 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
An Active Learning Based Robot Kinematic Calibration Framework Using Gaussian Processes
Mar 07, 2023
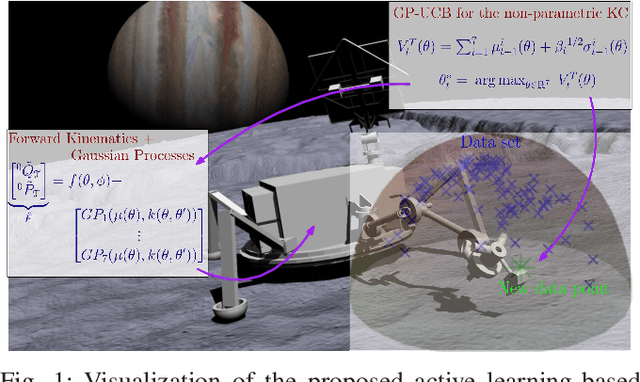
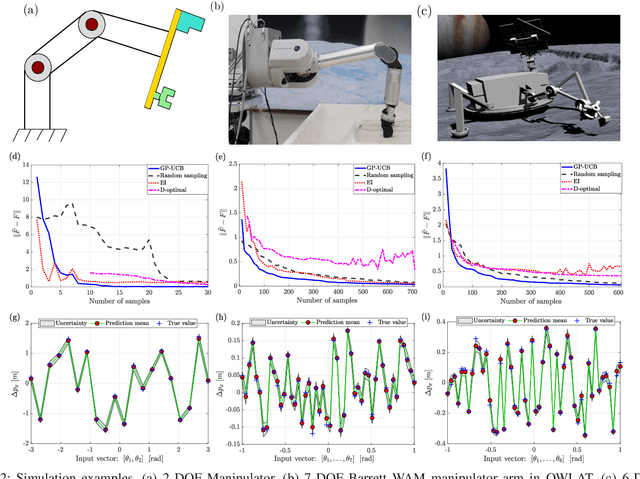
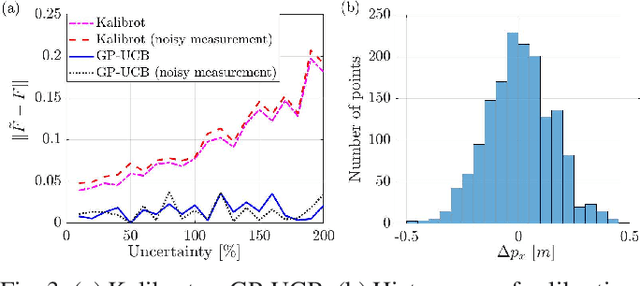

Future NASA lander missions to icy moons will require completely automated, accurate, and data efficient calibration methods for the robot manipulator arms that sample icy terrains in the lander's vicinity. To support this need, this paper presents a Gaussian Process (GP) approach to the classical manipulator kinematic calibration process. Instead of identifying a corrected set of Denavit-Hartenberg kinematic parameters, a set of GPs models the residual kinematic error of the arm over the workspace. More importantly, this modeling framework allows a Gaussian Process Upper Confident Bound (GP-UCB) algorithm to efficiently and adaptively select the calibration's measurement points so as to minimize the number of experiments, and therefore minimize the time needed for recalibration. The method is demonstrated in simulation on a simple 2-DOF arm, a 6 DOF arm whose geometry is a candidate for a future NASA mission, and a 7 DOF Barrett WAM arm.
