 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Dynamic Time Warping based Adversarial Framework for Time-Series Domain
Jul 09, 2022
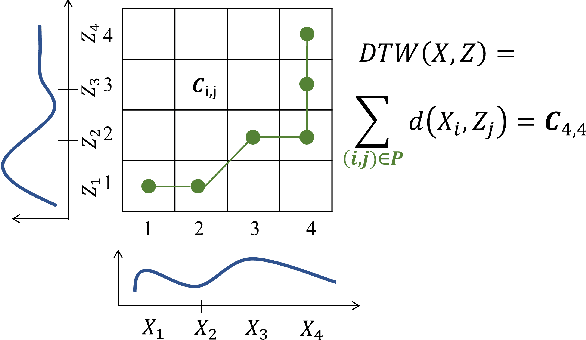
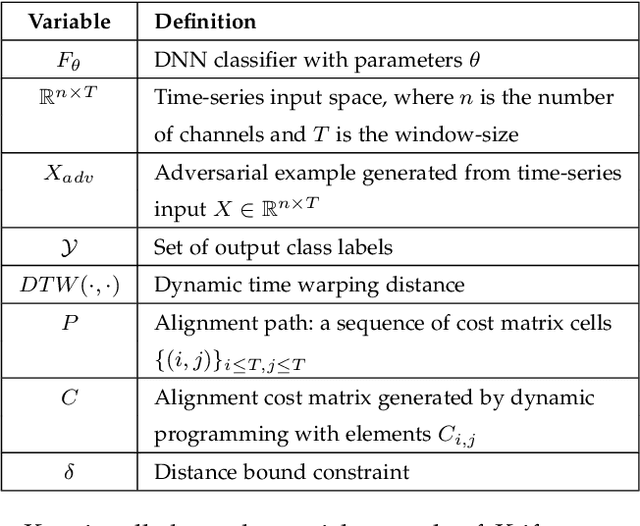
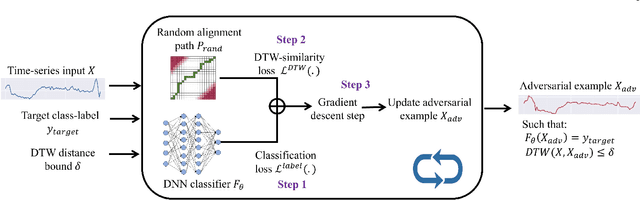
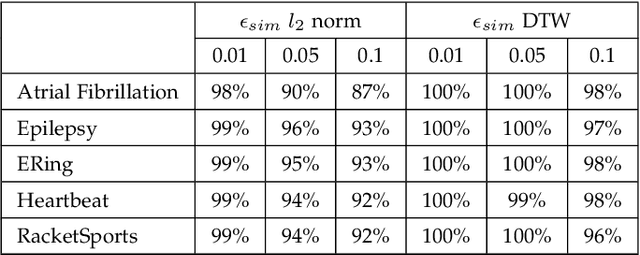
Despite the rapid progress on research in adversarial robustness of deep neural networks (DNNs), there is little principled work for the time-series domain. Since time-series data arises in diverse applications including mobile health, finance, and smart grid, it is important to verify and improve the robustness of DNNs for the time-series domain. In this paper, we propose a novel framework for the time-series domain referred as {\em Dynamic Time Warping for Adversarial Robustness (DTW-AR)} using the dynamic time warping measure. Theoretical and empirical evidence is provided to demonstrate the effectiveness of DTW over the standard Euclidean distance metric employed in prior methods for the image domain. We develop a