 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Bridging the Gap between ANNs and SNNs by Calibrating Offset Spikes
Feb 21, 2023
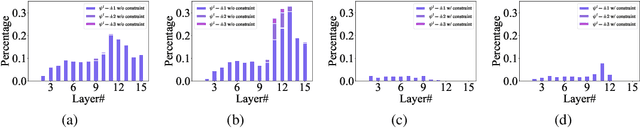
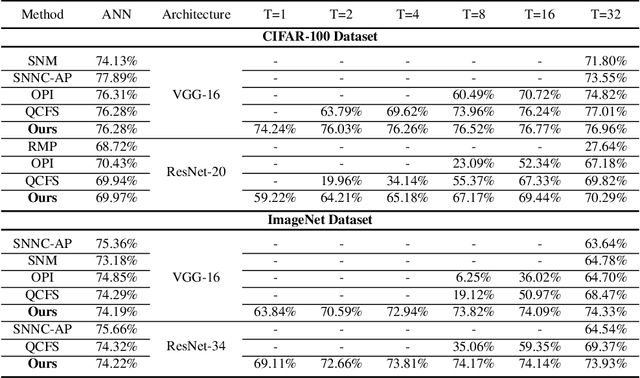

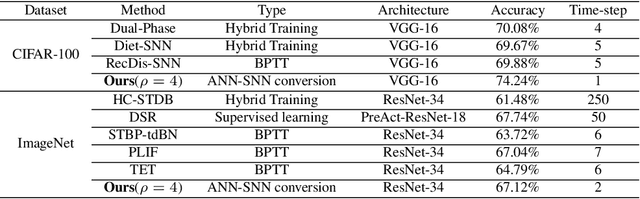
Spiking Neural Networks (SNNs) have attracted great attention due to their distinctive characteristics of low power consumption and temporal information processing. ANN-SNN conversion, as the most commonly used training method for applying SNNs, can ensure that converted SNNs achieve comparable performance to ANNs on large-scale datasets. However, the performance degrades severely under low quantities of time-steps, which hampers the practical applications of SNNs to neuromorphic chips. In this paper, instead of evaluating different conversion errors and then eliminating these errors, we define an offset spike to measure the degree of deviation between actual and desired SNN firing rates. We perform a detailed analysis of offset spike and note that the firing of one additional (or one less) spike is the main cause of conversion errors. Based on this, we propose an optimization strategy based on shifting the initial membrane potential and we theoretically prove the corresponding optimal shifting distance for calibrating the spike. In addition, we also note that our method has a unique iterative property that enables further reduction of conversion errors. The experimental results show that our proposed method achieves state-of-the-art performance on CIFAR-10, CIFAR-100, and ImageNet datasets. For example, we reach a top-1 accuracy of 67.12% on ImageNet when using 6 time-steps. To the best of our knowledge, this is the first time an ANN-SNN conversion has been shown to simultaneously achieve high accuracy and ultralow latency on complex datasets. Code is available at https://github.com/hzc1208/ANN2SNN_COS.
