 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A Composite T60 Regression and Classification Approach for Speech Dereverberation
Feb 09, 2023
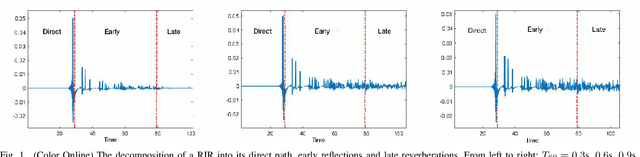
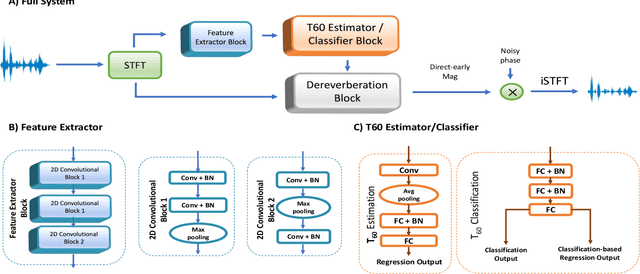
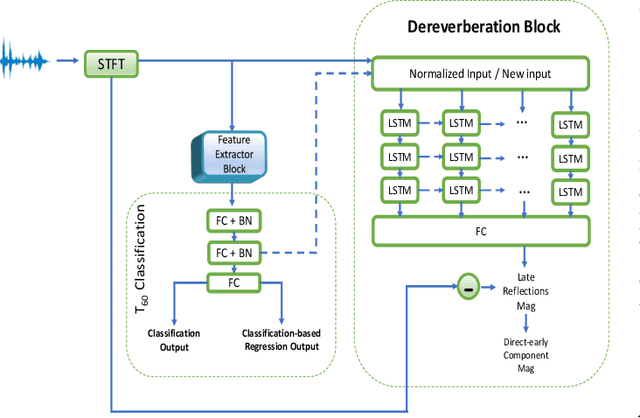
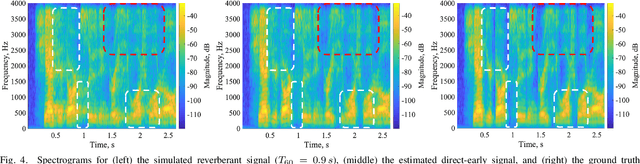
Dereverberation is often performed directly on the reverberant audio signal, without knowledge of the acoustic environment. Reverberation time, T60, however, is an essential acoustic factor that reflects how reverberation may impact a signal. In this work, we propose to perform dereverberation while leveraging key acoustic information from the environment. More specifically, we develop a joint learning approach that uses a composite T60 module and a separate dereverberation module to simultaneously perform reverberation time estimation and dereverberation. The reverberation time module provides key features to the dereverberation module during fine tuning. We evaluate our approach in simulated and real environments, and compare against several approaches. The results show that this composite framework improves performance in environments.
Dual Memory Aggregation Network for Event-Based Object Detection with Learnable Representation
Mar 17, 2023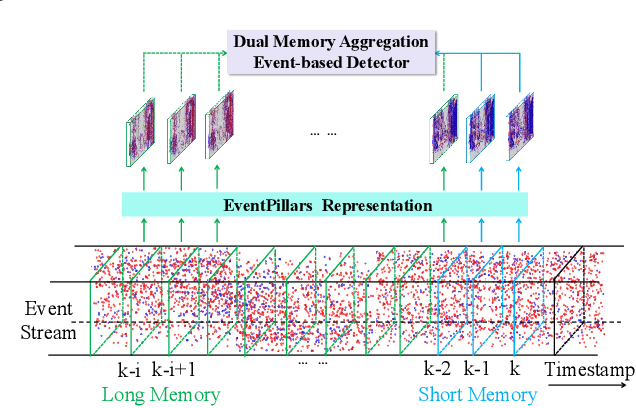

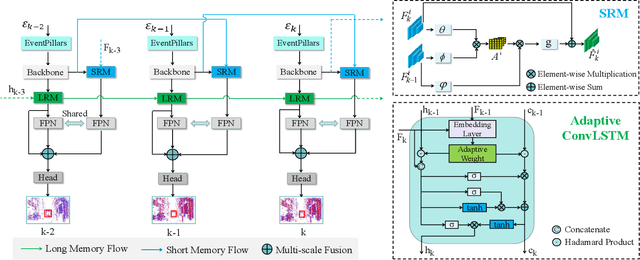
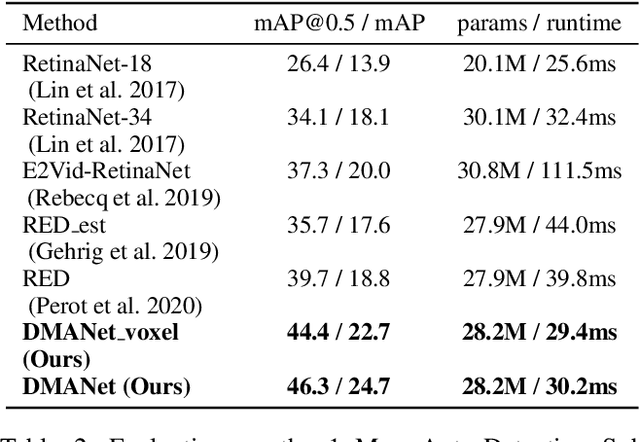
Event-based cameras are bio-inspired sensors that capture brightness change of every pixel in an asynchronous manner. Compared with frame-based sensors, event cameras have microsecond-level latency and high dynamic range, hence showing great potential for object detection under high-speed motion and poor illumination conditions. Due to sparsity and asynchronism nature with event streams, most of existing approaches resort to hand-crafted methods to convert event data into 2D grid representation. However, they are sub-optimal in aggregating information from event stream for object detection. In this work, we propose to learn an event representation optimized for event-based object detection. Specifically, event streams are divided into grids in the x-y-t coordinates for both positive and negative polarity, producing a set of pillars as 3D tensor representation. To fully exploit information with event streams to detect objects, a dual-memory aggregation network (DMANet) is proposed to leverage both long and short