 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Deep probabilistic model for lossless scalable point cloud attribute compression
Mar 11, 2023
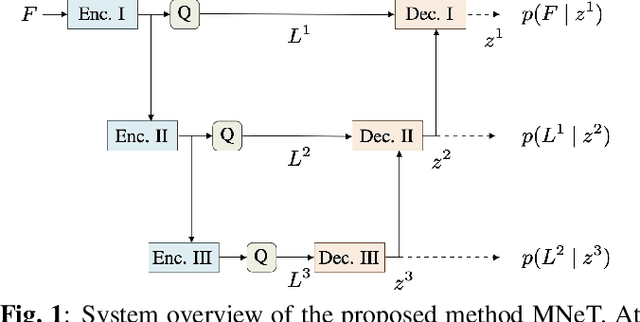
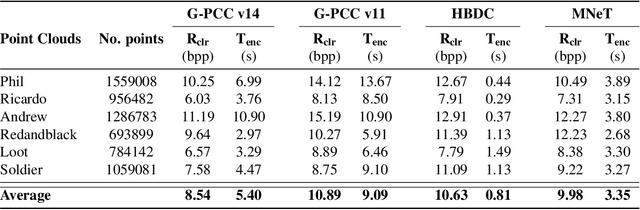
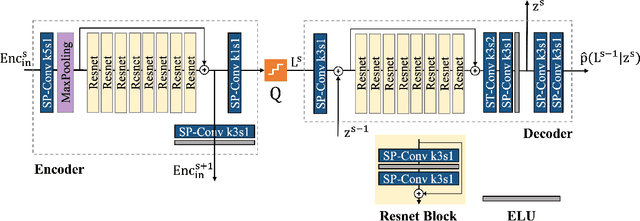

In recent years, several point cloud geometry compression methods that utilize advanced deep learning techniques have been proposed, but there are limited works on attribute compression, especially lossless compression. In this work, we build an end-to-end multiscale point cloud attribute coding method (MNeT) that progressively projects the attributes onto multiscale latent spaces. The multiscale architecture provides an accurate context for the attribute probability modeling and thus minimizes the coding bitrate with a single network prediction. Besides, our method allows scalable coding that lower quality versions can be easily extracted from the losslessly compressed bitstream. We validate our method on a set of point clouds from MVUB and MPEG and show that our method outperforms recently proposed methods and on par with the latest G-PCC version 14. Besides, our coding time is substantially faster than G-PCC.
Knowledge Distillation for Efficient Sequences of Training Runs
Mar 11, 2023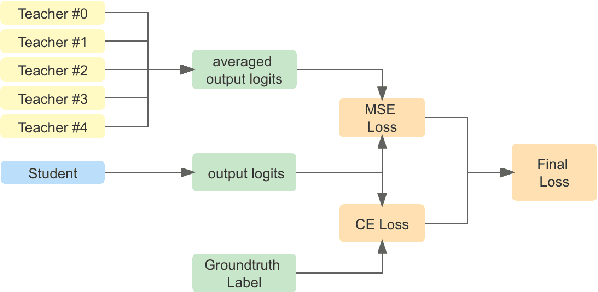
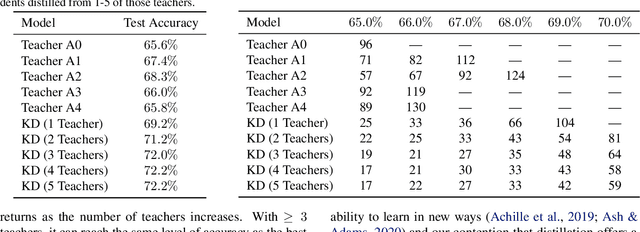
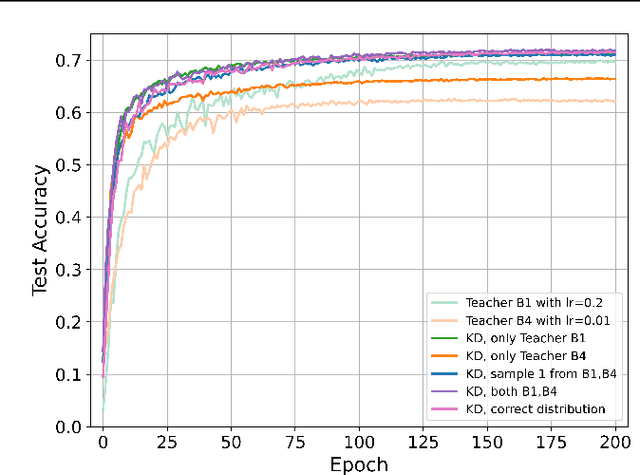
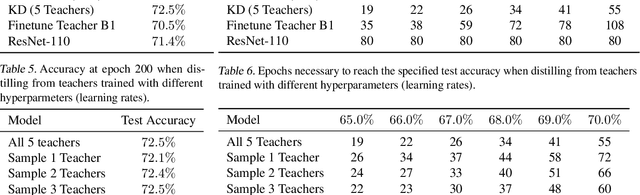
In many practical scenarios -- like hyperparameter search or continual retraining with new data -- related training runs are performed many times in sequence. Current practice is to train each of these models independently from scratch. We study the problem of exploiting the computation invested in previous runs to reduce the cost of future runs using knowledge distillation (KD). We find that augmenting future runs with KD from previous runs dramatically reduces the time necessary to train these models, even taking into account the overhead of KD. We improve on these results with two strategies that reduce the overhead of KD by 80-90% with minimal effect on accuracy and vast pareto-improvements in overall cost. We conclude that KD is a promising avenue for reducing the cost of the expensive preparatory work that precedes training final models in practice.
