 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Collaborative Trolley Transportation System with Autonomous Nonholonomic Robots
Mar 12, 2023

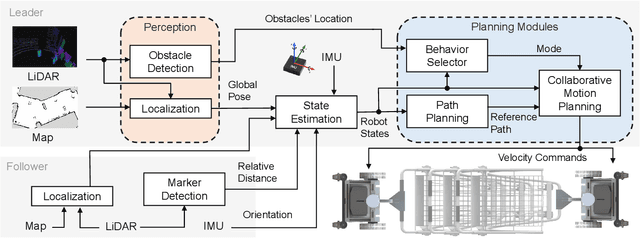
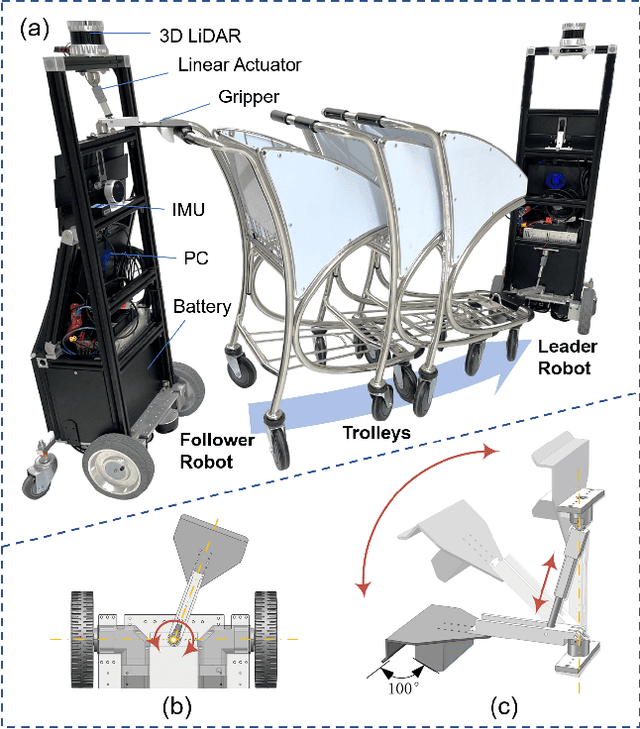
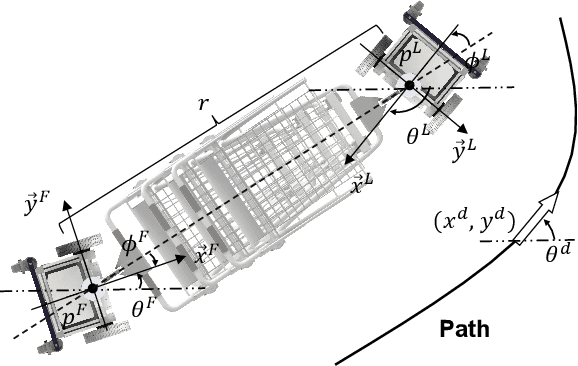
Cooperative object transportation using multiple robots has been intensively studied in the control and robotics literature, but most approaches are either only applicable to omnidirectional robots or lack a complete navigation and decision-making framework that operates in real time. This paper presents an autonomous nonholonomic multi-robot system and an end-to-end hierarchical autonomy framework for collaborative luggage trolley transportation. This framework finds kinematic-feasible paths, computes online motion plans, and provides feedback that enables the multi-robot system to handle long lines of luggage trolleys and navigate obstacles and pedestrians while dealing with multiple inherently complex and coupled constraints. We demonstrate the designed collaborative trolley transportation system through practical transportation tasks, and the experiment results reveal their effectiveness and reliability in complex and dynamic environments.
