 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Audio-based Roughness Sensing and Tactile Feedback for Haptic Perception in Telepresence
Mar 13, 2023
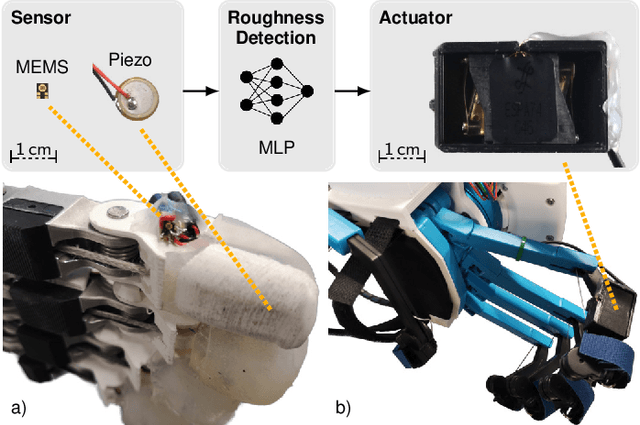

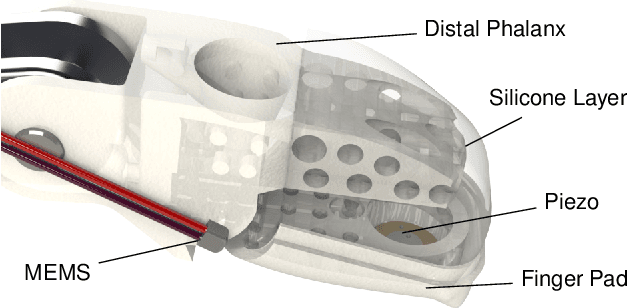

Haptic perception is incredibly important for immersive teleoperation of robots, especially for accomplishing manipulation tasks. We propose a low-cost haptic sensing and rendering system, which is capable of detecting and displaying surface roughness. As the robot fingertip moves across a surface of interest, two microphones capture sound coupled directly through the fingertip and through the air, respectively. A learning-based detector system analyzes the data in real-time and gives roughness estimates with both high temporal resolution and low latency. Finally, an audio-based haptic actuator displays the result to the human operator. We demonstrate the effectiveness of our system through experiments and our winning entry in the ANA Avatar XPRIZE competition finals, where impartial judges solved a roughness-based selection task even without additional vision feedback. We publish our dataset used for training and evaluation together with our trained models to enable reproducibility.
Learning Reduced-Order Models for Cardiovascular Simulations with Graph Neural Networks
Mar 13, 2023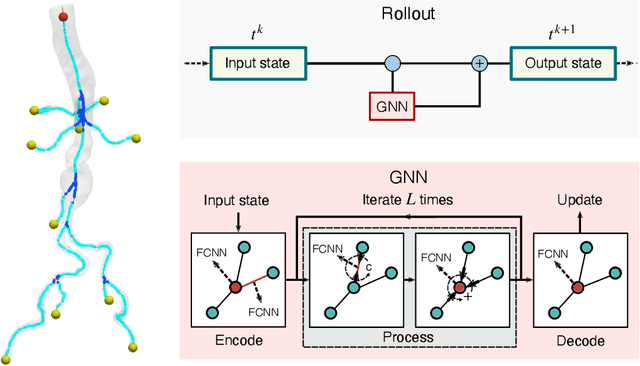


Reduced-order models based on physics are a popular choice in cardiovascular modeling due to their efficiency, but they may experience reduced accuracy when working with anatomies that contain numerous junctions or pathological conditions. We develop one-dimensional reduced-order models that simulate blood flow dynamics using a graph neural network trained on three-dimensional hemodynamic simulation data. Given the initial condition of the system, the network iteratively predicts the pressure and flow rate at the vessel centerline nodes. Our numerical results demonstrate the accuracy and generalizability of our method in physiological geometries comprising a variety of anatomies and boundary conditions. Our findings demonstrate that our approach can achieve errors below 2% and 3% for pressure and flow rate, respectively, provided there is adequate training data. As a result, our method exhibits superior performance compared to physics-based one-dimensional models, while maintaining high efficiency at inference time.
