 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Revisiting Wright: Improving supervised classification of rat ultrasonic vocalisations using synthetic training data
Mar 03, 2023

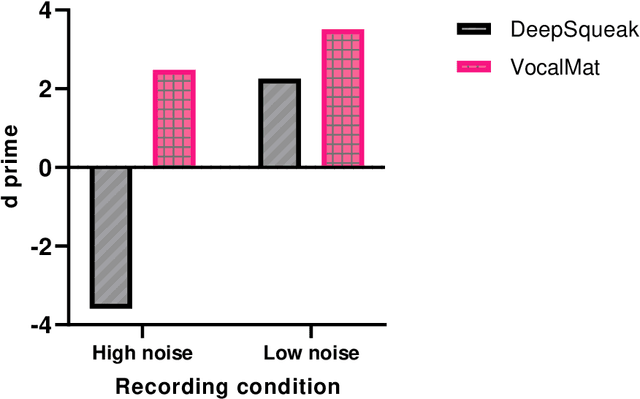
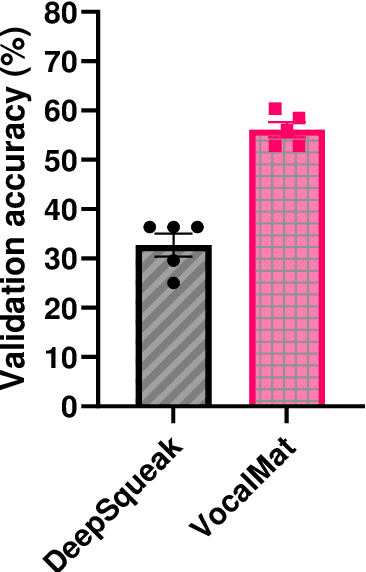
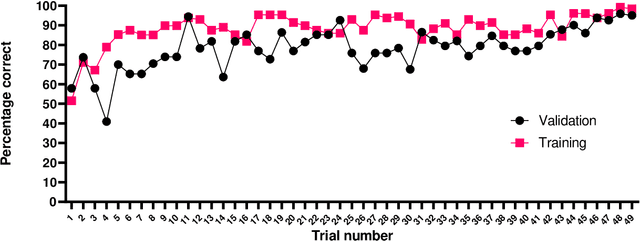
Rodents communicate through ultrasonic vocalizations (USVs). These calls are of interest because they provide insight into the development and function of vocal communication, and may prove to be useful as a biomarker for dysfunction in models of neurodevelopmental disorders. Rodent USVs can be categorised into different components and while manual classification is time consuming, advances in neural computing have allowed for fast and accurate identification and classification. Here, we adapt a convolutional neural network (CNN), VocalMat, created for analysing mice USVs, for use with rats. We codify a modified schema, adapted from that previously proposed by Wright et al. (2010), for classification, and compare the performance of our adaptation of VocalMat with a benchmark CNN, DeepSqueak. Additionally, we test the effect of inserting synthetic USVs into the training data of our classification network in order to reduce the workload involved in generating a training set. Our results show that the modified VocalMat outperformed the benchmark software on measures of both call identification, and classification. Additionally, we found that the augmentation of training data with synthetic images resulted in a marked improvement in the accuracy of VocalMat when it was subsequently used to analyse novel data. The resulting accuracy on the modified Wright categorizations was sufficiently high to allow for the application of this software in rat USV classification in laboratory conditions. Our findings also show that inserting synthetic USV calls into the training set leads to improvements in accuracy with little extra time-cost.
