 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Visual Prompt Tuning for Test-time Domain Adaptation
Oct 10, 2022
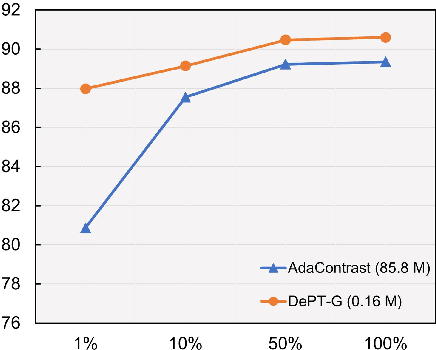
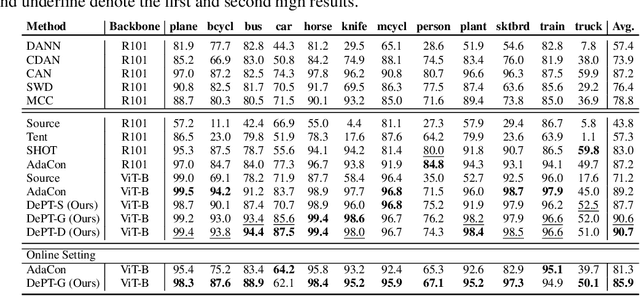
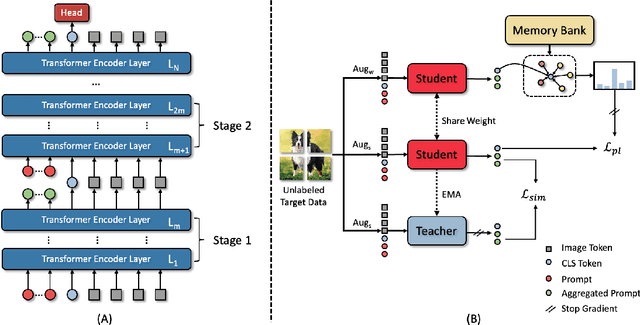
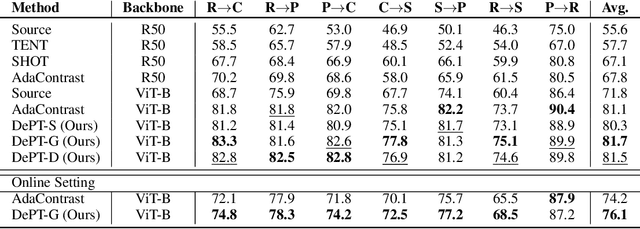
Models should have the ability to adapt to unseen data during test-time to avoid performance drop caused by inevitable distribution shifts in real-world deployment scenarios. In this work, we tackle the practical yet challenging test-time adaptation (TTA) problem, where a model adapts to the target domain without accessing the source data. We propose a simple recipe called data-efficient prompt tuning (DePT) with two key ingredients. First, DePT plugs visual prompts into the vision Transformer and only tunes these source-initialized prompts during adaptation. We find such parameter-efficient finetuning can efficiently adapt the model representation to the target domain without overfitting to the noise in the learning objective. Second, DePT bootstraps the source representation to the target domain by memory bank-based online pseudo labeling. A hierarchical self-supervised regularization specially designed for prompts is jointly optimized to alleviate error accumulation during self-training. With much fewer tunable parameters, DePT demonstrates not only state-of-the-art performance on major adaptation benchmarks, but also superior data efficiency, i.e., adaptation with only 1\% or 10\% data without much performance degradation compared to 100\% data. In addition, DePT is also versatile to be extended to online or multi-source TTA settings.
