 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Neural Pre-Processing: A Learning Framework for End-to-end Brain MRI Pre-processing
Mar 21, 2023
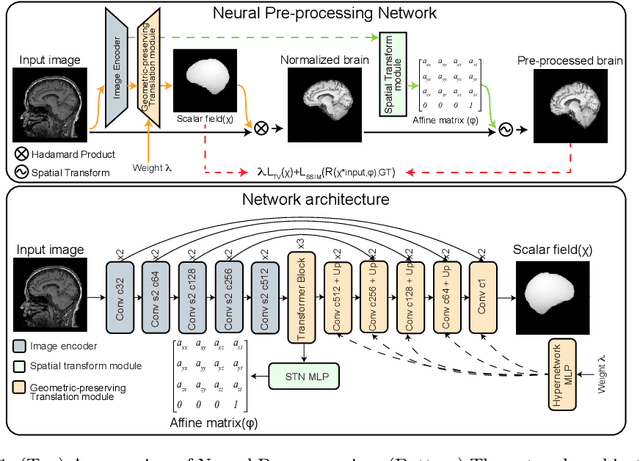
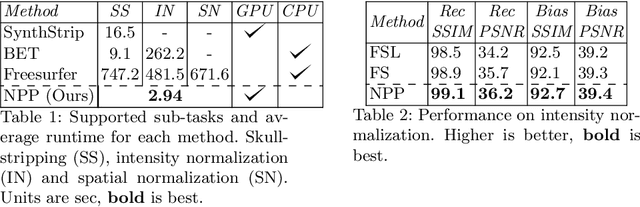
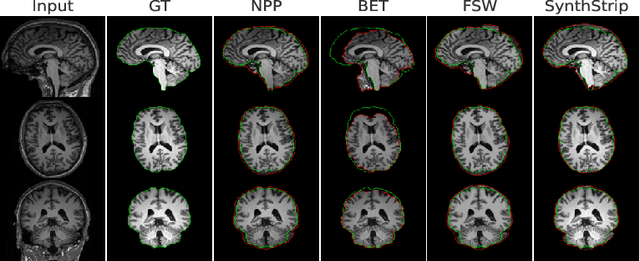
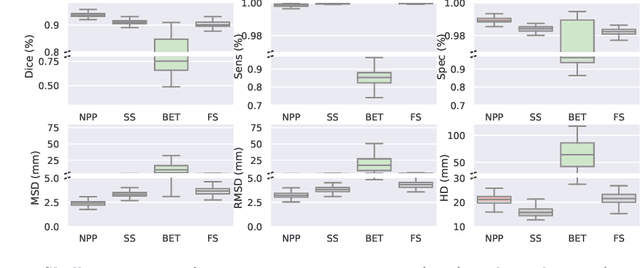
Head MRI pre-processing involves converting raw images to an intensity-normalized, skull-stripped brain in a standard coordinate space. In this paper, we propose an end-to-end weakly supervised learning approach, called Neural Pre-processing (NPP), for solving all three sub-tasks simultaneously via a neural network, trained on a large dataset without individual sub-task supervision. Because the overall objective is highly under-constrained, we explicitly disentangle geometric-preserving intensity mapping (skull-stripping and intensity normalization) and spatial transformation (spatial normalization). Quantitative results show that our model outperforms state-of-the-art methods which tackle only a single sub-task. Our ablation experiments demonstrate the importance of the architecture design we chose for NPP. Furthermore, NPP affords the user the flexibility to control each of these tasks at inference time. The code and model are freely-available at \url{https://github.com/Novestars/Neural-Pre-processing}.
