 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Experimental study of time series forecasting methods for groundwater level prediction
Sep 28, 2022
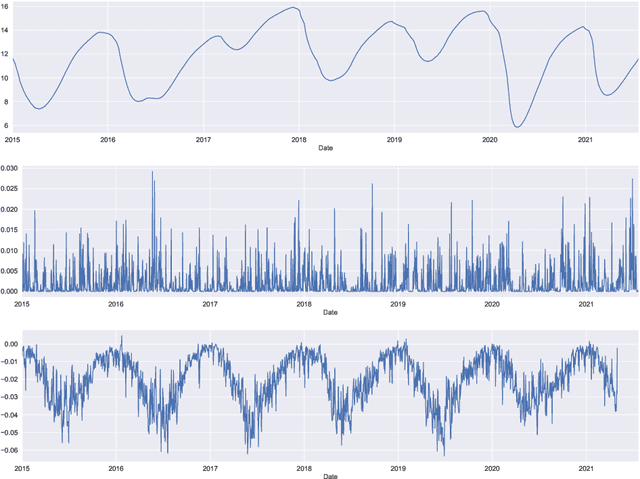
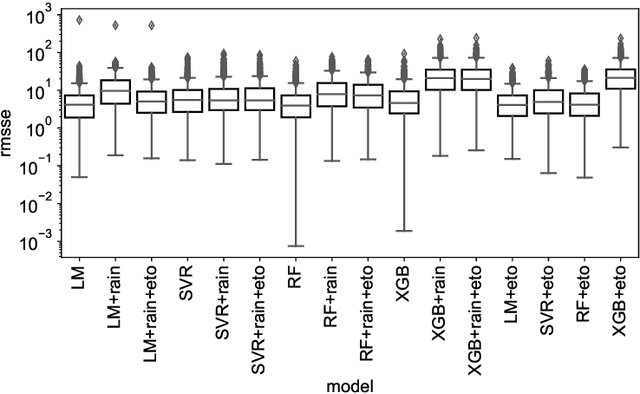
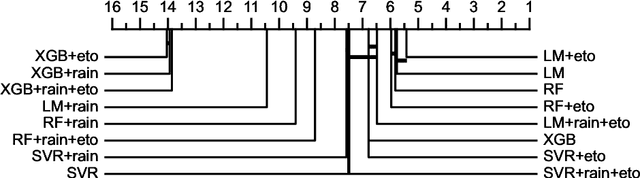
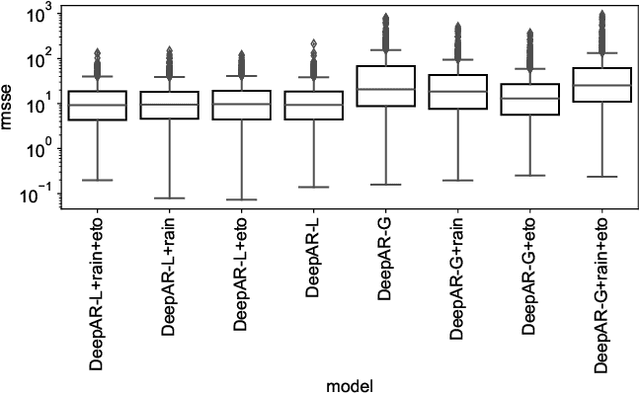
Groundwater level prediction is an applied time series forecasting task with important social impacts to optimize water management as well as preventing some natural disasters: for instance, floods or severe droughts. Machine learning methods have been reported in the literature to achieve this task, but they are only focused on the forecast of the groundwater level at a single location. A global forecasting method aims at exploiting the groundwater level time series from a wide range of locations to produce predictions at a single place or at several places at a time. Given the recent success of global forecasting methods in prestigious competitions, it is meaningful to assess them on groundwater level prediction and see how they are compared to local methods. In this work, we created a dataset of 1026 groundwater level time series. Each time series is made of daily measurements of groundwater levels and two exogenous variables, rainfall and evapotranspiration. This dataset is made available to the communities for reproducibility and further evaluation. To identify the best configuration to effectively predict groundwater level for the complete set of time series, we compared different predictors including local and global time series forecasting methods. We assessed the impact of exogenous variables. Our result analysis shows that the best predictions are obtained by training a global method on past groundwater levels and rainfall data.