memory along event streams to aggregate effective information for object detection. Long memory is encoded in the hidden state of adaptive convLSTMs while short memory is modeled by computing spatial-temporal correlation between event pillars at neighboring time intervals. Extensive experiments on the recently released event-based automotive detection dataset demonstrate the effectiveness of the proposed method.
E-MLB: Multilevel Benchmark for Event-Based Camera Denoising
Mar 21, 2023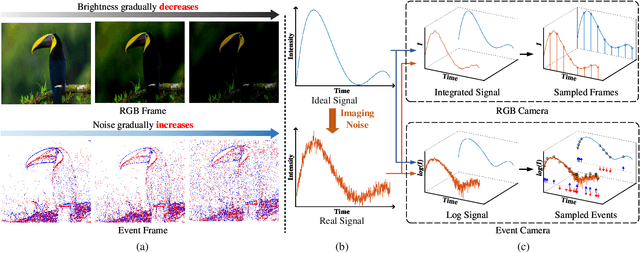
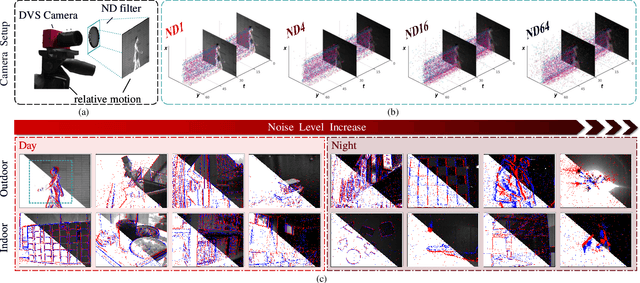
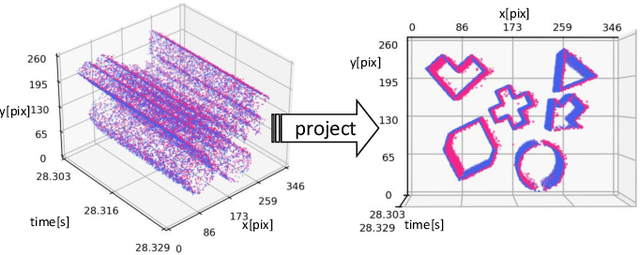
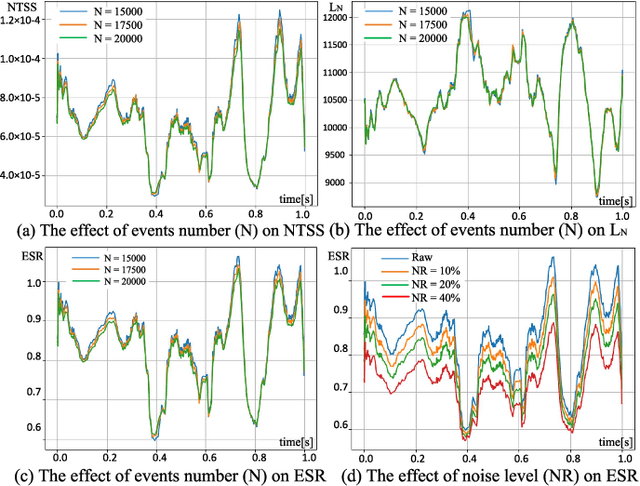
Event cameras, such as dynamic vision sensors (DVS), are biologically inspired vision sensors that have advanced over conventional cameras in high dynamic range, low latency and low power consumption, showing great application potential in many fields. Event cameras are more sensitive to junction leakage current and photocurrent as they output differential signals, losing the smoothing function of the integral imaging process in the RGB camera. The logarithmic conversion further amplifies noise, especially in low-contrast conditions. Recently, researchers proposed a series of datasets and evaluation metrics but limitations remain: 1) the existing datasets are small in scale and insufficient in noise diversity, which cannot reflect the authentic working environments of event cameras; and 2) the existing denoising evaluation metrics are mostly referenced evaluation metrics, relying on APS information or manual annotation. To address the above issues, we construct a large-scale event denoising dataset (multilevel benchmark for event denoising, E-MLB) for the first time, which consists of 100 scenes, each with four noise levels, that is 12 times larger than the largest existing denoising dataset. We also propose the first nonreference event denoising metric, the event structural ratio (ESR), which measures the structural intensity of given events. ESR is inspired by the contrast metric, but is independent of the number of events and projection direction. Based on the proposed benchmark and ESR, we evaluate the most representative denoising algorithms, including classic and SOTA, and provide denoising baselines under various scenes and noise levels. The corresponding results and codes are available at https://github.com/KugaMaxx/cuke-emlb.
