 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Non-separable Covariance Kernels for Spatiotemporal Gaussian Processes based on a Hybrid Spectral Method and the Harmonic Oscillator
Feb 19, 2023
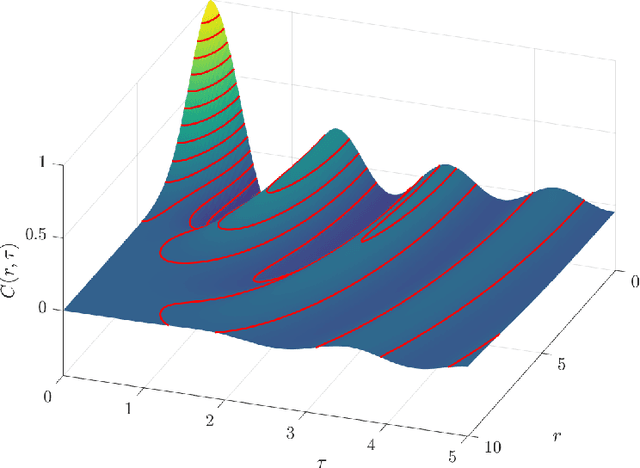
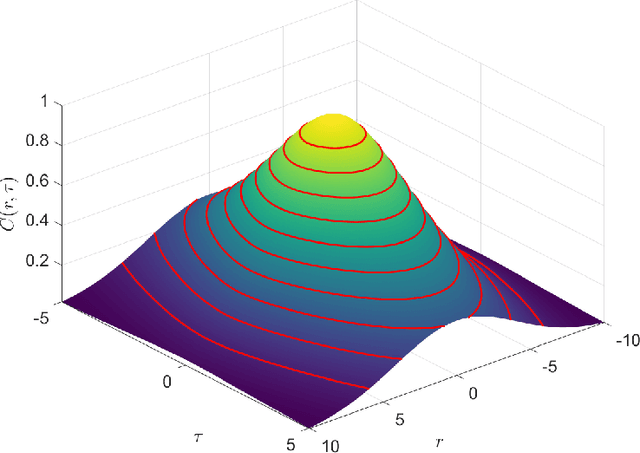
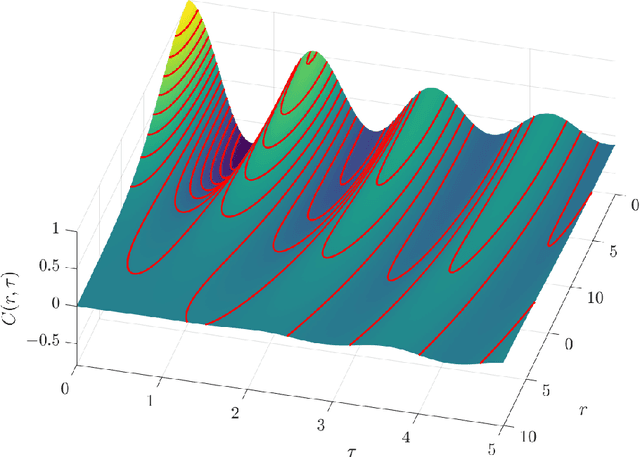
Gaussian processes provide a flexible, non-parametric framework for the approximation of functions in high-dimensional spaces. The covariance kernel is the main engine of Gaussian processes, incorporating correlations that underpin the predictive distribution. For applications with spatiotemporal datasets, suitable kernels should model joint spatial and temporal dependence. Separable space-time covariance kernels offer simplicity and computational efficiency. However, non-separable kernels include space-time interactions that better capture observed correlations. Most non-separable kernels that admit explicit expressions are based on mathematical considerations (admissibility conditions) rather than first-principles derivations. We present a hybrid spectral approach for generating covariance kernels which is based on physical arguments. We use this approach to derive a new class of physically motivated, non-separable covariance kernels which have their roots in the stochastic, linear, damped, harmonic oscillator (LDHO). The new kernels incorporate functions with both monotonic and oscillatory decay of space-time correlations. The LDHO covariance kernels involve space-time interactions which are introduced by dispersion relations that modulate the oscillator coefficients. We derive explicit relations for the spatiotemporal covariance kernels in the three oscillator regimes (underdamping, critical damping, overdamping) and investigate their properties.