Zero-Shot Self-Supervised Joint Temporal Image and Sensitivity Map Reconstruction via Linear Latent Space
Mar 03, 2023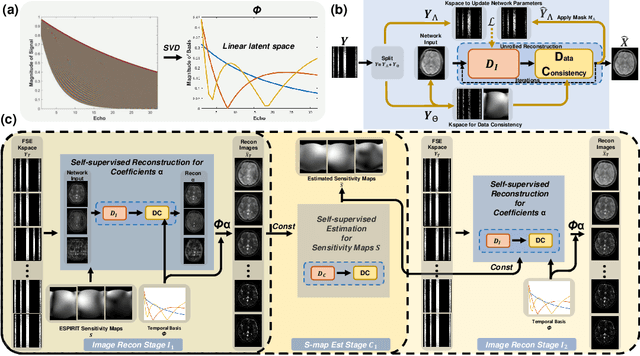
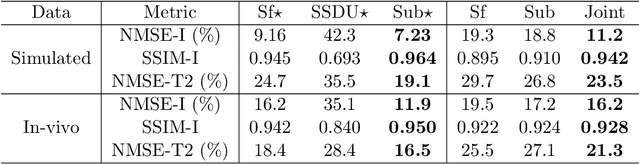
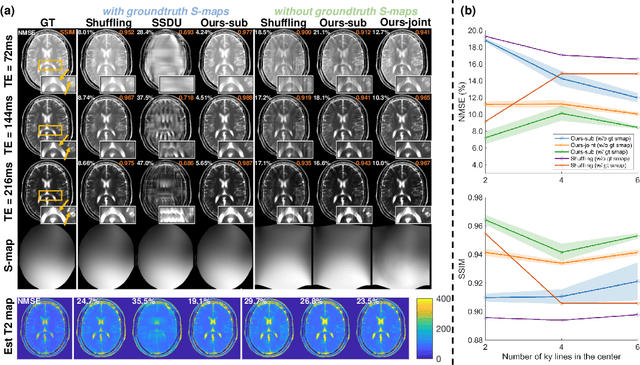
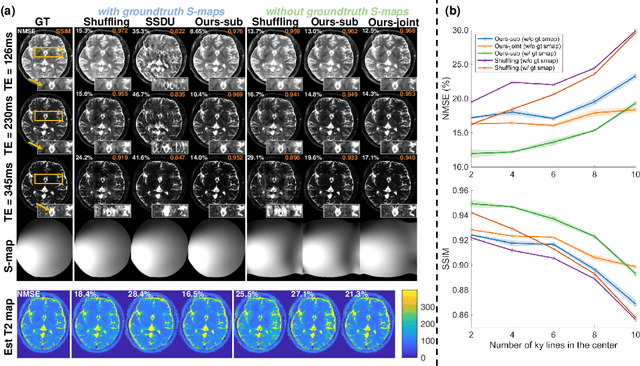
Fast spin-echo (FSE) pulse sequences for Magnetic Resonance Imaging (MRI) offer important imaging contrast in clinically feasible scan times. T2-shuffling is widely used to resolve temporal signal dynamics in FSE acquisitions by exploiting temporal correlations via linear latent space and a predefined regularizer. However, predefined regularizers fail to exploit the incoherence especially for 2D acquisitions.Recent self-supervised learning methods achieve high-fidelity reconstructions by learning a regularizer from undersampled data without a standard supervised training data set. In this work, we propose a novel approach that utilizes a self supervised learning framework to learn a regularizer constrained on a linear latent space which improves time-resolved FSE images reconstruction quality. Additionally, in regimes without groundtruth sensitivity maps, we propose joint estimation of coil-sensitivity maps using an iterative reconstruction technique. Our technique functions is in a zero-shot fashion, as it only utilizes data from a single scan of highly undersampled time series images. We perform experiments on simulated and retrospective in-vivo data to evaluate the performance of the proposed zero-shot learning method for temporal FSE reconstruction. The results demonstrate the success of our proposed method where NMSE and SSIM are significantly increased and the artifacts are reduced.