MixVPR: Feature Mixing for Visual Place Recognition
Mar 03, 2023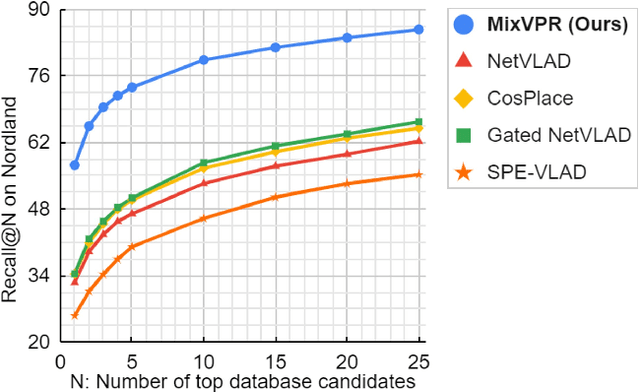
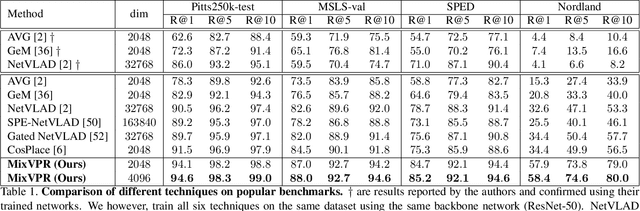
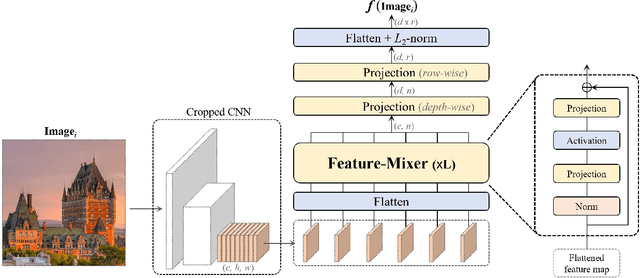
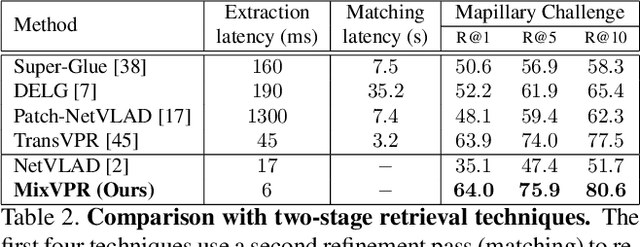
Visual Place Recognition (VPR) is a crucial part of mobile robotics and autonomous driving as well as other computer vision tasks. It refers to the process of identifying a place depicted in a query image using only computer vision. At large scale, repetitive structures, weather and illumination changes pose a real challenge, as appearances can drastically change over time. Along with tackling these challenges, an efficient VPR technique must also be practical in real-world scenarios where latency matters. To address this, we introduce MixVPR, a new holistic feature aggregation technique that takes feature maps from pre-trained backbones as a set of global features. Then, it incorporates a global relationship between elements in each feature map in a cascade of feature mixing, eliminating the need for local or pyramidal aggregation as done in NetVLAD or TransVPR. We demonstrate the effectiveness of our technique through extensive experiments on multiple large-scale benchmarks. Our method outperforms all existing techniques by a large margin while having less than half the number of parameters compared to CosPlace and NetVLAD. We achieve a new all-time high recall@1 score of 94.6% on Pitts250k-test, 88.0% on MapillarySLS, and more importantly, 58.4% on Nordland. Finally, our method outperforms two-stage retrieval techniques such as Patch-NetVLAD, TransVPR and SuperGLUE all while being orders of magnitude faster. Our code and trained models are available at https://github.com/amaralibey/MixVPR.