Constrained Bayesian Optimization for Automatic Underwater Vehicle Hull Design
Mar 15, 2023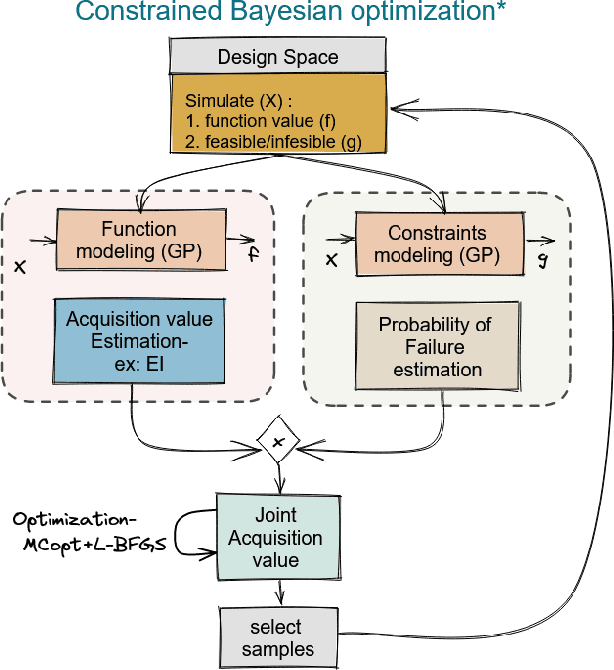
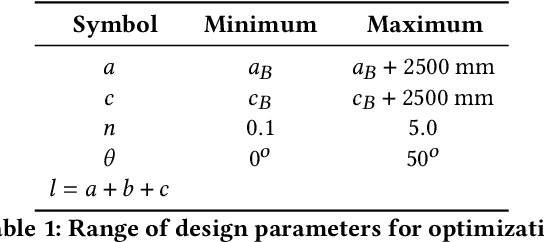
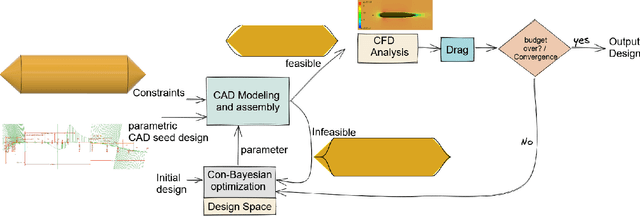
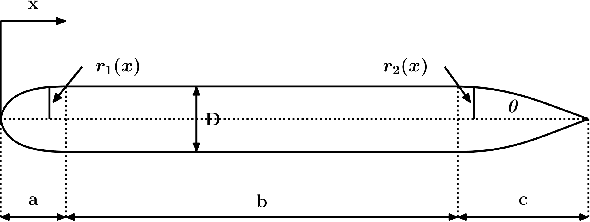
Automatic underwater vehicle hull Design optimization is a complex engineering process for generating a UUV hull with optimized properties on a given requirement. First, it involves the integration of involved computationally complex engineering simulation tools. Second, it needs integration of a sample efficient optimization framework with the integrated toolchain. To this end, we integrated the CAD tool called FreeCAD with CFD tool openFoam for automatic design evaluation. For optimization, we chose Bayesian optimization (BO), which is a well-known technique developed for optimizing time-consuming expensive engineering simulations and has proven to be very sample efficient in a variety of problems, including hyper-parameter tuning and experimental design. During the optimization process, we can handle infeasible design as constraints integrated into the optimization process. By integrating domain-specific toolchain with AI-based optimization, we executed the automatic design optimization of underwater vehicle hull design. For empirical evaluation, we took two different use cases of real-world underwater vehicle design to validate the execution of our tool.
Quality evaluation of point clouds: a novel no-reference approach using transformer-based architecture
Mar 15, 2023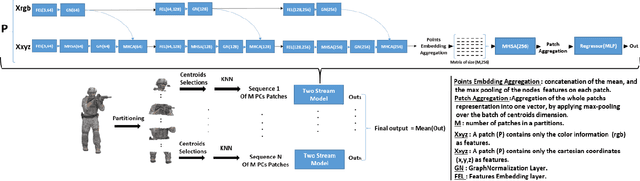
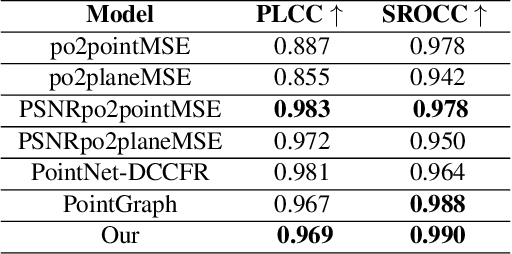
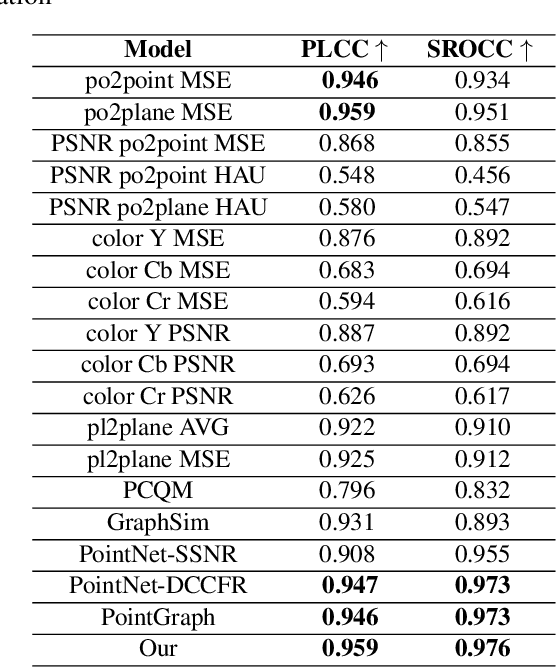
With the increased interest in immersive experiences, point cloud came to birth and was widely adopted as the first choice to represent 3D media. Besides several distortions that could affect the 3D content spanning from acquisition to rendering, efficient transmission of such volumetric content over traditional communication systems stands at the expense of the delivered perceptual quality. To estimate the magnitude of such degradation, employing quality metrics became an inevitable solution. In this work, we propose a novel deep-based no-reference quality metric that operates directly on the whole point cloud without requiring extensive pre-processing, enabling real-time evaluation over both transmission and rendering levels. To do so, we use a novel model design consisting primarily of cross and self-attention layers, in order to learn the best set of local semantic affinities while keeping the best combination of geometry and color information in multiple levels from basic features extraction to deep representation modeling.
