 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
What Can Human Sketches Do for Object Detection?
Mar 27, 2023
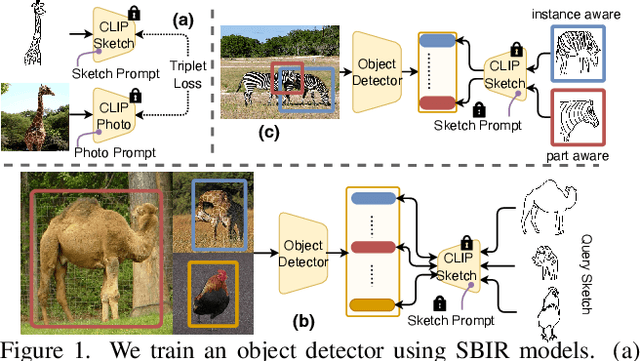
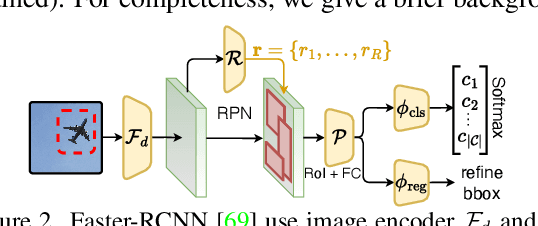
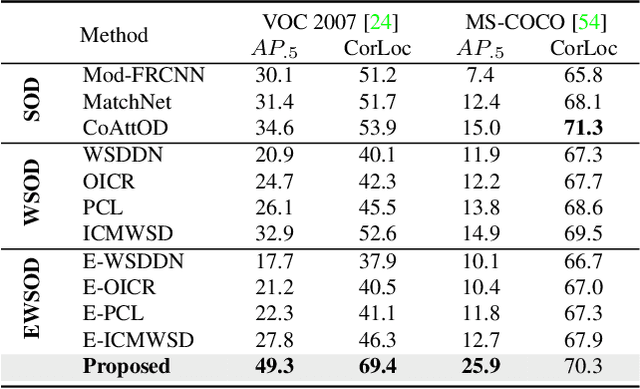
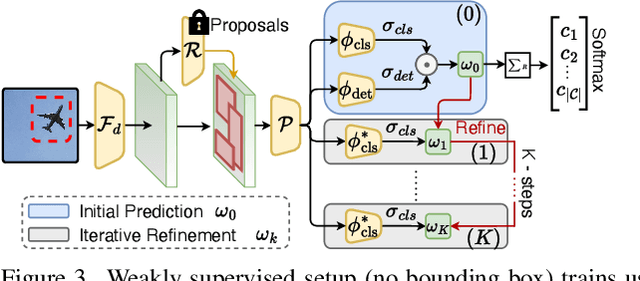
Sketches are highly expressive, inherently capturing subjective and fine-grained visual cues. The exploration of such innate properties of human sketches has, however, been limited to that of image retrieval. In this paper, for the first time, we cultivate the expressiveness of sketches but for the fundamental vision task of object detection. The end result is a sketch-enabled object detection framework that detects based on what \textit{you} sketch -- \textit{that} ``zebra'' (e.g., one that is eating the grass) in a herd of zebras (instance-aware detection), and only the \textit{part} (e.g., ``head" of a ``zebra") that you desire (part-aware detection). We further dictate that our model works without (i) knowing which category to expect at testing (zero-shot) and (ii) not requiring additional bounding boxes (as per fully supervised) and class labels (as per weakly supervised). Instead of devising a model from the ground up, we show an intuitive synergy between foundation models (e.g., CLIP) and existing sketch models build for sketch-based image retrieval (SBIR), which can already elegantly solve the task -- CLIP to provide model generalisation, and SBIR to bridge the (sketch$\rightarrow$photo) gap. In particular, we first perform independent prompting on both sketch and photo branches of an SBIR model to build highly generalisable sketch and photo encoders on the back of the generalisation ability of CLIP. We then devise a training paradigm to adapt the learned encoders for object detection, such that the region embeddings of detected boxes are aligned with the sketch and photo embeddings from SBIR. Evaluating our framework on standard object detection datasets like PASCAL-VOC and MS-COCO outperforms both supervised (SOD) and weakly-supervised object detectors (WSOD) on zero-shot setups. Project Page: \url{https://pinakinathc.github.io/sketch-detect}