Time Minimization in Hierarchical Federated Learning
Oct 07, 2022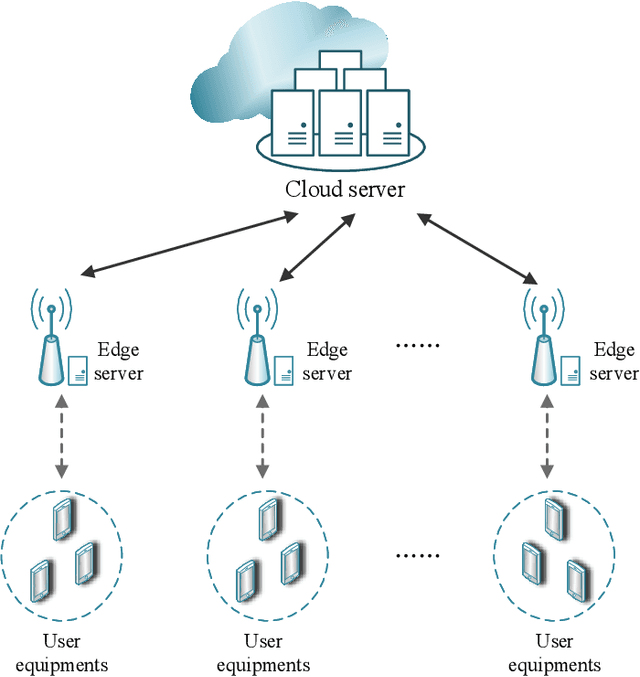
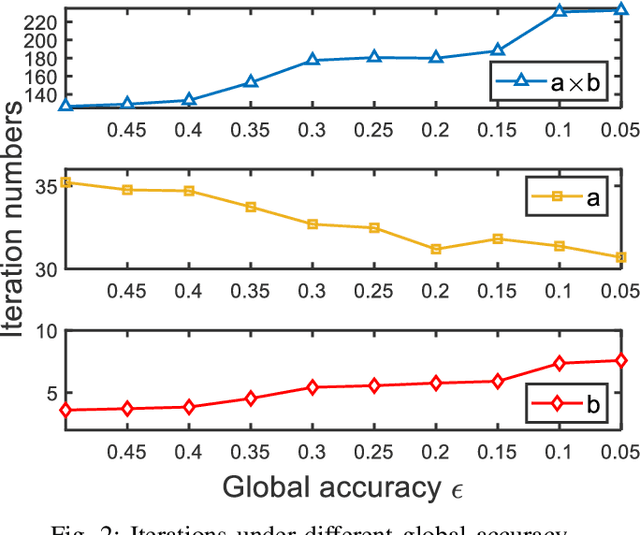
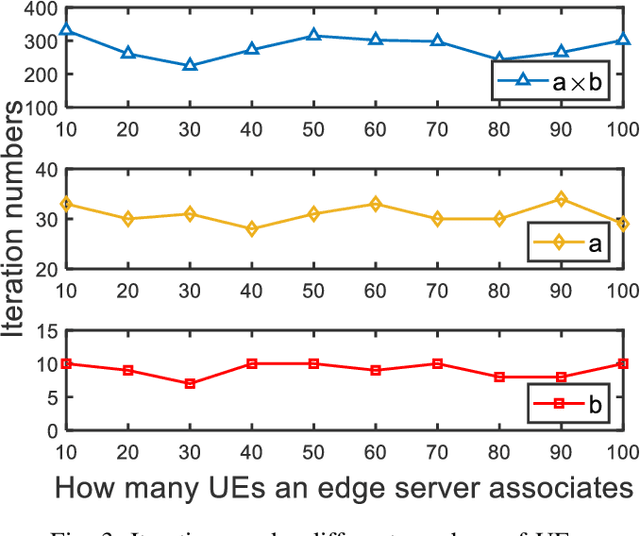
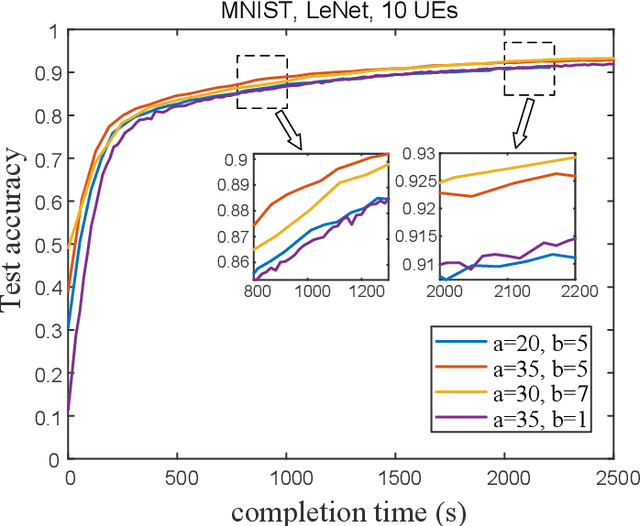
Federated Learning is a modern decentralized machine learning technique where user equipments perform machine learning tasks locally and then upload the model parameters to a central server. In this paper, we consider a 3-layer hierarchical federated learning system which involves model parameter exchanges between the cloud and edge servers, and the edge servers and user equipment. In a hierarchical federated learning model, delay in communication and computation of model parameters has a great impact on achieving a predefined global model accuracy. Therefore, we formulate a joint learning and communication optimization problem to minimize total model parameter communication and computation delay, by optimizing local iteration counts and edge iteration counts. To solve the problem, an iterative algorithm is proposed. After that, a time-minimized UE-to-edge association algorithm is presented where the maximum latency of the system is reduced. Simulation results show that the global model converges faster under optimal edge server and local iteration counts. The hierarchical federated learning latency is minimized with the proposed UE-to-edge association strategy.
