 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Approach to Learning Generalized Audio Representation Through Batch Embedding Covariance Regularization and Constant-Q Transforms
Mar 07, 2023
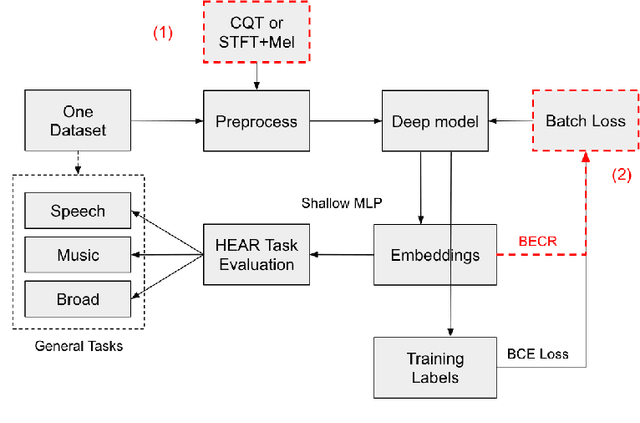
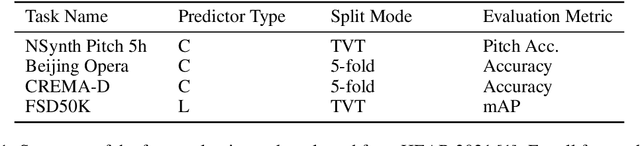
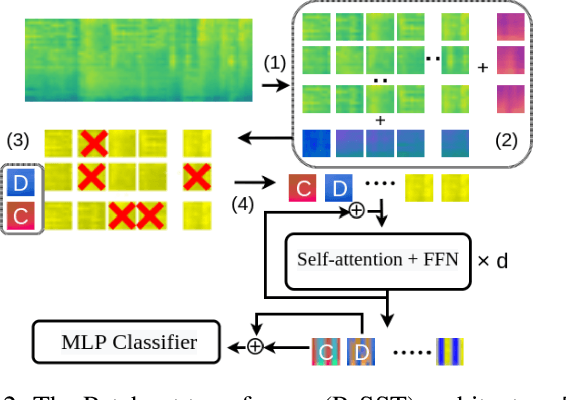
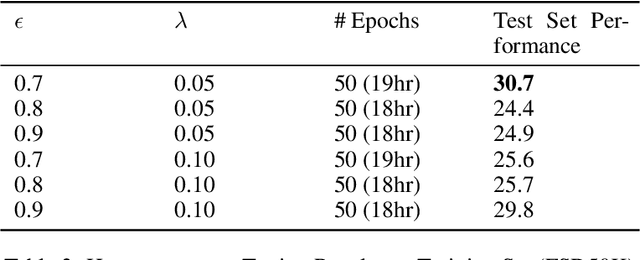
General-purpose embedding is highly desirable for few-shot even zero-shot learning in many application scenarios, including audio tasks. In order to understand representations better, we conducted a thorough error analysis and visualization of HEAR 2021 submission results. Inspired by the analysis, this work experiments with different front-end audio preprocessing methods, including Constant-Q Transform (CQT) and Short-time Fourier transform (STFT), and proposes a Batch Embedding Covariance Regularization (BECR) term to uncover a more holistic simulation of the frequency information received by the human auditory system. We tested the models on the suite of HEAR 2021 tasks, which encompass a broad category of tasks. Preliminary results show (1) the proposed BECR can incur a more dispersed embedding on the test set, (2) BECR improves the PaSST model without extra computation complexity, and (3) STFT preprocessing outperforms CQT in all tasks we tested. Github:https://github.com/ankitshah009/general_audio_embedding_hear_2021
A Multi-Stage Triple-Path Method for Speech Separation in Noisy and Reverberant Environments
Mar 07, 2023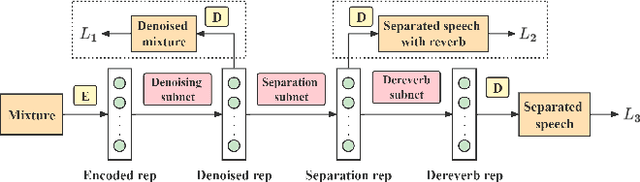
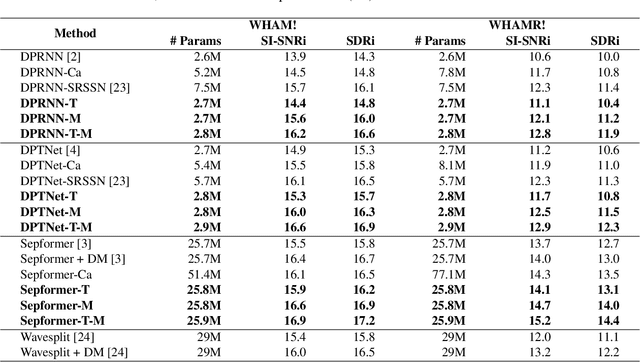
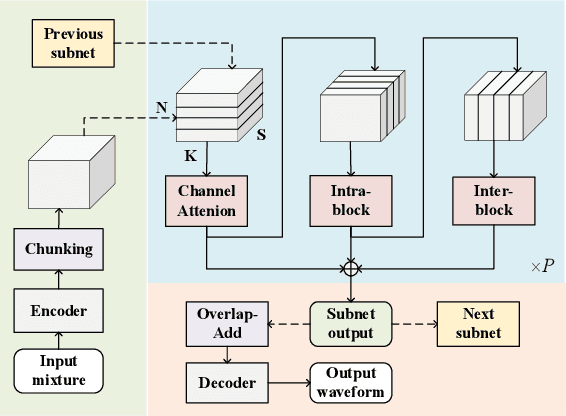
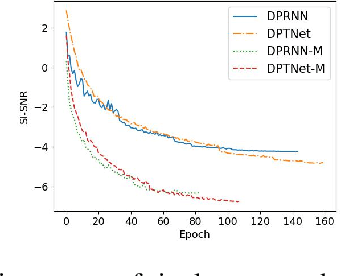
In noisy and reverberant environments, the performance of deep learning-based speech separation methods drops dramatically because previous methods are not designed and optimized for such situations. To address this issue, we propose a multi-stage end-to-end learning method that decouples the