A Survey on Oversmoothing in Graph Neural Networks
Mar 20, 2023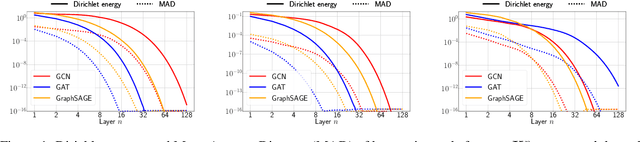

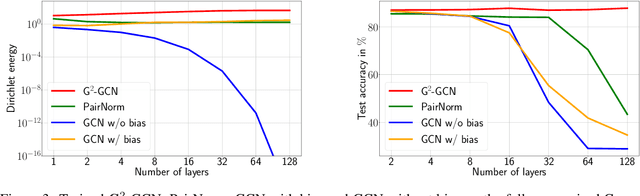
Node features of graph neural networks (GNNs) tend to become more similar with the increase of the network depth. This effect is known as over-smoothing, which we axiomatically define as the exponential convergence of suitable similarity measures on the node features. Our definition unifies previous approaches and gives rise to new quantitative measures of over-smoothing. Moreover, we empirically demonstrate this behavior for several over-smoothing measures on different graphs (small-, medium-, and large-scale). We also review several approaches for mitigating over-smoothing and empirically test their effectiveness on real-world graph datasets. Through illustrative examples, we demonstrate that mitigating over-smoothing is a necessary but not sufficient condition for building deep GNNs that are expressive on a wide range of graph learning tasks. Finally, we extend our definition of over-smoothing to the rapidly emerging field of continuous-time GNNs.
Implicit Temporal Reasoning for Evidence-Based Fact-Checking
Feb 24, 2023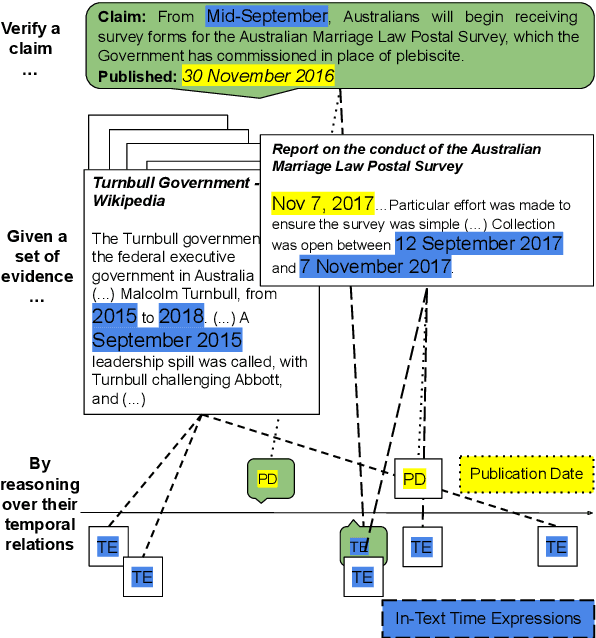
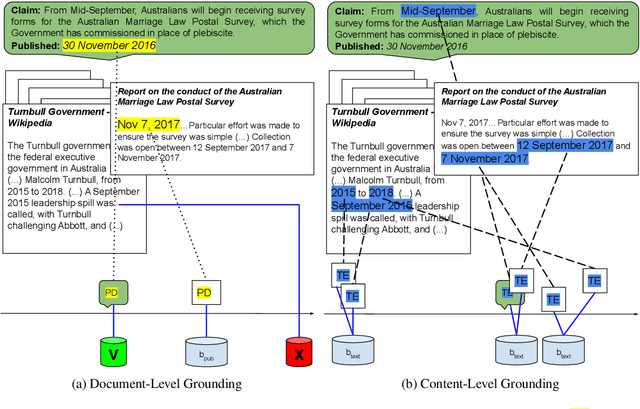
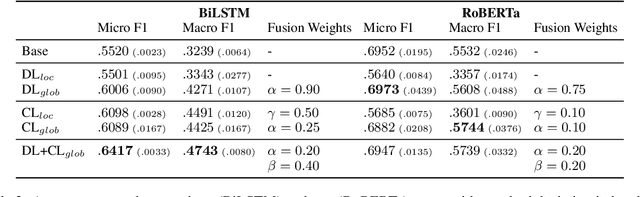
Leveraging contextual knowledge has become standard practice in automated claim verification, yet the impact of temporal reasoning has been largely overlooked. Our study demonstrates that time positively influences the claim verification process of evidence-based fact-checking. The temporal aspects and relations between claims and evidence are first established through grounding on shared timelines, which are constructed using publication dates and time expressions extracted from their text. Temporal information is then provided to RNN-based and Transformer-based classifiers before or after claim and evidence encoding. Our time-aware fact-checking models surpass base models by up to 9% Micro F1 (64.17%) and 15% Macro F1 (47.43%) on the MultiFC dataset. They also outperform prior methods that explicitly model temporal relations between evidence. Our findings show that the presence of temporal information and the manner in which timelines are constructed greatly influence how fact-checking models determine the relevance and supporting or refuting character of evidence documents.