Data-Efficient Learning of Natural Language to Linear Temporal Logic Translators for Robot Task Specification
Mar 21, 2023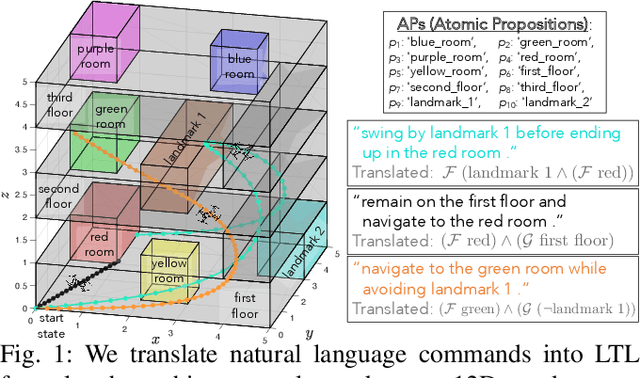
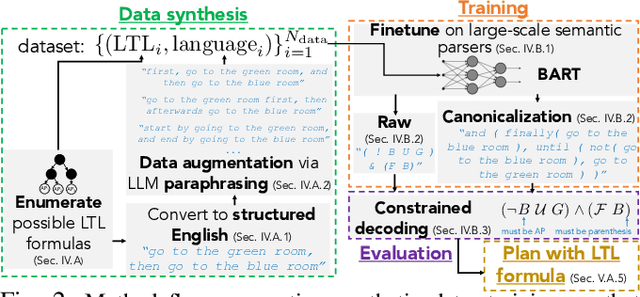
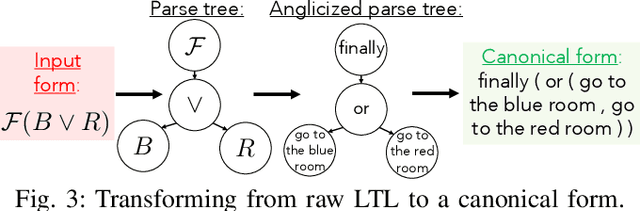

To make robots accessible to a broad audience, it is critical to endow them with the ability to take universal modes of communication, like commands given in natural language, and extract a concrete desired task specification, defined using a formal language like linear temporal logic (LTL). In this paper, we present a learning-based approach for translating from natural language commands to LTL specifications with very limited human-labeled training data. This is in stark contrast to existing natural-language to LTL translators, which require large human-labeled datasets, often in the form of labeled pairs of LTL formulas and natural language commands, to train the translator. To reduce reliance on human data, our approach generates a large synthetic training dataset through algorithmic generation of LTL formulas, conversion to structured English, and then exploiting the paraphrasing capabilities of modern large language models (LLMs) to synthesize a diverse corpus of natural language commands corresponding to the LTL formulas. We use this generated data to finetune an LLM and apply a constrained decoding procedure at inference time to ensure the returned LTL formula is syntactically correct. We evaluate our approach on three existing LTL/natural language datasets and show that we can translate natural language commands at 75\% accuracy with far less human data ($\le$12 annotations). Moreover, when training on large human-annotated datasets, our method achieves higher test accuracy (95\% on average) than prior work. Finally, we show the translated formulas can be used to plan long-horizon, multi-stage tasks on a 12D quadrotor.