A Universal Question-Answering Platform for Knowledge Graphs
Mar 01, 2023
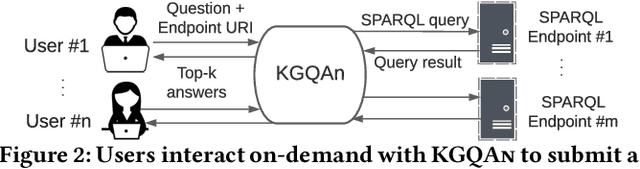

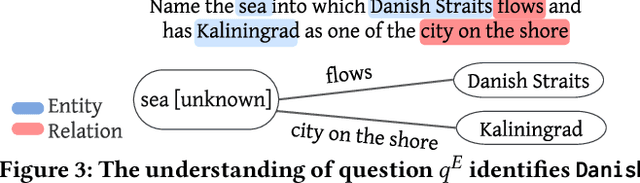
Knowledge from diverse application domains is organized as knowledge graphs (KGs) that are stored in RDF engines accessible in the web via SPARQL endpoints. Expressing a well-formed SPARQL query requires information about the graph structure and the exact URIs of its components, which is impractical for the average user. Question answering (QA) systems assist by translating natural language questions to SPARQL. Existing QA systems are typically based on application-specific human-curated rules, or require prior information, expensive pre-processing and model adaptation for each targeted KG. Therefore, they are hard to generalize to a broad set of applications and KGs. In this paper, we propose KGQAn, a universal QA system that does not need to be tailored to each target KG. Instead of curated rules, KGQAn introduces a novel formalization of question understanding as a text generation problem to convert a question into an intermediate abstract representation via a neural sequence-to-sequence model. We also develop a just-in-time linker that maps at query time the abstract representation to a SPARQL query for a specific KG, using only the publicly accessible APIs and the existing indices of the RDF store, without requiring any pre-processing. Our experiments with several real KGs demonstrate that KGQAn is easily deployed and outperforms by a large margin the state-of-the-art in terms of quality of answers and processing time, especially for arbitrary KGs, unseen during the training.
CAM++: A Fast and Efficient Network for Speaker Verification Using Context-Aware Masking
Mar 02, 2023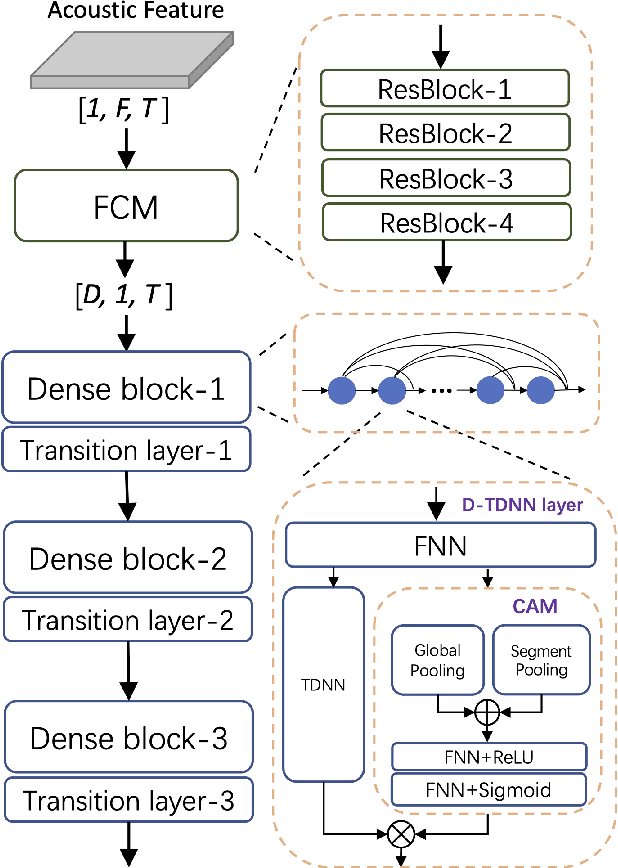
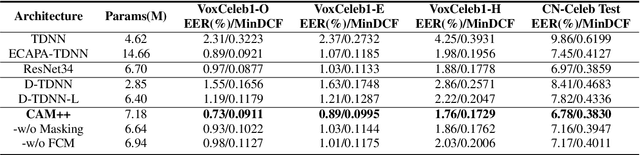
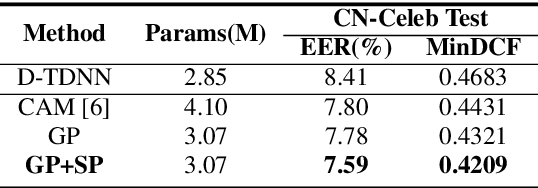

