 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
DFR-FastMOT: Detection Failure Resistant Tracker for Fast Multi-Object Tracking Based on Sensor Fusion
Feb 28, 2023
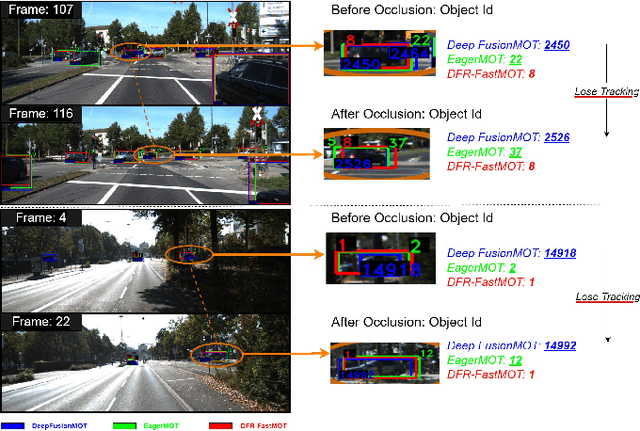
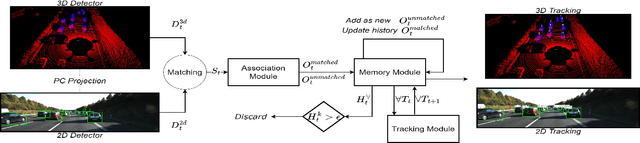

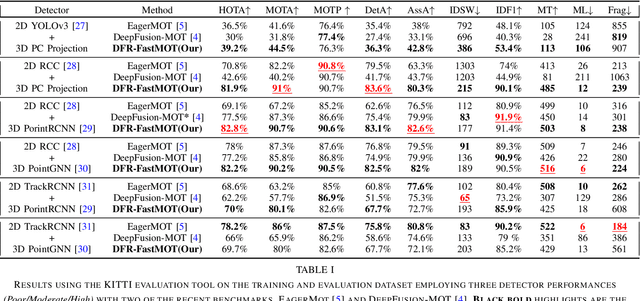
Persistent multi-object tracking (MOT) allows autonomous vehicles to navigate safely in highly dynamic environments. One of the well-known challenges in MOT is object occlusion when an object becomes unobservant for subsequent frames. The current MOT methods store objects information, like objects' trajectory, in internal memory to recover the objects after occlusions. However, they retain short-term memory to save computational time and avoid slowing down the MOT method. As a result, they lose track of objects in some occlusion scenarios, particularly long ones. In this paper, we propose DFR-FastMOT, a light MOT method that uses data from a camera and LiDAR sensors and relies on an algebraic formulation for object association and fusion. The formulation boosts the computational time and permits long-term memory that tackles more occlusion scenarios. Our method shows outstanding tracking performance over recent learning and non-learning benchmarks with about 3% and 4% margin in MOTA, respectively. Also, we conduct extensive experiments that simulate occlusion phenomena by employing detectors with various distortion levels. The proposed solution enables superior performance under various distortion levels in detection over current state-of-art methods. Our framework processes about 7,763 frames in 1.48 seconds, which is seven times faster than recent benchmarks. The framework will be available at https://github.com/MohamedNagyMostafa/DFR-FastMOT.
