 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Finding Similar Exercises in Retrieval Manner
Mar 15, 2023



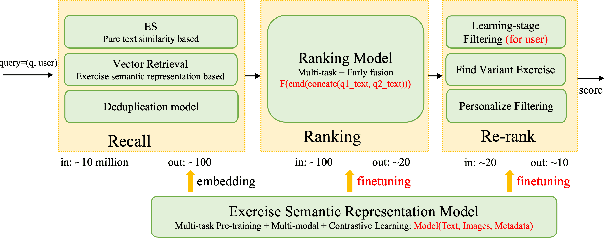
When students make a mistake in an exercise, they can consolidate it by ``similar exercises'' which have the same concepts, purposes and methods. Commonly, for a certain subject and study stage, the size of the exercise bank is in the range of millions to even tens of millions, how to find similar exercises for a given exercise becomes a crucial technical problem. Generally, we can assign a variety of explicit labels to the exercise, and then query through the labels, but the label annotation is time-consuming, laborious and costly, with limited precision and granularity, so it is not feasible. In practice, we define ``similar exercises'' as a retrieval process of finding a set of similar exercises based on recall, ranking and re-rank procedures, called the \textbf{FSE} problem (Finding similar exercises). Furthermore, comprehensive representation of the semantic information of exercises was obtained through representation learning. In addition to the reasonable architecture, we also explore what kind of tasks are more conducive to the learning of exercise semantic information from pre-training and supervised learning. It is difficult to annotate similar exercises and the annotation consistency among experts is low. Therefore this paper also provides solutions to solve the problem of low-quality annotated data. Compared with other methods, this paper has obvious advantages in both architecture rationality and algorithm precision, which now serves the daily teaching of hundreds of schools.
* 37th Conference on AAAI 2023 Artificial Intelligence for Education(AI4Edu)
Multi label classification of Artificial Intelligence related patents using Modified D2SBERT and Sentence Attention mechanism
Mar 03, 2023
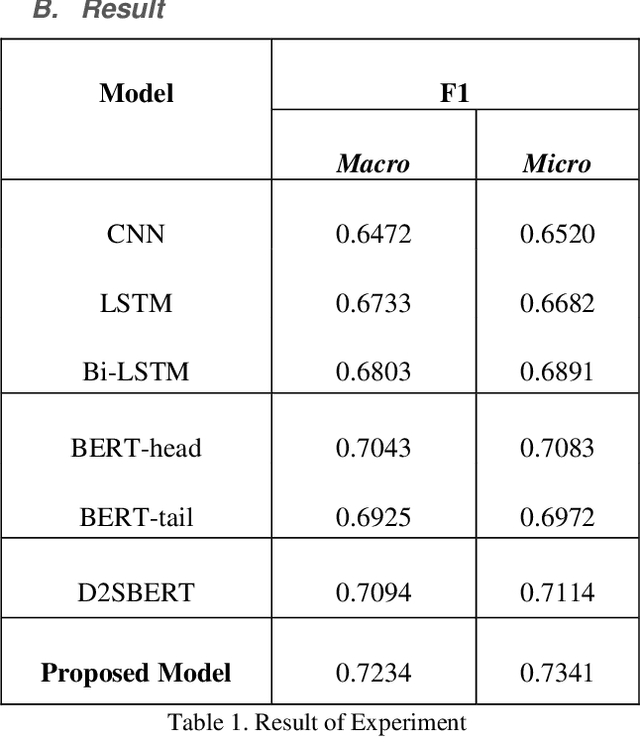
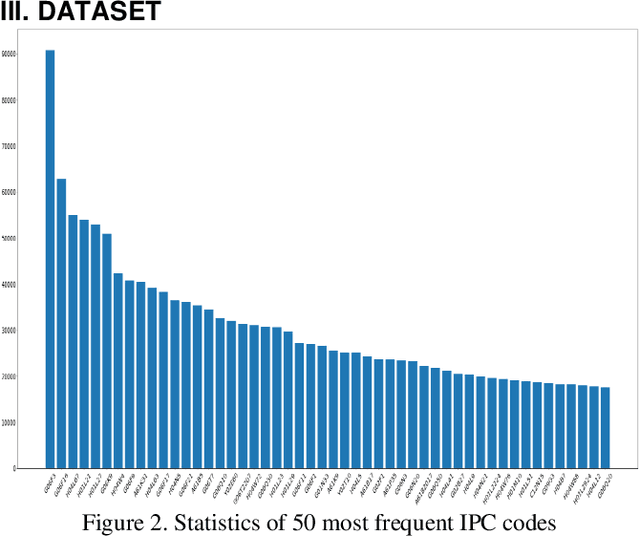
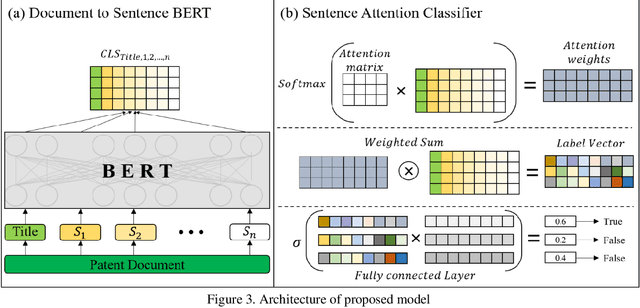
