 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Branch & Learn with Post-hoc Correction for Predict+Optimize with Unknown Parameters in Constraints
Mar 12, 2023
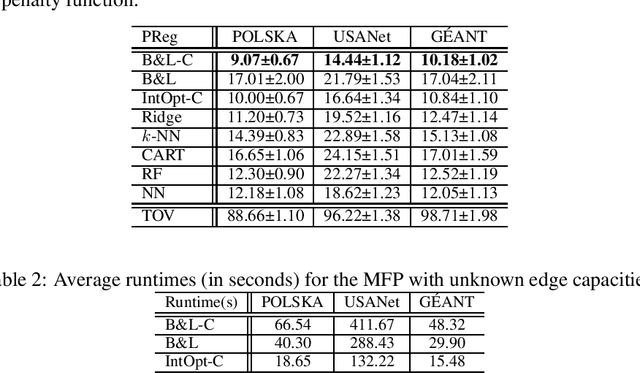
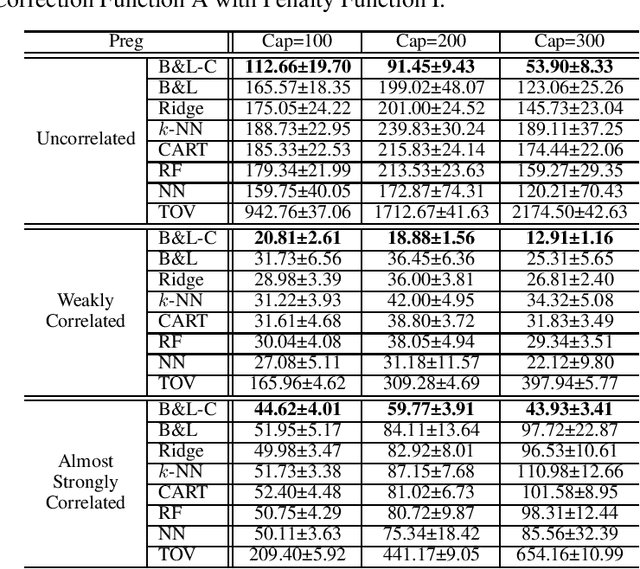
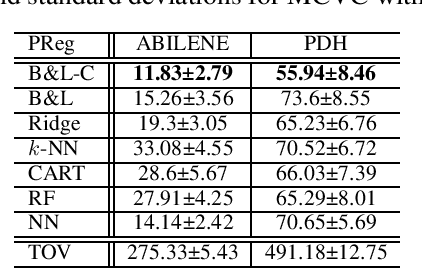
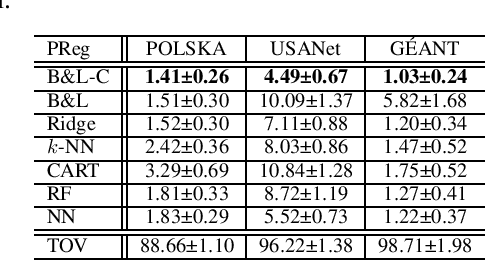
Combining machine learning and constrained optimization, Predict+Optimize tackles optimization problems containing parameters that are unknown at the time of solving. Prior works focus on cases with unknowns only in the objectives. A new framework was recently proposed to cater for unknowns also in constraints by introducing a loss function, called Post-hoc Regret, that takes into account the cost of correcting an unsatisfiable prediction. Since Post-hoc Regret is non-differentiable, the previous work computes only its approximation. While the notion of Post-hoc Regret is general, its specific implementation is applicable to only packing and covering linear programming problems. In this paper, we first show how to compute Post-hoc Regret exactly for any optimization problem solvable by a recursive algorithm satisfying simple conditions. Experimentation demonstrates substantial improvement in the quality of solutions as compared to the earlier approximation approach. Furthermore, we show experimentally the empirical behavior of different combinations of correction and penalty functions used in the Post-hoc Regret of the same benchmarks. Results provide insights for defining the appropriate Post-hoc Regret in different application scenarios.
