 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Universal Fourier Attack for Time Series
Sep 02, 2022
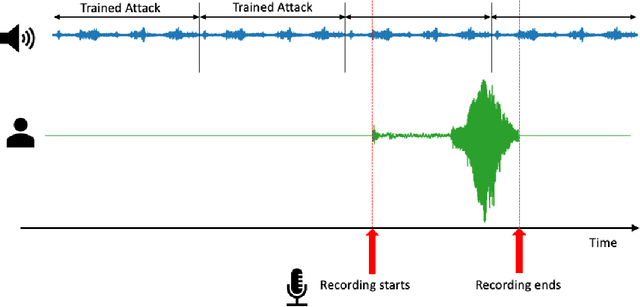
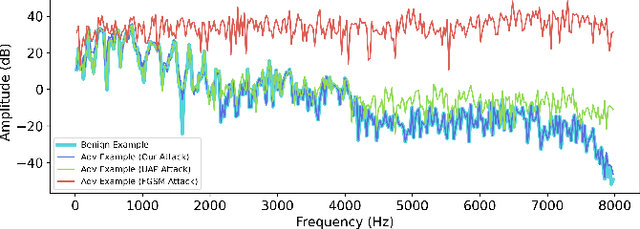
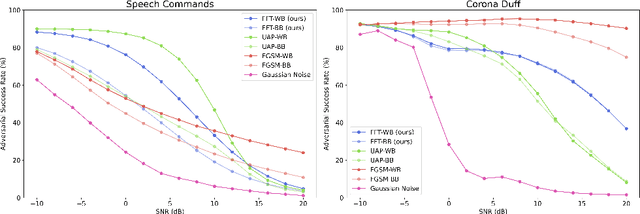
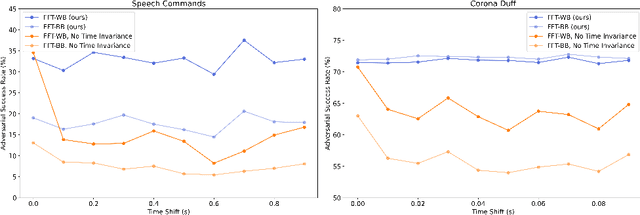
A wide variety of adversarial attacks have been proposed and explored using image and audio data. These attacks are notoriously easy to generate digitally when the attacker can directly manipulate the input to a model, but are much more difficult to implement in the real-world. In this paper we present a universal, time invariant attack for general time series data such that the attack has a frequency spectrum primarily composed of the frequencies present in the original data. The universality of the attack makes it fast and easy to implement as no computation is required to add it to an input, while time invariance is useful for real-world deployment. Additionally, the frequency constraint ensures the attack can withstand filtering. We demonstrate the effectiveness of the attack in two different domains, speech recognition and unintended radiated emission, and show that the attack is robust against common transform-and-compare defense pipelines.
Imbalance Knowledge-Driven Multi-modal Network for Land-Cover Semantic Segmentation Using Images and LiDAR Point Clouds
Mar 28, 2023

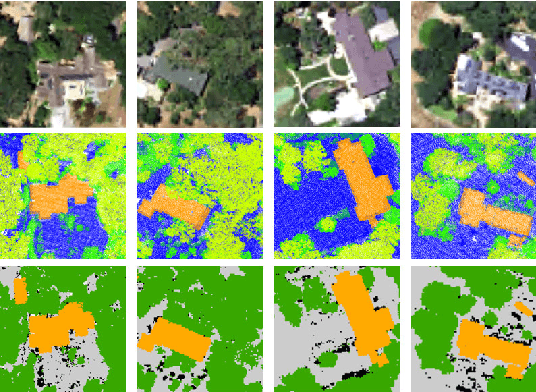
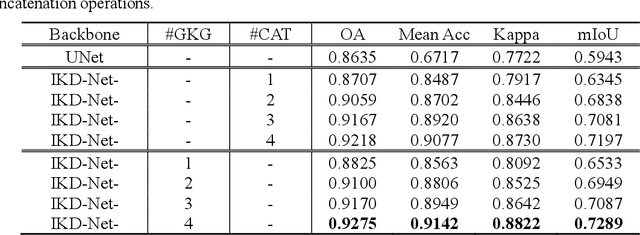
Despite the good results that have been achieved in unimodal segmentation, the inherent limitations of individual data increase the difficulty of achieving breakthroughs in performance. For that reason, multi-modal learning is increasingly being explored within the field of remote sensing. The present multi-modal methods usually map high-dimensional features to low-dimensional spaces as a preprocess before feature extraction to address the nonnegligible domain gap, which inevitably leads to information loss. To address this issue, in this paper we present our novel Imbalance Knowledge-Driven Multi-modal Network (IKD-Net) to extract features from raw multi-modal heterogeneous data directly. IKD-Net is capable of mining imbalance information across modalities while utilizing a strong modal to drive the feature map refinement of the weaker ones in the global and categorical perspectives by way of two sophisticated plug-and-play modules: the Global Knowledge-Guided (GKG) and Class Knowledge-Guided (CKG) gated modules. The whole network then is optimized using a holistic loss function. While we were developing IKD-Net, we also established a new dataset called the National Agriculture Imagery Program and 3D Elevation Program Combined dataset in California (N3C-California), which provides a particular benchmark for multi-modal joint segmentation tasks. In our experiments, IKD-Net outperformed the benchmarks and state-of-the-art methods both in the N3C-California and the small-scale ISPRS Vaihingen dataset. IKD-Net has been ranked first on the real-time leaderboard for the GRSS DFC 2018 challenge evaluation until this paper's submission.
