 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Low Frequency Spinning LiDAR De-Skewing
Mar 13, 2023
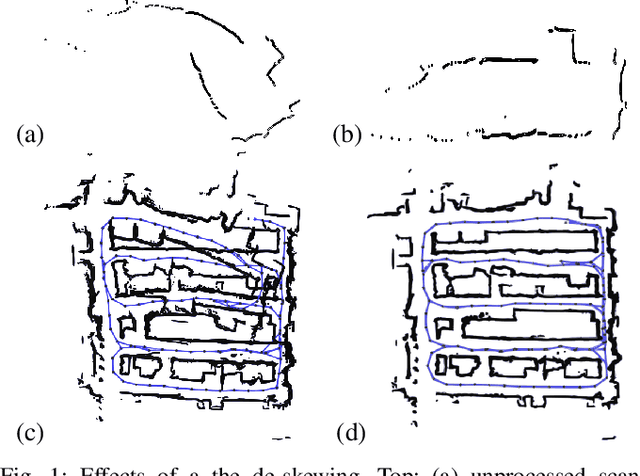
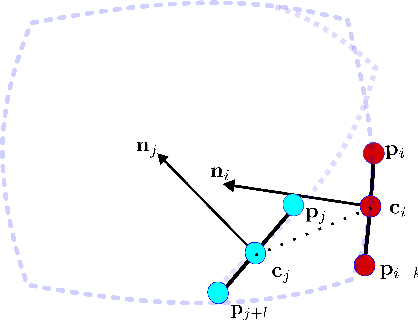

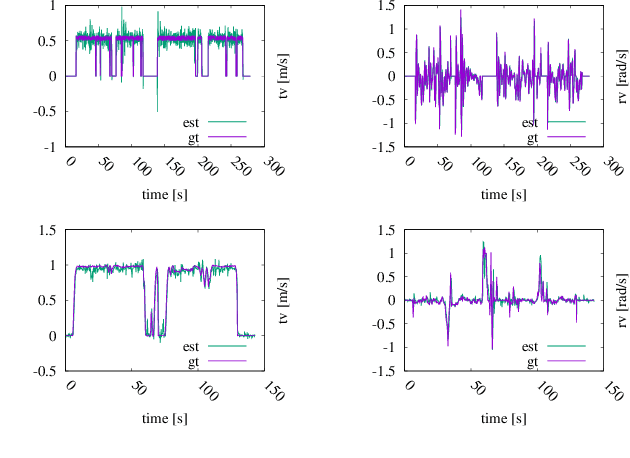
Most commercially available Light Detection and Ranging (LiDAR)s measure the distances along a 2D section of the environment by sequentially sampling the free range along directions centered at the sensor's origin. When the sensor moves during the acquisition, the measured ranges are affected by a phenomenon known as skewing, which appears as a distortion in the acquired scan. Skewing potentially affects all systems that rely on LiDAR data, however it could be compensated if the position of the sensor were known each time a single range is measured. Most methods to de-skew a LiDAR are based on external sensors such as IMU or wheel odometry, to estimate these intermediate LiDAR positions. In this paper we present a method that relies exclusively on range measurements to effectively estimate the robot velocities which are then used for de-skewing. Our approach is suitable for low frequency LiDAR where the skewing is more evident. It can be seamlessly integrated into existing pipelines, enhancing their performance at negligible computational cost. We validated the proposed method with statistical experiments characterizing different operating conditions
Loss of Plasticity in Continual Deep Reinforcement Learning
Mar 13, 2023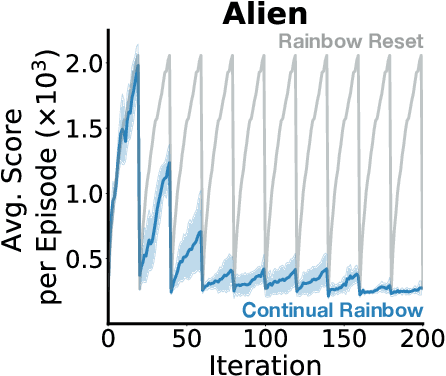

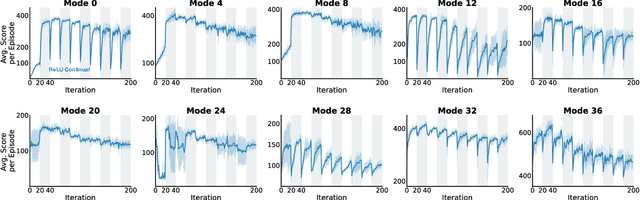

The ability to learn continually is essential in a complex and changing world. In this paper, we characterize the behavior of canonical value-based deep reinforcement learning (RL) approaches under varying degrees of non-stationarity. In particular, we demonstrate that deep RL agents lose their ability to learn good policies when they cycle through a sequence of Atari 2600 games. This phenomenon is alluded to in prior work under various guises -- e.g., loss of plasticity, implicit under-parameterization, primacy bias, and capacity loss. We investigate this phenomenon closely at scale and analyze how the weights, gradients, and activations change over time in several experiments with varying dimensions (e.g., similarity between games, number of games, number of frames per game), with some experiments spanning 50 days and 2 billion environment interactions. Our analysis shows that the activation footprint of the network becomes sparser, contributing to the diminishing gradients. We investigate a remarkably simple mitigation strategy -- Concatenated ReLUs (CReLUs) activation function -- and demonstrate its effectiveness in facilitating continual learning in a changing environment.