Forming and Controlling Hitches in Midair Using Aerial Robots
Mar 13, 2023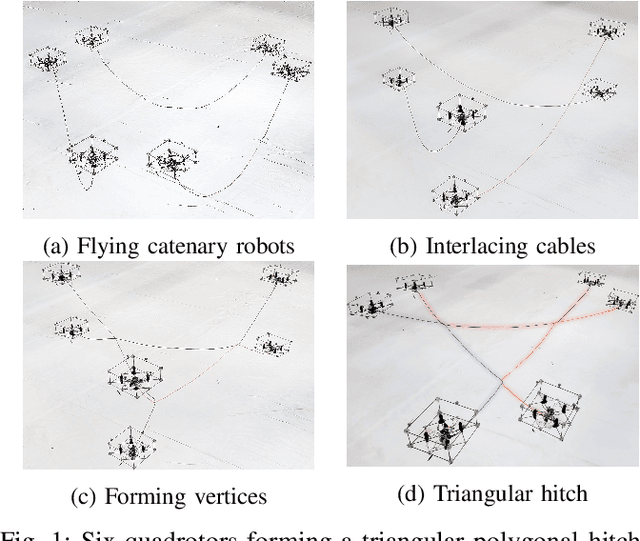
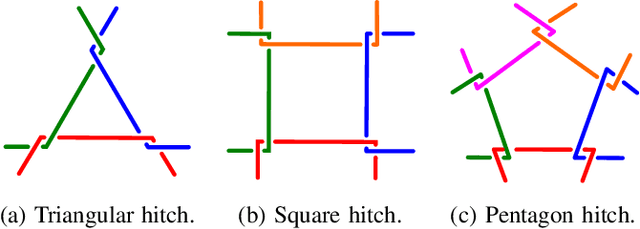
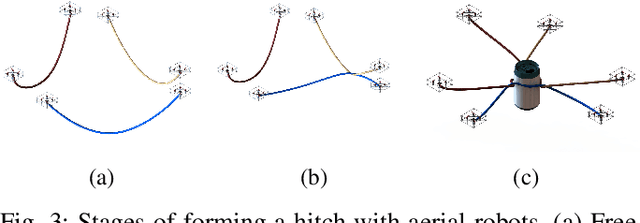
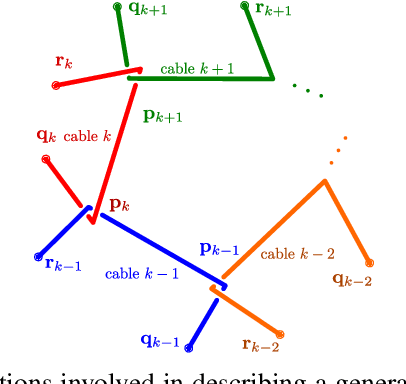
The use of cables for aerial manipulation has shown to be a lightweight and versatile way to interact with objects. However, fastening objects using cables is still a challenge and human is required. In this work, we propose a novel way to secure objects using hitches. The hitch can be formed and morphed in midair using a team of aerial robots with cables. The hitch's shape is modeled as a convex polygon, making it versatile and adaptable to a wide variety of objects. We propose an algorithm to form the hitch systematically. The steps can run in parallel, allowing hitches with a large number of robots to be formed in constant time. We develop a set of actions that include different actions to change the shape of the hitch. We demonstrate our methods using a team of aerial robots via simulation and actual experiments.
Efficient Symbolic Approaches for Quantitative Reactive Synthesis with Finite Tasks
Mar 13, 2023
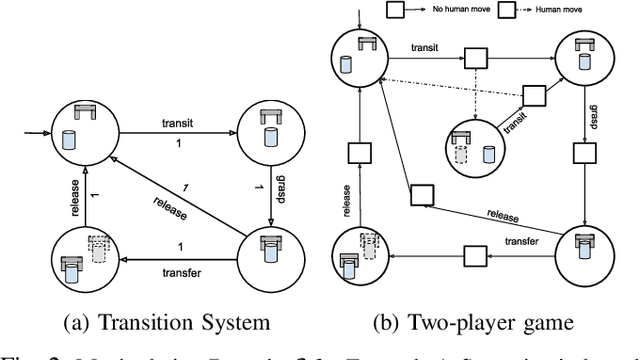
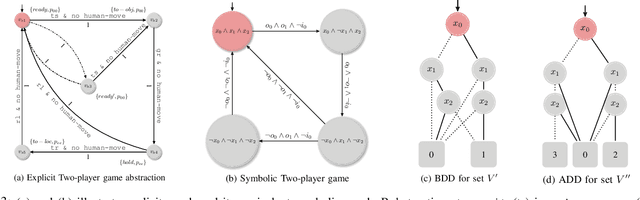
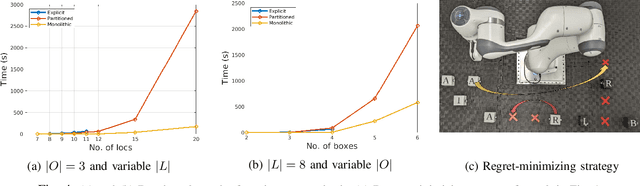
This work introduces efficient symbolic algorithms for quantitative reactive synthesis. We consider resource-constrained robotic manipulators that need to interact with a human to achieve a complex task expressed in linear temporal logic. Our framework generates reactive strategies that not only guarantee task completion but also seek cooperation with the human when possible. We model the interaction as a two-player game and consider regret-minimizing strategies to encourage cooperation. We use symbolic representation of the game to enable scalability. For synthesis, we first introduce value iteration algorithms for such games with min-max objectives. Then, we extend our method to the regret-minimizing objectives. Our benchmarks reveal that our symbolic framework not only significantly improves computation time (up to an order of magnitude) but also can scale up to much larger instances of manipulation problems with up to 2x number of objects and locations than the state of the art.