Patent classification is an essential task in patent information management and patent knowledge mining. It is very important to classify patents related to artificial intelligence, which is the biggest topic these days. However, artificial intelligence-related patents are very difficult to classify because it is a mixture of complex technologies and legal terms. Moreover, due to the unsatisfactory performance of current algorithms, it is still mostly done manually, wasting a lot of time and money. Therefore, we present a method for classifying artificial intelligence-related patents published by the USPTO using natural language processing technique and deep learning methodology. We use deformed BERT and sentence attention overcome the limitations of BERT. Our experiment result is highest performance compared to other deep learning methods.
Atrial Fibrillation Detection Using RR-Intervals for Application in Photoplethysmographs
Feb 13, 2023
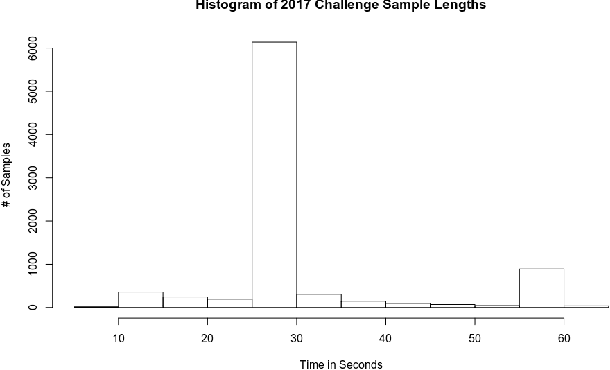

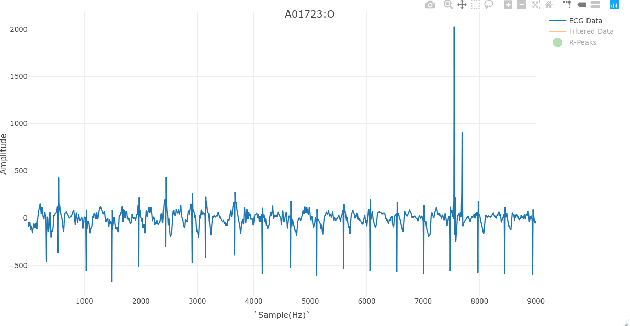
Atrial Fibrillation is a common form of irregular heart rhythm that can be very dangerous. Our primary goal is to analyze Atrial Fibrillation data within ECGs to develop a model based only on RR-Intervals, or the length between heart-beats, to create a real time classification model for Atrial Fibrillation to be implemented in common heart-rate monitors on the market today. Physionet's MIT-BIH Atrial Fibrillation Database \cite{goldberger2000physiobank} and 2017 Challenge Database \cite{clifford2017af} were used to identify patterns of Atrial Fibrillation and test classification models on. These two datasets are very different. The MIT-BIH database contains long samples taken with a medical grade device, which is not useful for simulating a consumer device, but is useful for Atrial Fibrillation pattern detection. The 2017 Challenge database includes short ($<60sec$) samples taken with a portable device and reveals many of the challenges of Atrial Fibrillation classification in a real-time device. We developed multiple SVM models with three sets of extracted features as predictor variables which gave us moderately high accuracies with low computational intensity. With robust filtering techniques already applied in many Photoplethysmograph-based consumer heart-rate monitors, this method can be used to develop a reliable real time model for Atrial Fibrillation detection in consumer-grade heart-rate monitors.