Communicating human intent to a robotic companion by multi-type gesture sentences
Mar 08, 2023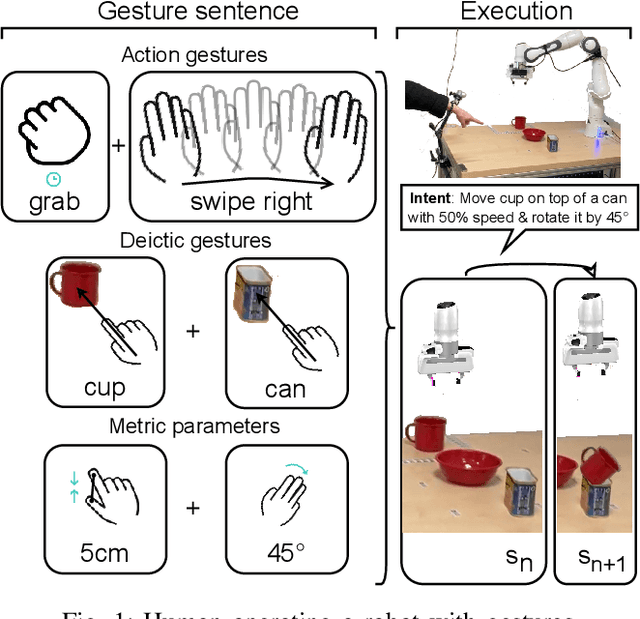
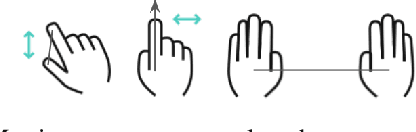
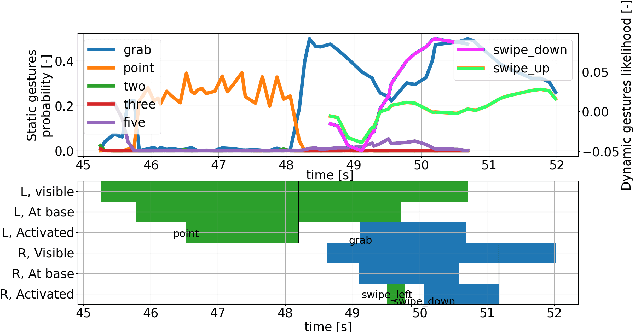
Human-Robot collaboration in home and industrial workspaces is on the rise. However, the communication between robots and humans is a bottleneck. Although people use a combination of different types of gestures to complement speech, only a few robotic systems utilize gestures for communication. In this paper, we propose a gesture pseudo-language and show how multiple types of gestures can be combined to express human intent to a robot (i.e., expressing both the desired action and its parameters - e.g., pointing to an object and showing that the object should be emptied into a bowl). The demonstrated gestures and the perceived table-top scene (object poses detected by CosyPose) are processed in real-time) to extract the human's intent. We utilize behavior trees to generate reactive robot behavior that handles various possible states of the world (e.g., a drawer has to be opened before an object is placed into it) and recovers from errors (e.g., when the scene changes). Furthermore, our system enables switching between direct teleoperation of the end-effector and high-level operation using the proposed gesture sentences. The system is evaluated on increasingly complex tasks using a real 7-DoF Franka Emika Panda manipulator. Controlling the robot via action gestures lowered the execution time by up to 60%, compared to direct teleoperation.
Multimodal Multi-User Surface Recognition with the Kernel Two-Sample Test
Mar 08, 2023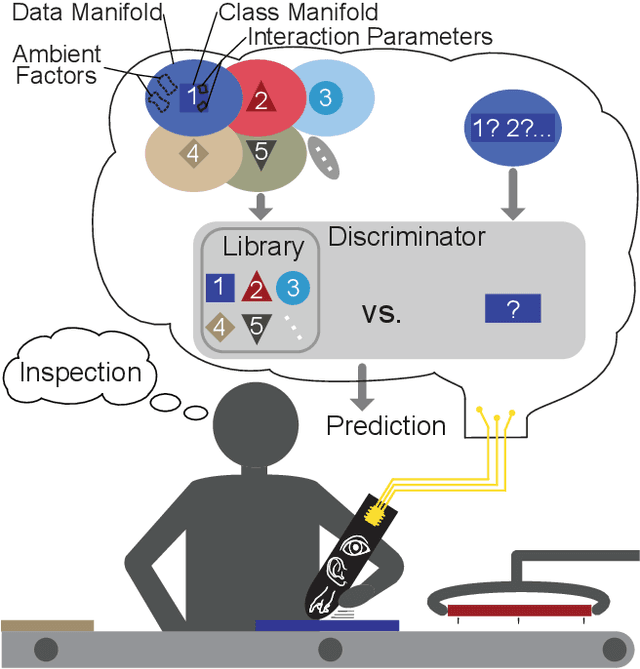
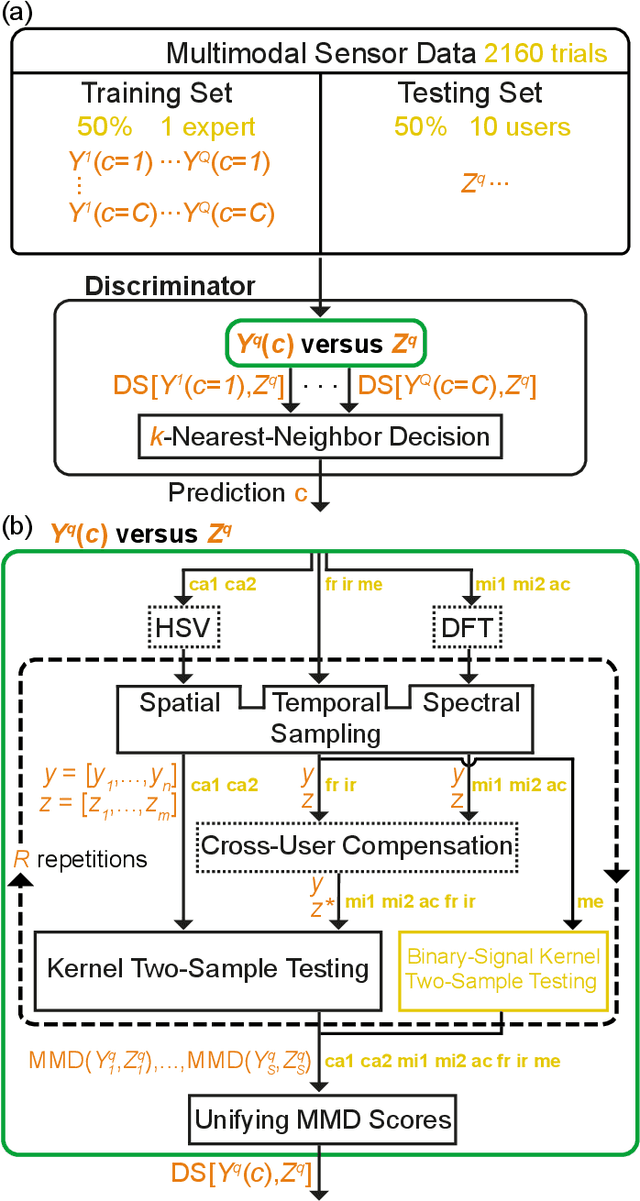
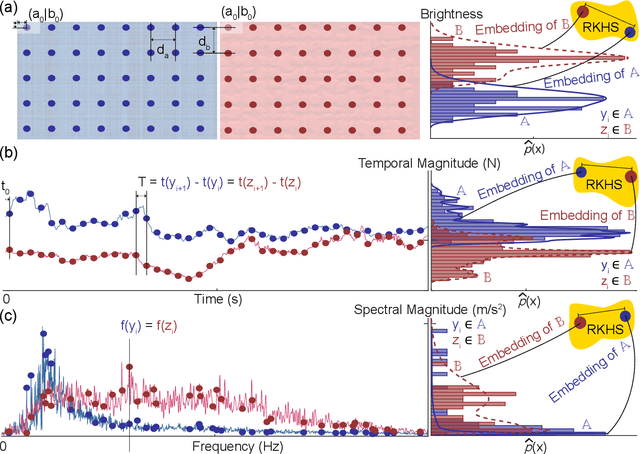

Machine learning and deep learning have been used extensively to classify physical surfaces through images and time-series contact data. However, these methods rely on human expertise and entail the time-consuming processes of data and parameter tuning. To overcome these challenges, we propose an easily implemented