 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Text-to-Image Diffusion Models are Great Sketch-Photo Matchmakers
Mar 12, 2024
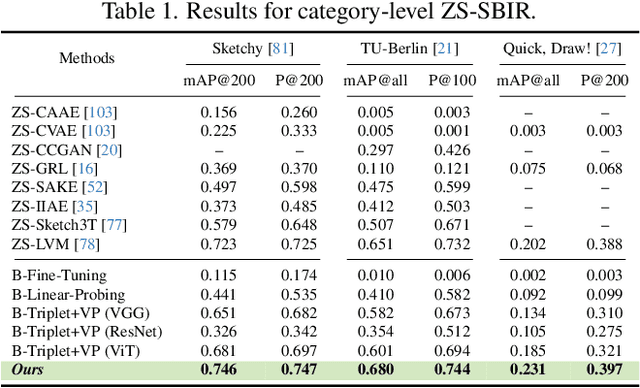
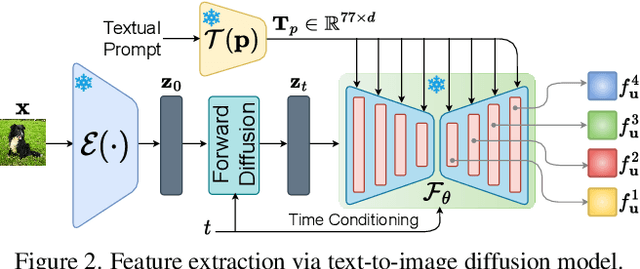


This paper, for the first time, explores text-to-image diffusion models for Zero-Shot Sketch-based Image Retrieval (ZS-SBIR). We highlight a pivotal discovery: the capacity of text-to-image diffusion models to seamlessly bridge the gap between sketches and photos. This proficiency is underpinned by their robust cross-modal capabilities and shape bias, findings that are substantiated through our pilot studies. In order to harness pre-trained diffusion models effectively, we introduce a straightforward yet powerful strategy focused on two key aspects: selecting optimal feature layers and utilising visual and textual prompts. For the former, we identify which layers are most enriched with information and are best suited for the specific retrieval requirements (category-level or fine-grained). Then we employ visual and textual prompts to guide the model's feature extraction process, enabling it to generate more discriminative and contextually relevant cross-modal representations. Extensive experiments on several benchmark datasets validate significant performance improvements.
BAGEL: Bootstrapping Agents by Guiding Exploration with Language
Mar 12, 2024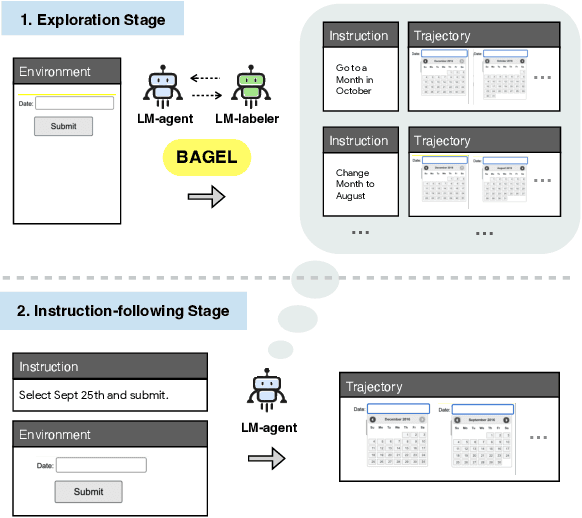
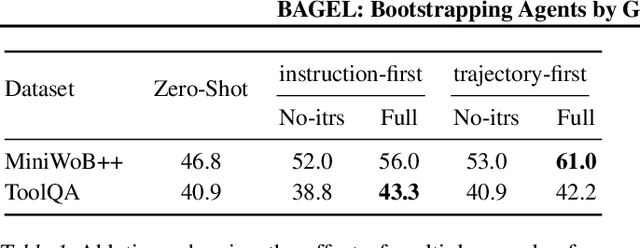
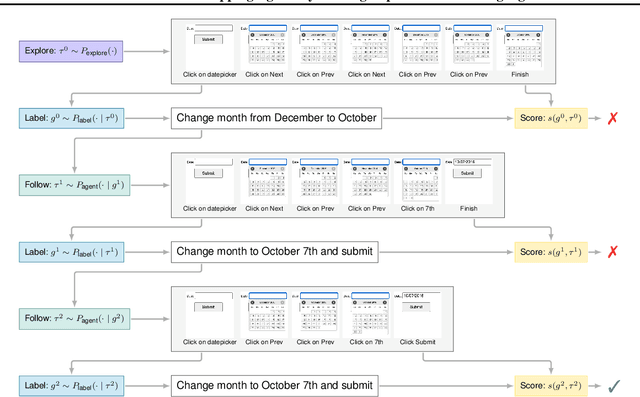
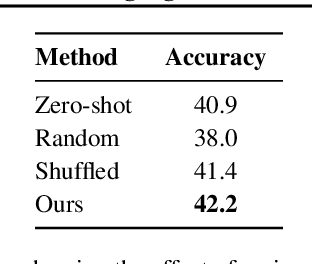
Following natural language instructions by executing actions in digital environments (e.g. web-browsers and REST APIs) is a challenging task for language model (LM) agents. Unfortunately, LM agents often fail to generalize to new environments without human demonstrations. This work presents BAGEL, a method for bootstrapping LM agents without human supervision. BAGEL converts a seed set of randomly explored trajectories or synthetic instructions, into demonstrations, via round-trips between two noisy LM components: an LM labeler which converts a trajectory into a synthetic instruction, and a zero-shot LM agent which maps the synthetic instruction into a refined trajectory. By performing these round-trips iteratively, BAGEL quickly converts the initial distribution of trajectories towards those that are well-described by natural language. We use BAGEL demonstrations to adapt a zero shot LM agent at test time via in-context learning over retrieved demonstrations, and find improvements of over 2-13% absolute on ToolQA and MiniWob++, with up to 13x reduction in execution failures.
Target Speaker Extraction by Directly Exploiting Contextual Information in the Time-Frequency Domain