Generative Modeling with Flow-Guided Density Ratio Learning
Mar 07, 2023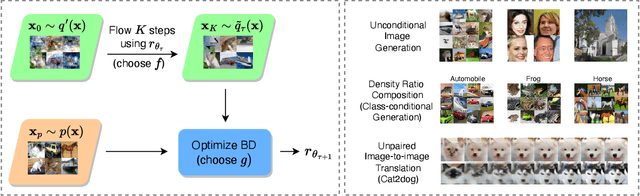

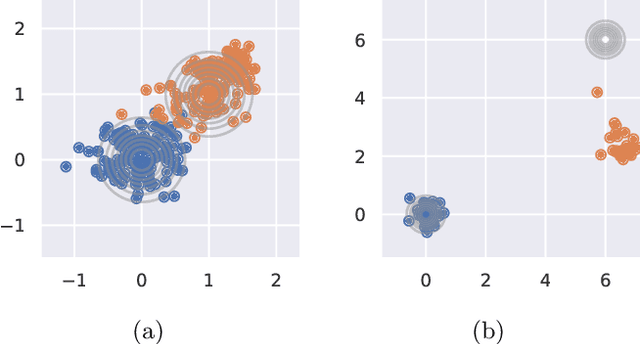
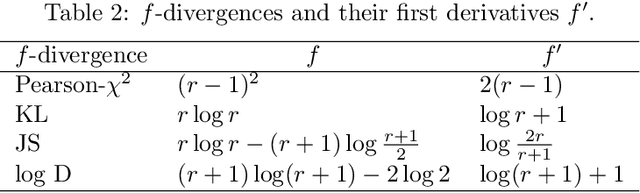
We present Flow-Guided Density Ratio Learning (FDRL), a simple and scalable approach to generative modeling which builds on the stale (time-independent) approximation of the gradient flow of entropy-regularized f-divergences introduced in DGflow. In DGflow, the intractable time-dependent density ratio is approximated by a stale estimator given by a GAN discriminator. This is sufficient in the case of sample refinement, where the source and target distributions of the flow are close to each other. However, this assumption is invalid for generation and a naive application of the stale estimator fails due to the large chasm between the two distributions. FDRL proposes to train a density ratio estimator such that it learns from progressively improving samples during the training process. We show that this simple method alleviates the density chasm problem, allowing FDRL to generate images of dimensions as high as $128\times128$, as well as outperform existing gradient flow baselines on quantitative benchmarks. We also show the flexibility of FDRL with two use cases. First, unconditional FDRL can be easily composed with external classifiers to perform class-conditional generation. Second, FDRL can be directly applied to unpaired image-to-image translation with no modifications needed to the framework. Code is publicly available at https://github.com/ajrheng/FDRL.