SETAR-Tree: A Novel and Accurate Tree Algorithm for Global Time Series Forecasting
Nov 16, 2022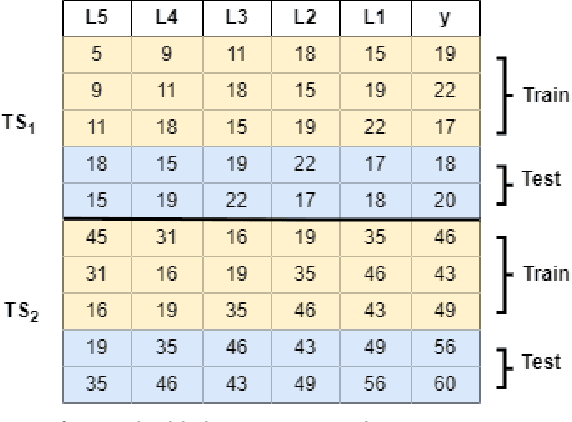
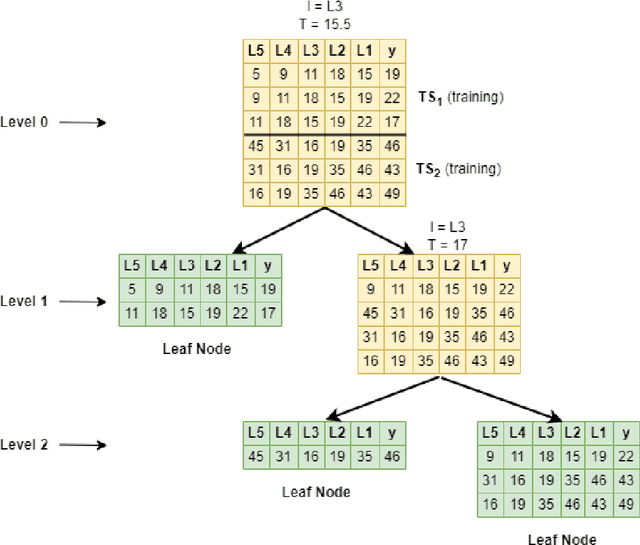
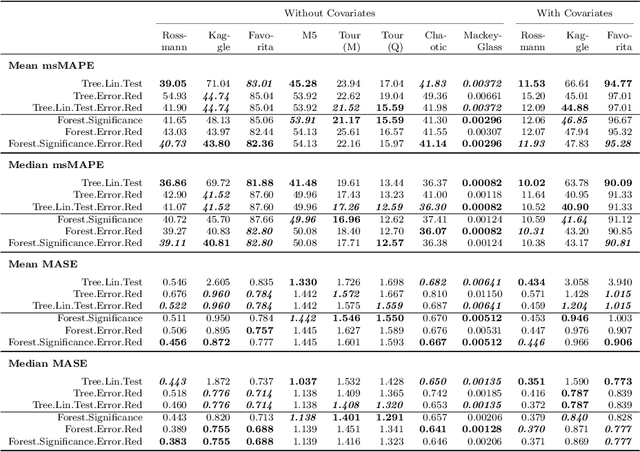
Threshold Autoregressive (TAR) models have been widely used by statisticians for non-linear time series forecasting during the past few decades, due to their simplicity and mathematical properties. On the other hand, in the forecasting community, general-purpose tree-based regression algorithms (forests, gradient-boosting) have become popular recently due to their ease of use and accuracy. In this paper, we explore the close connections between TAR models and regression trees. These enable us to use the rich methodology from the literature on TAR models to define a hierarchical TAR model as a regression tree that trains globally across series, which we call SETAR-Tree. In contrast to the general-purpose tree-based models that do not primarily focus on forecasting, and calculate averages at the leaf nodes, we introduce a new forecasting-specific tree algorithm that trains global Pooled Regression (PR) models in the leaves allowing the models to learn cross-series information and also uses some time-series-specific splitting and stopping procedures. The depth of the tree is controlled by conducting a statistical linearity test commonly employed in TAR models, as well as measuring the error reduction percentage at each node split. Thus, the proposed tree model requires minimal external hyperparameter tuning and provides competitive results under its default configuration. We also use this tree algorithm to develop a forest where the forecasts provided by a collection of diverse SETAR-Trees are combined during the forecasting process. In our evaluation on eight publicly available datasets, the proposed tree and forest models are able to achieve significantly higher accuracy than a set of state-of-the-art tree-based algorithms and forecasting benchmarks across four evaluation metrics.