Dataset Management Platform for Machine Learning
Mar 15, 2023
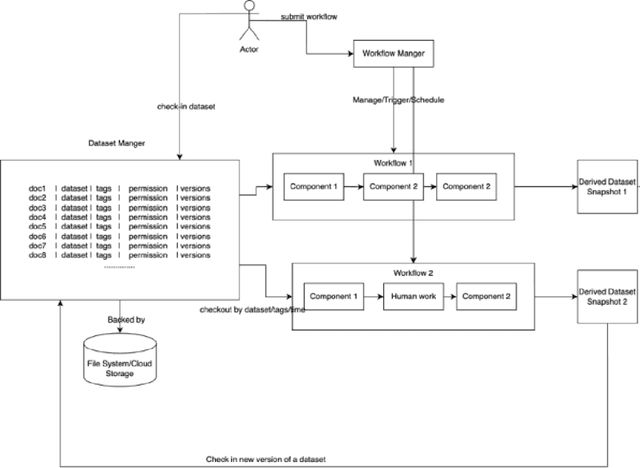
The quality of the data in a dataset can have a substantial impact on the performance of a machine learning model that is trained and/or evaluated using the dataset. Effective dataset management, including tasks such as data cleanup, versioning, access control, dataset transformation, automation, integrity and security, etc., can help improve the efficiency and speed of the machine learning process. Currently, engineers spend a substantial amount of manual effort and time to manage dataset versions or to prepare datasets for machine learning tasks. This disclosure describes a platform to manage and use datasets effectively. The techniques integrate dataset management and dataset transformation mechanisms. A storage engine is described that acts as a source of truth for all data and handles versioning, access control etc. The dataset transformation mechanism is a key part to generate a dataset (snapshot) to serve different purposes. The described techniques can support different workflows, pipelines, or data orchestration needs, e.g., for training and/or evaluation of machine learning models.
Image Deblurring by Exploring In-depth Properties of Transformer
Mar 24, 2023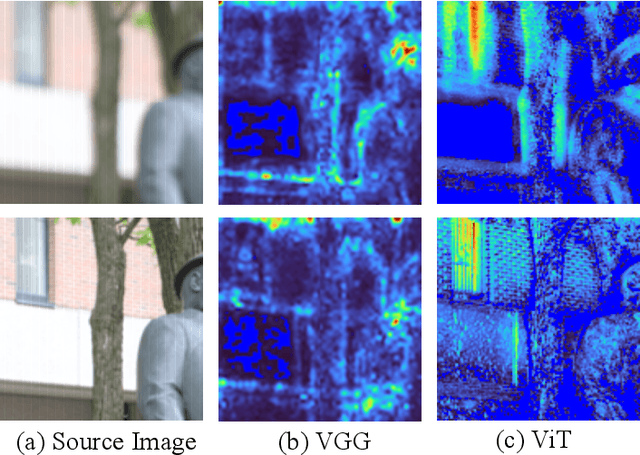
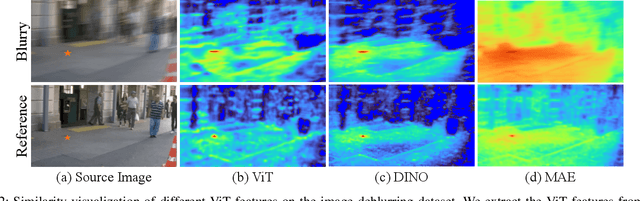
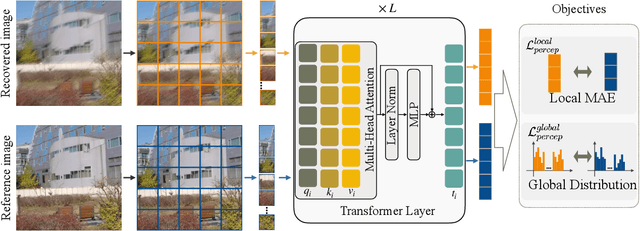

Image deblurring continues to achieve impressive performance with the development of generative models. Nonetheless, there still remains a displeasing problem if one wants to improve perceptual quality and quantitative scores of recovered image at the same time. In this study, drawing inspiration from the research of transformer