Dynamic Graph Convolution Network with Spatio-Temporal Attention Fusion for Traffic Flow Prediction
Feb 24, 2023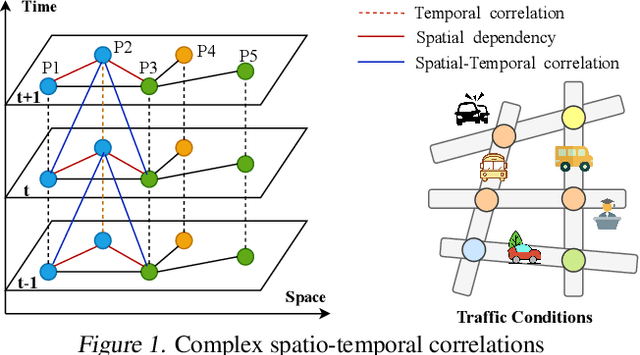
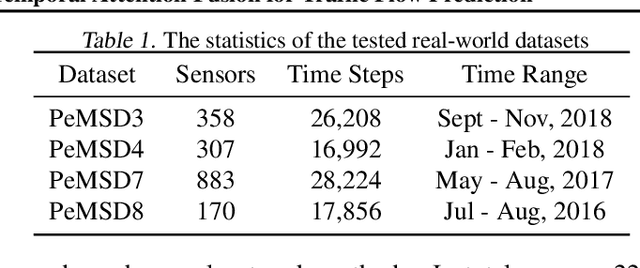
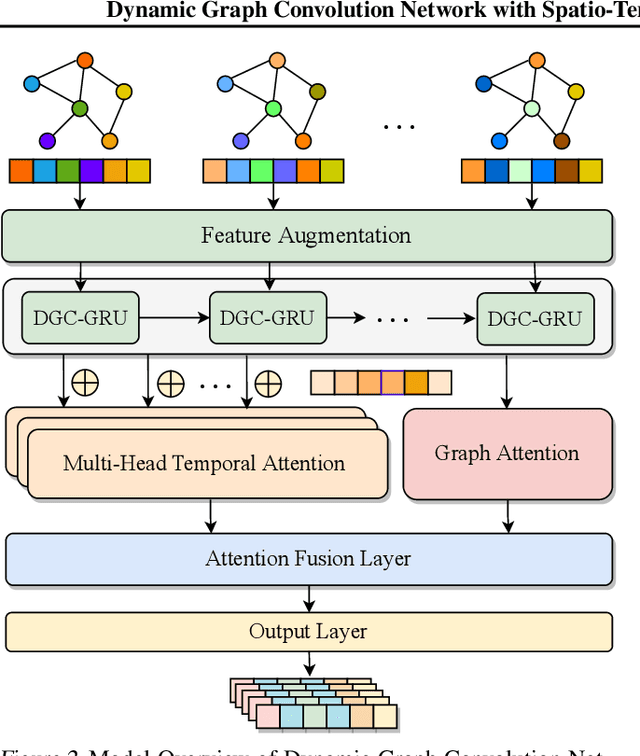
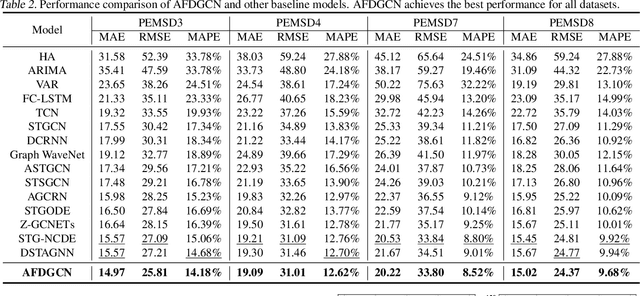
Accurate and real-time traffic state prediction is of great practical importance for urban traffic control and web mapping services (e.g. Google Maps). With the support of massive data, deep learning methods have shown their powerful capability in capturing the complex spatio-temporal patterns of road networks. However, existing approaches use independent components to model temporal and spatial dependencies and thus ignore the heterogeneous characteristics of traffic flow that vary with time and space. In this paper, we propose a novel dynamic graph convolution network with spatio-temporal attention fusion. The method not only captures local spatio-temporal information that changes over time, but also comprehensively models long-distance and multi-scale spatio-temporal patterns based on the fusion mechanism of temporal and spatial attention. This design idea can greatly improve the spatio-temporal perception of the model. We conduct extensive experiments in 4 real-world datasets to demonstrate that our model achieves state-of-the-art performance compared to 22 baseline models.
