 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
HyperAttack: Multi-Gradient-Guided White-box Adversarial Structure Attack of Hypergraph Neural Networks
Feb 24, 2023
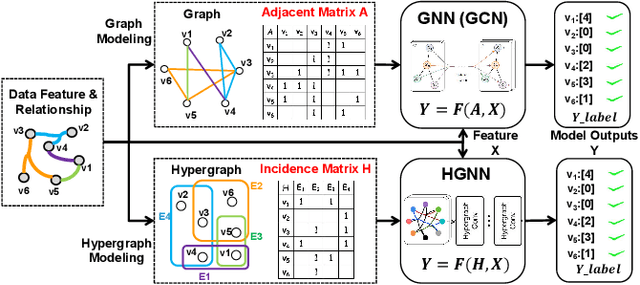

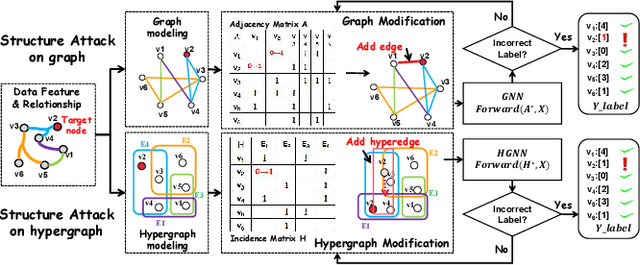
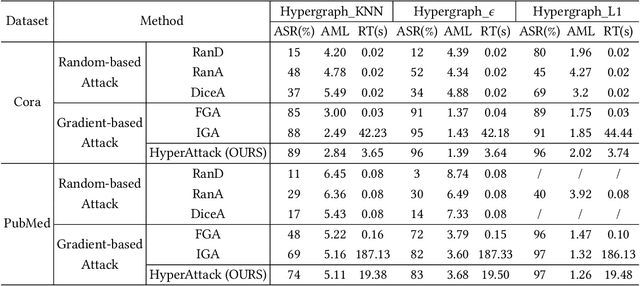
Hypergraph neural networks (HGNN) have shown superior performance in various deep learning tasks, leveraging the high-order representation ability to formulate complex correlations among data by connecting two or more nodes through hyperedge modeling. Despite the well-studied adversarial attacks on Graph Neural Networks (GNN), there is few study on adversarial attacks against HGNN, which leads to a threat to the safety of HGNN applications. In this paper, we introduce HyperAttack, the first white-box adversarial attack framework against hypergraph neural networks. HyperAttack conducts a white-box structure attack by perturbing hyperedge link status towards the target node with the guidance of both gradients and integrated gradients. We evaluate HyperAttack on the widely-used Cora and PubMed datasets and three hypergraph neural networks with typical hypergraph modeling techniques. Compared to state-of-the-art white-box structural attack methods for GNN, HyperAttack achieves a 10-20X improvement in time efficiency while also increasing attack success rates by 1.3%-3.7%. The results show that HyperAttack can achieve efficient adversarial attacks that balance effectiveness and time costs.