End-to-End Integration of Speech Separation and Voice Activity Detection for Low-Latency Diarization of Telephone Conversations
Mar 21, 2023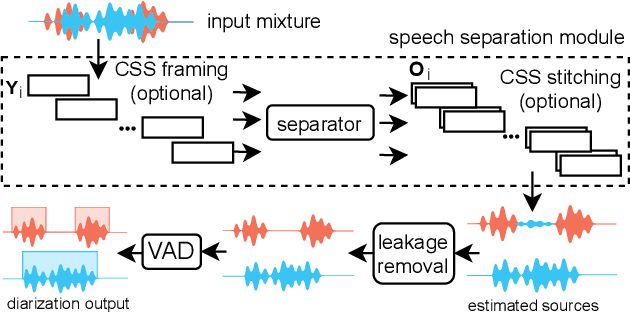
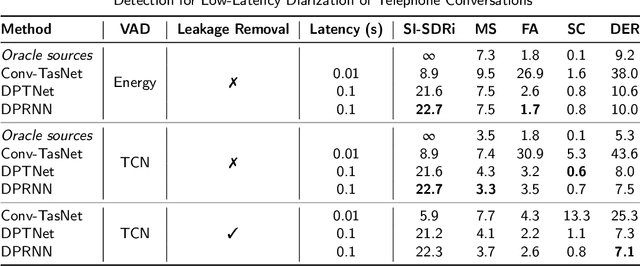
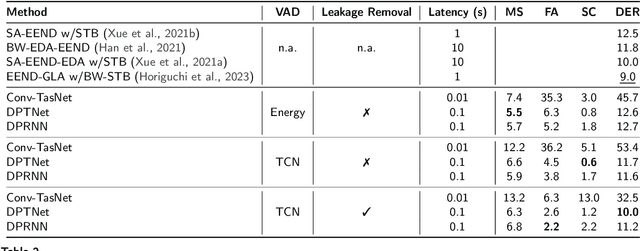

Recent works show that speech separation guided diarization (SSGD) is an increasingly promising direction, mainly thanks to the recent progress in speech separation. It performs diarization by first separating the speakers and then applying voice activity detection (VAD) on each separated stream. In this work we conduct an in-depth study of SSGD in the conversational telephone speech (CTS) domain, focusing mainly on low-latency streaming diarization applications. We consider three state-of-the-art speech separation (SSep) algorithms and study their performance both in online and offline scenarios, considering non-causal and causal implementations as well as continuous SSep (CSS) windowed inference. We compare different SSGD algorithms on two widely used CTS datasets: CALLHOME and Fisher Corpus (Part 1 and 2) and evaluate both separation and diarization performance. To improve performance, a novel, causal and computationally efficient leakage removal algorithm is proposed, which significantly decreases false alarms. We also explore, for the first time, fully end-to-end SSGD integration between SSep and VAD modules. Crucially, this enables fine-tuning on real-world data for which oracle speakers sources are not available. In particular, our best model achieves 8.8% DER on CALLHOME, which outperforms the current state-of-the-art end-to-end neural diarization model, despite being trained on an order of magnitude less data and having significantly lower latency, i.e., 0.1 vs. 1 seconds. Finally, we also show that the separated signals can be readily used also for automatic speech recognition, reaching performance close to using oracle sources in some configurations.
Policy Optimization for Personalized Interventions in Behavioral Health
Mar 21, 2023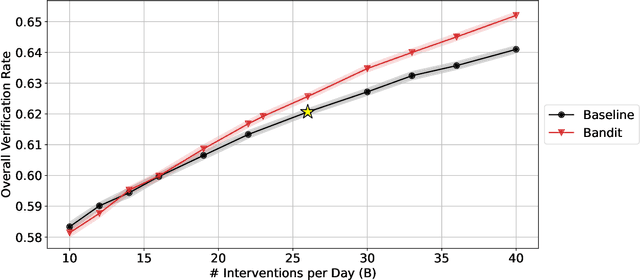

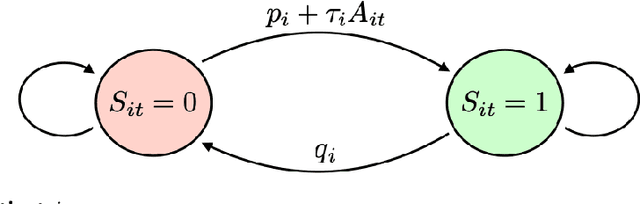
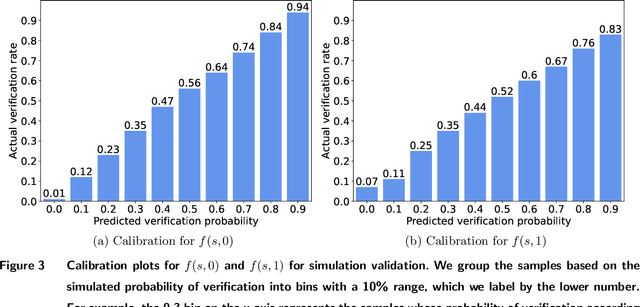
Problem definition: Behavioral health interventions, delivered through digital platforms, have the potential to significantly improve health outcomes, through education, motivation, reminders, and outreach. We study the problem of optimizing personalized interventions for patients to maximize some long-term outcome, in a setting where interventions are costly and capacity-constrained. Methodology/results: This paper provides a model-free approach to solving this problem. We find that generic model-free approaches from the reinforcement learning literature are too data intensive for healthcare applications, while simpler bandit approaches make progress at the expense of ignoring long-term patient dynamics. We present a new algorithm we dub DecompPI that approximates one step of policy iteration. Implementing DecompPI simply consists of a prediction task from offline data, alleviating the need for online experimentation. Theoretically, we show that under a natural set of structural assumptions on patient dynamics, DecompPI surprisingly recovers at least 1/2 of the improvement possible between a naive baseline policy and the optimal policy. At the same time, DecompPI is both robust to estimation errors and interpretable. Through an empirical case study on a mobile health platform for improving treatment adherence for tuberculosis, we find that DecompPI can provide the same efficacy as the status quo with approximately half the capacity of interventions. Managerial implications: DecompPI is general and is easily implementable for organizations aiming to improve long-term behavior through targeted interventions. Our case study suggests that the platform's costs of deploying interventions can potentially be cut by 50%, which facilitates the ability to scale up the system in a cost-efficient fashion.