MFDNet: Towards Real-time Image Denoising On Mobile Devices
Nov 09, 2022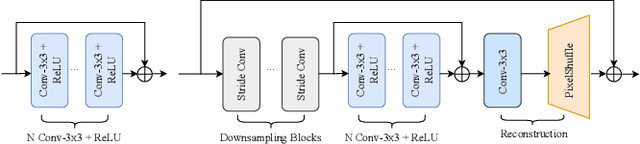

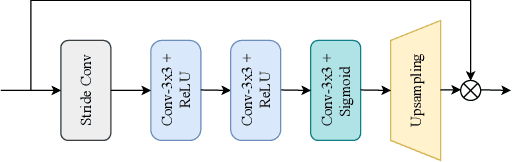
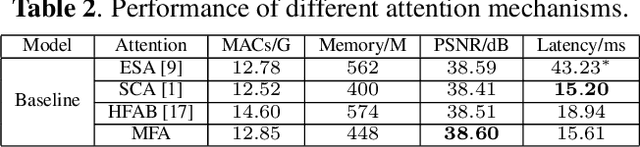
Deep convolutional neural networks have achieved great progress in image denoising tasks. However, their complicated architectures and heavy computational cost hinder their deployments on a mobile device. Some recent efforts in designing lightweight denoising networks focus on reducing either FLOPs (floating-point operations) or the number of parameters. However, these metrics are not directly correlated with the on-device latency. By performing extensive analysis and experiments, we identify the network architectures that can fully utilize powerful neural processing units (NPUs) and thus enjoy both low latency and excellent denoising performance. To this end, we propose a mobile-friendly denoising network, namely MFDNet. The experiments show that MFDNet achieves state-of-the-art performance on real-world denoising benchmarks SIDD and DND under real-time latency on mobile devices. The code and pre-trained models will be released.
Scalability and Sample Efficiency Analysis of Graph Neural Networks for Power System State Estimation
Mar 02, 2023
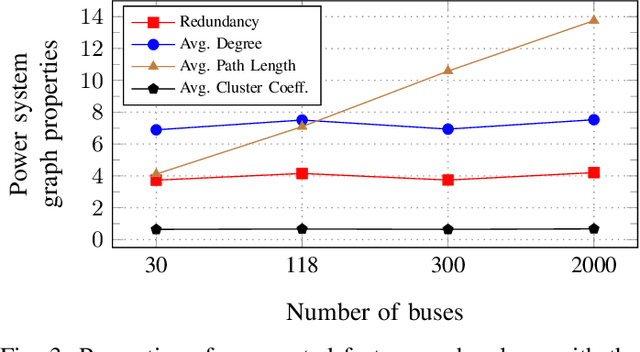
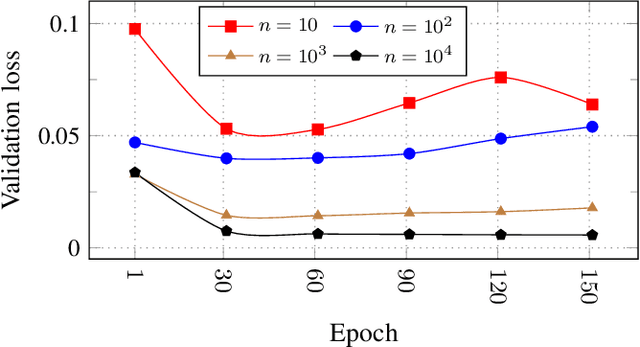
Data-driven state estimation (SE) is becoming increasingly important in modern power systems, as it allows for more efficient analysis of system behaviour using real-time measurement data. This paper thoroughly evaluates a phasor measurement unit-only state estimator based on graph neural networks (GNNs) applied over factor graphs. To assess the sample efficiency of the GNN model, we perform multiple training experiments on various training set sizes. Additionally, to evaluate the scalability of the GNN model, we conduct experiments on power systems of various sizes. Our results show that the GNN-based state estimator exhibits high accuracy and efficient use of data. Additionally, it demonstrated scalability in terms of both memory usage and inference time, making it a promising solution for data-driven SE in modern power systems.
