 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Generalized Semantic Segmentation by Self-Supervised Source Domain Projection and Multi-Level Contrastive Learning
Mar 03, 2023
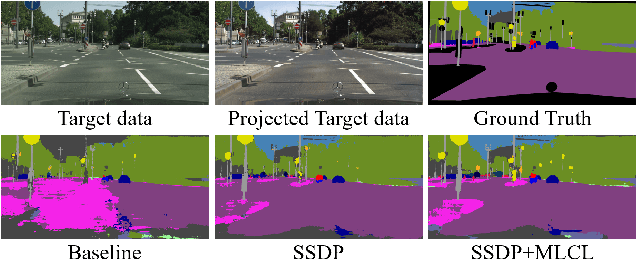
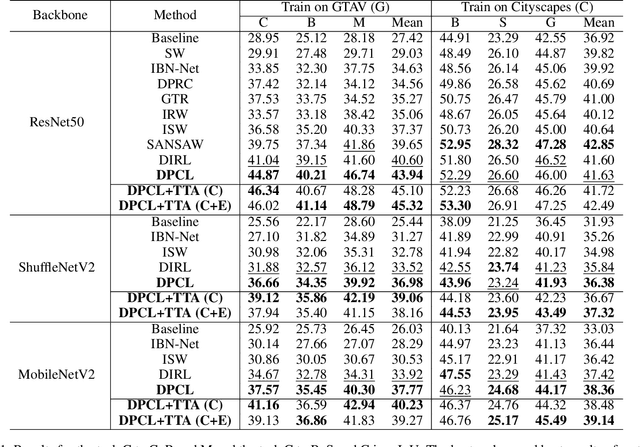
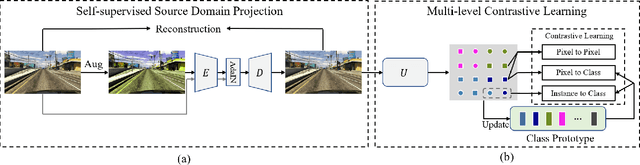
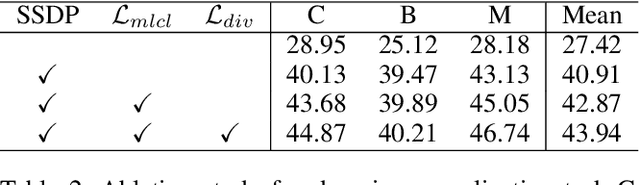
Deep networks trained on the source domain show degraded performance when tested on unseen target domain data. To enhance the model's generalization ability, most existing domain generalization methods learn domain invariant features by suppressing domain sensitive features. Different from them, we propose a Domain Projection and Contrastive Learning (DPCL) approach for generalized semantic segmentation, which includes two modules: Self-supervised Source Domain Projection (SSDP) and Multi-level Contrastive Learning (MLCL). SSDP aims to reduce domain gap by projecting data to the source domain, while MLCL is a learning scheme to learn discriminative and generalizable features on the projected data. During test time, we first project the target data by SSDP to mitigate domain shift, then generate the segmentation results by the learned segmentation network based on MLCL. At test time, we can update the projected data by minimizing our proposed pixel-to-pixel contrastive loss to obtain better results. Extensive experiments for semantic segmentation demonstrate the favorable generalization capability of our method on benchmark datasets.
