving the Transferability of Adversarial Examples
Mar 17, 2023
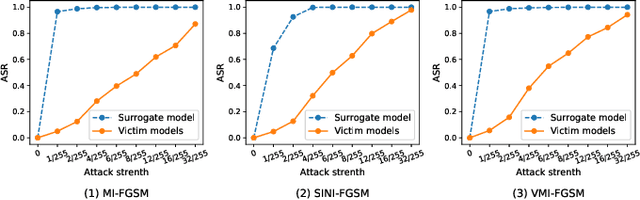
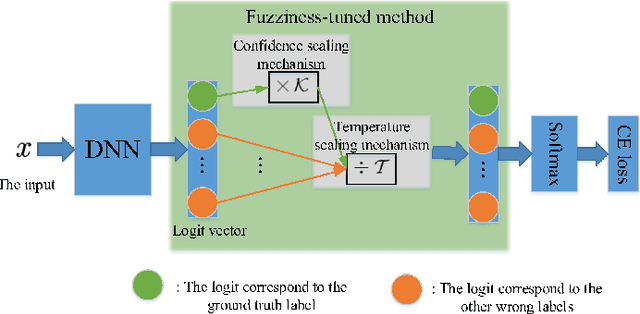
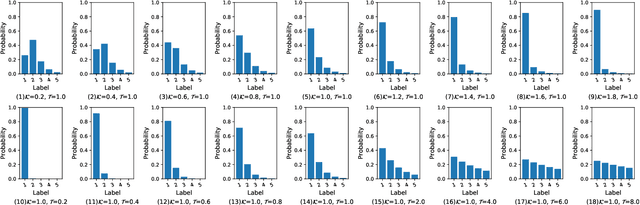
With the development of adversarial attacks, adversairal examples have been widely used to enhance the robustness of the training models on deep neural networks. Although considerable efforts of adversarial attacks on improving the transferability of adversarial examples have been developed, the attack success rate of the transfer-based attacks on the surrogate model is much higher than that on victim model under the low attack strength (e.g., the attack strength $\epsilon=8/255$). In this paper, we first systematically investigated this issue and found that the enormous difference of attack success rates between the surrogate model and victim model is caused by the existence of a special area (known as fuzzy domain in our paper), in which the adversarial examples in the area are classified wrongly by the surrogate model while correctly by the victim model. Then, to eliminate such enormous difference of attack success rates for improving the transferability of generated adversarial examples, a fuzziness-tuned method consisting of confidence scaling mechanism and temperature scaling mechanism is proposed to ensure the generated adversarial examples can effectively skip out of the fuzzy domain. The confidence scaling mechanism and the temperature scaling mechanism can collaboratively tune the fuzziness of the generated adversarial examples through adjusting the gradient descent weight of fuzziness and stabilizing the update direction, respectively. Specifically, the proposed fuzziness-tuned method can be effectively integrated with existing adversarial attacks to further improve the transferability of adverarial examples without changing the time complexity. Extensive experiments demonstrated that fuzziness-tuned method can effectively enhance the transferability of adversarial examples in the latest transfer-based attacks.
