 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A unified scalable framework for causal sweeping strategies for Physics-Informed Neural Networks (PINNs) and their temporal decompositions
Feb 28, 2023
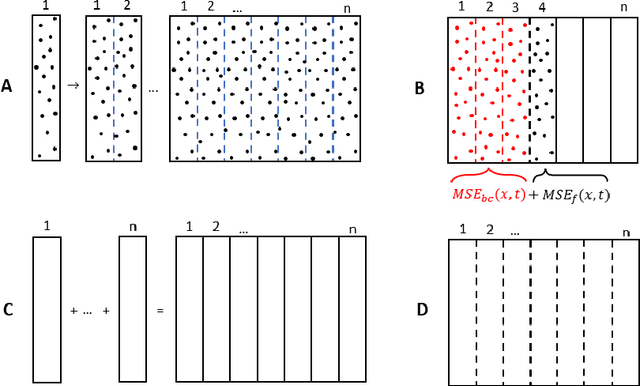

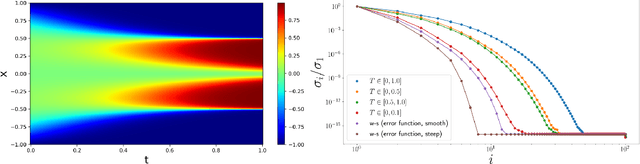
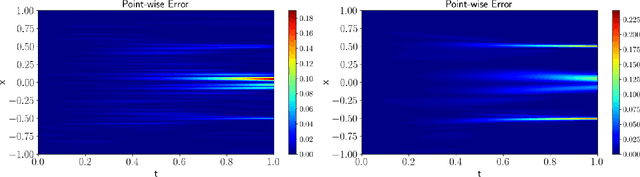
Physics-informed neural networks (PINNs) as a means of solving partial differential equations (PDE) have garnered much attention in Computational Science and Engineering (CS&E). However, a recent topic of interest is exploring various training (i.e., optimization) challenges - in particular, arriving at poor local minima in the optimization landscape results in a PINN approximation giving an inferior, and sometimes trivial, solution when solving forward time-dependent PDEs with no data. This problem is also found in, and in some sense more difficult, with domain decomposition strategies such as temporal decomposition using XPINNs. To address this problem, we first enable a general categorization for previous causality methods, from which we identify a gap in the previous approaches. We then furnish examples and explanations for different training challenges, their cause, and how they relate to information propagation and temporal decomposition. We propose a solution to fill this gap by reframing these causality concepts into a generalized information propagation framework in which any prior method or combination of methods can be described. Our unified framework moves toward reducing the number of PINN methods to consider and the implementation and retuning cost for thorough comparisons. We propose a new stacked-decomposition method that bridges the gap between time-marching PINNs and XPINNs. We also introduce significant computational speed-ups by using transfer learning concepts to initialize subnetworks in the domain and loss tolerance-based propagation for the subdomains. We formulate a new time-sweeping collocation point algorithm inspired by the previous PINNs causality literature, which our framework can still describe, and provides a significant computational speed-up via reduced-cost collocation point segmentation. Finally, we provide numerical results on baseline PDE problems.