Transformer-based World Models Are Happy With 100k Interactions
Mar 13, 2023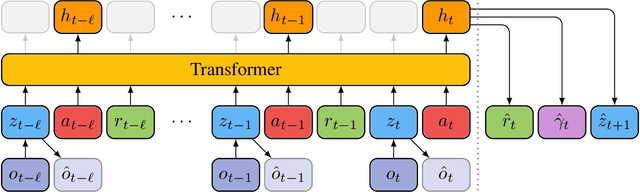
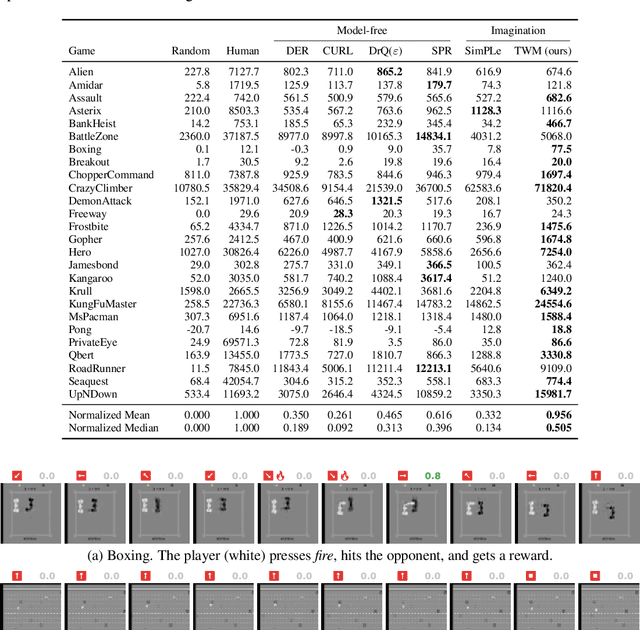
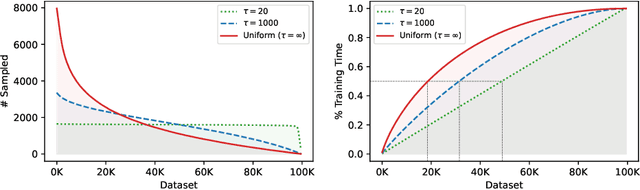
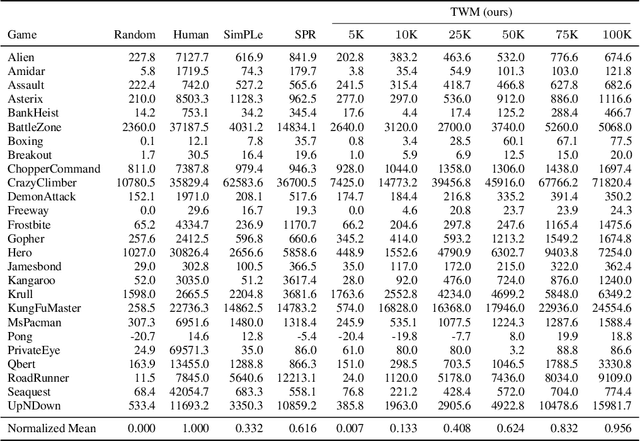
Deep neural networks have been successful in many reinforcement learning settings. However, compared to human learners they are overly data hungry. To build a sample-efficient world model, we apply a transformer to real-world episodes in an autoregressive manner: not only the compact latent states and the taken actions but also the experienced or predicted rewards are fed into the transformer, so that it can attend flexibly to all three modalities at different time steps. The transformer allows our world model to access previous states directly, instead of viewing them through a compressed recurrent state. By utilizing the Transformer-XL architecture, it is able to learn long-term dependencies while staying computationally efficient. Our transformer-based world model (TWM) generates meaningful, new experience, which is used to train a policy that outperforms previous model-free and model-based reinforcement learning algorithms on the Atari 100k benchmark.
