 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A machine-learning approach to thunderstorm forecasting through post-processing of simulation data
Mar 15, 2023
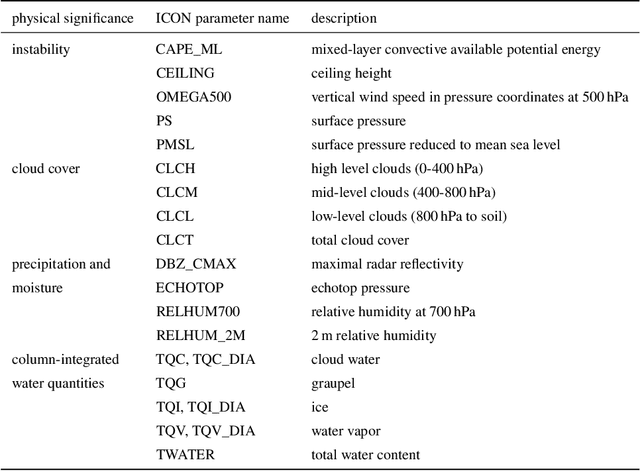

Thunderstorms pose a major hazard to society and economy, which calls for reliable thunderstorm forecasts. In this work, we introduce SALAMA, a feedforward neural network model for identifying thunderstorm occurrence in numerical weather prediction (NWP) data. The model is trained on convection-resolving ensemble forecasts over Central Europe and lightning observations. Given only a set of pixel-wise input parameters that are extracted from NWP data and related to thunderstorm development, SALAMA infers the probability of thunderstorm occurrence in a reliably calibrated manner. For lead times up to eleven hours, we find a forecast skill superior to classification based only on convective available potential energy. Varying the spatiotemporal criteria by which we associate lightning observations with NWP data, we show that the time scale for skillful thunderstorm predictions increases linearly with the spatial scale of the forecast.
DeblurSR: Event-Based Motion Deblurring Under the Spiking Representation
Mar 15, 2023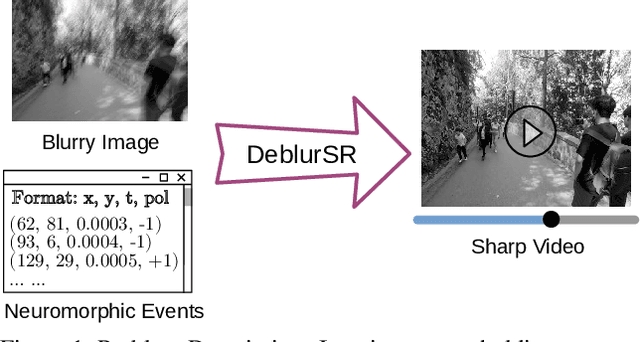

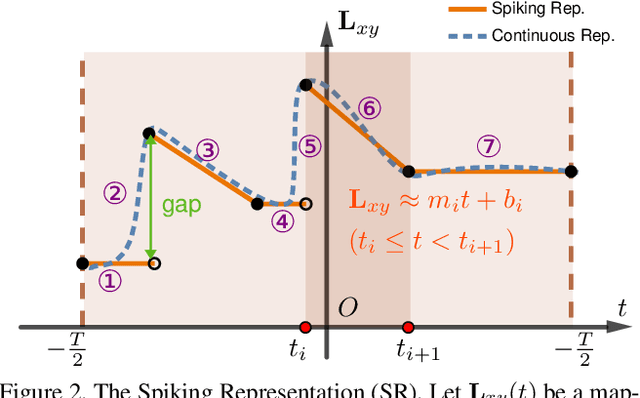

We present DeblurSR, a novel motion deblurring approach that converts a blurry image into a sharp video. DeblurSR utilizes event data to compensate for motion ambiguities and exploits the spiking representation to parameterize the sharp output video as a mapping from time to intensity. Our key contribution, the Spiking Representation (SR), is inspired by the neuromorphic principles determining how biological neurons communicate with each other in living organisms. We discuss why the spikes can represent sharp edges and how the spiking parameters are interpreted from the neuromorphic perspective. DeblurSR has higher output quality and requires fewer computing resources than state-of-the-art event-based motion deblurring methods. We additionally show that our approach easily extends to video super-resolution when combined with recent advances in implicit neural representation. The implementation and animated visualization of DeblurSR are available at https://github.com/chensong1995/DeblurSR.