framework that can directly handle heterogeneous data sources for classification tasks. Our data-versus-data approach automatically quantifies distinctive differences in distributions in a high-dimensional space via kernel two-sample testing between two sets extracted from multimodal data (e.g., images, sounds, haptic signals). We demonstrate the effectiveness of our technique by benchmarking against expertly engineered classifiers for visual-audio-haptic surface recognition due to the industrial relevance, difficulty, and competitive baselines of this application; ablation studies confirm the utility of key components of our pipeline. As shown in our open-source code, we achieve 97.2% accuracy on a standard multi-user dataset with 108 surface classes, outperforming the state-of-the-art machine-learning algorithm by 6% on a more difficult version of the task. The fact that our classifier obtains this performance with minimal data processing in the standard algorithm setting reinforces the powerful nature of kernel methods for learning to recognize complex patterns.
Sleep Quality Prediction from Wearables using Convolution Neural Networks and Ensemble Learning
Mar 08, 2023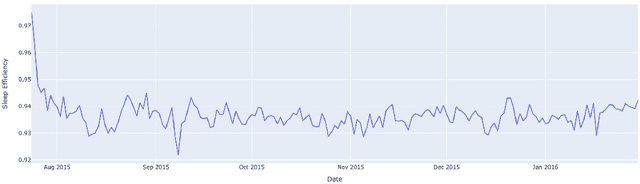
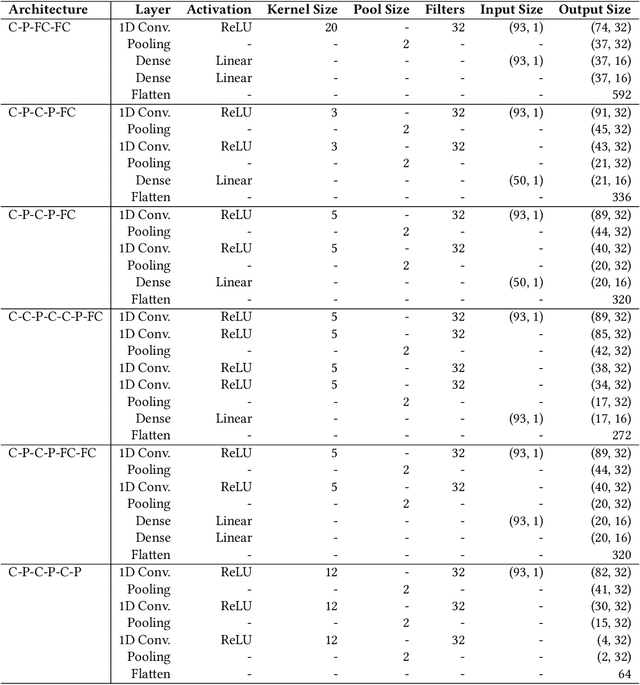
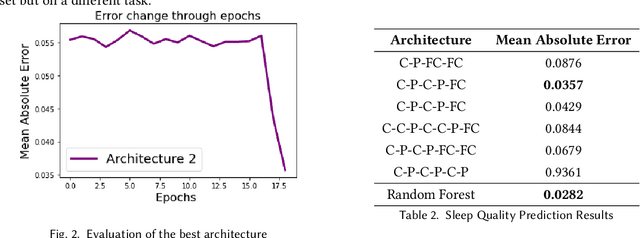
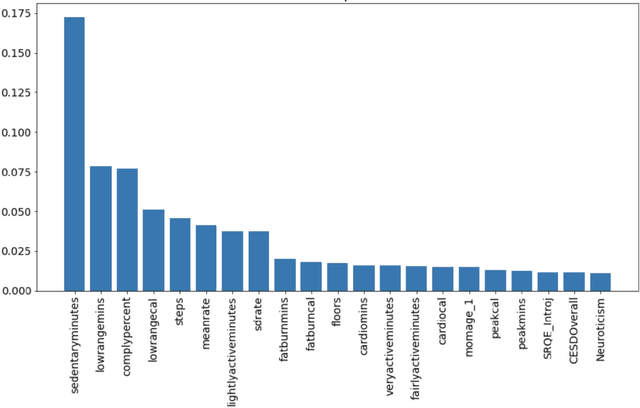
Sleep is among the most important factors affecting one's daily performance, well-being, and life quality. Nevertheless, it became possible to measure it in daily life in an unobtrusive manner with wearable devices. Rather than camera recordings and extraction of the state from the images, wrist-worn devices can measure directly via accelerometer, heart rate, and heart rate variability sensors. Some measured features can be as follows: time to bed, time out of bed, bedtime duration, minutes to fall asleep, and minutes after wake-up. There are several studies in the literature regarding sleep quality and stage prediction. However, they use only wearable data to predict or focus on the sleep stage. In this study, we use the NetHealth dataset, which