Reinforcement Learning Aided Sequential Optimization for Unsignalized Intersection Management of Robot Traffic
Feb 10, 2023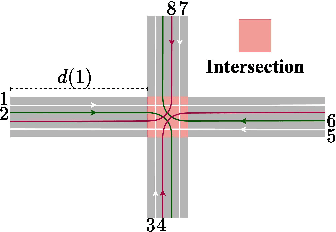

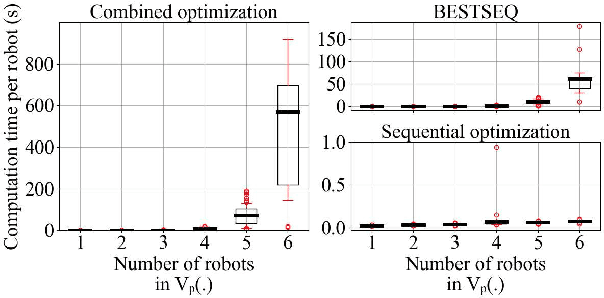
We consider the problem of optimal unsignalized intersection management for continual streams of randomly arriving robots. This problem involves solving many instances of a mixed integer program, for which the computation time using a naive optimization algorithm scales exponentially with the number of robots and lanes. Hence, such an approach is not suitable for real-time implementation. In this paper, we propose a solution framework that combines learning and sequential optimization. In particular, we propose an algorithm for learning a policy that given the traffic state information, determines the crossing order of the robots. Then, we optimize the trajectories of the robots sequentially according to that crossing order. The proposed algorithm learns a shared policy that can be deployed in a distributed manner. We validate the performance of this approach using extensive simulations. Our approach, on average, significantly outperforms the heuristics from the literature and gives near-optimal solutions. We also show through simulations that the computation time for our approach scales linearly with the number of robots.
Could a Large Language Model be Conscious?
Mar 04, 2023There has recently been widespread discussion of whether large language models might be sentient or conscious. Should we take this idea seriously? I will discuss the underlying issue and will break down the strongest reasons for and against. I suggest that given mainstream assumptions in the science of consciousness, there are significant obstacles to consciousness in current models: for example, their lack of recurrent processing, a global workspace, and unified agency. At the same time, it is quite possible that these obstacles will be overcome in the next decade or so. I conclude that while it is somewhat unlikely that current large language models are conscious, we should take seriously the possibility that extensions and successors to large language models may be conscious in the not-too-distant future.