Improved automated lesion segmentation in whole-body FDG/PET-CT via Test-Time Augmentation
Oct 14, 2022
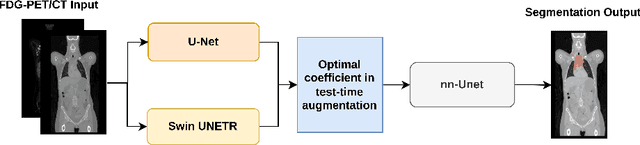
Numerous oncology indications have extensively quantified metabolically active tumors using positron emission tomography (PET) and computed tomography (CT). F-fluorodeoxyglucose-positron emission tomography (FDG-PET) is frequently utilized in clinical practice and clinical drug research to detect and measure metabolically active malignancies. The assessment of tumor burden using manual or computer-assisted tumor segmentation in FDG-PET images is widespread. Deep learning algorithms have also produced effective solutions in this area. However, there may be a need to improve the performance of a pre-trained deep learning network without the opportunity to modify this network. We investigate the potential benefits of test-time augmentation for segmenting tumors from PET-CT pairings. We applied a new framework of multilevel and multimodal tumor segmentation techniques that can simultaneously consider PET and CT data. In this study, we improve the network using a learnable composition of test time augmentations. We trained U-Net and Swin U-Netr on the training database to determine how different test time augmentation improved segmentation performance. We also developed an algorithm that finds an optimal test time augmentation contribution coefficient set. Using the newly trained U-Net and Swin U-Netr results, we defined an optimal set of coefficients for test-time augmentation and utilized them in combination with a pre-trained fixed nnU-Net. The ultimate idea is to improve performance at the time of testing when the model is fixed. Averaging the predictions with varying ratios on the augmented data can improve prediction accuracy. Our code will be available at \url{https://github.com/sepidehamiri/pet\_seg\_unet}