TempEL: Linking Dynamically Evolving and Newly Emerging Entities
Feb 05, 2023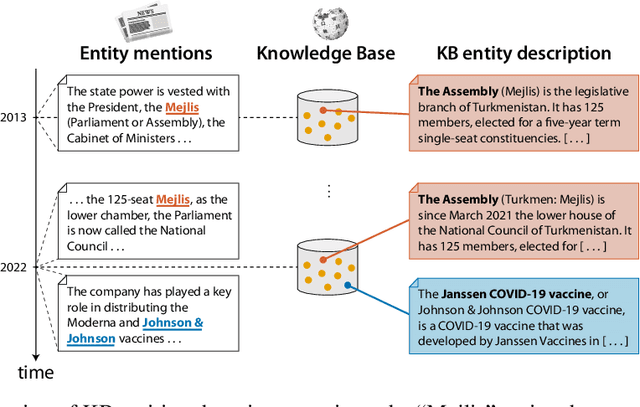
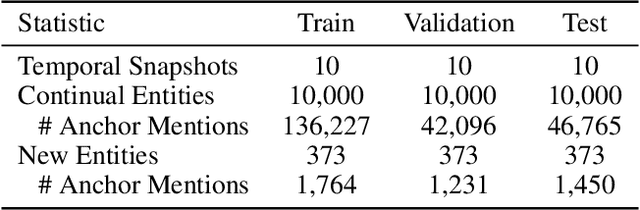
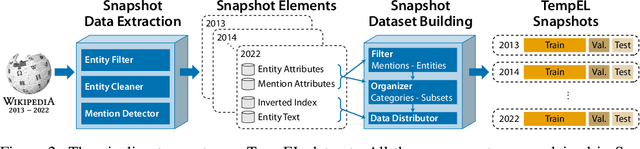
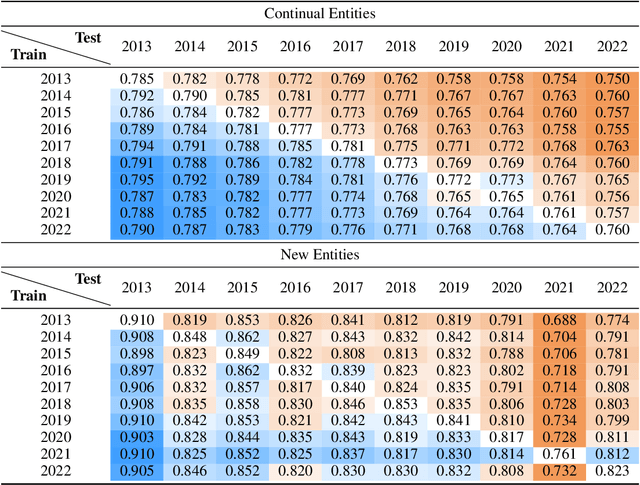
In our continuously evolving world, entities change over time and new, previously non-existing or unknown, entities appear. We study how this evolutionary scenario impacts the performance on a well established entity linking (EL) task. For that study, we introduce TempEL, an entity linking dataset that consists of time-stratified English Wikipedia snapshots from 2013 to 2022, from which we collect both anchor mentions of entities, and these target entities' descriptions. By capturing such temporal aspects, our newly introduced TempEL resource contrasts with currently existing entity linking datasets, which are composed of fixed mentions linked to a single static version of a target Knowledge Base (e.g., Wikipedia 2010 for CoNLL-AIDA). Indeed, for each of our collected temporal snapshots, TempEL contains links to entities that are continual, i.e., occur in all of the years, as well as completely new entities that appear for the first time at some point. Thus, we enable to quantify the performance of current state-of-the-art EL models for: (i) entities that are subject to changes over time in their Knowledge Base descriptions as well as their mentions' contexts, and (ii) newly created entities that were previously non-existing (e.g., at the time the EL model was trained). Our experimental results show that in terms of temporal performance degradation, (i) continual entities suffer a decrease of up to 3.1% EL accuracy, while (ii) for new entities this accuracy drop is up to 17.9%. This highlights the challenge of the introduced TempEL dataset and opens new research prospects in the area of time-evolving entity disambiguation.