External Camera-based Mobile Robot Pose Estimation for Collaborative Perception with Smart Edge Sensors
Mar 07, 2023

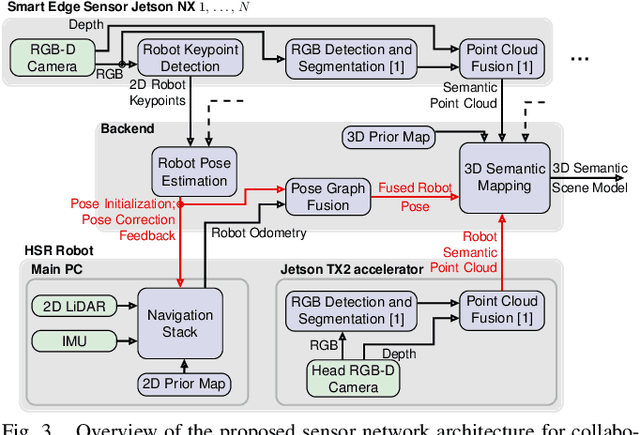
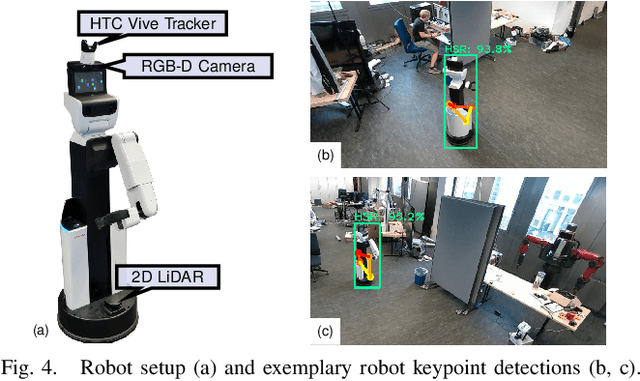
We present an approach for estimating a mobile robot's pose w.r.t. the allocentric coordinates of a network of static cameras using multi-view RGB images. The images are processed online, locally on smart edge sensors by deep neural networks to detect the robot and estimate 2D keypoints defined at distinctive positions of the 3D robot model. Robot keypoint detections are synchronized and fused on a central backend, where the robot's pose is estimated via multi-view minimization of reprojection errors. Through the pose estimation from external cameras, the robot's localization can be initialized in an allocentric map from a completely unknown state (kidnapped robot problem) and robustly tracked over time. We conduct a series of experiments evaluating the accuracy and robustness of the camera-based pose estimation compared to the robot's internal navigation stack, showing that our camera-based method achieves pose errors below 3 cm and 1{\deg} and does not drift over time, as the robot is localized allocentrically. With the robot's pose precisely estimated, its observations can be fused into the allocentric scene model. We show a real-world application, where observations from mobile robot and static smart edge sensors are fused to collaboratively build a 3D semantic map of a $\sim$240 m$^2$ indoor environment.
Do Machine Learning Models Learn Common Sense?
Mar 02, 2023
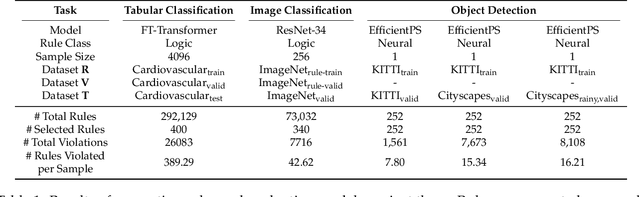
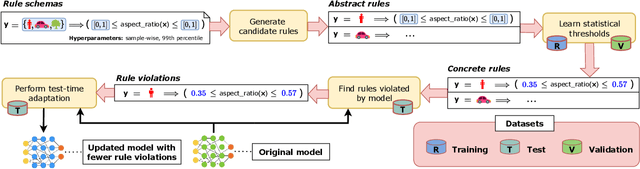

Machine learning models can make basic errors that are easily hidden within vast amounts of data. Such errors often run counter to human intuition referred to as "common sense". We thereby seek to characterize common sense for data-driven models, and quantify the extent to which a model has learned common sense. We propose a framework that integrates logic-based methods with statistical inference to derive common sense rules from a model's training data without supervision. We further show how to adapt models at test-time to reduce common sense rule violations and produce more coherent predictions. We evaluate our framework on datasets and models for three different domains. It generates around 250 to 300k rules over these datasets, and uncovers 1.5k to 26k violations of those rules by state-of-the-art models for the respective datasets. Test-time adaptation reduces these violations by up to 38% without impacting overall model accuracy.