properties, we introduce the pretrained transformers to address this problem. In particular, we leverage deep features extracted from a pretrained vision transformer (ViT) to encourage recovered images to be sharp without sacrificing the performance measured by the quantitative metrics. The pretrained transformer can capture the global topological relations (i.e., self-similarity) of image, and we observe that the captured topological relations about the sharp image will change when blur occurs. By comparing the transformer features between recovered image and target one, the pretrained transformer provides high-resolution blur-sensitive semantic information, which is critical in measuring the sharpness of the deblurred image. On the basis of the advantages, we present two types of novel perceptual losses to guide image deblurring. One regards the features as vectors and computes the discrepancy between representations extracted from recovered image and target one in Euclidean space. The other type considers the features extracted from an image as a distribution and compares the distribution discrepancy between recovered image and target one. We demonstrate the effectiveness of transformer properties in improving the perceptual quality while not sacrificing the quantitative scores (PSNR) over the most competitive models, such as Uformer, Restormer, and NAFNet, on defocus deblurring and motion deblurring tasks.
Non-invasive urinary bladder volume estimation with artefact-suppressed bio-impedance measurements
Mar 24, 2023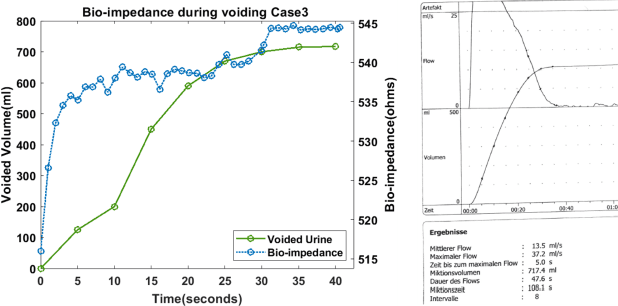
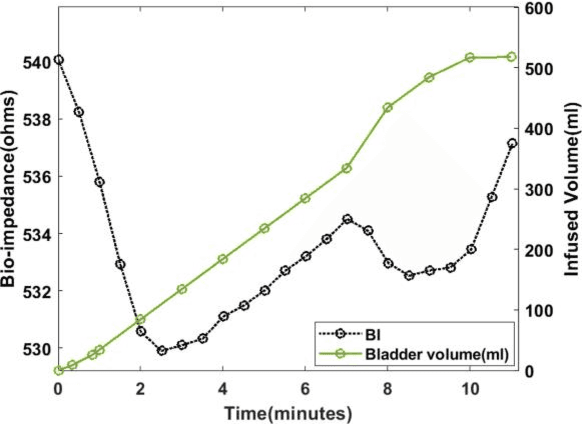
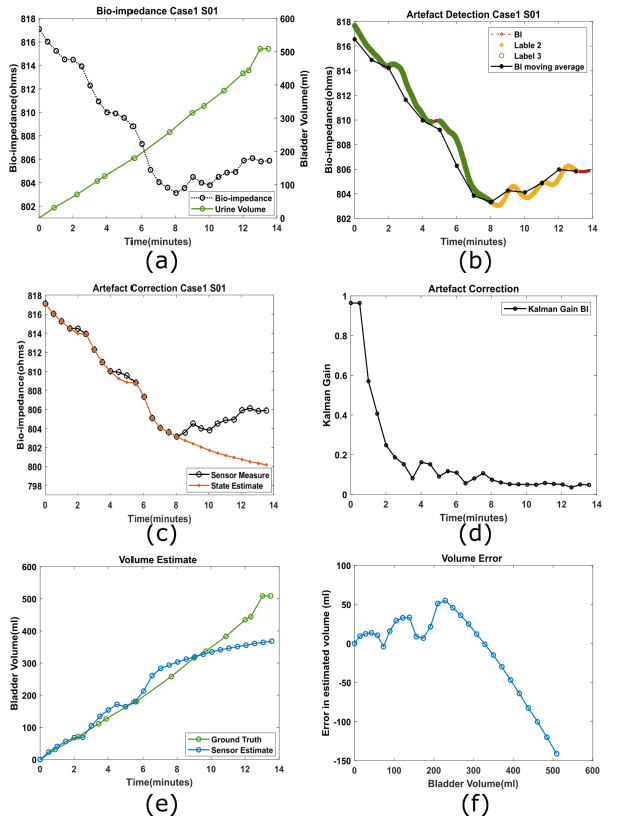
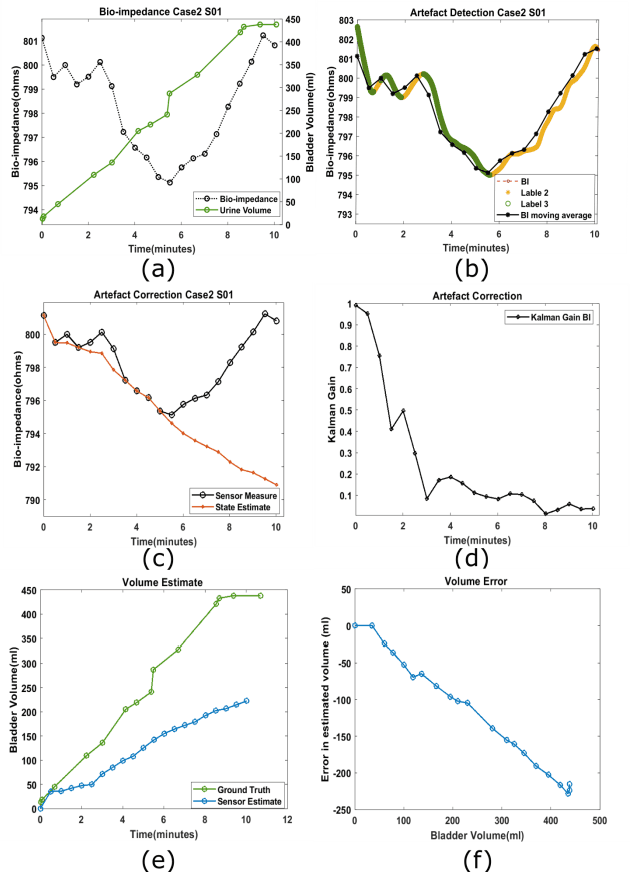