RAFEN -- Regularized Alignment Framework for Embeddings of Nodes
Mar 03, 2023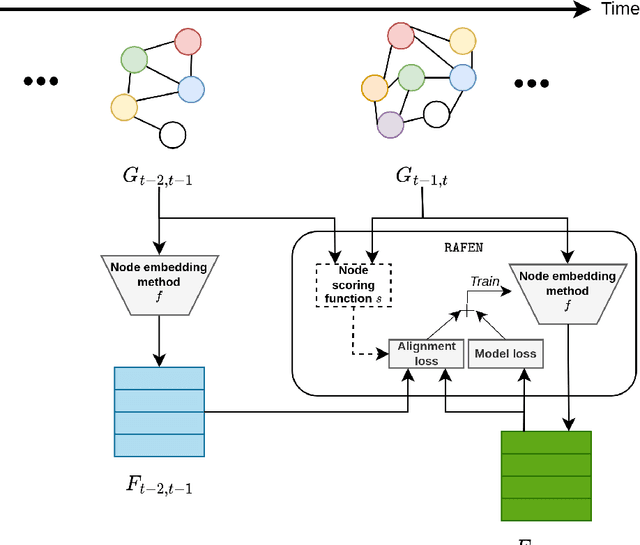
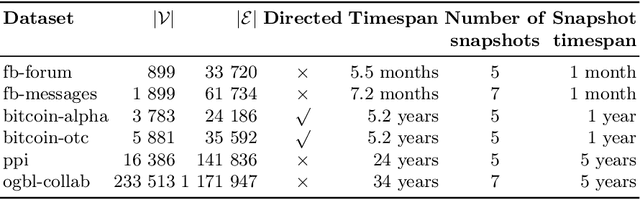
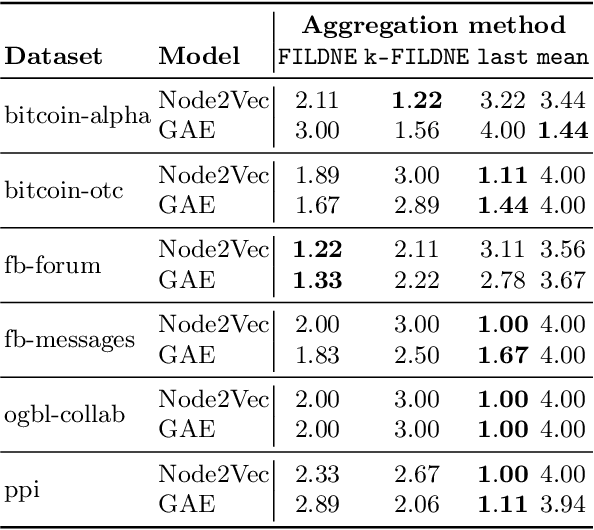
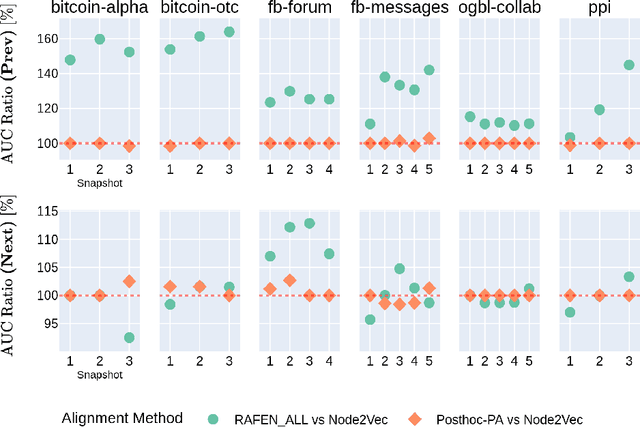
Learning representations of nodes has been a crucial area of the graph machine learning research area. A well-defined node embedding model should reflect both node features and the graph structure in the final embedding. In the case of dynamic graphs, this problem becomes even more complex as both features and structure may change over time. The embeddings of particular nodes should remain comparable during the evolution of the graph, what can be achieved by applying an alignment procedure. This step was often applied in existing works after the node embedding was already computed. In this paper, we introduce a framework -- RAFEN -- that allows to enrich any existing node embedding method using the aforementioned alignment term and learning aligned node embedding during training time. We propose several variants of our framework and demonstrate its performance on six real-world datasets. RAFEN achieves on-par or better performance than existing approaches without requiring additional processing steps.