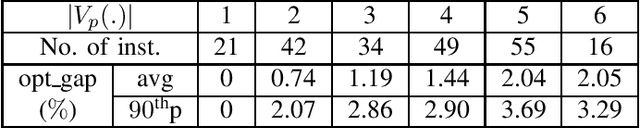
Interactive Trajectory Planner for Mandatory Lane Changing in Dense Non-Cooperative Traffic
Mar 04, 2023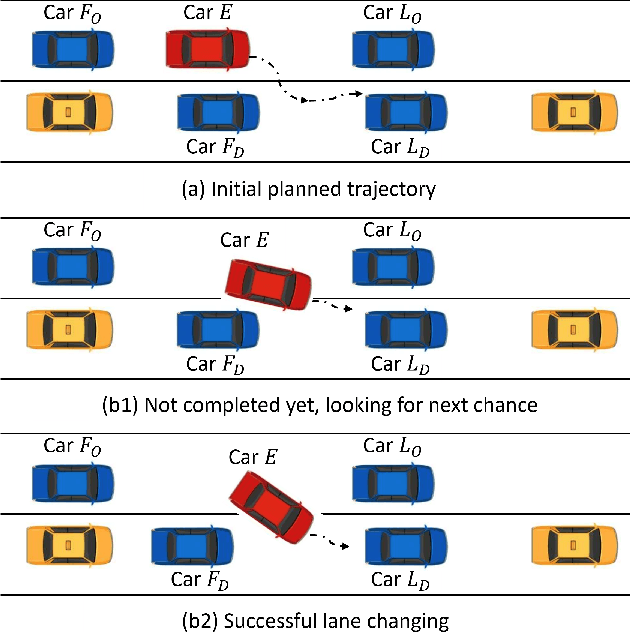
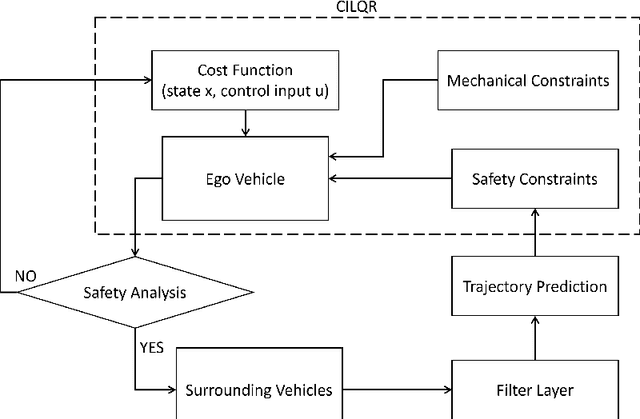
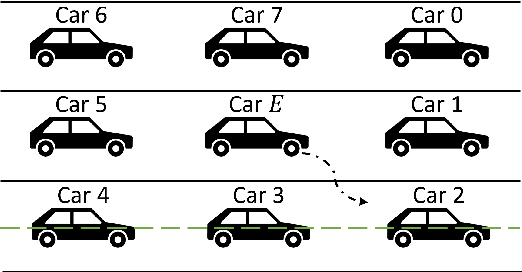
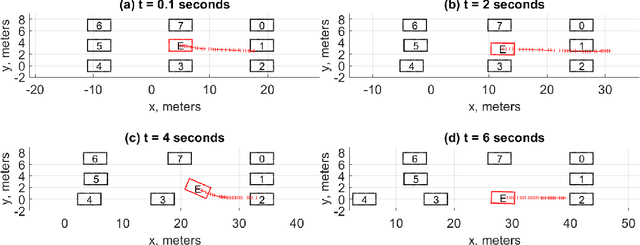
When the traffic stream is extremely congested and surrounding vehicles are not cooperative, the mandatory lane changing can be significantly difficult. In this work, we propose an interactive trajectory planner, which will firstly attempt to change lanes as long as safety is ensured. Based on receding horizon planning, the ego vehicle can abort or continue changing lanes according to surrounding vehicles' reactions. We demonstrate the performance of our planner in extensive simulations with eight surrounding vehicles, initial velocity ranging from 0.5 to 5 meters per second, and bumper to bumper gap ranging from 4 to 10 meters. The ego vehicle with our planner can change lanes safely and smoothly. The computation time of the planner at every step is within 10 milliseconds in most cases on a laptop with 1.8GHz Intel Core i7-10610U.
Online Re-Planning and Adaptive Parameter Update for Multi-Agent Path Finding with Stochastic Travel Times
Feb 03, 2023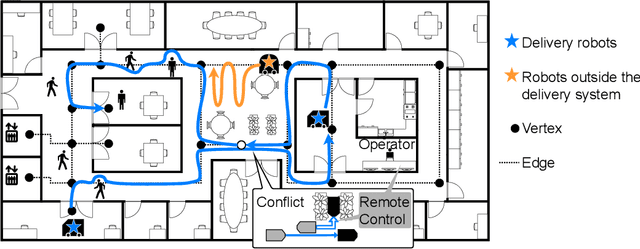
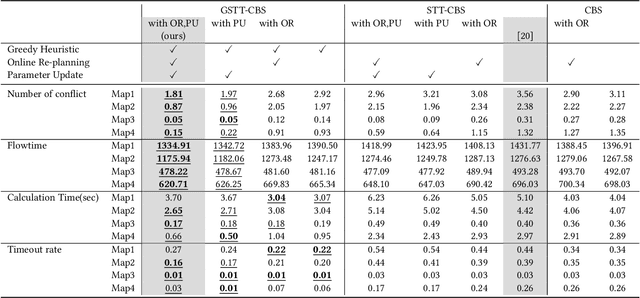
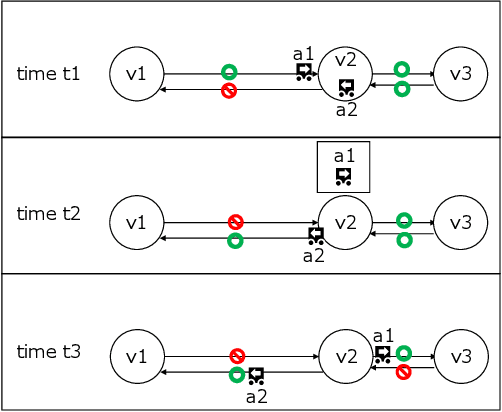
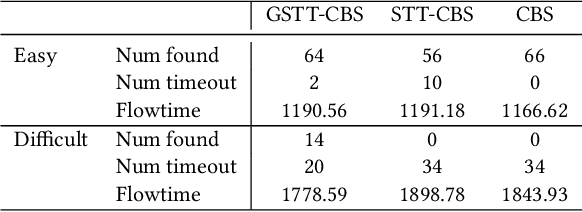
This study explores the problem of Multi-Agent Path Finding with continuous and stochastic travel times whose probability distribution is unknown. Our purpose is to manage a group of automated robots that provide package delivery services in a building where pedestrians and a wide variety of robots coexist, such as delivery services in office buildings, hospitals, and apartments. It is often the case with these real-world applications that the time required for the robots to traverse a corridor takes a continuous value and is randomly distributed, and the prior knowledge of the probability distribution of the travel time is limited. Multi-Agent Path Finding has been widely studied and applied to robot management systems; however, automating the robot operation in such environments remains