GlucoSynth: Generating Differentially-Private Synthetic Glucose Traces
Mar 02, 2023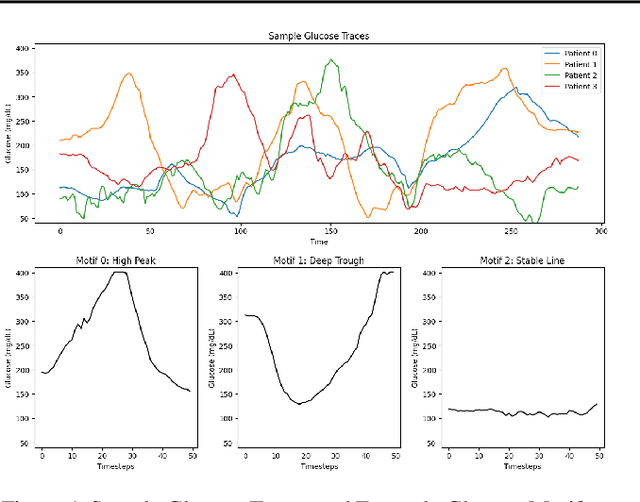
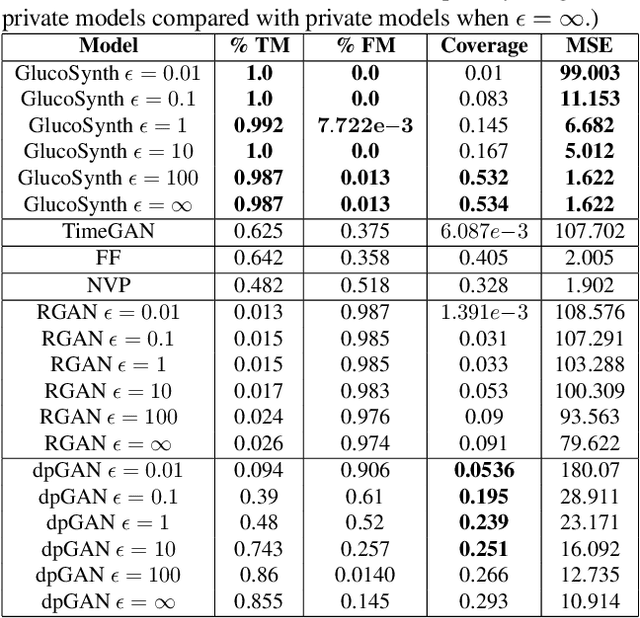
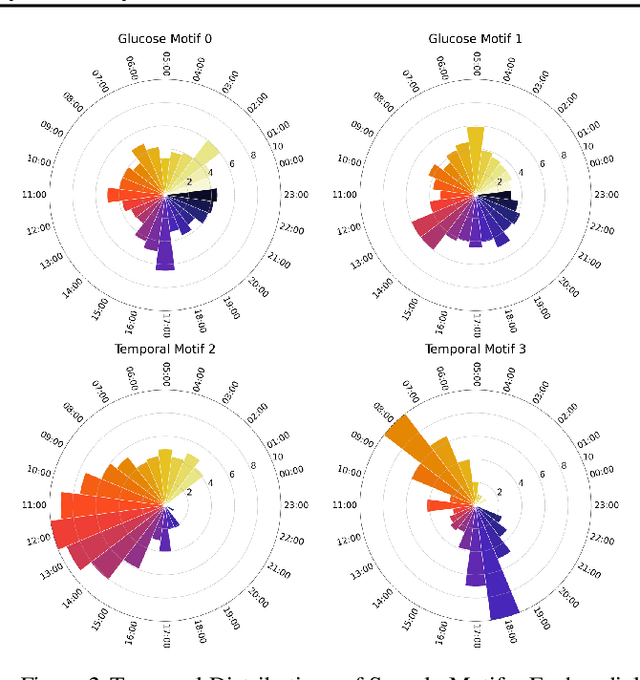
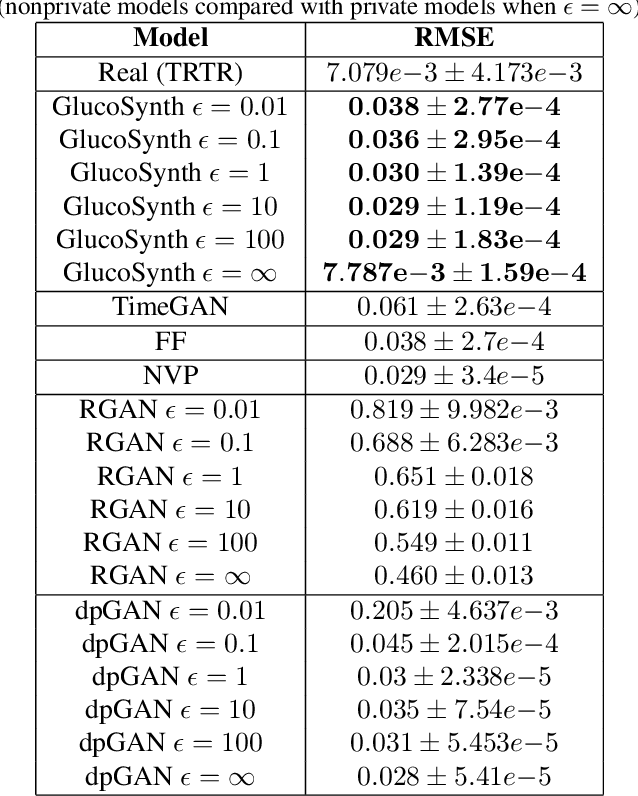
In this paper we focus on the problem of generating high-quality, private synthetic glucose traces, a task generalizable to many other time series sources. Existing methods for time series data synthesis, such as those using Generative Adversarial Networks (GANs), are not able to capture the innate characteristics of glucose data and, in terms of privacy, either do not include any formal privacy guarantees or, in order to uphold a strong formal privacy guarantee, severely degrade the utility of the synthetic data. Therefore, in this paper we present GlucoSynth, a novel privacy-preserving GAN framework to generate synthetic glucose traces. The core intuition in our approach is to conserve relationships amongst motifs (glucose events) within the traces, in addition to typical temporal dynamics. Moreover, we integrate differential privacy into the framework to provide strong formal privacy guarantees. Finally, we provide a comprehensive evaluation on the real-world utility of the data using 1.2 million glucose traces
FastViT: A Fast Hybrid Vision Transformer using Structural Reparameterization
Mar 24, 2023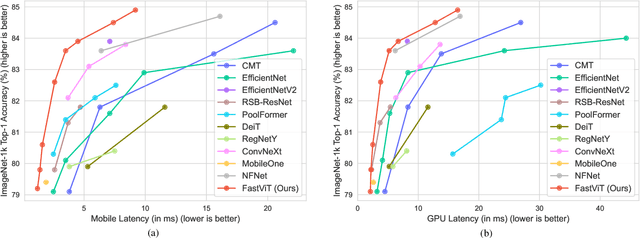
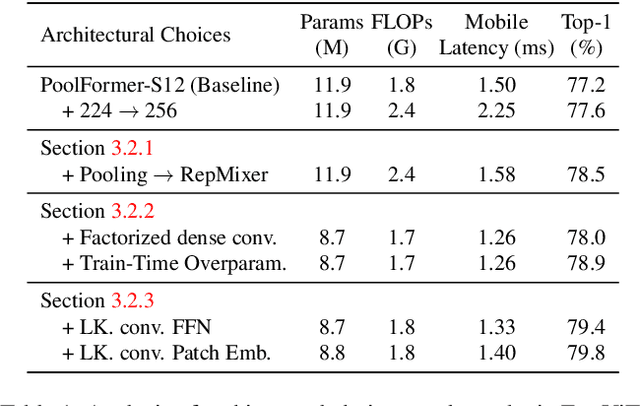
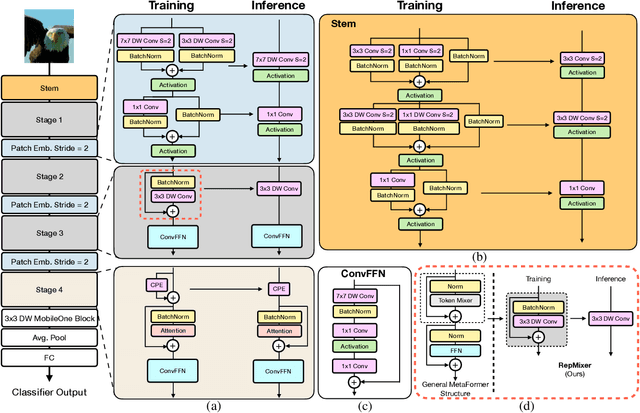
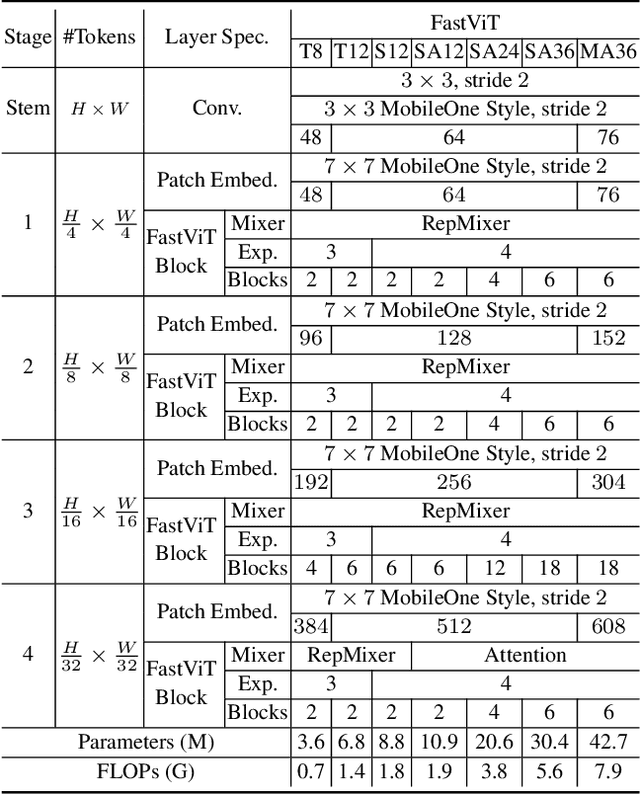