Driver Maneuver Detection and Analysis using Time Series Segmentation and Classification
Nov 10, 2022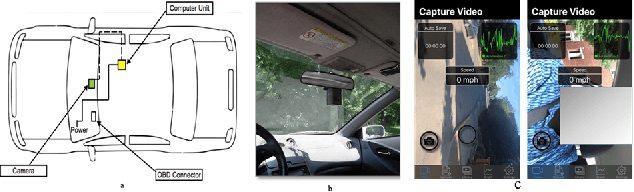

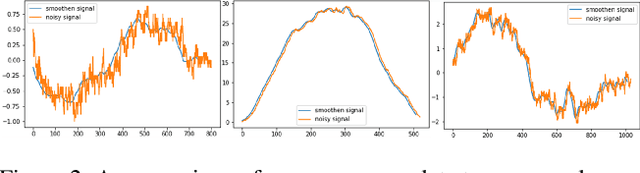

The current paper implements a methodology for automatically detecting vehicle maneuvers from vehicle telemetry data under naturalistic driving settings. Previous approaches have treated vehicle maneuver detection as a classification problem, although both time series segmentation and classification are required since input telemetry data is continuous. Our objective is to develop an end-to-end pipeline for frame-by-frame annotation of naturalistic driving studies videos into various driving events including stop and lane keeping events, lane changes, left-right turning movements, and horizontal curve maneuvers. To address the time series segmentation problem, the study developed an Energy Maximization Algorithm (EMA) capable of extracting driving events of varying durations and frequencies from continuous signal data. To reduce overfitting and false alarm rates, heuristic algorithms were used to classify events with highly variable patterns such as stops and lane-keeping. To classify segmented driving events, four machine learning models were implemented, and their accuracy and transferability were assessed over multiple data sources. The duration of events extracted by EMA were comparable to actual events, with accuracies ranging from 59.30% (left lane change) to 85.60% (lane-keeping). Additionally, the overall accuracy of the 1D-convolutional neural network model was 98.99%, followed by the Long-short-term-memory model at 97.75%, then random forest model at 97.71%, and the support vector machine model at 97.65%. These model accuracies where consistent across different data sources. The study concludes that implementing a segmentation-classification pipeline significantly improves both the accuracy for driver maneuver detection and transferability of shallow and deep ML models across diverse datasets.