Super-Resolution Information Enhancement For Crowd Counting
Mar 13, 2023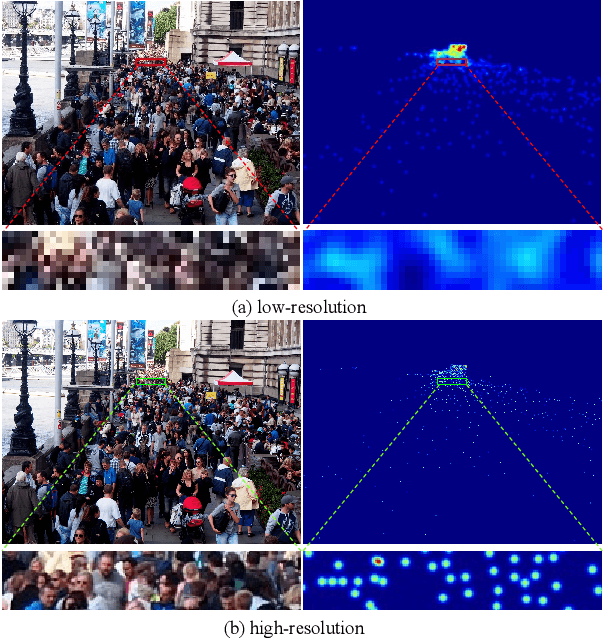
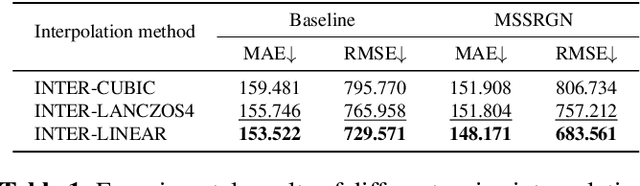
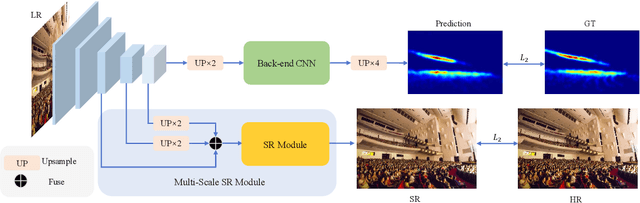
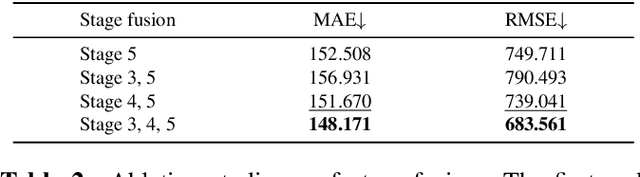
Crowd counting is a challenging task due to the heavy occlusions, scales, and density variations. Existing methods handle these challenges effectively while ignoring low-resolution (LR) circumstances. The LR circumstances weaken the counting performance deeply for two crucial reasons: 1) limited detail information; 2) overlapping head regions accumulate in density maps and result in extreme ground-truth values. An intuitive solution is to employ super-resolution (SR) pre-processes for the input LR images. However, it complicates the inference steps and thus limits application potentials when requiring real-time. We propose a more elegant method termed Multi-Scale Super-Resolution Module (MSSRM). It guides the network to estimate the lost de tails and enhances the detailed information in the feature space. Noteworthy that the MSSRM is plug-in plug-out and deals with the LR problems with no inference cost. As the proposed method requires SR labels, we further propose a Super-Resolution Crowd Counting dataset (SR-Crowd). Extensive experiments on three datasets demonstrate the superiority of our method. The code will be available at https://github.com/PRIS-CV/MSSRM.git.
Erasing Concepts from Diffusion Models
Mar 13, 2023
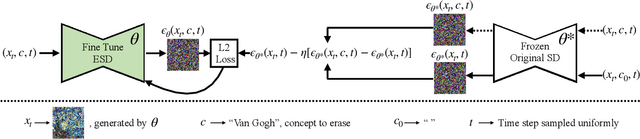
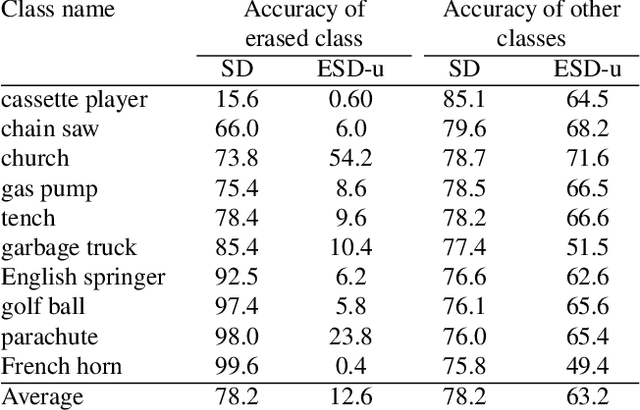

Motivated by recent advancements in text-to-image diffusion, we study erasure of specific concepts from the model's weights. While Stable Diffusion has shown promise in producing explicit or realistic artwork, it has raised concerns regarding its potential for misuse. We propose a fine-tuning method that can erase a visual concept from a pre-trained diffusion model, given only the name of the style and using negative guidance as a teacher. We benchmark our method against previous approaches that remove sexually explicit content and demonstrate its effectiveness, performing on par with Safe Latent Diffusion and censored training. To evaluate artistic style removal, we conduct experiments erasing five modern artists from the network and conduct a user study to assess the human perception of the removed styles. Unlike previous methods, our approach can remove concepts from a diffusion model permanently rather than modifying the output at the inference time, so it cannot be circumvented even if a user has access to model weights. Our code, data, and results are available at https://erasing.baulab.info/