SuperTran: Reference Based Video Transformer for Enhancing Low Bitrate Streams in Real Time
Nov 22, 2022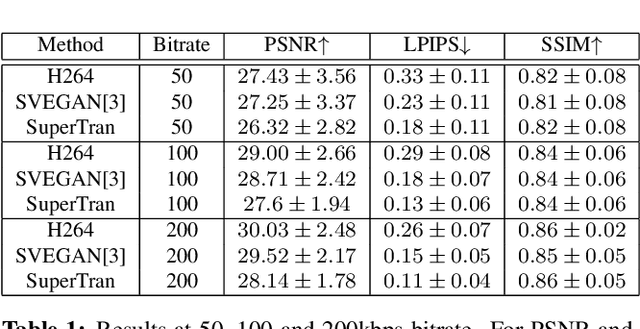
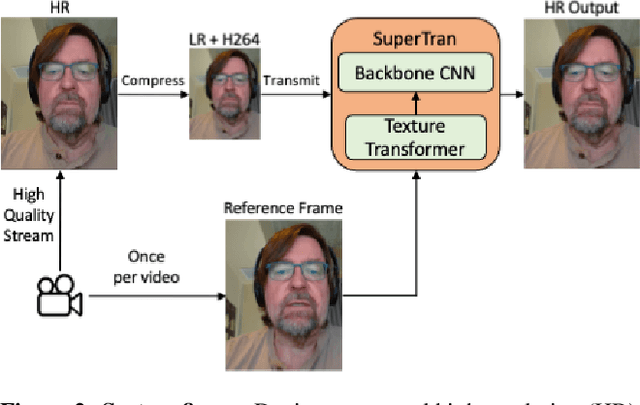
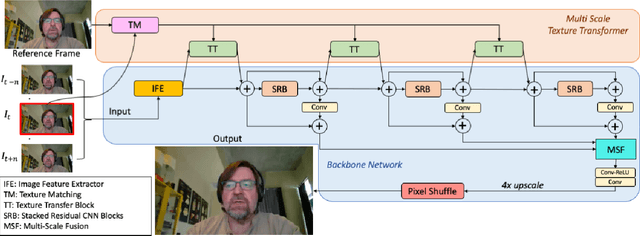
This work focuses on low bitrate video streaming scenarios (e.g. 50 - 200Kbps) where the video quality is severely compromised. We present a family of novel deep generative models for enhancing perceptual video quality of such streams by performing super-resolution while also removing compression artifacts. Our model, which we call SuperTran, consumes as input a single high-quality, high-resolution reference images in addition to the low-quality, low-resolution video stream. The model thus learns how to borrow or copy visual elements like textures from the reference image and fill in the remaining details from the low resolution stream in order to produce perceptually enhanced output video. The reference frame can be sent once at the start of the video session or be retrieved from a gallery. Importantly, the resulting output has substantially better detail than what has been otherwise possible with methods that only use a low resolution input such as the SuperVEGAN method. SuperTran works in real-time (up to 30 frames/sec) on the cloud alongside standard pipelines.
Contrastive Alignment of Vision to Language Through Parameter-Efficient Transfer Learning
Mar 21, 2023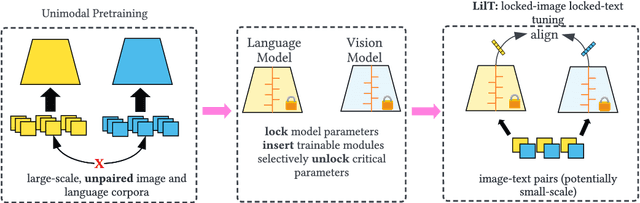

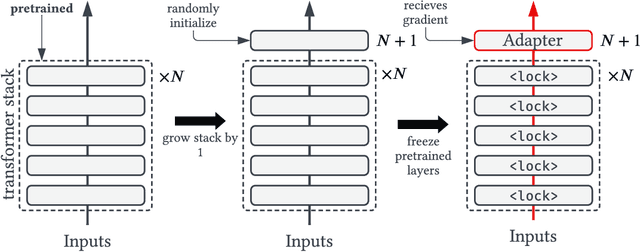
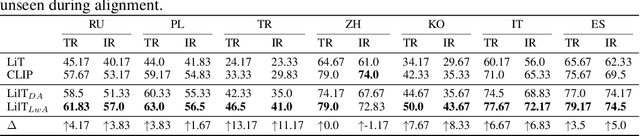
Contrastive vision-language models (e.g. CLIP) are typically created by updating all the parameters of a vision model and language model through contrastive training. Can such models be created by a small number of parameter updates to an already-trained language model and vision model? The literature describes techniques that can create vision-language models by updating a small number of parameters in a language model, but these require already aligned visual representations and are non-contrastive, hence unusable for latency-sensitive applications such as neural search. We explore the feasibility and benefits of parameter-efficient contrastive vision-language alignment through transfer learning: creating a model such as CLIP by minimally updating an already-trained vision and language model. We find that a minimal set of parameter updates ($<$7%) can achieve the same performance as full-model training, and updating specific components ($<$1% of parameters) can match 75% of full-model training. We describe a series of experiments: we show that existing knowledge is conserved more strongly in parameter-efficient training and that parameter-efficient scaling scales with model and dataset size. Where paired-image text data is scarce but strong multilingual language models exist (e.g. low resource languages), parameter-efficient training is even preferable to full-model training. Given a fixed compute budget, parameter-efficient training allows training larger models on the same hardware, achieving equivalent performance in less time. Parameter-efficient training hence constitutes an energy-efficient and effective training strategy for contrastive vision-language models that may be preferable to the full-model training paradigm for common use cases. Code and weights at https://github.com/codezakh/LilT.