Probabilistic Guarantees for Nonlinear Safety-Critical Optimal Control
Mar 11, 2023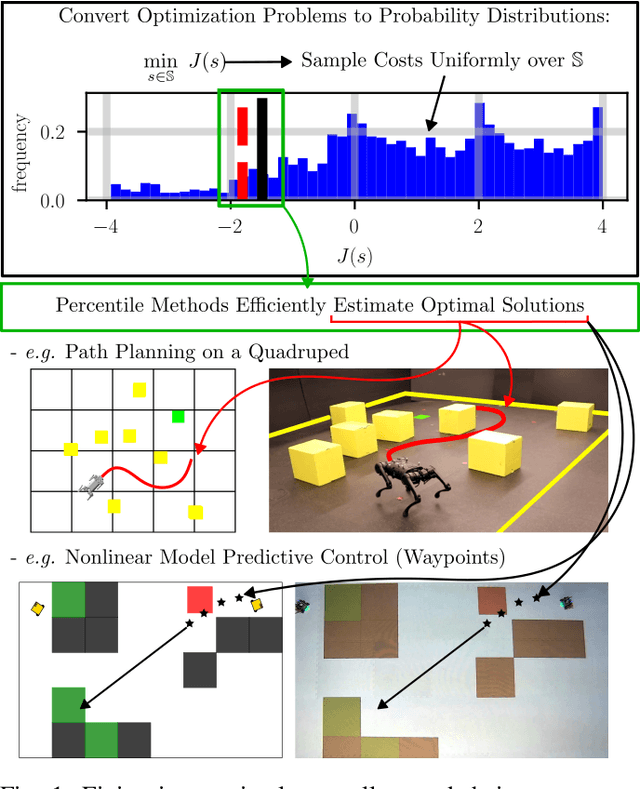
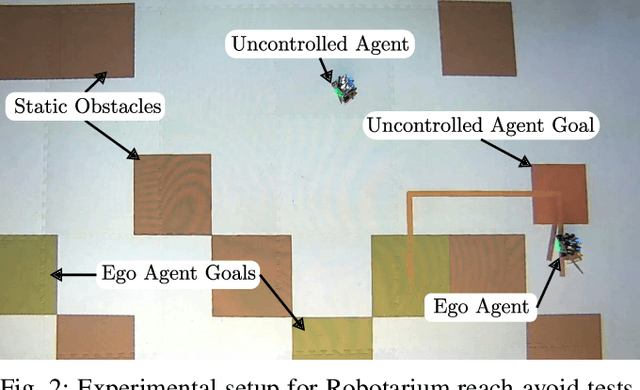
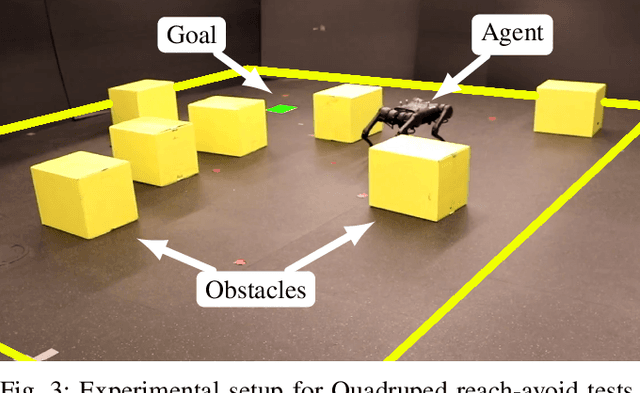
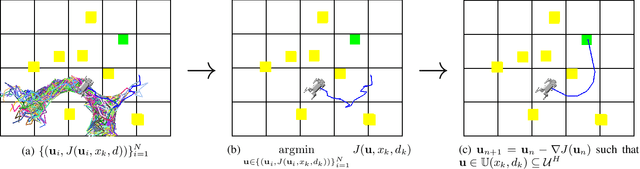
Leveraging recent developments in black-box risk-aware verification, we provide three algorithms that generate probabilistic guarantees on (1) optimality of solutions, (2) recursive feasibility, and (3) maximum controller runtimes for general nonlinear safety-critical finite-time optimal controllers. These methods forego the usual (perhaps) restrictive assumptions required for typical theoretical guarantees, e.g. terminal set calculation for recursive feasibility in Nonlinear Model Predictive Control, or convexification of optimal controllers to ensure optimality. Furthermore, we show that these methods can directly be applied to hardware systems to generate controller guarantees on their respective systems.
Multi-Task Sub-Band Network For Deep Residual Echo Suppression
Mar 11, 2023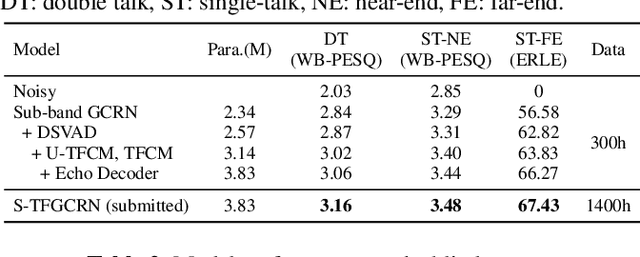
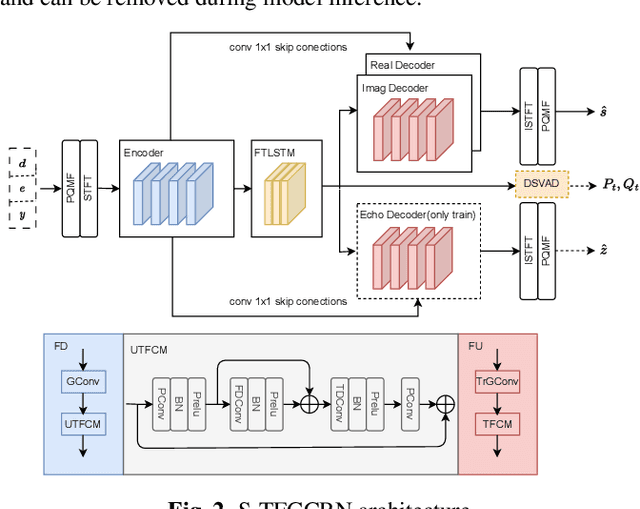
This paper introduces the SWANT team entry to the ICASSP 2023 AEC Challenge. We submit a system that cascades a linear filter with a neural post-filter. Particularly, we adopt sub-band processing to handle full-band signals and shape the network with multi-task learning, where dual signal voice activity detection (DSVAD) and echo estimation are adopted as auxiliary tasks. Moreover, we particularly improve the time frequency convolution module (TFCM) to increase the receptive field using small convolution kernels. Finally, our system has ranked 4th in ICASSP 2023 AEC Challenge Non-personalized track.