Hyperdimensional Computing with Spiking-Phasor Neurons
Feb 28, 2023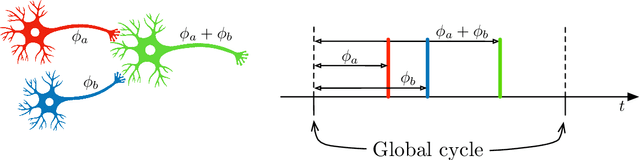
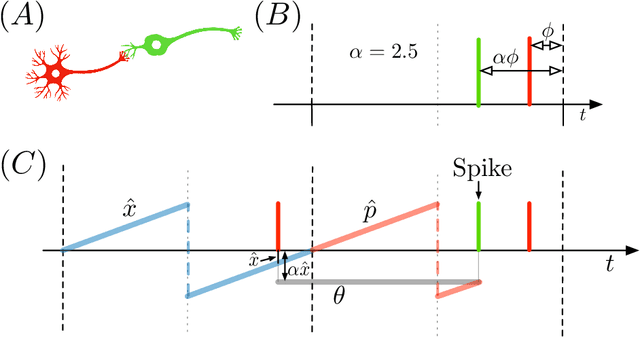
Vector Symbolic Architectures (VSAs) are a powerful framework for representing compositional reasoning. They lend themselves to neural-network implementations, allowing us to create neural networks that can perform cognitive functions, like spatial reasoning, arithmetic, symbol binding, and logic. But the vectors involved can be quite large, hence the alternative label Hyperdimensional (HD) computing. Advances in neuromorphic hardware hold the promise of reducing the running time and energy footprint of neural networks by orders of magnitude. In this paper, we extend some pioneering work to run VSA algorithms on a substrate of spiking neurons that could be run efficiently on neuromorphic hardware.
In Search of Deep Learning Architectures for Load Forecasting: A Comparative Analysis and the Impact of the Covid-19 Pandemic on Model Performance
Feb 25, 2023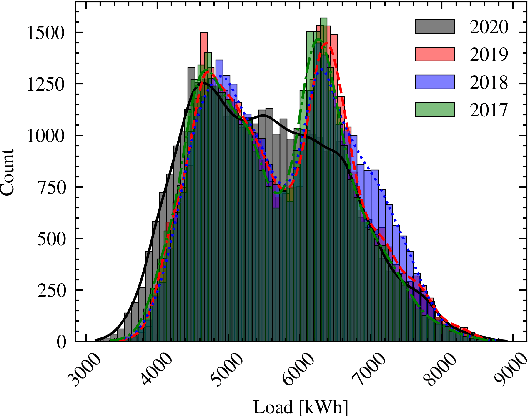
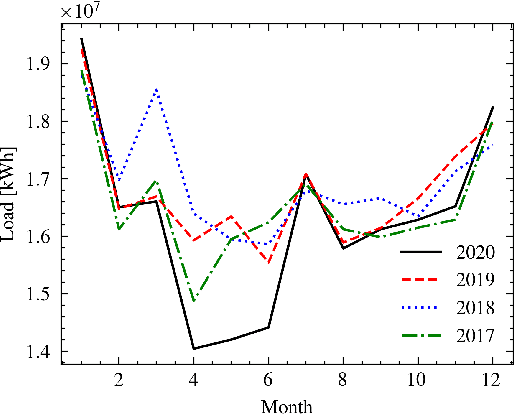
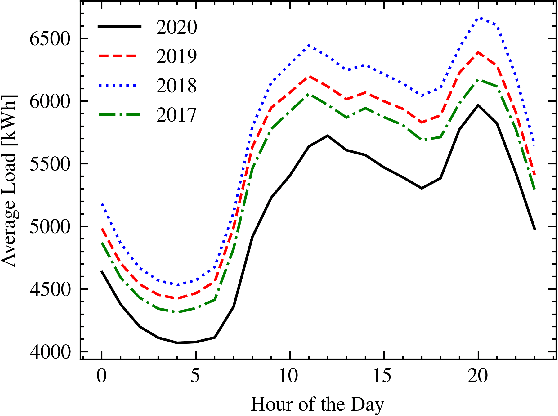
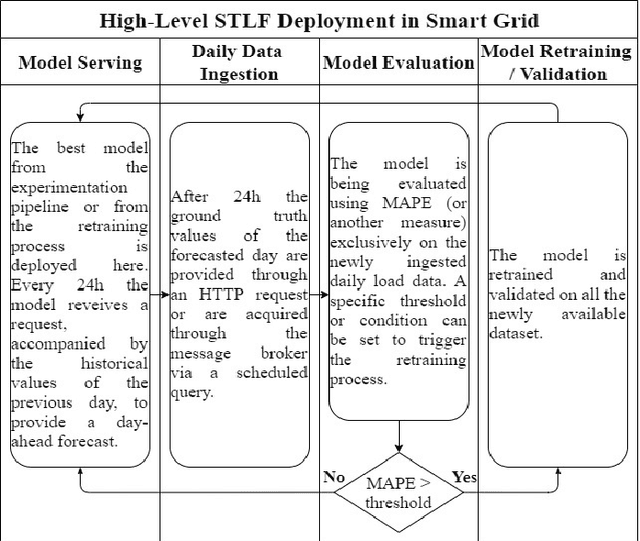
In power grids, short-term load forecasting (STLF) is crucial as it contributes to the optimization of their reliability, emissions, and costs, while it enables the participation of energy companies in the energy market. STLF is a challenging task, due to the complex demand of active and reactive power from multiple types of electrical loads and their dependence on numerous exogenous variables. Amongst them, special circumstances, such as the COVID-19 pandemic, can often be the reason behind distribution shifts of load series. This work conducts a comparative study of Deep Learning (DL) architectures, namely Neural Basis Expansion Analysis Time Series Forecasting (N-BEATS), Long Short-Term Memory (LSTM), and Temporal Convolutional Networks (TCN), with respect to forecasting accuracy and training sustainability, meanwhile examining their out-of-distribution generalization capabilities during the COVID-19 