Best-of-three-worlds Analysis for Linear Bandits with Follow-the-regularized-leader Algorithm
Mar 13, 2023
The linear bandit problem has been studied for many years in both stochastic and adversarial settings. Designing an algorithm that can optimize the environment without knowing the loss type attracts lots of interest. \citet{LeeLWZ021} propose an algorithm that actively detects the loss type and then switches between different algorithms specially designed for different settings. However, such an approach requires meticulous designs to perform well in all settings. Follow-the-regularized-leader (FTRL) is another popular algorithm type that can adapt to different environments. This algorithm is of simple design and the regret bounds are shown to be optimal in traditional multi-armed bandit problems compared with the detect-switch type algorithms. Designing an FTRL-type algorithm for linear bandits is an important question that has been open for a long time. In this paper, we prove that the FTRL-type algorithm with a negative entropy regularizer can achieve the best-of-three-world results for the linear bandit problem with the tacit cooperation between the choice of the learning rate and the specially designed self-bounding inequality.
DiffusionDepth: Diffusion Denoising Approach for Monocular Depth Estimation
Mar 13, 2023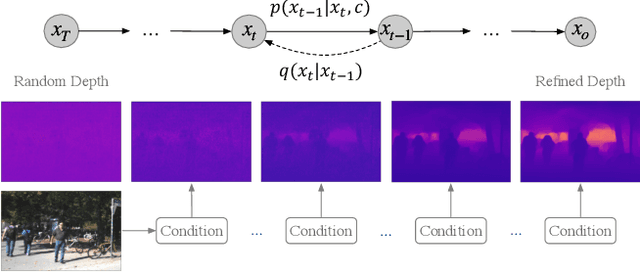
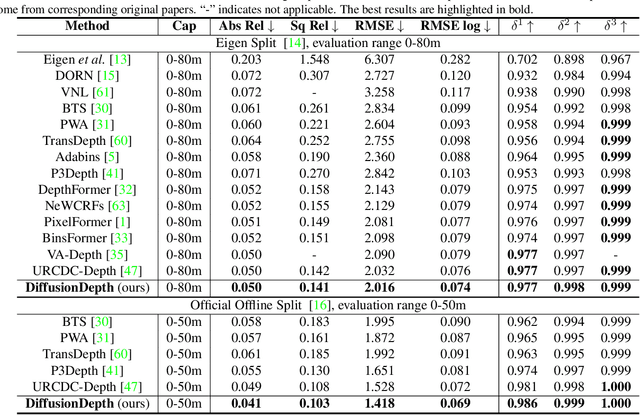
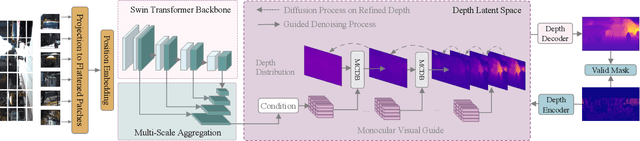
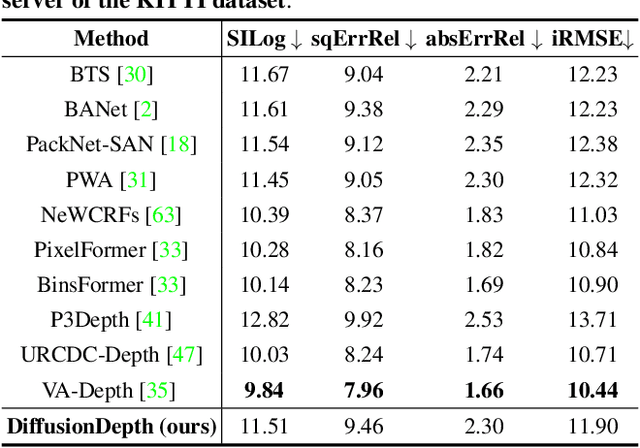
Monocular depth estimation is a challenging task that predicts the pixel-wise depth from a single 2D image. Current methods typically model this problem as a regression or classification task. We propose DiffusionDepth, a new approach that reformulates monocular depth estimation as a denoising diffusion process. It learns an iterative denoising process to `denoise' random depth distribution into a depth map with the guidance of monocular visual conditions. The process is performed in the latent space