 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Flipped Classroom: Effective Teaching for Time Series Forecasting
Oct 17, 2022
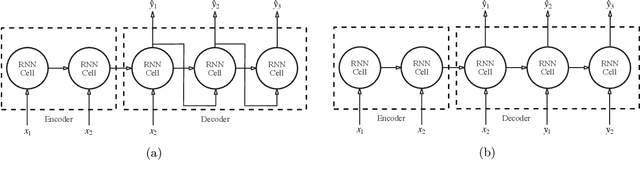
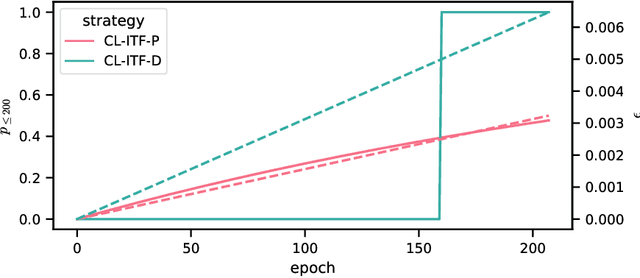
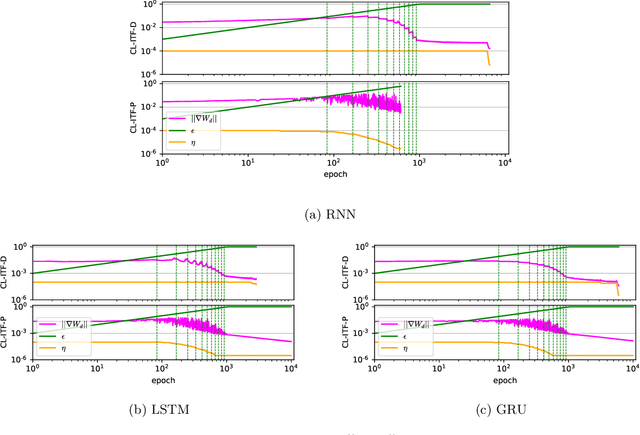
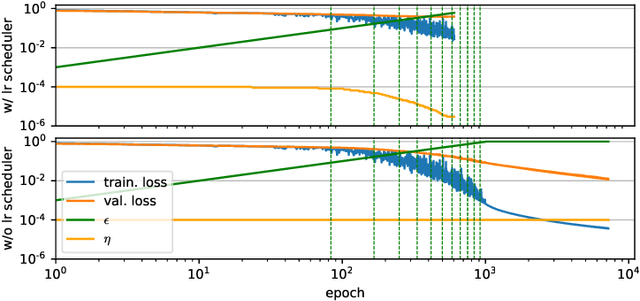
Sequence-to-sequence models based on LSTM and GRU are a most popular choice for forecasting time series data reaching state-of-the-art performance. Training such models can be delicate though. The two most common training strategies within this context are teacher forcing (TF) and free running (FR). TF can be used to help the model to converge faster but may provoke an exposure bias issue due to a discrepancy between training and inference phase. FR helps to avoid this but does not necessarily lead to better results, since it tends to make the training slow and unstable instead. Scheduled sampling was the first approach tackling these issues by picking the best from both worlds and combining it into a curriculum learning (CL) strategy. Although scheduled sampling seems to be a convincing alternative to FR and TF, we found that, even if parametrized carefully, scheduled sampling may lead to premature termination of the training when applied for time series forecasting. To mitigate the problems of the above approaches we formalize CL strategies along the training as well as the training iteration scale. We propose several new curricula, and systematically evaluate their performance in two experimental sets. For our experiments, we utilize six datasets generated from prominent chaotic systems. We found that the newly proposed increasing training scale curricula with a probabilistic iteration scale curriculum consistently outperforms previous training strategies yielding an NRMSE improvement of up to 81% over FR or TF training. For some datasets we additionally observe a reduced number of training iterations. We observed that all models trained with the new curricula yield higher prediction stability allowing for longer prediction horizons.