Fine-tuning of sign language recognition models: a technical report
Feb 16, 2023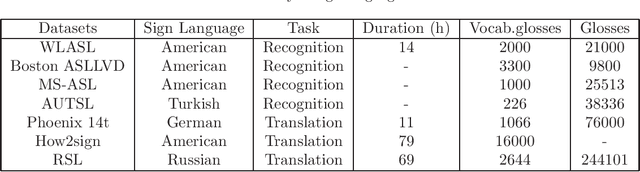
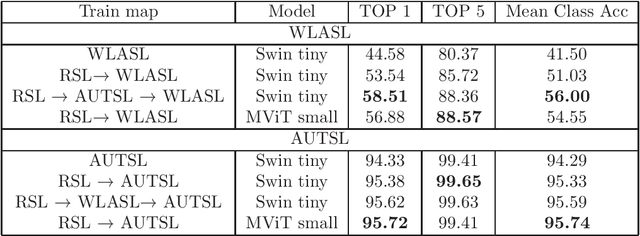
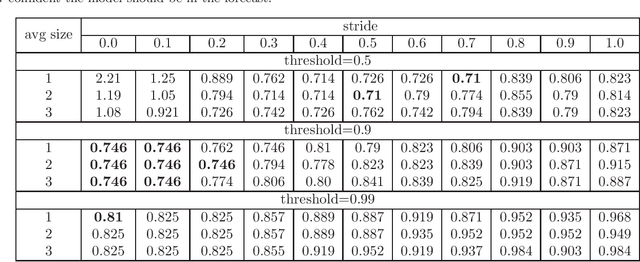
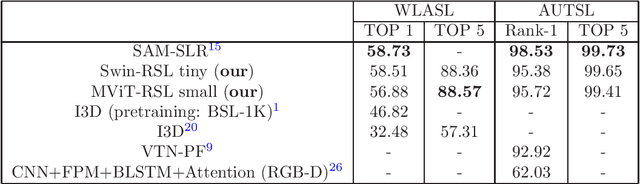
Sign Language Recognition (SLR) is an essential yet challenging task since sign language is performed with the fast and complex movement of hand gestures, body posture, and even facial expressions. %Skeleton Aware Multi-modal Sign Language Recognition In this work, we focused on investigating two questions: how fine-tuning on datasets from other sign languages helps improve sign recognition quality, and whether sign recognition is possible in real-time without using GPU. Three different languages datasets (American sign language WLASL, Turkish - AUTSL, Russian - RSL) have been used to validate the models. The average speed of this system has reached 3 predictions per second, which meets the requirements for the real-time scenario. This model (prototype) will benefit speech or hearing impaired people talk with other trough internet. We also investigated how the additional training of the model in another sign language affects the quality of recognition. The results show that further training of the model on the data of another sign language almost always leads to an improvement in the quality of gesture recognition. We also provide code for reproducing model training experiments, converting models to ONNX format, and inference for real-time gesture recognition.
Convolutional Neural Networks as 2-D systems
Mar 06, 2023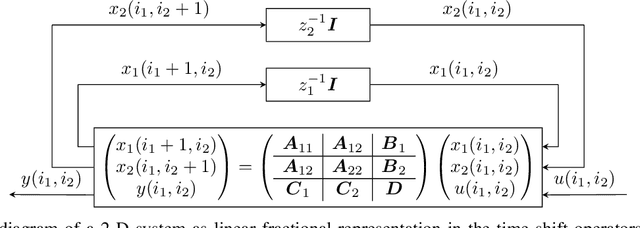
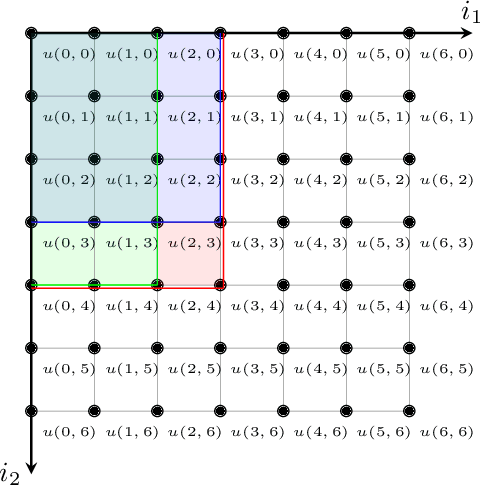
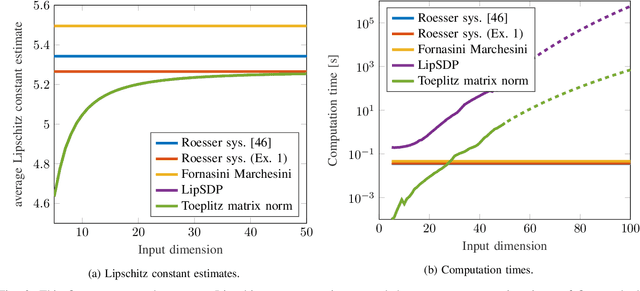
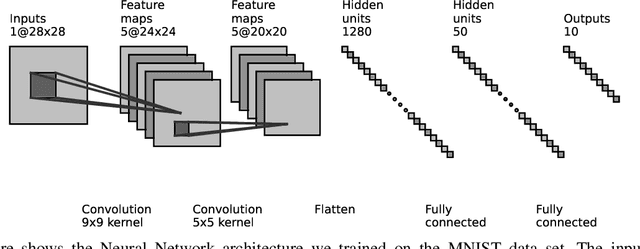