Inverting the Fundamental Diagram and Forecasting Boundary Conditions: How Machine Learning Can Improve Macroscopic Models for Traffic Flow
Mar 21, 2023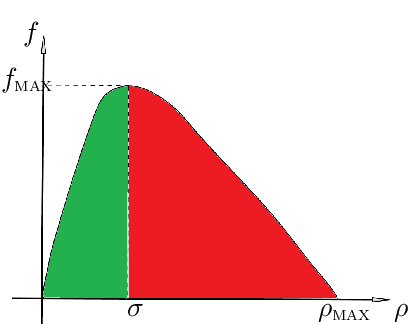
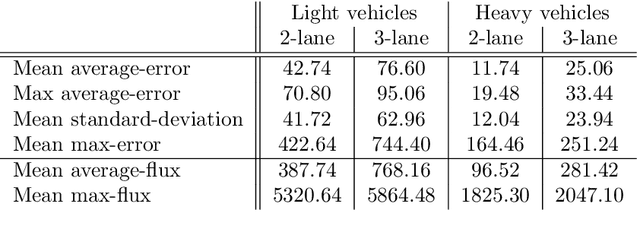
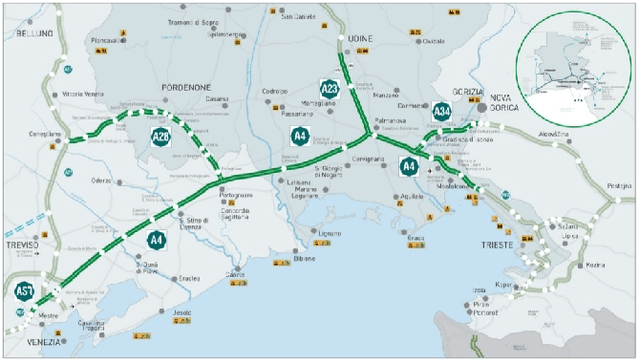
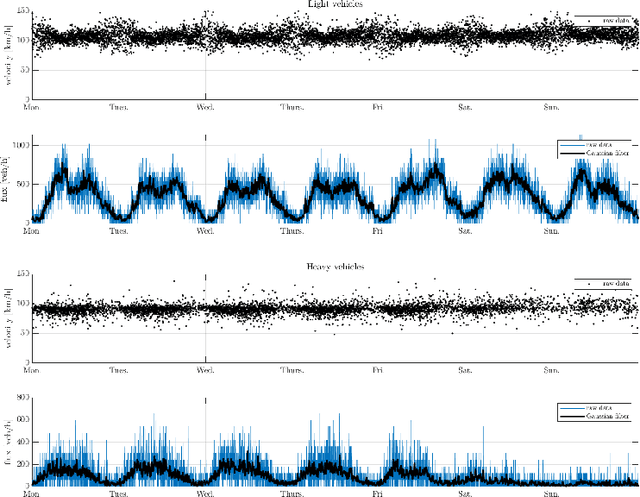
In this paper, we aim at developing new methods to join machine learning techniques and macroscopic differential models for vehicular traffic estimation and forecast. It is well known that data-driven and model-driven approaches have (sometimes complementary) advantages and drawbacks. We consider here a dataset with flux and velocity data of vehicles moving on a highway, collected by fixed sensors and classified by lane and by class of vehicle. By means of a machine learning model based on an LSTM recursive neural network, we extrapolate two important pieces of information: 1) if congestion is appearing under the sensor, and 2) the total amount of vehicles which is going to pass under the sensor in the next future (30 min). These pieces of information are then used to improve the accuracy of an LWR-based first-order multi-class model describing the dynamics of traffic flow between sensors. The first piece of information is used to invert the (concave) fundamental diagram, thus recovering the density of vehicles from the flux data, and then inject directly the density datum in the model. This allows one to better approximate the dynamics between sensors, especially if an accident happens in a not monitored stretch of the road. The second piece of information is used instead as boundary conditions for the equations underlying the traffic model, to better reconstruct the total amount of vehicles on the road at any future time. Some examples motivated by real scenarios will be discussed. Real data are provided by the Italian motorway company Autovie Venete S.p.A.