encoded by a dedicated depth encoder and decoder. Instead of diffusing ground truth (GT) depth, the model learns to reverse the process of diffusing the refined depth of itself into random depth distribution. This self-diffusion formulation overcomes the difficulty of applying generative models to sparse GT depth scenarios. The proposed approach benefits this task by refining depth estimation step by step, which is superior for generating accurate and highly detailed depth maps. Experimental results on KITTI and NYU-Depth-V2 datasets suggest that a simple yet efficient diffusion approach could reach state-of-the-art performance in both indoor and outdoor scenarios with acceptable inference time.
LocalEyenet: Deep Attention framework for Localization of Eyes
Mar 13, 2023
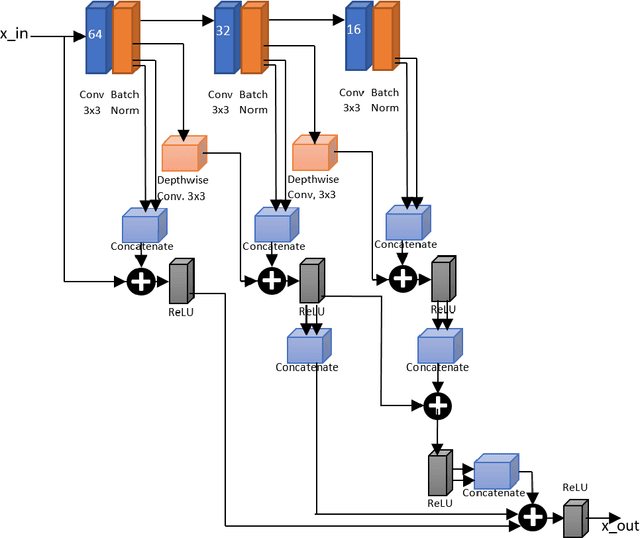
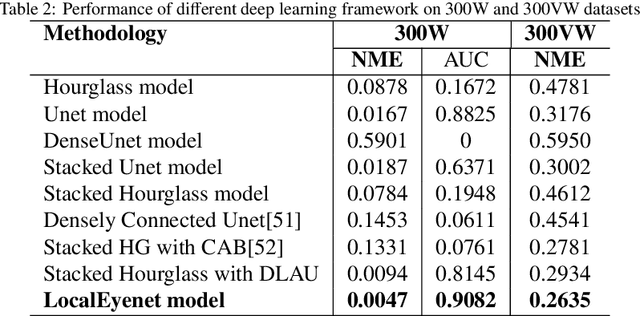
Development of human machine interface has become a necessity for modern day machines to catalyze more autonomy and more efficiency. Gaze driven human intervention is an effective and convenient option for creating an interface to alleviate human errors. Facial landmark detection is very crucial for designing a robust gaze detection system. Regression based methods capacitate good spatial localization of the landmarks corresponding to different parts of the faces. But there are still scope of improvements which have been addressed by incorporating attention. In this paper, we have proposed a deep coarse-to-fine architecture called LocalEyenet for localization of only the eye regions that can be trained end-to-end. The model architecture, build on stacked hourglass backbone, learns the self-attention in feature maps which aids in preserving global as well as local spatial dependencies in face image. We have incorporated deep layer aggregation in each hourglass to minimize the loss of attention over the depth of architecture. Our model shows good generalization ability in cross-dataset evaluation and in real-time localization of eyes.