SLAS: Speed and Lane Advisory System for Highway Navigation
Mar 01, 2023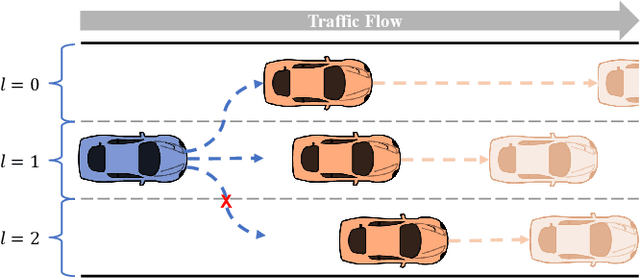
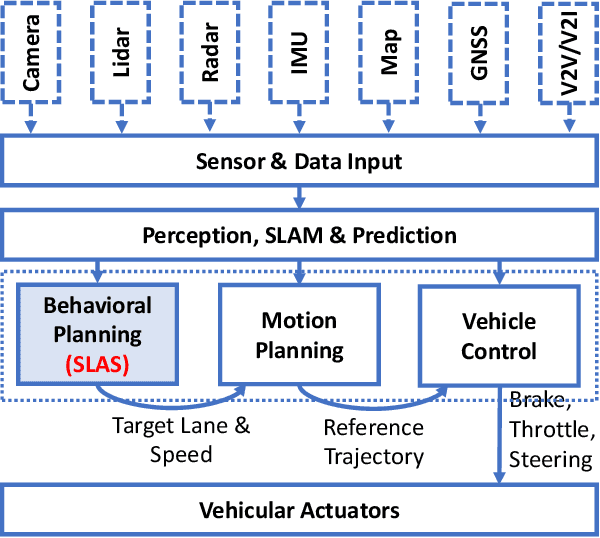
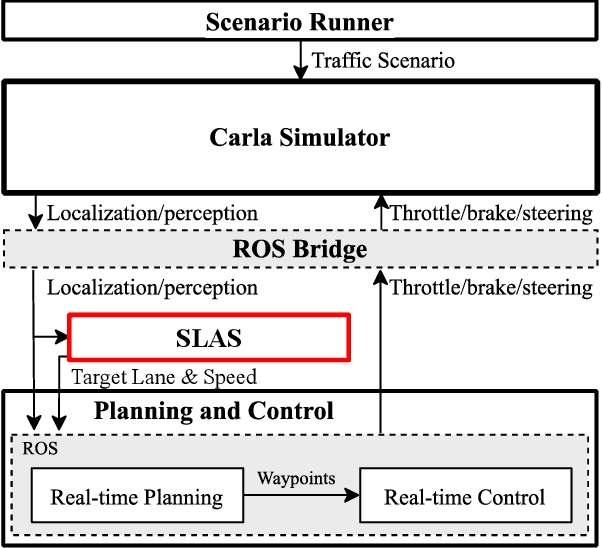

This paper proposes a hierarchical autonomous vehicle navigation architecture, composed of a high-level speed and lane advisory system (SLAS) coupled with low-level trajectory generation and trajectory following modules. Specifically, we target a multi-lane highway driving scenario where an autonomous ego vehicle navigates in traffic. We propose a novel receding horizon mixed-integer optimization based method for SLAS with the objective to minimize travel time while accounting for passenger comfort. We further incorporate various modifications in the proposed approach to improve the overall computational efficiency and achieve real-time performance. We demonstrate the efficacy of the proposed approach in contrast to the existing methods, when applied in conjunction with state-of-the-art trajectory generation and trajectory following frameworks, in a CARLA simulation environment.