Smart ROI Detection for Alzheimer's disease prediction using explainable AI
Mar 18, 2023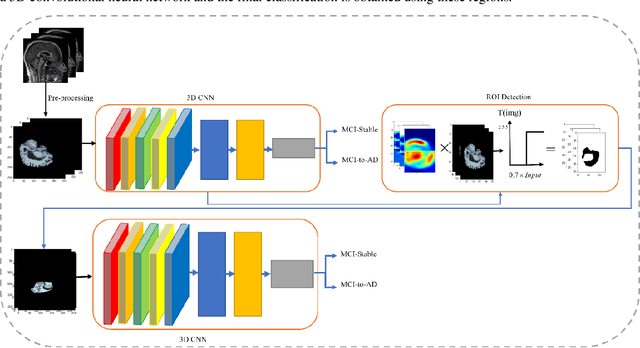
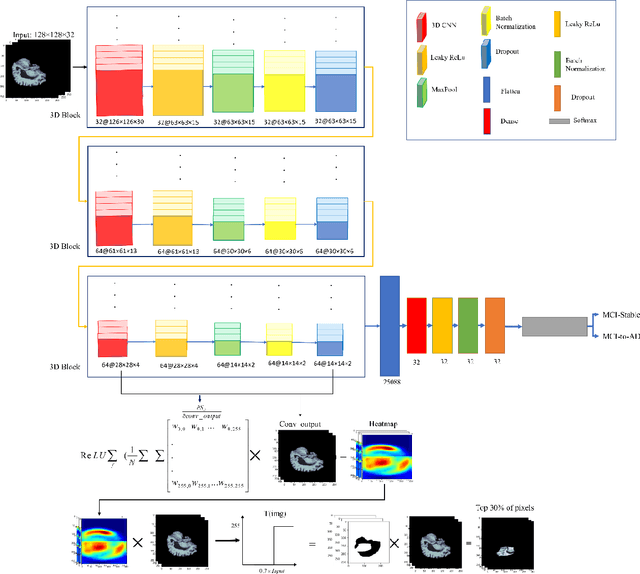
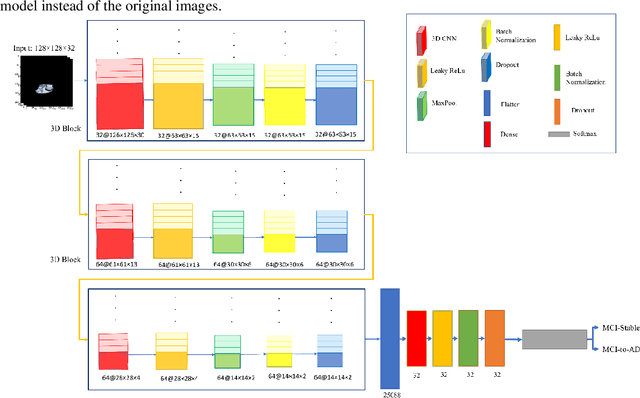
Purpose Predicting the progression of MCI to Alzheimer's disease is an important step in reducing the progression of the disease. Therefore, many methods have been introduced for this task based on deep learning. Among these approaches, the methods based on ROIs are in a good position in terms of accuracy and complexity. In these techniques, some specific parts of the brain are extracted as ROI manually for all of the patients. Extracting ROI manually is time-consuming and its results depend on human expertness and precision. Method To overcome these limitations, we propose a novel smart method for detecting ROIs automatically based on Explainable AI using Grad-Cam and a 3DCNN model that extracts ROIs per patient. After extracting the ROIs automatically, Alzheimer's disease is predicted using extracted ROI-based 3D CNN. Results We implement our method on 176 MCI patients of the famous ADNI dataset and obtain remarkable results compared to the state-of-the-art methods. The accuracy acquired using 5-fold cross-validation is 98.6 and the AUC is 1. We also compare the results of the ROI-based method with the whole brain-based method. The results show that the performance is impressively increased. Conclusion The experimental results show that the proposed smart ROI extraction, which extracts the ROIs automatically, performs well for Alzheimer's disease prediction. The proposed method can also be used for Alzheimer's disease classification and diagnosis.