Safe peeling for l0-regularized least-squares with supplementary material
Mar 03, 2023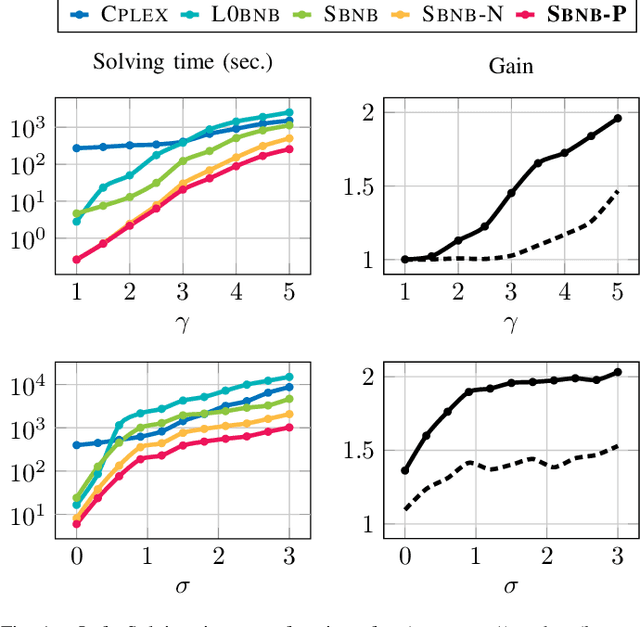
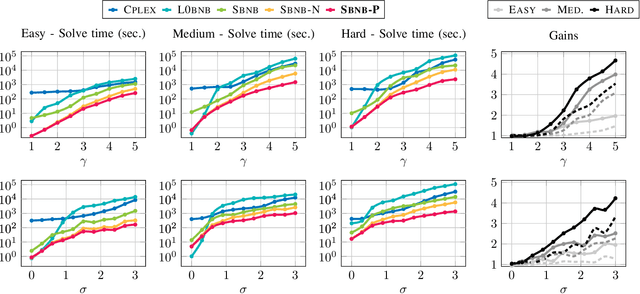
We introduce a new methodology dubbed ``safe peeling'' to accelerate the resolution of L0-regularized least-squares problems via a Branch-and-Bound (BnB) algorithm. Our procedure enables to tighten the convex relaxation considered at each node of the BnB decision tree and therefore potentially allows for more aggressive pruning. Numerical simulations show that our proposed methodology leads to significant gains in terms of number of nodes explored and overall solving time.s show that our proposed methodology leads to significant gains in terms of number of nodes explored and overall solving time.
Digital staining in optical microscopy using deep learning -- a review
Mar 14, 2023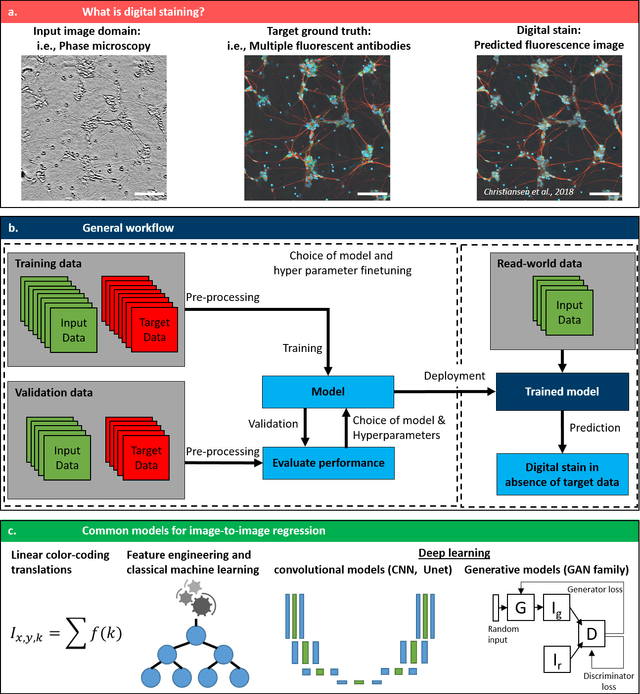
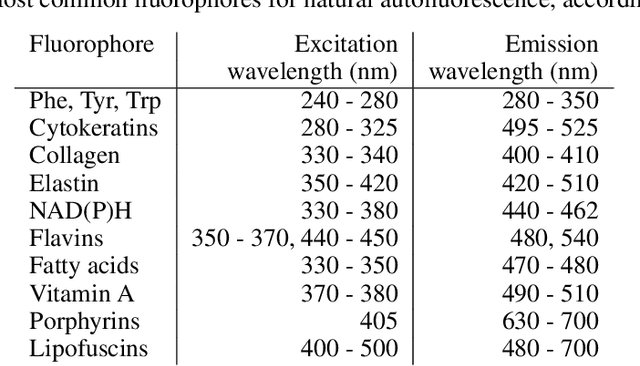
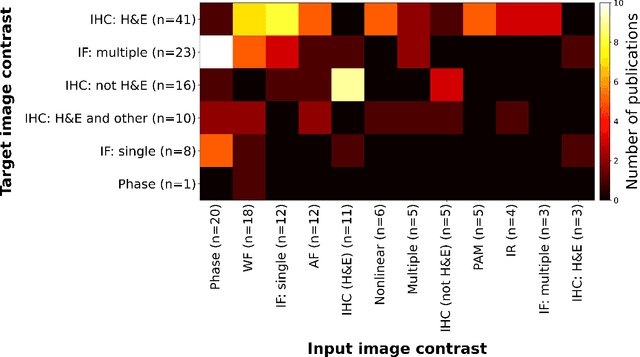

Until recently, conventional biochemical staining had the undisputed status as well-established benchmark for most biomedical problems related to clinical diagnostics, fundamental research and biotechnology. Despite this role as gold-standard, staining protocols face several challenges, such as a need for extensive, manual processing of samples, substantial time delays, altered tissue homeostasis, limited