difficult speech separation problem in noisy and reverberant environments into three sub-problems: speech denoising, separation, and de-reverberation. The probability and speed of searching for the optimal solution of the speech separation model are improved by reducing the solution space. Moreover, since the channel information of the audio sequence in the time domain is crucial for speech separation, we propose a triple-path structure capable of modeling the channel dimension of audio sequences. Experimental results show that the proposed multi-stage triple-path method can improve the performance of speech separation models at the cost of little model parameter increment.
An Active Learning Based Robot Kinematic Calibration Framework Using Gaussian Processes
Mar 07, 2023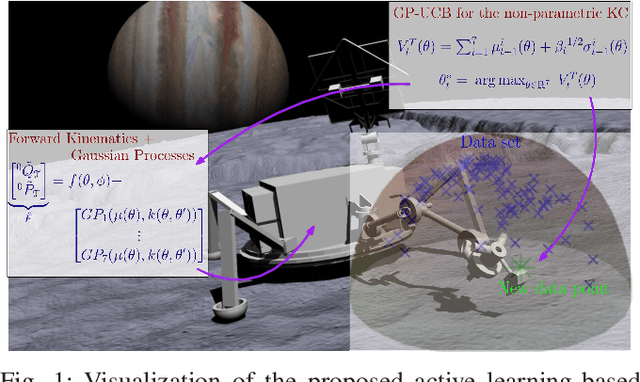
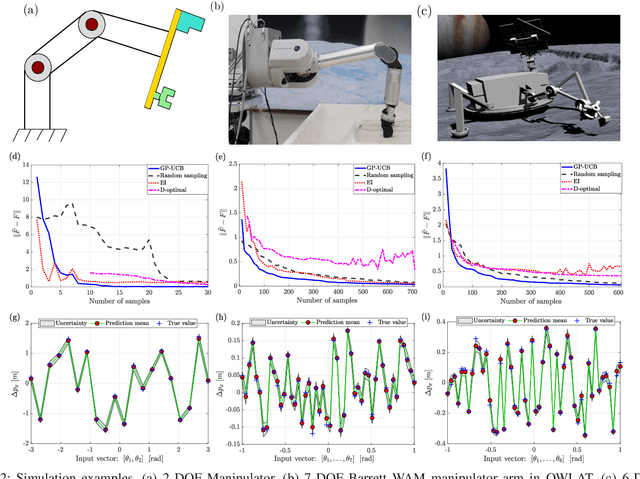
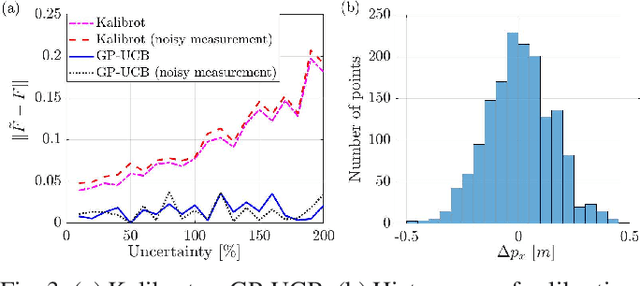

Future NASA lander missions to icy moons will require completely automated, accurate, and data efficient calibration methods for the robot manipulator arms that sample icy terrains in the lander's vicinity. To support this need, this paper presents a Gaussian Process (GP) approach to the classical manipulator kinematic calibration process. Instead of identifying a corrected set of Denavit-Hartenberg kinematic parameters, a set of GPs models the residual kinematic error of the arm over the workspace. More importantly, this modeling framework allows a Gaussian Process Upper Confident Bound (GP-UCB) algorithm to efficiently and adaptively select the calibration's measurement points so as to minimize the number of experiments, and therefore minimize the time needed for recalibration. The method is demonstrated in simulation on a simple 2-DOF arm, a 6 DOF arm whose geometry is a candidate for a future NASA mission, and a 7 DOF Barrett WAM arm.
Bias, diversity, and challenges to fairness in classification and automated text analysis. From libraries to AI and back