Low Frequency Spinning LiDAR De-Skewing
Mar 13, 2023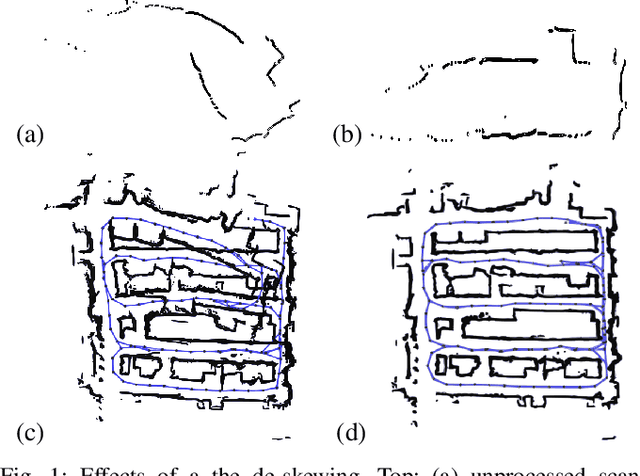
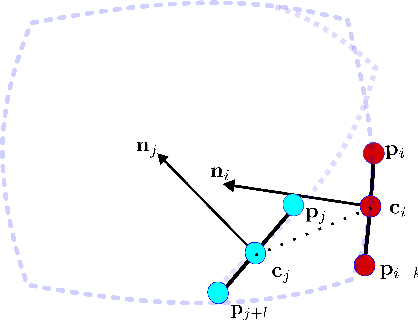

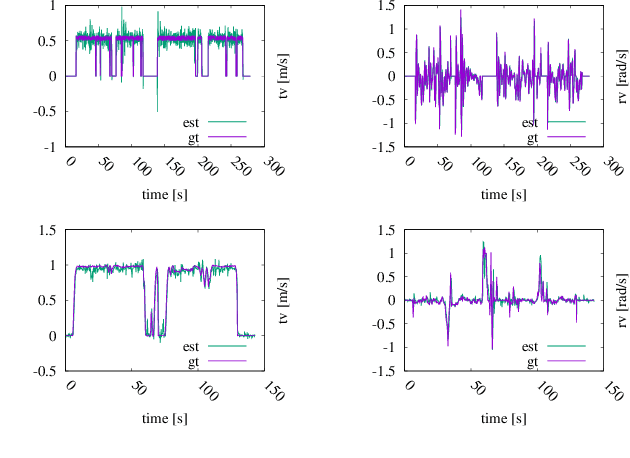
Most commercially available Light Detection and Ranging (LiDAR)s measure the distances along a 2D section of the environment by sequentially sampling the free range along directions centered at the sensor's origin. When the sensor moves during the acquisition, the measured ranges are affected by a phenomenon known as skewing, which appears as a distortion in the acquired scan. Skewing potentially affects all systems that rely on LiDAR data, however it could be compensated if the position of the sensor were known each time a single range is measured. Most methods to de-skew a LiDAR are based on external sensors such as IMU or wheel odometry, to estimate these intermediate LiDAR positions. In this paper we present a method that relies exclusively on range measurements to effectively estimate the robot velocities which are then used for de-skewing. Our approach is suitable for low frequency LiDAR where the skewing is more evident. It can be seamlessly integrated into existing pipelines, enhancing their performance at negligible computational cost. We validated the proposed method with statistical experiments characterizing different operating conditions
Loss of Plasticity in Continual Deep Reinforcement Learning
Mar 13, 2023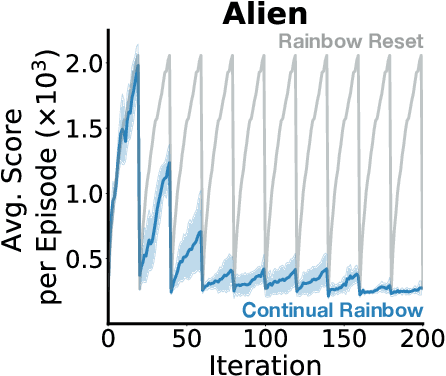

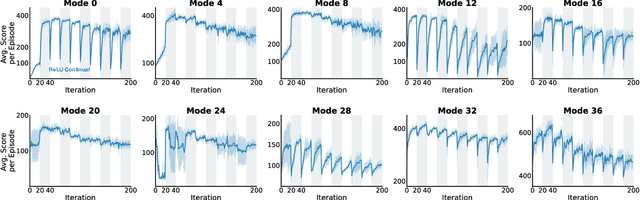

The ability to learn continually is essential in a complex and changing world. In this paper, we characterize the behavior of canonical value-based deep reinforcement learning (RL) approaches under varying degrees of non-stationarity. In particular, we demonstrate that deep RL agents lose their ability to learn good policies when they cycle through a sequence of Atari 2600 games. This phenomenon is alluded to in prior work under various guises -- e.g., loss of plasticity, implicit under-parameterization, primacy