Sparse in Space and Time: Audio-visual Synchronisation with Trainable Selectors
Oct 13, 2022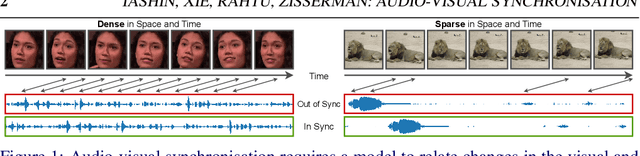

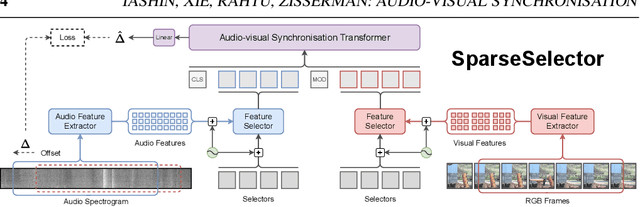
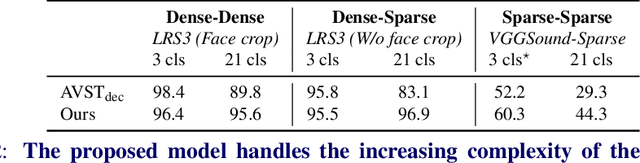
The objective of this paper is audio-visual synchronisation of general videos 'in the wild'. For such videos, the events that may be harnessed for synchronisation cues may be spatially small and may occur only infrequently during a many seconds-long video clip, i.e. the synchronisation signal is 'sparse in space and time'. This contrasts with the case of synchronising videos of talking heads, where audio-visual correspondence is dense in both time and space. We make four contributions: (i) in order to handle longer temporal sequences required for sparse synchronisation signals, we design a multi-modal transformer model that employs 'selectors' to distil the long audio and visual streams into small sequences that are then used to predict the temporal offset between streams. (ii) We identify artefacts that can arise from the compression codecs used for audio and video and can be used by audio-visual models in training to artificially solve the synchronisation task. (iii) We curate a dataset with only sparse in time and space synchronisation signals; and (iv) the effectiveness of the proposed model is shown on both dense and sparse datasets quantitatively and qualitatively. Project page: v-iashin.github.io/SparseSync
DeepTIMe: Deep Time-Index Meta-Learning for Non-Stationary Time-Series Forecasting
Jul 14, 2022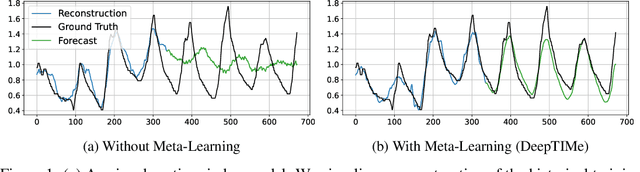
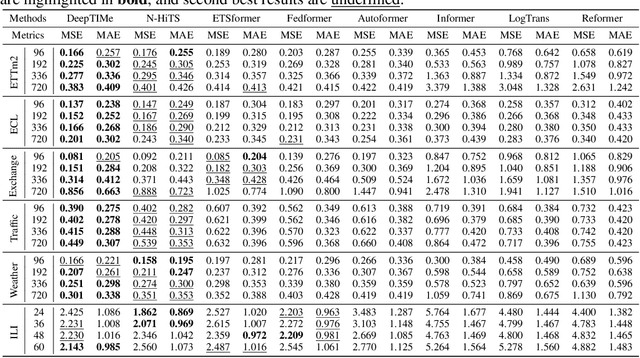
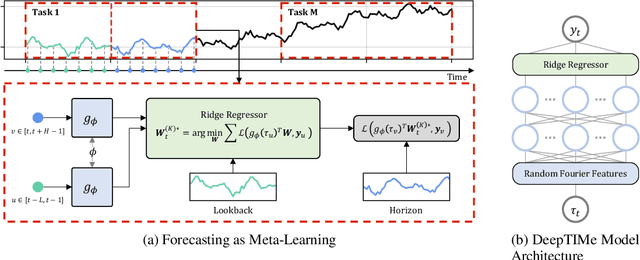
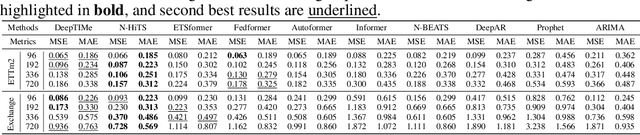
Deep learning has been actively applied to time-series forecasting, leading to a deluge of new autoregressive model architectures. Yet, despite the attractive properties of time-index based models, such as being a continuous signal function over time leading to smooth representations, little attention has been given to them. Indeed, while naive deep time-index based models are far more expressive than the manually predefined function representations of classical time-index based models, they are inadequate for forecasting due to the lack of inductive biases, and the non-stationarity of time-series. In this paper, we propose DeepTIMe, a deep time-index based model trained via a meta-learning formulation which overcomes these limitations, yielding an efficient and accurate forecasting model. Extensive experiments on real world datasets demonstrate that our approach achieves competitive results with state-of-the-art methods, and is highly efficient. Code is available at https://github.com/salesforce/DeepTIMe.