Mar 07, 2023Libraries are increasingly relying on computational methods, including methods from Artificial Intelligence (AI). This increasing usage raises concerns about the risks of AI that are currently broadly discussed in scientific literature, the media and law-making. In this article we investigate the risks surrounding bias and unfairness in AI usage in classification and automated text analysis within the context of library applications. We describe examples that show how the library community has been aware of such risks for a long time, and how it has developed and deployed countermeasures. We take a closer look at the notion of '(un)fairness' in relation to the notion of 'diversity', and we investigate a formalisation of diversity that models both inclusion and distribution. We argue that many of the unfairness problems of automated content analysis can also be regarded through the lens of diversity and the countermeasures taken to enhance diversity.
Channel Estimation for Underwater Visible Light Communication: A Sparse Learning Perspective
Mar 13, 2023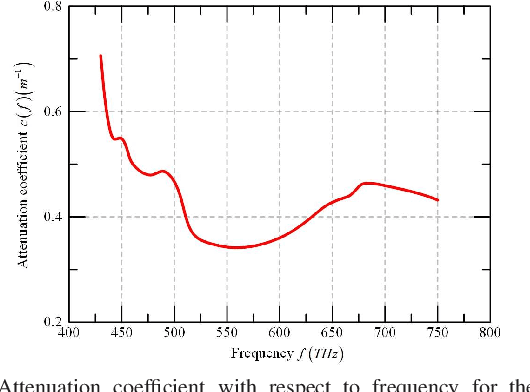
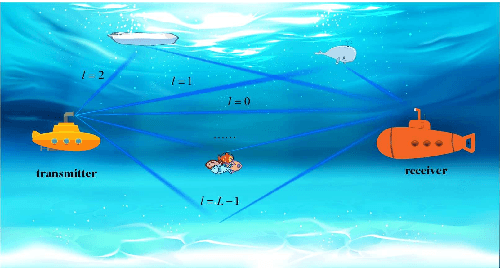
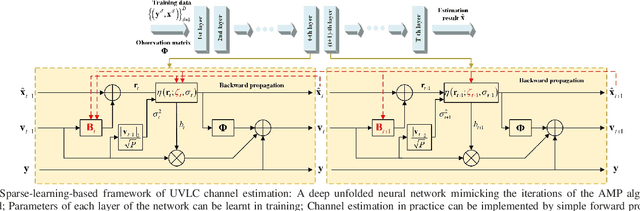
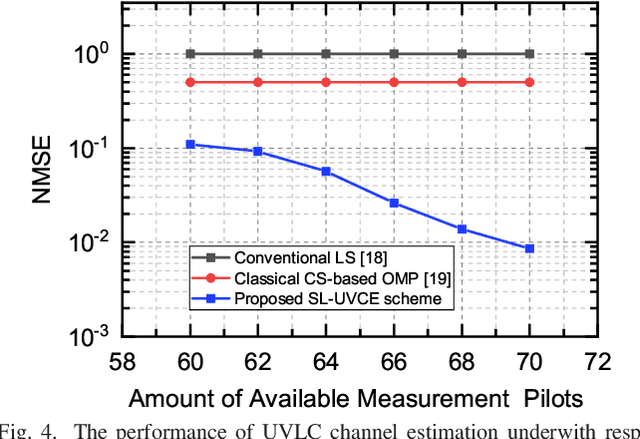
The underwater propagation environment for visible light signals is affected by complex factors such as absorption, shadowing, and reflection, making it very challengeable to achieve effective underwater visible light communication (UVLC) channel estimation. It is difficult for the UVLC channel to be sparse represented in the time and frequency domains, which limits the chance of using sparse signal processing techniques to achieve better performance of channel estimation. To this end, a compressed sensing (CS) based framework is established in this paper by fully exploiting the sparsity of the underwater visible light channel in the distance domain of the propagation links. In order to solve