Enhancing Data Space Semantic Interoperability through Machine Learning: a Visionary Perspective
Mar 15, 2023
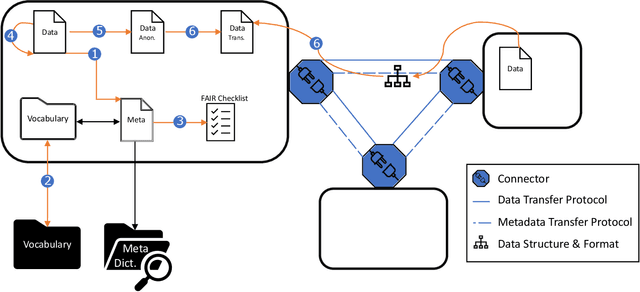
Our vision paper outlines a plan to improve the future of semantic interoperability in data spaces through the application of machine learning. The use of data spaces, where data is exchanged among members in a self-regulated environment, is becoming increasingly popular. However, the current manual practices of managing metadata and vocabularies in these spaces are time-consuming, prone to errors, and may not meet the needs of all stakeholders. By leveraging the power of machine learning, we believe that semantic interoperability in data spaces can be significantly improved. This involves automatically generating and updating metadata, which results in a more flexible vocabulary that can accommodate the diverse terminologies used by different sub-communities. Our vision for the future of data spaces addresses the limitations of conventional data exchange and makes data more accessible and valuable for all members of the community.
Vision Based Docking of Multiple Satellites with an Uncooperative Target
Mar 16, 2023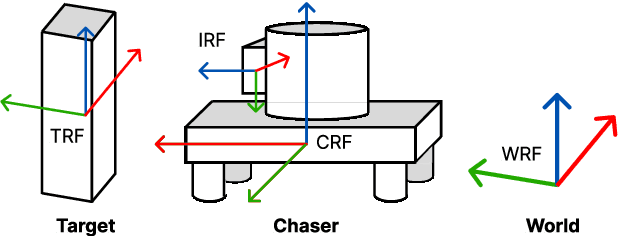

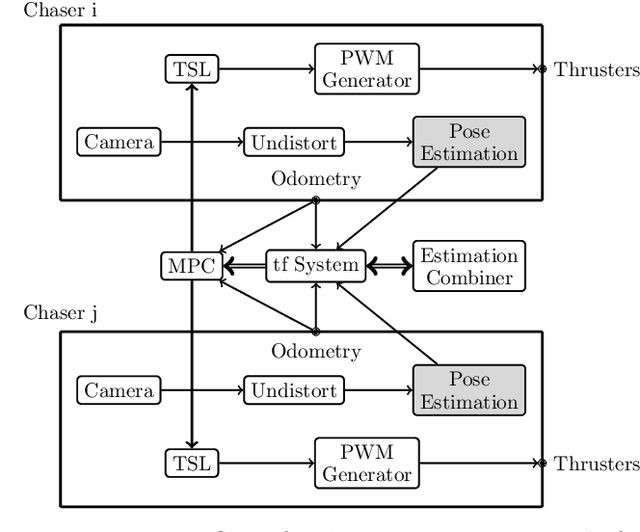
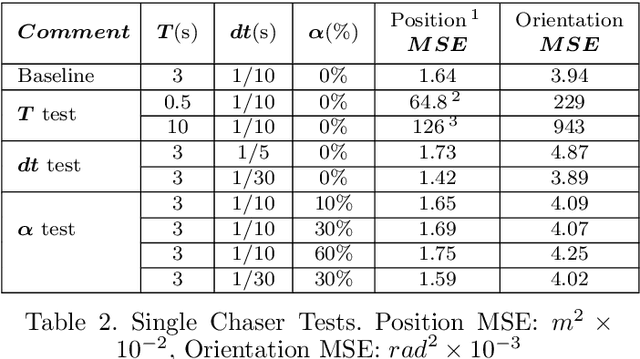
With the ever growing number of space debris in orbit, the need to prevent further space population is becoming more and more apparent. Refueling, servicing, inspection and deorbiting of spacecraft are some example missions that require precise navigation and docking in space. Having multiple, collaborating robots handling these tasks can greatly increase the efficiency of the mission in terms of time and cost. This article will introduce a modern and efficient control architecture for satellites on collaborative docking missions. The proposed architecture uses a centralized scheme that combines state-of-the-art, ad-hoc implementations of algorithms and techniques to maximize robustness and flexibility. It is based on a Model Predictive Controller (MPC) for which efficient cost function and constraint sets are designed to ensure a safe and accurate docking. A simulation environment is also presented to validate and test the proposed control scheme.