On Frequency-Domain Implementation of Digital FIR Filters Using Overlap-Add and Overlap-Save Techniques
Feb 17, 2023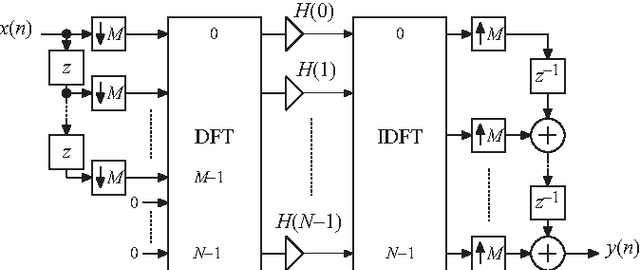
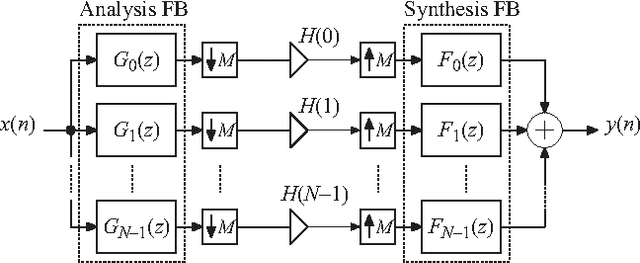
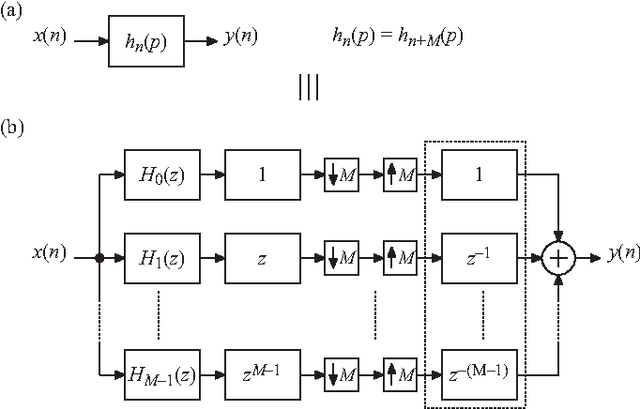
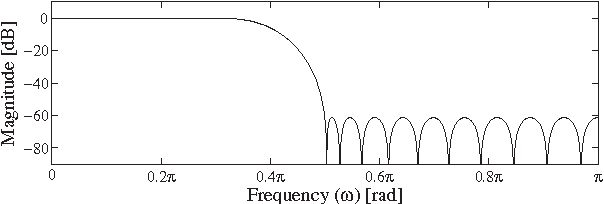
In this paper, new insights in frequency-domain implementations of digital finite-length impulse response filtering (linear convolution) using overlap-add and overlap-save techniques are provided. It is shown that, in practical finite-wordlength implementations, the overall system corresponds to a time-varying system that can be represented in essentially two different ways. One way is to represent the system with a distortion function and aliasing functions, which in this paper is derived from multirate filter bank representations. The other way is to use a periodically time-varying impulse-response representation or, equivalently, a set of time-invariant impulse responses and the corresponding frequency responses. The paper provides systematic derivations and analyses of these representations along with filter impulse response properties and design examples. The representations are particularly useful when analyzing the effect of coefficient quantizations as well as the use of shorter DFT lengths than theoretically required. A comprehensive computational-complexity analysis is also provided, and accurate formulas for estimating the optimal DFT lengths for given filter lengths are derived. Using optimal DFT lengths, it is shown that the frequency-domain implementations have lower computational complexities (multiplication rates) than the corresponding time-domain implementations for filter lengths that are shorter than those reported earlier in the literature. In particular, for general (unsymmetric) filters, the frequency-domain implementations are shown to be more efficient for all filter lengths. This opens up for new considerations when comparing complexities of different filter implementations.