Feb 27, 2024In target speaker extraction, many studies rely on the speaker embedding which is obtained from an enrollment of the target speaker and employed as the guidance. However, solely using speaker embedding may not fully utilize the contextual information contained in the enrollment. In this paper, we directly exploit this contextual information in the time-frequency (T-F) domain. Specifically, the T-F representations of the enrollment and the mixed signal are interacted to compute the weighting matrices through an attention mechanism. These weighting matrices reflect the similarity among different frames of the T-F representations and are further employed to obtain the consistent T-F representations of the enrollment. These consistent representations are served as the guidance, allowing for better exploitation of the contextual information. Furthermore, the proposed method achieves the state-of-the-art performance on the benchmark dataset and shows its effectiveness in the complex scenarios.
Accelerated Real-time Cine and Flow under In-magnet Staged Exercise
Feb 27, 2024Background: Cardiovascular magnetic resonance imaging (CMR) is a well-established imaging tool for diagnosing and managing cardiac conditions. The integration of exercise stress with CMR (ExCMR) can enhance its diagnostic capacity. Despite recent advances in CMR technology, ExCMR remains technically challenging due to motion artifacts and limited spatial and temporal resolution. Methods: This study investigates the feasibility of biventricular functional and hemodynamic assessment using real-time (RT) ExCMR during a staged exercise protocol in 26 healthy volunteers. We introduce a coil reweighting technique to minimize motion artifacts. In addition, we identify and analyze heartbeats from the end-expiratory phase to enhance the repeatability of cardiac function quantification. To demonstrate clinical feasibility, qualitative results from five patients are also presented. Results: Our findings indicate a consistent decrease in end-systolic volume (ESV) and stable end-diastolic volume (EDV) across exercise intensities, leading to increased stroke volume (SV) and ejection fraction (EF). Coil reweighting effectively reduces motion artifacts, improving image quality in both healthy volunteers and patients. The repeatability of cardiac function parameters, demonstrated by scan-rescan tests in nine volunteers, improves with the selection of end-expiratory beats. Conclusions: The study demonstrates that RT ExCMR with in-magnet exercise is a feasible and effective method for dynamic cardiac function monitoring during exercise. The proposed coil reweighting technique and selection of end-expiratory beats significantly enhance image quality and repeatability.