Constrained Bayesian Optimization for Automatic Underwater Vehicle Hull Design
Mar 15, 2023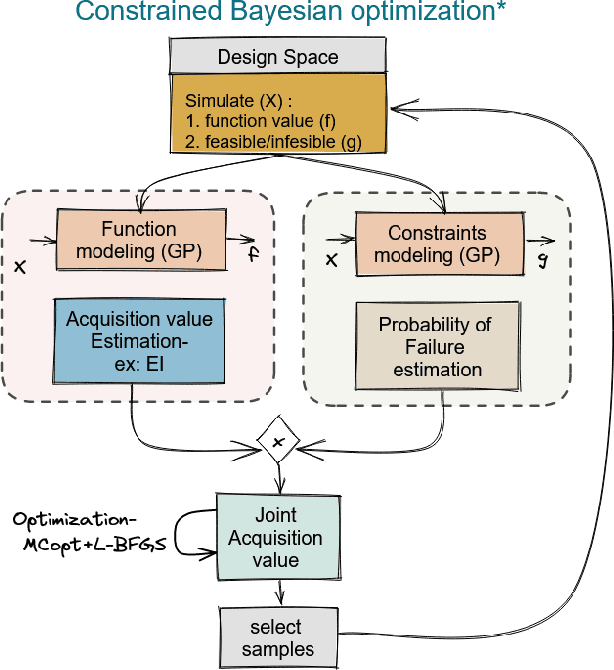
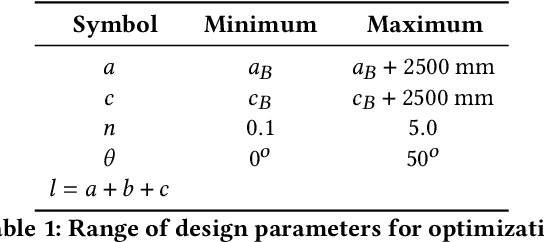
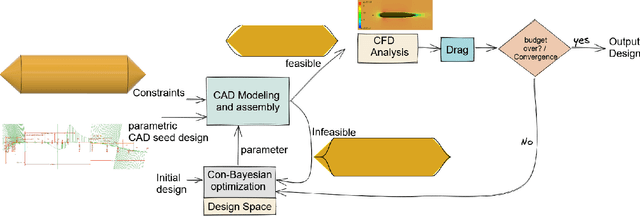
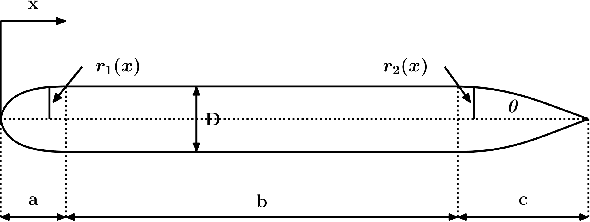
Automatic underwater vehicle hull Design optimization is a complex engineering process for generating a UUV hull with optimized properties on a given requirement. First, it involves the integration of involved computationally complex engineering simulation tools. Second, it needs integration of a sample efficient optimization framework with the integrated toolchain. To this end, we integrated the CAD tool called FreeCAD with CFD tool openFoam for automatic design evaluation. For optimization, we chose Bayesian optimization (BO), which is a well-known technique developed for optimizing time-consuming expensive engineering simulations and has proven to be very sample efficient in a variety of problems, including hyper-parameter tuning and experimental design. During the optimization process, we can handle infeasible design as constraints integrated into the optimization process. By integrating domain-specific toolchain with AI-based optimization, we executed the automatic design optimization of underwater vehicle hull design. For empirical evaluation, we took two different use cases of real-world underwater vehicle design to validate the execution of our tool.
Quality evaluation of point clouds: a novel no-reference approach using transformer-based architecture
Mar 15, 2023
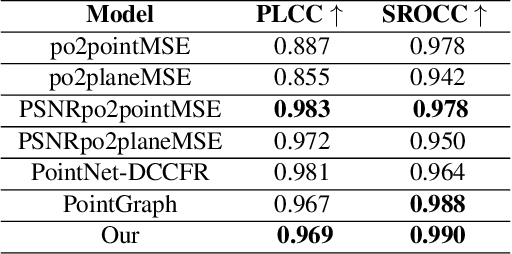
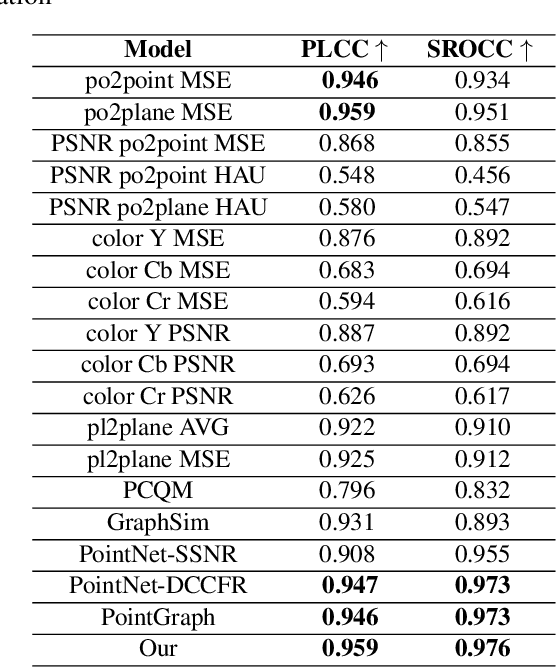
With the increased interest in immersive experiences, point cloud came to birth and was widely adopted as the first choice to represent 3D media. Besides several distortions that could affect the 3D content spanning from acquisition to rendering, efficient transmission of such volumetric content over traditional communication systems stands at the expense of the delivered perceptual quality. To estimate the magnitude of such degradation, employing quality metrics became an inevitable solution. In this work, we propose a novel deep-based no-reference quality metric that operates directly on the whole point cloud without requiring extensive pre-processing, enabling real-time evaluation over both transmission and rendering levels. To do so, we use a novel model design consisting primarily of cross and self-attention layers, in order to learn the best set of local semantic affinities while keeping the best combination of geometry and color information in multiple levels from basic features extraction to deep representation modeling.