FedRight: An Effective Model Copyright Protection for Federated Learning
Mar 18, 2023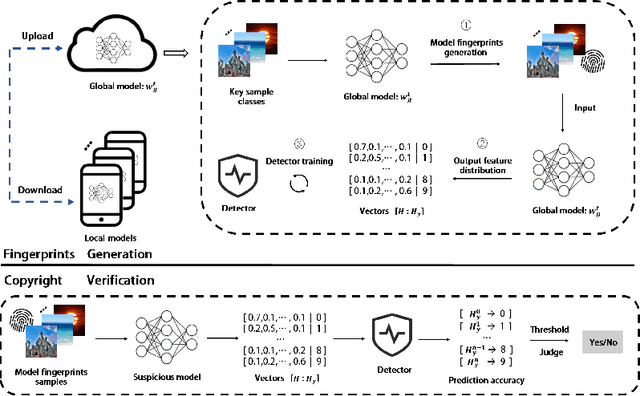

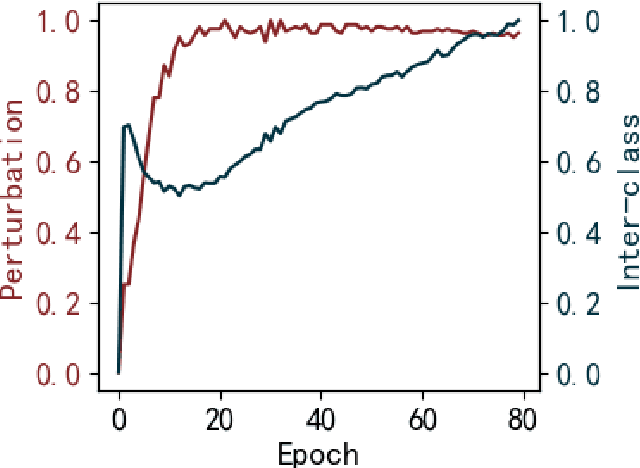
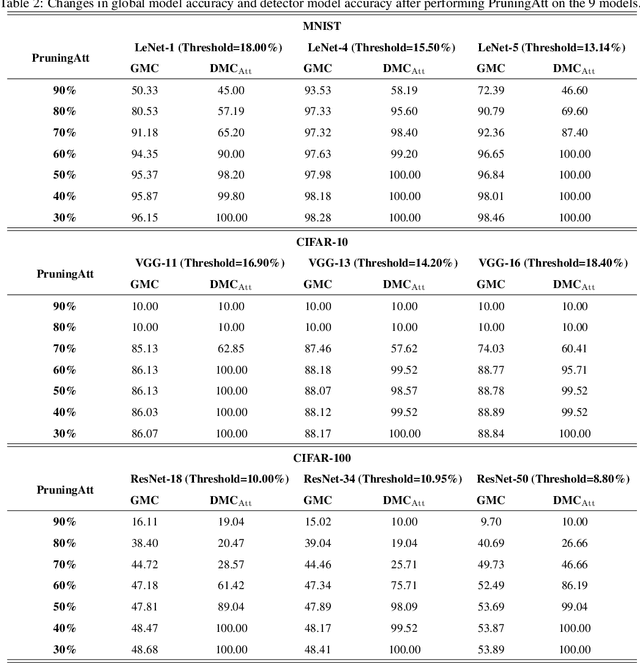
Federated learning (FL), an effective distributed machine learning framework, implements model training and meanwhile protects local data privacy. It has been applied to a broad variety of practice areas due to its great performance and appreciable profits. Who owns the model, and how to protect the copyright has become a real problem. Intuitively, the existing property rights protection methods in centralized scenarios (e.g., watermark embedding and model fingerprints) are possible solutions for FL. But they are still challenged by the distributed nature of FL in aspects of the no data sharing, parameter aggregation, and federated training settings. For the first time, we formalize the problem of copyright protection for FL, and propose FedRight to protect model copyright based on model fingerprints, i.e., extracting model features by generating adversarial examples as model fingerprints. FedRight outperforms previous works in four key aspects: (i) Validity: it extracts model features to generate transferable fingerprints to train a detector to verify the copyright of the model. (ii) Fidelity: it is with imperceptible impact on the federated training, thus promising good main task performance. (iii) Robustness: it is empirically robust against malicious attacks on copyright protection, i.e., fine-tuning, model pruning, and adaptive attacks. (iv) Black-box: it is valid in the black-box forensic scenario where only application programming interface calls to the model are available. Extensive evaluations across 3 datasets and 9 model structures demonstrate FedRight's superior fidelity, validity, and robustness.