The Media Inequality, Uncanny Mountain, and the Singularity is Far from Near: Iwaa and Sophia Robot versus a Real Human Being
Mar 16, 2023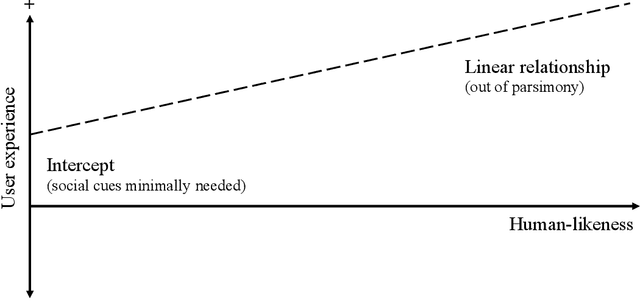
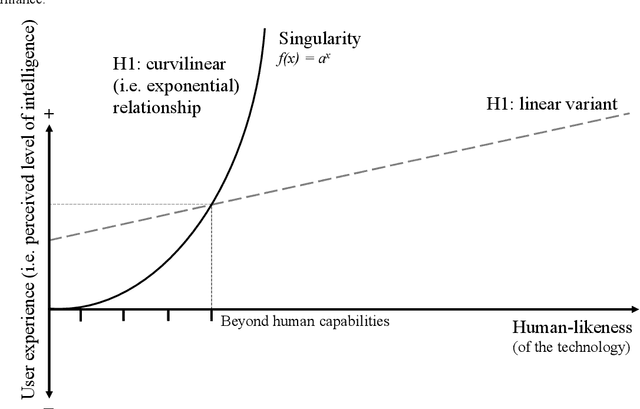
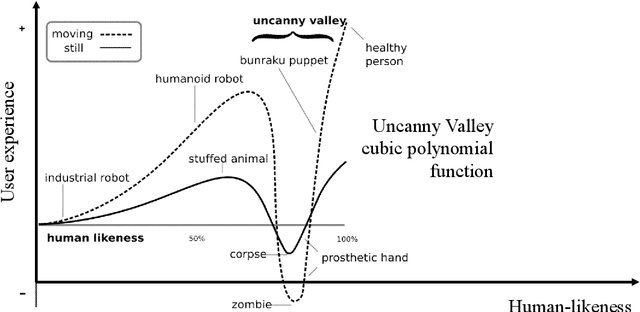
Design of Artificial Intelligence and robotics habitually assumes that adding more humanlike features improves the user experience, mainly kept in check by suspicion of uncanny effects. Three strands of theorizing are brought together for the first time and empirically put to the test: Media Equation (and in its wake, Computers Are Social Actors), Uncanny Valley theory, and as an extreme of human-likeness assumptions, the Singularity. We measured the user experience of real-life visitors of a number of seminars who were checked in either by Smart Dynamics' Iwaa, Hanson's Sophia robot, Sophia's on-screen avatar, or a human assistant. Results showed that human-likeness was not in appearance or behavior but in attributed qualities of being alive. Media Equation, Singularity, and Uncanny hypotheses were not confirmed. We discuss the imprecision in theorizing about human-likeness and rather opt for machines that 'function adequately.'