principled algorithm justified by theoretical analysis to efficiently create diverse adversarial examples using random alignment paths. Experiments on diverse real-world benchmarks show the effectiveness of DTW-AR to fool DNNs for time-series data and to improve their robustness using adversarial training. The source code of DTW-AR algorithms is available at https://github.com/tahabelkhouja/DTW-AR
Complexity-calibrated Benchmarks for Machine Learning Reveal When Next-Generation Reservoir Computer Predictions Succeed and Mislead
Mar 25, 2023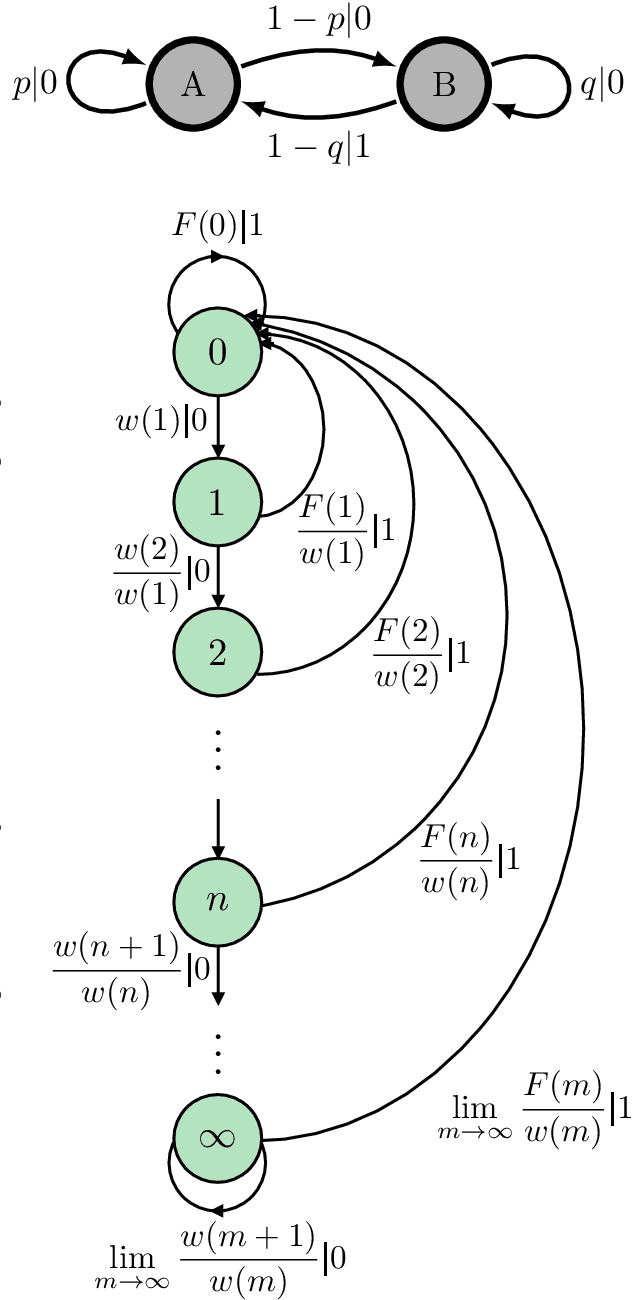
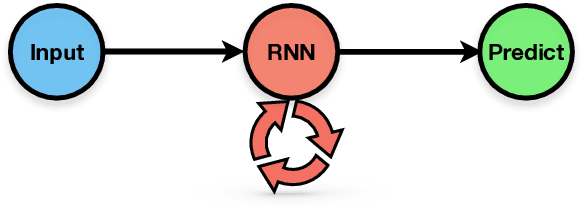
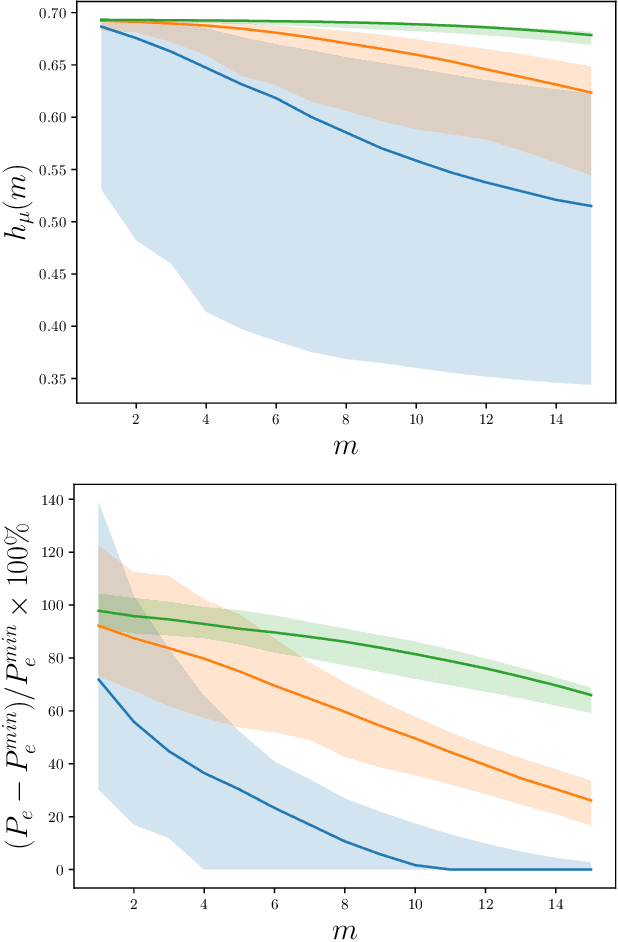
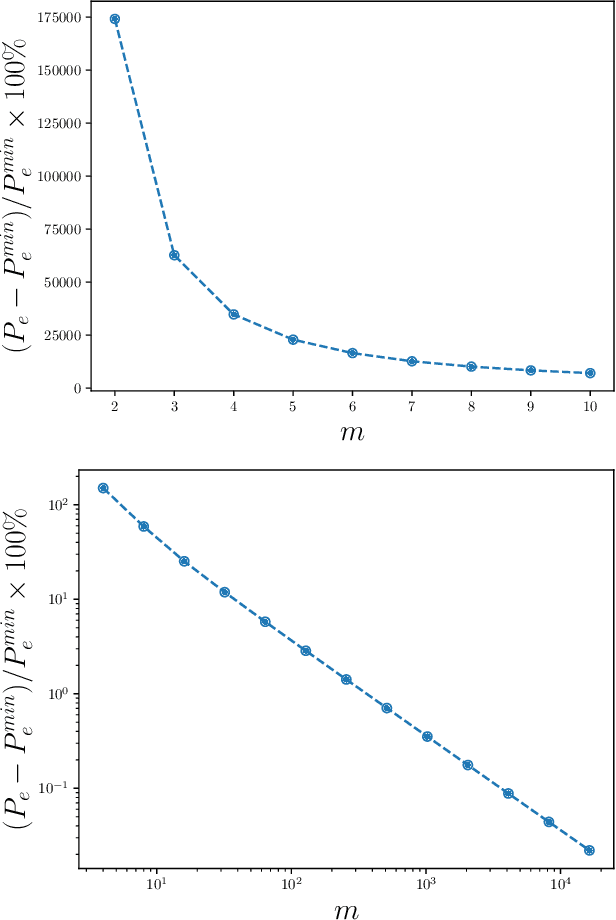
Recurrent neural networks are used to forecast time series in finance, climate, language, and from many other domains. Reservoir computers are a particularly easily trainable form of recurrent neural network. Recently, a "next-generation" reservoir computer was introduced in which the memory trace involves only a finite number of previous symbols. We explore the inherent limitations of finite-past memory traces in this intriguing proposal. A lower bound from Fano's inequality shows that, on highly non-Markovian processes generated by large probabilistic state machines, next-generation reservoir computers with reasonably long memory traces have an error probability that is at least ~ 60% higher than the minimal attainable error probability in predicting the next observation. More generally, it appears that popular recurrent neural networks fall far short of optimally predicting such complex processes. These results highlight the need for a new generation of optimized recurrent neural network architectures. Alongside this finding, we present concentration-of-measure results for randomly-generated but complex processes. One conclusion is that large probabilistic state machines -- specifically, large $\epsilon$-machines -- are key to generating challenging and structurally-unbiased stimuli for ground-truthing recurrent neural network architectures.