pandemic era. A Pattern Sequence Forecasting (PSF) model is used as baseline. The case study focuses on day-ahead forecasts for the Portuguese national 15-minute resolution net load time series. The results can be leveraged by energy companies and network operators (i) to reinforce their forecasting toolkit with state-of-the-art DL models; (ii) to become aware of the serious consequences of crisis events on model performance; (iii) as a high-level model evaluation, deployment, and sustainability guide within a smart grid context.
Towards Real-Time Text2Video via CLIP-Guided, Pixel-Level Optimization
Oct 23, 2022


We introduce an approach to generating videos based on a series of given language descriptions. Frames of the video are generated sequentially and optimized by guidance from the CLIP image-text encoder; iterating through language descriptions, weighting the current description higher than others. As opposed to optimizing through an image generator model itself, which tends to be computationally heavy, the proposed approach computes the CLIP loss directly at the pixel level, achieving general content at a speed suitable for near real-time systems. The approach can generate videos in up to 720p resolution, variable frame-rates, and arbitrary aspect ratios at a rate of 1-2 frames per second. Please visit our website to view videos and access our open-source code: https://pschaldenbrand.github.io/text2video/ .
Channel Estimation for Underwater Visible Light Communication: A Sparse Learning Perspective
Mar 13, 2023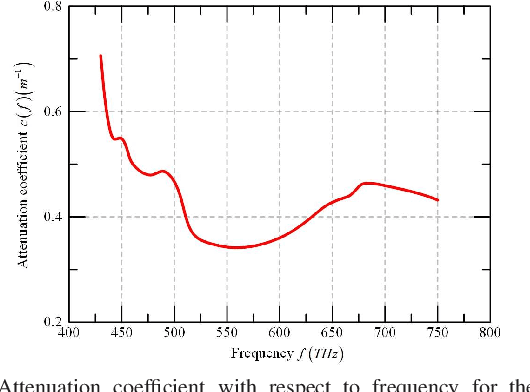
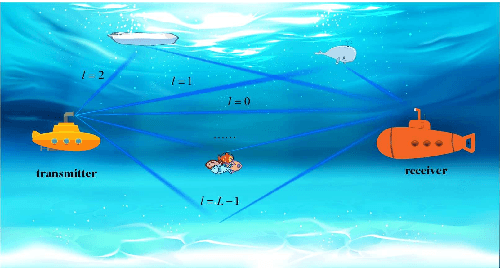
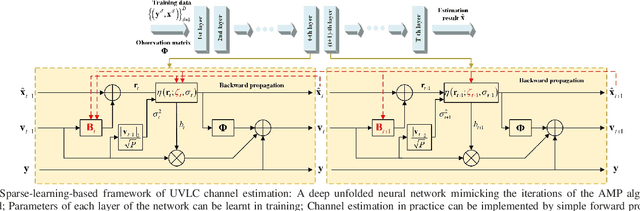
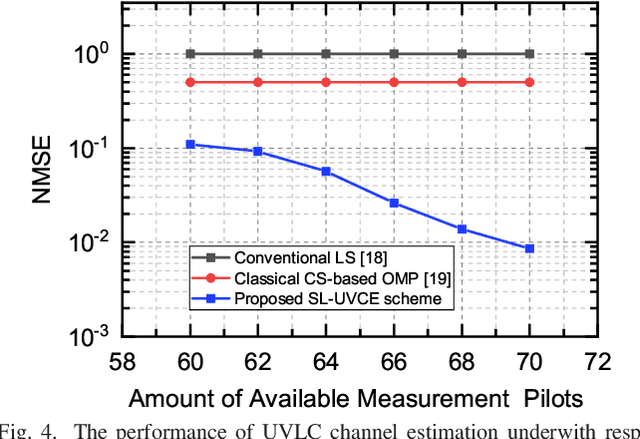
The underwater propagation environment for visible light signals is affected by complex factors such as absorption, shadowing, and reflection, making it very challengeable to achieve effective underwater visible light communication (UVLC) channel estimation. It is difficult for the UVLC channel to be sparse represented in the time and frequency domains, which limits the chance of using