Time delay neural network (TDNN) has been proven to be efficient for speaker verification. One of its successful variants, ECAPA-TDNN, achieved state-of-the-art performance at the cost of much higher computational complexity and slower inference speed. This makes it inadequate for scenarios with demanding inference rate and limited computational resources. We are thus interested in finding an architecture that can achieve the performance of ECAPA-TDNN and the efficiency of vanilla TDNN. In this paper, we propose an efficient network based on context-aware masking, namely CAM++, which uses densely connected time delay neural network (D-TDNN) as backbone and adopts a novel multi-granularity pooling to capture contextual information at different levels. Extensive experiments on two public benchmarks, VoxCeleb and CN-Celeb, demonstrate that the proposed architecture outperforms other mainstream speaker verification systems with lower computational cost and faster inference speed.
Conditional Deformable Image Registration with Spatially-Variant and Adaptive Regularization
Mar 19, 2023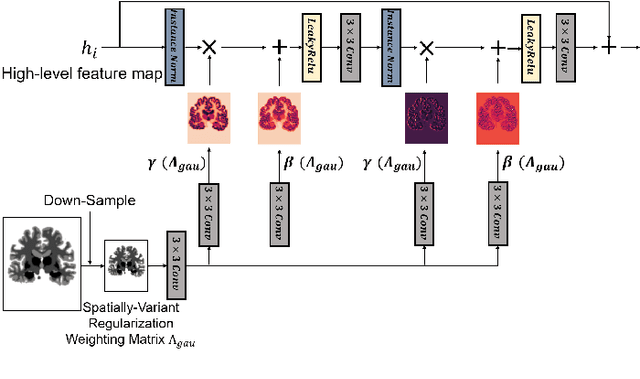

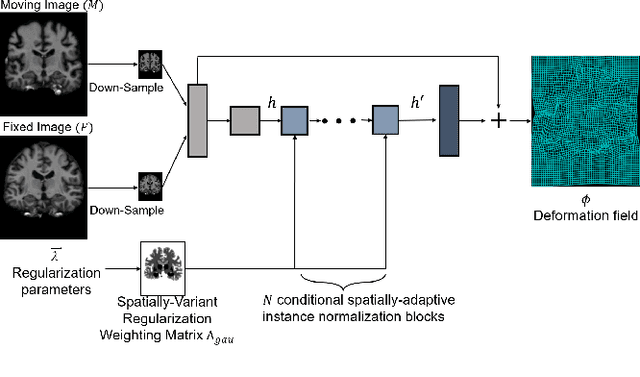
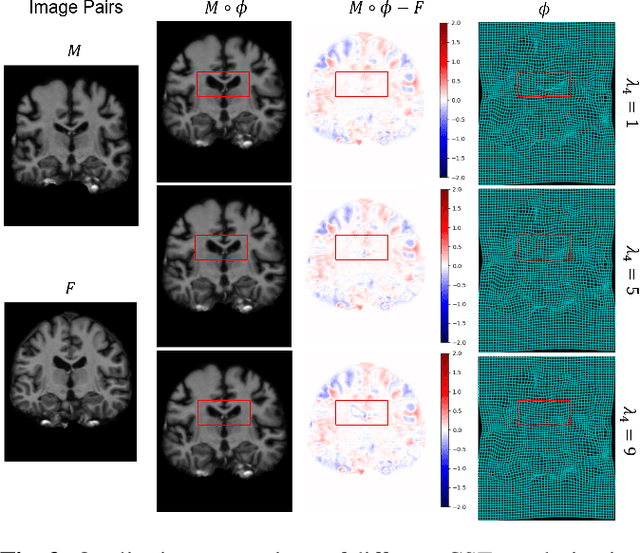
Deep learning-based image registration approaches have shown competitive performance and run-time advantages compared to conventional image registration methods. However, existing learning-based approaches mostly require to train separate models with respect to different regularization hyperparameters for manual hyperparameter searching and often do not allow spatially-variant regularization. In this work, we propose a learning-based registration approach based on a novel conditional spatially adaptive instance normalization (CSAIN) to address these challenges. The proposed method introduces a spatially-variant regularization and learns its effect of achieving spatially-adaptive regularization by conditioning the registration network on the hyperparameter matrix via CSAIN. This allows varying of spatially adaptive regularization at inference to obtain multiple plausible deformations with a single pre-trained model. Additionally, the proposed method enables automatic hyperparameter optimization to avoid manual hyperparameter searching. Experiments show that our proposed method outperforms the baseline approaches while achieving spatially-variant and adaptive regularization.