the sparse recovery problem and achieve more accurate UVLC channel estimation, a sparse learning based underwater visible light channel estimation (SL-UVCE) scheme is proposed. Specifically, a deep-unfolding neural network mimicking the classical iterative sparse recovery algorithm of approximate message passing (AMP) is employed, which decomposes the iterations of AMP into a series of layers with different learnable parameters. Compared with the existing non-CS-based and CS-based schemes, the proposed scheme shows better performance of accuracy in channel estimation, especially in severe conditions such as insufficient measurement pilots and large number of multipath components.
High-throughput Generative Inference of Large Language Models with a Single GPU
Mar 13, 2023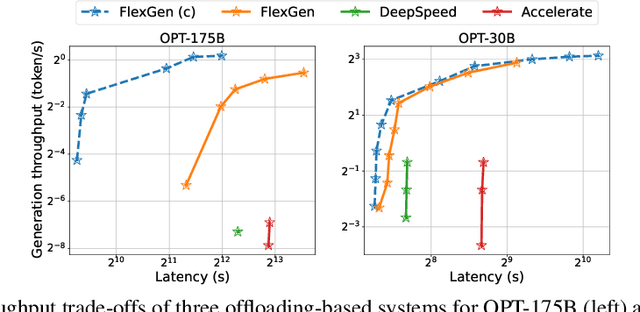

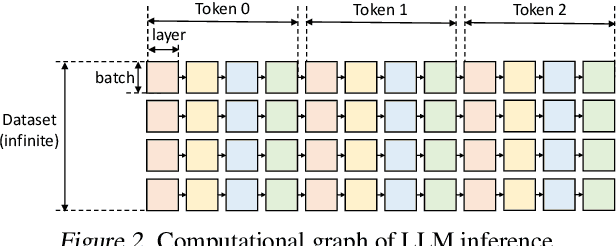
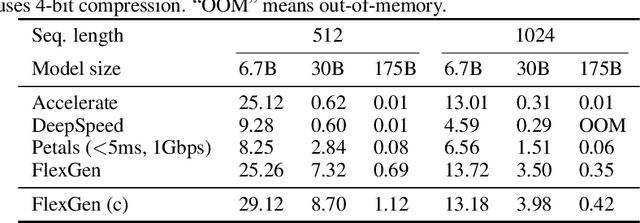
The high computational and memory requirements of large language model (LLM) inference traditionally make it feasible only with multiple high-end accelerators. Motivated by the emerging demand for latency-insensitive tasks with batched processing, this paper initiates the study of high-throughput LLM inference using limited resources, such as a single commodity GPU. We present FlexGen, a high-throughput generation engine for running LLMs with limited GPU memory. FlexGen can be flexibly configured under various hardware resource constraints by aggregating memory and computation from the GPU, CPU, and disk. Through a linear programming optimizer, it searches for efficient patterns to store and access tensors. FlexGen further compresses these weights and the attention cache to 4 bits with negligible accuracy loss. These techniques enable FlexGen to have a larger space of batch size choices and thus significantly increase maximum throughput. As a result, when running OPT-175B on a single 16GB GPU, FlexGen achieves significantly higher throughput