Image Moment Invariants to Rotational Motion Blur
Mar 25, 2023
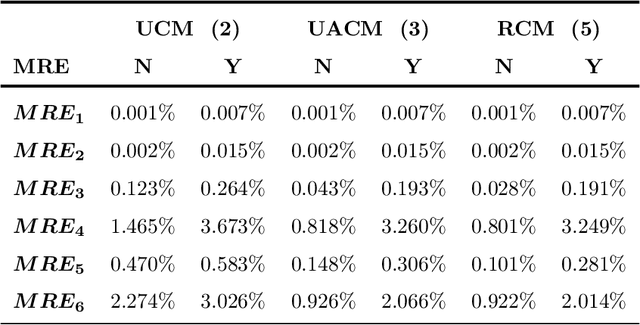
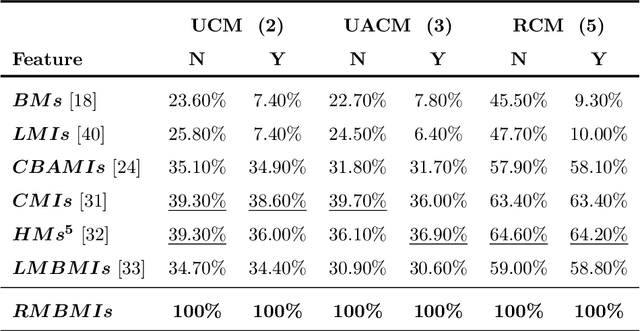

Rotational motion blur caused by the circular motion of the camera or/and object is common in life. Identifying objects from images affected by rotational motion blur is challenging because this image degradation severely impacts image quality. Therefore, it is meaningful to develop image invariant features under rotational motion blur and then use them in practical tasks, such as object classification and template matching. This paper proposes a novel method to generate image moment invariants under general rotational motion blur and provides some instances. Further, we achieve their invariance to similarity transform. To the best of our knowledge, this is the first time that moment invariants for rotational motion blur have been proposed in the literature. We conduct extensive experiments on various image datasets disturbed by similarity transform and rotational motion blur to test these invariants' numerical stability and robustness to image noise. We also demonstrate their performance in image classification and handwritten digit recognition. Current state-of-the-art blur moment invariants and deep neural networks are chosen for comparison. Our results show that the moment invariants proposed in this paper significantly outperform other features in various tasks.
Body-UAV Near-Ground LoRa Links through a Mediterranean Forest
Mar 25, 2023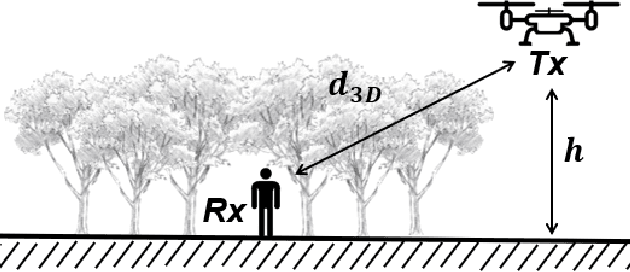
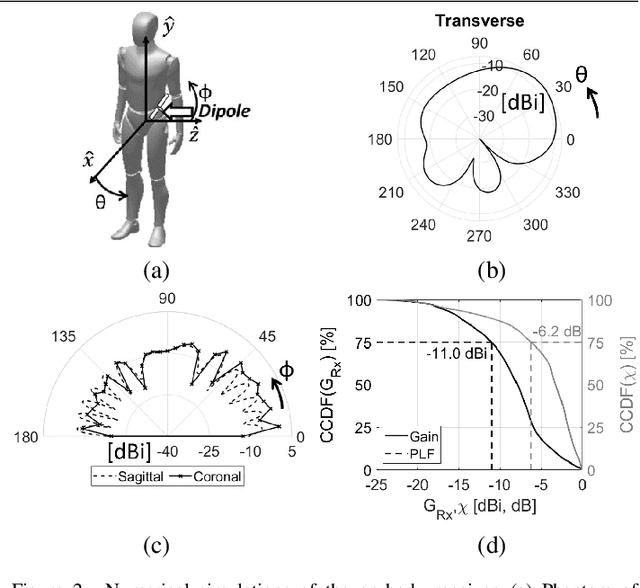
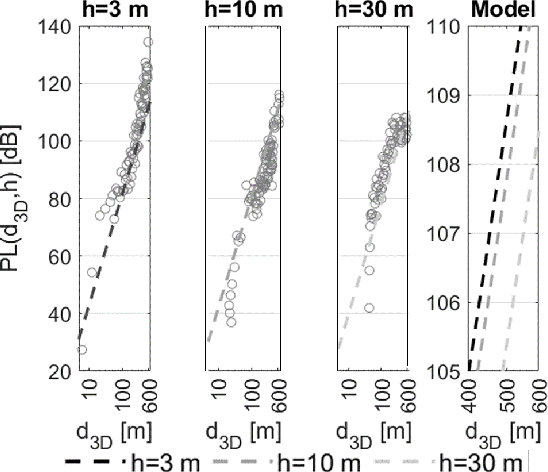
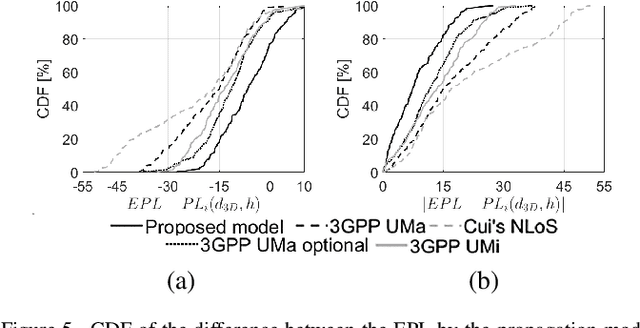
LoRa low-power wide-area network protocol has recently gained attention for deploying ad-hoc search and rescue (SaR) systems. They could be empowered by exploiting body-UAV links that enable communications between a body-worn radio and a UAV-mounted one. However, to employ UAVs effectively, knowledge of the signal's propagation in the environment is required. Otherwise, communications and localization could be hindered. The radio range, the packet delivery ratio (PDR), and the large- and small-scale fading of body-UAV LoRa links at 868 MHz when the radio wearer is in a Mediterranean forest are here characterized for the first time with a near-ground UAV having a maximum flying height of 30 m. A log-distance model accounting for the body shadowing and the wearer's movements is derived. Over the full LoRa radio range of about 600 m, the new model predicts the path loss (PL) better than the state-of-the-art ones, with a reduction of the median error even by 10 dB. The observed small-scale fading is severe and follows a Nakagami-m distribution. Extensions of the model for similar scenarios can be drawn through appropriate corrective factors.
Drugs Resistance Analysis from Scarce Health Records via Multi-task Graph Representation
Mar 08, 2023

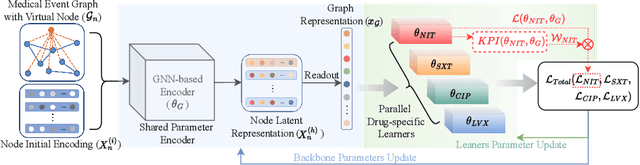

Clinicians prescribe antibiotics by looking at the patient's health record with an experienced eye. However, the therapy might be rendered futile if the patient has drug resistance. Determining drug resistance requires time-consuming laboratory-level testing while applying clinicians' heuristics in an automated way is difficult due to the categorical or binary medical events that constitute health records. In this paper, we propose a novel framework for rapid clinical intervention by viewing health records as graphs whose nodes are mapped from medical events and edges as correspondence between events in given a time window. A novel graph-based model is then proposed to extract informative features and yield automated drug resistance analysis from those high-dimensional and scarce graphs. The proposed method integrates multi-task learning into a common feature extracting graph encoder for simultaneous analyses of multiple drugs as well as stabilizing learning. On a massive dataset comprising over 110,000 patients with urinary tract infections, we verify the proposed method is capable of attaining superior performance on the drug resistance prediction problem. Furthermore, automated drug recommendations resemblant to laboratory-level testing can also be made based on the model resistance analysis.