This paper introduces a novel representation of convolutional Neural Networks (CNNs) in terms of 2-D dynamical systems. To this end, the usual description of convolutional layers with convolution kernels, i.e., the impulse responses of linear filters, is realized in state space as a linear time-invariant 2-D system. The overall convolutional Neural Network composed of convolutional layers and nonlinear activation functions is then viewed as a 2-D version of a Lur'e system, i.e., a linear dynamical system interconnected with static nonlinear components. One benefit of this 2-D Lur'e system perspective on CNNs is that we can use robust control theory much more efficiently for Lipschitz constant estimation than previously possible.
Expert-Free Online Transfer Learning in Multi-Agent Reinforcement Learning
Mar 02, 2023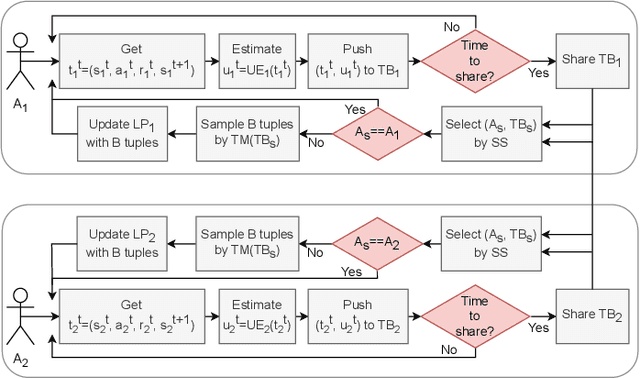
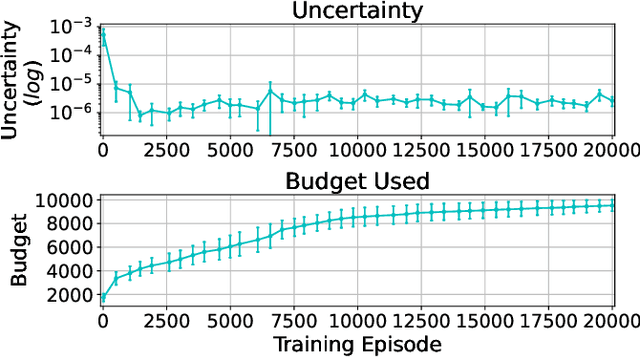
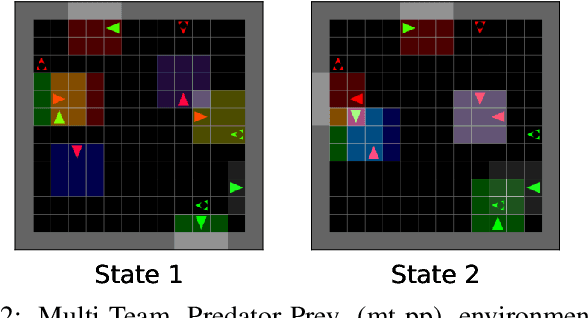
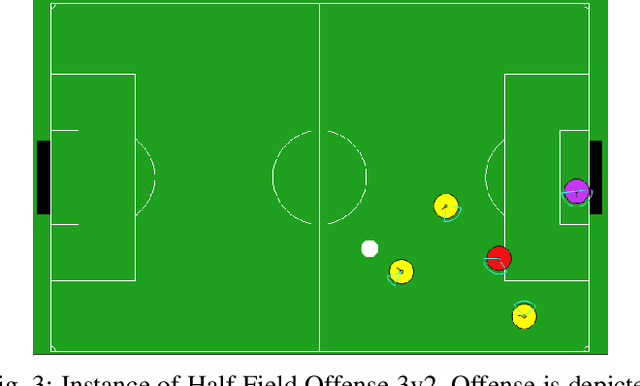
Transfer learning in Reinforcement Learning (RL) has been widely studied to overcome training issues of Deep-RL, i.e., exploration cost, data availability and convergence time, by introducing a way to enhance training phase with external knowledge. Generally, knowledge is transferred from expert-agents to novices. While this fixes the issue for a novice agent, a good understanding of the task on expert agent is required for such transfer to be effective. As an alternative, in this paper we propose Expert-Free Online Transfer Learning (EF-OnTL), an algorithm that enables expert-free real-time dynamic transfer learning in multi-agent system. No dedicated expert exists, and transfer source agent and knowledge to be transferred are dynamically selected at each transfer step based on agents' performance and uncertainty. To improve uncertainty estimation, we also propose State Action Reward Next-State Random Network Distillation (sars-RND), an extension of RND that estimates uncertainty from RL agent-environment interaction. We demonstrate EF-OnTL effectiveness against a no-transfer scenario and advice-based baselines, with and without expert agents, in three benchmark tasks: Cart-Pole, a grid-based Multi-Team Predator-Prey (mt-pp) and Half Field Offense (HFO). Our results show that EF-OnTL achieve overall comparable performance when compared against advice-based baselines while not requiring any external input nor threshold tuning. EF-OnTL outperforms no-transfer with an improvement related to the complexity of the task addressed.