compared to state-of-the-art offloading systems, reaching a generation throughput of 1 token/s for the first time with an effective batch size of 144. On the HELM benchmark, FlexGen can benchmark a 30B model with a 16GB GPU on 7 representative sub-scenarios in 21 hours. The code is available at https://github.com/FMInference/FlexGen
Guiding the Guidance: A Comparative Analysis of User Guidance Signals for Interactive Segmentation of Volumetric Images
Mar 13, 2023
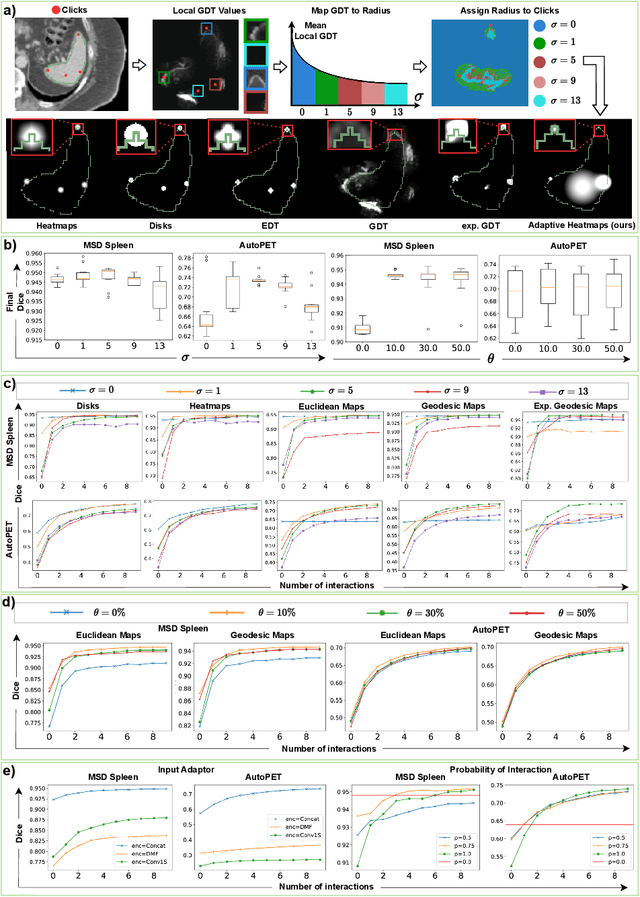

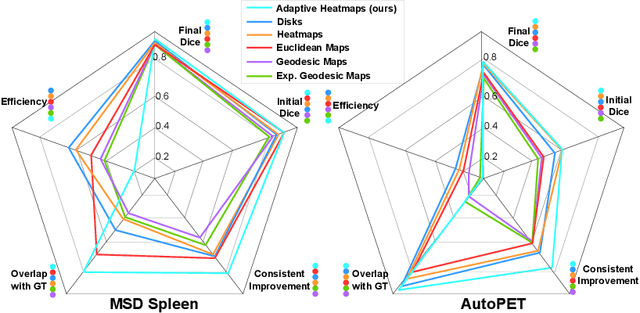
Interactive segmentation reduces the annotation time of medical images and allows annotators to iteratively refine labels with corrective interactions, such as clicks. While existing interactive models transform clicks into user guidance signals, which are combined with images to form (image, guidance) pairs, the question of how to best represent the guidance has not been fully explored. To address this, we conduct a comparative study of existing guidance signals by training interactive models with different signals and parameter settings to identify crucial parameters for the model's design. Based on our findings, we design a guidance signal that retains the benefits of other signals while addressing their limitations. We propose an adaptive Gaussian heatmaps guidance signal that utilizes the geodesic distance transform to dynamically adapt the radius of each heatmap when encoding clicks. We conduct our study on the MSD Spleen and the AutoPET datasets to explore the segmentation of both anatomy (spleen) and pathology (tumor lesions). Our results show that choosing the guidance signal is crucial for interactive segmentation as we improve the performance by 14% Dice with our adaptive heatmaps on the challenging AutoPET dataset when compared to non-interactive models. This brings interactive models one step closer to deployment on clinical workflows. We will make our code publically available.
