 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Development of a Modular Real-time Shared-control System for a Smart Wheelchair
Nov 27, 2022
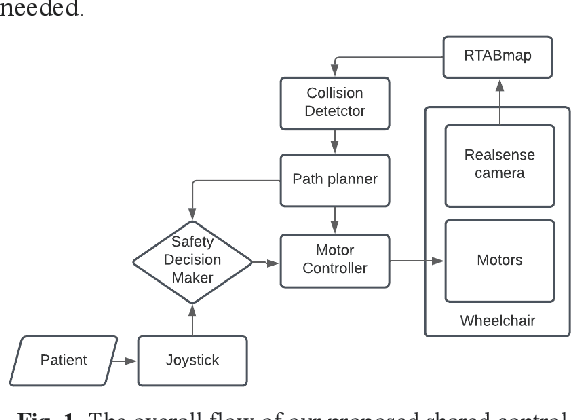
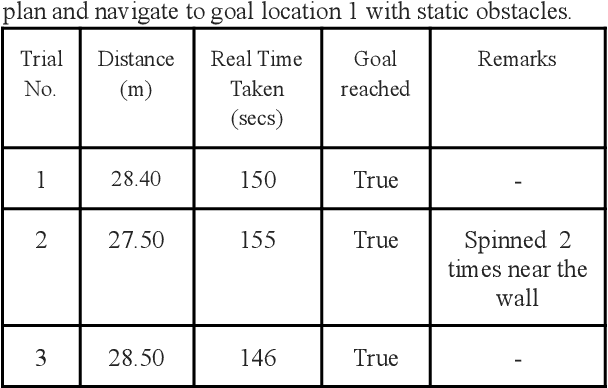
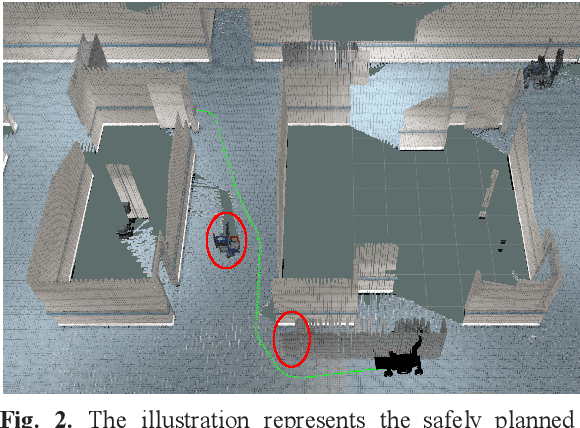
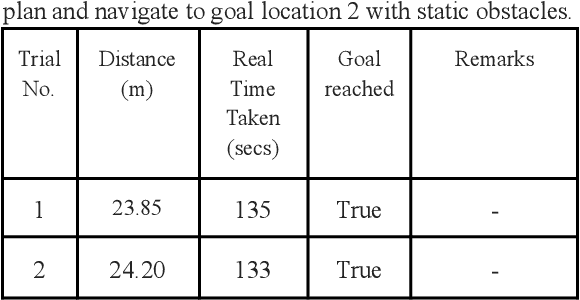
In this paper, we propose a modular navigation system that can be mounted on a regular powered wheelchair to assist disabled children and the elderly with autonomous mobility and shared-control features. The lack of independent mobility drastically affects an individual's mental and physical health making them feel less self-reliant, especially children with Cerebral Palsy and limited cognitive skills. To address this problem, we propose a comparatively inexpensive and modular system that uses a stereo camera to perform tasks such as path planning, obstacle avoidance, and collision detection in environments with narrow corridors. We avoid any major changes to the hardware of the wheelchair for an easy installation by replacing wheel encoders with a stereo camera for visual odometry. An open source software package, the Real-Time Appearance Based Mapping package, running on top of the Robot Operating System (ROS) allows us to perform visual SLAM that allows mapping and localizing itself in the environment. The path planning is performed by the move base package provided by ROS, which quickly and efficiently computes the path trajectory for the wheelchair. In this work, we present the design and development of the system along with its significant functionalities. Further, we report experimental results from a Gazebo simulation and real-world scenarios to prove the effectiveness of our proposed system with a compact form factor and a single stereo camera.