Semiparametric Language Models Are Scalable Continual Learners
Mar 02, 2023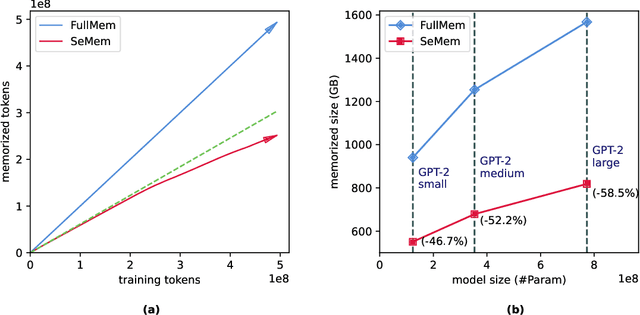

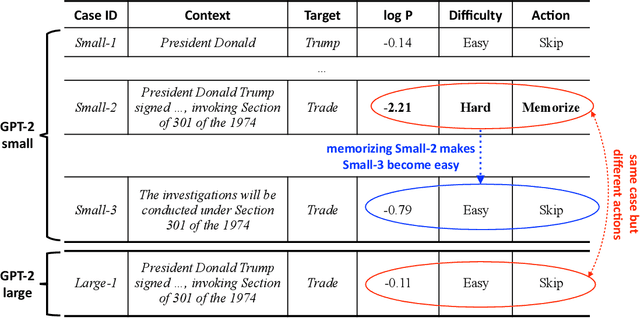

Semiparametric language models (LMs) have shown promise in continuously learning from new text data by combining a parameterized neural LM with a growable non-parametric memory for memorizing new content. However, conventional semiparametric LMs will finally become prohibitive for computing and storing if they are applied to continual learning over streaming data, because the non-parametric memory grows linearly with the amount of data they learn from over time. To address the issue of scalability, we present a simple and intuitive approach called Selective Memorization (SeMem), which only memorizes difficult samples that the model is likely to struggle with. We demonstrate that SeMem improves the scalability of semiparametric LMs for continual learning over streaming data in two ways: (1) data-wise scalability: as the model becomes stronger through continual learning, it will encounter fewer difficult cases that need to be memorized, causing the growth of the non-parametric memory to slow down over time rather than growing at a linear rate with the size of training data; (2) model-wise scalability: SeMem allows a larger model to memorize fewer samples than its smaller counterpart because it is rarer for a larger model to encounter incomprehensible cases, resulting in a non-parametric memory that does not scale linearly with model size. We conduct extensive experiments in language modeling and downstream tasks to test SeMem's results, showing SeMem enables a semiparametric LM to be a scalable continual learner with little forgetting.