is collected from 698 college students' via wearables, as well as surveys. Recently, there has been an advancement in deep learning algorithms, and they generally perform better than conventional machine learning techniques. Among them, Convolutional Neural Networks (CNN) have high performances. Thus, in this study, we apply different CNN architectures that have already performed well in the human activity recognition domain and compare their results. We also apply Random Forest (RF) since it performs best among the conventional methods. In future studies, we will compare them with other deep learning algorithms.
Dextrous Tactile In-Hand Manipulation Using a Modular Reinforcement Learning Architecture
Mar 08, 2023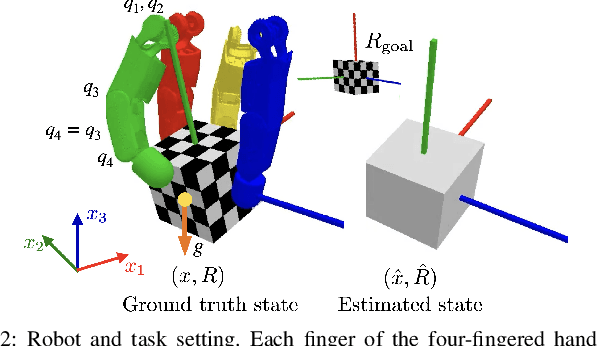
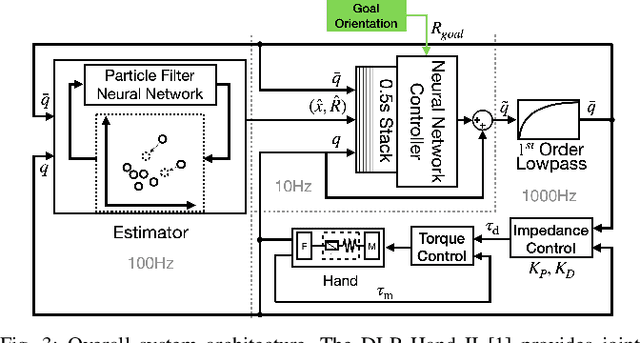
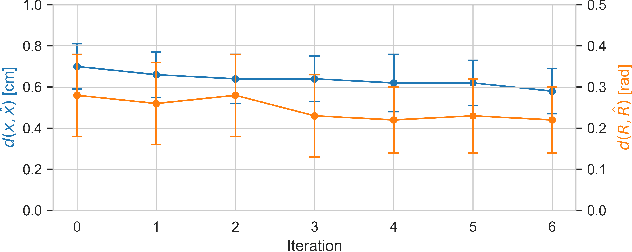
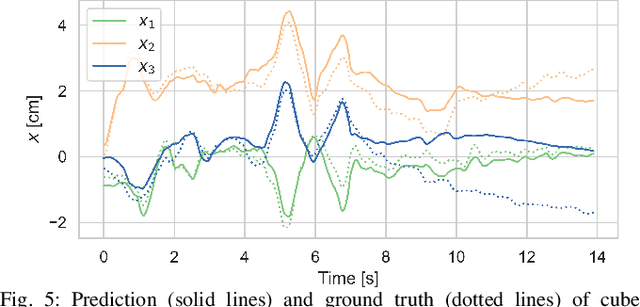
Dextrous in-hand manipulation with a multi-fingered robotic hand is a challenging task, esp. when performed with the hand oriented upside down, demanding permanent force-closure, and when no external sensors are used. For the task of reorienting an object to a given goal orientation (vs. infinitely spinning it around an axis), the lack of external sensors is an additional fundamental challenge as the state of the object has to be estimated all the time, e.g., to detect when the goal is reached. In this paper, we show that the task of reorienting a cube to any of the 24 possible goal orientations in a ${\pi}$/2-raster using the torque-controlled DLR-Hand II is possible. The task is learned in simulation using a modular deep reinforcement learning architecture: the actual policy has only a small observation time window of 0.5s but gets the cube state as an explicit input which is estimated via a deep differentiable particle filter trained on data generated by running the policy. In simulation, we reach a success rate of 92% while applying significant domain randomization. Via zero-shot Sim2Real-transfer on the real robotic system, all 24 goal orientations can be reached with a high success rate.