Practical Knowledge Distillation: Using DNNs to Beat DNNs
Feb 23, 2023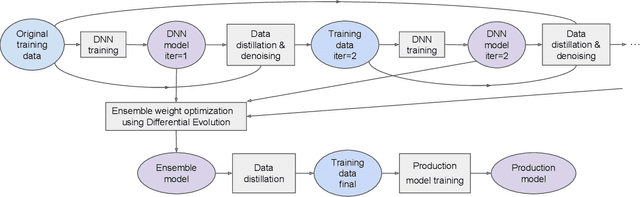
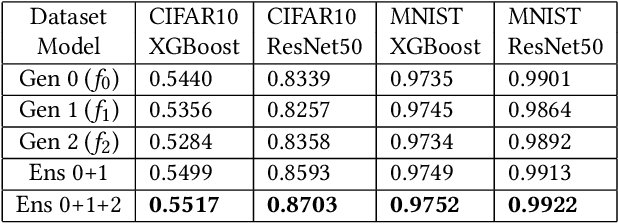
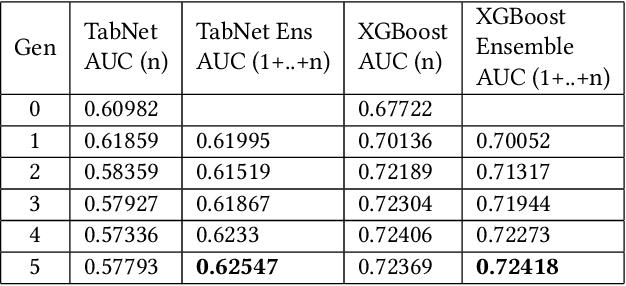

For tabular data sets, we explore data and model distillation, as well as data denoising. These techniques improve both gradient-boosting models and a specialized DNN architecture. While gradient boosting is known to outperform DNNs on tabular data, we close the gap for datasets with 100K+ rows and give DNNs an advantage on small data sets. We extend these results with input-data distillation and optimized ensembling to help DNN performance match or exceed that of gradient boosting. As a theoretical justification of our practical method, we prove its equivalence to classical cross-entropy knowledge distillation. We also qualitatively explain the superiority of DNN ensembles over XGBoost on small data sets. For an industry end-to-end real-time ML platform with 4M production inferences per second, we develop a model-training workflow based on data sampling that distills ensembles of models into a single gradient-boosting model favored for high-performance real-time inference, without performance loss. Empirical evaluation shows that the proposed combination of methods consistently improves model accuracy over prior best models across several production applications deployed worldwide.
UATTA-ENS: Uncertainty Aware Test Time Augmented Ensemble for PIRC Diabetic Retinopathy Detection
Nov 08, 2022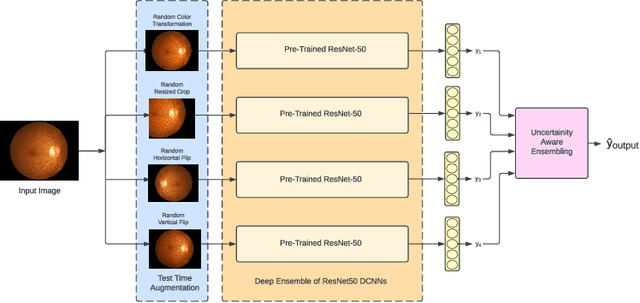
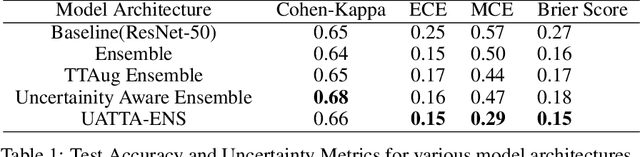
Deep Ensemble Convolutional Neural Networks has become a methodology of choice for analyzing medical images with a diagnostic performance comparable to a physician, including the diagnosis of Diabetic Retinopathy. However, commonly used techniques are deterministic and are therefore unable to provide any estimate of predictive uncertainty. Quantifying model uncertainty is crucial for reducing the risk of misdiagnosis. A reliable architecture should be well-calibrated to avoid over-confident predictions. To address this, we propose a UATTA-ENS: Uncertainty-Aware Test-Time Augmented Ensemble Technique for 5 Class PIRC Diabetic Retinopathy Classification to produce reliable and well-calibrated predictions.