SGD learning on neural networks: leap complexity and saddle-to-saddle dynamics
Feb 21, 2023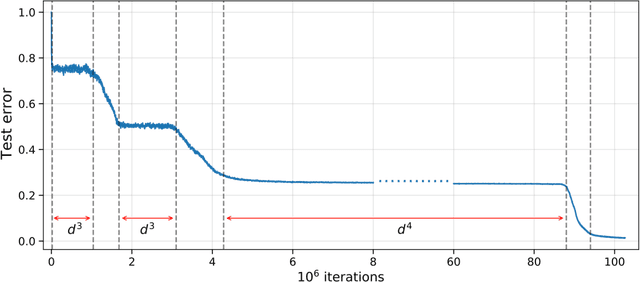
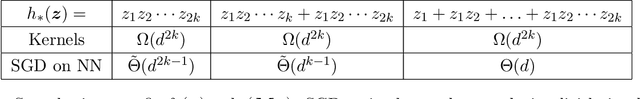
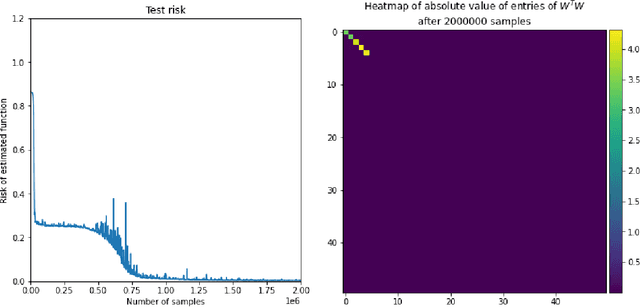
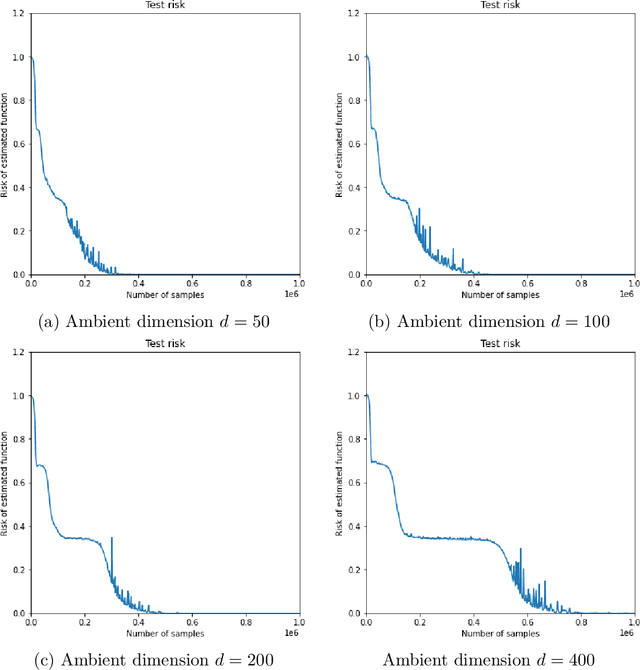
We investigate the time complexity of SGD learning on fully-connected neural networks with isotropic data. We put forward a complexity measure -- the leap -- which measures how "hierarchical" target functions are. For $d$-dimensional uniform Boolean or isotropic Gaussian data, our main conjecture states that the time complexity to learn a function $f$ with low-dimensional support is $\tilde\Theta (d^{\max(\mathrm{Leap}(f),2)})$. We prove a version of this conjecture for a class of functions on Gaussian isotropic data and 2-layer neural networks, under additional technical assumptions on how SGD is run. We show that the training sequentially learns the function support with a saddle-to-saddle dynamic. Our result departs from [Abbe et al. 2022] by going beyond leap 1 (merged-staircase functions), and by going beyond the mean-field and gradient flow approximations that prohibit the full complexity control obtained here. Finally, we note that this gives an SGD complexity for the full training trajectory that matches that of Correlational Statistical Query (CSQ) lower-bounds.