Aligned Diffusion Schrödinger Bridges
Feb 22, 2023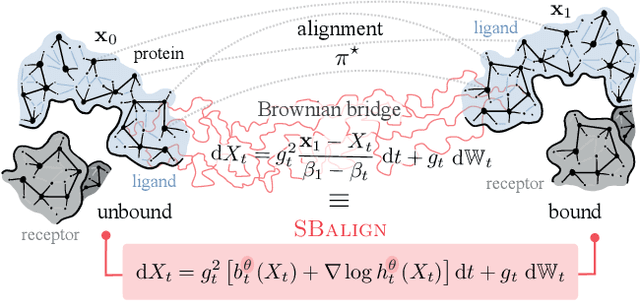
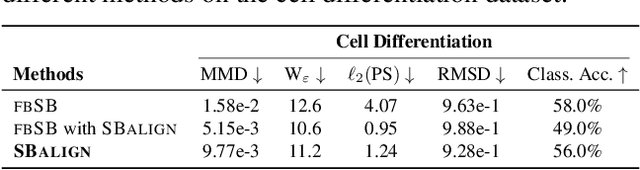
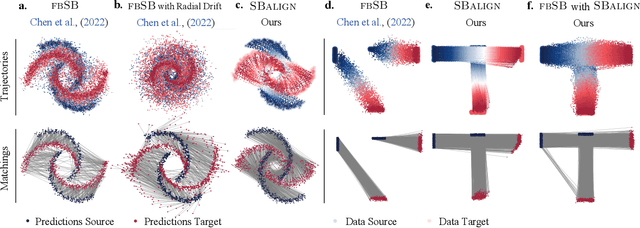
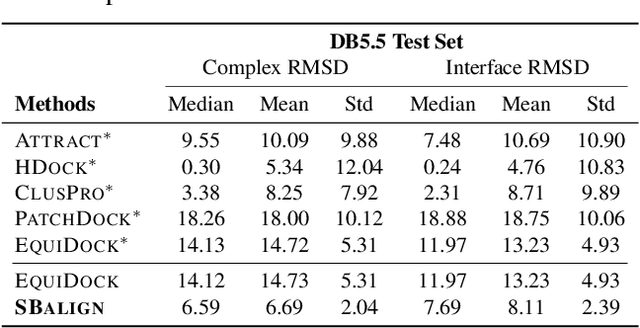
Diffusion Schr\"odinger bridges (DSB) have recently emerged as a powerful framework for recovering stochastic dynamics via their marginal observations at different time points. Despite numerous successful applications, existing algorithms for solving DSBs have so far failed to utilize the structure of aligned data, which naturally arises in many biological phenomena. In this paper, we propose a novel algorithmic framework that, for the first time, solves DSBs while respecting the data alignment. Our approach hinges on a combination of two decades-old ideas: The classical Schr\"odinger bridge theory and Doob's $h$-transform. Compared to prior methods, our approach leads to a simpler training procedure with lower variance, which we further augment with principled regularization schemes. This ultimately leads to sizeable improvements across experiments on synthetic and real data, including the tasks of rigid protein docking and temporal evolution of cellular differentiation processes.
Retinal blood flow speed quantification at the capillary level using temporal autocorrelation fitting OCTA
Feb 22, 2023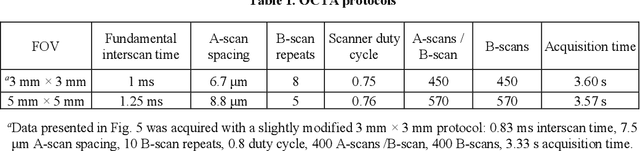
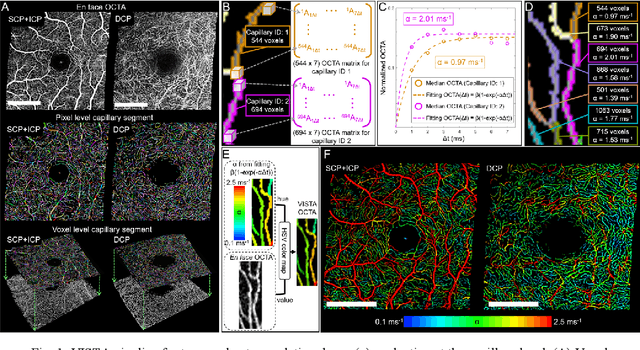
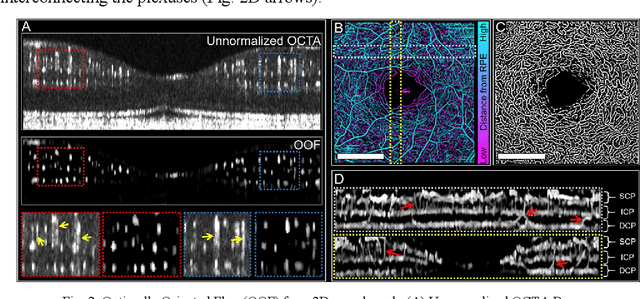
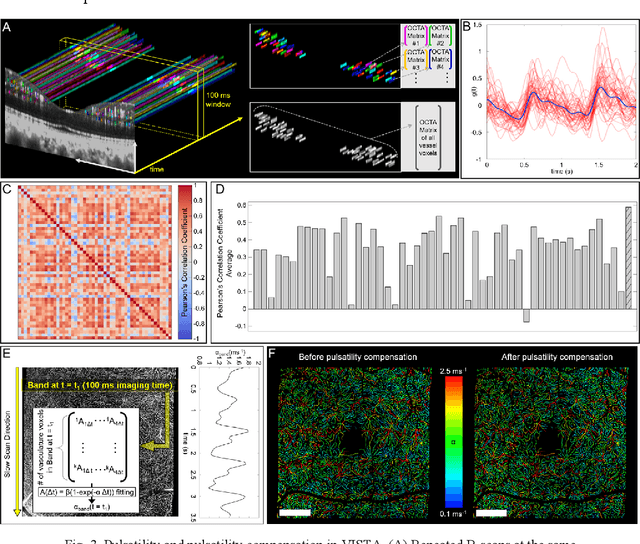
Optical coherence tomography angiography (OCTA) can visualize vasculature structures, but provides limited information about the blood flow speeds. Here, we present a second generation variable interscan time analysis (VISTA) OCTA, which evaluates a quantitative surrogate marker for blood flow speed in vasculature. At the capillary level, spatially