Switching Pushing Skill Combined MPC and Deep Reinforcement Learning for Planar Non-prehensile Manipulation
Mar 30, 2023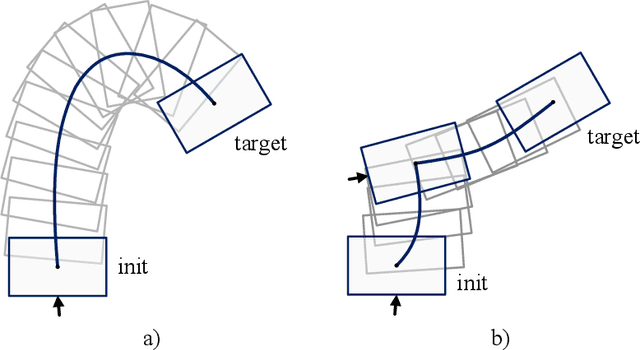
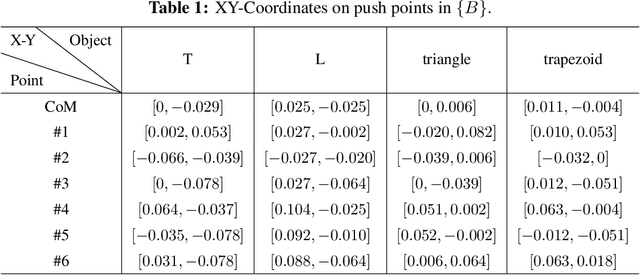
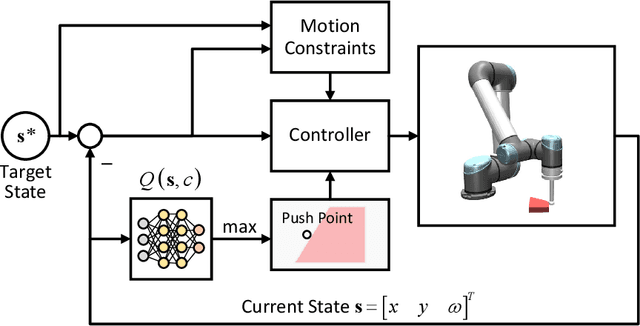
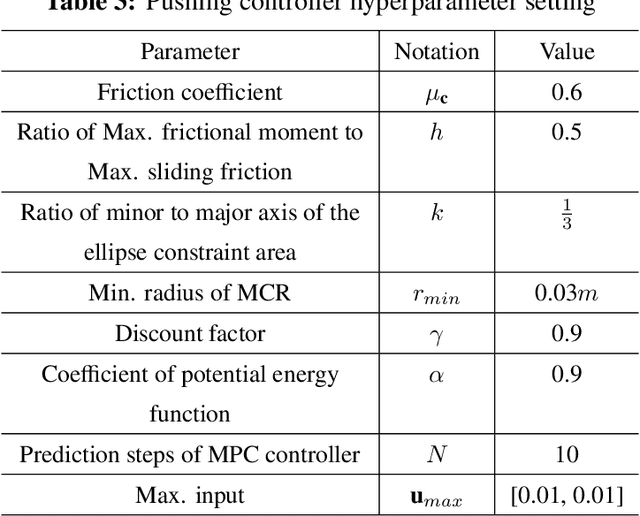
In this paper, a novel switching pushing skill algorithm is proposed to improve the efficiency of planar non-prehensile manipulation, which draws inspiration from human pushing actions and comprises two sub-problems, i.e., discrete decision-making of pushing point and continuous feedback control of pushing action. In order to solve the sub-problems above, a combination of Model Predictive Control (MPC) and Deep Reinforcement Learning (DRL) method is employed. Firstly, the selection of pushing point is modeled as a Markov decision process,and an off-policy DRL method is used by reshaping the reward function to train the decision-making model for selecting pushing point from a pre-constructed set based on the current state. Secondly, a motion constraint region (MCR) is constructed for the specific pushing point based on the distance from the target, followed by utilizing the MPC controller to regulate the motion of the object within the MCR towards the target pose. The trigger condition for switching the pushing point occurs when the object reaches the boundary of the MCR under the pushing action. Subsequently, the pushing point and the controller are updated iteratively until the target pose is reached. We conducted pushing experiments on four distinct object shapes in both simulated and physical