Sibling-Attack: Rethinking Transferable Adversarial Attacks against Face Recognition
Mar 22, 2023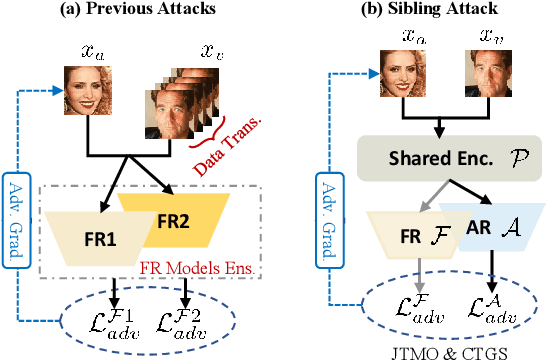


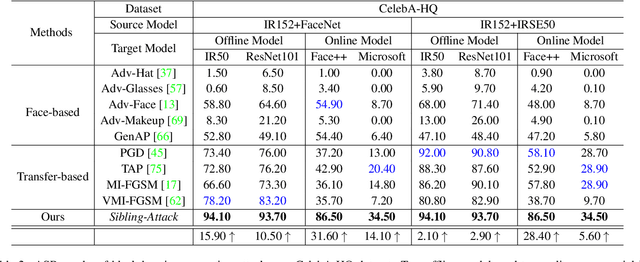
A hard challenge in developing practical face recognition (FR) attacks is due to the black-box nature of the target FR model, i.e., inaccessible gradient and parameter information to attackers. While recent research took an important step towards attacking black-box FR models through leveraging transferability, their performance is still limited, especially against online commercial FR systems that can be pessimistic (e.g., a less than 50% ASR--attack success rate on average). Motivated by this, we present Sibling-Attack, a new FR attack technique for the first time explores a novel multi-task perspective (i.e., leveraging extra information from multi-correlated tasks to boost attacking transferability). Intuitively, Sibling-Attack selects a set of tasks correlated with FR and picks the Attribute Recognition (AR) task as the task used in Sibling-Attack based on theoretical and quantitative analysis. Sibling-Attack then develops an optimization framework that fuses adversarial gradient information through (1) constraining the cross-task features to be under the same space, (2) a joint-task meta optimization framework that enhances the gradient compatibility among tasks, and (3) a cross-task gradient stabilization method which mitigates the oscillation effect during attacking. Extensive experiments demonstrate that Sibling-Attack outperforms state-of-the-art FR attack techniques by a non-trivial margin, boosting ASR by 12.61% and 55.77% on average on state-of-the-art pre-trained FR models and two well-known, widely used commercial FR systems.
Diffuse-Denoise-Count: Accurate Crowd-Counting with Diffusion Models
Mar 22, 2023Crowd counting is a key aspect of crowd analysis and has been typically accomplished by estimating a crowd-density map and summing over the density values. However, this approach suffers from background noise accumulation and loss of density due to the use of broad Gaussian kernels to create the ground truth density maps. This issue can be overcome by narrowing the Gaussian kernel. However, existing approaches perform poorly when trained with such ground truth density maps. To overcome this limitation, we propose using conditional diffusion models to predict density maps, as diffusion models are known to model complex distributions well and show high fidelity to training data during crowd-density map generation. Furthermore, as the intermediate time steps of the diffusion process are noisy, we incorporate a regression branch for direct crowd estimation only during training to improve the feature learning. In addition, owing to the stochastic nature of the diffusion model, we introduce producing multiple density maps to improve the counting performance contrary to the existing crowd counting pipelines. Further, we also differ from the density summation and introduce contour detection followed by summation as the counting operation, which is more immune to background noise. We conduct extensive experiments on public datasets to validate the effectiveness of our method. Specifically, our novel crowd-counting pipeline improves the error of crowd-counting by up to $6\%$ on JHU-CROWD++ and up to $7\%$ on UCF-QNRF.