Going faster to see further: GPU-accelerated value iteration and simulation for perishable inventory control using JAX
Mar 19, 2023
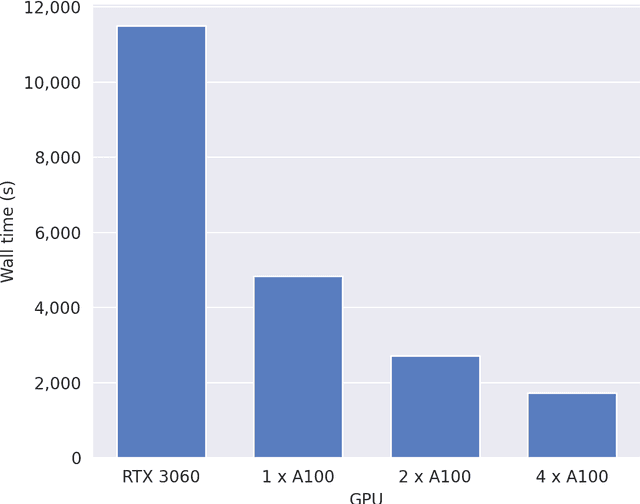

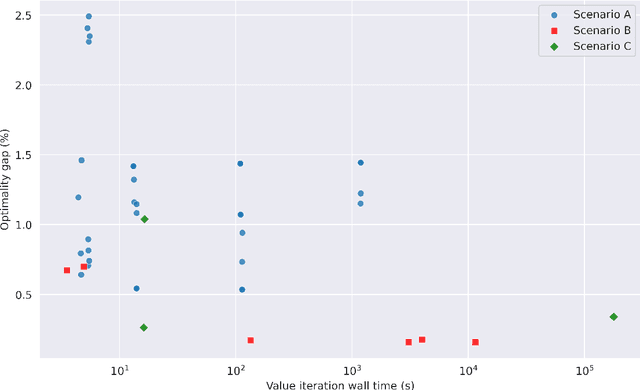
Value iteration can find the optimal replenishment policy for a perishable inventory problem, but is computationally demanding due to the large state spaces that are required to represent the age profile of stock. The parallel processing capabilities of modern GPUs can reduce the wall time required to run value iteration by updating many states simultaneously. The adoption of GPU-accelerated approaches has been limited in operational research relative to other fields like machine learning, in which new software frameworks have made GPU programming widely accessible. We used the Python library JAX to implement value iteration and simulators of the underlying Markov decision processes in a high-level API, and relied on this library's function transformations and compiler to efficiently utilize GPU hardware. Our method can extend use of value iteration to settings that were previously considered infeasible or impractical. We demonstrate this on example scenarios from three recent studies which include problems with over 16 million states and additional problem features, such as substitution between products, that increase computational complexity. We compare the performance of the optimal replenishment policies to heuristic policies, fitted using simulation optimization in JAX which allowed the parallel evaluation of multiple candidate policy parameters on thousands of simulated years. The heuristic policies gave a maximum optimality gap of 2.49%. Our general approach may be applicable to a wide range of problems in operational research that would benefit from large-scale parallel computation on consumer-grade GPU hardware.