Conversation Modeling to Predict Derailment
Mar 20, 2023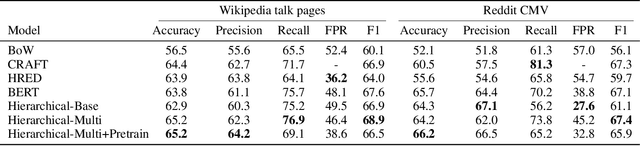
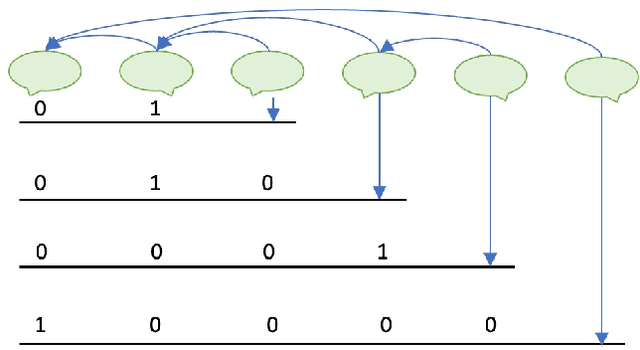

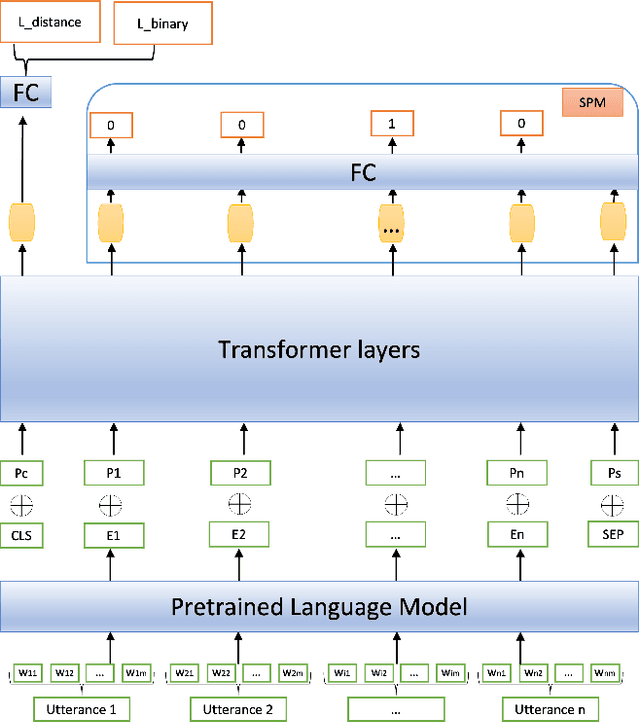
Conversations among online users sometimes derail, i.e., break down into personal attacks. Such derailment has a negative impact on the healthy growth of cyberspace communities. The ability to predict whether ongoing conversations are likely to derail could provide valuable real-time insight to interlocutors and moderators. Prior approaches predict conversation derailment retrospectively without the ability to forestall the derailment proactively. Some works attempt to make dynamic prediction as the conversation develops, but fail to incorporate multisource information, such as conversation structure and distance to derailment. We propose a hierarchical transformer-based framework that combines utterance-level and conversation-level information to capture fine-grained contextual semantics. We propose a domain-adaptive pretraining objective to integrate conversational structure information and a multitask learning scheme to leverage the distance from each utterance to derailment. An evaluation of our framework on two conversation derailment datasets yields improvement over F1 score for the prediction of derailment. These results demonstrate the effectiveness of incorporating multisource information.