Physical Adversarial Attacks on Deep Neural Networks for Traffic Sign Recognition: A Feasibility Study
Feb 27, 2023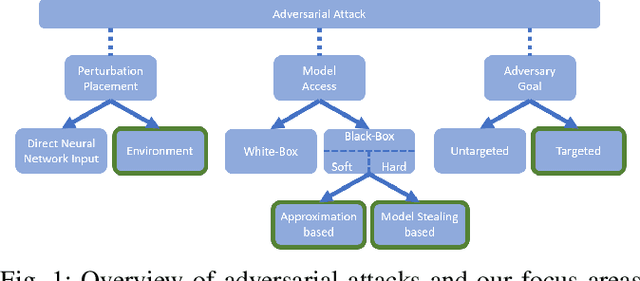
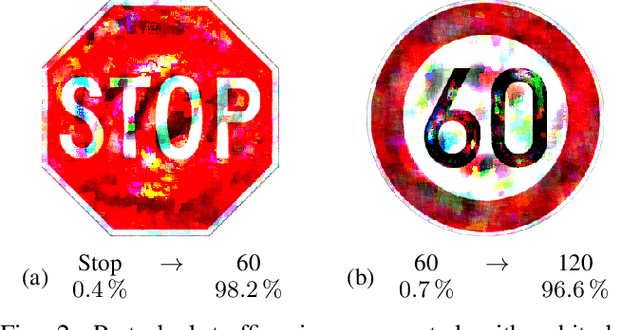

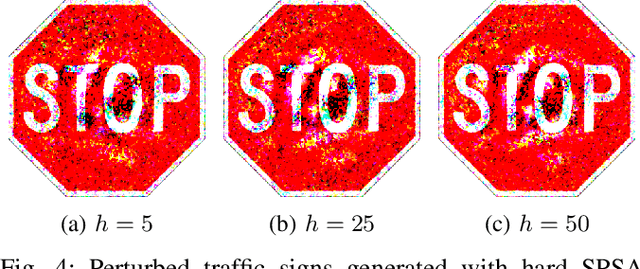
Deep Neural Networks (DNNs) are increasingly applied in the real world in safety critical applications like advanced driver assistance systems. An example for such use case is represented by traffic sign recognition systems. At the same time, it is known that current DNNs can be fooled by adversarial attacks, which raises safety concerns if those attacks can be applied under realistic conditions. In this work we apply different black-box attack methods to generate perturbations that are applied in the physical environment and can be used to fool systems under different environmental conditions. To the best of our knowledge we are the first to combine a general framework for physical attacks with different black-box attack methods and study the impact of the different methods on the success rate of the attack under the same setting. We show that reliable physical adversarial attacks can be performed with different methods and that it is also possible to reduce the perceptibility of the resulting perturbations. The findings highlight the need for viable defenses of a DNN even in the black-box case, but at the same time form the basis for securing a DNN with methods like adversarial training which utilizes adversarial attacks to augment the original training data.