CLSA: Contrastive Learning-based Survival Analysis for Popularity Prediction in MEC Networks
Mar 21, 2023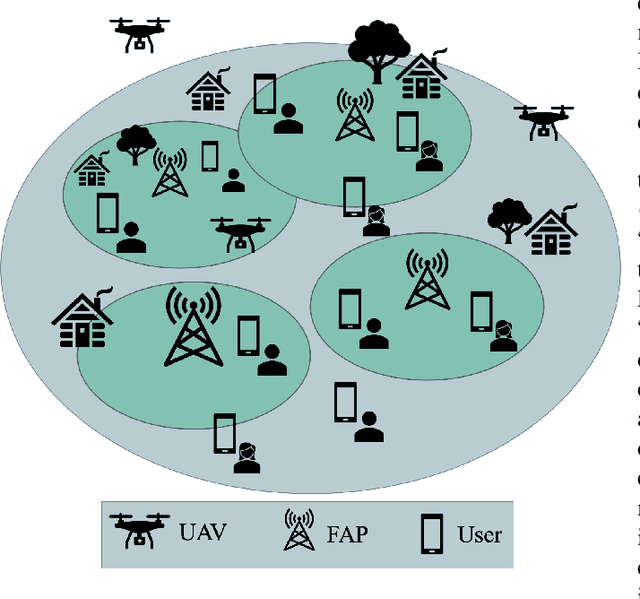
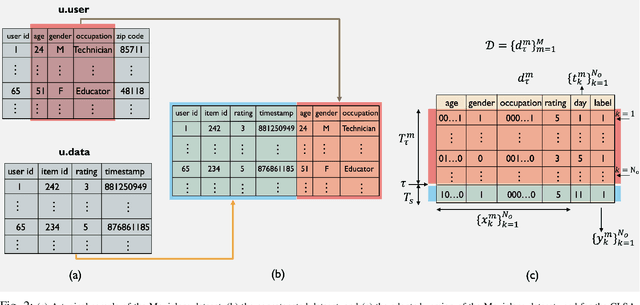
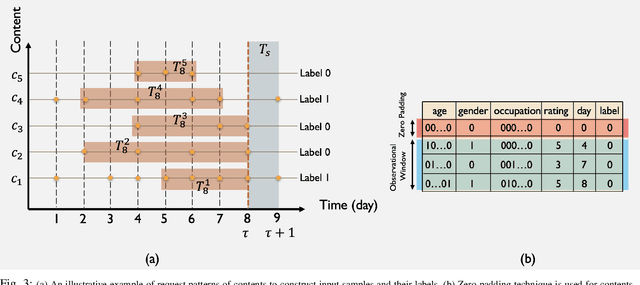
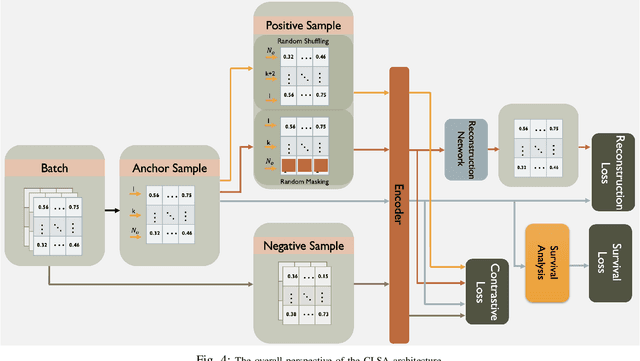
Mobile Edge Caching (MEC) integrated with Deep Neural Networks (DNNs) is an innovative technology with significant potential for the future generation of wireless networks, resulting in a considerable reduction in users' latency. The MEC network's effectiveness, however, heavily relies on its capacity to predict and dynamically update the storage of caching nodes with the most popular contents. To be effective, a DNN-based popularity prediction model needs to have the ability to understand the historical request patterns of content, including their temporal and spatial correlations. Existing state-of-the-art time-series DNN models capture the latter by simultaneously inputting the sequential request patterns of multiple contents to the network, considerably increasing the size of the input sample. This motivates us to address this challenge by proposing a DNN-based popularity prediction framework based on the idea of contrasting input samples against each other, designed for the Unmanned Aerial Vehicle (UAV)-aided MEC networks. Referred to as the Contrastive Learning-based Survival Analysis (CLSA), the proposed architecture consists of a self-supervised Contrastive Learning (CL) model, where the temporal information of sequential requests is learned using a Long Short Term Memory (LSTM) network as the encoder of the CL architecture. Followed by a Survival Analysis (SA) network, the output of the proposed CLSA architecture is probabilities for each content's future popularity, which are then sorted in descending order to identify the Top-K popular contents. Based on the simulation results, the proposed CLSA architecture outperforms its counterparts across the classification accuracy and cache-hit ratio.