Randomized Control of Wireless Temporal Coherence via Reconfigurable Intelligent Surface
Jan 31, 2023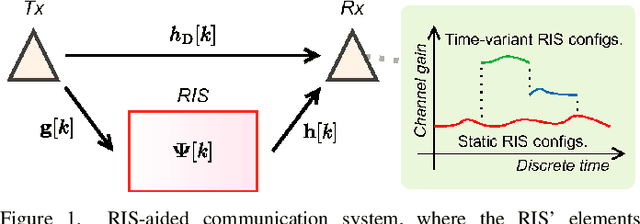
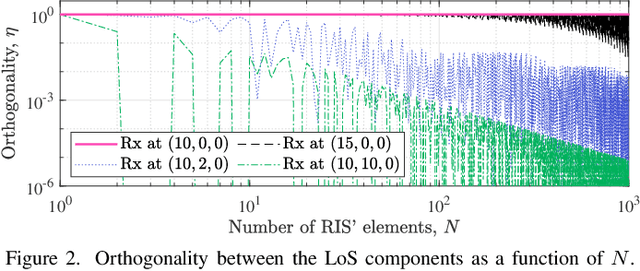
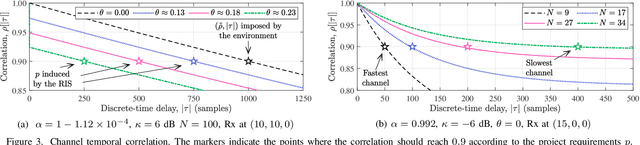
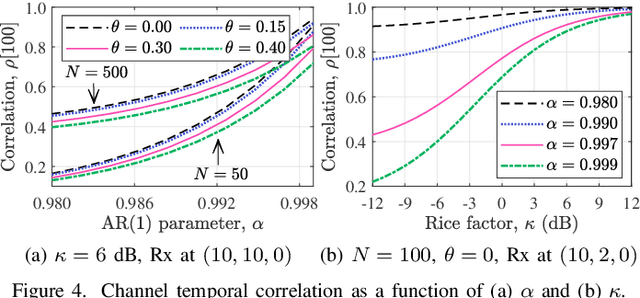
A reconfigurable intelligent surface (RIS) can shape the wireless propagation channel by inducing controlled phase shift variations to the impinging signals. Multiple works have considered the use of RIS by time-varying configurations of reflection coefficients. In this work we use the RIS to control the channel coherence time and introduce a generalized discrete-time-varying channel model for RIS-aided systems. We characterize the temporal variation of channel correlation by assuming that a configuration of RIS' elements changes at every time step. The analysis converges to a randomized framework to control the channel coherence time by setting the number of RIS' elements and their phase shifts. The main result is a framework for a flexible block-fading model, where the number of samples within a coherence block can be dynamically adapted.