Deep Spiking Neural Networks with High Representation Similarity Model Visual Pathways of Macaque and Mouse
Mar 09, 2023

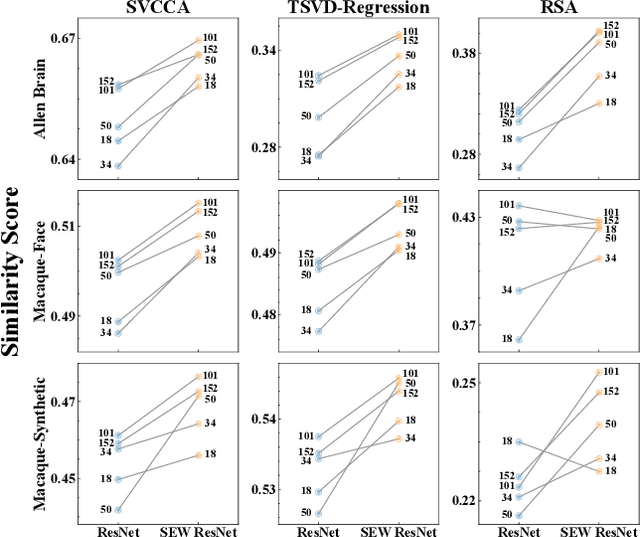

Deep artificial neural networks (ANNs) play a major role in modeling the visual pathways of primate and rodent. However, they highly simplify the computational properties of neurons compared to their biological counterparts. Instead, Spiking Neural Networks (SNNs) are more biologically plausible models since spiking neurons encode information with time sequences of spikes, just like biological neurons do. However, there is a lack of studies on visual pathways with deep SNNs models. In this study, we model the visual cortex with deep SNNs for the first time, and also with a wide range of state-of-the-art deep CNNs and ViTs for comparison. Using three similarity metrics, we conduct neural representation similarity experiments on three neural datasets collected from two species under three types of stimuli. Based on extensive similarity analyses, we further investigate the functional hierarchy and mechanisms across species. Almost all similarity scores of SNNs are higher than their counterparts of CNNs with an average of 6.6%. Depths of the layers with the highest similarity scores exhibit little differences across mouse cortical regions, but vary significantly across macaque regions, suggesting that the visual processing structure of mice is more regionally homogeneous than that of macaques. Besides, the multi-branch structures observed in some top mouse brain-like neural networks provide computational evidence of parallel processing streams in mice, and the different performance in fitting macaque neural representations under different stimuli exhibits the functional specialization of information processing in macaques. Taken together, our study demonstrates that SNNs could serve as promising candidates to better model and explain the functional hierarchy and mechanisms of the visual system.
Identifying Resonant Poles by Visual Inspection of Pole-Zero Plots
Feb 10, 2023
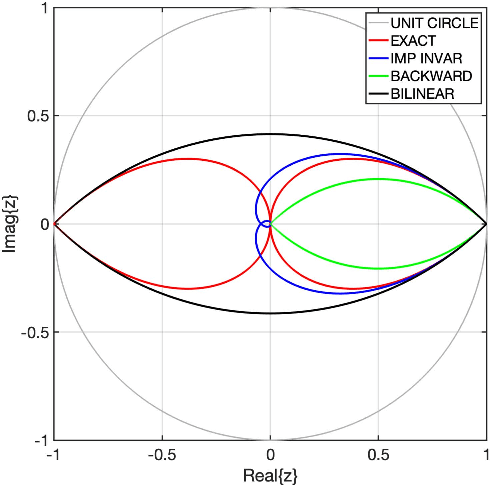
We derive the s- and z-plane pole regions for continuous-time and discrete-time LTI systems to yield resonance. In this way, resonance can be identified by visual inspection of the pole-zero plot, without the need for calculations.