Real-time Neural Radiance Talking Portrait Synthesis via Audio-spatial Decomposition
Nov 22, 2022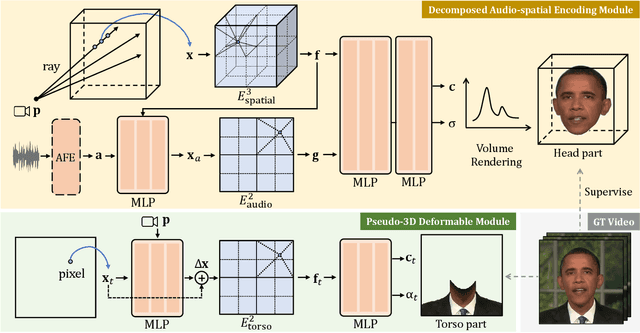

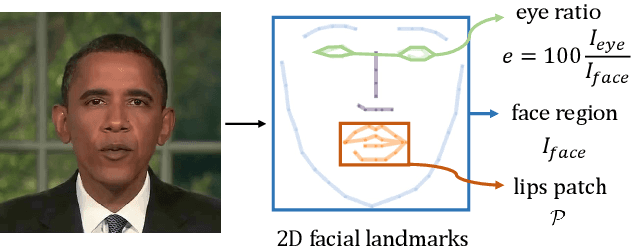
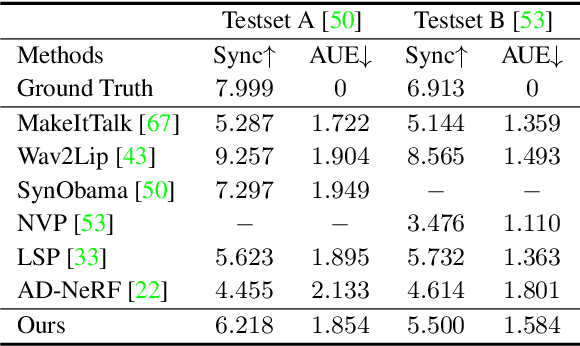
While dynamic Neural Radiance Fields (NeRF) have shown success in high-fidelity 3D modeling of talking portraits, the slow training and inference speed severely obstruct their potential usage. In this paper, we propose an efficient NeRF-based framework that enables real-time synthesizing of talking portraits and faster convergence by leveraging the recent success of grid-based NeRF. Our key insight is to decompose the inherently high-dimensional talking portrait representation into three low-dimensional feature grids. Specifically, a Decomposed Audio-spatial Encoding Module models the dynamic head with a 3D spatial grid and a 2D audio grid. The torso is handled with another 2D grid in a lightweight Pseudo-3D Deformable Module. Both modules focus on efficiency under the premise of good rendering quality. Extensive experiments demonstrate that our method can generate realistic and audio-lips synchronized talking portrait videos, while also being highly efficient compared to previous methods.
CoordFill: Efficient High-Resolution Image Inpainting via Parameterized Coordinate Querying
Mar 15, 2023
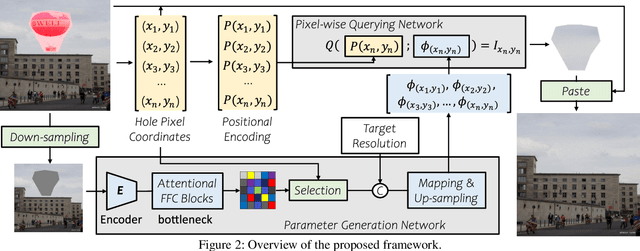
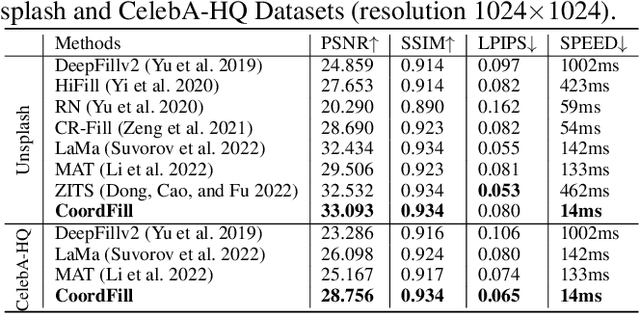
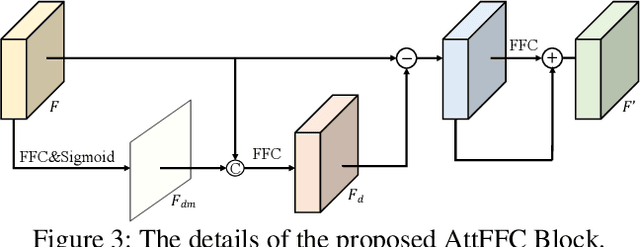
Image inpainting aims to fill the missing hole of the input. It is hard to solve this task efficiently when facing high-resolution images due to two reasons: (1) Large reception field needs to be handled for high-resolution image inpainting. (2) The general encoder and decoder network synthesizes many background pixels synchronously due to the form of the image matrix. In this paper, we try to break the above limitations for the first time thanks to the recent development of continuous implicit representation. In detail, we down-sample and encode the degraded image to produce the spatial-adaptive parameters for each spatial patch via an attentional Fast Fourier Convolution(FFC)-based parameter generation network. Then, we take these parameters as the weights