RangedIK: An Optimization-based Robot Motion Generation Method for Ranged-Goal Tasks
Feb 27, 2023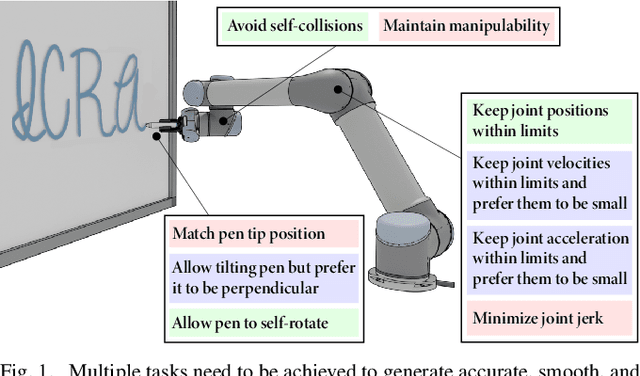
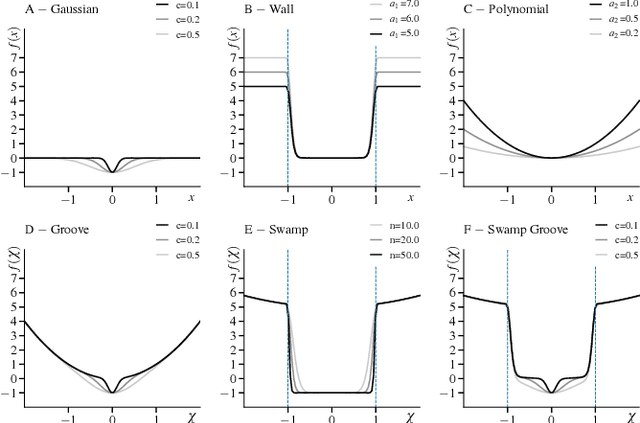
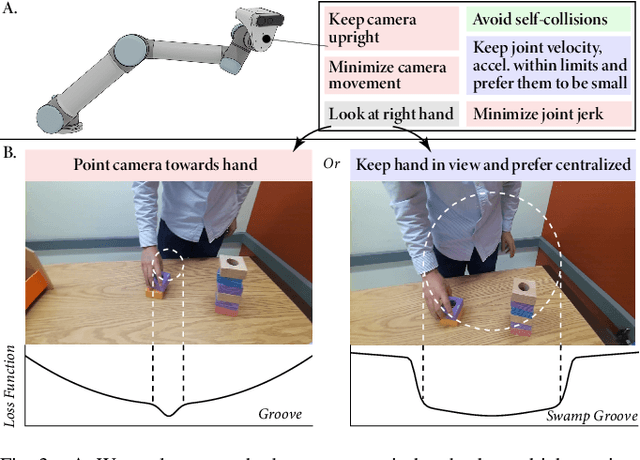
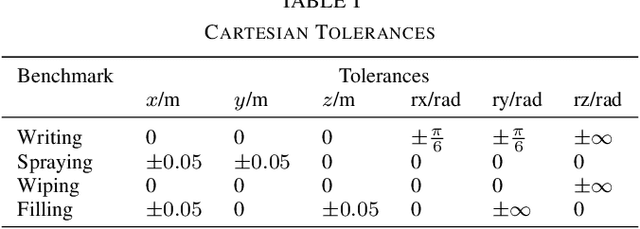
Generating feasible robot motions in real-time requires achieving multiple tasks (i.e., kinematic requirements) simultaneously. These tasks can have a specific goal, a range of equally valid goals, or a range of acceptable goals with a preference toward a specific goal. To satisfy multiple and potentially competing tasks simultaneously, it is important to exploit the flexibility afforded by tasks with a range of goals. In this paper, we propose a real-time motion generation method that accommodates all three categories of tasks within a single, unified framework and leverages the flexibility of tasks with a range of goals to accommodate other tasks. Our method incorporates tasks in a weighted-sum multiple-objective optimization structure and uses barrier methods with novel loss functions to encode the valid range of a task. We demonstrate the effectiveness of our method through a simulation experiment that compares it to state-of-the-art alternative approaches, and by demonstrating it on a physical camera-in-hand robot that shows that our method enables the robot to achieve smooth and feasible camera motions.