Self-FiLM: Conditioning GANs with self-supervised representations for bandwidth extension based speaker recognition
Mar 07, 2023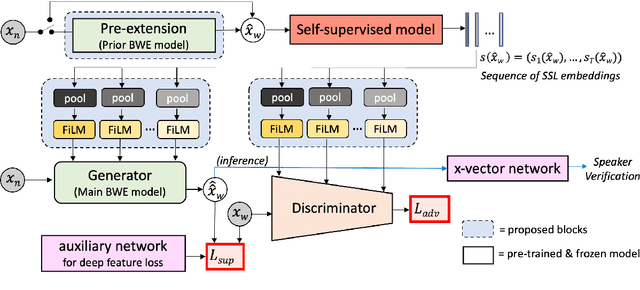
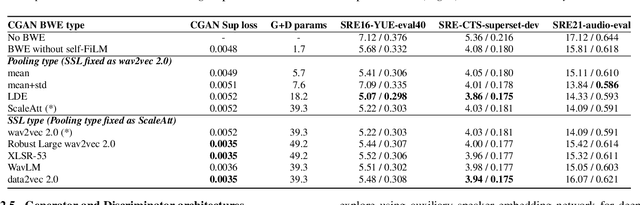
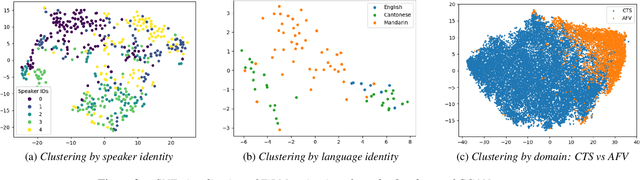
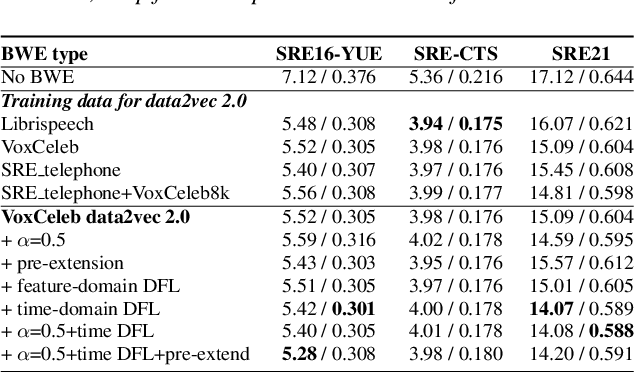
Speech super-resolution/Bandwidth Extension (BWE) can improve downstream tasks like Automatic Speaker Verification (ASV). We introduce a simple novel technique called Self-FiLM to inject self-supervision into existing BWE models via Feature-wise Linear Modulation. We hypothesize that such information captures domain/environment information, which can give zero-shot generalization. Self-FiLM Conditional GAN (CGAN) gives 18% relative improvement in Equal Error Rate and 8.5% in minimum Decision Cost Function using state-of-the-art ASV system on SRE21 test. We further by 1) deep feature loss from time-domain models and 2) re-training of data2vec 2.0 models on naturalistic wideband (VoxCeleb) and telephone data (SRE Superset etc.). Lastly, we integrate self-supervision with CycleGAN to present a completely unsupervised solution that matches the semi-supervised performance.
The hierarchical Newton's method for numerically stable prioritized dynamic control
Mar 08, 2023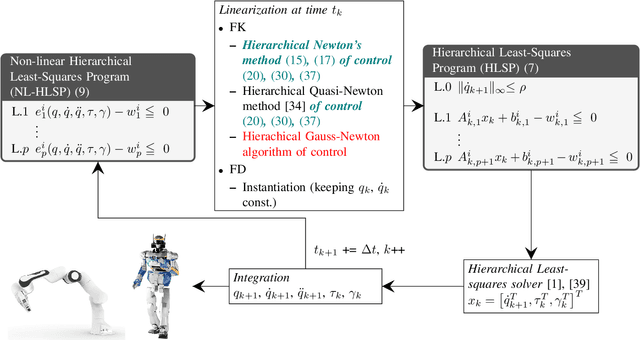
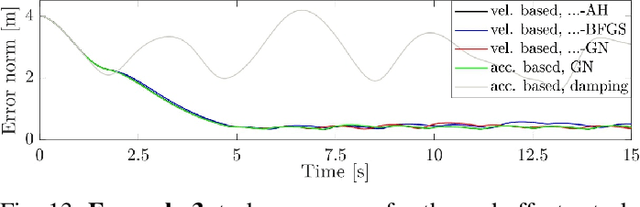
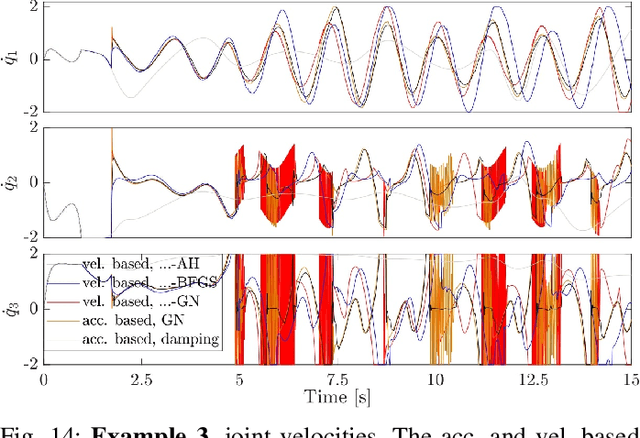
This work links optimization approaches from hierarchical least-squares programming to instantaneous prioritized whole-body robot control. Concretely, we formulate the hierarchical Newton's method which solves prioritized non-linear least-squares problems in a numerically stable fashion even in the presence of kinematic and algorithmic singularities of the approximated kinematic constraints. These results are then transferred to control problems which exhibit the additional variability of time. This is necessary in order to formulate acceleration based controllers and to incorporate the second order dynamics. However, we show that the Newton's method without complicated adaptations is not appropriate in the acceleration domain. We therefore formulate a velocity based controller which exhibits second order proportional derivative convergence characteristics. Our developments are verified in toy robot control scenarios as well as in complex robot experiments which stress the importance of prioritized control and its singularity resolution.