difficult. We propose 1) online re-planning to update the action plan of robots while it is executed, and 2) parameter update to estimate the probability distribution of travel time using Bayesian inference as the delay is observed. We use a greedy heuristic to obtain solutions in a limited computation time. Through simulations, we empirically compare the performance of our method to those of existing methods in terms of the conflict probability and the actual travel time of robots. The simulation results indicate that the proposed method can find travel paths with at least 50% fewer conflicts and a shorter actual total travel time than existing methods. The proposed method requires a small number of trials to achieve the performance because the parameter update is prioritized on the important edges for path planning, thereby satisfying the requirements of quick implementation of robust planning of automated delivery services.
FSVVD: A Dataset of Full Scene Volumetric Video
Mar 07, 2023
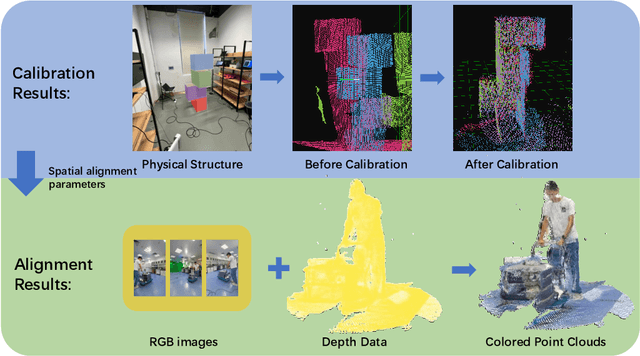
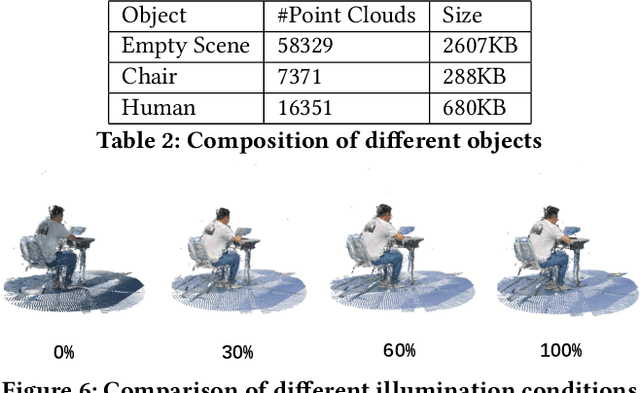
Recent years have witnessed a rapid development of immersive multimedia which bridges the gap between the real world and virtual space. Volumetric videos, as an emerging representative 3D video paradigm that empowers extended reality, stand out to provide unprecedented immersive and interactive video watching experience. Despite the tremendous potential, the research towards 3D volumetric video is still in its infancy, relying on sufficient and complete datasets for further exploration. However, existing related volumetric video datasets mostly only include a single object, lacking details about the scene and the interaction between them. In this paper, we focus on the current most widely used data format, point cloud, and for the first time release a full-scene volumetric video dataset that includes multiple people and their daily activities interacting with the external environments. Comprehensive dataset description and analysis are conducted, with potential usage of this dataset. The dataset and additional tools can be accessed via the following website: https://cuhksz-inml.github.io/full_scene_volumetric_video_dataset/.