Label-Efficient Deep Learning in Medical Image Analysis: Challenges and Future Directions
Mar 22, 2023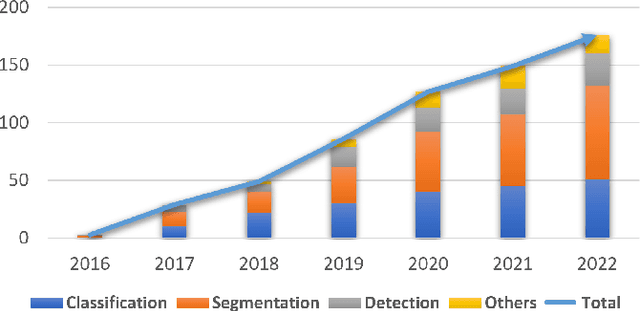
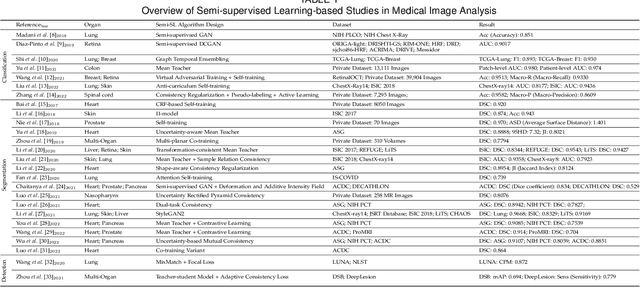
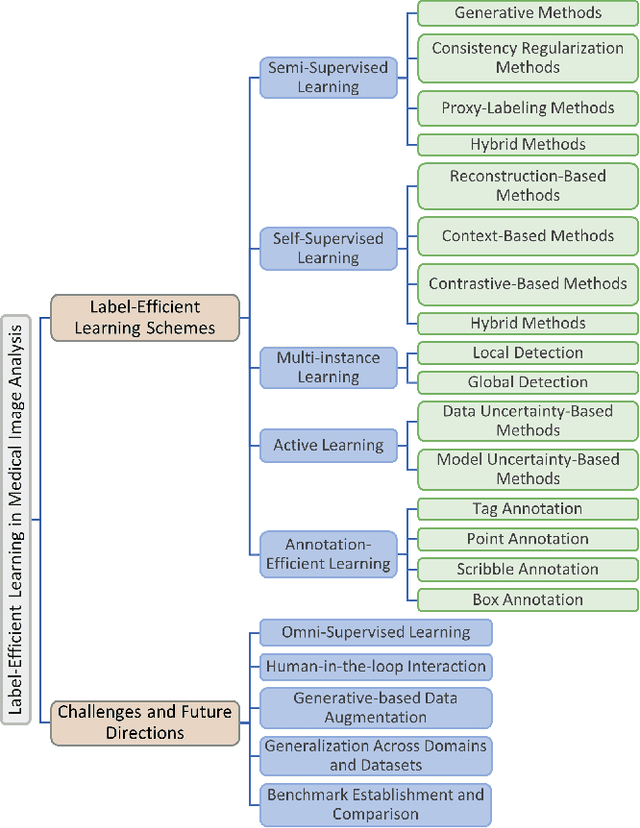
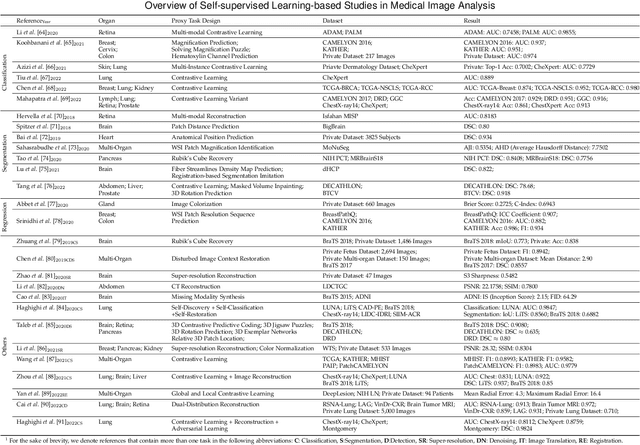
Deep learning has seen rapid growth in recent years and achieved state-of-the-art performance in a wide range of applications. However, training models typically requires expensive and time-consuming collection of large quantities of labeled data. This is particularly true within the scope of medical imaging analysis (MIA), where data are limited and labels are expensive to be acquired. Thus, label-efficient deep learning methods are developed to make comprehensive use of the labeled data as well as the abundance of unlabeled and weak-labeled data. In this survey, we extensively investigated over 300 recent papers to provide a comprehensive overview of recent progress on label-efficient learning strategies in MIA. We first present the background of label-efficient learning and categorize the approaches into different schemes. Next, we examine the current state-of-the-art methods in detail through each scheme. Specifically, we provide an in-depth investigation, covering not only canonical semi-supervised, self-supervised, and multi-instance learning schemes, but also recently emerged active and annotation-efficient learning strategies. Moreover, as a comprehensive contribution to the field, this survey not only elucidates the commonalities and unique features of the surveyed methods but also presents a detailed analysis of the current challenges in the field and suggests potential avenues for future research.