Distributed Average Consensus via Noisy and Non-Coherent Over-the-Air Aggregation
Mar 11, 2024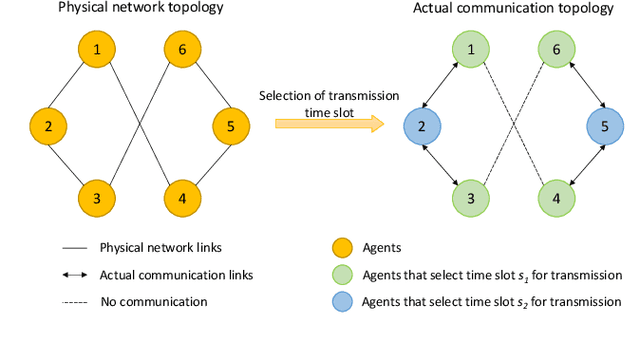
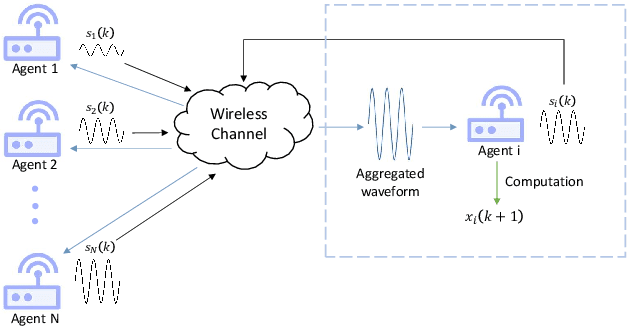
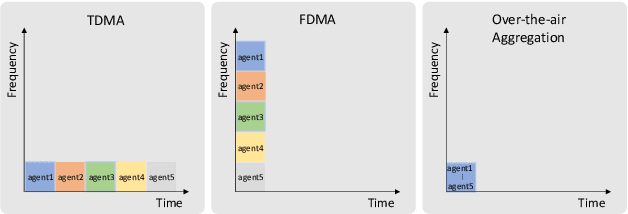
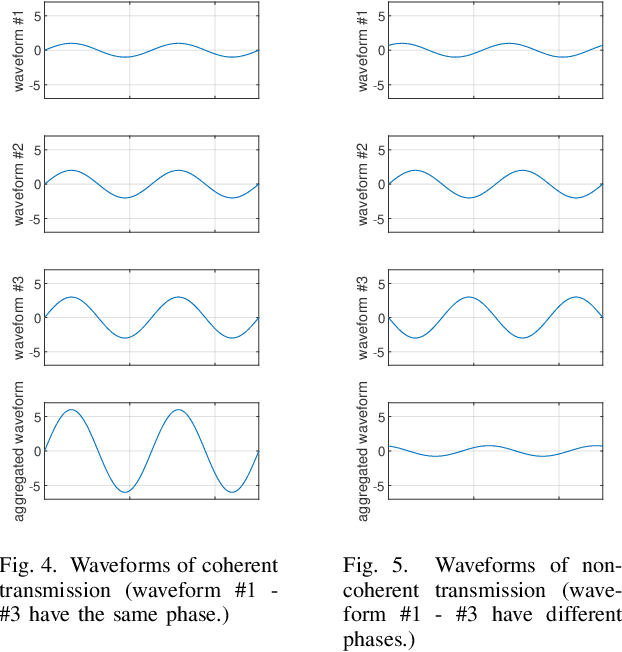
Over-the-air aggregation has attracted widespread attention for its potential advantages in task-oriented applications, such as distributed sensing, learning, and consensus. In this paper, we develop a communication-efficient distributed average consensus protocol by utilizing over-the-air aggregation, which exploits the superposition property of wireless channels rather than combat it. Noisy channels and non-coherent transmission are taken into account, and only half-duplex transceivers are required. We prove that the system can achieve average consensus in mean square and even almost surely under the proposed protocol. Furthermore, we extend the analysis to the scenarios with time-varying topology. Numerical simulation shows the effectiveness of the proposed protocol.