Functional Knowledge Transfer with Self-supervised Representation Learning
Mar 12, 2023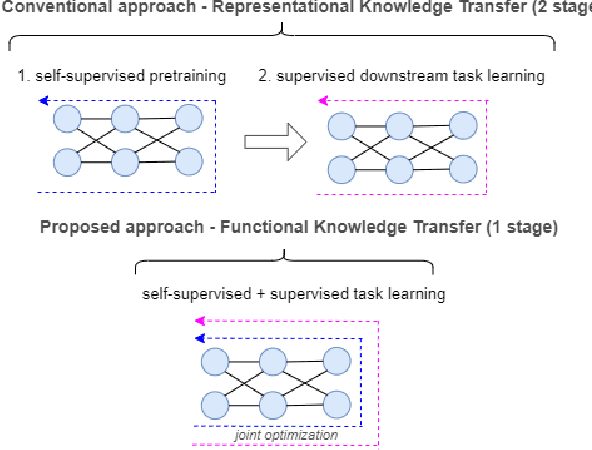
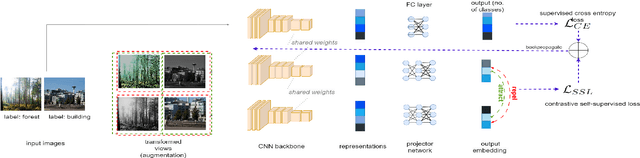

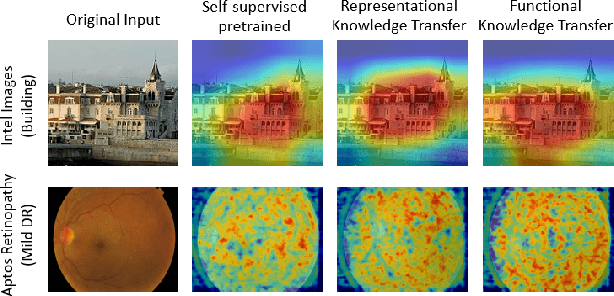
This work investigates the unexplored usability of self-supervised representation learning in the direction of functional knowledge transfer. In this work, functional knowledge transfer is achieved by joint optimization of self-supervised learning pseudo task and supervised learning task, improving supervised learning task performance. Recent progress in self-supervised learning uses a large volume of data, which becomes a constraint for its applications on small-scale datasets. This work shares a simple yet effective joint training framework that reinforces human-supervised task learning by learning self-supervised representations just-in-time and vice versa. Experiments on three public datasets from different visual domains, Intel Image, CIFAR, and APTOS, reveal a consistent track of performance improvements on classification tasks during joint optimization. Qualitative analysis also supports the robustness of learnt representations. Source code and trained models are available on GitHub.
Cyclic Delay-Doppler Shift: A Simple Transmit Diversity Technique for Delay-Doppler Waveforms in Doubly Selective Channels
Feb 22, 2023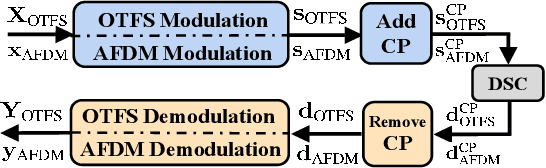

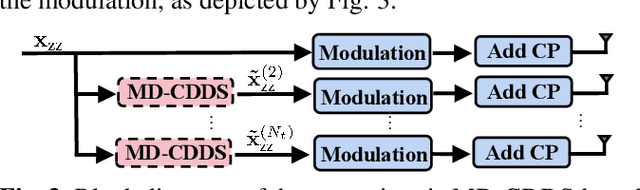

Delay-Doppler waveform design has been considered as a promising solution to achieve reliable communication under high-mobility channels for the space-air-ground-integrated networks (SAGIN). In this paper, we introduce the cyclic delay-Doppler shift (CDDS) technique for delay-Doppler waveforms to extract transmit diversity in doubly selective channels. Two simple CDDS schemes, named time-domain CDDS (TD-CDDS) and modulation-domain CDDS (MD-CDDS), are proposed in the setting of multiple-input multiple-output (MIMO). We demonstrate the applications of CDDS on two representative delay-Doppler waveforms, namely orthogonal time frequency space (OTFS) and affine frequency division multiplexing (AFDM), by deriving their corresponding CDDS matrices. Furthermore, we prove theoretically and experimentally that CDDS can provide OTFS and AFDM with full transmit diversity gain on most occasions.