environments to evaluate our method. The results indicate that our method achieves a significantly higher training efficiency, with a training time that is only about 20% of the baseline method while maintaining around the same success rate. Moreover, our method outperforms the baseline method in terms of both training and execution efficiency of pushing operations, allowing for rapid learning of robot pushing skills.
An Efficient Two-stage Gradient Boosting Framework for Short-term Traffic State Estimation
Feb 21, 2023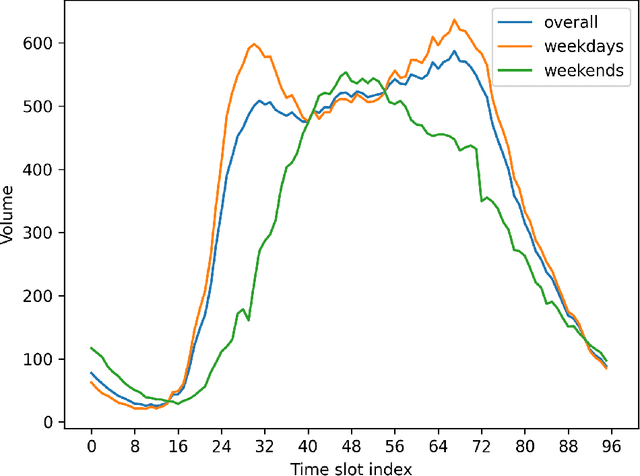

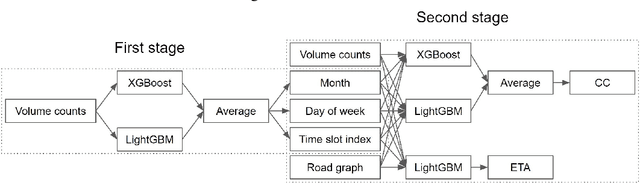

Real-time traffic state estimation is essential for intelligent transportation systems. The NeurIPS 2022 Traffic4cast challenge provides an excellent testbed for benchmarking short-term traffic state estimation approaches. This technical report describes our solution to this challenge. In particular, we present an efficient two-stage gradient boosting framework for short-term traffic state estimation. The first stage derives the month, day of the week, and time slot index based on the sparse loop counter data, and the second stage predicts the future traffic states based on the sparse loop counter data and the derived month, day of the week, and time slot index. Experimental results demonstrate that our two-stage gradient boosting framework achieves strong empirical performance, achieving third place in both the core and the extended challenges while remaining highly efficient. The source code for this technical report is available at \url{https://github.com/YichaoLu/Traffic4cast2022}.