A Generalized Framework with Adaptive Weighted Soft-Margin for Imbalanced SVM Classification
Mar 13, 2024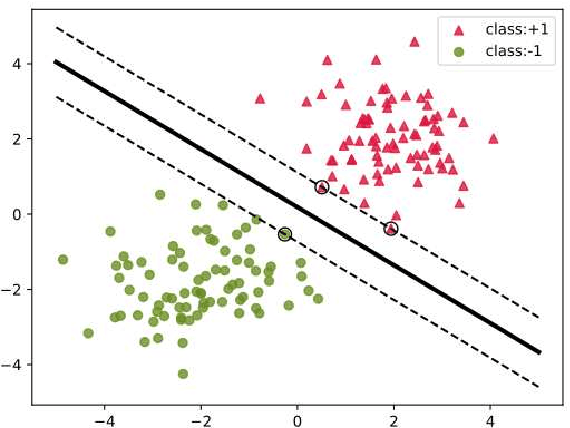

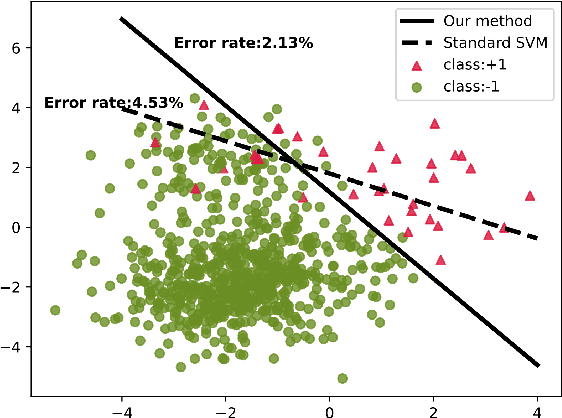
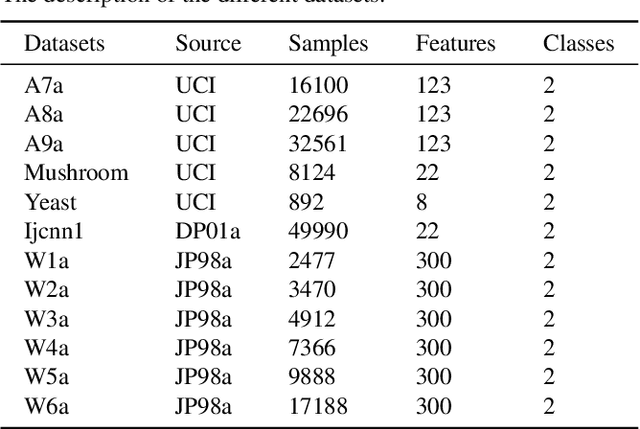
Category imbalance is one of the most popular and important issues in the domain of classification. In this paper, we present a new generalized framework with Adaptive Weight function for soft-margin Weighted SVM (AW-WSVM), which aims to enhance the issue of imbalance and outlier sensitivity in standard support vector machine (SVM) for classifying two-class data. The weight coefficient is introduced into the unconstrained soft-margin support vector machines, and the sample weights are updated before each training. The Adaptive Weight function (AW function) is constructed from the distance between the samples and the decision hyperplane, assigning different weights to each sample. A weight update method is proposed, taking into account the proximity of the support vectors to the decision hyperplane. Before training, the weights of the corresponding samples are initialized according to different categories. Subsequently, the samples close to the decision hyperplane are identified and assigned more weights. At the same time, lower weights are assigned to samples that are far from the decision hyperplane. Furthermore, we also put forward an effective way to eliminate noise. To evaluate the strength of the proposed generalized framework, we conducted experiments on standard datasets and emotion classification datasets with different imbalanced ratios (IR). The experimental results prove that the proposed generalized framework outperforms in terms of accuracy, recall metrics and G-mean, validating the effectiveness of the weighted strategy provided in this paper in enhancing support vector machines.