Dataset Management Platform for Machine Learning
Mar 15, 2023
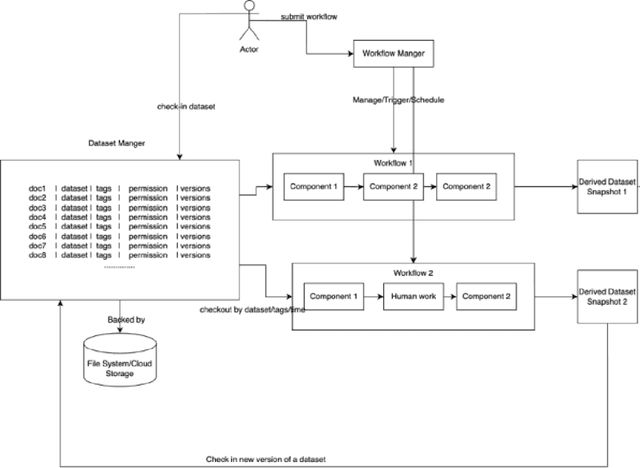
The quality of the data in a dataset can have a substantial impact on the performance of a machine learning model that is trained and/or evaluated using the dataset. Effective dataset management, including tasks such as data cleanup, versioning, access control, dataset transformation, automation, integrity and security, etc., can help improve the efficiency and speed of the machine learning process. Currently, engineers spend a substantial amount of manual effort and time to manage dataset versions or to prepare datasets for machine learning tasks. This disclosure describes a platform to manage and use datasets effectively. The techniques integrate dataset management and dataset transformation mechanisms. A storage engine is described that acts as a source of truth for all data and handles versioning, access control etc. The dataset transformation mechanism is a key part to generate a dataset (snapshot) to serve different purposes. The described techniques can support different workflows, pipelines, or data orchestration needs, e.g., for training and/or evaluation of machine learning models.
Sketch In, Sketch Out: Accelerating both Learning and Inference for Structured Prediction with Kernels
Feb 20, 2023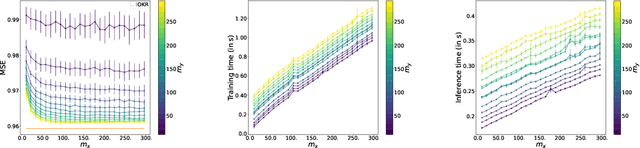
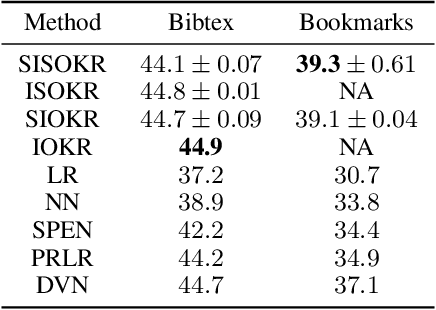
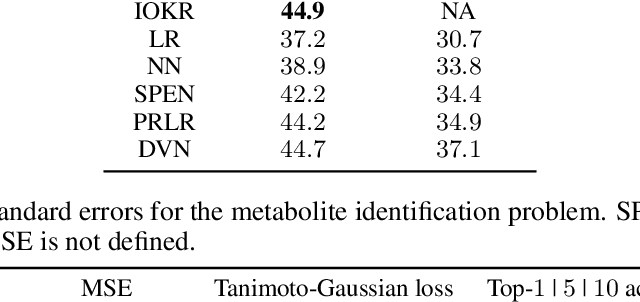
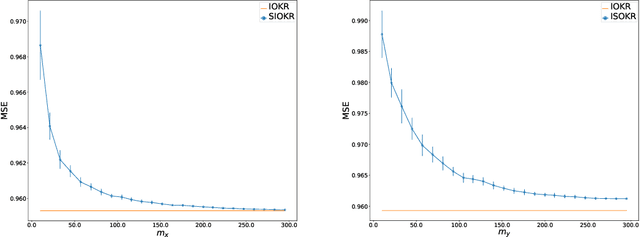
Surrogate kernel-based methods offer a flexible solution to structured output prediction by leveraging the kernel trick in both input and output spaces. In contrast to energy-based models, they avoid to pay the cost of inference during training, while enjoying statistical guarantees. However, without approximation, these approaches are condemned to be used only on a limited amount of training data. In this paper, we propose to equip