Subspace Perturbation Analysis for Data-Driven Radar Target Localization
Mar 14, 2023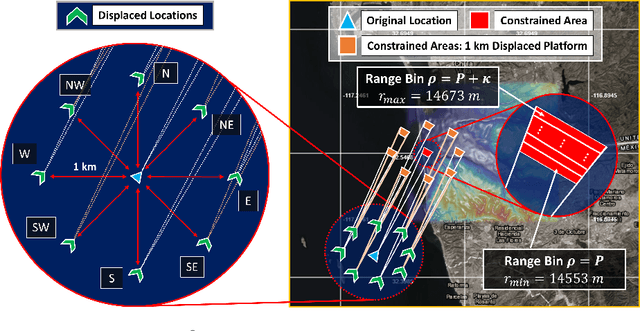
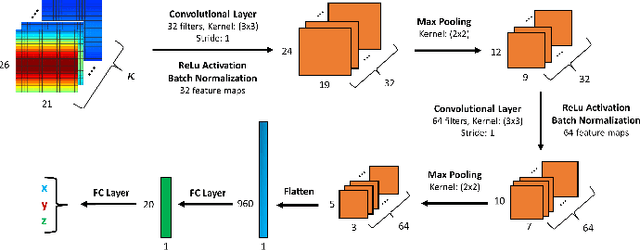
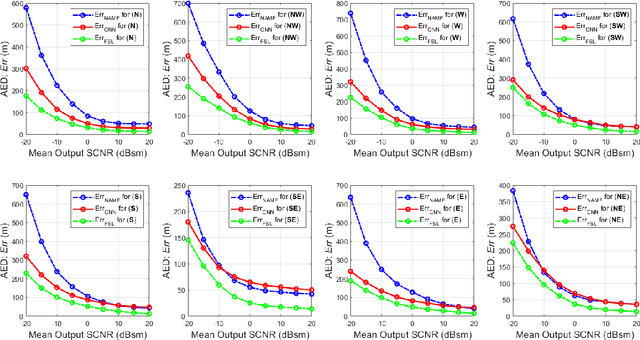

Recent works exploring data-driven approaches to classical problems in adaptive radar have demonstrated promising results pertaining to the task of radar target localization. Via the use of space-time adaptive processing (STAP) techniques and convolutional neural networks, these data-driven approaches to target localization have helped benchmark the performance of neural networks for matched scenarios. However, the thorough bridging of these topics across mismatched scenarios still remains an open problem. As such, in this work, we augment our data-driven approach to radar target localization by performing a subspace perturbation analysis, which allows us to benchmark the localization accuracy of our proposed deep learning framework across mismatched scenarios. To evaluate this framework, we generate comprehensive datasets by randomly placing targets of variable strengths in mismatched constrained areas via RFView, a high-fidelity, site-specific modeling and simulation tool. For the radar returns from these constrained areas, we generate heatmap tensors in range, azimuth, and elevation using the normalized adaptive matched filter (NAMF) test statistic. We estimate target locations from these heatmap tensors using a convolutional neural network, and demonstrate that the predictive performance of our framework in the presence of mismatches can be predetermined.
Neural Video Compression with Diverse Contexts
Mar 14, 2023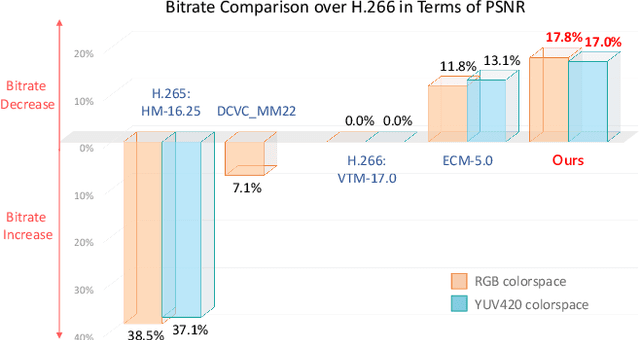
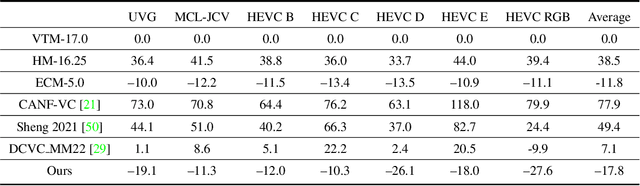
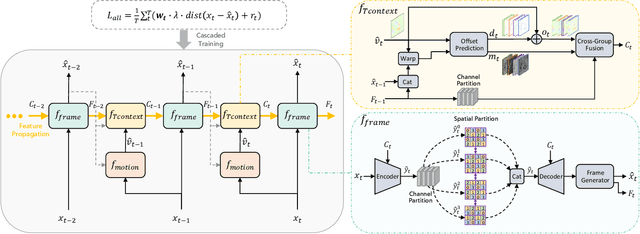
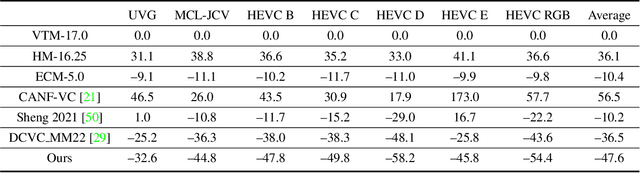
For any video codecs, the coding efficiency highly relies on whether the current signal to be encoded can find the relevant contexts from the previous reconstructed signals. Traditional codec has verified more contexts bring substantial coding gain, but in a time-consuming manner. However, for the emerging neural video codec (NVC), its contexts are still limited, leading to low compression ratio. To boost NVC, this paper proposes increasing the context diversity in both temporal and spatial dimensions. First, we guide the model to learn hierarchical quality patterns across frames, which enriches long-term and yet high-quality temporal contexts. Furthermore, to tap the potential of optical flow-based coding framework, we introduce a group-based offset diversity where the cross-group interaction is proposed for better context mining. In addition, this paper also adopts a quadtree-based partition to increase spatial context diversity when encoding the latent representation in parallel. Experiments show that our codec obtains 23.5% bitrate saving over previous SOTA NVC. Better yet, our codec has surpassed the under-developing next generation traditional codec/ECM in both RGB and YUV420 colorspaces, in terms of PSNR. The codes are at https://github.com/microsoft/DCVC.