MD-Dose: A Diffusion Model based on the Mamba for Radiotherapy Dose Prediction
Mar 13, 2024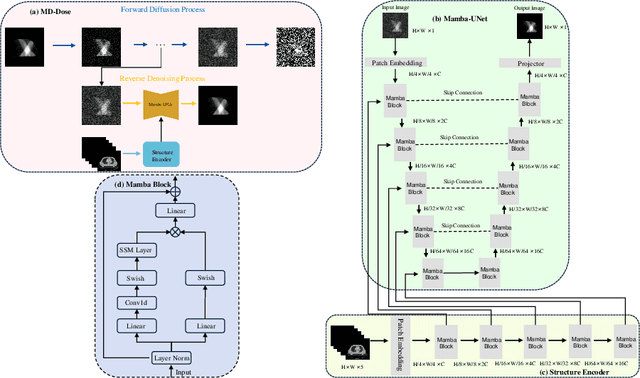
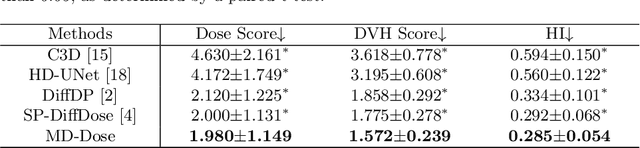
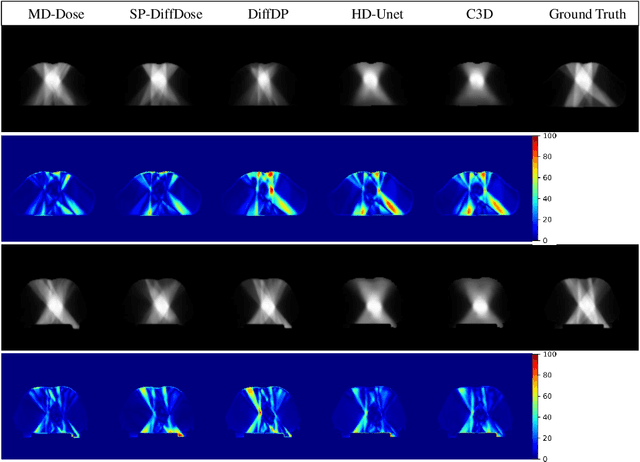
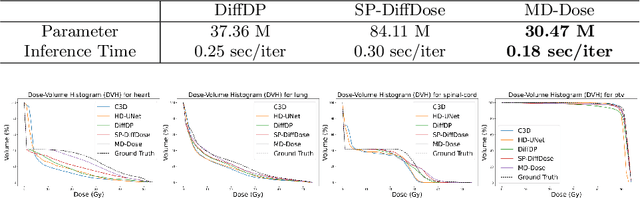
Radiation therapy is crucial in cancer treatment. Experienced experts typically iteratively generate high-quality dose distribution maps, forming the basis for excellent radiation therapy plans. Therefore, automated prediction of dose distribution maps is significant in expediting the treatment process and providing a better starting point for developing radiation therapy plans. With the remarkable results of diffusion models in predicting high-frequency regions of dose distribution maps, dose prediction methods based on diffusion models have been extensively studied. However, existing methods mainly utilize CNNs or Transformers as denoising networks. CNNs lack the capture of global receptive fields, resulting in suboptimal prediction performance. Transformers excel in global modeling but face quadratic complexity with image size, resulting in significant computational overhead. To tackle these challenges, we introduce a novel diffusion model, MD-Dose, based on the Mamba architecture for predicting radiation therapy dose distribution in thoracic cancer patients. In the forward process, MD-Dose adds Gaussian noise to dose distribution maps to obtain pure noise images. In the backward process, MD-Dose utilizes a noise predictor based on the Mamba to predict the noise, ultimately outputting the dose distribution maps. Furthermore, We develop a Mamba encoder to extract structural information and integrate it into the noise predictor for localizing dose regions in the planning target volume (PTV) and organs at risk (OARs). Through extensive experiments on a dataset of 300 thoracic tumor patients, we showcase the superiority of MD-Dose in various metrics and time consumption.