choice of contrast agents for a given sample, 2D imaging instead of 3D tomography and many more. Label-free optical technologies, on the other hand, do not rely on exogenous and artificial markers, by exploiting intrinsic optical contrast mechanisms, where the specificity is typically less obvious to the human observer. Over the past few years, digital staining has emerged as a promising concept to use modern deep learning for the translation from optical contrast to established biochemical contrast of actual stainings. In this review article, we provide an in-depth analysis of the current state-of-the-art in this field, suggest methods of good practice, identify pitfalls and challenges and postulate promising advances towards potential future implementations and applications.
SAILOR: Perceptual Anchoring For Robotic Cognitive Architectures
Mar 14, 2023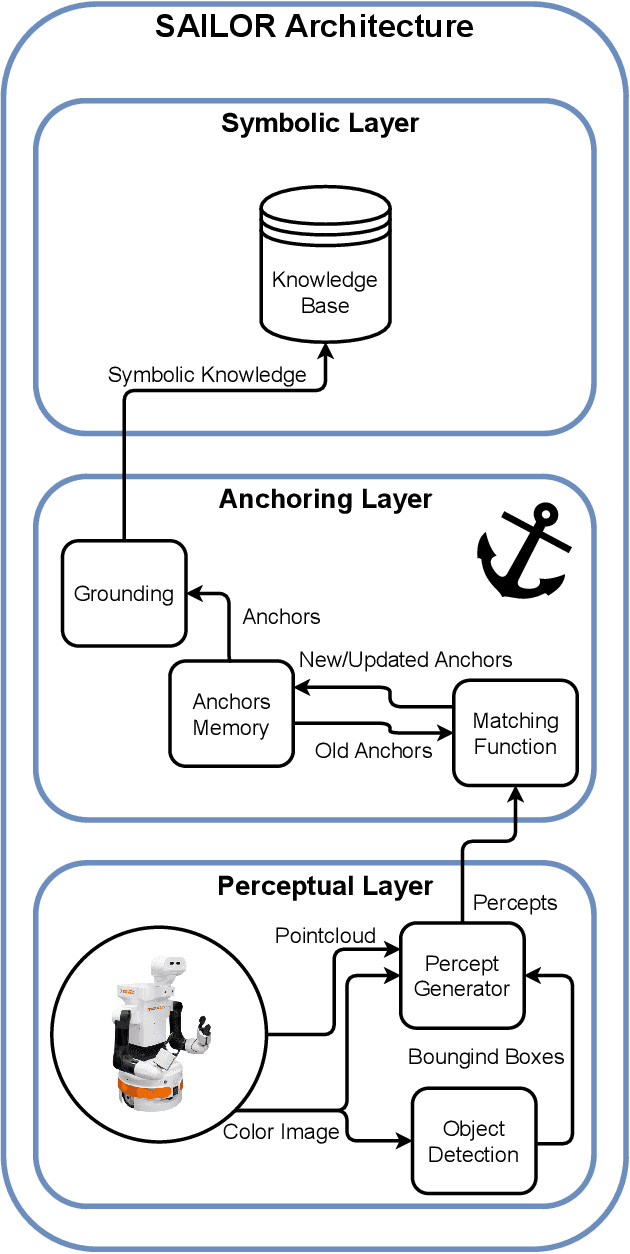
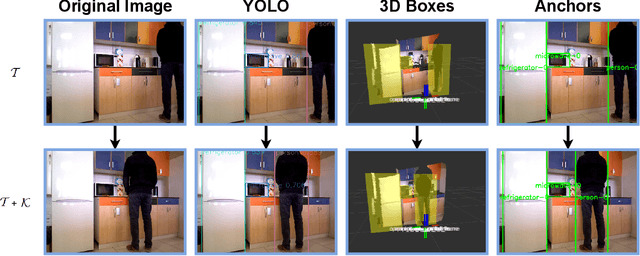
Symbolic anchoring is a crucial problem in the field of robotics, as it enables robots to obtain symbolic knowledge from the perceptual information acquired through their sensors. In cognitive-based robots, this process of processing sub-symbolic data from real-world sensors to obtain symbolic knowledge is still an open problem. To address this issue, this paper presents SAILOR, a framework for providing symbolic anchoring in