A Framework for History-Aware Hyperparameter Optimisation in Reinforcement Learning
Mar 09, 2023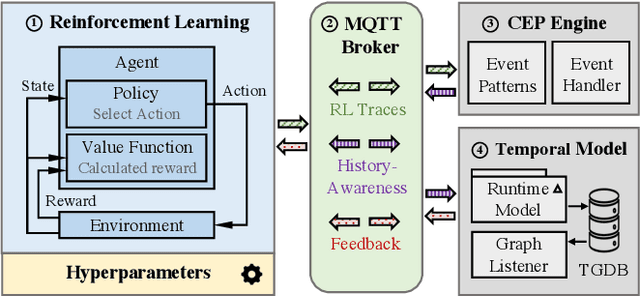
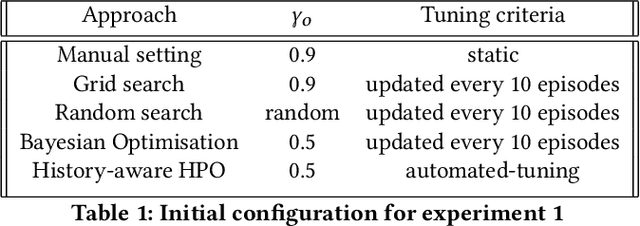
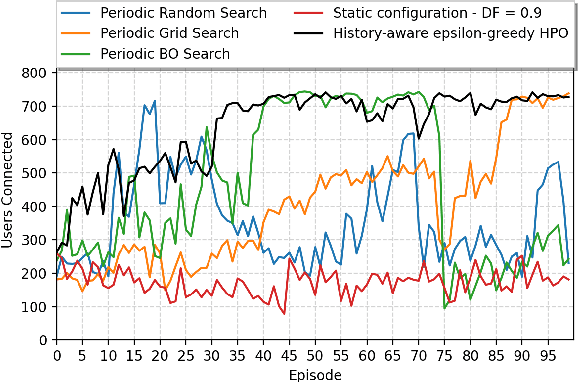
A Reinforcement Learning (RL) system depends on a set of initial conditions (hyperparameters) that affect the system's performance. However, defining a good choice of hyperparameters is a challenging problem. Hyperparameter tuning often requires manual or automated searches to find optimal values. Nonetheless, a noticeable limitation is the high cost of algorithm evaluation for complex models, making the tuning process computationally expensive and time-consuming. In this paper, we propose a framework based on integrating complex event processing and temporal models, to alleviate these trade-offs. Through this combination, it is possible to gain insights about a running RL system efficiently and unobtrusively based on data stream monitoring and to create abstract representations that allow reasoning about the historical behaviour of the RL system. The obtained knowledge is exploited to provide feedback to the RL system for optimising its hyperparameters while making effective use of parallel resources. We introduce a novel history-aware epsilon-greedy logic for hyperparameter optimisation that instead of using static hyperparameters that are kept fixed for the whole training, adjusts the hyperparameters at runtime based on the analysis of the agent's performance over time windows in a single agent's lifetime. We tested the proposed approach in a 5G mobile communications case study that uses DQN, a variant of RL, for its decision-making. Our experiments demonstrated the effects of hyperparameter tuning using history on training stability and reward values. The encouraging results show that the proposed history-aware framework significantly improved performance compared to traditional hyperparameter tuning approaches.
Railway Network Delay Evolution: A Heterogeneous Graph Neural Network Approach
Mar 27, 2023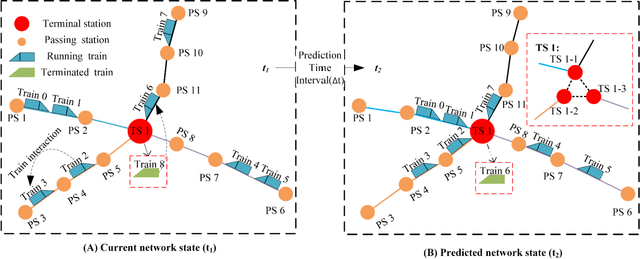

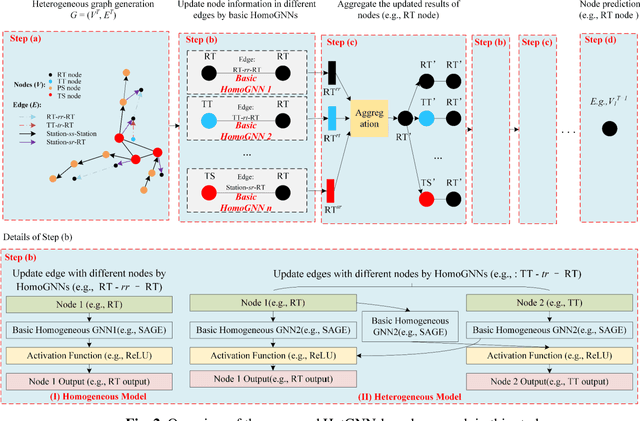
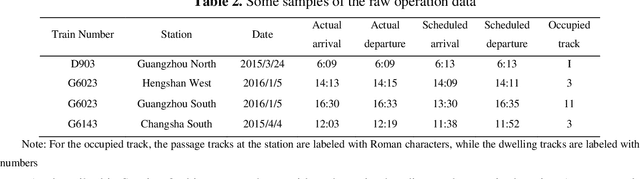
Railway operations involve different types of entities (stations, trains, etc.), making the existing graph/network models with homogenous nodes (i.e., the same kind of nodes) incapable of capturing the interactions between the entities. This paper aims to develop a heterogeneous graph neural network (HetGNN) model, which can address different types of nodes (i.e., heterogeneous nodes), to investigate the train delay evolution on railway networks. To this end, a graph architecture combining the HetGNN model and the GraphSAGE