Wasserstein Auto-encoded MDPs: Formal Verification of Efficiently Distilled RL Policies with Many-sided Guarantees
Mar 22, 2023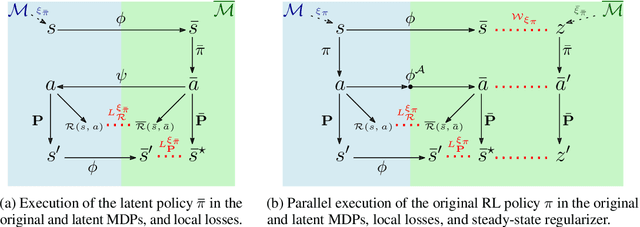

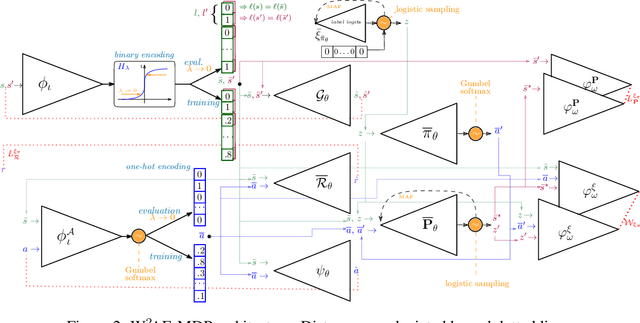

Although deep reinforcement learning (DRL) has many success stories, the large-scale deployment of policies learned through these advanced techniques in safety-critical scenarios is hindered by their lack of formal guarantees. Variational Markov Decision Processes (VAE-MDPs) are discrete latent space models that provide a reliable framework for distilling formally verifiable controllers from any RL policy. While the related guarantees address relevant practical aspects such as the satisfaction of performance and safety properties, the VAE approach suffers from several learning flaws (posterior collapse, slow learning speed, poor dynamics estimates), primarily due to the absence of abstraction and representation guarantees to support latent optimization. We introduce the Wasserstein auto-encoded MDP (WAE-MDP), a latent space model that fixes those issues by minimizing a penalized form of the optimal transport between the behaviors of the agent executing the original policy and the distilled policy, for which the formal guarantees apply. Our approach yields bisimulation guarantees while learning the distilled policy, allowing concrete optimization of the abstraction and representation model quality. Our experiments show that, besides distilling policies up to 10 times faster, the latent model quality is indeed better in general. Moreover, we present experiments from a simple time-to-failure verification algorithm on the latent space. The fact that our approach enables such simple verification techniques highlights its applicability.