bias, and capacity loss. We investigate this phenomenon closely at scale and analyze how the weights, gradients, and activations change over time in several experiments with varying dimensions (e.g., similarity between games, number of games, number of frames per game), with some experiments spanning 50 days and 2 billion environment interactions. Our analysis shows that the activation footprint of the network becomes sparser, contributing to the diminishing gradients. We investigate a remarkably simple mitigation strategy -- Concatenated ReLUs (CReLUs) activation function -- and demonstrate its effectiveness in facilitating continual learning in a changing environment.
Best-of-three-worlds Analysis for Linear Bandits with Follow-the-regularized-leader Algorithm
Mar 13, 2023
The linear bandit problem has been studied for many years in both stochastic and adversarial settings. Designing an algorithm that can optimize the environment without knowing the loss type attracts lots of interest. \citet{LeeLWZ021} propose an algorithm that actively detects the loss type and then switches between different algorithms specially designed for different settings. However, such an approach requires meticulous designs to perform well in all settings. Follow-the-regularized-leader (FTRL) is another popular algorithm type that can adapt to different environments. This algorithm is of simple design and the regret bounds are shown to be optimal in traditional multi-armed bandit problems compared with the detect-switch type algorithms. Designing an FTRL-type algorithm for linear bandits is an important question that has been open for a long time. In this paper, we prove that the FTRL-type algorithm with a negative entropy regularizer can achieve the best-of-three-world results for the linear bandit problem with the tacit cooperation between the choice of the learning rate and the specially designed self-bounding inequality.
DiffusionDepth: Diffusion Denoising Approach for Monocular Depth Estimation
Mar 13, 2023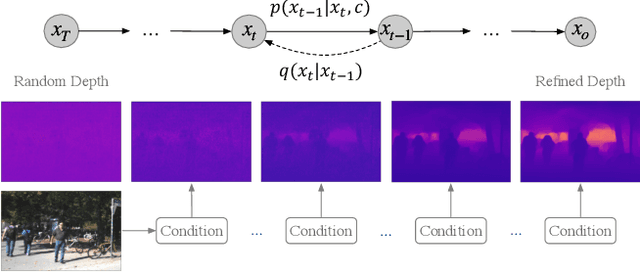
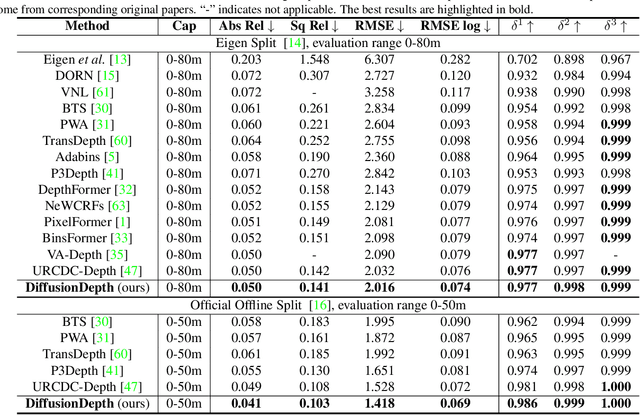
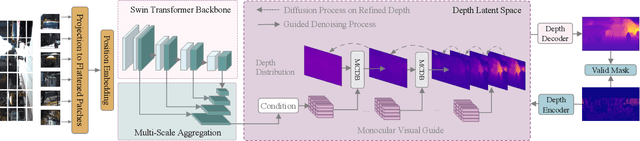
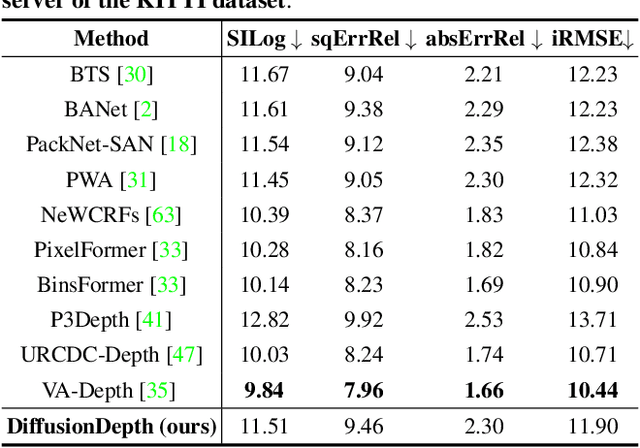