Lower Generalization Bounds for GD and SGD in Smooth Stochastic Convex Optimization
Mar 19, 2023
Recent progress was made in characterizing the generalization error of gradient methods for general convex loss by the learning theory community. In this work, we focus on how training longer might affect generalization in smooth stochastic convex optimization (SCO) problems. We first provide tight lower bounds for general non-realizable SCO problems. Furthermore, existing upper bound results suggest that sample complexity can be improved by assuming the loss is realizable, i.e. an optimal solution simultaneously minimizes all the data points. However, this improvement is compromised when training time is long and lower bounds are lacking. Our paper examines this observation by providing excess risk lower bounds for gradient descent (GD) and stochastic gradient descent (SGD) in two realizable settings: 1) realizable with $T = O(n)$, and (2) realizable with $T = \Omega(n)$, where $T$ denotes the number of training iterations and $n$ is the size of the training dataset. These bounds are novel and informative in characterizing the relationship between $T$ and $n$. In the first small training horizon case, our lower bounds almost tightly match and provide the first optimal certificates for the corresponding upper bounds. However, for the realizable case with $T = \Omega(n)$, a gap exists between the lower and upper bounds. We provide a conjecture to address this problem, that the gap can be closed by improving upper bounds, which is supported by our analyses in one-dimensional and linear regression scenarios.
Multi-Channel Attentive Feature Fusion for Radio Frequency Fingerprinting
Mar 19, 2023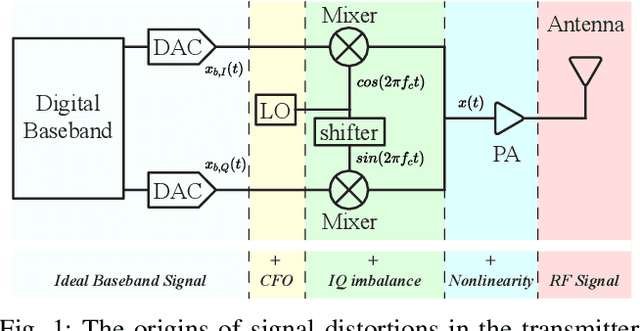
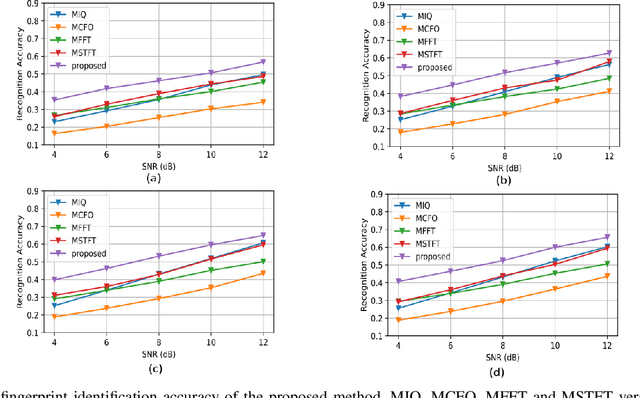
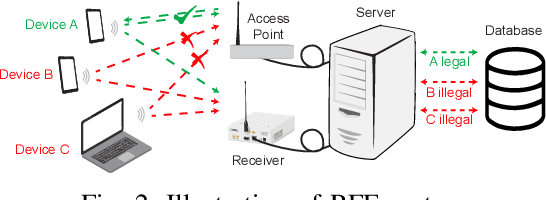
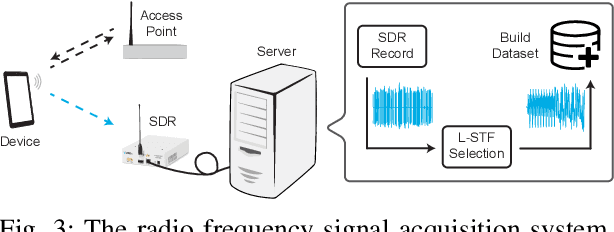
Radio frequency fingerprinting (RFF) is a promising device authentication technique for securing the Internet of things. It exploits the intrinsic and unique hardware impairments of the transmitters for RF device identification. In real-world communication systems, hardware impairments across transmitters are subtle, which are difficult to model explicitly. Recently, due to the superior performance of deep learning (DL)-based classification models on real-world datasets, DL networks have been explored for RFF. Most existing DL-based RFF models use a single representation of radio signals as the input. Multi-channel input model can leverage information from different representations of radio signals and improve the identification accuracy of the RF fingerprint. In this work, we propose a novel multi-channel attentive feature fusion (McAFF) method for RFF. It utilizes multi-channel neural features extracted from multiple representations of radio signals, including IQ samples, carrier frequency offset, fast Fourier transform coefficients and short-time Fourier transform coefficients, for better RF fingerprint identification. The features extracted from different channels are fused adaptively using a shared attention module, where the weights of neural features from multiple channels are learned during training the McAFF model. In addition, we design a signal identification module using a convolution-based ResNeXt block to map the fused features to device identities. To evaluate the identification performance of the proposed method, we construct a WiFi dataset, named WFDI, using commercial WiFi end-devices as the transmitters and a Universal Software Radio Peripheral (USRP) as the receiver. ...