Urine output is a vital parameter to gauge kidney health. Current monitoring methods include manually written records, invasive urinary catheterization or ultrasound measurements performed by highly skilled personnel. Catheterization bears high risks of infection while intermittent ultrasound measures and manual recording are time consuming and might miss early signs of kidney malfunction. Bioimpedance (BI) measurements may serve as a non-invasive alternative for measuring urine volume in vivo. However, limited robustness have prevented its clinical translation. Here, a deep learning-based algorithm is presented that processes the local BI of the lower abdomen and suppresses artefacts to measure the bladder volume quantitatively, non-invasively and without the continuous need for additional personnel. A tetrapolar BI wearable system called ANUVIS was used to collect continuous bladder volume data from three healthy subjects to demonstrate feasibility of operation, while clinical gold standards of urodynamic (n=6) and uroflowmetry tests (n=8) provided the ground truth. Optimized location for electrode placement and a model for the change in BI with changing bladder volume is deduced. The average error for full bladder volume estimation and for residual volume estimation was -29 +/-87.6 ml, thus, comparable to commercial portable ultrasound devices (Bland Altman analysis showed a bias of -5.2 ml with LoA between 119.7 ml to -130.1 ml), while providing the additional benefit of hands-free, non-invasive, and continuous bladder volume estimation. The combination of the wearable BI sensor node and the presented algorithm provides an attractive alternative to current standard of care with potential benefits in providing insights into kidney function.