GoNet: An Approach-Constrained Generative Grasp Sampling Network
Mar 14, 2023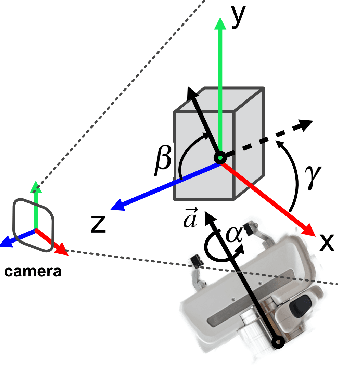

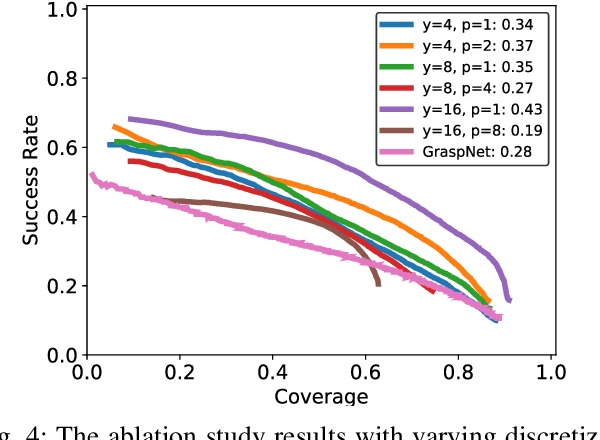
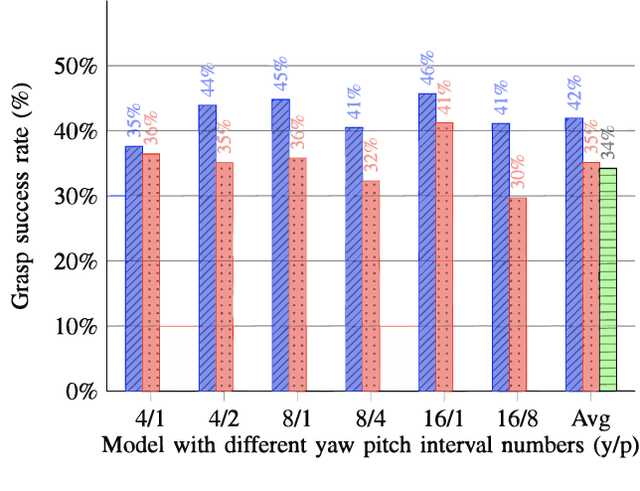
Constraining the approach direction of grasps is important when picking objects in confined spaces, such as when emptying a shelf. Yet, such capabilities are not available in state-of-the-art data-driven grasp sampling methods that sample grasps all around the object. In this work, we address the specific problem of training approach-constrained data-driven grasp samplers and how to generate good grasping directions automatically. Our solution is GoNet: a generative grasp sampler that can constrain the grasp approach direction to lie close to a specified direction. This is achieved by discretizing SO(3) into bins and training GoNet to generate grasps from those bins. At run-time, the bin aligning with the second largest principal component of the observed point cloud is selected. GoNet is benchmarked against GraspNet, a state-of-the-art unconstrained grasp sampler, in an unconfined grasping experiment in simulation and on an unconfined and confined grasping experiment in the real world. The results demonstrate that GoNet achieves higher success-over-coverage in simulation and a 12%-18% higher success rate in real-world table-picking and shelf-picking tasks than the baseline.