Time Minimization in Hierarchical Federated Learning
Oct 07, 2022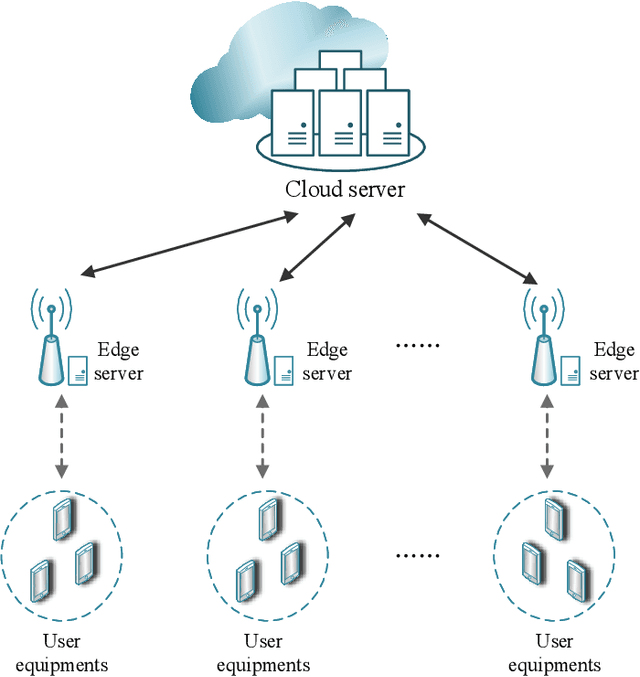
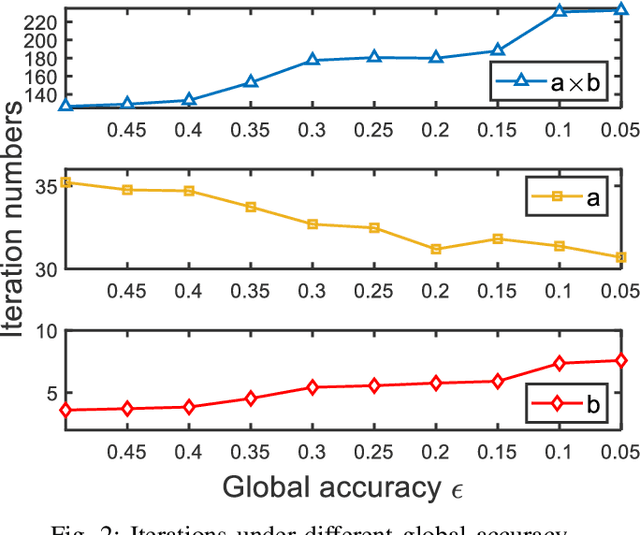
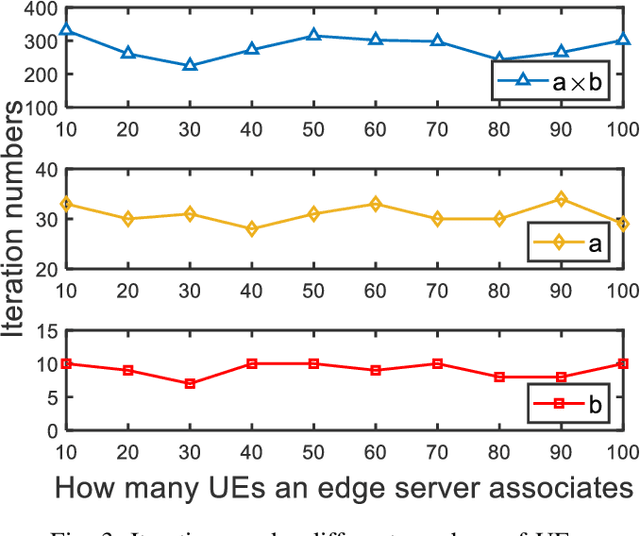
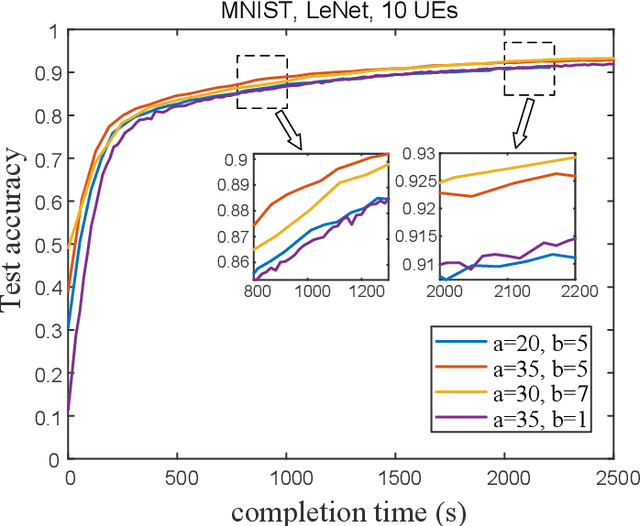
Federated Learning is a modern decentralized machine learning technique where user equipments perform machine learning tasks locally and then upload the model parameters to a central server. In this paper, we consider a 3-layer hierarchical federated learning system which involves model parameter exchanges between the cloud and edge servers, and the edge servers and user equipment. In a hierarchical federated learning model, delay in communication and computation of model parameters has a great impact on achieving a predefined global model accuracy. Therefore, we formulate a joint learning and communication optimization problem to minimize total model parameter communication and computation delay, by optimizing local iteration counts and edge iteration counts. To solve the problem, an iterative algorithm is proposed. After that, a time-minimized UE-to-edge association algorithm is presented where the maximum latency of the system is reduced. Simulation results show that the global model converges faster under optimal edge server and local iteration counts. The hierarchical federated learning latency is minimized with the proposed UE-to-edge association strategy.