Towards AI-controlled FES-restoration of movements: Learning cycling stimulation pattern with reinforcement learning
Mar 22, 2023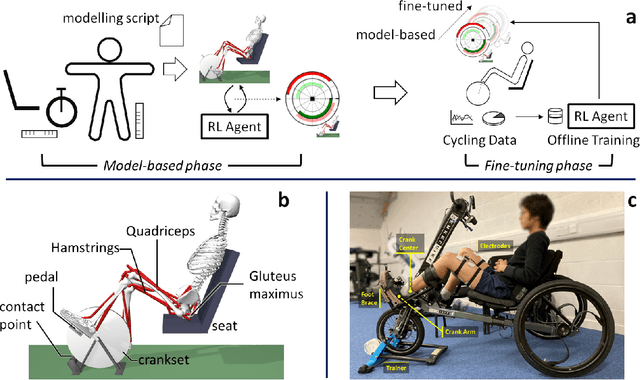
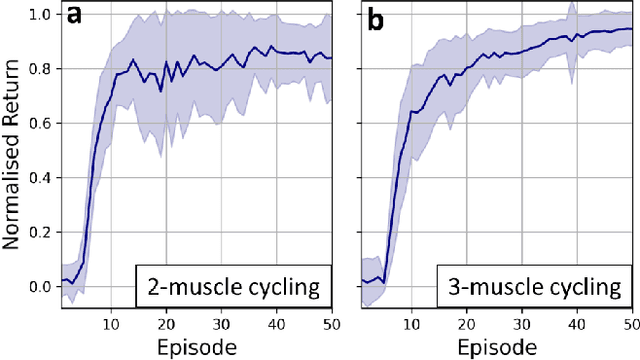
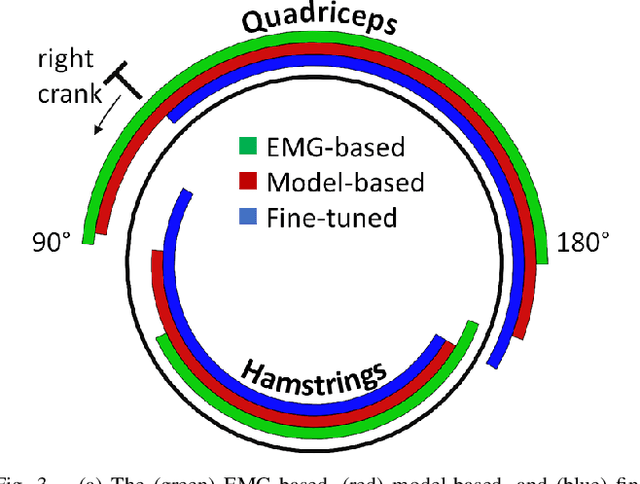
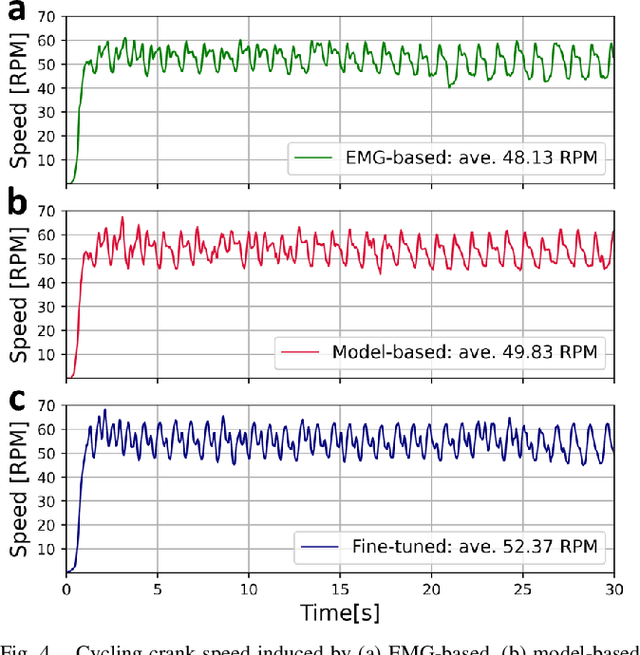
Functional electrical stimulation (FES) has been increasingly integrated with other rehabilitation devices, including robots. FES cycling is one of the common FES applications in rehabilitation, which is performed by stimulating leg muscles in a certain pattern. The appropriate pattern varies across individuals and requires manual tuning which can be time-consuming and challenging for the individual user. Here, we present an AI-based method for finding the patterns, which requires no extra hardware or sensors. Our method has two phases, starting with finding model-based patterns using reinforcement learning and detailed musculoskeletal models. The models, built using open-source software, can be customised through our automated script and can be therefore used by non-technical individuals without extra cost. Next, our method fine-tunes the pattern using real cycling data. We test our both in simulation and experimentally on a stationary tricycle. In the simulation test, our method can robustly deliver model-based patterns for different cycling configurations. The experimental evaluation shows that our method can find a model-based pattern that induces higher cycling speed than an EMG-based pattern. By using just 100 seconds of cycling data, our method can deliver a fine-tuned pattern that gives better cycling performance. Beyond FES cycling, this work is a showcase, displaying the feasibility and potential of human-in-the-loop AI in real-world rehabilitation.