Location-based Physical Layer Authentication in Underwater Acoustic Communication Networks
Mar 12, 2023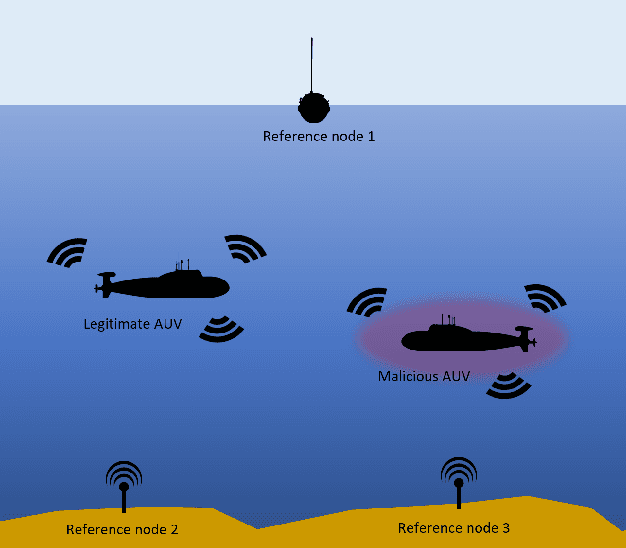
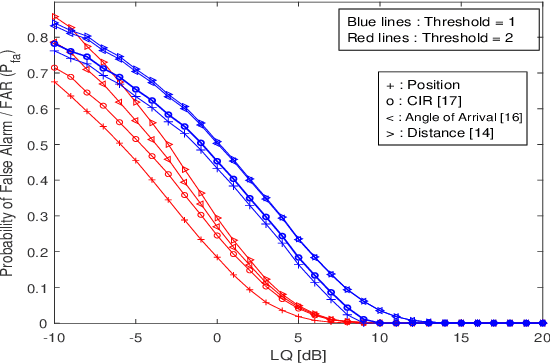
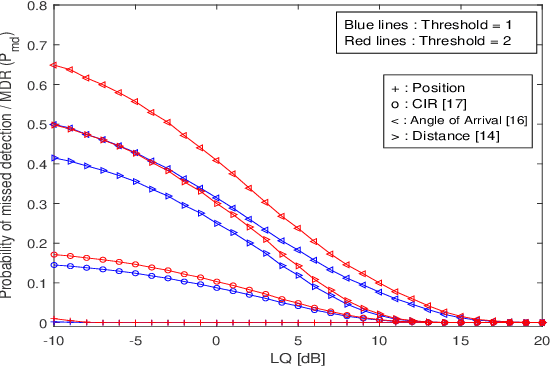
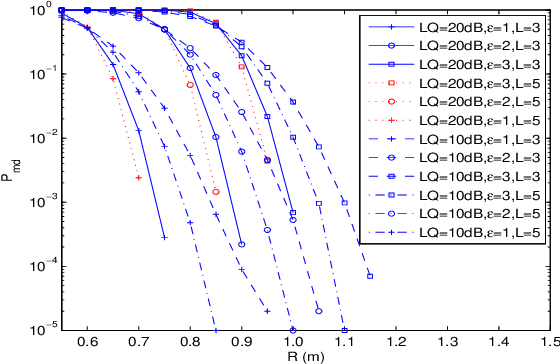
Research in underwater communication is rapidly becoming attractive due to its various modern applications. An efficient mechanism to secure such communication is via physical layer security. In this paper, we propose a novel physical layer authentication (PLA) mechanism in underwater acoustic communication networks where we exploit the position/location of the transmitter nodes to achieve authentication. We perform transmitter position estimation from the received signals at reference nodes deployed at fixed positions in a predefined underwater region. We use time of arrival (ToA) estimation and derive the distribution of inherent uncertainty in the estimation. Next, we perform binary hypothesis testing on the estimated position to decide whether the transmitter node is legitimate or malicious. We then provide closed-form expressions of false alarm rate and missed detection rate resulted from binary hypothesis testing. We validate our proposal via simulation results, which demonstrate errors' behavior against the link quality, malicious node location, and receiver operating characteristic (ROC) curves. We also compare our results with the performance of previously proposed fingerprint mechanisms for PLA in underwater acoustic communication networks, for which we show a clear advantage of using the position as a fingerprint in PLA.