homogeneous GNN (HomoGNN), called SAGE-Het, is proposed. The aim is to capture the interactions between trains, trains and stations, and stations and other stations on delay evolution based on different edges. In contrast to the traditional methods that require the inputs to have constant dimensions (e.g., in rectangular or grid-like arrays) or only allow homogeneous nodes in the graph, SAGE-Het allows for flexible inputs and heterogeneous nodes. The data from two sub-networks of the China railway network are applied to test the performance and robustness of the proposed SAGE-Het model. The experimental results show that SAGE-Het exhibits better performance than the existing delay prediction methods and some advanced HetGNNs used for other prediction tasks; the predictive performances of SAGE-Het under different prediction time horizons (10/20/30 min ahead) all outperform other baseline methods; Specifically, the influences of train interactions on delay propagation are investigated based on the proposed model. The results show that train interactions become subtle when the train headways increase . This finding directly contributes to decision-making in the situation where conflict-resolution or train-canceling actions are needed.
Towards Understanding GD with Hard and Conjugate Pseudo-labels for Test-Time Adaptation
Oct 18, 2022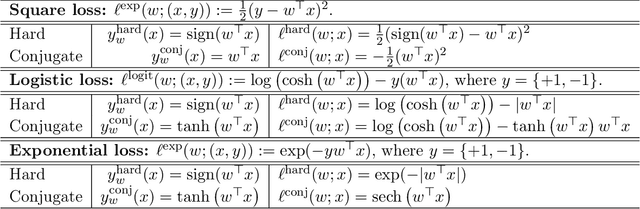
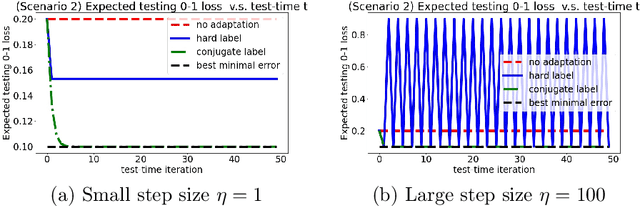

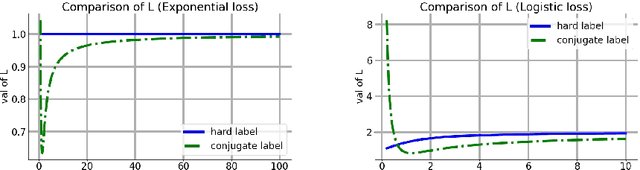
We consider a setting that a model needs to adapt to a new domain under distribution shifts, given that only unlabeled test samples from the new domain are accessible at test time. A common idea in most of the related works is constructing pseudo-labels for the unlabeled test samples and applying gradient descent (GD) to a loss function with the pseudo-labels. Recently, Goyal et al. (2022) propose conjugate labels, which is a new kind of pseudo-labels for self-training at test time. They empirically show that the conjugate label outperforms other ways of pseudo-labeling on many domain adaptation benchmarks. However, provably showing that GD with conjugate labels learns a good classifier for test-time adaptation remains open. In this work, we aim at theoretically understanding GD with hard and conjugate labels for a binary classification problem. We show that for square loss, GD with conjugate labels converges to a solution that minimizes the testing 0-1 loss under a Gaussian model, while GD with hard pseudo-labels fails in this task. We also analyze them under different loss functions for the update. Our results shed lights on understanding when and why GD with hard labels or conjugate labels works in test-time adaptation.