Digital twin in virtual reality for human-vehicle interactions in the context of autonomous driving
Mar 20, 2023

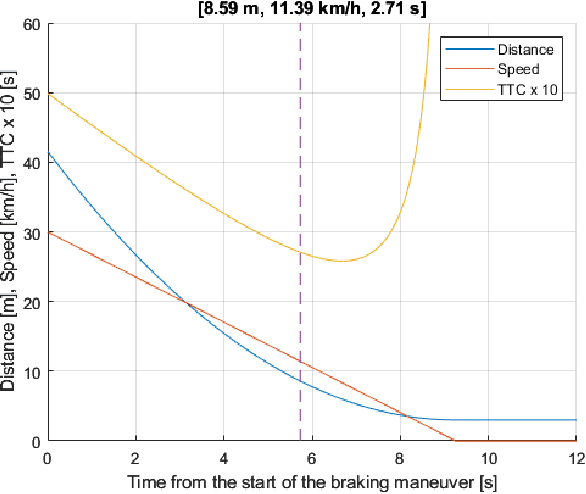

The traditional simulation methods present some limitations, such as the reality gap between simulated experiences and real-world performance. In the field of autonomous driving research, we propose the handling of an immersive virtual reality system for pedestrians to include in simulations real behaviors of agents that interact with the simulated environment in real time, to improve the quality of the virtual-world data and reduce the gap. In this paper we employ a digital twin to replicate a study on communication interfaces between autonomous vehicles and pedestrians, generating an equivalent virtual scenario to compare the results and establish qualitative and quantitative measurements of the discrepancy. The goal is to evaluate the effectiveness and acceptability of implicit and explicit forms of communication in both scenarios and to verify that the behavior carried out by the pedestrian inside the simulator through a virtual reality interface is directly comparable with their role performed in a real traffic situation.
Bridging Imitation and Online Reinforcement Learning: An Optimistic Tale
Mar 20, 2023
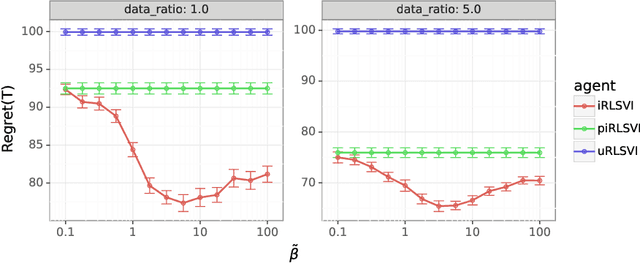
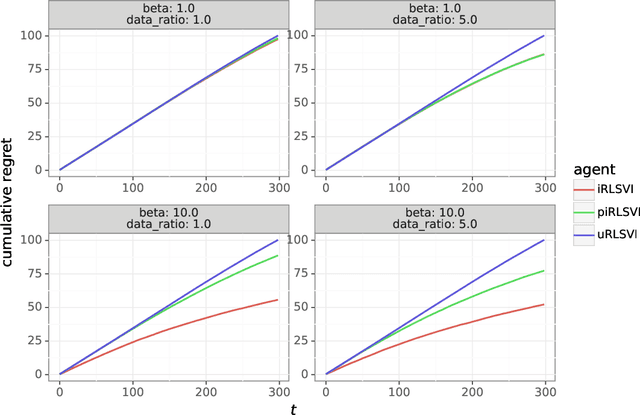
In this paper, we address the following problem: Given an offline demonstration dataset from an imperfect expert, what is the best way to leverage it to bootstrap online learning performance in MDPs. We first propose an Informed Posterior Sampling-based RL (iPSRL) algorithm that uses the offline dataset, and information about the expert's behavioral policy used to generate the offline dataset. Its cumulative Bayesian regret goes down to zero exponentially fast in N, the offline dataset size if the expert is competent enough. Since this algorithm is computationally impractical, we then propose the iRLSVI algorithm that can be seen as a combination of the RLSVI algorithm for online RL, and imitation learning. Our empirical results show that the proposed iRLSVI algorithm is able to achieve significant reduction in regret as compared to two baselines: no offline data, and offline dataset but used without information about the generative policy. Our algorithm bridges online RL and imitation learning for the first time.