4D iRIOM: 4D Imaging Radar Inertial Odometry and Mapping
Mar 24, 2023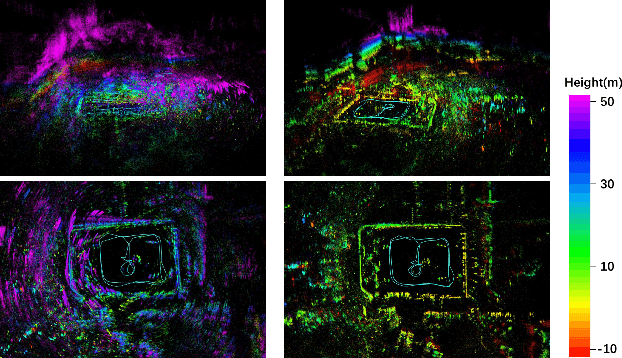
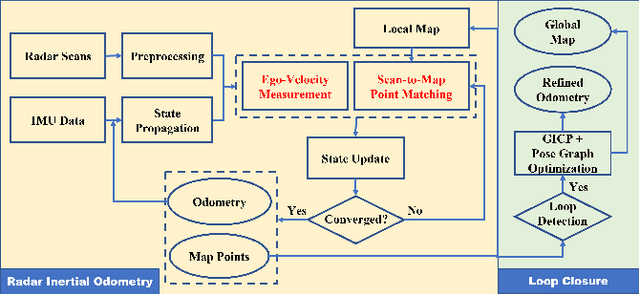

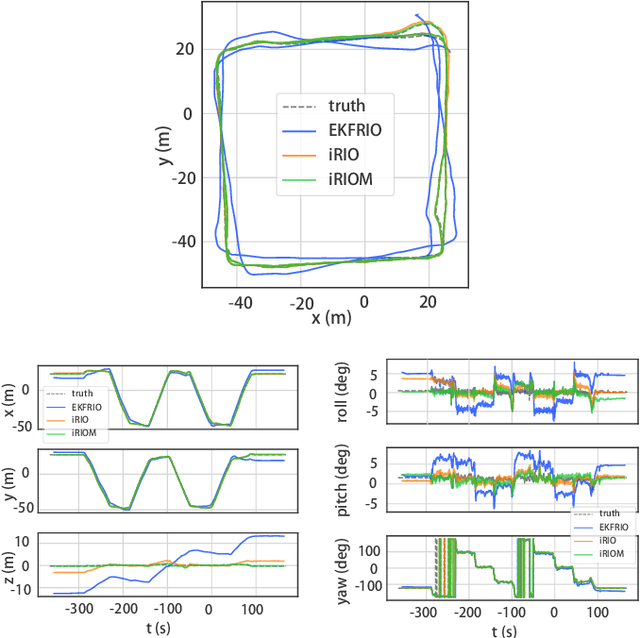
Millimeter wave radar can measure distances, directions, and Doppler velocity for objects in harsh conditions such as fog. The 4D imaging radar with both vertical and horizontal data resembling an image can also measure objects' height. Previous studies have used 3D radars for ego-motion estimation. But few methods leveraged the rich data of imaging radars, and they usually omitted the mapping aspect which is affected by the radar multipath returns, thus leading to inferior odometry accuracy. This paper presents a real-time imaging radar inertial odometry and mapping method, iRIOM, based on the submap concept. To fend off moving objects and multipath reflections, the iteratively reweighted least squares method is used for getting the ego-velocity from a single scan. To measure the agreement between sparse non-repetitive radar scan points and submap points, the distribution-to-multi-distribution distance for matches is adopted. The ego-velocity, scan-to-submap matches are fused with the 6D inertial data by an iterative extended Kalman filter to get the platform's 3D position and orientation. A loop closure module is also developed to curb the odometry module's drift. To our knowledge, iRIOM based on the two modules is the first 4D radar inertial SLAM system. On our and third-party data, we show iRIOM's favorable odometry accuracy and mapping consistency against the FastLIO-SLAM and the EKFRIO. Also, the ablation study reveal the benefit of inertial data versus the constant velocity model, the scan-to-submap matching versus the scan-to-scans matching, and loop closure.