End-to-end Deformable Attention Graph Neural Network for Single-view Liver Mesh Reconstruction
Mar 13, 2023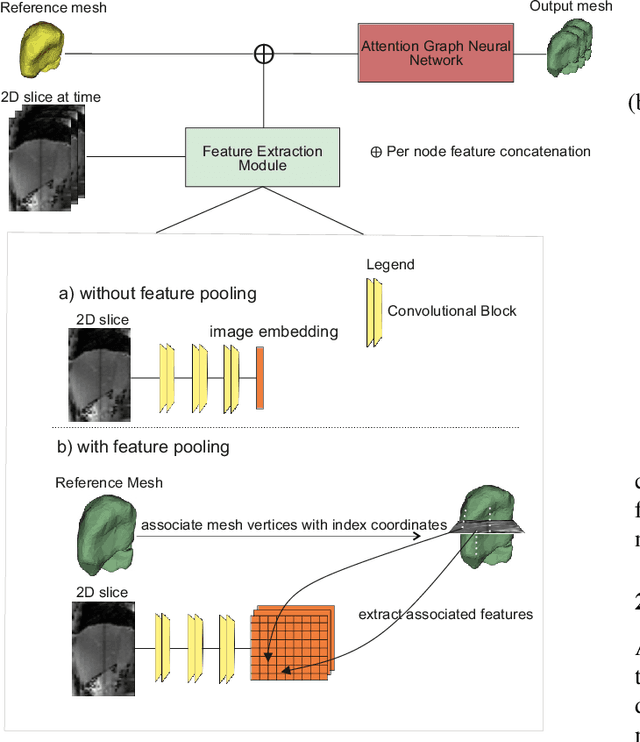
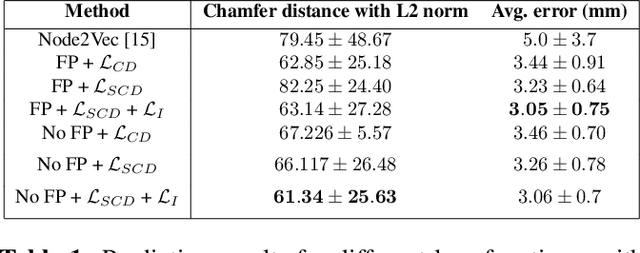
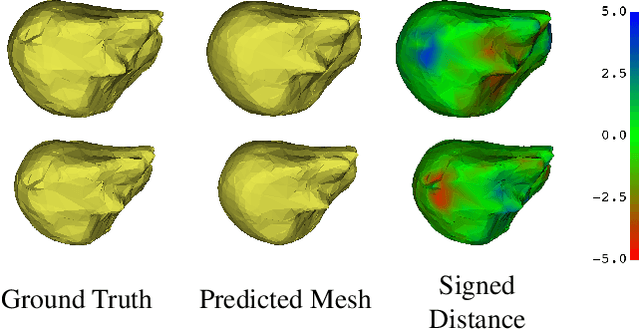
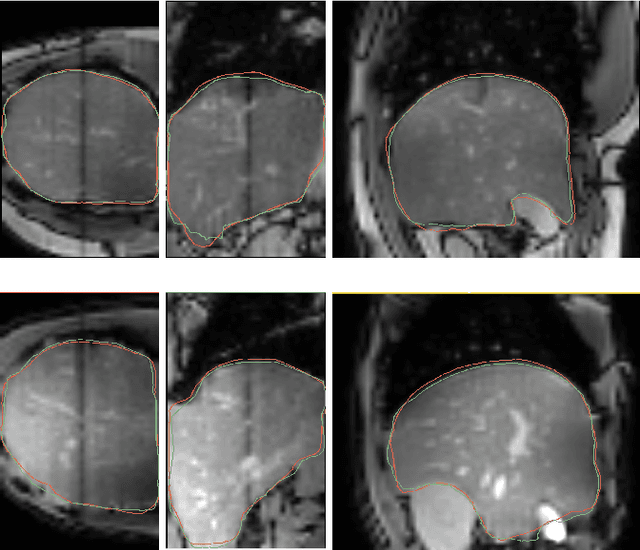
Intensity modulated radiotherapy (IMRT) is one of the most common modalities for treating cancer patients. One of the biggest challenges is precise treatment delivery that accounts for varying motion patterns originating from free-breathing. Currently, image-guided solutions for IMRT is limited to 2D guidance due to the complexity of 3D tracking solutions. We propose a novel end-to-end attention graph neural network model that generates in real-time a triangular shape of the liver based on a reference segmentation obtained at the preoperative phase and a 2D MRI coronal slice taken during the treatment. Graph neural networks work directly with graph data and can capture hidden patterns in non-Euclidean domains. Furthermore, contrary to existing methods, it produces the shape entirely in a mesh structure and correctly infers mesh shape and position based on a surrogate image. We define two on-the-fly approaches to make the correspondence of liver mesh vertices with 2D images obtained during treatment. Furthermore, we introduce a novel task-specific identity loss to constrain the deformation of the liver in the graph neural network to limit phenomenons such as flying vertices or mesh holes. The proposed method achieves results with an average error of 3.06 +- 0.7 mm and Chamfer distance with L2 norm of 63.14 +- 27.28.