Zero-shot Object Counting
Mar 03, 2023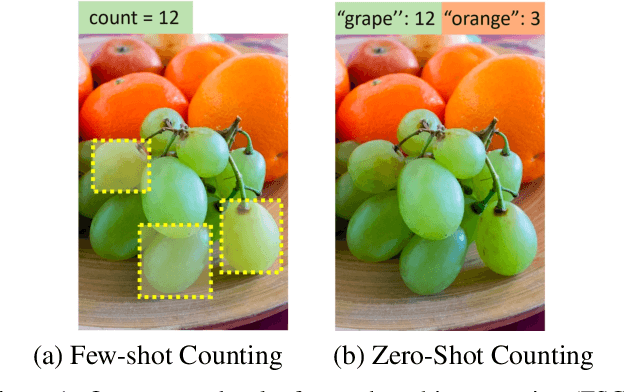
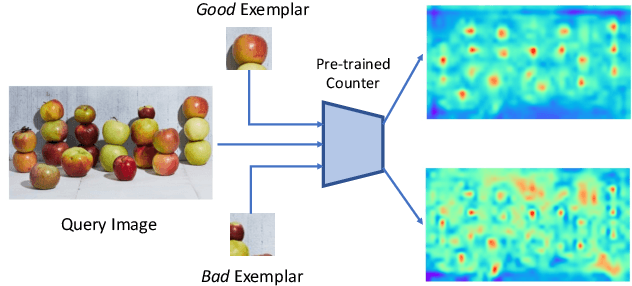
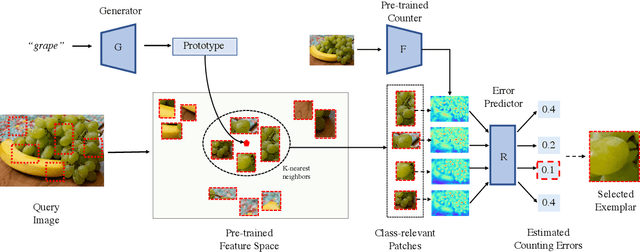
Class-agnostic object counting aims to count object instances of an arbitrary class at test time. It is challenging but also enables many potential applications. Current methods require human-annotated exemplars as inputs which are often unavailable for novel categories, especially for autonomous systems. Thus, we propose zero-shot object counting (ZSC), a new setting where only the class name is available during test time. Such a counting system does not require human annotators in the loop and can operate automatically. Starting from a class name, we propose a method that can accurately identify the optimal patches which can then be used as counting exemplars. Specifically, we first construct a class prototype to select the patches that are likely to contain the objects of interest, namely class-relevant patches. Furthermore, we introduce a model that can quantitatively measure how suitable an arbitrary patch is as a counting exemplar. By applying this model to all the candidate patches, we can select the most suitable patches as exemplars for counting. Experimental results on a recent class-agnostic counting dataset, FSC-147, validate the effectiveness of our method. Code is available at https://github.com/cvlab-stonybrook/zero-shot-counting
EfficientTempNet: Temporal Super-Resolution of Radar Rainfall
Mar 09, 2023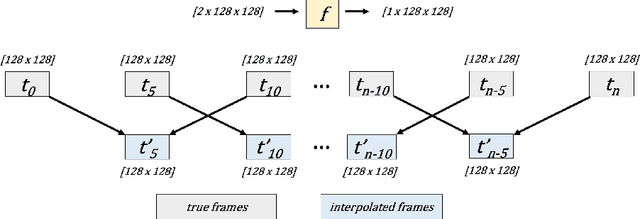


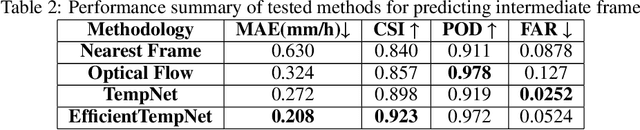
Rainfall data collected by various remote sensing instruments such as radars or satellites has different space-time resolutions. This study aims to improve the temporal resolution of radar rainfall products to help with more accurate climate change modeling and studies. In this direction, we introduce a solution based on EfficientNetV2, namely EfficientTempNet, to increase the temporal resolution of radar-based rainfall products from 10 minutes to 5 minutes. We tested EfficientRainNet over a dataset for the state of Iowa, US, and compared its performance to three different baselines to show that EfficientTempNet presents a viable option for better climate change monitoring.