Monocular depth estimation is a challenging task that predicts the pixel-wise depth from a single 2D image. Current methods typically model this problem as a regression or classification task. We propose DiffusionDepth, a new approach that reformulates monocular depth estimation as a denoising diffusion process. It learns an iterative denoising process to `denoise' random depth distribution into a depth map with the guidance of monocular visual conditions. The process is performed in the latent space encoded by a dedicated depth encoder and decoder. Instead of diffusing ground truth (GT) depth, the model learns to reverse the process of diffusing the refined depth of itself into random depth distribution. This self-diffusion formulation overcomes the difficulty of applying generative models to sparse GT depth scenarios. The proposed approach benefits this task by refining depth estimation step by step, which is superior for generating accurate and highly detailed depth maps. Experimental results on KITTI and NYU-Depth-V2 datasets suggest that a simple yet efficient diffusion approach could reach state-of-the-art performance in both indoor and outdoor scenarios with acceptable inference time.
LocalEyenet: Deep Attention framework for Localization of Eyes
Mar 13, 2023
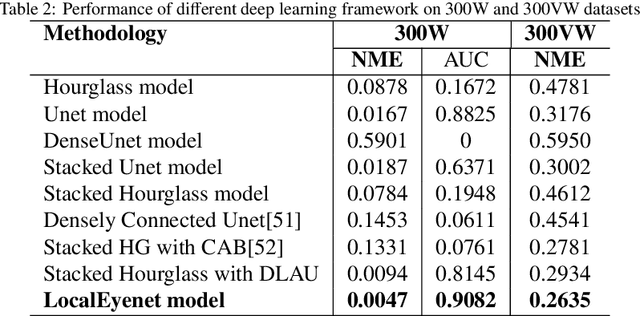
Development of human machine interface has become a necessity for modern day machines to catalyze more autonomy and more efficiency. Gaze driven human intervention is an effective and convenient option for creating an interface to alleviate human errors. Facial landmark detection is very crucial for designing a robust gaze detection system. Regression based methods capacitate good spatial localization of the landmarks corresponding to different parts of the faces. But there are still scope of improvements which have been addressed by incorporating attention. In this paper, we have proposed a deep coarse-to-fine architecture called LocalEyenet for localization of only the eye regions that can be trained end-to-end. The model architecture, build on stacked hourglass backbone, learns the self-attention in feature maps which aids in preserving global as well as local spatial dependencies in face image. We have incorporated deep layer aggregation in each hourglass to minimize the loss of attention over the depth of architecture. Our model shows good generalization ability in cross-dataset evaluation and in real-time localization of eyes.