AGTGAN: Unpaired Image Translation for Photographic Ancient Character Generation
Mar 13, 2023
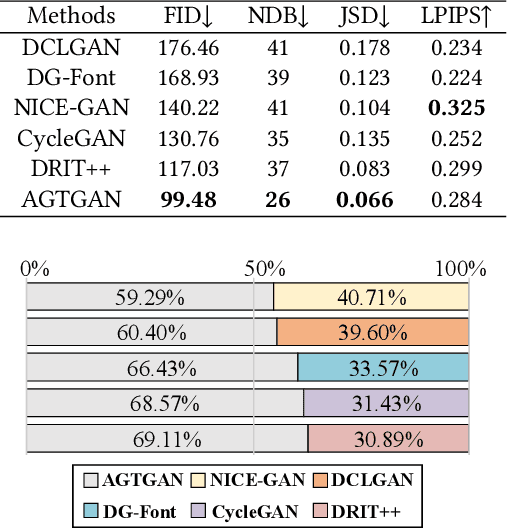

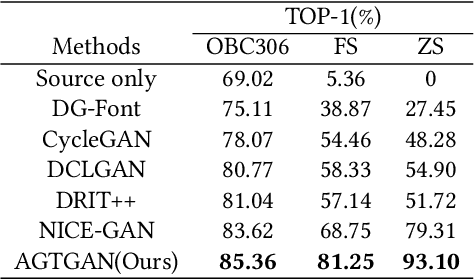
The study of ancient writings has great value for archaeology and philology. Essential forms of material are photographic characters, but manual photographic character recognition is extremely time-consuming and expertise-dependent. Automatic classification is therefore greatly desired. However, the current performance is limited due to the lack of annotated data. Data generation is an inexpensive but useful solution for data scarcity. Nevertheless, the diverse glyph shapes and complex background textures of photographic ancient characters make the generation task difficult, leading to the unsatisfactory results of existing methods. In this paper, we propose an unsupervised generative adversarial network called AGTGAN. By the explicit global and local glyph shape style modeling followed by the stroke-aware texture transfer, as well as an associate adversarial learning mechanism, our method can generate characters with diverse glyphs and realistic textures. We evaluate our approach on the photographic ancient character datasets, e.g., OBC306 and CSDD. Our method outperforms the state-of-the-art approaches in various metrics and performs much better in terms of the diversity and authenticity of generated samples. With our generated images, experiments on the largest photographic oracle bone character dataset show that our method can achieve a significant increase in classification accuracy, up to 16.34%.
Drugs Resistance Analysis from Scarce Health Records via Multi-task Graph Representation
Feb 22, 2023

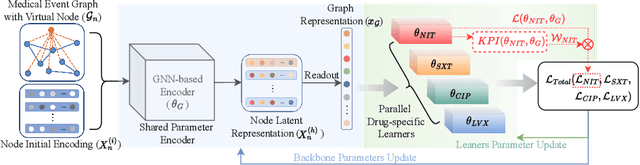

Clinicians prescribe antibiotics by looking at the patient's health record with an experienced eye. However, the therapy might be rendered futile if the patient has drug resistance. Determining drug resistance requires time-consuming laboratory-level testing while applying clinicians' heuristics in an automated way is difficult due to the categorical or binary medical events that constitute health records. In this paper, we propose a novel framework for rapid clinical intervention by viewing health records as graphs whose nodes are mapped from medical events and edges as correspondence between events in given a time window. A novel graph-based model is then proposed to extract informative features and yield automated drug resistance analysis from those high-dimensional and scarce graphs. The proposed method integrates multi-task learning into a common feature extracting graph encoder for simultaneous analyses of multiple drugs as well as stabilizing learning. On a massive dataset comprising over 110,000 patients with urinary tract infections, we verify the proposed method is capable of attaining superior performance on the drug resistance prediction problem. Furthermore, automated drug recommendations resemblant to laboratory-level testing can also be made based on the model resistance analysis.