compiled OCTA and a simple temporal autocorrelation model, {\rho}({\tau}) = exp(-{\alpha}{\tau}), were used to evaluate a temporal autocorrelation decay constant, {\alpha}, as the blood flow speed marker. A 600 kHz A-scan rate swept-source provides short interscan time OCTA and fine A-scan spacing acquisition, while maintaining multi mm2 field of views for human retinal imaging. We demonstrate the cardiac pulsatility and repeatability of {\alpha} measured with VISTA. We show different {\alpha} for different retinal capillary plexuses in healthy eyes and present representative VISTA OCTA of eyes with diabetic retinopathy.
Direct Embedding of Temporal Network Edges via Time-Decayed Line Graphs
Sep 30, 2022
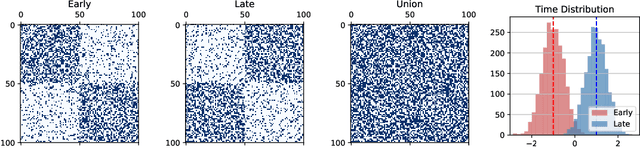
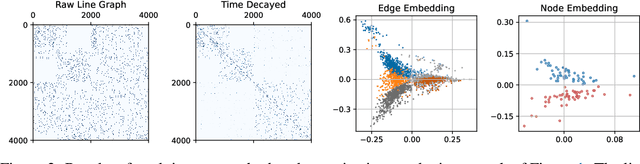
Temporal networks model a variety of important phenomena involving timed interactions between entities. Existing methods for machine learning on temporal networks generally exhibit at least one of two limitations. First, time is assumed to be discretized, so if the time data is continuous, the user must determine the discretization and discard precise time information. Second, edge representations can only be calculated indirectly from the nodes, which may be suboptimal for tasks like edge classification. We present a simple method that avoids both shortcomings: construct the line graph of the network, which includes a node for each interaction, and weigh the edges of this graph based on the difference in time between interactions. From this derived graph, edge representations for the original network can be computed with efficient classical methods. The simplicity of this approach facilitates explicit theoretical analysis: we can constructively show the effectiveness of our method's representations for a natural synthetic model of temporal networks. Empirical results on real-world networks demonstrate our method's efficacy and efficiency on both edge classification and temporal link prediction.