and biases of a series of multi-layer perceptron(MLP), where the input is the encoded continuous coordinates and the output is the synthesized color value. Thanks to the proposed structure, we only encode the high-resolution image in a relatively low resolution for larger reception field capturing. Then, the continuous position encoding will be helpful to synthesize the photo-realistic high-frequency textures by re-sampling the coordinate in a higher resolution. Also, our framework enables us to query the coordinates of missing pixels only in parallel, yielding a more efficient solution than the previous methods. Experiments show that the proposed method achieves real-time performance on the 2048$\times$2048 images using a single GTX 2080 Ti GPU and can handle 4096$\times$4096 images, with much better performance than existing state-of-the-art methods visually and numerically. The code is available at: https://github.com/NiFangBaAGe/CoordFill.
Context-specific kernel-based hidden Markov model for time series analysis
Jan 24, 2023
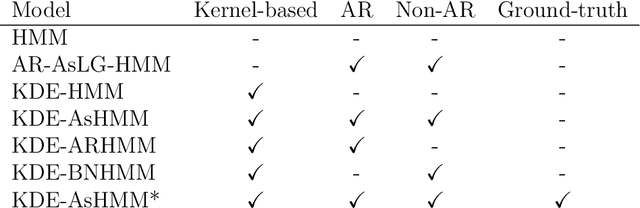
Traditional hidden Markov models have been a useful tool to understand and model stochastic dynamic linear data; in the case of non-Gaussian data or not linear in mean data, models such as mixture of Gaussian hidden Markov models suffer from the computation of precision matrices and have a lot of unnecessary parameters. As a consequence, such models often perform better when it is assumed that all variables are independent, a hypothesis that may be unrealistic. Hidden Markov models based on kernel density estimation is also capable of modeling non Gaussian data, but they assume independence between variables. In this article, we introduce a new hidden Markov model based on kernel density estimation, which is capable of introducing kernel dependencies using context-specific Bayesian networks. The proposed model is described, together with a learning algorithm based on the expectation-maximization algorithm. Additionally, the model is compared with related HMMs using synthetic and real data. From the results, the benefits in likelihood and classification accuracy from the proposed model are quantified and analyzed.