LMPDNet: TOF-PET list-mode image reconstruction using model-based deep learning method
Feb 21, 2023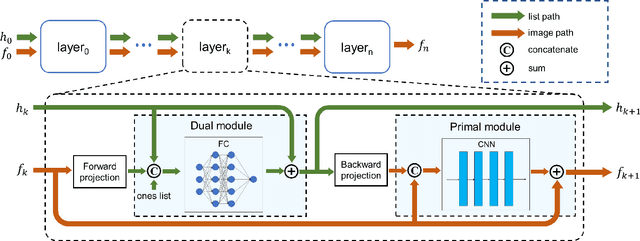
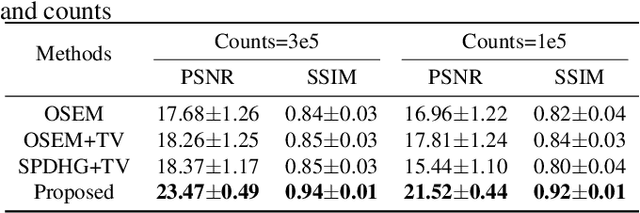
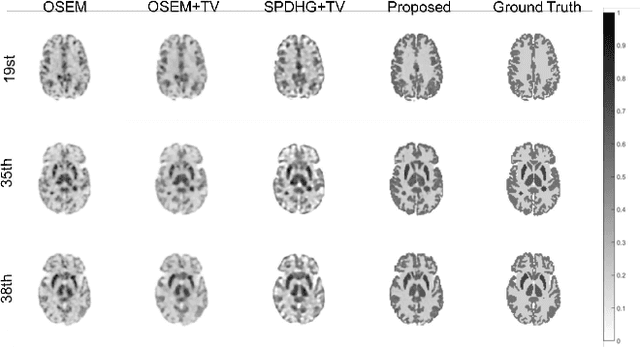
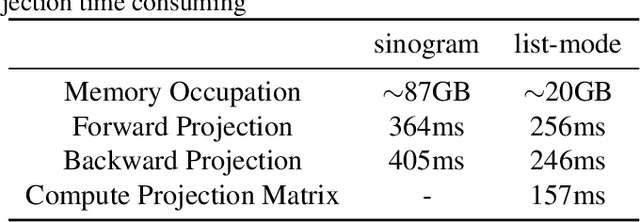
The integration of Time-of-Flight (TOF) information in the reconstruction process of Positron Emission Tomography (PET) yields improved image properties. However, implementing the cutting-edge model-based deep learning methods for TOF-PET reconstruction is challenging due to the substantial memory requirements. In this study, we present a novel model-based deep learning approach, LMPDNet, for TOF-PET reconstruction from list-mode data. We address the issue of real-time parallel computation of the projection matrix for list-mode data, and propose an iterative model-based module that utilizes a dedicated network model for list-mode data. Our experimental results indicate that the proposed LMPDNet outperforms traditional iteration-based TOF-PET list-mode reconstruction algorithms. Additionally, we compare the spatial and temporal consumption of list-mode data and sinogram data in model-based deep learning methods, demonstrating the superiority of list-mode data in model-based TOF-PET reconstruction.
HyperTime: Implicit Neural Representation for Time Series
Aug 11, 2022
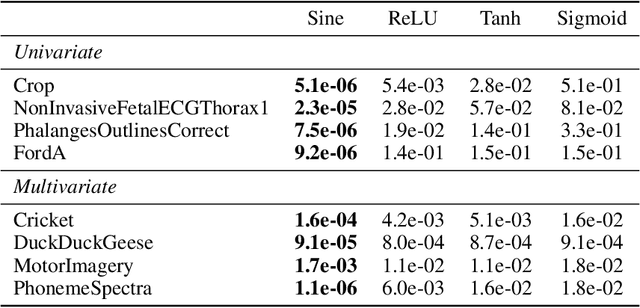
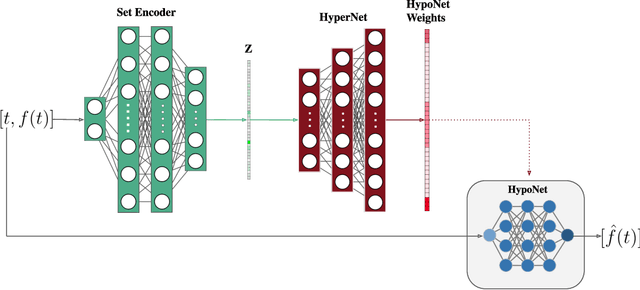
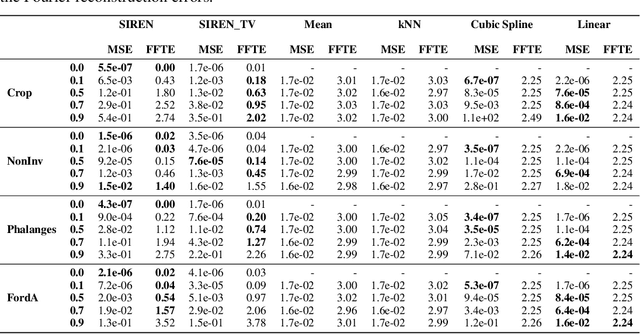
Implicit neural representations (INRs) have recently emerged as a powerful tool that provides an accurate and resolution-independent encoding of data. Their robustness as general approximators has been shown in a wide variety of data sources, with applications on image, sound, and 3D scene representation. However, little attention has been given to leveraging these architectures for the representation and analysis of time series data. In this paper, we analyze the representation of time series using INRs, comparing different activation functions in terms of reconstruction accuracy and training convergence speed. We show how these networks can be leveraged for the imputation of time series, with applications on both univariate and multivariate data. Finally, we propose a hypernetwork architecture that leverages INRs to learn a compressed latent representation of an entire time series dataset. We introduce an FFT-based loss to guide training so that all frequencies are preserved in the time series. We show that this network can be used to encode time series as INRs, and their embeddings can be interpolated to generate new time series from existing ones. We evaluate our generative method by using it for data augmentation, and show that it is competitive against current state-of-the-art approaches for augmentation of time series.