surrogate kernel methods with approximations based on sketching, seen as low rank projections of feature maps both on input and output feature maps. We showcase the approach on Input Output Kernel ridge Regression (or Kernel Dependency Estimation) and provide excess risk bounds that can be in turn directly plugged on the final predictive model. An analysis of the complexity in time and memory show that sketching the input kernel mostly reduces training time while sketching the output kernel allows to reduce the inference time. Furthermore, we show that Gaussian and sub-Gaussian sketches are admissible sketches in the sense that they induce projection operators ensuring a small excess risk. Experiments on different tasks consolidate our findings.
Collaborative Trolley Transportation System with Autonomous Nonholonomic Robots
Mar 12, 2023
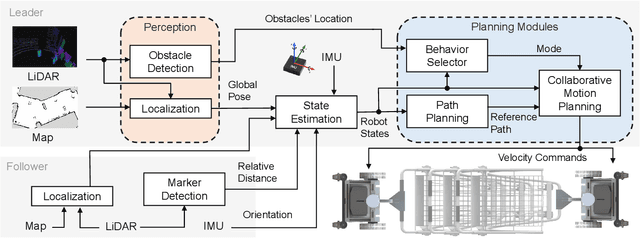
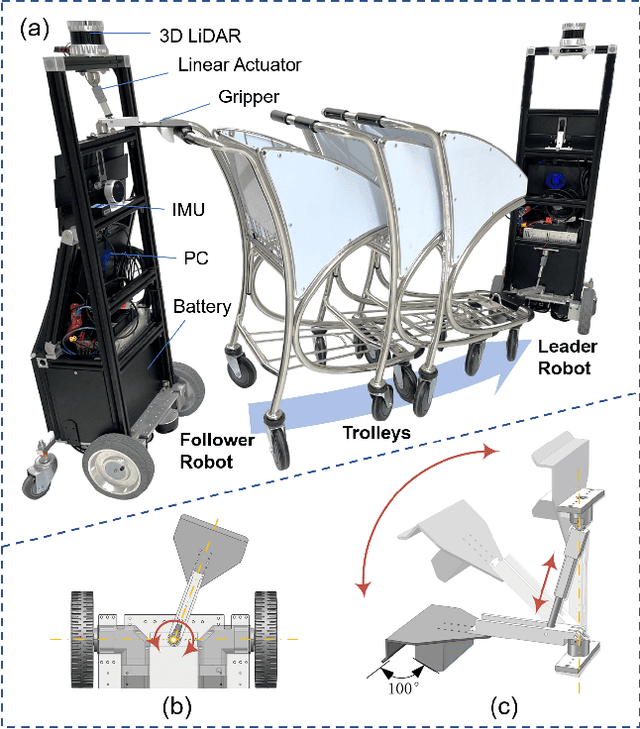
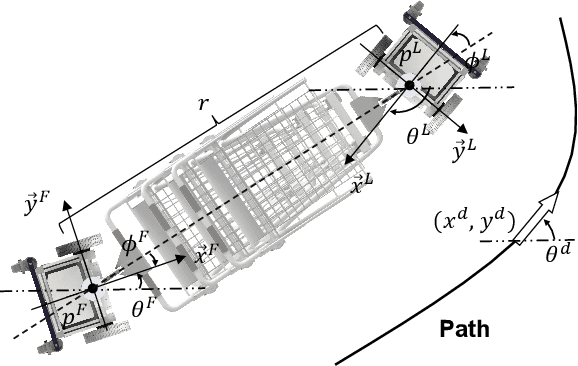
Cooperative object transportation using multiple robots has been intensively studied in the control and robotics literature, but most approaches are either only applicable to omnidirectional robots or lack a complete navigation and decision-making framework that operates in real time. This paper presents an autonomous nonholonomic multi-robot system and an end-to-end hierarchical autonomy framework for collaborative luggage trolley transportation. This framework finds kinematic-feasible paths, computes online motion plans, and provides feedback that enables the multi-robot system to handle long lines of luggage trolleys and navigate obstacles and pedestrians while dealing with multiple inherently complex and coupled constraints. We demonstrate the designed collaborative trolley transportation system through practical transportation tasks, and the experiment results reveal their effectiveness and reliability in complex and dynamic environments.