* Presented at the IEEE 61st Conference on Decision and Control (CDC), Cancun, Mexico, 2022
Boosting Night-time Scene Parsing with Learnable Frequency
Aug 30, 2022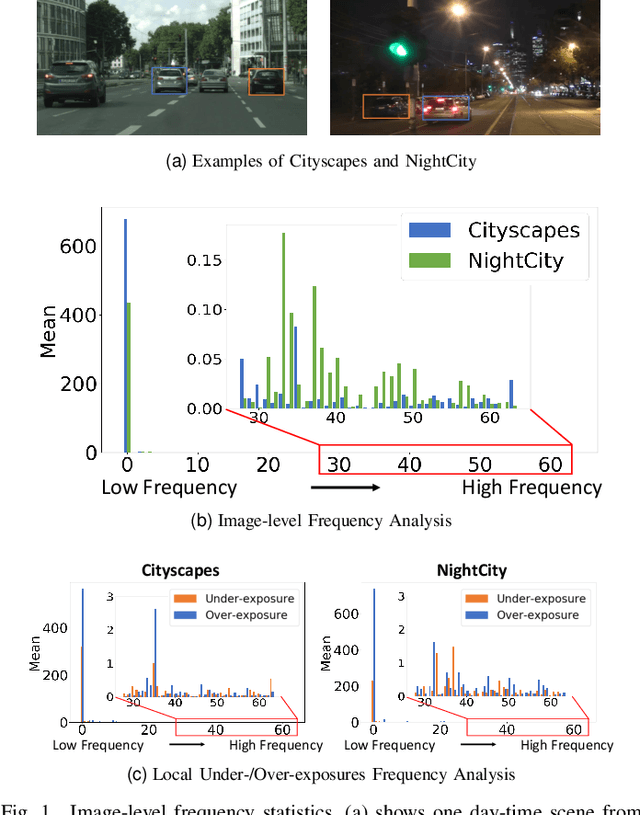
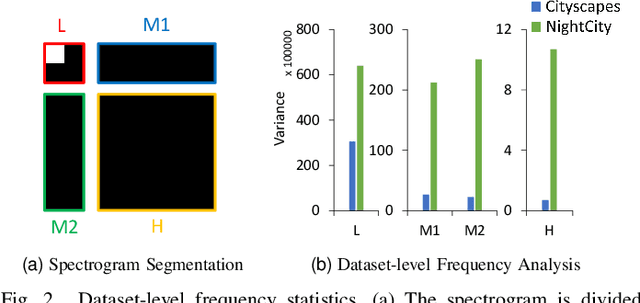
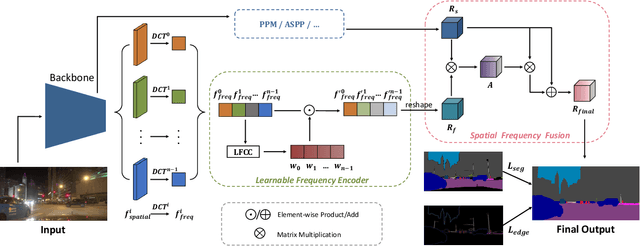
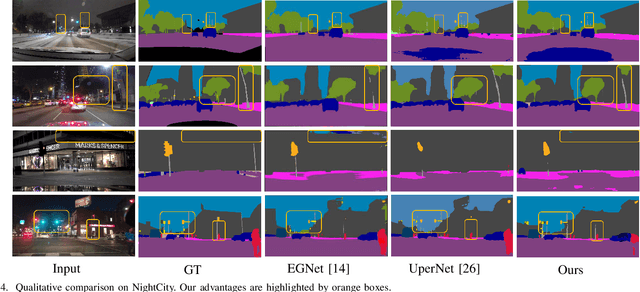
Night-Time Scene Parsing (NTSP) is essential to many vision applications, especially for autonomous driving. Most of the existing methods are proposed for day-time scene parsing. They rely on modeling pixel intensity-based spatial contextual cues under even illumination. Hence, these methods do not perform well in night-time scenes as such spatial contextual cues are buried in the over-/under-exposed regions in night-time scenes. In this paper, we first conduct an image frequency-based statistical experiment to interpret the day-time and night-time scene discrepancies. We find that image frequency distributions differ significantly between day-time and night-time scenes, and understanding such frequency distributions is critical to NTSP problem. Based on this, we propose to exploit the image frequency distributions for night-time scene parsing. First, we propose a Learnable Frequency Encoder (LFE) to model the relationship between different frequency coefficients to measure all frequency components dynamically. Second, we propose a Spatial Frequency Fusion module (SFF) that fuses both spatial and frequency information to guide the extraction of spatial context features. Extensive experiments show that our method performs favorably against the state-of-the-art methods on the NightCity, NightCity+ and BDD100K-night datasets. In addition, we demonstrate that our method can be applied to existing day-time scene parsing methods and boost their performance on night-time scenes.