Fast Saturating Gate for Learning Long Time Scales with Recurrent Neural Networks
Oct 04, 2022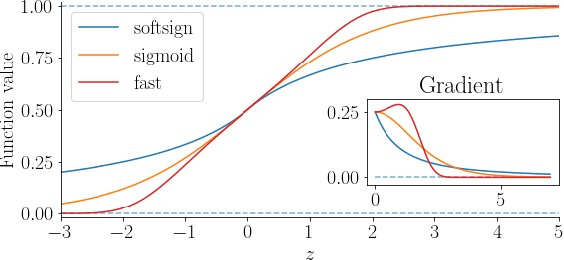

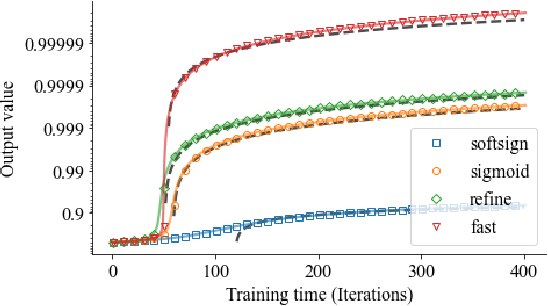
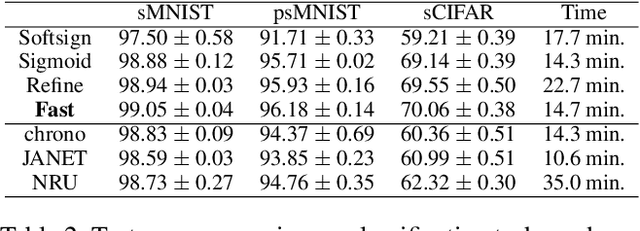
Gate functions in recurrent models, such as an LSTM and GRU, play a central role in learning various time scales in modeling time series data by using a bounded activation function. However, it is difficult to train gates to capture extremely long time scales due to gradient vanishing of the bounded function for large inputs, which is known as the saturation problem. We closely analyze the relation between saturation of the gate function and efficiency of the training. We prove that the gradient vanishing of the gate function can be mitigated by accelerating the convergence of the saturating function, i.e., making the output of the function converge to 0 or 1 faster. Based on the analysis results, we propose a gate function called fast gate that has a doubly exponential convergence rate with respect to inputs by simple function composition. We empirically show that our method outperforms previous methods in accuracy and computational efficiency on benchmark tasks involving extremely long time scales.
Delay Sensitive Hierarchical Federated Learning with Stochastic Local Updates
Feb 09, 2023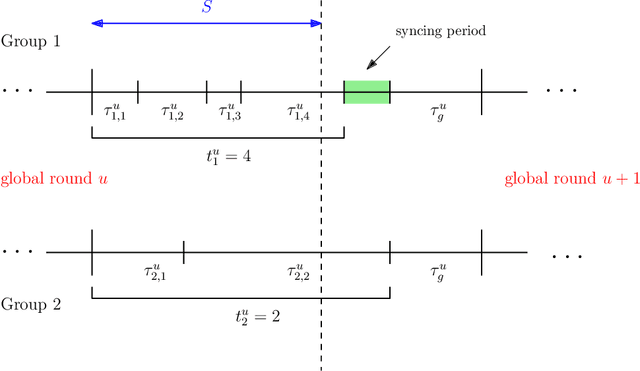
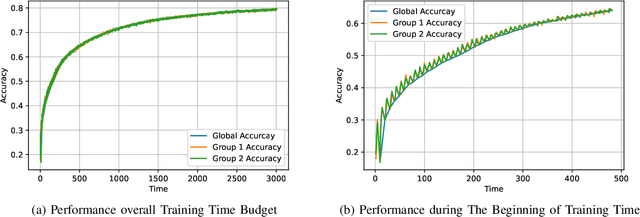
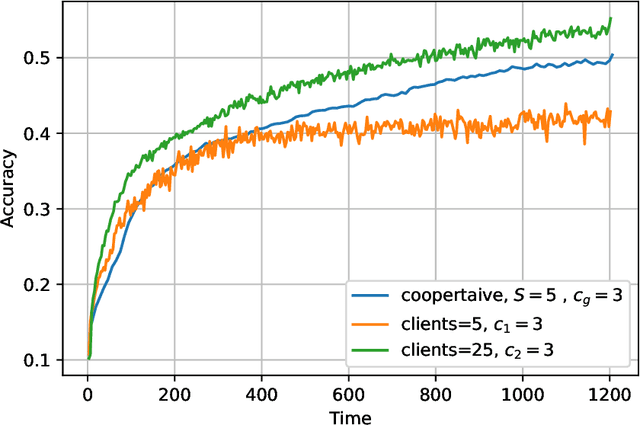
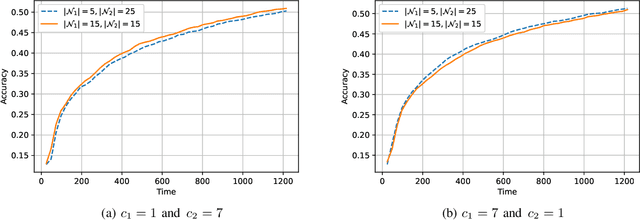
The impact of local averaging on the performance of federated learning (FL) systems is studied in the presence of communication delay between the clients and the parameter server. To minimize the effect of delay, clients are assigned into different groups, each having its own local parameter server (LPS) that aggregates its clients' models. The groups' models are then aggregated at a global parameter server (GPS) that only communicates with the LPSs. Such setting is known as hierarchical FL (HFL). Different from most works in the literature, the number of local and global communication rounds in our work is randomly determined by the (different) delays experienced by each group of clients. Specifically, the number of local averaging rounds are tied to a wall-clock time period coined the sync time $S$, after which the LPSs synchronize their models by sharing them with the GPS. Such sync time $S$ is then reapplied until a global wall-clock time is exhausted.