Gotcha: A Challenge-Response System for Real-Time Deepfake Detection
Oct 12, 2022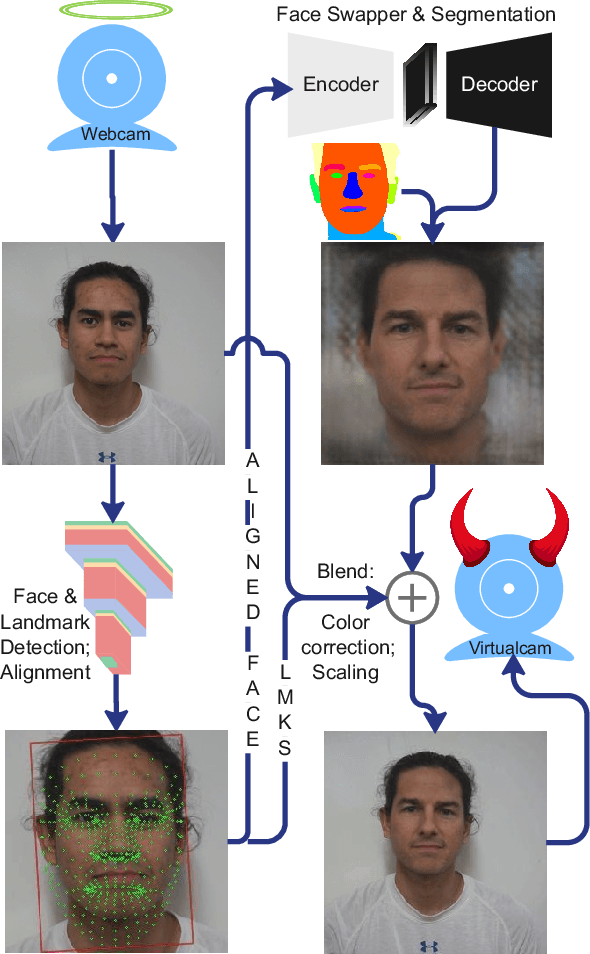
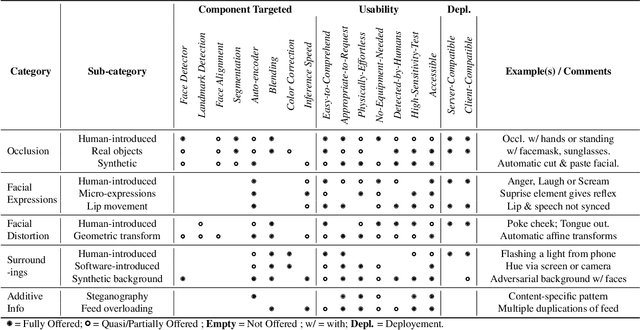
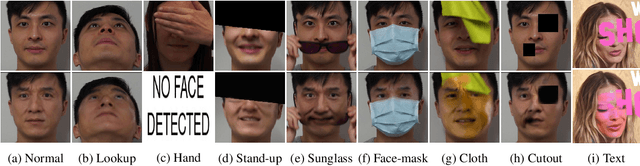
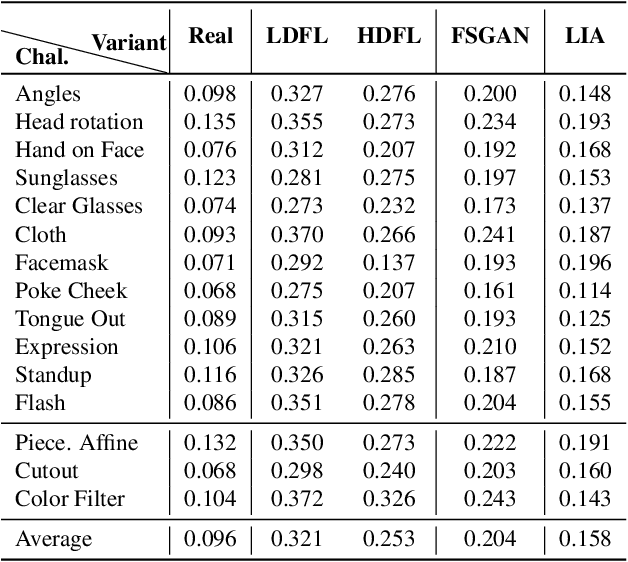
The integrity of online video interactions is threatened by the widespread rise of AI-enabled high-quality deepfakes that are now deployable in real-time. This paper presents Gotcha, a real-time deepfake detection system for live video interactions. The core principle underlying Gotcha is the presentation of a specially chosen cascade of both active and passive challenges to video conference participants. Active challenges include inducing changes in face occlusion, face expression, view angle, and ambiance; passive challenges include digital manipulation of the webcam feed. The challenges are designed to target vulnerabilities in the structure of modern deepfake generators and create perceptible artifacts for the human eye while inducing robust signals for ML-based automatic deepfake detectors. We present a comprehensive taxonomy of a large set of challenge tasks, which reveals a natural hierarchy among different challenges. Our system leverages this hierarchy by cascading progressively more demanding challenges to a suspected deepfake. We evaluate our system on a novel dataset of live users emulating deepfakes and show that our system provides consistent, measurable degradation of deepfake quality, showcasing its promise for robust real-time deepfake detection when deployed in the wild.