FastSurf: Fast Neural RGB-D Surface Reconstruction using Per-Frame Intrinsic Refinement and TSDF Fusion Prior Learning
Mar 08, 2023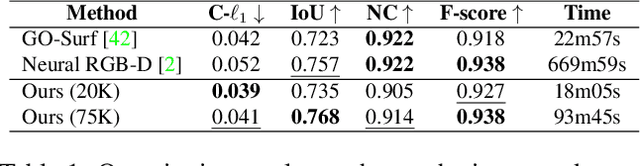



We introduce FastSurf, an accelerated neural radiance field (NeRF) framework that incorporates depth information for 3D reconstruction. A dense feature grid and shallow multi-layer perceptron are used for fast and accurate surface optimization of the entire scene. Our per-frame intrinsic refinement scheme corrects the frame-specific errors that cannot be handled by global optimization. Furthermore, FastSurf utilizes a classical real-time 3D surface reconstruction method, the truncated signed distance field (TSDF) Fusion, as prior knowledge to pretrain the feature grid to accelerate the training. The quantitative and qualitative experiments comparing the performances of FastSurf against prior work indicate that our method is capable of quickly and accurately reconstructing a scene with high-frequency details. We also demonstrate the effectiveness of our per-frame intrinsic refinement and TSDF Fusion prior learning techniques via an ablation study.
Dynamic Scenario Representation Learning for Motion Forecasting with Heterogeneous Graph Convolutional Recurrent Networks
Mar 08, 2023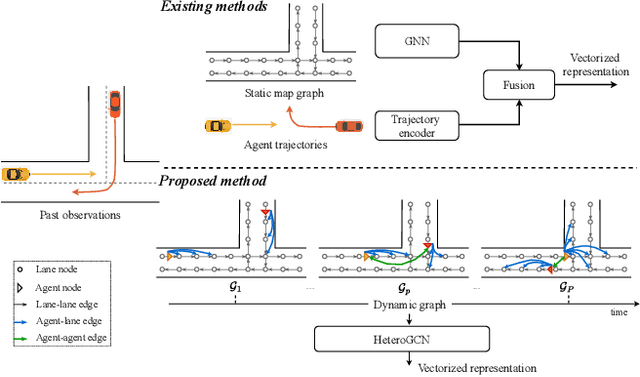
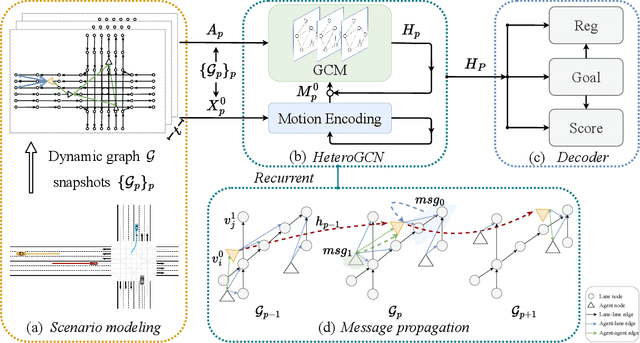

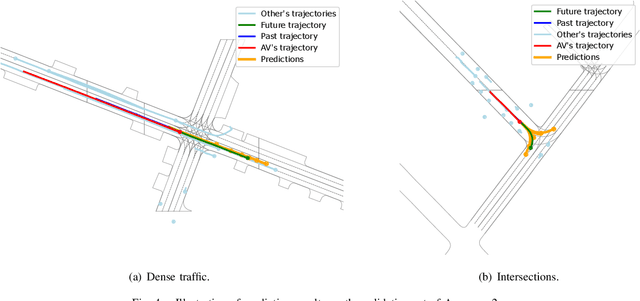
Due to the complex and changing interactions in dynamic scenarios, motion forecasting is a challenging problem in autonomous driving. Most existing works exploit static road graphs to characterize scenarios and are limited in modeling evolving spatio-temporal dependencies in dynamic scenarios. In this paper, we resort to dynamic heterogeneous graphs to model the scenario. Various scenario components including vehicles (agents) and lanes, multi-type interactions, and their changes over time are jointly encoded. Furthermore, we design a novel heterogeneous graph convolutional recurrent network, aggregating diverse interaction information and capturing their evolution, to learn to exploit intrinsic spatio-temporal dependencies in dynamic graphs and obtain effective representations of dynamic scenarios. Finally, with a motion forecasting decoder, our model predicts realistic and multi-modal future trajectories of agents and outperforms state-of-the-art published works on several motion forecasting benchmarks.