SLICT: Multi-input Multi-scale Surfel-Based Lidar-Inertial Continuous-Time Odometry and Mapping
Nov 09, 2022

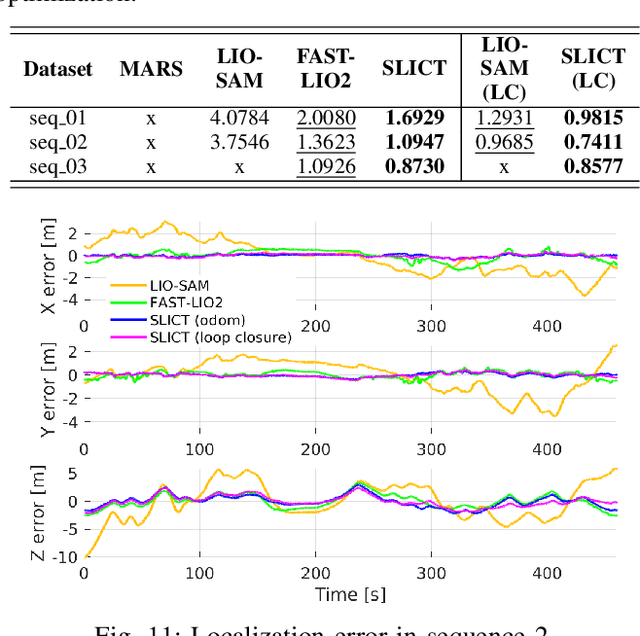
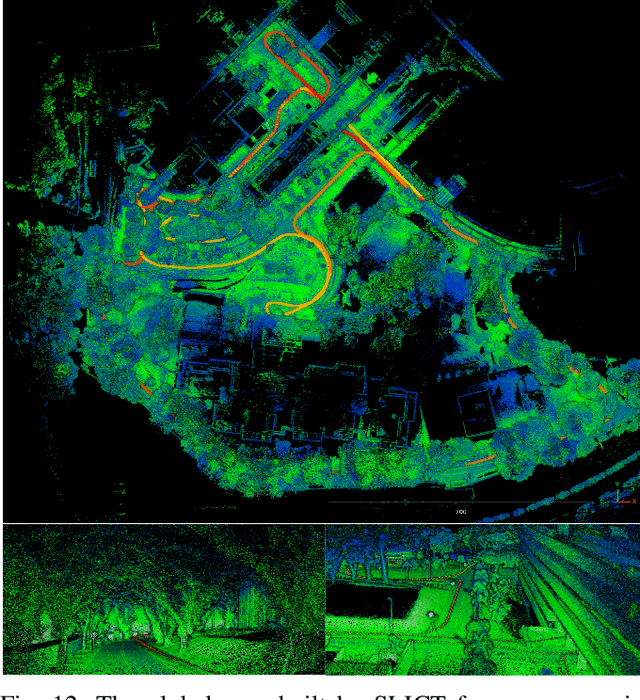
While feature association to a global map has significant benefits, to keep the computations from growing exponentially, most lidar-based odometry and mapping methods opt to associate features with local maps at one voxel scale. Taking advantage of the fact that surfels (surface elements) at different voxel scales can be organized in a tree-like structure, we propose an octree-based global map of multi-scale surfels that can be updated incrementally. This alleviates the need for recalculating, for example, a k-d tree of the whole map repeatedly. The system can also take input from a single or a number of sensors, reinforcing the robustness in degenerate cases. We also propose a point-to-surfel (PTS) association scheme, continuous-time optimization on PTS and IMU preintegration factors, along with loop closure and bundle adjustment, making a complete framework for Lidar-Inertial continuous-time odometry and mapping. Experiments on public and in-house datasets demonstrate the advantages of our system compared to other state-of-the-art methods. To benefit the community, we release the source code and dataset at https://github.com/brytsknguyen/slict.