Auto-AVSR: Audio-Visual Speech Recognition with Automatic Labels
Mar 25, 2023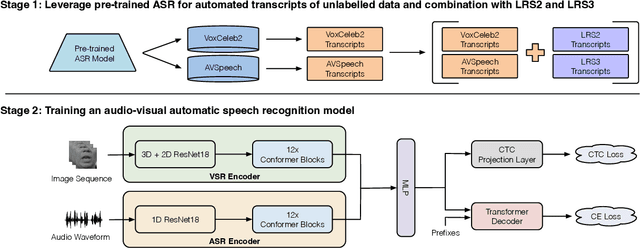
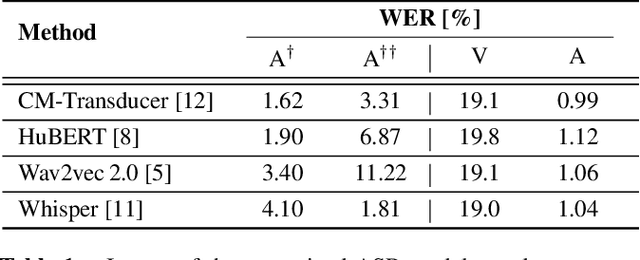
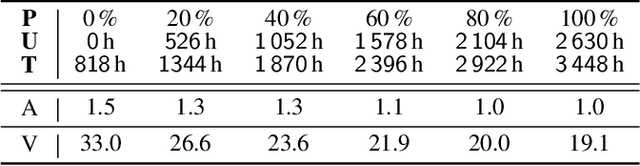
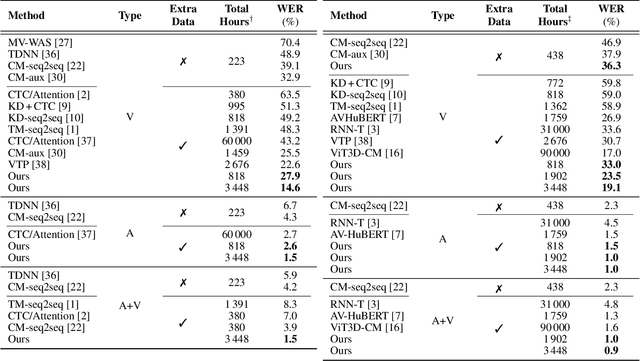
Audio-visual speech recognition has received a lot of attention due to its robustness against acoustic noise. Recently, the performance of automatic, visual, and audio-visual speech recognition (ASR, VSR, and AV-ASR, respectively) has been substantially improved, mainly due to the use of larger models and training sets. However, accurate labelling of datasets is time-consuming and expensive. Hence, in this work, we investigate the use of automatically-generated transcriptions of unlabelled datasets to increase the training set size. For this purpose, we use publicly-available pre-trained ASR models to automatically transcribe unlabelled datasets such as AVSpeech and VoxCeleb2. Then, we train ASR, VSR and AV-ASR models on the augmented training set, which consists of the LRS2 and LRS3 datasets as well as the additional automatically-transcribed data. We demonstrate that increasing the size of the training set, a recent trend in the literature, leads to reduced WER despite using noisy transcriptions. The proposed model achieves new state-of-the-art performance on AV-ASR on LRS2 and LRS3. In particular, it achieves a WER of 0.9% on LRS3, a relative improvement of 30% over the current state-of-the-art approach, and outperforms methods that have been trained on non-publicly available datasets with 26 times more training data.