CROSSFIRE: Camera Relocalization On Self-Supervised Features from an Implicit Representation
Mar 08, 2023
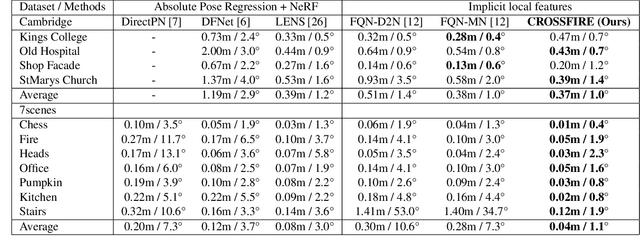
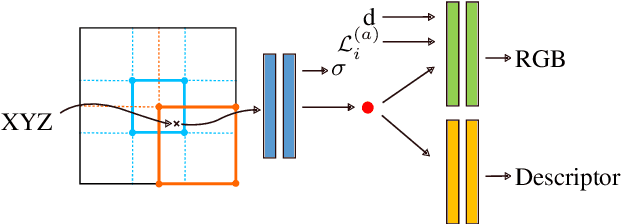

Beyond novel view synthesis, Neural Radiance Fields are useful for applications that interact with the real world. In this paper, we use them as an implicit map of a given scene and propose a camera relocalization algorithm tailored for this representation. The proposed method enables to compute in real-time the precise position of a device using a single RGB camera, during its navigation. In contrast with previous work, we do not rely on pose regression or photometric alignment but rather use dense local features obtained through volumetric rendering which are specialized on the scene with a self-supervised objective. As a result, our algorithm is more accurate than competitors, able to operate in dynamic outdoor environments with changing lightning conditions and can be readily integrated in any volumetric neural renderer.
Near-Field Low-WISL Unimodular Waveform Design for Terahertz Automotive Radar
Mar 08, 2023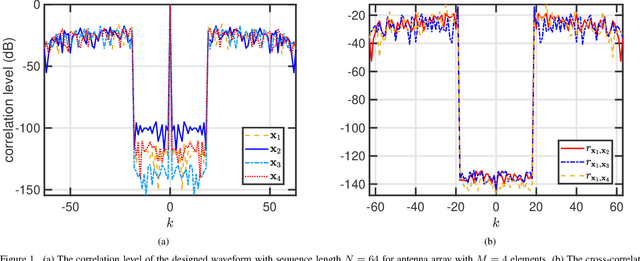
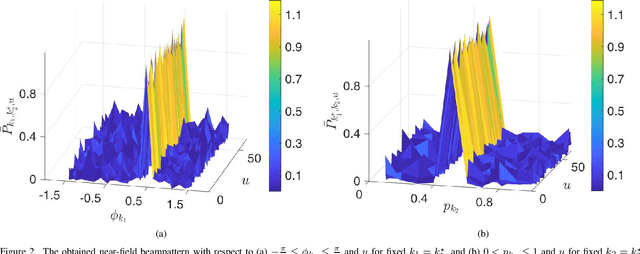
Conventional sensing applications rely on electromagnetic far-field channel models with plane wave propagation. However, recent ultra-short-range automotive radar applications at upper millimeter-wave or low terahertz (THz) frequencies envisage operation in the near-field region, where the wavefront is spherical. Unlike far-field, the near-field beampattern is dependent on both range and angle, thus requiring a different approach to waveform design. For the first time in the literature, we adopt the beampattern matching approach to design unimodular waveforms for THz automotive radars with low weighted integrated sidelobe levels (WISL). We formulate this problem as a unimodular bi-quadratic matrix program, and solve its constituent quadratic sub-problems using our cyclic power method-like iterations (CyPMLI) algorithm. Numerical experiments demonstrate that the CyPMLI approach yields the required beampattern with low autocorrelation levels.