HyperTime: Implicit Neural Representation for Time Series
Aug 11, 2022
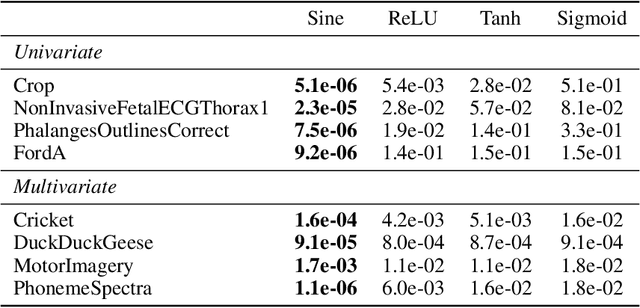
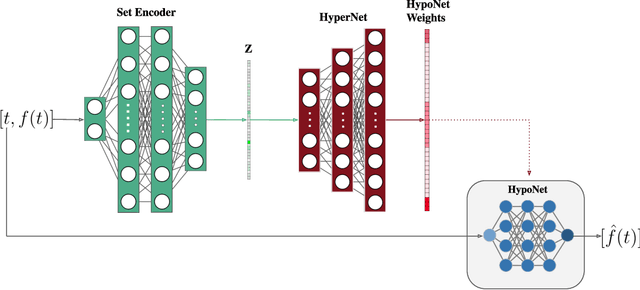
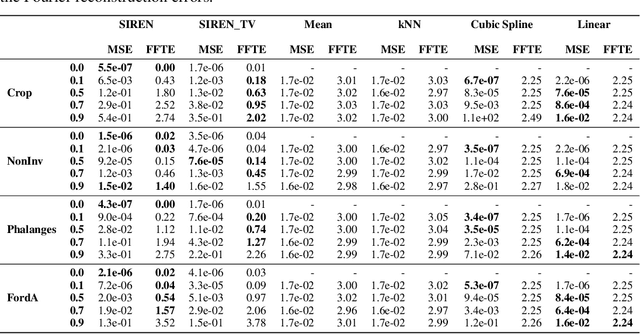
Implicit neural representations (INRs) have recently emerged as a powerful tool that provides an accurate and resolution-independent encoding of data. Their robustness as general approximators has been shown in a wide variety of data sources, with applications on image, sound, and 3D scene representation. However, little attention has been given to leveraging these architectures for the representation and analysis of time series data. In this paper, we analyze the representation of time series using INRs, comparing different activation functions in terms of reconstruction accuracy and training convergence speed. We show how these networks can be leveraged for the imputation of time series, with applications on both univariate and multivariate data. Finally, we propose a hypernetwork architecture that leverages INRs to learn a compressed latent representation of an entire time series dataset. We introduce an FFT-based loss to guide training so that all frequencies are preserved in the time series. We show that this network can be used to encode time series as INRs, and their embeddings can be interpolated to generate new time series from existing ones. We evaluate our generative method by using it for data augmentation, and show that it is competitive against current state-of-the-art approaches for augmentation of time series.