The recent amalgamation of transformer and convolutional designs has led to steady improvements in accuracy and efficiency of the models. In this work, we introduce FastViT, a hybrid vision transformer architecture that obtains the state-of-the-art latency-accuracy trade-off. To this end, we introduce a novel token mixing operator, RepMixer, a building block of FastViT, that uses structural reparameterization to lower the memory access cost by removing skip-connections in the network. We further apply train-time overparametrization and large kernel convolutions to boost accuracy and empirically show that these choices have minimal effect on latency. We show that - our model is 3.5x faster than CMT, a recent state-of-the-art hybrid transformer architecture, 4.9x faster than EfficientNet, and 1.9x faster than ConvNeXt on a mobile device for the same accuracy on the ImageNet dataset. At similar latency, our model obtains 4.2% better Top-1 accuracy on ImageNet than MobileOne. Our model consistently outperforms competing architectures across several tasks -- image classification, detection, segmentation and 3D mesh regression with significant improvement in latency on both a mobile device and a desktop GPU. Furthermore, our model is highly robust to out-of-distribution samples and corruptions, improving over competing robust models.
PreMa: Predictive Maintenance of Solenoid Valve in Real-Time at Embedded Edge-Level
Nov 21, 2022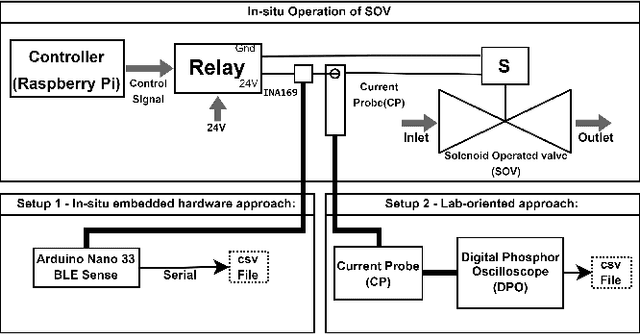
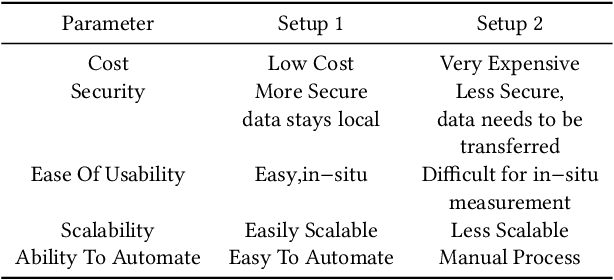
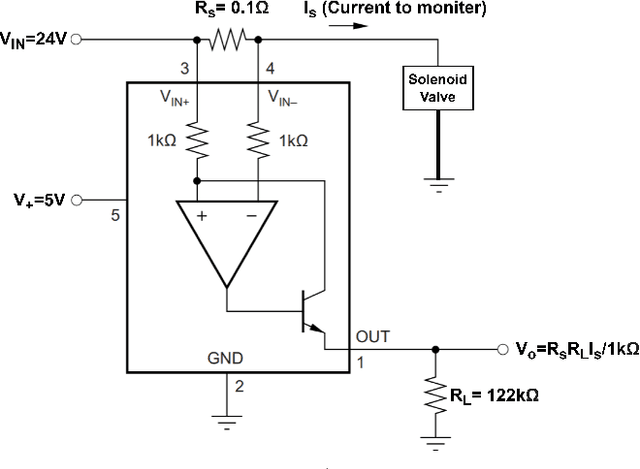