PL-UNeXt: Per-stage Edge Detail and Line Feature Guided Segmentation for Power Line Detection
Mar 08, 2023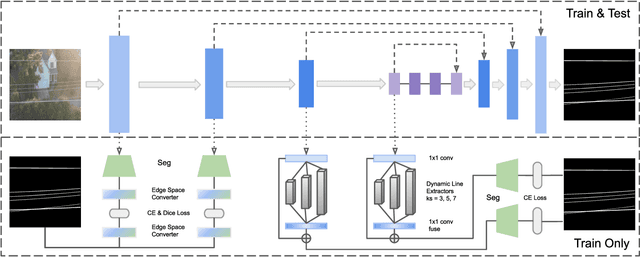
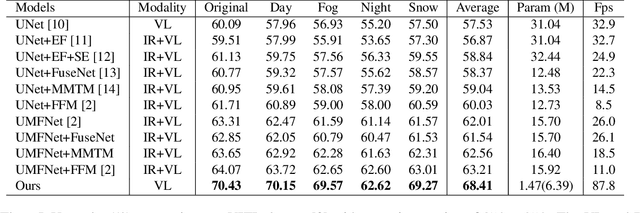
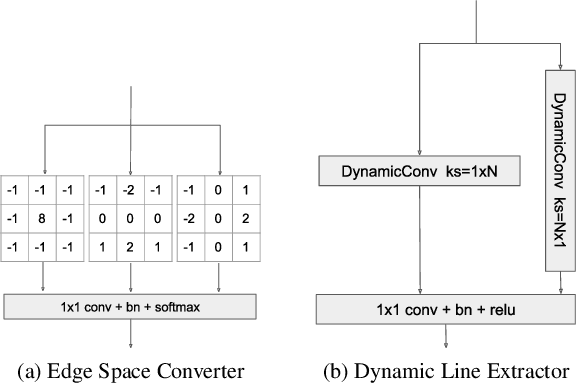
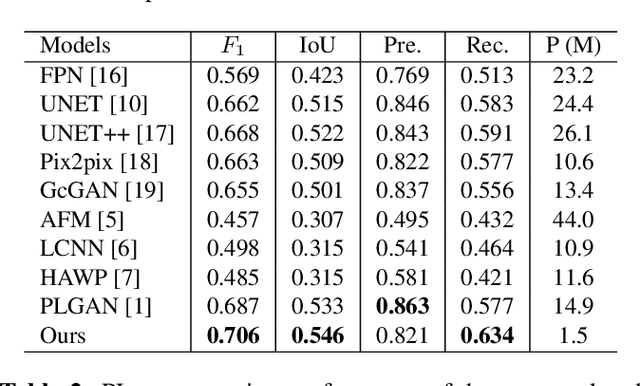
Power line detection is a critical inspection task for electricity companies and is also useful in avoiding drone obstacles. Accurately separating power lines from the surrounding area in the aerial image is still challenging due to the intricate background and low pixel ratio. In order to properly capture the guidance of the spatial edge detail prior and line features, we offer PL-UNeXt, a power line segmentation model with a booster training strategy. We design edge detail heads computing the loss in edge space to guide the lower-level detail learning and line feature heads generating auxiliary segmentation masks to supervise higher-level line feature learning. Benefited from this design, our model can reach 70.6 F1 score (+1.9%) on TTPLA and 68.41 mIoU (+5.2%) on VITL (without utilizing IR images), while preserving a real-time performance due to few inference parameters.