Resolution Complete In-Place Object Retrieval given Known Object Models
Mar 25, 2023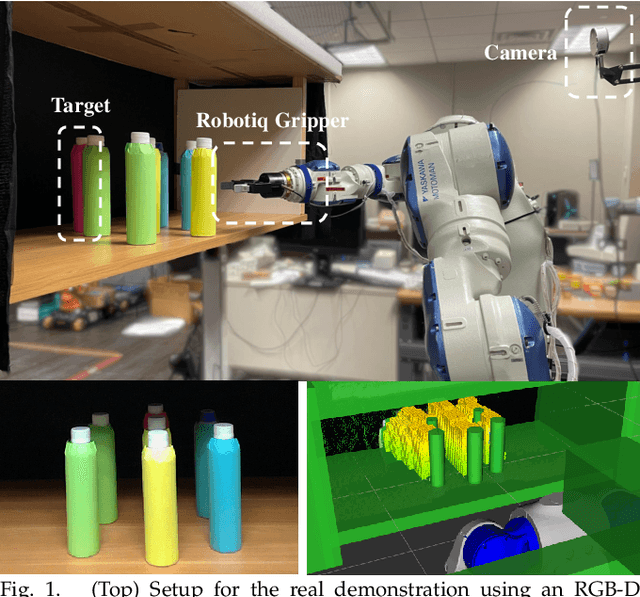
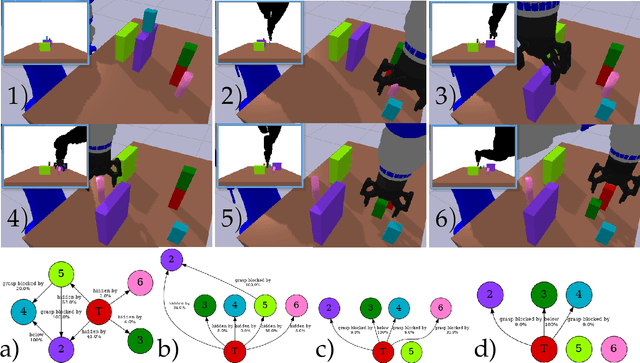

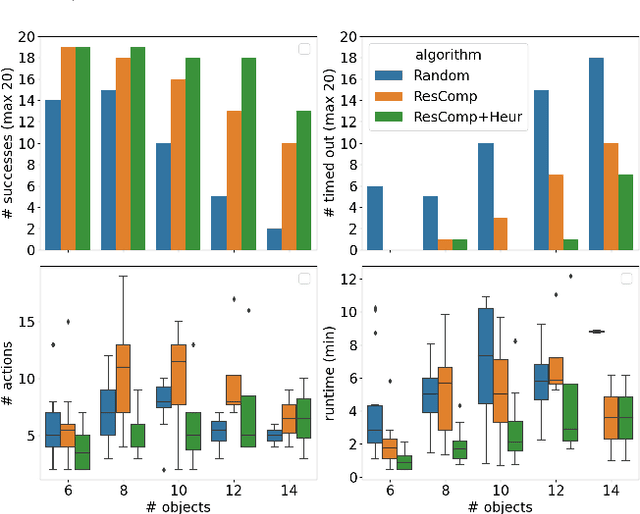
This work proposes a robot task planning framework for retrieving a target object in a confined workspace among multiple stacked objects that obstruct the target. The robot can use prehensile picking and in-workspace placing actions. The method assumes access to 3D models for the visible objects in the scene. The key contribution is in achieving desirable properties, i.e., to provide (a) safety, by avoiding collisions with sensed obstacles, objects, and occluded regions, and (b) resolution completeness (RC) - or probabilistic completeness (PC) depending on implementation - which indicates a solution will be eventually found (if it exists) as the resolution of algorithmic parameters increases. A heuristic variant of the basic RC algorithm is also proposed to solve the task more efficiently while retaining the desirable properties. Simulation results compare using random picking and placing operations against the basic RC algorithm that reasons about object dependency as well as its heuristic variant. The success rate is higher for the RC approaches given the same amount of time. The heuristic variant is able to solve the problem even more efficiently than the basic approach. The integration of the RC algorithm with perception, where an RGB-D sensor detects the objects as they are being moved, enables real robot demonstrations of safely retrieving target objects from a cluttered shelf.