TopSpark: A Timestep Optimization Methodology for Energy-Efficient Spiking Neural Networks on Autonomous Mobile Agents
Mar 03, 2023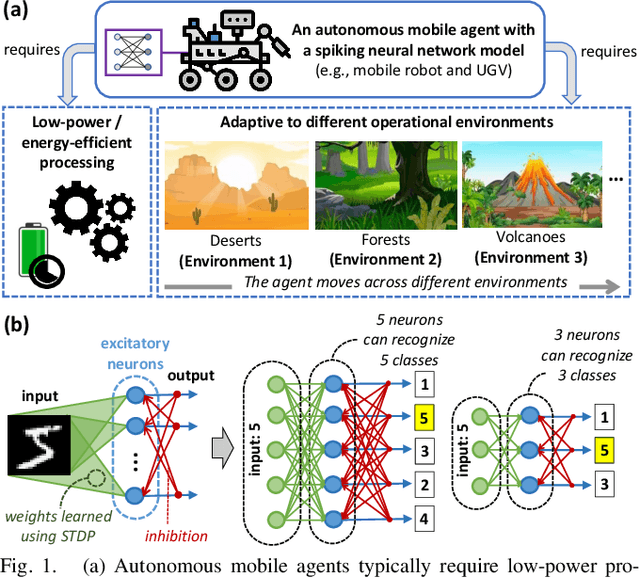
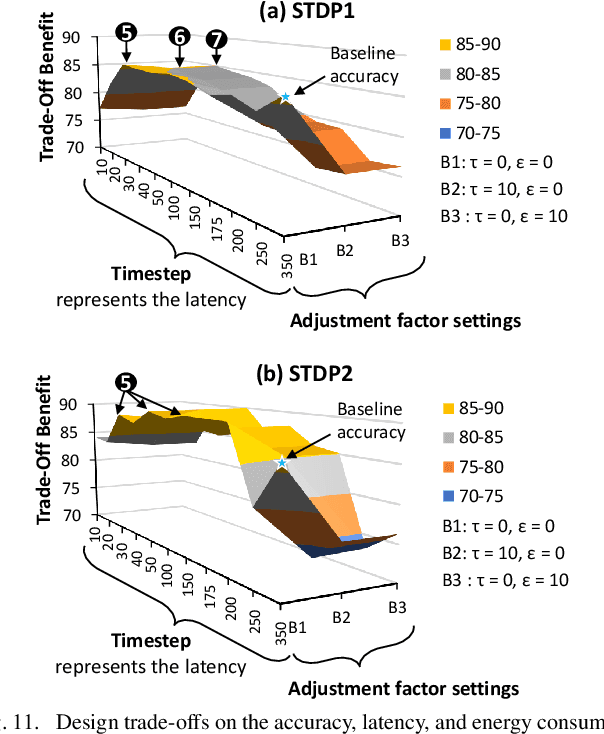
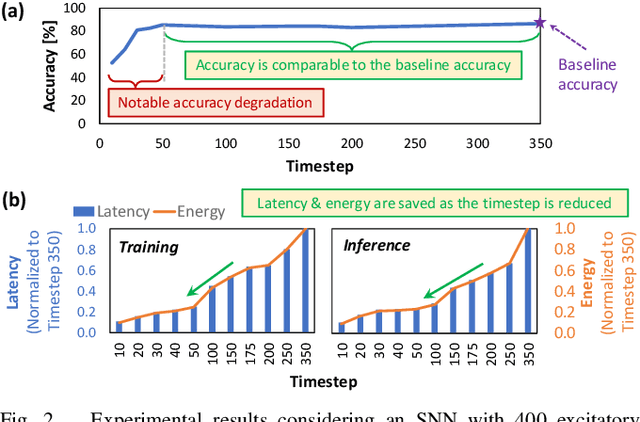

Autonomous mobile agents require low-power/energy-efficient machine learning (ML) algorithms to complete their ML-based tasks while adapting to diverse environments, as mobile agents are usually powered by batteries. These requirements can be fulfilled by Spiking Neural Networks (SNNs) as they offer low power/energy processing due to their sparse computations and efficient online learning with bio-inspired learning mechanisms for adapting to different environments. Recent works studied that the energy consumption of SNNs can be optimized by reducing the computation time of each neuron for processing a sequence of spikes (timestep). However, state-of-the-art techniques rely on intensive design searches to determine fixed timestep settings for only inference, thereby hindering SNNs from achieving further energy efficiency gains in both training and inference. These techniques also restrict SNNs from performing efficient online learning at run time. Toward this, we propose TopSpark, a novel methodology that leverages adaptive timestep reduction to enable energy-efficient SNN processing in both training and inference, while keeping its accuracy close to the accuracy of SNNs without timestep reduction. The ideas of TopSpark include analyzing the impact of different timesteps on the accuracy; identifying neuron parameters that have a significant impact on accuracy in different timesteps; employing parameter enhancements that make SNNs effectively perform learning and inference using less spiking activity; and developing a strategy to trade-off accuracy, latency, and energy to meet the design requirements. The results show that, TopSpark saves the SNN latency by 3.9x as well as energy consumption by 3.5x for training and 3.3x for inference on average, across different network sizes, learning rules, and workloads, while maintaining the accuracy within 2% of SNNs without timestep reduction.