TS-SEP: Joint Diarization and Separation Conditioned on Estimated Speaker Embeddings
Mar 08, 2023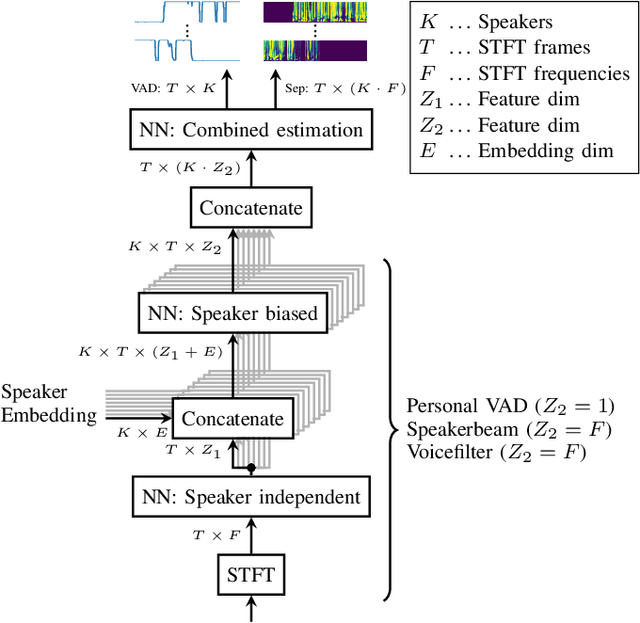
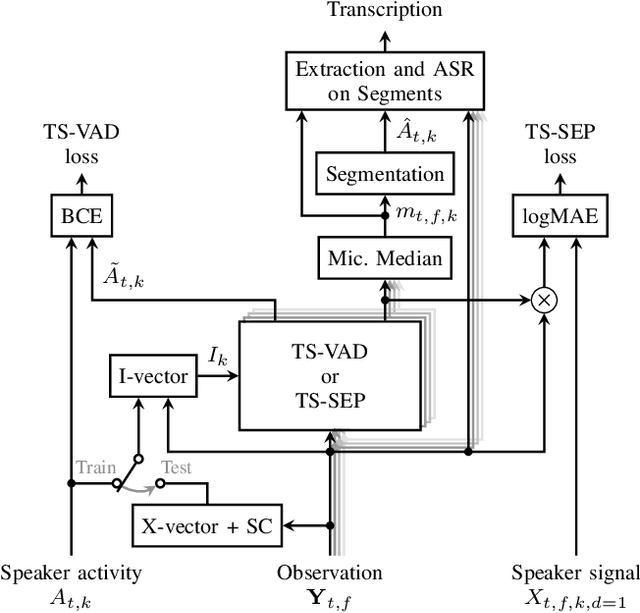
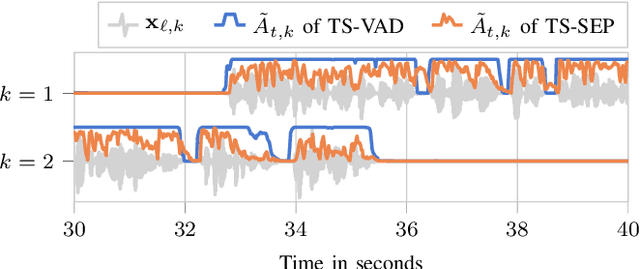
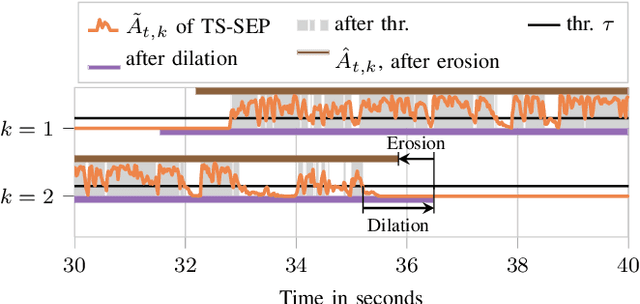
Since diarization and source separation of meeting data are closely related tasks, we here propose an approach to perform the two objectives jointly. It builds upon the target-speaker voice activity detection (TS-VAD) diarization approach, which assumes that initial speaker embeddings are available. We replace the final combined speaker activity estimation network of TS-VAD with a network that produces speaker activity estimates at a time-frequency resolution. Those act as masks for source extraction, either via masking or via beamforming. The technique can be applied both for single-channel and multi-channel input and, in both cases, achieves a new state-of-the-art word error rate (WER) on the LibriCSS meeting data recognition task. We further compute speaker-aware and speaker-agnostic WERs to isolate the contribution of diarization errors to the overall WER performance.