Renaissance canons with asymmetric schemes
Feb 27, 2023



By a "scheme" of a musical canon, we mean the order of voice entry with the time and pitch displacement of each entering voice. When the time displacements are unequal, achieving consonant sonorities is especially challenging. Using a first-species theoretical model, we quantify the flexibility of schemes that Renaissance composers used or could have used. We craft an algorithm to compute the flexibility value precisely (finding in the process that it is an $h$-th root of a Pisot number). We find that Palestrina consistently selected some of the most flexible schemes, more so than his predecessors, but that he by no means exhausted the feasible schemes. We close by presenting a new composition within the limits of the style utilizing an unexplored canonic scheme.
Transitions between quasi-stationary states in traffic systems: Cologne orbital motorways as an example
Feb 28, 2023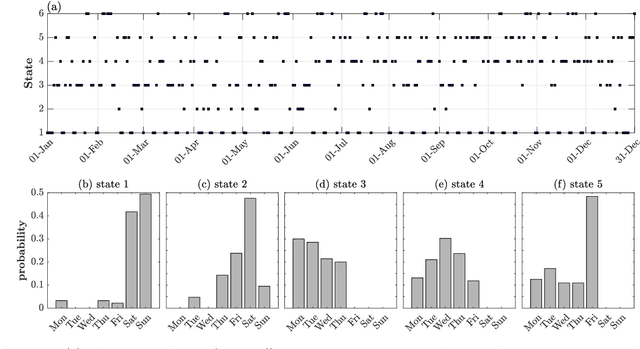
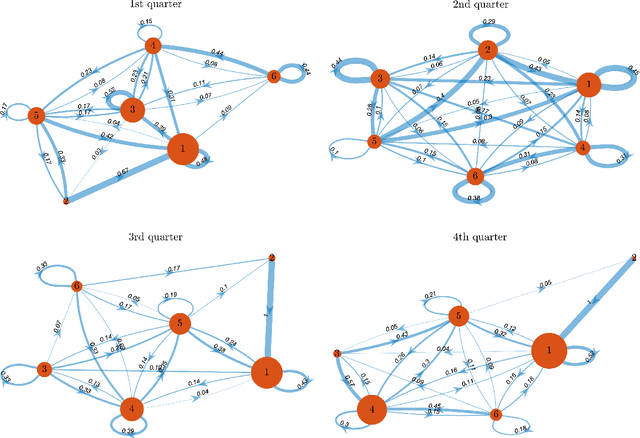
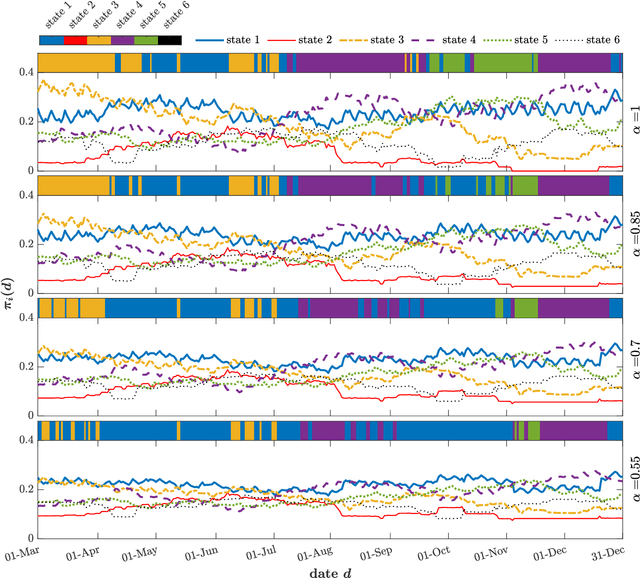
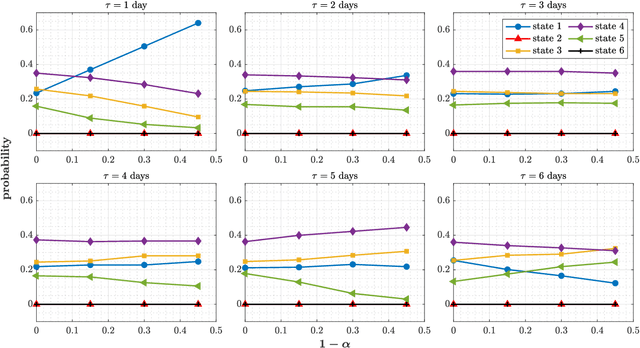
Traffic systems can operate in different modes. In a previous work, we identified these modes as different quasi-stationary states in the correlation structure. Here, we analyze the transitions between such quasi-stationary states, i.e., how the system changes its operational mode. In the longer run this might be helpful to forecast the time evolution of correlation patterns in traffic. We take Cologne orbital motorways as an example, we construct a state transition network for each quarter of 2015 and find a seasonal dependence for those quasi-stationary states in the traffic system. Using the PageRank algorithm, we identify and explore the dominant states which occur frequently within a moving time window of 60 days in 2015. To the best of our knowledge, this is the first study of this type for traffic systems.
Event-based Human Pose Tracking by Spiking Spatiotemporal Transformer