On the Doppler Squint Effect in OTFS Systems over Doubly-Dispersive Channels: Modeling and Evaluation
Feb 13, 2023
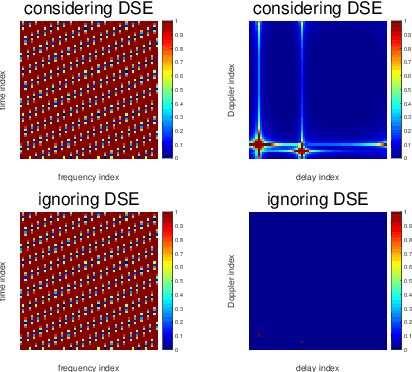
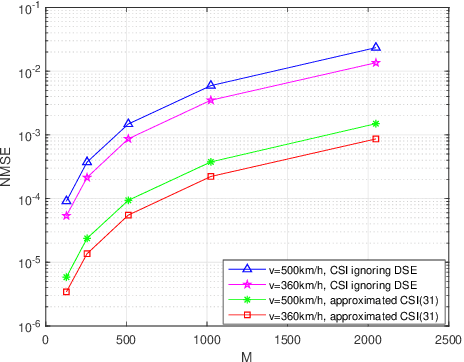
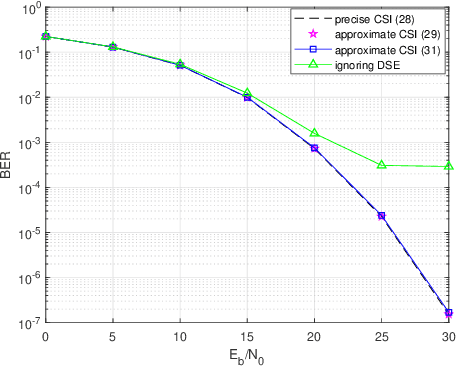
Extensive work has demonstrated the excellent performance of orthogonal time frequency space (OTFS) modulation in high-mobility scenarios. Time-variant wideband channel estimation serves as one of the key compositions of OTFS receivers since the data detection requires accurate channel state information (CSI). In practical wideband OTFS systems, the Doppler shift brought by the high mobility is frequency-dependent, which is referred to as the Doppler Squint Effect (DSE). Unfortunately, DSE was ignored in overall prior estimation schemes employed in OTFS systems, which leads to severe performance loss in channel estimation and the consequent data detection. In this paper, we investigate DSE of wideband time-variant channel in delay-Doppler domain and concentrate on the characterization of OTFS channel coefficients considering DSE. The formulation and evaluation of OTFS input-output relationship are provided for both ideal and rectangular waveforms considering DSE. The channel estimation is therefore formulated as a sparse signal recovery problem and an orthogonal matching pursuit (OMP)-based scheme is adopted to solve it. Simulation results confirm the significance of DSE and the performance superiority compared with traditional channel estimation approaches ignoring DSE.
On the Statistical Benefits of Temporal Difference Learning
Feb 09, 2023
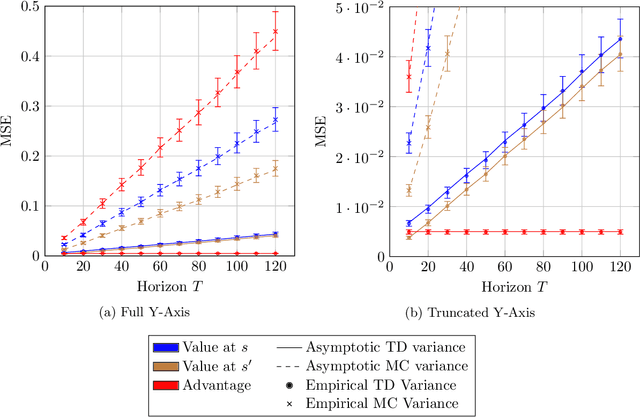
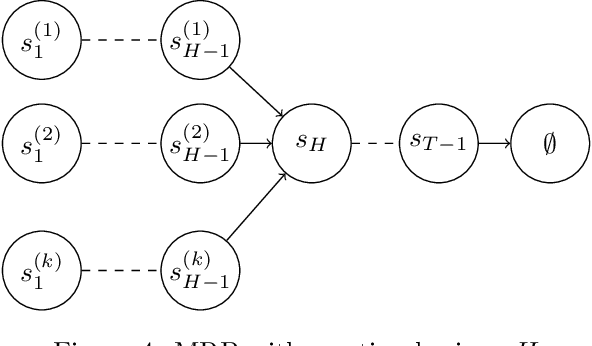
Given a dataset on actions and resulting long-term rewards, a direct estimation approach fits value functions that minimize prediction error on the training data. Temporal difference learning (TD) methods instead fit value functions by minimizing the degree of temporal inconsistency between estimates made at successive time-steps. Focusing on finite state Markov chains, we provide a crisp asymptotic theory of the statistical advantages of this approach. First, we show that an intuitive inverse trajectory pooling coefficient completely characterizes the percent reduction in mean-squared error of value estimates. Depending on problem structure, the reduction could be enormous or nonexistent. Next, we prove that there can be dramatic improvements in estimates of the difference in value-to-go for two states: TD's errors are bounded in terms of a novel measure - the problem's trajectory crossing time - which can be much smaller than the problem's time horizon.