ROS 2 ecosystem. SAILOR aims to maintain the link between symbolic data and perceptual data in real robots over time. It provides a semantic world modeling approach using two deep learning-based sub-symbolic robotic skills: object recognition and matching function. The object recognition skill allows the robot to recognize and identify objects in its environment, while the matching function enables the robot to decide if new perceptual data corresponds to existing symbolic data. This paper provides a description of the framework, the pipeline and development as well as its integration in MERLIN2, a hybrid cognitive architecture fully functional in robots running ROS 2.
Comfortable Priority Handling with Predictive Velocity Optimization for Intersection Crossings
Mar 14, 2023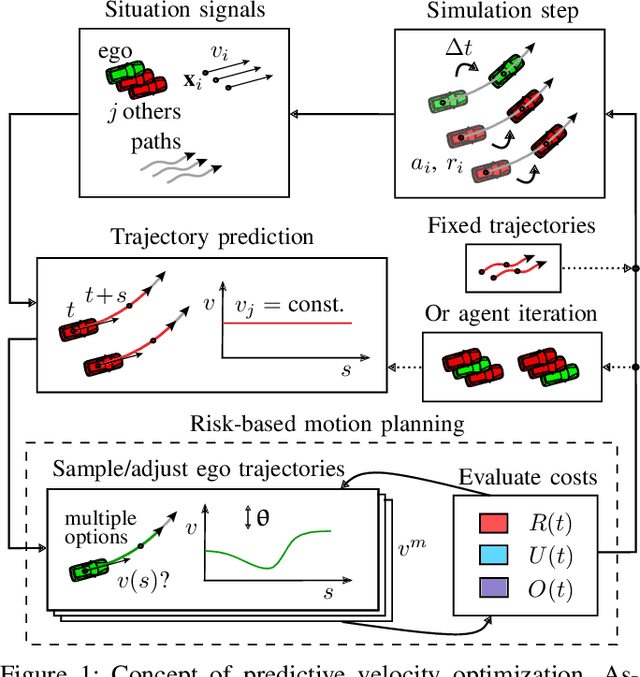
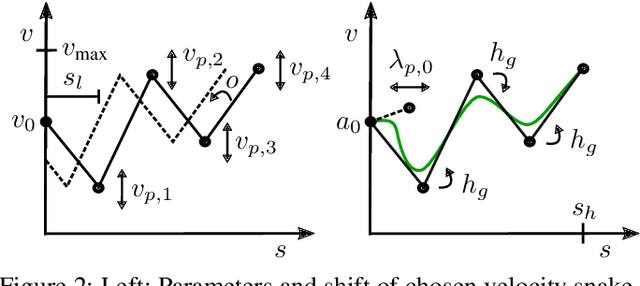
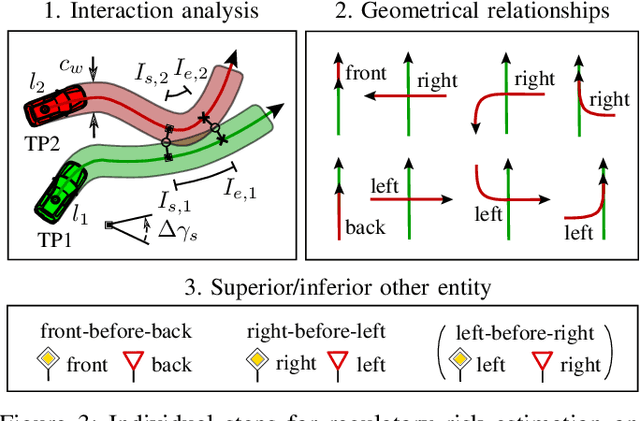
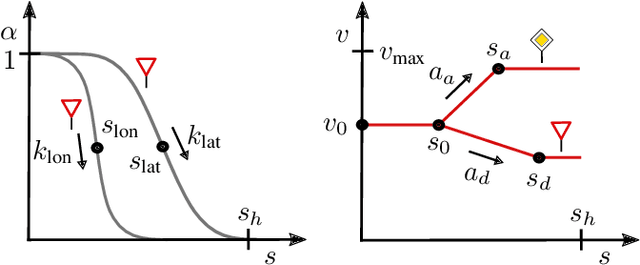
We address the problem of motion planning for four-way intersection crossings with right-of-ways. Road safety typically assigns liability to the follower in rear-end collisions and to the approaching vehicle required to yield in side crashes. As an alternative to previous models based on heuristic state machines, we propose a planning framework which changes the prediction model of other cars (e.g. their prototypical accelerations