FogGuard: guarding YOLO against fog using perceptual loss
Mar 13, 2024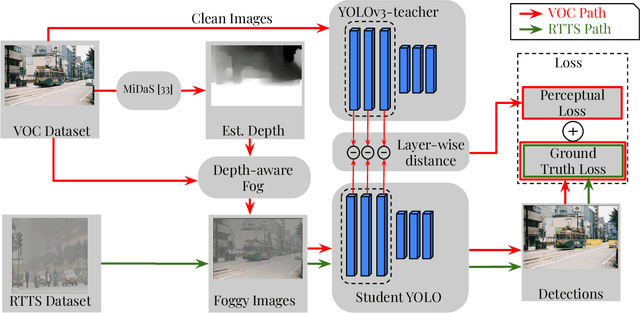
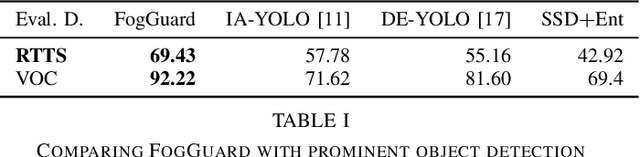

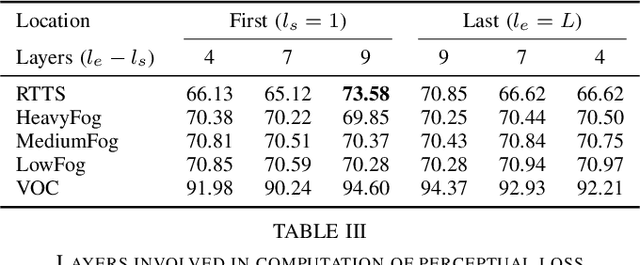
In this paper, we present a novel fog-aware object detection network called FogGuard, designed to address the challenges posed by foggy weather conditions. Autonomous driving systems heavily rely on accurate object detection algorithms, but adverse weather conditions can significantly impact the reliability of deep neural networks (DNNs). Existing approaches fall into two main categories, 1) image enhancement such as IA-YOLO 2) domain adaptation based approaches. Image enhancement based techniques attempt to generate fog-free image. However, retrieving a fogless image from a foggy image is a much harder problem than detecting objects in a foggy image. Domain-adaptation based approaches, on the other hand, do not make use of labelled datasets in the target domain. Both categories of approaches are attempting to solve a harder version of the problem. Our approach builds over fine-tuning on the Our framework is specifically designed to compensate for foggy conditions present in the scene, ensuring robust performance even. We adopt YOLOv3 as the baseline object detection algorithm and introduce a novel Teacher-Student Perceptual loss, to high accuracy object detection in foggy images. Through extensive evaluations on common datasets such as PASCAL VOC and RTTS, we demonstrate the improvement in performance achieved by our network. We demonstrate that FogGuard achieves 69.43\% mAP, as compared to 57.78\% for YOLOv3 on the RTTS dataset. Furthermore, we show that while our training method increases time complexity, it does not introduce any additional overhead during inference compared to the regular YOLO network.
Local Binary and Multiclass SVMs Trained on a Quantum Annealer
Mar 13, 2024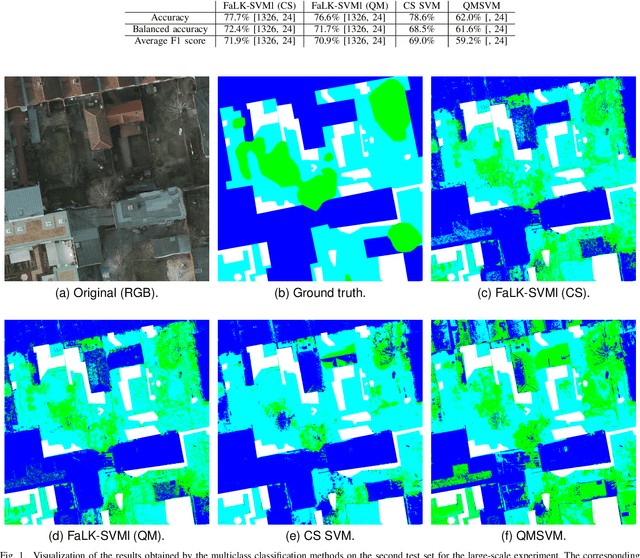



Support vector machines (SVMs) are widely used machine learning models (e.g., in remote sensing), with formulations for both classification and regression tasks. In the last years, with the advent of working quantum annealers, hybrid SVM models characterised by quantum training and classical execution have been introduced. These models have demonstrated comparable performance to their classical counterparts. However, they are limited in the training set size due to the restricted connectivity of the current quantum annealers. Hence, to take advantage of large datasets (like those related to Earth observation), a strategy is required. In the classical domain, local SVMs, namely, SVMs trained on the data samples selected by a k-nearest neighbors model, have already proven successful. Here, the local application of quantum-trained SVM models is proposed and empirically assessed. In particular, this approach allows overcoming the constraints on the training set size of the quantum-trained models while enhancing their performance. In practice, the FaLK-SVM method, designed for efficient local SVMs, has been combined with quantum-trained SVM models for binary and multiclass classification. In addition, for comparison, FaLK-SVM has been interfaced for the first time with a classical single-step multiclass SVM model (CS SVM). Concerning the empirical evaluation, D-Wave's quantum annealers and real-world datasets taken from the remote sensing domain have been employed. The results have shown the effectiveness and scalability of the proposed approach, but also its practical applicability in a real-world large-scale scenario.