GAN-RXA: A Practical Scalable Solution to Receiver-Agnostic Transmitter Fingerprinting
Mar 25, 2023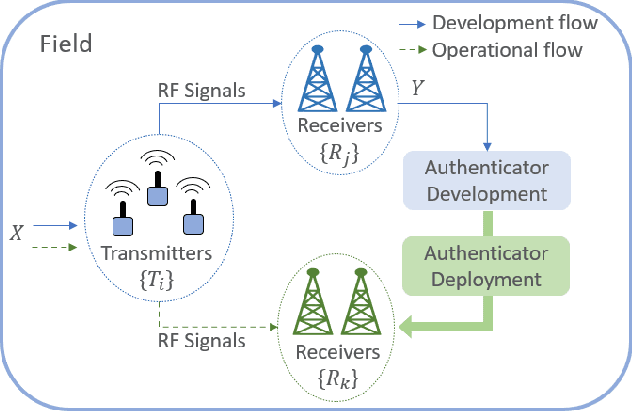
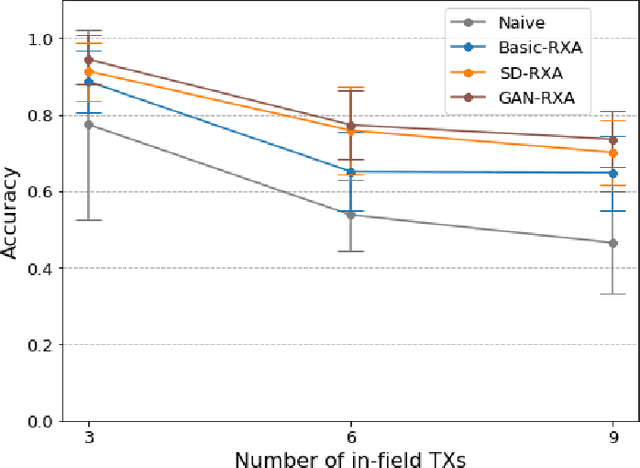
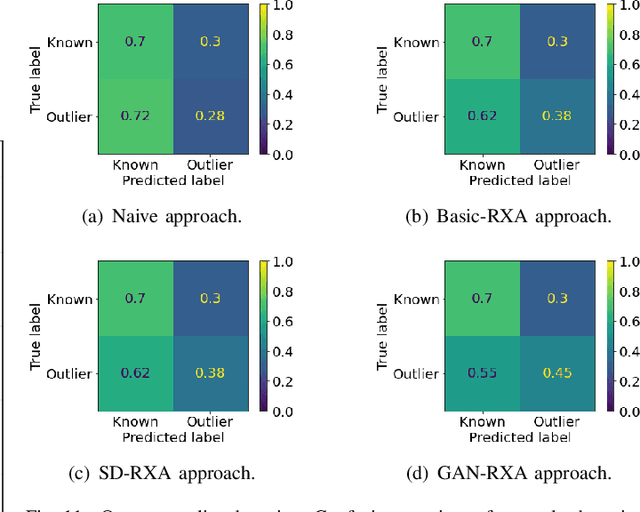
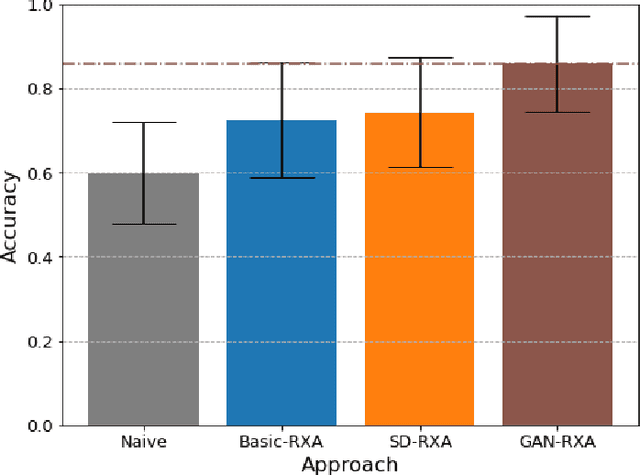
Radio frequency fingerprinting has been proposed for device identification. However, experimental studies also demonstrated its sensitivity to deployment changes. Recent works have addressed channel impacts by developing robust algorithms accounting for time and location variability, but the impacts of receiver impairments on transmitter fingerprints are yet to be solved. In this work, we investigat the receiver-agnostic transmitter fingerprinting problem, and propose a novel two-stage supervised learning framework (RXA) to address it. In the first stage, our approach calibrates a receiver-agnostic transmitter feature-extractor. We also propose two deep-learning approaches (SD-RXA and GAN-RXA) in this first stage to improve the receiver-agnostic property of the RXA framework. In the second stage, the calibrated feature-extractor is utilized to train a transmitter classifier with only one receiver. We evaluate the proposed approaches on transmitter identification problem using a large-scale WiFi dataset. We show that when a trained transmitter-classifier is deployed on new receivers, the RXA framework can improve the classification accuracy by 19.5%, and the outlier detection rate by 10.0% compared to a naive approach without calibration. Moreover, GAN-RXA can further increase the closed-set classification accuracy by 5.0%, and the outlier detection rate by 7.5% compared to the RXA approach.