Lower Generalization Bounds for GD and SGD in Smooth Stochastic Convex Optimization
Mar 19, 2023
Recent progress was made in characterizing the generalization error of gradient methods for general convex loss by the learning theory community. In this work, we focus on how training longer might affect generalization in smooth stochastic convex optimization (SCO) problems. We first provide tight lower bounds for general non-realizable SCO problems. Furthermore, existing upper bound results suggest that sample complexity can be improved by assuming the loss is realizable, i.e. an optimal solution simultaneously minimizes all the data points. However, this improvement is compromised when training time is long and lower bounds are lacking. Our paper examines this observation by providing excess risk lower bounds for gradient descent (GD) and stochastic gradient descent (SGD) in two realizable settings: 1) realizable with $T = O(n)$, and (2) realizable with $T = \Omega(n)$, where $T$ denotes the number of training iterations and $n$ is the size of the training dataset. These bounds are novel and informative in characterizing the relationship between $T$ and $n$. In the first small training horizon case, our lower bounds almost tightly match and provide the first optimal certificates for the corresponding upper bounds. However, for the realizable case with $T = \Omega(n)$, a gap exists between the lower and upper bounds. We provide a conjecture to address this problem, that the gap can be closed by improving upper bounds, which is supported by our analyses in one-dimensional and linear regression scenarios.
Going faster to see further: GPU-accelerated value iteration and simulation for perishable inventory control using JAX
Mar 19, 2023
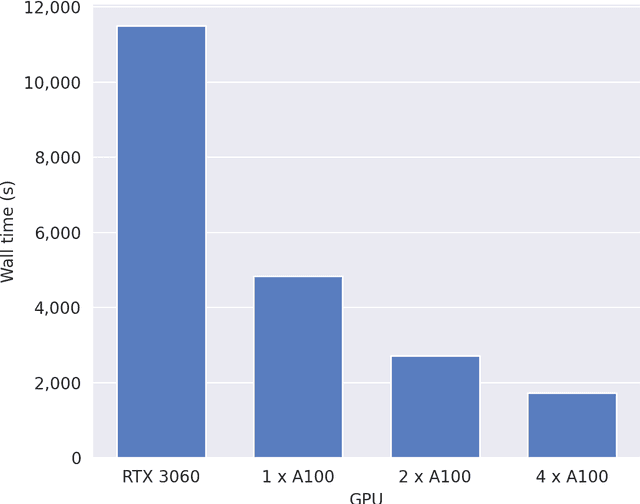

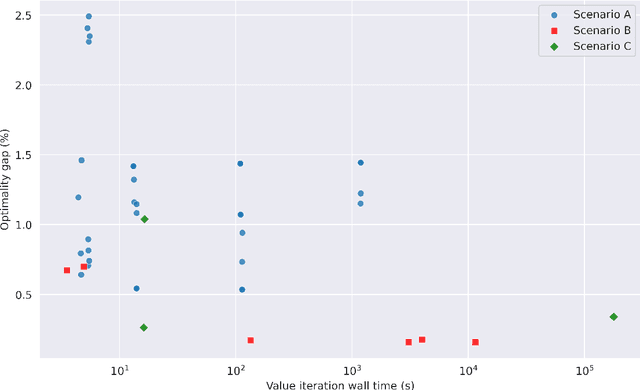
Value iteration can find the optimal replenishment policy for a perishable inventory problem, but is computationally demanding due to the large state spaces that are required to represent the age profile of stock. The parallel processing capabilities of modern GPUs can reduce the wall time required to run value iteration by updating many states simultaneously. The adoption of GPU-accelerated approaches has been limited in operational research relative to other fields like machine learning, in which new software frameworks have made GPU programming widely accessible. We used the Python library JAX to implement value iteration and simulators of the underlying Markov decision processes in a high-level API, and relied on this library's function transformations and compiler to efficiently utilize GPU hardware. Our method can extend use of value iteration to settings that were previously considered infeasible or impractical. We demonstrate this on example scenarios from three recent studies which include problems with over 16 million states and additional problem features, such as substitution between products, that increase computational complexity. We compare the performance of the optimal replenishment policies to heuristic policies, fitted using simulation optimization in JAX which allowed the parallel evaluation of multiple candidate policy parameters on thousands of simulated years. The heuristic policies gave a maximum optimality gap of 2.49%. Our general approach may be applicable to a wide range of problems in operational research that would benefit from large-scale parallel computation on consumer-grade GPU hardware.