Deployment of Image Analysis Algorithms under Prevalence Shifts
Mar 22, 2023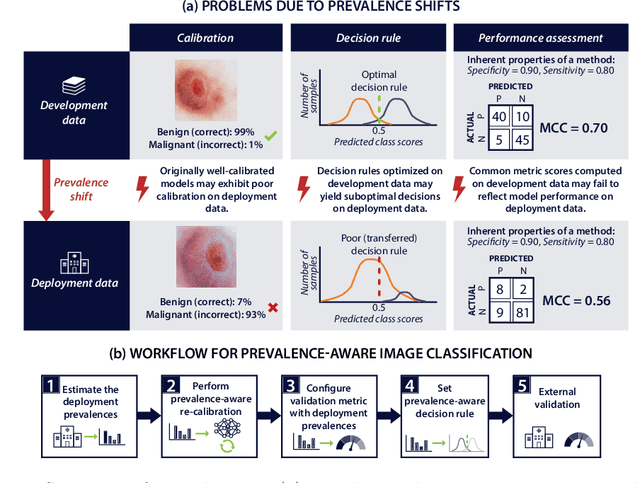

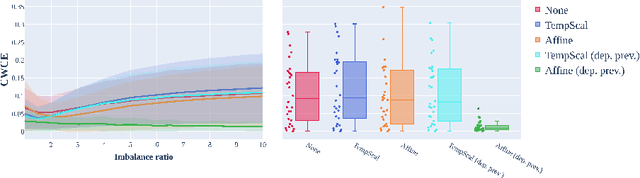
Domain gaps are among the most relevant roadblocks in the clinical translation of machine learning (ML)-based solutions for medical image analysis. While current research focuses on new training paradigms and network architectures, little attention is given to the specific effect of prevalence shifts on an algorithm deployed in practice. Such discrepancies between class frequencies in the data used for a method's development/validation and that in its deployment environment(s) are of great importance, for example in the context of artificial intelligence (AI) democratization, as disease prevalences may vary widely across time and location. Our contribution is twofold. First, we empirically demonstrate the potentially severe consequences of missing prevalence handling by analyzing (i) the extent of miscalibration, (ii) the deviation of the decision threshold from the optimum, and (iii) the ability of validation metrics to reflect neural network performance on the deployment population as a function of the discrepancy between development and deployment prevalence. Second, we propose a workflow for prevalence-aware image classification that uses estimated deployment prevalences to adjust a trained classifier to a new environment, without requiring additional annotated deployment data. Comprehensive experiments based on a diverse set of 30 medical classification tasks showcase the benefit of the proposed workflow in generating better classifier decisions and more reliable performance estimates compared to current practice.
Anomaly Detection in Aeronautics Data with Quantum-compatible Discrete Deep Generative Model
Mar 22, 2023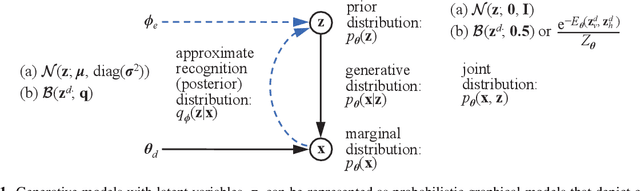
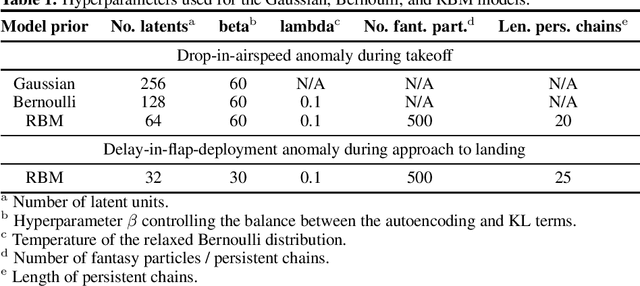
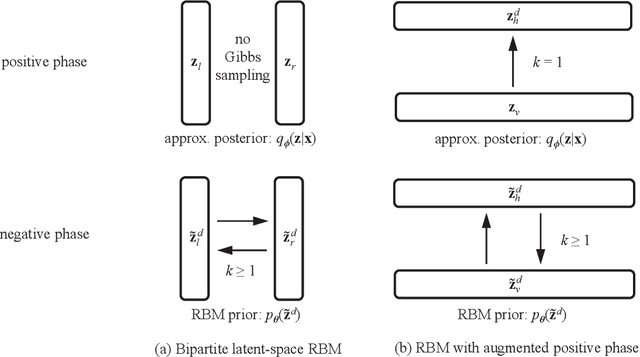

Deep generative learning cannot only be used for generating new data with statistical characteristics derived from input data but also for anomaly detection, by separating nominal and anomalous instances based on their reconstruction quality. In this paper, we explore the performance of three unsupervised deep generative models -- variational autoencoders (VAEs) with Gaussian, Bernoulli, and Boltzmann priors -- in detecting anomalies in flight-operations data of commercial flights consisting of multivariate time series. We devised two VAE models with discrete latent variables (DVAEs), one with a factorized Bernoulli prior and one with a restricted Boltzmann machine (RBM) as prior, because of the demand for discrete-variable models in machine-learning applications and because the integration of quantum devices based on two-level quantum systems requires such models. The DVAE with RBM prior, using a relatively simple -- and classically or quantum-mechanically enhanceable -- sampling technique for the evolution of the RBM's negative phase, performed better than the Bernoulli DVAE and on par with the Gaussian model, which has a continuous latent space. Our studies demonstrate the competitiveness of a discrete deep generative model with its Gaussian counterpart on anomaly-detection tasks. Moreover, the DVAE model with RBM prior can be easily integrated with quantum sampling by outsourcing its generative process to measurements of quantum states obtained from a quantum annealer or gate-model device.