Augmented Reality Remote Operation of Dual Arm Manipulators in Hot Boxes
Mar 28, 2023

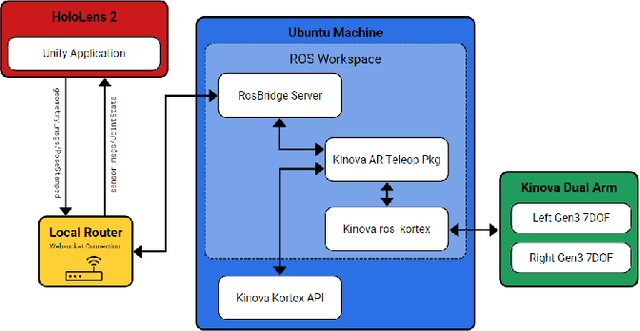
In nuclear isotope and chemistry laboratories, hot cells and gloveboxes provide scientists with a controlled and safe environment to perform experiments. Working on experiments in these isolated containment cells requires scientists to be physically present. For hot cell work today, scientists manipulate equipment and radioactive material inside through a bilateral mechanical control mechanism. Motions produced outside the cell with the master control levers are mechanically transferred to the internal grippers inside the shielded containment cell. There is a growing need to have the capability to conduct experiments within these cells remotely. A simple method to enable remote manipulations within hot cell and glovebox cells is to mount two robotic arms inside a box to mimic the motions of human hands. An AR application was built in this work to allow a user wearing a Microsoft HoloLens 2 headset to teleoperate dual arm manipulators by grasping robotic end-effector digital replicas in AR from a remote location. In addition to the real-time replica of the physical robotic arms in AR, the application enables users to view a live video stream attached to the robotic arms and parse a 3D point cloud of 3D objects in their remote AR environment for better situational awareness. This work also provides users with virtual fixture to assist in manipulation and other teleoperation tasks.