Invariant Neural Ordinary Differential Equations
Feb 26, 2023

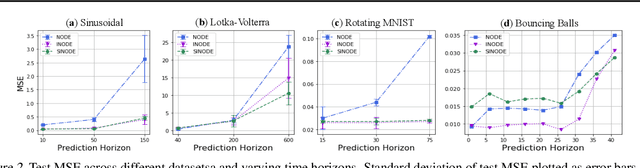

Latent neural ordinary differential equations have been proven useful for learning non-linear dynamics of arbitrary sequences. In contrast with their mechanistic counterparts, the predictive accuracy of neural ODEs decreases over longer prediction horizons (Rubanova et al., 2019). To mitigate this issue, we propose disentangling dynamic states from time-invariant variables in a completely data-driven way, enabling robust neural ODE models that can generalize across different settings. We show that such variables can control the latent differential function and/or parameterize the mapping from latent variables to observations. By explicitly modeling the time-invariant variables, our framework enables the use of recent advances in representation learning. We demonstrate this by introducing a straightforward self-supervised objective that enhances the learning of these variables. The experiments on low-dimensional oscillating systems and video sequences reveal that our disentangled model achieves improved long-term predictions, when the training data involve sequence-specific factors of variation such as different rotational speeds, calligraphic styles, and friction constants.
ICICLE: Interpretable Class Incremental Continual Learning
Mar 14, 2023
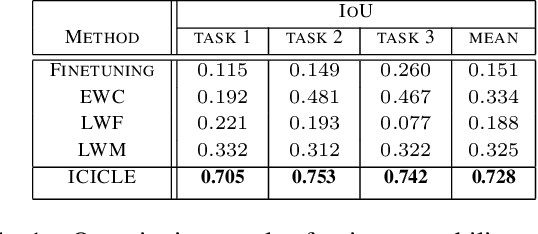
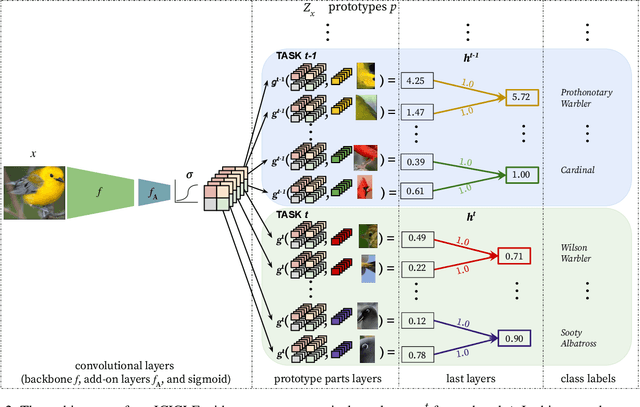
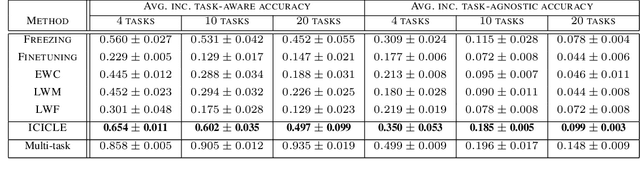
Continual learning enables incremental learning of new tasks without forgetting those previously learned, resulting in positive knowledge transfer that can enhance performance on both new and old tasks. However, continual learning poses new challenges for interpretability, as the rationale behind model predictions may change over time, leading to interpretability concept drift. We address this problem by proposing Interpretable Class-InCremental LEarning (ICICLE), an exemplar-free approach that adopts a prototypical part-based approach. It consists of three crucial novelties: interpretability regularization that distills previously learned concepts while preserving user-friendly positive reasoning; proximity-based prototype initialization strategy dedicated to the fine-grained setting; and task-recency bias compensation devoted to prototypical parts. Our experimental results demonstrate that ICICLE reduces the interpretability concept drift and outperforms the existing exemplar-free methods of common class-incremental learning when applied to concept-based models. We make the code available.