Super-Resolution Information Enhancement For Crowd Counting
Mar 13, 2023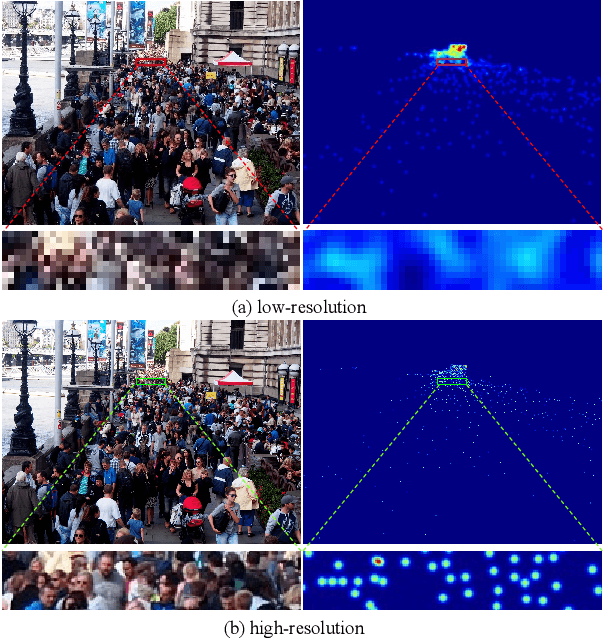
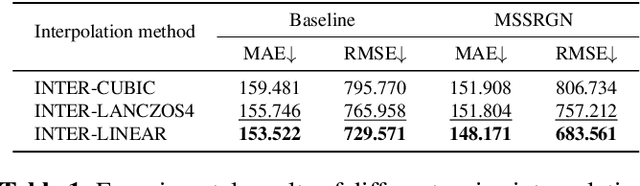
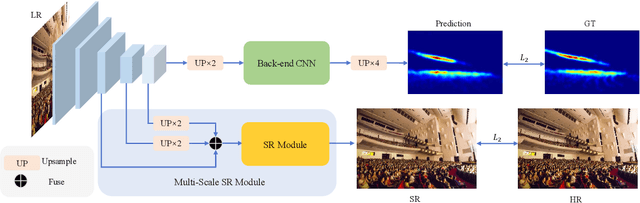
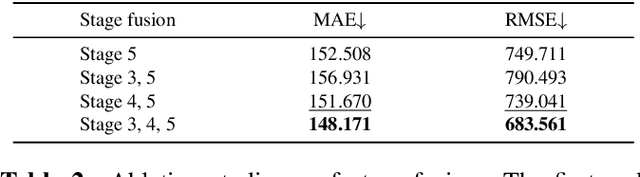
Crowd counting is a challenging task due to the heavy occlusions, scales, and density variations. Existing methods handle these challenges effectively while ignoring low-resolution (LR) circumstances. The LR circumstances weaken the counting performance deeply for two crucial reasons: 1) limited detail information; 2) overlapping head regions accumulate in density maps and result in extreme ground-truth values. An intuitive solution is to employ super-resolution (SR) pre-processes for the input LR images. However, it complicates the inference steps and thus limits application potentials when requiring real-time. We propose a more elegant method termed Multi-Scale Super-Resolution Module (MSSRM). It guides the network to estimate the lost de tails and enhances the detailed information in the feature space. Noteworthy that the MSSRM is plug-in plug-out and deals with the LR problems with no inference cost. As the proposed method requires SR labels, we further propose a Super-Resolution Crowd Counting dataset (SR-Crowd). Extensive experiments on three datasets demonstrate the superiority of our method. The code will be available at https://github.com/PRIS-CV/MSSRM.git.