Posterior Estimation Using Deep Learning: A Simulation Study of Compartmental Modeling in Dynamic PET
Mar 17, 2023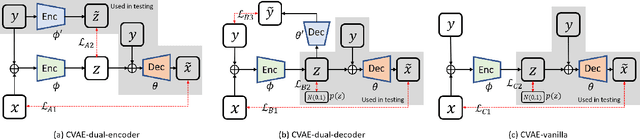
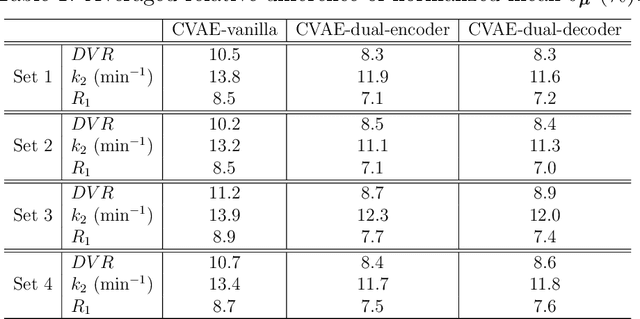
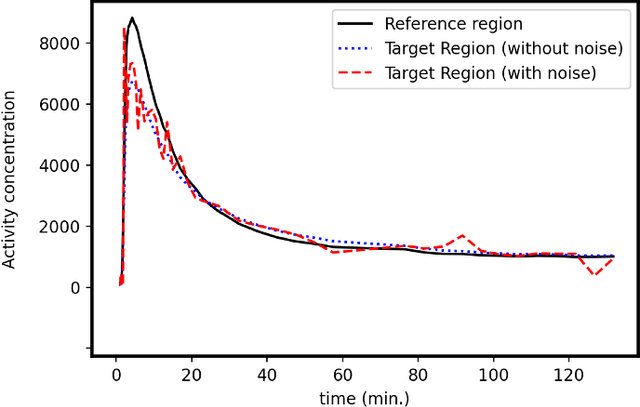
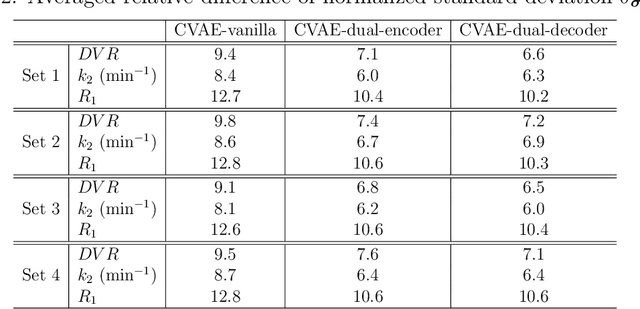
Background: In medical imaging, images are usually treated as deterministic, while their uncertainties are largely underexplored. Purpose: This work aims at using deep learning to efficiently estimate posterior distributions of imaging parameters, which in turn can be used to derive the most probable parameters as well as their uncertainties. Methods: Our deep learning-based approaches are based on a variational Bayesian inference framework, which is implemented using two different deep neural networks based on conditional variational auto-encoder (CVAE), CVAE-dual-encoder and CVAE-dual-decoder. The conventional CVAE framework, i.e., CVAE-vanilla, can be regarded as a simplified case of these two neural networks. We applied these approaches to a simulation study of dynamic brain PET imaging using a reference region-based kinetic model. Results: In the simulation study, we estimated posterior distributions of PET kinetic parameters given a measurement of time-activity curve. Our proposed CVAE-dual-encoder and CVAE-dual-decoder yield results that are in good agreement with the asymptotically unbiased posterior distributions sampled by Markov Chain Monte Carlo (MCMC). The CVAE-vanilla can also be used for estimating posterior distributions, although it has an inferior performance to both CVAE-dual-encoder and CVAE-dual-decoder. Conclusions: We have evaluated the performance of our deep learning approaches for estimating posterior distributions in dynamic brain PET. Our deep learning approaches yield posterior distributions, which are in good agreement with unbiased distributions estimated by MCMC. All these neural networks have different characteristics and can be chosen by the user for specific applications. The proposed methods are general and can be adapted to other problems.