sparse signal processing techniques to achieve better performance of channel estimation. To this end, a compressed sensing (CS) based framework is established in this paper by fully exploiting the sparsity of the underwater visible light channel in the distance domain of the propagation links. In order to solve the sparse recovery problem and achieve more accurate UVLC channel estimation, a sparse learning based underwater visible light channel estimation (SL-UVCE) scheme is proposed. Specifically, a deep-unfolding neural network mimicking the classical iterative sparse recovery algorithm of approximate message passing (AMP) is employed, which decomposes the iterations of AMP into a series of layers with different learnable parameters. Compared with the existing non-CS-based and CS-based schemes, the proposed scheme shows better performance of accuracy in channel estimation, especially in severe conditions such as insufficient measurement pilots and large number of multipath components.
High-throughput Generative Inference of Large Language Models with a Single GPU
Mar 13, 2023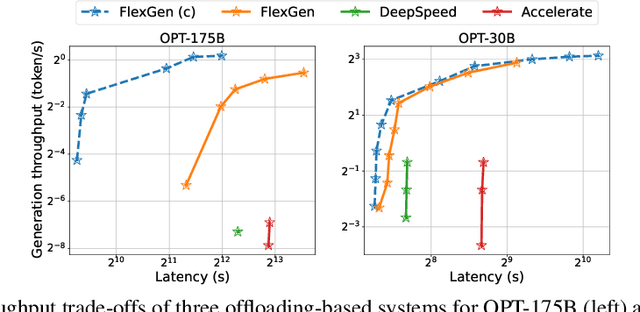

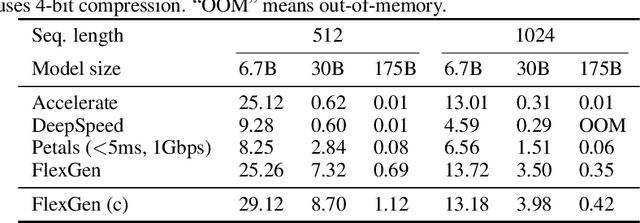
The high computational and memory requirements of large language model (LLM) inference traditionally make it feasible only with multiple high-end accelerators. Motivated by the emerging demand for latency-insensitive tasks with batched processing, this paper initiates the study of high-throughput LLM inference using limited resources, such as a single commodity GPU. We present FlexGen, a high-throughput generation engine for running LLMs with limited GPU memory. FlexGen can be flexibly configured under various hardware resource constraints by aggregating memory and computation from the GPU, CPU, and disk. Through a linear programming optimizer, it searches for efficient patterns to store and access tensors. FlexGen further compresses these weights and the attention cache to 4 bits with negligible accuracy loss. These techniques enable FlexGen to have a larger space of batch size choices and thus significantly