Complexity-calibrated Benchmarks for Machine Learning Reveal When Next-Generation Reservoir Computer Predictions Succeed and Mislead
Mar 25, 2023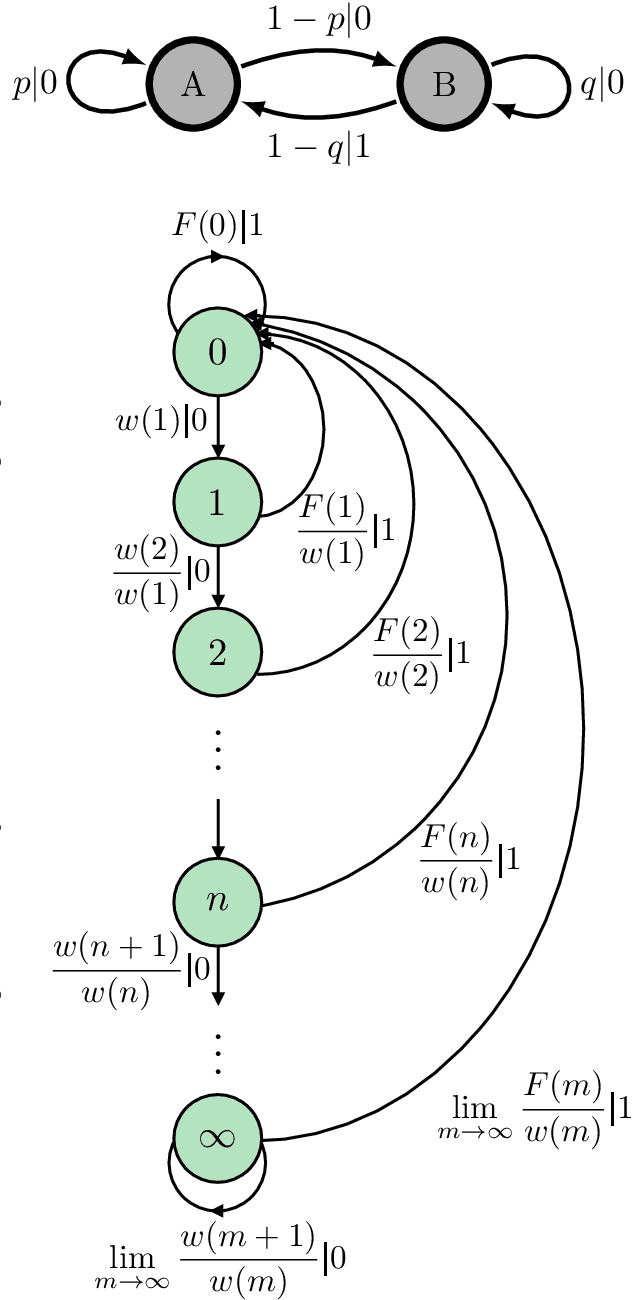
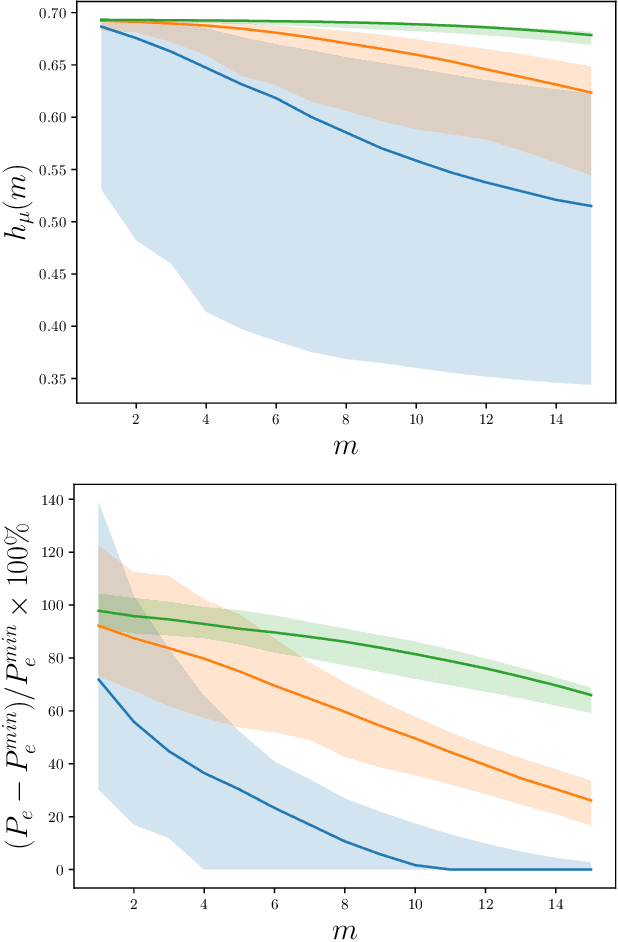
Recurrent neural networks are used to forecast time series in finance, climate, language, and from many other domains. Reservoir computers are a particularly easily trainable form of recurrent neural network. Recently, a "next-generation" reservoir computer was introduced in which the memory trace involves only a finite number of previous symbols. We explore the inherent limitations of finite-past memory traces in this intriguing proposal. A lower bound from Fano's inequality shows that, on highly non-Markovian processes generated by large probabilistic state machines, next-generation reservoir computers with reasonably long memory traces have an error probability that is at least ~ 60% higher than the minimal attainable error probability in predicting the next observation. More generally, it appears that popular recurrent neural networks fall far short of optimally predicting such complex processes. These results highlight the need for a new generation of optimized recurrent neural network architectures. Alongside this finding, we present concentration-of-measure results for randomly-generated but complex processes. One conclusion is that large probabilistic state machines -- specifically, large $\epsilon$-machines -- are key to generating challenging and structurally-unbiased stimuli for ground-truthing recurrent neural network architectures.