Dynamic EM Ray Tracing for Large Urban Scenes with Multiple Receivers
Mar 19, 2023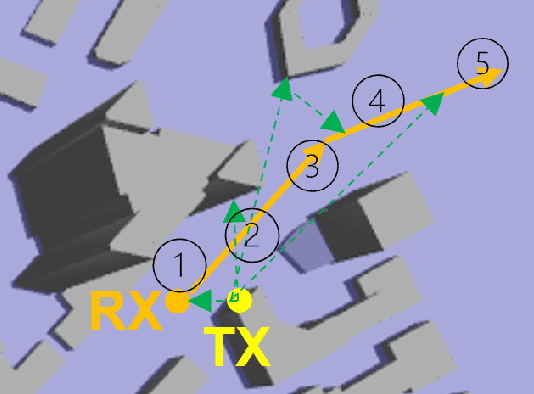
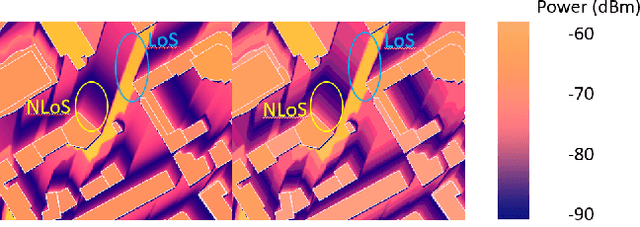
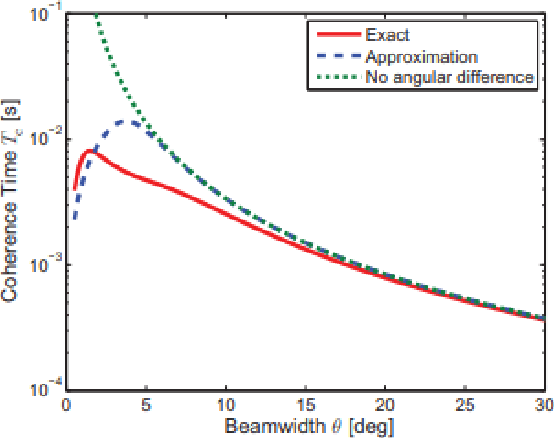
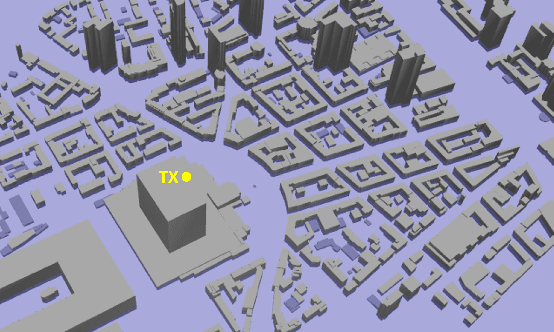
Radio applications are increasingly being used in urban environments for cellular radio systems and safety applications that use vehicle-vehicle, and vehicle-to-infrastructure. We present a novel ray tracing-based radio propagation algorithm that can handle large urban scenes with hundreds or thousands of dynamic objects and receivers. Our approach is based on the use of coherence-based techniques that exploit spatial and temporal coherence for efficient wireless propagation and radio network planning. Our formulation also utilizes channel coherence which is used to determine the effectiveness of the propagation model within a certain time in dynamically generated paths; and spatial consistency which is used to estimate the similarity and accuracy of changes in a dynamic environment with varying propagation models and blocking obstacles. We highlight the performance of our simulator in large urban traffic scenes with an area of 2*2 km^2 and more than 10,000 users and devices. We evaluate the accuracy by comparing the results with discrete model simulations performed using WinProp. In practice, our approach scales linearly with the area of the urban environment and the number of dynamic obstacles or receivers.