New Perspectives on Regularization and Computation in Optimal Transport-Based Distributionally Robust Optimization
Mar 07, 2023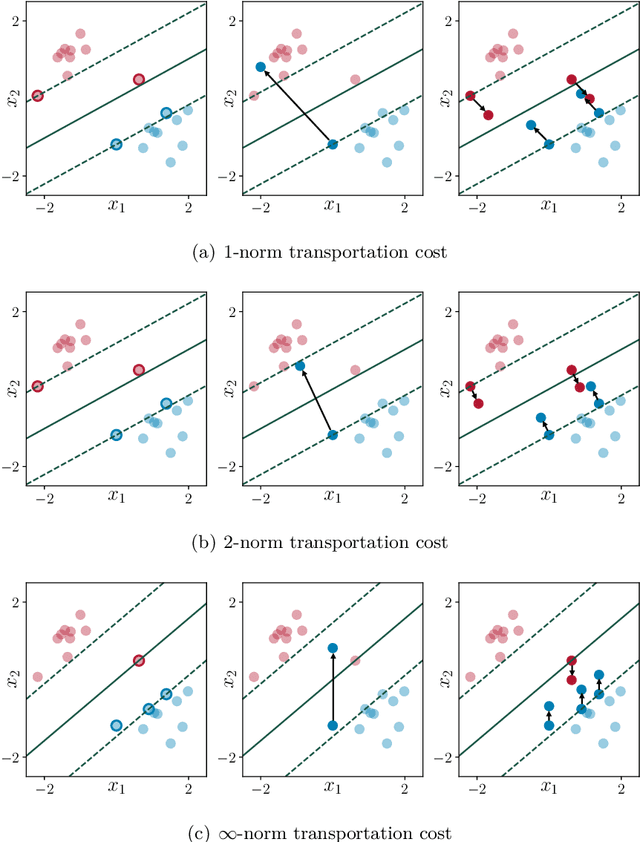
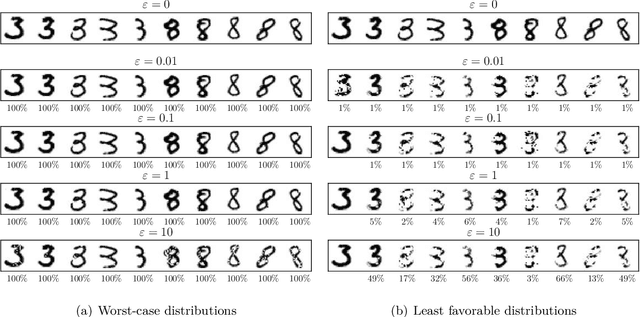
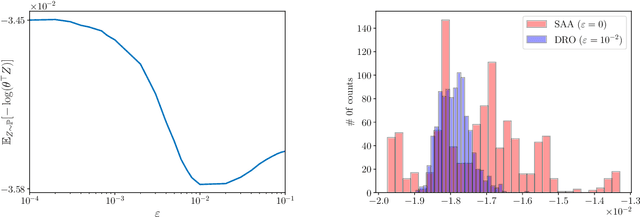
We study optimal transport-based distributionally robust optimization problems where a fictitious adversary, often envisioned as nature, can choose the distribution of the uncertain problem parameters by reshaping a prescribed reference distribution at a finite transportation cost. In this framework, we show that robustification is intimately related to various forms of variation and Lipschitz regularization even if the transportation cost function fails to be (some power of) a metric. We also derive conditions for the existence and the computability of a Nash equilibrium between the decision-maker and nature, and we demonstrate numerically that nature's Nash strategy can be viewed as a distribution that is supported on remarkably deceptive adversarial samples. Finally, we identify practically relevant classes of optimal transport-based distributionally robust optimization problems that can be addressed with efficient gradient descent algorithms even if the loss function or the transportation cost function are nonconvex (but not both at the same time).