Localizing Spatial Information in Neural Spatiospectral Filters
Mar 14, 2023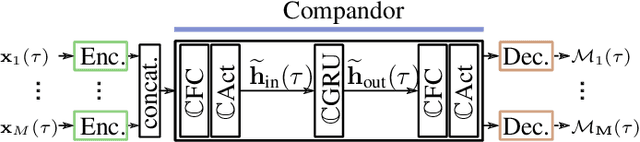
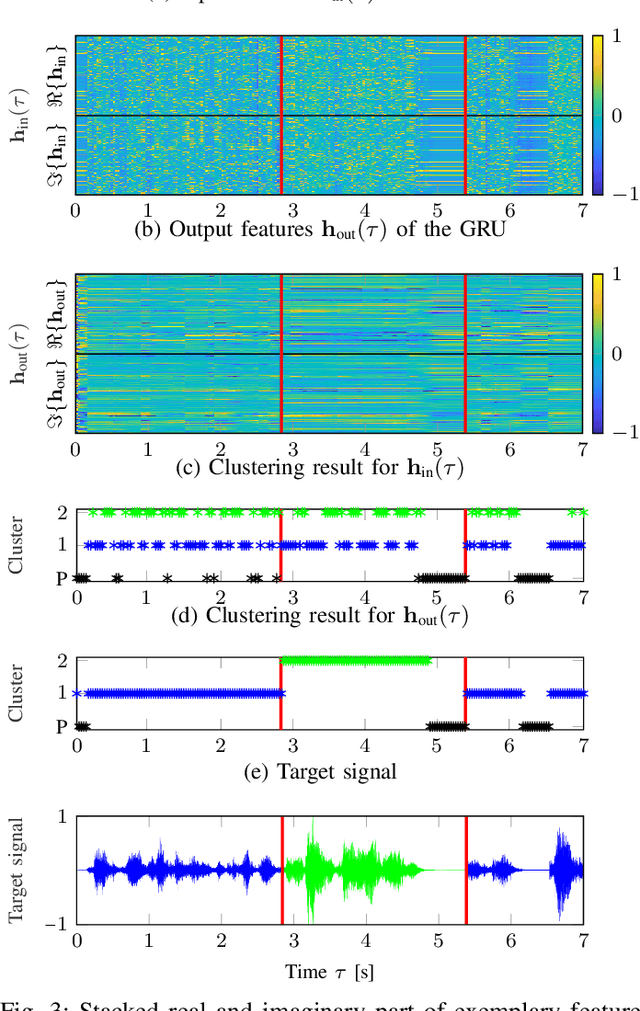
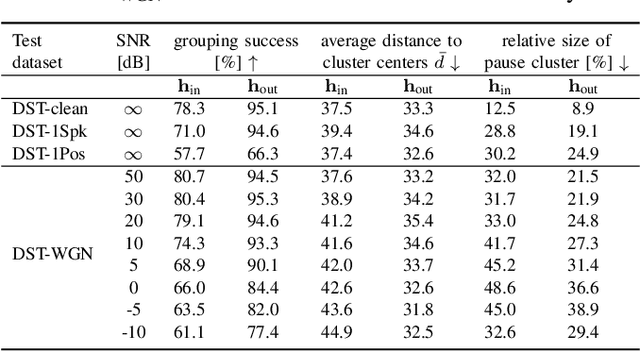
Beamforming for multichannel speech enhancement relies on the estimation of spatial characteristics of the acoustic scene. In its simplest form, the delay-and-sum beamformer (DSB) introduces a time delay to all channels to align the desired signal components for constructive superposition. Recent investigations of neural spatiospectral filtering revealed that these filters can be characterized by a beampattern similar to one of traditional beamformers, which shows that artificial neural networks can learn and explicitly represent spatial structure. Using the Complex-valued Spatial Autoencoder (COSPA) as an exemplary neural spatiospectral filter for multichannel speech enhancement, we investigate where and how such networks represent spatial information. We show via clustering that for COSPA the spatial information is represented by the features generated by a gated recurrent unit (GRU) layer that has access to all channels simultaneously and that these features are not source -- but only direction of arrival-dependent.