PAAPLoss: A Phonetic-Aligned Acoustic Parameter Loss for Speech Enhancement
Feb 16, 2023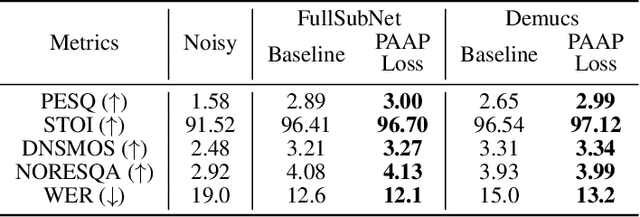
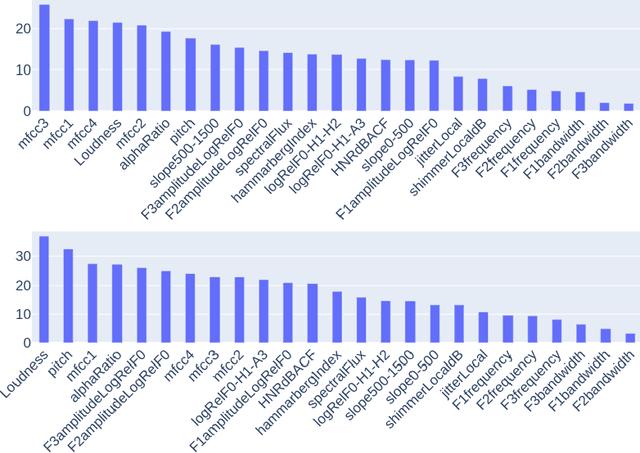
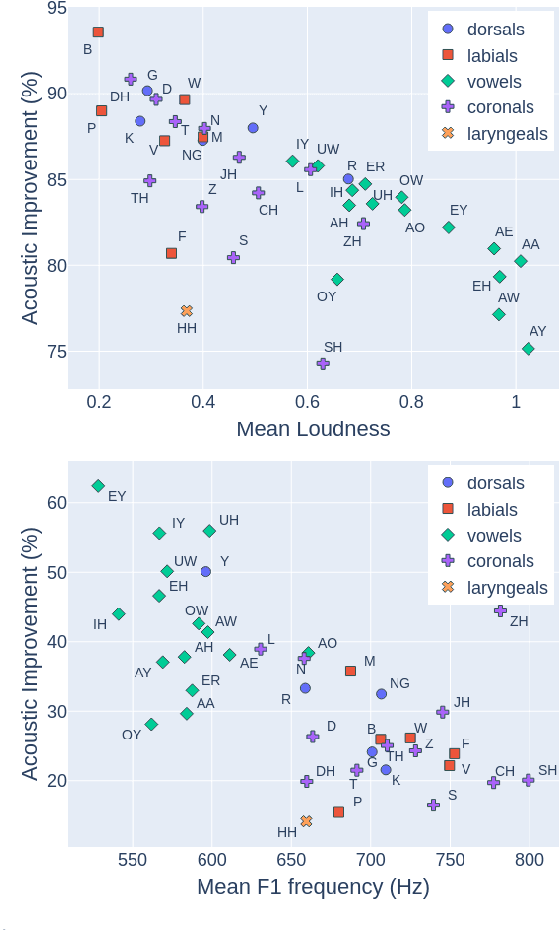
Despite rapid advancement in recent years, current speech enhancement models often produce speech that differs in perceptual quality from real clean speech. We propose a learning objective that formalizes differences in perceptual quality, by using domain knowledge of acoustic-phonetics. We identify temporal acoustic parameters -- such as spectral tilt, spectral flux, shimmer, etc. -- that are non-differentiable, and we develop a neural network estimator that can accurately predict their time-series values across an utterance. We also model phoneme-specific weights for each feature, as the acoustic parameters are known to show different behavior in different phonemes. We can add this criterion as an auxiliary loss to any model that produces speech, to optimize speech outputs to match the values of clean speech in these features. Experimentally we show that it improves speech enhancement workflows in both time-domain and time-frequency domain, as measured by standard evaluation metrics. We also provide an analysis of phoneme-dependent improvement on acoustic parameters, demonstrating the additional interpretability that our method provides. This analysis can suggest which features are currently the bottleneck for improvement.