In industrial process automation, sensors (pressure, temperature, etc.), controllers, and actuators (solenoid valves, electro-mechanical relays, circuit breakers, motors, etc.) make sure that production lines are working under the pre-defined conditions. When these systems malfunction or sometimes completely fail, alerts have to be generated in real-time to make sure not only production quality is not compromised but also safety of humans and equipment is assured. In this work, we describe the construction of a smart and real-time edge-based electronic product called PreMa, which is basically a sensor for monitoring the health of a Solenoid Valve (SV). PreMa is compact, low power, easy to install, and cost effective. It has data fidelity and measurement accuracy comparable to signals captured using high end equipment. The smart solenoid sensor runs TinyML, a compact version of TensorFlow (a.k.a. TFLite) machine learning framework. While fault detection inferencing is in-situ, model training uses mobile phones to accomplish the `on-device' training. Our product evaluation shows that the sensor is able to differentiate between the distinct types of faults. These faults include: (a) Spool stuck (b) Spring failure and (c) Under voltage. Furthermore, the product provides maintenance personnel, the remaining useful life (RUL) of the SV. The RUL provides assistance to decide valve replacement or otherwise. We perform an extensive evaluation on optimizing metrics related to performance of the entire system (i.e. embedded platform and the neural network model). The proposed implementation is such that, given any electro-mechanical actuator with similar transient response to that of the SV, the system is capable of condition monitoring, hence presenting a first of its kind generic infrastructure.
PseudoBound: Limiting the anomaly reconstruction capability of one-class classifiers using pseudo anomalies
Mar 19, 2023

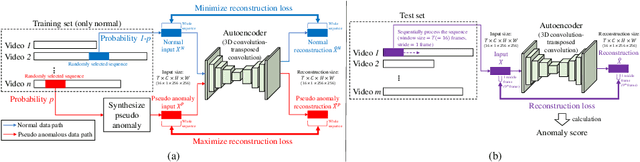
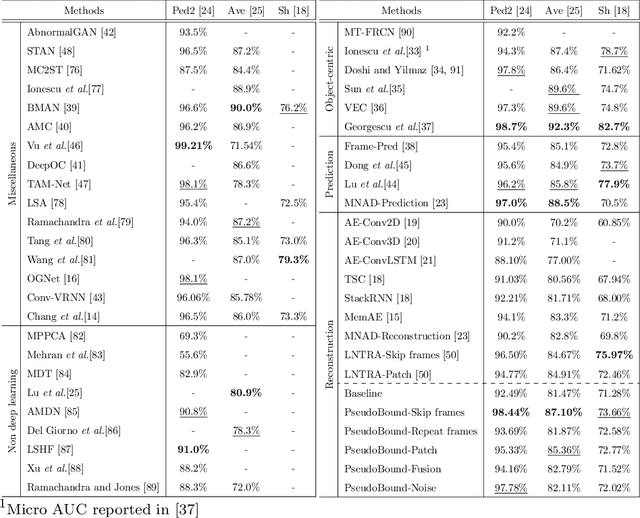
Due to the rarity of anomalous events, video anomaly detection is typically approached as one-class classification (OCC) problem. Typically in OCC, an autoencoder (AE) is trained to reconstruct the normal only training data with the expectation that, in test time, it can poorly reconstruct the anomalous data. However, previous studies have shown that, even trained with only normal data, AEs can often reconstruct anomalous data as well, resulting in a decreased performance. To mitigate this problem, we propose to limit the anomaly reconstruction capability of AEs by incorporating pseudo anomalies during the training of an AE. Extensive experiments using five types of pseudo anomalies show the robustness of our training mechanism towards any kind of pseudo anomaly. Moreover, we demonstrate the effectiveness of our proposed pseudo anomaly based training approach against several existing state-ofthe-art (SOTA) methods on three benchmark video anomaly datasets, outperforming all the other reconstruction-based approaches in two datasets and showing the second best performance in the other dataset.