and decelerations) depending on the given longitudinal or lateral priority rules. Combined with a state-of-the-art trajectory optimization approach ROPT (Risk Optimization Method) this allows to find ego velocity profiles minimizing risks from curves and all involved vehicles while maximizing utility (needed time to arrive at a goal) and comfort (change and duration of acceleration) under the presence of regulatory conditions. Analytical and statistical evaluations show that our method is able to follow right-of-ways for a wide range of other vehicle behaviors and path geometries. Even when the other cars drive in a non-priority-compliant way, ROPT achieves good risk-comfort tradeoffs.
Moderate Adaptive Linear Units (MoLU)
Feb 28, 2023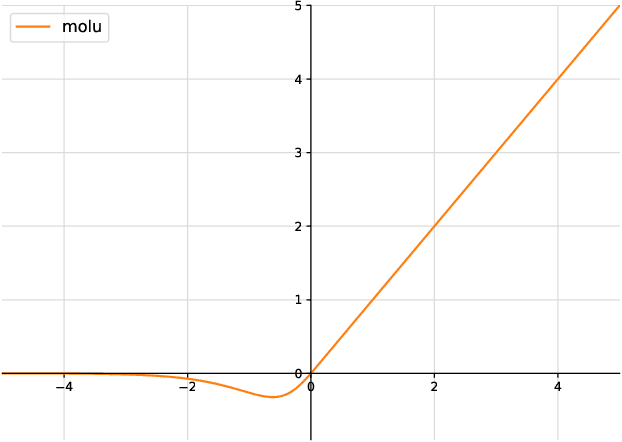
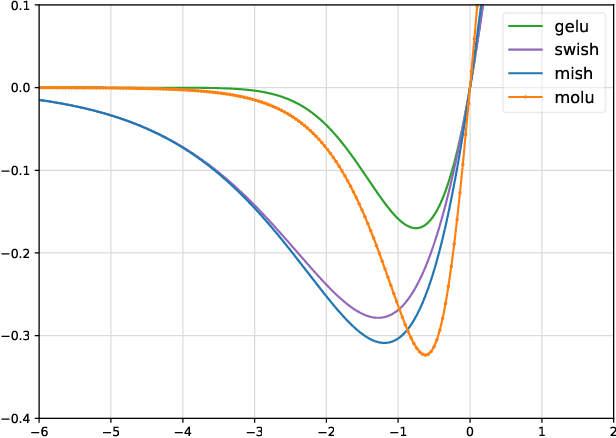
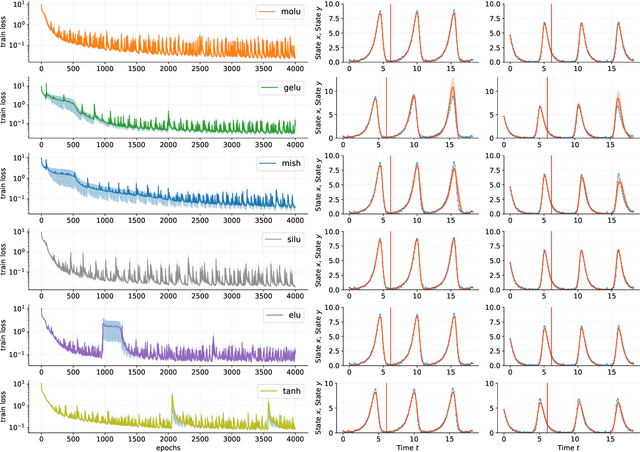
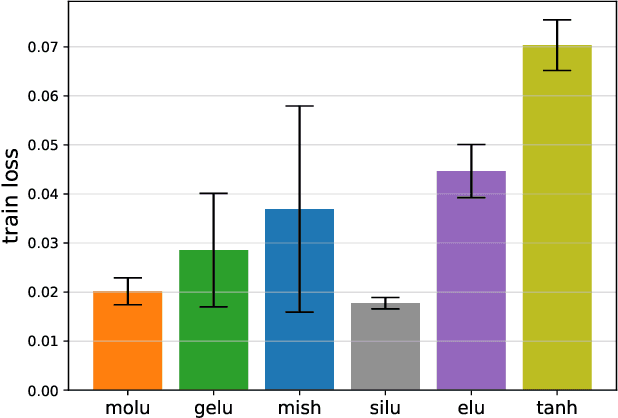
We propose a new high-performance activation function, Moderate Adaptive Linear Units (MoLU), for the deep neural network. The MoLU is a simple, beautiful and powerful activation function that can be a good main activation function among hundreds of activation functions. Because the MoLU is made up of the elementary functions, not only it is a infinite diffeomorphism (i.e. smooth and infinitely differentiable over whole domains), but also it decreases training time.