increase maximum throughput. As a result, when running OPT-175B on a single 16GB GPU, FlexGen achieves significantly higher throughput compared to state-of-the-art offloading systems, reaching a generation throughput of 1 token/s for the first time with an effective batch size of 144. On the HELM benchmark, FlexGen can benchmark a 30B model with a 16GB GPU on 7 representative sub-scenarios in 21 hours. The code is available at https://github.com/FMInference/FlexGen
Guiding the Guidance: A Comparative Analysis of User Guidance Signals for Interactive Segmentation of Volumetric Images
Mar 13, 2023
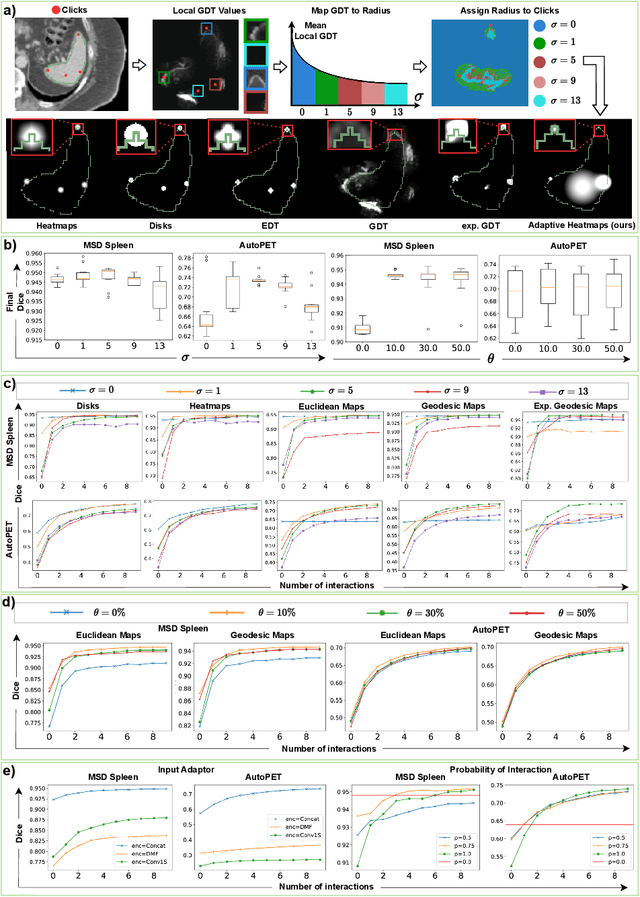

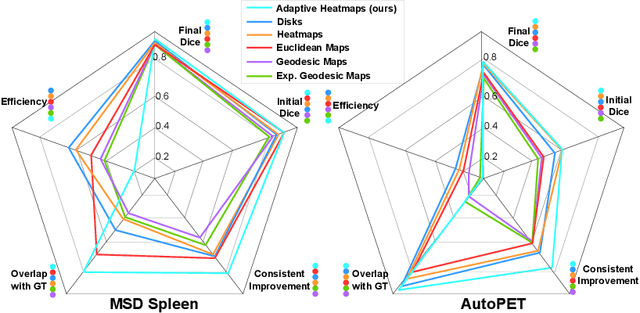
Interactive segmentation reduces the annotation time of medical images and allows annotators to iteratively refine labels with corrective interactions, such as clicks. While existing interactive models transform clicks into user guidance signals, which are combined with images to form (image, guidance) pairs, the question of how to best represent the guidance has not been fully explored. To address this, we conduct a comparative study of existing guidance signals by training interactive models with different signals and parameter settings to identify crucial parameters for the model's design. Based on our findings, we design a guidance signal that retains the benefits of other signals while addressing their limitations. We propose an adaptive Gaussian heatmaps guidance signal that utilizes the geodesic distance transform to dynamically adapt the radius of each heatmap when encoding clicks. We conduct our study on the MSD Spleen and the AutoPET datasets to explore the segmentation of both anatomy (spleen) and pathology (tumor lesions). Our results show that choosing the guidance signal is crucial for interactive segmentation as we improve the performance by 14% Dice with our adaptive heatmaps on the challenging AutoPET dataset when compared to non-interactive models. This brings interactive models one step closer to deployment on clinical workflows. We will make our code publically available.