Agent-based Simulation for Online Mental Health Matching
Mar 20, 2023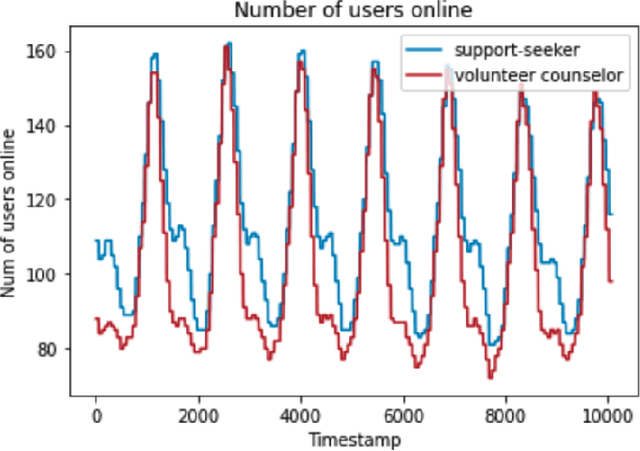
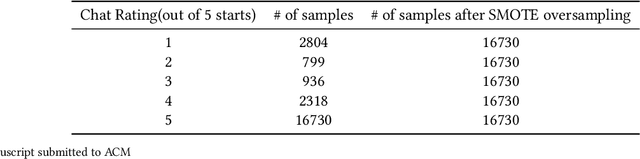
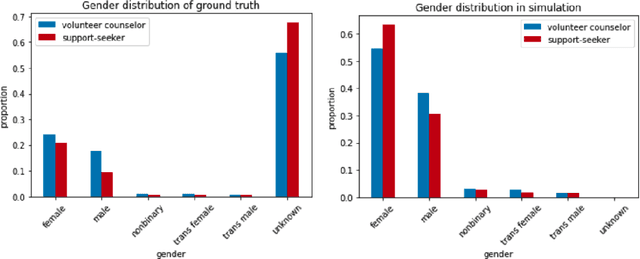
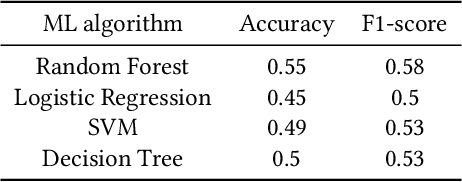
Online mental health communities (OMHCs) are an effective and accessible channel to give and receive social support for individuals with mental and emotional issues. However, a key challenge on these platforms is finding suitable partners to interact with given that mechanisms to match users are currently underdeveloped. In this paper, we collaborate with one of the world's largest OMHC to develop an agent-based simulation framework and explore the trade-offs in different matching algorithms. The simulation framework allows us to compare current mechanisms and new algorithmic matching policies on the platform, and observe their differing effects on a variety of outcome metrics. Our findings include that usage of the deferred-acceptance algorithm can significantly better the experiences of support-seekers in one-on-one chats while maintaining low waiting time. We note key design considerations that agent-based modeling reveals in the OMHC context, including the potential benefits of algorithmic matching on marginalized communities.
A Universal Question-Answering Platform for Knowledge Graphs
Mar 01, 2023
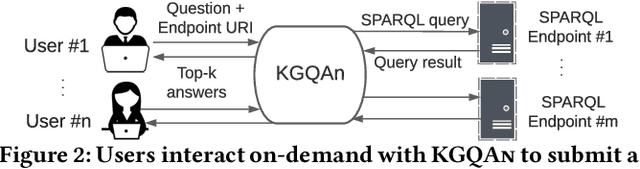

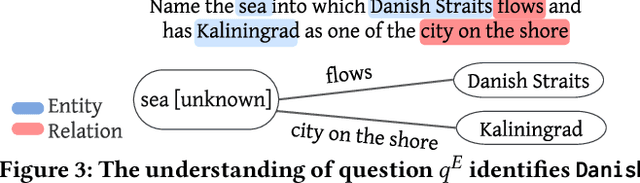
Knowledge from diverse application domains is organized as knowledge graphs (KGs) that are stored in RDF engines accessible in the web via SPARQL endpoints. Expressing a well-formed SPARQL query requires information about the graph structure and the exact URIs of its components, which is impractical for the average user. Question answering (QA) systems assist by translating natural language questions to SPARQL. Existing QA systems are typically based on application-specific human-curated rules, or require prior information, expensive pre-processing and model adaptation for each targeted KG. Therefore, they are hard to generalize to a broad set of applications and KGs. In this paper, we propose KGQAn, a universal QA system that does not need to be tailored to each target KG. Instead of curated rules, KGQAn introduces a novel formalization of question understanding as a text generation problem to convert a question into an intermediate abstract representation via a neural sequence-to-sequence model. We also develop a just-in-time linker that maps at query time the abstract representation to a SPARQL query for a specific KG, using only the publicly accessible APIs and the existing indices of the RDF store, without requiring any pre-processing. Our experiments with several real KGs demonstrate that KGQAn is easily deployed and outperforms by a large margin the state-of-the-art in terms of quality of answers and processing time, especially for arbitrary KGs, unseen during the training.