Robust Evaluation of Diffusion-Based Adversarial Purification
Mar 16, 2023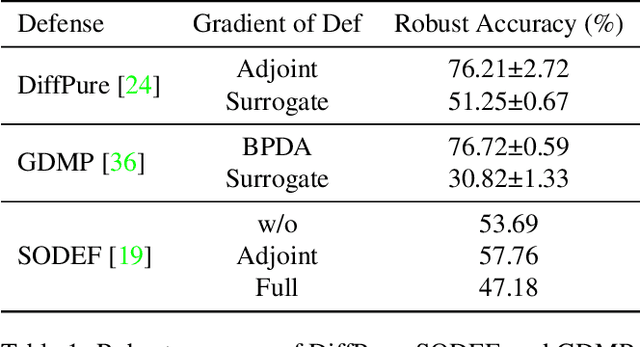
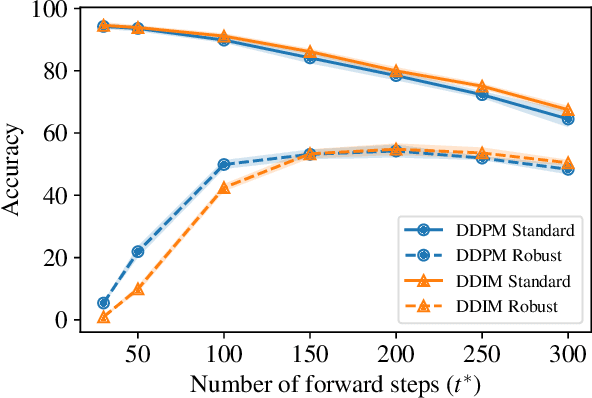

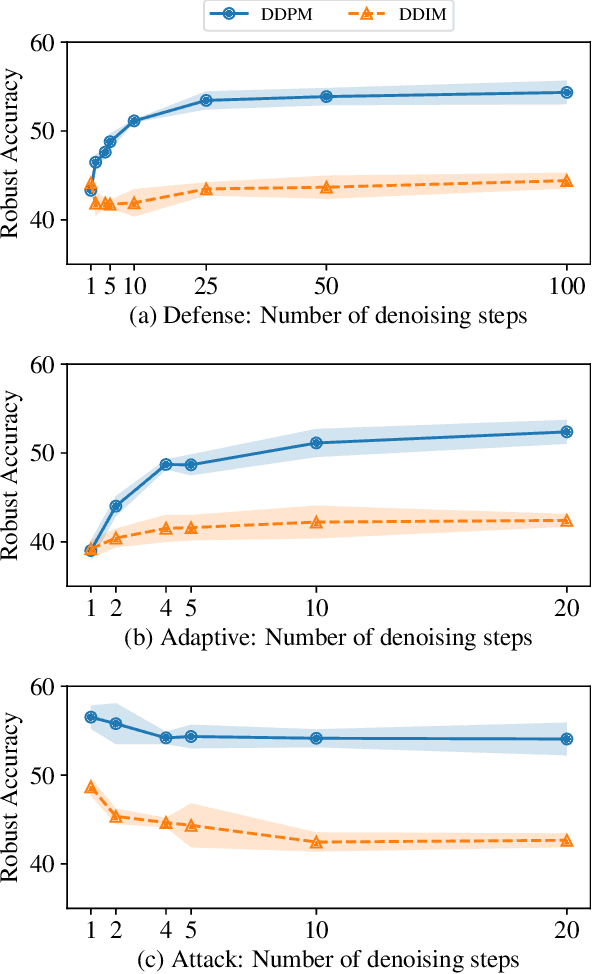
We question the current evaluation practice on diffusion-based purification methods. Diffusion-based purification methods aim to remove adversarial effects from an input data point at test time. The approach gains increasing attention as an alternative to adversarial training due to the disentangling between training and testing. Well-known white-box attacks are often employed to measure the robustness of the purification. However, it is unknown whether these attacks are the most effective for the diffusion-based purification since the attacks are often tailored for adversarial training. We analyze the current practices and provide a new guideline for measuring the robustness of purification methods against adversarial attacks. Based on our analysis, we further propose a new purification strategy showing competitive results against the state-of-the-art adversarial training approaches.