FRoGGeR: Fast Robust Grasp Generation via the Min-Weight Metric
Feb 27, 2023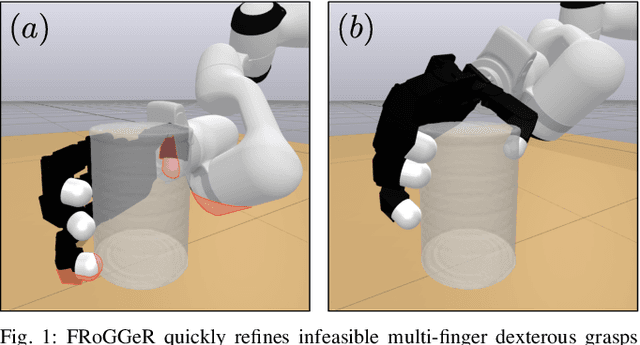
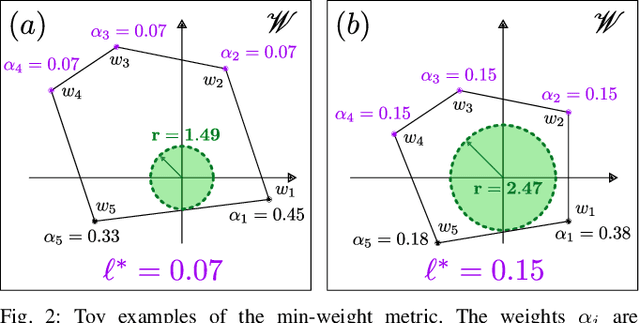
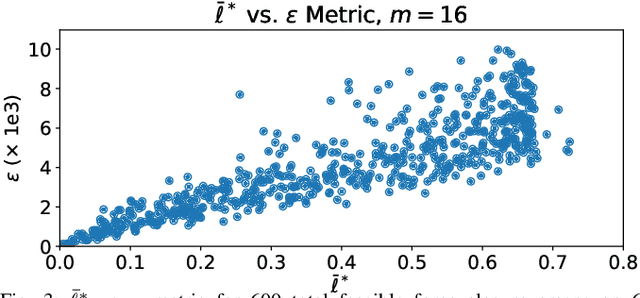
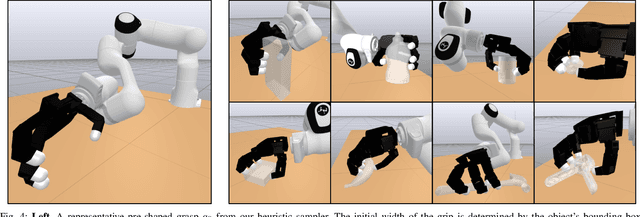
Many approaches to grasp synthesis optimize analytic quality metrics that measure grasp robustness based on finger placements and local surface geometry. However, generating feasible dexterous grasps by optimizing these metrics is slow, often taking minutes. To address this issue, this paper presents FRoGGeR: a method that quickly generates robust precision grasps using the min-weight metric, a novel, almost-everywhere differentiable approximation of the classical epsilon grasp metric. The min-weight metric is simple and interpretable, provides a reasonable measure of grasp robustness, and admits numerically efficient gradients for smooth optimization. We leverage these properties to rapidly synthesize collision-free robust grasps - typically in less than a second. FRoGGeR can refine the candidate grasps generated by other methods (heuristic, data-driven, etc.) and is compatible with many object representations (SDFs, meshes, etc.). We study FRoGGeR's performance on over 40 objects drawn from the YCB dataset, outperforming a competitive baseline in computation time, feasibility rate of grasp synthesis, and picking success in simulation. We conclude that FRoGGeR is fast: it has a median synthesis time of 0.834s over hundreds of experiments.