Equilibrium Bandits: Learning Optimal Equilibria of Unknown Dynamics
Feb 27, 2023
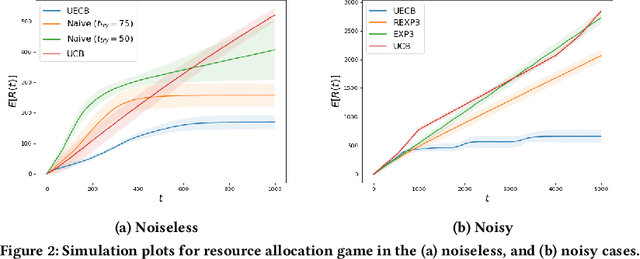
Consider a decision-maker that can pick one out of $K$ actions to control an unknown system, for $T$ turns. The actions are interpreted as different configurations or policies. Holding the same action fixed, the system asymptotically converges to a unique equilibrium, as a function of this action. The dynamics of the system are unknown to the decision-maker, which can only observe a noisy reward at the end of every turn. The decision-maker wants to maximize its accumulated reward over the $T$ turns. Learning what equilibria are better results in higher rewards, but waiting for the system to converge to equilibrium costs valuable time. Existing bandit algorithms, either stochastic or adversarial, achieve linear (trivial) regret for this problem. We present a novel algorithm, termed Upper Equilibrium Concentration Bound (UECB), that knows to switch an action quickly if it is not worth it to wait until the equilibrium is reached. This is enabled by employing convergence bounds to determine how far the system is from equilibrium. We prove that UECB achieves a regret of $\mathcal{O}(\log(T)+\tau_c\log(\tau_c)+\tau_c\log\log(T))$ for this equilibrium bandit problem where $\tau_c$ is the worst case approximate convergence time to equilibrium. We then show that both epidemic control and game control are special cases of equilibrium bandits, where $\tau_c\log \tau_c$ typically dominates the regret. We then test UECB numerically for both of these applications.
Stock Broad-Index Trend Patterns Learning via Domain Knowledge Informed Generative Network
Feb 27, 2023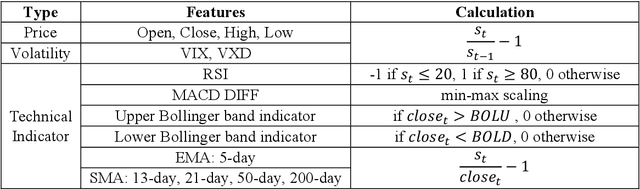
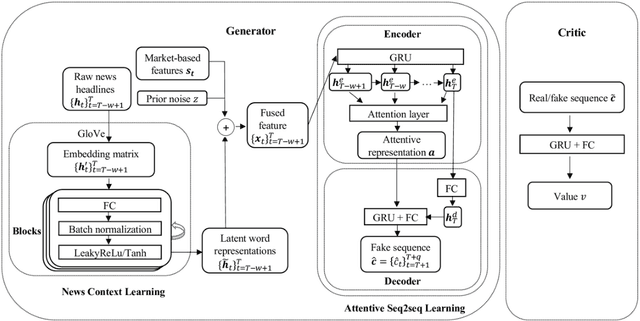

Predicting the Stock movement attracts much attention from both industry and academia. Despite such significant efforts, the results remain unsatisfactory due to the inherently complicated nature of the stock market driven by factors including supply and demand, the state of the economy, the political climate, and even irrational human behavior. Recently, Generative Adversarial Networks (GAN) have been extended for time series data; however, robust methods are primarily for synthetic series generation, which fall short for appropriate stock prediction. This is because existing GANs for stock applications suffer from mode collapse and only consider one-step prediction, thus underutilizing the potential of GAN. Furthermore, merging news and market volatility are neglected in current GANs. To address these issues, we exploit expert domain knowledge in finance and, for the first time, attempt to formulate stock movement prediction into a Wasserstein GAN framework for multi-step prediction. We propose IndexGAN, which includes deliberate designs for the inherent characteristics of the stock market, leverages news context learning to thoroughly investigate textual information and develop an attentive seq2seq learning network that captures the temporal dependency among stock prices, news, and market sentiment. We also utilize the critic to approximate the Wasserstein distance between actual and predicted sequences and develop a rolling strategy for deployment that mitigates noise from the financial market. Extensive experiments are conducted on real-world broad-based indices, demonstrating the superior performance of our architecture over other state-of-the-art baselines, also validating all its contributing components.