A Graph Neural Network Approach to Nanosatellite Task Scheduling: Insights into Learning Mixed-Integer Models
Mar 24, 2023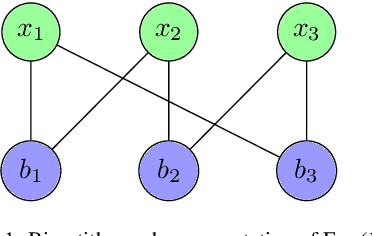

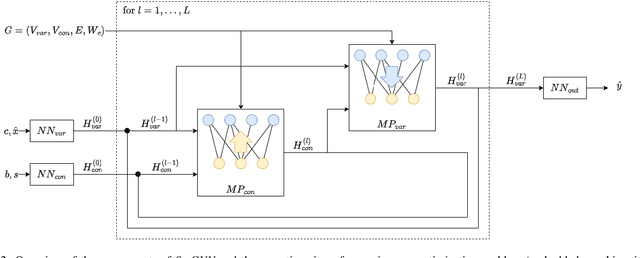
This study investigates how to schedule nanosatellite tasks more efficiently using Graph Neural Networks (GNN). In the Offline Nanosatellite Task Scheduling (ONTS) problem, the goal is to find the optimal schedule for tasks to be carried out in orbit while taking into account Quality-of-Service (QoS) considerations such as priority, minimum and maximum activation events, execution time-frames, periods, and execution windows, as well as constraints on the satellite's power resources and the complexity of energy harvesting and management. The ONTS problem has been approached using conventional mathematical formulations and precise methods, but their applicability to challenging cases of the problem is limited. This study examines the use of GNNs in this context, which has been effectively applied to many optimization problems, including traveling salesman problems, scheduling problems, and facility placement problems. Here, we fully represent MILP instances of the ONTS problem in bipartite graphs. We apply a feature aggregation and message-passing methodology allied to a ReLU activation function to learn using a classic deep learning model, obtaining an optimal set of parameters. Furthermore, we apply Explainable AI (XAI), another emerging field of research, to determine which features -- nodes, constraints -- had the most significant impact on learning performance, shedding light on the inner workings and decision process of such models. We also explored an early fixing approach by obtaining an accuracy above 80\% both in predicting the feasibility of a solution and the probability of a decision variable value being in the optimal solution. Our results point to GNNs as a potentially effective method for scheduling nanosatellite tasks and shed light on the advantages of explainable machine learning models for challenging combinatorial optimization problems.
CLIP for All Things Zero-Shot Sketch-Based Image Retrieval, Fine-Grained or Not
Mar 24, 2023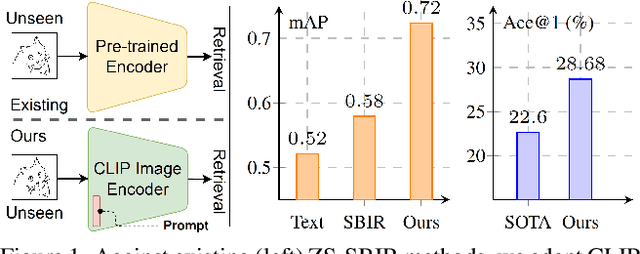
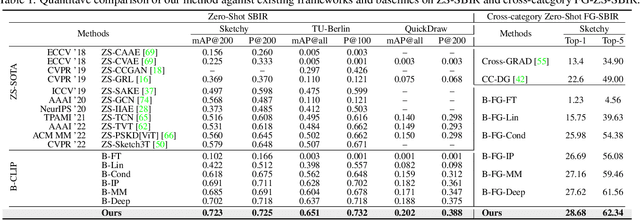

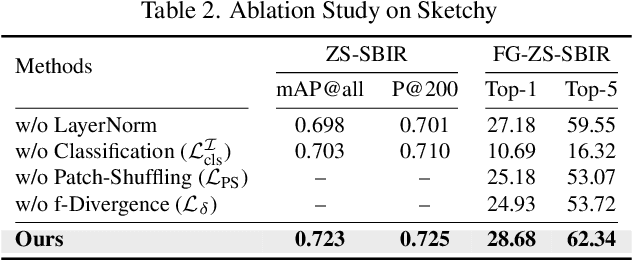