Reachability Analysis of Neural Networks with Uncertain Parameters
Mar 14, 2023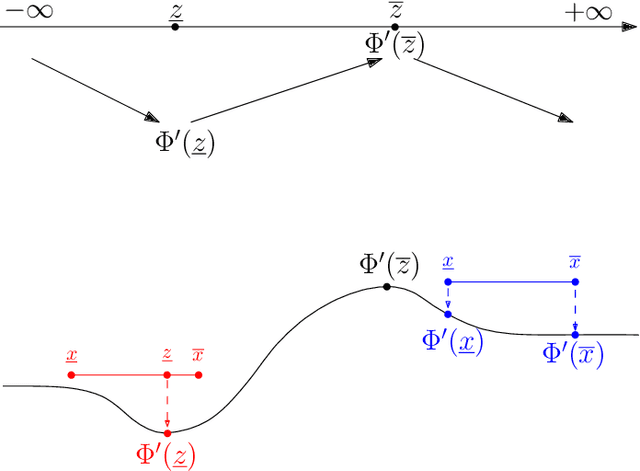

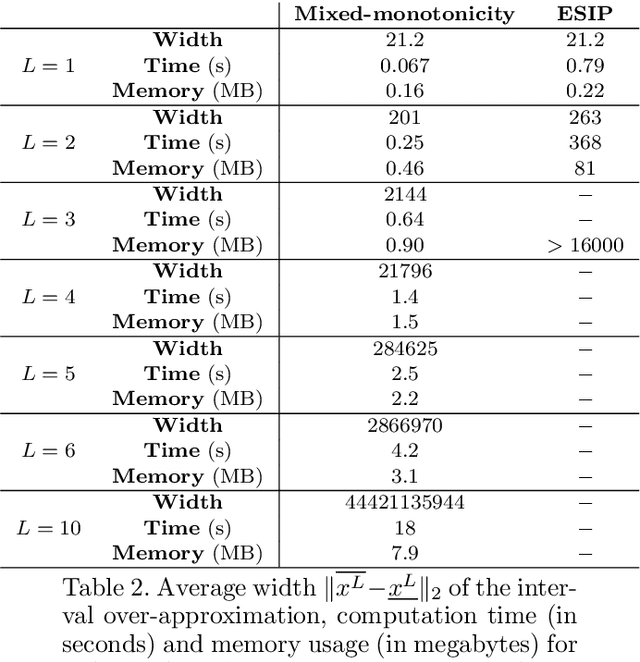
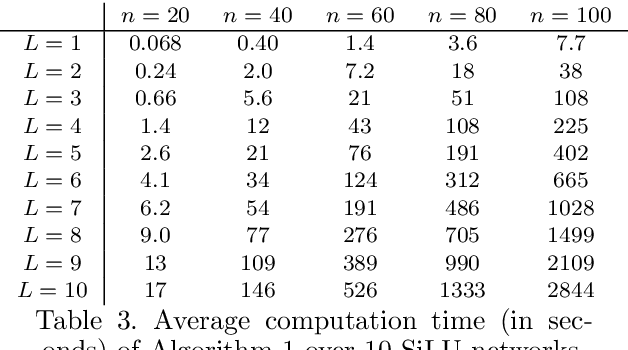
The literature on reachability analysis methods for neural networks currently only focuses on uncertainties on the network's inputs. In this paper, we introduce two new approaches for the reachability analysis of neural networks with additional uncertainties on their internal parameters (weight matrices and bias vectors of each layer), which may open the field of formal methods on neural networks to new topics, such as safe training or network repair. The first and main method that we propose relies on existing reachability analysis approach based on mixed monotonicity (initially introduced for dynamical systems). The second proposed approach extends the ESIP (Error-based Symbolic Interval Propagation) approach which was first implemented in the verification tool Neurify, and first mentioned in the publication of the tool VeriNet. Although the ESIP approach has been shown to often outperform the mixed-monotonicity reachability analysis in the classical case with uncertainties only on the network's inputs, we show in this paper through numerical simulations that the situation is greatly reversed (in terms of precision, computation time, memory usage, and broader applicability) when dealing with uncertainties on the weights and biases.