Data-driven Real-time Short-term Prediction of Air Quality: Comparison of ES, ARIMA, and LSTM
Nov 16, 2022
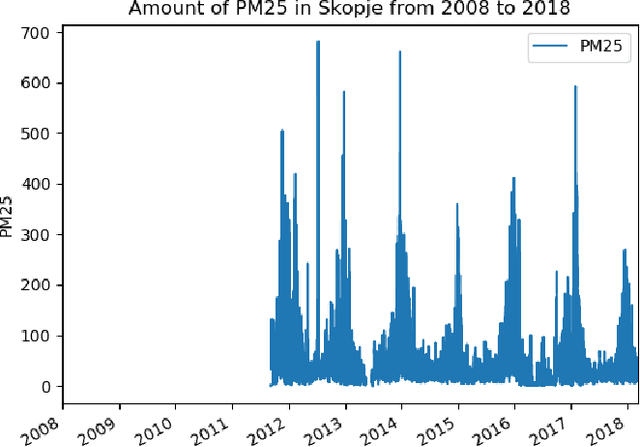
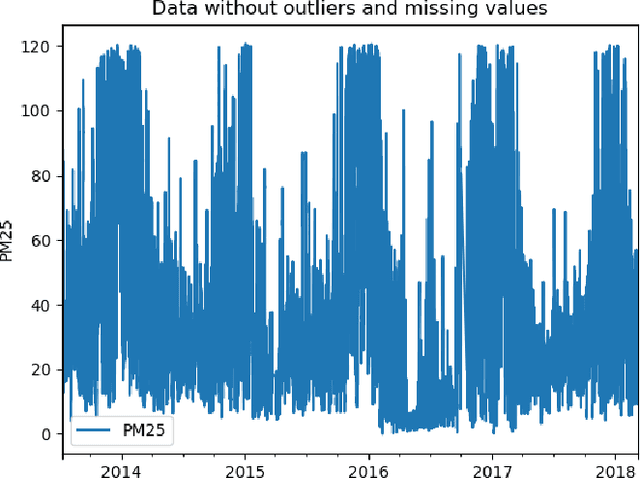
Air pollution is a worldwide issue that affects the lives of many people in urban areas. It is considered that the air pollution may lead to heart and lung diseases. A careful and timely forecast of the air quality could help to reduce the exposure risk for affected people. In this paper, we use a data-driven approach to predict air quality based on historical data. We compare three popular methods for time series prediction: Exponential Smoothing (ES), Auto-Regressive Integrated Moving Average (ARIMA) and Long short-term memory (LSTM). Considering prediction accuracy and time complexity, our experiments reveal that for short-term air pollution prediction ES performs better than ARIMA and LSTM.
Acoustic source localization in the spherical harmonics domain exploiting low-rank approximations
Mar 15, 2023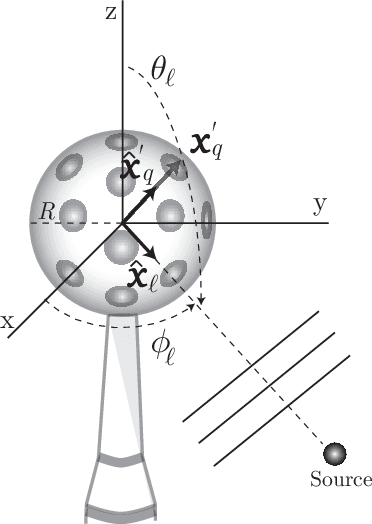
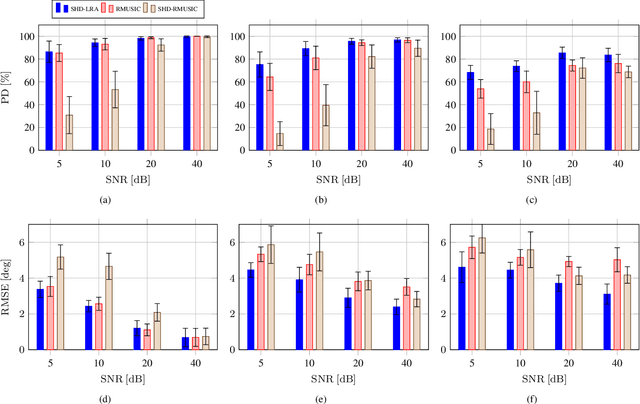
Acoustic signal processing in the spherical harmonics domain (SHD) is an active research area that exploits the signals acquired by higher order microphone arrays. A very important task is that concerning the localization of active sound sources. In this paper, we propose a simple yet effective method to localize prominent acoustic sources in adverse acoustic scenarios. By using a proper normalization and arrangement of the estimated spherical harmonic coefficients, we exploit low-rank approximations to estimate the far field modal directional pattern of the dominant source at each time-frame. The experiments confirm the validity of the proposed approach, with superior performance compared to other recent SHD-based approaches.
* To appear in ICASSP 2023