Optimizing Risk-averse Human-AI Hybrid Teams
Mar 13, 2024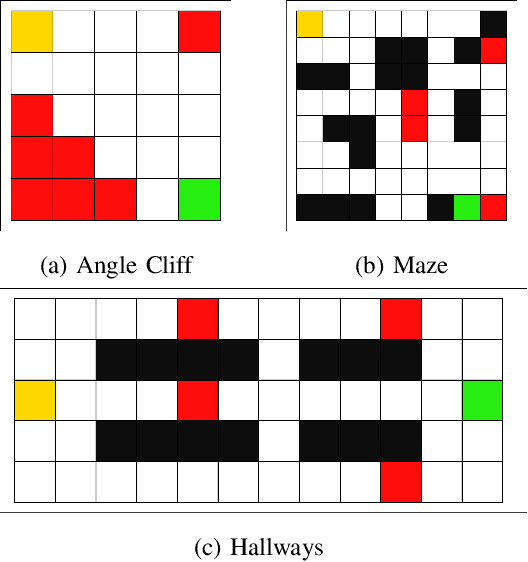
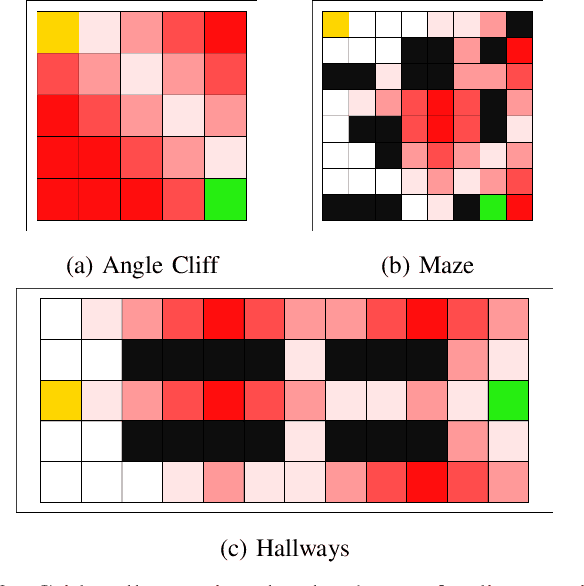
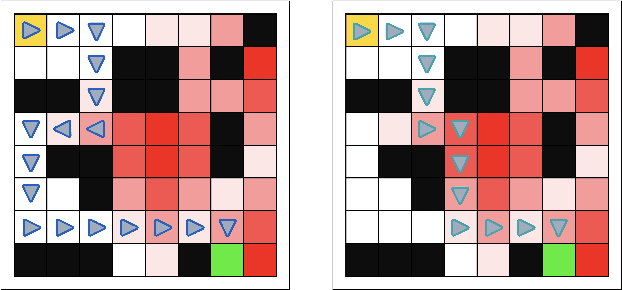
We anticipate increased instances of humans and AI systems working together in what we refer to as a hybrid team. The increase in collaboration is expected as AI systems gain proficiency and their adoption becomes more widespread. However, their behavior is not error-free, making hybrid teams a very suitable solution. As such, we consider methods for improving performance for these teams of humans and AI systems. For hybrid teams, we will refer to both the humans and AI systems as agents. To improve team performance over that seen for agents operating individually, we propose a manager which learns, through a standard Reinforcement Learning scheme, how to best delegate, over time, the responsibility of taking a decision to any of the agents. We further guide the manager's learning so they also minimize how many changes in delegation are made resulting from undesirable team behavior. We demonstrate the optimality of our manager's performance in several grid environments which include failure states which terminate an episode and should be avoided. We perform our experiments with teams of agents with varying degrees of acceptable risk, in the form of proximity to a failure state, and measure the manager's ability to make effective delegation decisions with respect to its own risk-based constraints, then compare these to the optimal decisions. Our results show our manager can successfully learn desirable delegations which result in team paths near/exactly optimal with respect to path length and number of delegations.