Generating Initial Conditions for Ensemble Data Assimilation of Large-Eddy Simulations with Latent Diffusion Models
Mar 01, 2023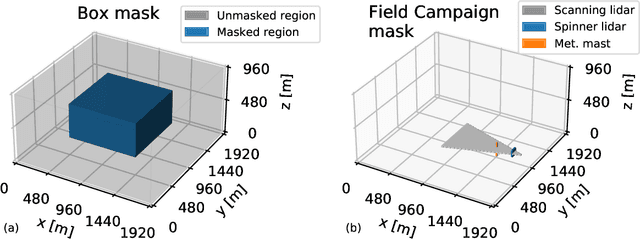
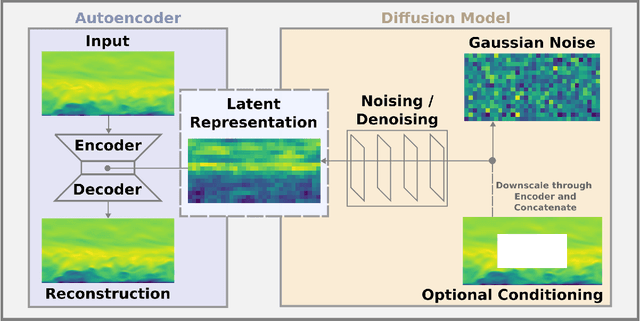
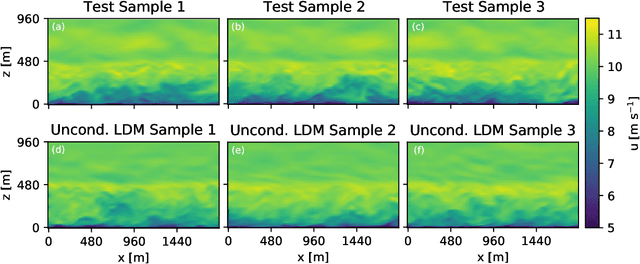
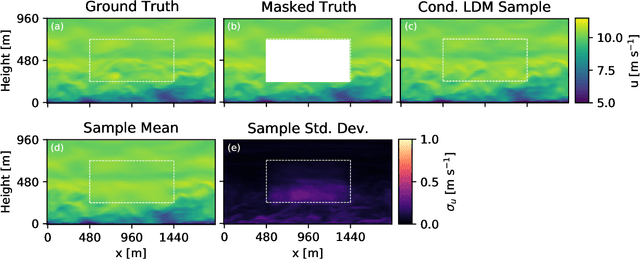
In order to accurately reconstruct the time history of the atmospheric state, ensemble-based data assimilation algorithms need to be initialized appropriately. At present, there is no standard approach to initializing large-eddy simulation codes for microscale data assimilation. Here, given synthetic observations, we generate ensembles of plausible initial conditions using a latent diffusion model. We modify the original, two-dimensional latent diffusion model code to work on three-dimensional turbulent fields. The algorithm produces realistic and diverse samples that successfully run when inserted into a large-eddy simulation code. The samples have physically plausible turbulent structures on large and moderate spatial scales in the context of our simulations. The generated ensembles show a lower spread in the vicinity of observations while having higher variability further from the observations, matching expected behavior. Ensembles demonstrate near-zero bias relative to ground truth in the vicinity of observations, but rank histogram analysis suggests that ensembles have too little member-to-member variability when compared to an ideal ensemble. Given the success of the latent diffusion model, the generated ensembles will be tested in their ability to recreate a time history of the atmosphere when coupled to an ensemble-based data assimilation algorithm in upcoming work. We find that diffusion models show promise and potential for other applications within the geosciences.