Mar 31, 2023
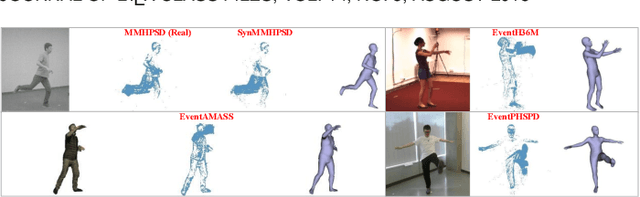

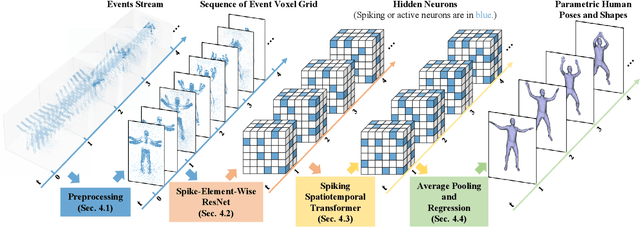
Event camera, as an emerging biologically-inspired vision sensor for capturing motion dynamics, presents new potential for 3D human pose tracking, or video-based 3D human pose estimation. However, existing works in pose tracking either require the presence of additional gray-scale images to establish a solid starting pose, or ignore the temporal dependencies all together by collapsing segments of event streams to form static event frames. Meanwhile, although the effectiveness of Artificial Neural Networks (ANNs, a.k.a. dense deep learning) has been showcased in many event-based tasks, the use of ANNs tends to neglect the fact that compared to the dense frame-based image sequences, the occurrence of events from an event camera is spatiotemporally much sparser. Motivated by the above mentioned issues, we present in this paper a dedicated end-to-end sparse deep learning approach for event-based pose tracking: 1) to our knowledge this is the first time that 3D human pose tracking is obtained from events only, thus eliminating the need of accessing to any frame-based images as part of input; 2) our approach is based entirely upon the framework of Spiking Neural Networks (SNNs), which consists of Spike-Element-Wise (SEW) ResNet and a novel Spiking Spatiotemporal Transformer; 3) a large-scale synthetic dataset is constructed that features a broad and diverse set of annotated 3D human motions, as well as longer hours of event stream data, named SynEventHPD. Empirical experiments demonstrate that, with superior performance over the state-of-the-art (SOTA) ANNs counterparts, our approach also achieves a significant computation reduction of 80% in FLOPS. Furthermore, our proposed method also outperforms SOTA SNNs in the regression task of human pose tracking. Our implementation is available at https://github.com/JimmyZou/HumanPoseTracking_SNN and dataset will be released upon paper acceptance.