Less is More: Reducing Task and Model Complexity for 3D Point Cloud Semantic Segmentation
Mar 20, 2023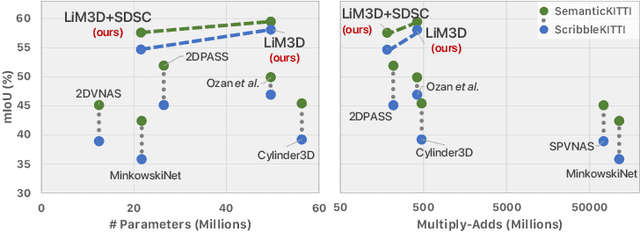
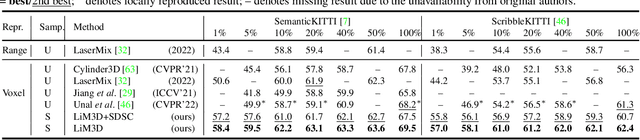
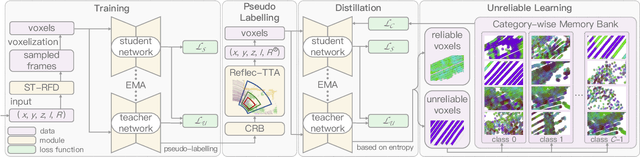
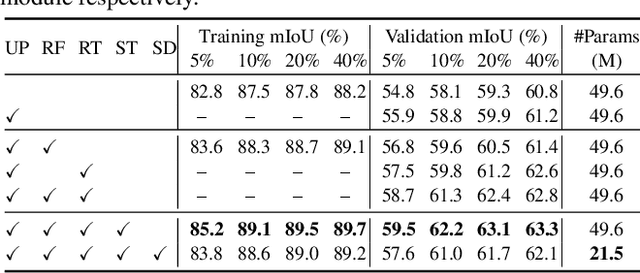
Whilst the availability of 3D LiDAR point cloud data has significantly grown in recent years, annotation remains expensive and time-consuming, leading to a demand for semi-supervised semantic segmentation methods with application domains such as autonomous driving. Existing work very often employs relatively large segmentation backbone networks to improve segmentation accuracy, at the expense of computational costs. In addition, many use uniform sampling to reduce ground truth data requirements for learning needed, often resulting in sub-optimal performance. To address these issues, we propose a new pipeline that employs a smaller architecture, requiring fewer ground-truth annotations to achieve superior segmentation accuracy compared to contemporary approaches. This is facilitated via a novel Sparse Depthwise Separable Convolution module that significantly reduces the network parameter count while retaining overall task performance. To effectively sub-sample our training data, we propose a new Spatio-Temporal Redundant Frame Downsampling (ST-RFD) method that leverages knowledge of sensor motion within the environment to extract a more diverse subset of training data frame samples. To leverage the use of limited annotated data samples, we further propose a soft pseudo-label method informed by LiDAR reflectivity. Our method outperforms contemporary semi-supervised work in terms of mIoU, using less labeled data, on the SemanticKITTI (59.5@5%) and ScribbleKITTI (58.1@5%) benchmark datasets, based on a 2.3x reduction in model parameters and 641x fewer multiply-add operations whilst also demonstrating significant performance improvement on limited training data (i.e., Less is More).