End-to-end Deformable Attention Graph Neural Network for Single-view Liver Mesh Reconstruction
Mar 13, 2023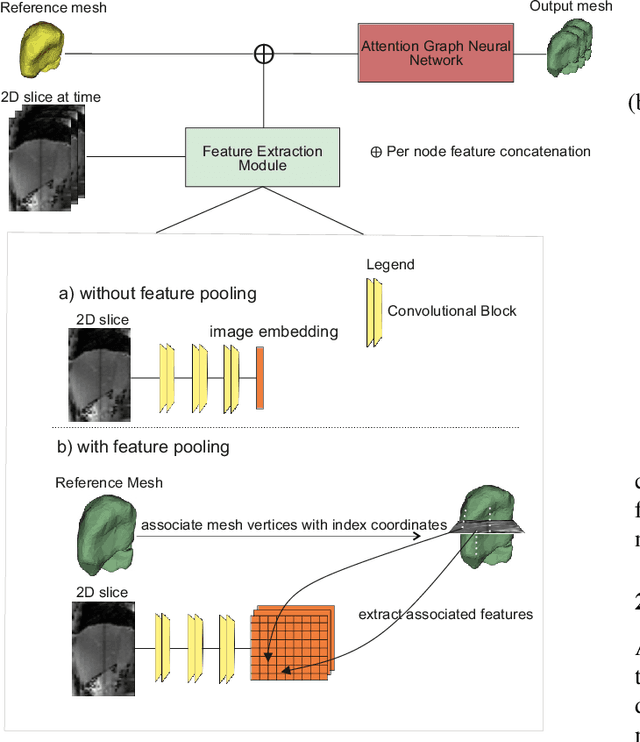
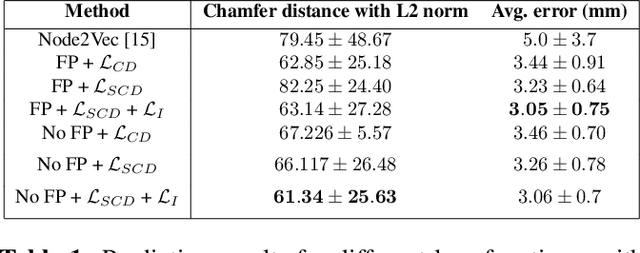
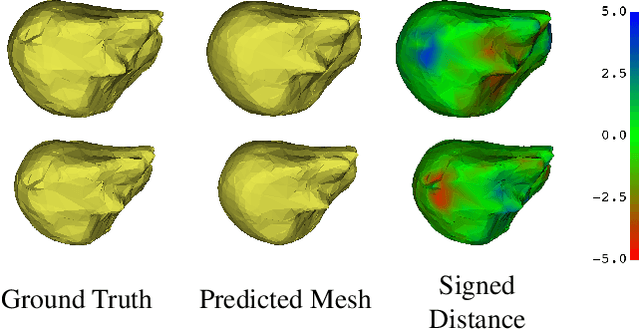
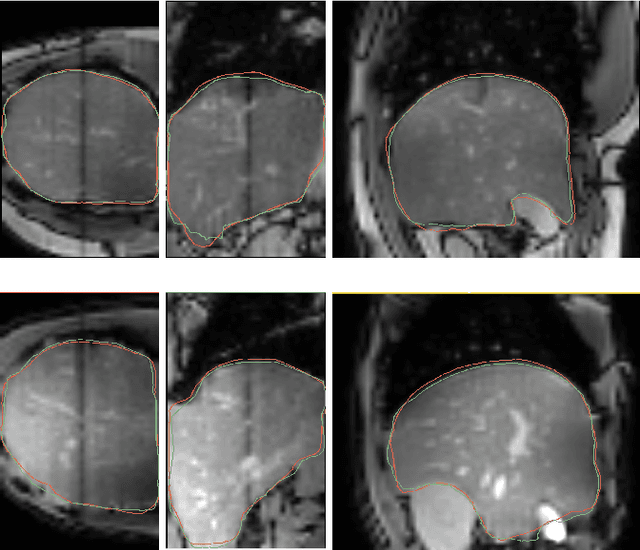
Intensity modulated radiotherapy (IMRT) is one of the most common modalities for treating cancer patients. One of the biggest challenges is precise treatment delivery that accounts for varying motion patterns originating from free-breathing. Currently, image-guided solutions for IMRT is limited to 2D guidance due to the complexity of 3D tracking solutions. We propose a novel end-to-end attention graph neural network model that generates in real-time a triangular shape of the liver based on a reference segmentation obtained at the preoperative phase and a 2D MRI coronal slice taken during the treatment. Graph neural networks work directly with graph data and can capture hidden patterns in non-Euclidean domains. Furthermore, contrary to existing methods, it produces the shape entirely in a mesh structure and correctly infers mesh shape and position based on a surrogate image. We define two on-the-fly approaches to make the correspondence of liver mesh vertices with 2D images obtained during treatment. Furthermore, we introduce a novel task-specific identity loss to constrain the deformation of the liver in the graph neural network to limit phenomenons such as flying vertices or mesh holes. The proposed method achieves results with an average error of 3.06 +- 0.7 mm and Chamfer distance with L2 norm of 63.14 +- 27.28.