Dynamic Resource Allocation for Metaverse Applications with Deep Reinforcement Learning
Feb 27, 2023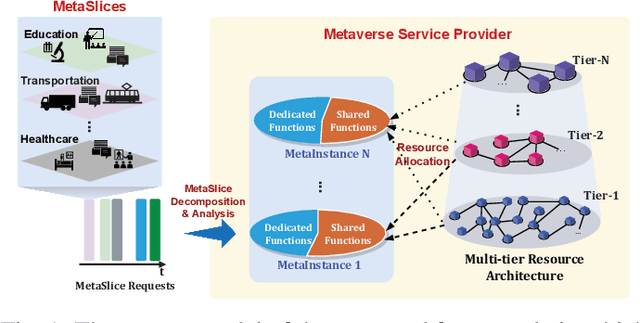
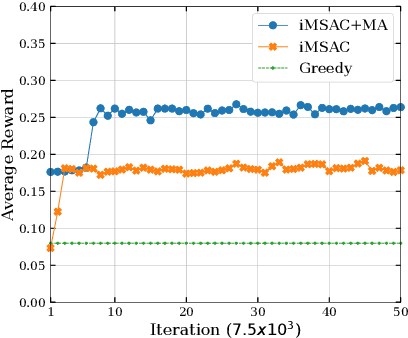
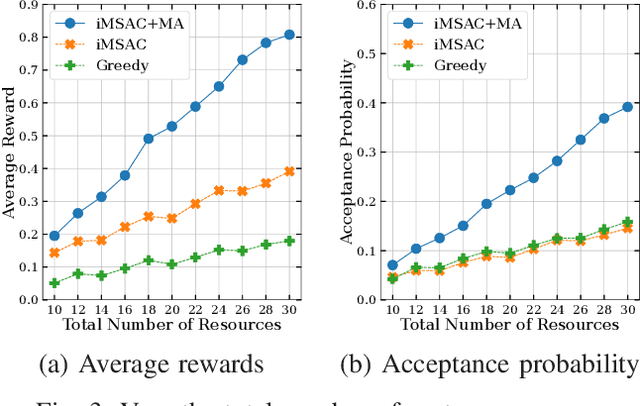
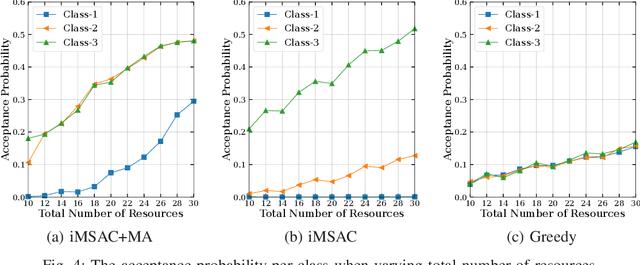
This work proposes a novel framework to dynamically and effectively manage and allocate different types of resources for Metaverse applications, which are forecasted to demand massive resources of various types that have never been seen before. Specifically, by studying functions of Metaverse applications, we first propose an effective solution to divide applications into groups, namely MetaInstances, where common functions can be shared among applications to enhance resource usage efficiency. Then, to capture the real-time, dynamic, and uncertain characteristics of request arrival and application departure processes, we develop a semi-Markov decision process-based framework and propose an intelligent algorithm that can gradually learn the optimal admission policy to maximize the revenue and resource usage efficiency for the Metaverse service provider and at the same time enhance the Quality-of-Service for Metaverse users. Extensive simulation results show that our proposed approach can achieve up to 120% greater revenue for the Metaverse service providers and up to 178.9% higher acceptance probability for Metaverse application requests than those of other baselines.