Rendezvous in Time: An Attention-based Temporal Fusion approach for Surgical Triplet Recognition
Nov 30, 2022

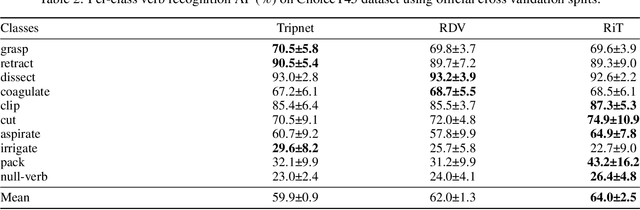
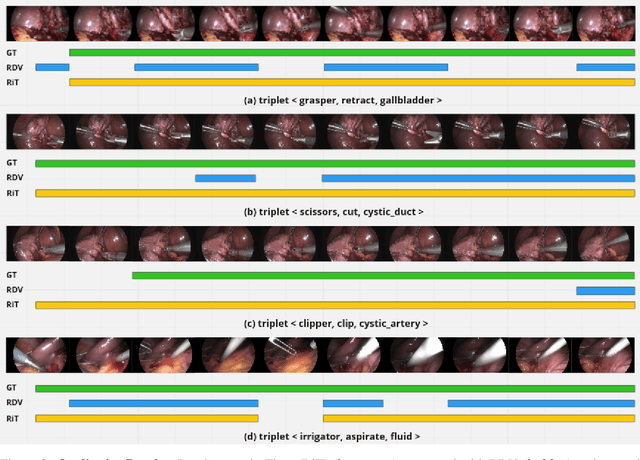
One of the recent advances in surgical AI is the recognition of surgical activities as triplets of (instrument, verb, target). Albeit providing detailed information for computer-assisted intervention, current triplet recognition approaches rely only on single frame features. Exploiting the temporal cues from earlier frames would improve the recognition of surgical action triplets from videos. In this paper, we propose Rendezvous in Time (RiT) - a deep learning model that extends the state-of-the-art model, Rendezvous, with temporal modeling. Focusing more on the verbs, our RiT explores the connectedness of current and past frames to learn temporal attention-based features for enhanced triplet recognition. We validate our proposal on the challenging surgical triplet dataset, CholecT45, demonstrating an improved recognition of the verb and triplet along with other interactions involving the verb such as (instrument, verb). Qualitative results show that the RiT produces smoother predictions for most triplet instances than the state-of-the-arts. We present a novel attention-based approach that leverages the temporal fusion of video frames to model the evolution of surgical actions and exploit their benefits for surgical triplet recognition.
Bronchoscopic video synchronization for interactive multimodal inspection of bronchial lesions
Mar 20, 2023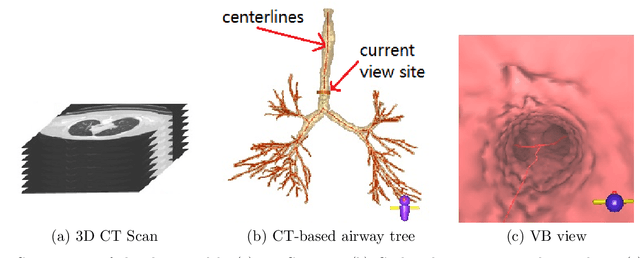
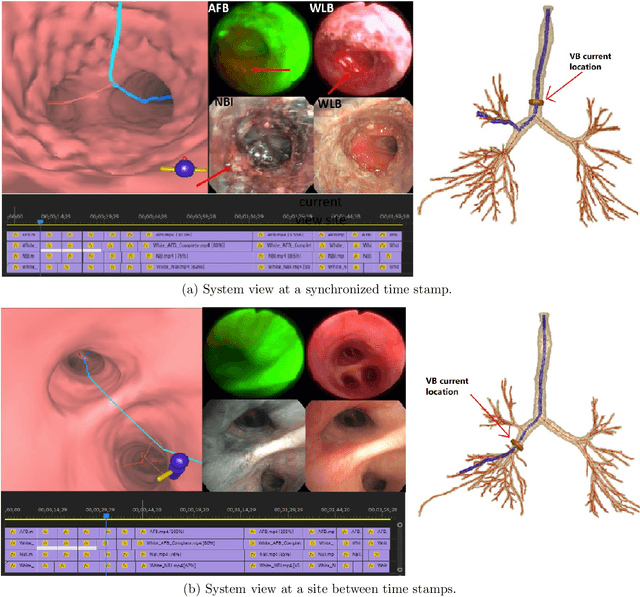
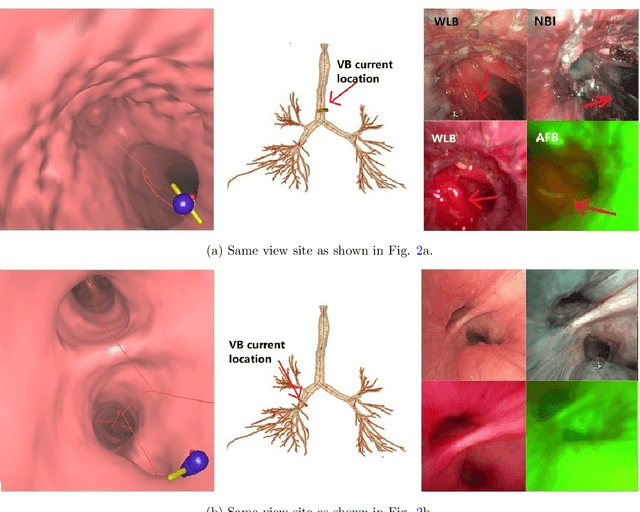
With lung cancer being the most fatal cancer worldwide, it is important to detect the disease early. A potentially effective way of detecting early cancer lesions developing along the airway walls (epithelium) is bronchoscopy. To this end, developments in bronchoscopy offer three promising noninvasive modalities for imaging bronchial lesions: white-light bronchoscopy (WLB), autofluorescence bronchoscopy (AFB), and narrow-band imaging (NBI). While these modalities give complementary views of the airway epithelium, the physician must manually inspect each video stream produced by a given modality to locate the suspect cancer lesions. Unfortunately, no effort has been made to rectify this situation by providing