Frequency Cam: Imaging Periodic Signals in Real-Time
Nov 01, 2022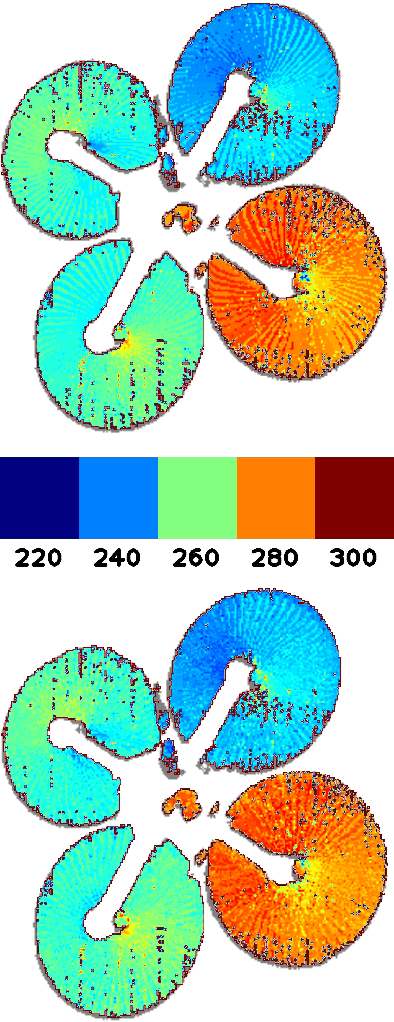
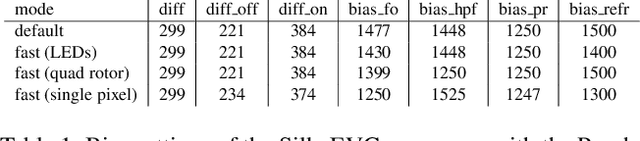
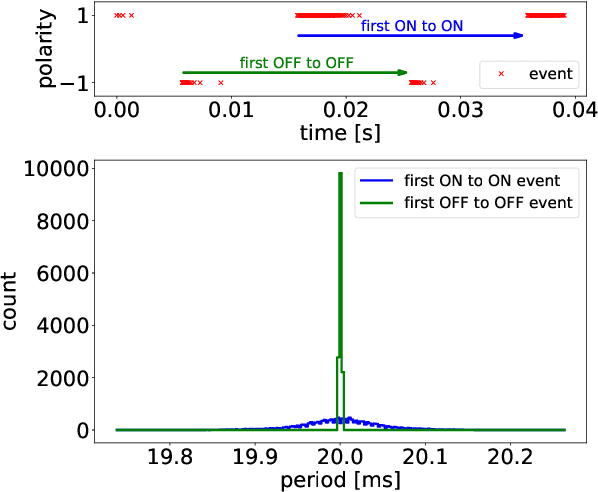
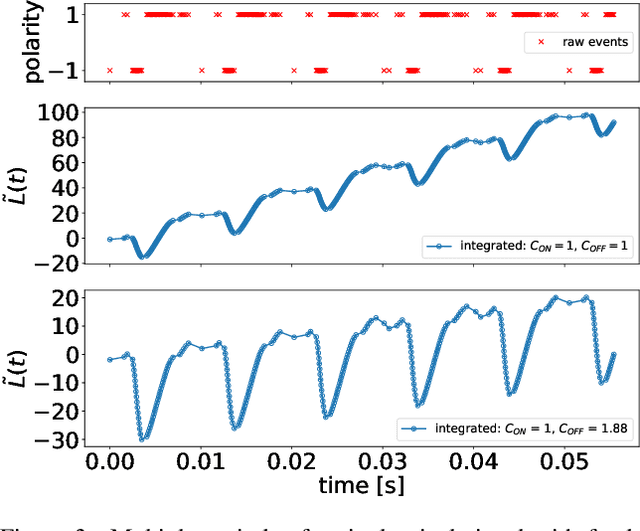
Due to their high temporal resolution and large dynamic range event cameras are uniquely suited for the analysis of time-periodic signals in an image. In this work we present an efficient and fully asynchronous event camera algorithm for detecting the fundamental frequency at which image pixels flicker. The algorithm employs a second-order digital infinite impulse response (IIR) filter to perform an approximate per-pixel brightness reconstruction and is more robust to high-frequency noise than the baseline method we compare to. We further demonstrate that using the falling edge of the signal leads to more accurate period estimates than the rising edge, and that for certain signals interpolating the zero-level crossings can further increase accuracy. Our experiments find that the outstanding capabilities of the camera in detecting frequencies up to 64kHz for a single pixel do not carry over to full sensor imaging as readout bandwidth limitations become a serious obstacle. This suggests that a hardware implementation closer to the sensor will allow for greatly improved frequency imaging. We discuss the important design parameters for fullsensor frequency imaging and present Frequency Cam, an open-source implementation as a ROS node that can run on a single core of a laptop CPU at more than 50 million events per second. It produces results that are qualitatively very similar to those obtained from the closed source vibration analysis module in Prophesee's Metavision Toolkit. The code for Frequency Cam and a demonstration video can be found at https://github.com/berndpfrommer/frequency_cam