PSVT: End-to-End Multi-person 3D Pose and Shape Estimation with Progressive Video Transformers
Mar 16, 2023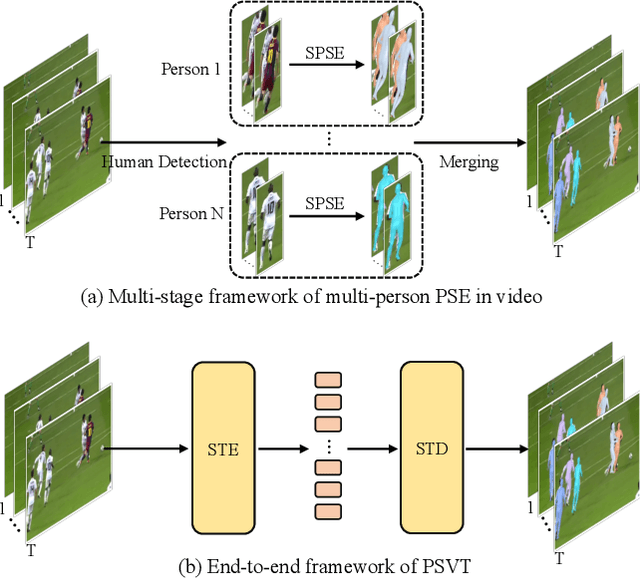
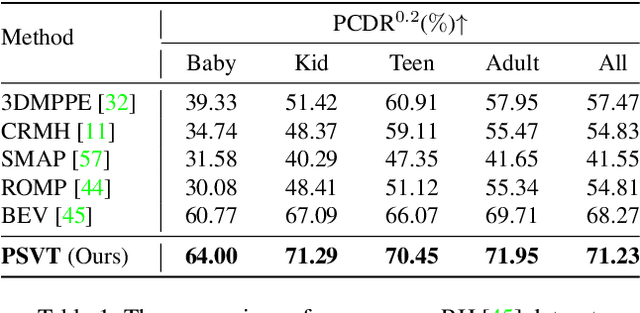
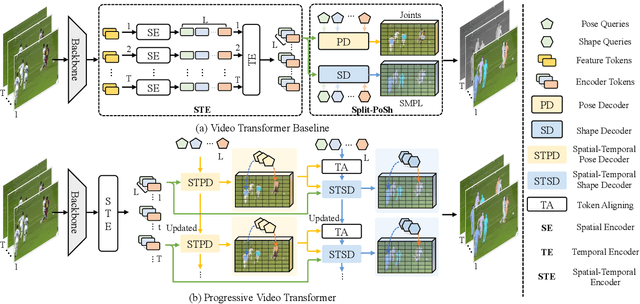
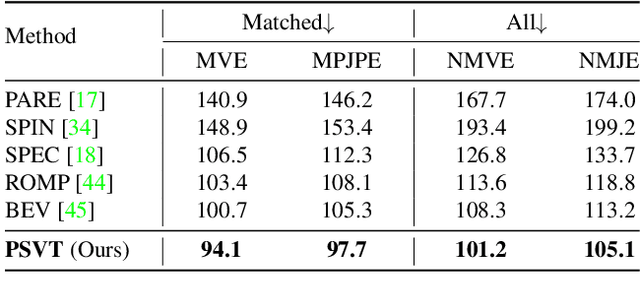
Existing methods of multi-person video 3D human Pose and Shape Estimation (PSE) typically adopt a two-stage strategy, which first detects human instances in each frame and then performs single-person PSE with temporal model. However, the global spatio-temporal context among spatial instances can not be captured. In this paper, we propose a new end-to-end multi-person 3D Pose and Shape estimation framework with progressive Video Transformer, termed PSVT. In PSVT, a spatio-temporal encoder (STE) captures the global feature dependencies among spatial objects. Then, spatio-temporal pose decoder (STPD) and shape decoder (STSD) capture the global dependencies between pose queries and feature tokens, shape queries and feature tokens, respectively. To handle the variances of objects as time proceeds, a novel scheme of progressive decoding is used to update pose and shape queries at each frame. Besides, we propose a novel pose-guided attention (PGA) for shape decoder to better predict shape parameters. The two components strengthen the decoder of PSVT to improve performance. Extensive experiments on the four datasets show that PSVT achieves stage-of-the-art results.