efficient quantitative and visual tools for analyzing these video streams. This makes the lesion search process extremely time-consuming and error-prone, thereby making it impractical to utilize these rich data sources effectively. We propose a framework for synchronizing multiple bronchoscopic videos to enable an interactive multimodal analysis of bronchial lesions. Our methods first register the video streams to a reference 3D chest computed-tomography (CT) scan to produce multimodal linkages to the airway tree. Our methods then temporally correlate the videos to one another to enable synchronous visualization of the resulting multimodal data set. Pictorial and quantitative results illustrate the potential of the methods.
VIMI: Vehicle-Infrastructure Multi-view Intermediate Fusion for Camera-based 3D Object Detection
Mar 20, 2023
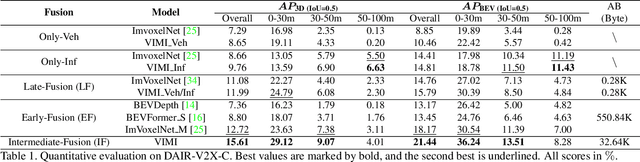
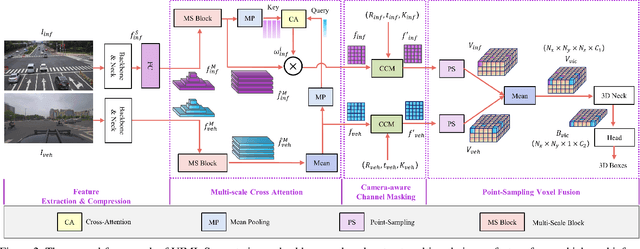
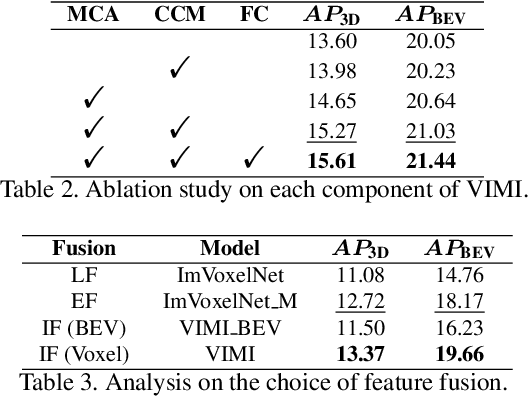
In autonomous driving, Vehicle-Infrastructure Cooperative 3D Object Detection (VIC3D) makes use of multi-view cameras from both vehicles and traffic infrastructure, providing a global vantage point with rich semantic context of road conditions beyond a single vehicle viewpoint. Two major challenges prevail in VIC3D: 1) inherent calibration noise when fusing multi-view images, caused by time asynchrony across cameras; 2) information loss when projecting 2D features into 3D space. To address these issues, We propose a novel 3D object detection framework, Vehicles-Infrastructure Multi-view Intermediate fusion (VIMI). First, to fully exploit the holistic perspectives from both vehicles and infrastructure, we propose a Multi-scale Cross Attention (MCA) module that fuses infrastructure and vehicle features on selective multi-scales to correct the calibration noise introduced by camera asynchrony. Then, we design a Camera-aware Channel Masking (CCM) module that uses camera parameters as priors to augment the fused features. We further introduce a Feature Compression (FC) module with channel and spatial compression blocks to reduce the size of transmitted features for enhanced efficiency. Experiments show that VIMI achieves 15.61% overall AP_3D and 21.44% AP_BEV on the new VIC3D dataset, DAIR-V2X-C, significantly outperforming state-of-the-art early fusion and late fusion methods with comparable transmission cost.