AGTGAN: Unpaired Image Translation for Photographic Ancient Character Generation
Mar 13, 2023
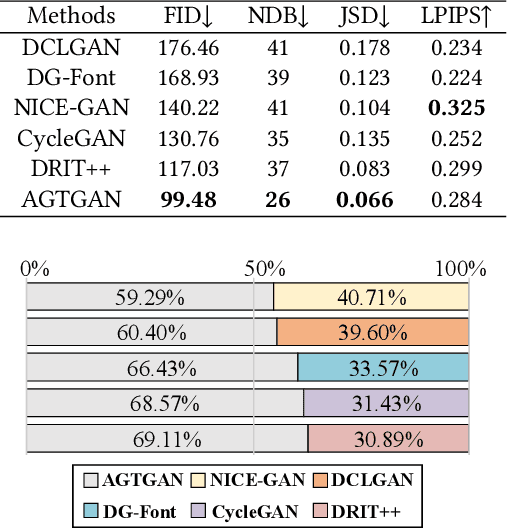

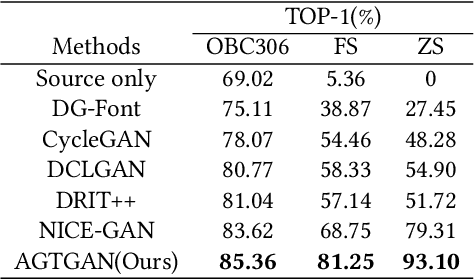
The study of ancient writings has great value for archaeology and philology. Essential forms of material are photographic characters, but manual photographic character recognition is extremely time-consuming and expertise-dependent. Automatic classification is therefore greatly desired. However, the current performance is limited due to the lack of annotated data. Data generation is an inexpensive but useful solution for data scarcity. Nevertheless, the diverse glyph shapes and complex background textures of photographic ancient characters make the generation task difficult, leading to the unsatisfactory results of existing methods. In this paper, we propose an unsupervised generative adversarial network called AGTGAN. By the explicit global and local glyph shape style modeling followed by the stroke-aware texture transfer, as well as an associate adversarial learning mechanism, our method can generate characters with diverse glyphs and realistic textures. We evaluate our approach on the photographic ancient character datasets, e.g., OBC306 and CSDD. Our method outperforms the state-of-the-art approaches in various metrics and performs much better in terms of the diversity and authenticity of generated samples. With our generated images, experiments on the largest photographic oracle bone character dataset show that our method can achieve a significant increase in classification accuracy, up to 16.34%.