COVERED, CollabOratiVE Robot Environment Dataset for 3D Semantic segmentation
Feb 24, 2023
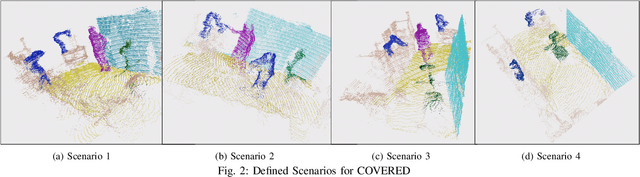
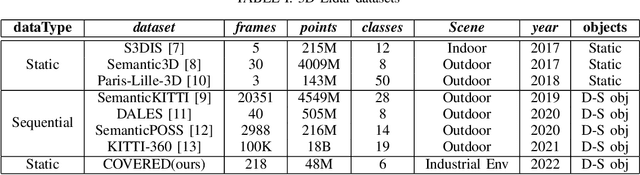
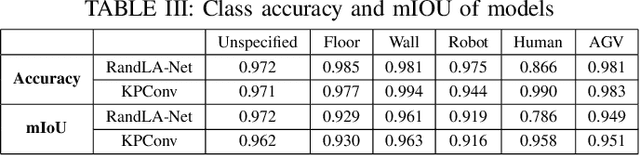
Safe human-robot collaboration (HRC) has recently gained a lot of interest with the emerging Industry 5.0 paradigm. Conventional robots are being replaced with more intelligent and flexible collaborative robots (cobots). Safe and efficient collaboration between cobots and humans largely relies on the cobot's comprehensive semantic understanding of the dynamic surrounding of industrial environments. Despite the importance of semantic understanding for such applications, 3D semantic segmentation of collaborative robot workspaces lacks sufficient research and dedicated datasets. The performance limitation caused by insufficient datasets is called 'data hunger' problem. To overcome this current limitation, this work develops a new dataset specifically designed for this use case, named "COVERED", which includes point-wise annotated point clouds of a robotic cell. Lastly, we also provide a benchmark of current state-of-the-art (SOTA) algorithm performance on the dataset and demonstrate a real-time semantic segmentation of a collaborative robot workspace using a multi-LiDAR system. The promising results from using the trained Deep Networks on a real-time dynamically changing situation shows that we are on the right track. Our perception pipeline achieves 20Hz throughput with a prediction point accuracy of $>$96\% and $>$92\% mean intersection over union (mIOU) while maintaining an 8Hz throughput.