Tightness of prescriptive tree-based mixed-integer optimization formulations
Feb 28, 2023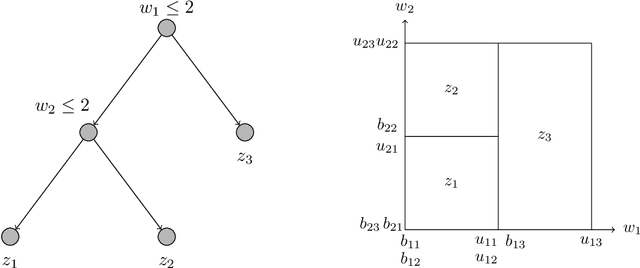
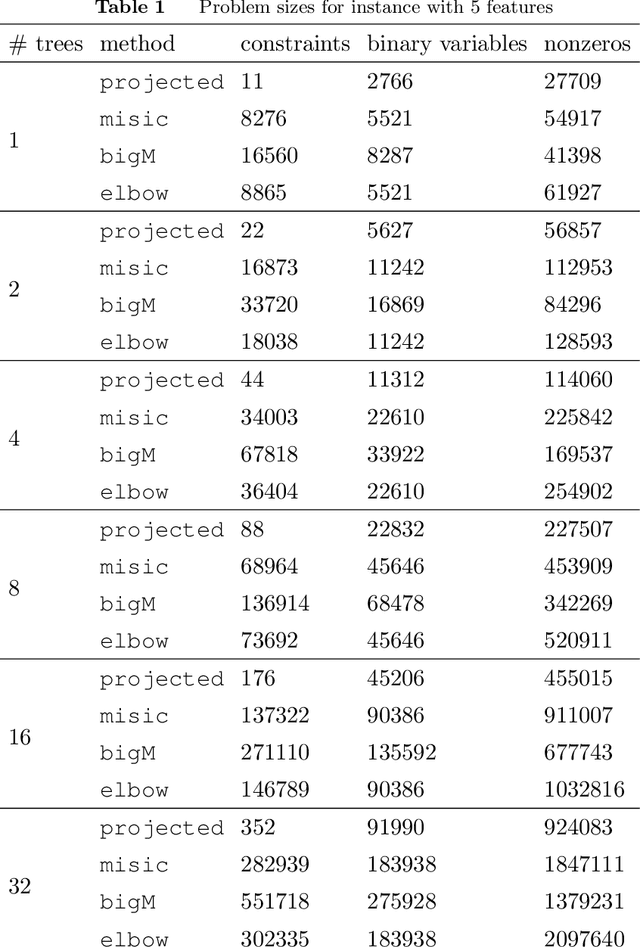
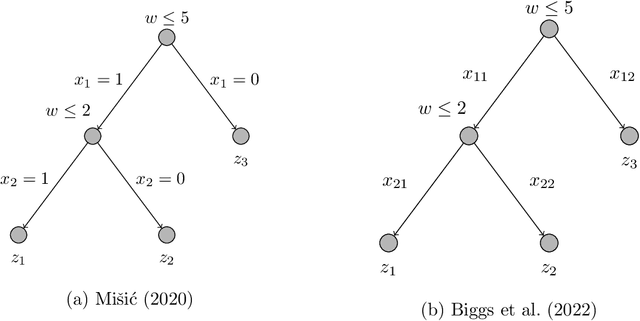
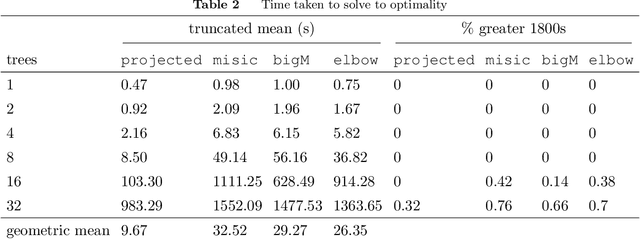
We focus on modeling the relationship between an input feature vector and the predicted outcome of a trained decision tree using mixed-integer optimization. This can be used in many practical applications where a decision tree or tree ensemble is incorporated into an optimization problem to model the predicted outcomes of a decision. We propose tighter mixed-integer optimization formulations than those previously introduced. Existing formulations can be shown to have linear relaxations that have fractional extreme points, even for the simple case of modeling a single decision tree. A formulation we propose, based on a projected union of polyhedra approach, is ideal for a single decision tree. While the formulation is generally not ideal for tree ensembles or if additional constraints are added, it generally has fewer extreme points, leading to a faster time to solve, particularly if the formulation has relatively few trees. However, previous work has shown that formulations based on a binary representation of the feature vector perform well computationally and hence are attractive for use in practical applications. We present multiple approaches to tighten existing formulations with binary vectors, and show that fractional extreme points are removed when there are multiple splits on the same feature. At an extreme, we prove that this results in ideal formulations for tree ensembles modeling a one-dimensional feature vector. Building on this result, we also show via numerical simulations that these additional constraints result in significantly tighter linear relaxations when the feature vector is low dimensional. We also present instances where the time to solve to optimality is significantly improved using these formulations.