Fast and Painless Image Reconstruction in Deep Image Prior Subspaces
Feb 20, 2023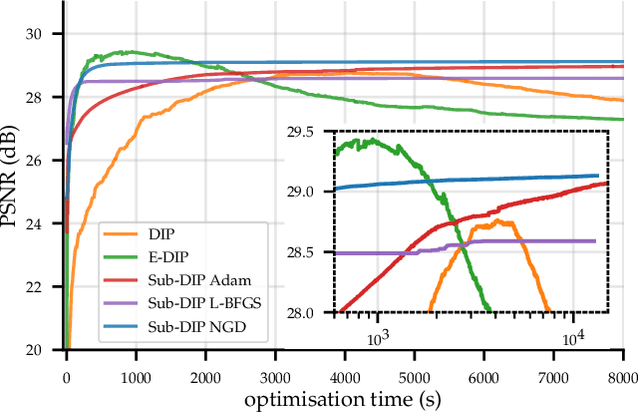
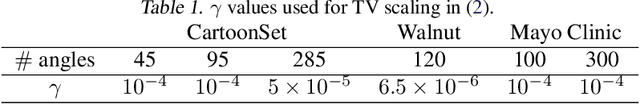
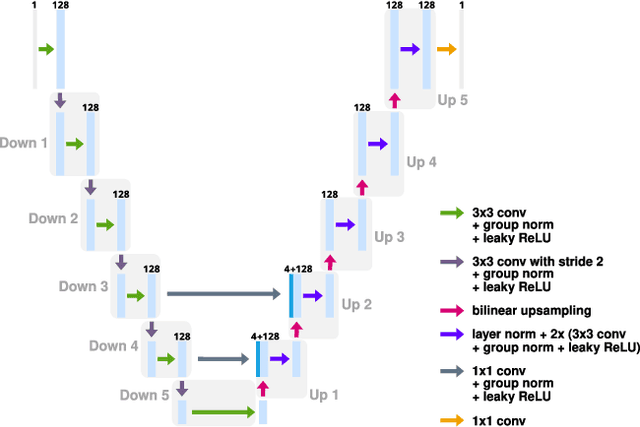
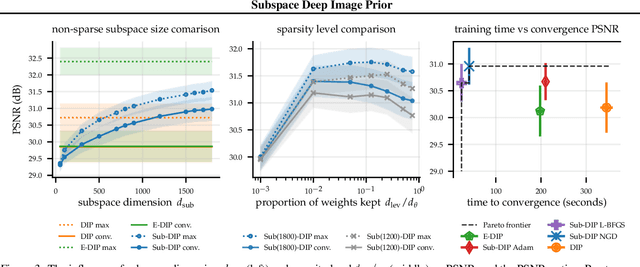
The deep image prior (DIP) is a state-of-the-art unsupervised approach for solving linear inverse problems in imaging. We address two key issues that have held back practical deployment of the DIP: the long computing time needed to train a separate deep network per reconstruction, and the susceptibility to overfitting due to a lack of robust early stopping strategies in the unsupervised setting. To this end, we restrict DIP optimisation to a sparse linear subspace of the full parameter space. We construct the subspace from the principal eigenspace of a set of parameter vectors sampled at equally spaced intervals during DIP pre-training on synthetic task-agnostic data. The low-dimensionality of the resulting subspace reduces DIP's capacity to fit noise and allows the use of fast second order optimisation methods, e.g., natural gradient descent or L-BFGS. Experiments across tomographic tasks of different geometry, ill-posedness and stopping criteria consistently show that second order optimisation in a subspace is Pareto-optimal in terms of optimisation time to reconstruction fidelity trade-off.