In this paper, we leverage CLIP for zero-shot sketch based image retrieval (ZS-SBIR). We are largely inspired by recent advances on foundation models and the unparalleled generalisation ability they seem to offer, but for the first time tailor it to benefit the sketch community. We put forward novel designs on how best to achieve this synergy, for both the category setting and the fine-grained setting ("all"). At the very core of our solution is a prompt learning setup. First we show just via factoring in sketch-specific prompts, we already have a category-level ZS-SBIR system that overshoots all prior arts, by a large margin (24.8%) - a great testimony on studying the CLIP and ZS-SBIR synergy. Moving onto the fine-grained setup is however trickier, and requires a deeper dive into this synergy. For that, we come up with two specific designs to tackle the fine-grained matching nature of the problem: (i) an additional regularisation loss to ensure the relative separation between sketches and photos is uniform across categories, which is not the case for the gold standard standalone triplet loss, and (ii) a clever patch shuffling technique to help establishing instance-level structural correspondences between sketch-photo pairs. With these designs, we again observe significant performance gains in the region of 26.9% over previous state-of-the-art. The take-home message, if any, is the proposed CLIP and prompt learning paradigm carries great promise in tackling other sketch-related tasks (not limited to ZS-SBIR) where data scarcity remains a great challenge. Project page: https://aneeshan95.github.io/Sketch_LVM/
Generating Real-Time Strategy Game Units Using Search-Based Procedural Content Generation and Monte Carlo Tree Search
Dec 07, 2022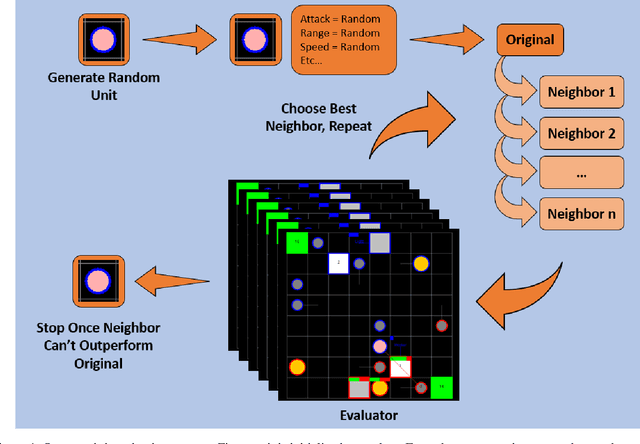
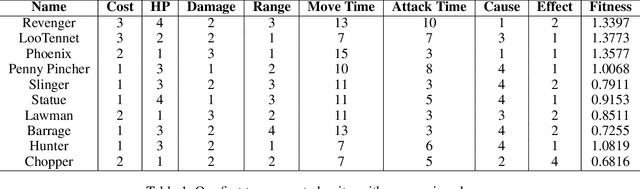

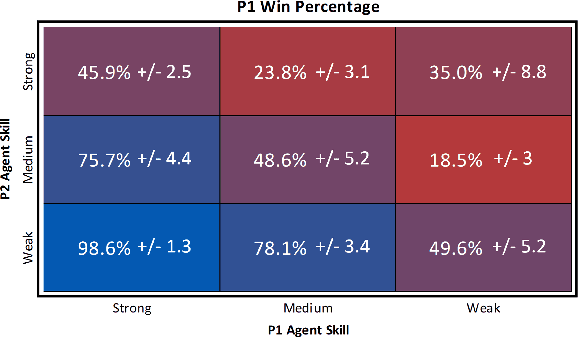
Real-Time Strategy (RTS) game unit generation is an unexplored area of Procedural Content Generation (PCG) research, which leaves the question of how to automatically generate interesting and balanced units unanswered. Creating unique and balanced units can be a difficult task when designing an RTS game, even for humans. Having an automated method of designing units could help developers speed up the creation process as well as find new ideas. In this work we propose a method of generating balanced and useful RTS units. We draw on Search-Based PCG and a fitness function based on Monte Carlo Tree Search (MCTS). We present ten units generated by our system designed to be used in the game microRTS, as well as results demonstrating that these units are unique, useful, and balanced.