Can discrete information extraction prompts generalize across language models?
Mar 07, 2023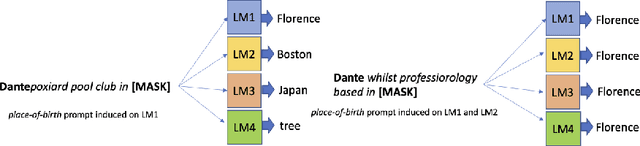
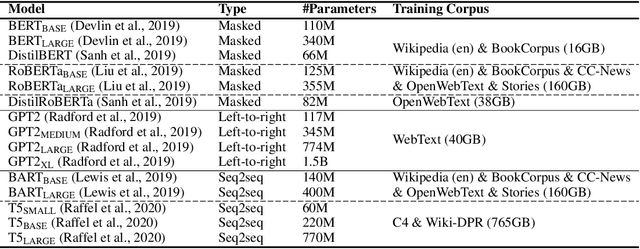
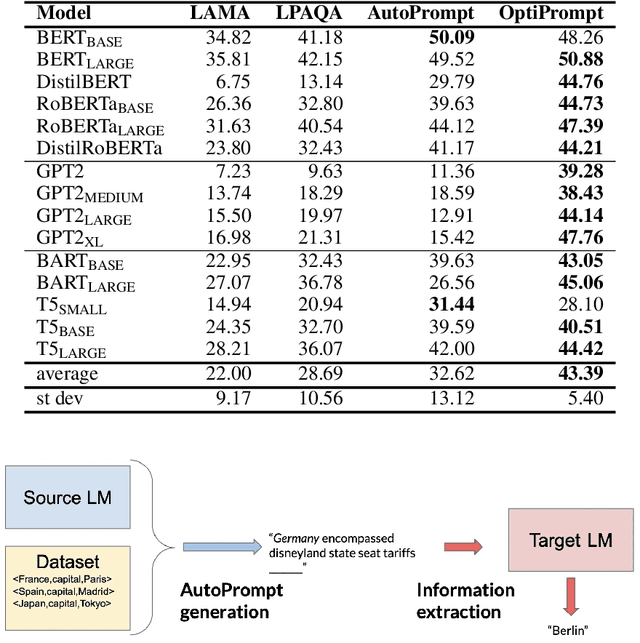
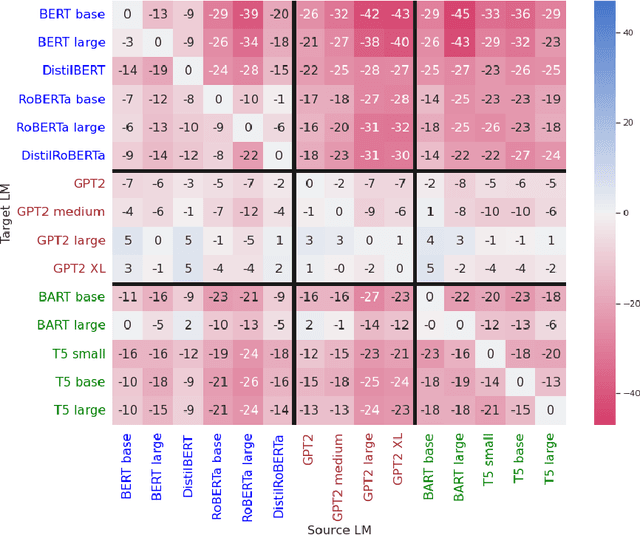
We study whether automatically-induced prompts that effectively extract information from a language model can also be used, out-of-the-box, to probe other language models for the same information. After confirming that discrete prompts induced with the AutoPrompt algorithm outperform manual and semi-manual prompts on the slot-filling task, we demonstrate a drop in performance for AutoPrompt prompts learned on a model and tested on another. We introduce a way to induce prompts by mixing language models at training time that results in prompts that generalize well across models. We conduct an extensive analysis of the induced prompts, finding that the more general prompts include a larger proportion of existing English words and have a less order-dependent and more uniform distribution of information across their component tokens. Our work provides preliminary evidence that it's possible to generate discrete prompts that can be induced once and used with a number of different models, and gives insights on the properties characterizing such prompts.