ChatGPT for Programming Numerical Methods
Mar 25, 2023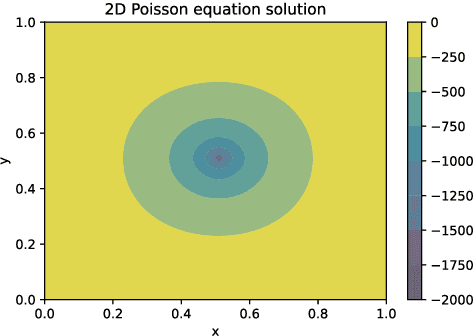
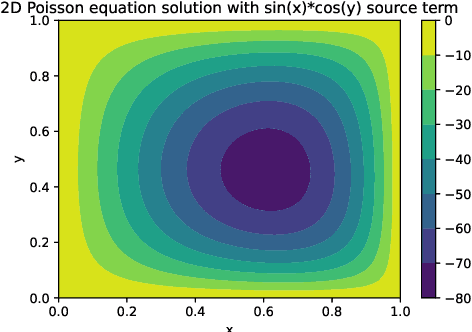
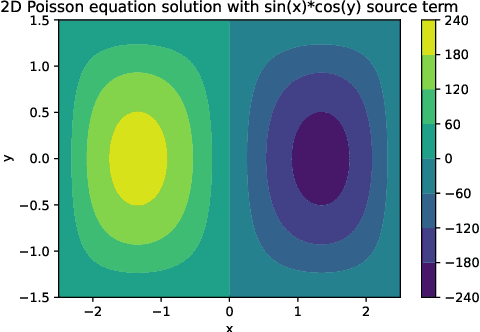
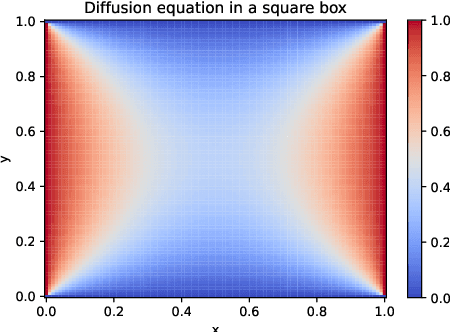
ChatGPT is a large language model recently released by the OpenAI company. In this technical report, we explore for the first time the capability of ChatGPT for programming numerical algorithms. Specifically, we examine the capability of GhatGPT for generating codes for numerical algorithms in different programming languages, for debugging and improving written codes by users, for completing missed parts of numerical codes, rewriting available codes in other programming languages, and for parallelizing serial codes. Additionally, we assess if ChatGPT can recognize if given codes are written by humans or machines. To reach this goal, we consider a variety of mathematical problems such as the Poisson equation, the diffusion equation, the incompressible Navier-Stokes equations, compressible inviscid flow, eigenvalue problems, solving linear systems of equations, storing sparse matrices, etc. Furthermore, we exemplify scientific machine learning such as physics-informed neural networks and convolutional neural networks with applications to computational physics. Through these examples, we investigate the successes, failures, and challenges of ChatGPT. Examples of failures are producing singular matrices, operations on arrays with incompatible sizes, programming interruption for relatively long codes, etc. Our outcomes suggest that ChatGPT can successfully program numerical algorithms in different programming languages, but certain limitations and challenges exist that require further improvement of this machine learning model.
AdvCheck: Characterizing Adversarial Examples via Local Gradient Checking
Mar 25, 2023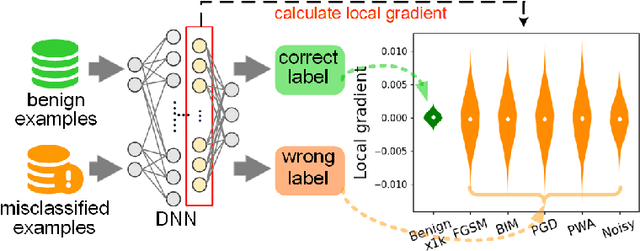

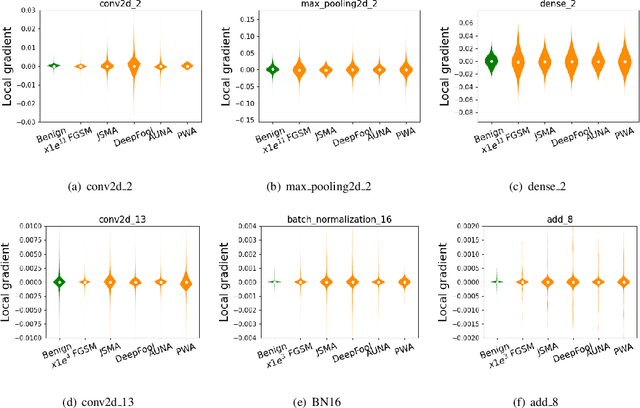
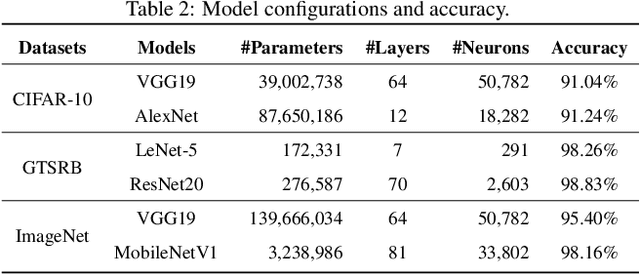
Deep neural networks (DNNs) are vulnerable to adversarial examples, which may lead to catastrophe in security-critical domains. Numerous detection methods are proposed to characterize the feature uniqueness of adversarial examples, or to distinguish DNN's behavior activated by the adversarial examples. Detections based on features cannot handle adversarial examples with large perturbations. Besides, they require a large amount of specific adversarial examples. Another mainstream, model-based detections, which characterize input properties by model behaviors, suffer from heavy computation cost. To address the issues, we introduce the concept of local gradient, and reveal that adversarial examples have a quite larger bound of local gradient than the benign ones. Inspired by the observation, we leverage local gradient for detecting adversarial examples, and propose a general framework AdvCheck. Specifically, by calculating the local gradient from a few benign examples and noise-added misclassified examples to train a detector, adversarial examples and even misclassified natural inputs can be precisely distinguished from benign ones. Through extensive experiments, we have validated the AdvCheck's superior performance to the state-of-the-art (SOTA) baselines, with detection rate ($\sim \times 1.2$) on general adversarial attacks and ($\sim \times 1.4$) on misclassified natural inputs on average, with average 1/500 time cost. We also provide interpretable results for successful detection.