Decoding and Visualising Intended Emotion in an Expressive Piano Performance
Mar 03, 2023
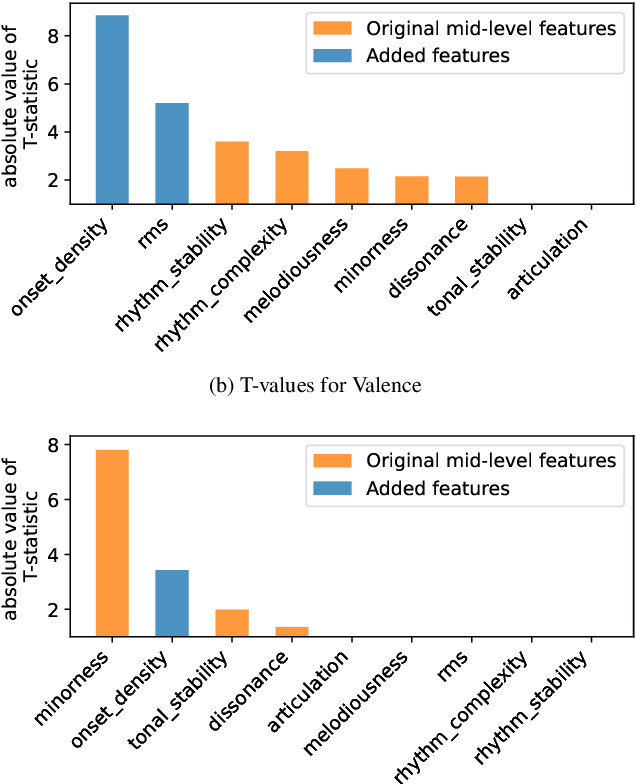
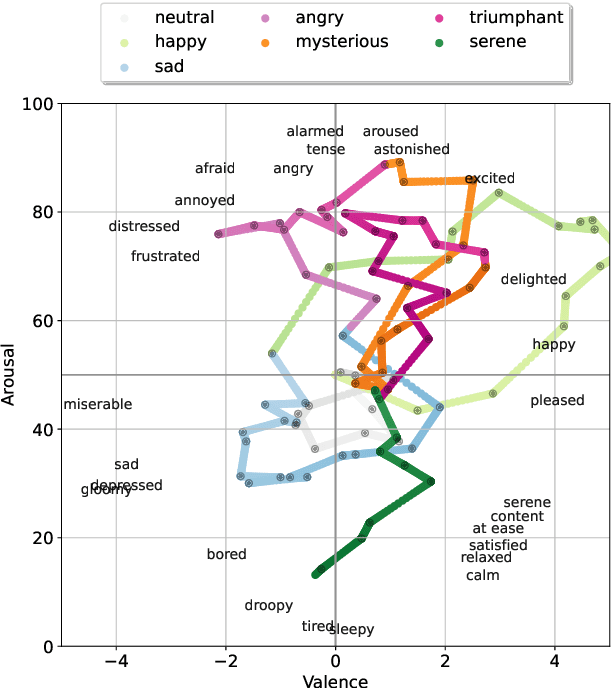
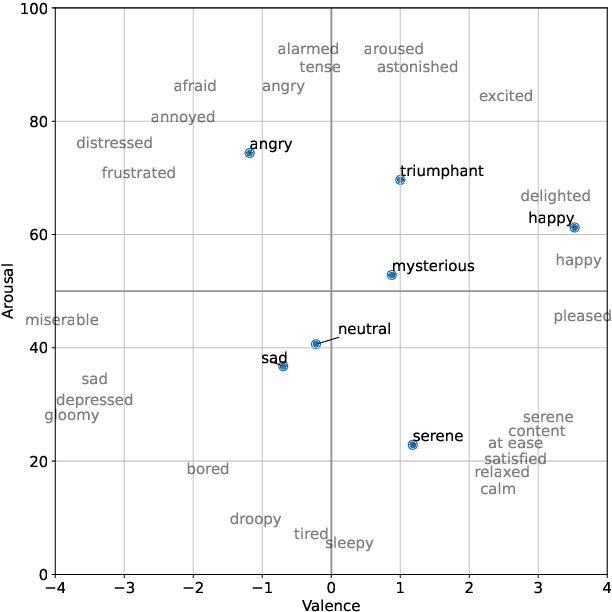
Expert musicians can mould a musical piece to convey specific emotions that they intend to communicate. In this paper, we place a mid-level features based music emotion model in this performer-to-listener communication scenario, and demonstrate via a small visualisation music emotion decoding in real time. We also extend the existing set of mid-level features using analogues of perceptual speed and perceived dynamics.
DevelSet: Deep Neural Level Set for Instant Mask Optimization
Mar 18, 2023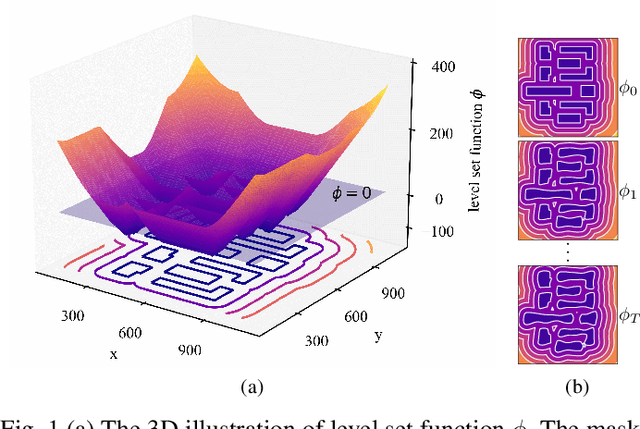
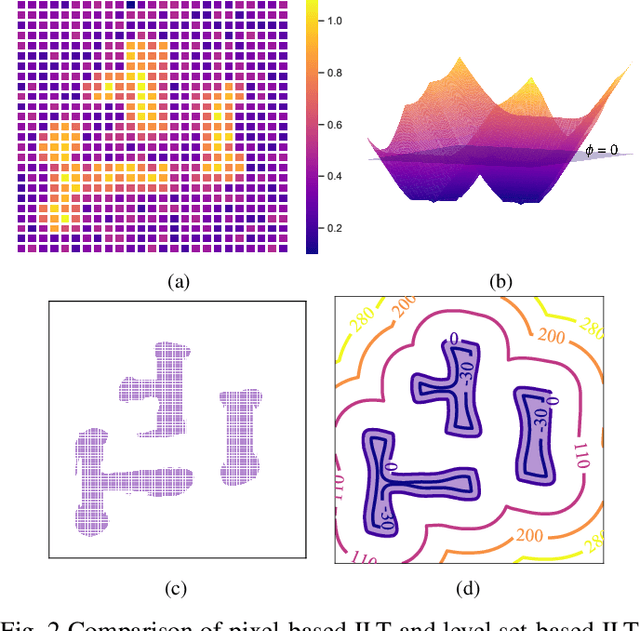
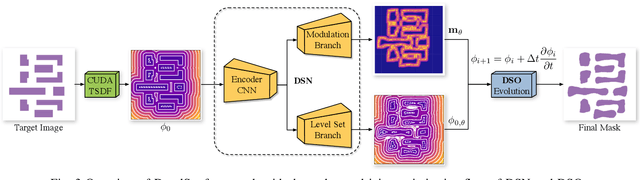

With the feature size continuously shrinking in advanced technology nodes, mask optimization is increasingly crucial in the conventional design flow, accompanied by an explosive growth in prohibitive computational overhead in optical proximity correction (OPC) methods. Recently, inverse lithography technique (ILT) has drawn significant attention and is becoming prevalent in emerging OPC solutions. However, ILT methods are either time-consuming or in weak performance of mask printability and manufacturability. In this paper, we present DevelSet, a GPU and deep neural network (DNN) accelerated level set OPC framework for metal layer. We first improve the conventional level set-based ILT algorithm by introducing the curvature term to reduce mask complexity and applying GPU acceleration to overcome computational bottlenecks. To further enhance printability and fast iterative convergence, we propose a novel deep neural network delicately designed with level set intrinsic principles to facilitate the joint optimization of DNN and GPU accelerated level set optimizer. Experimental results show that DevelSet framework surpasses the state-of-the-art methods in printability and boost the runtime performance achieving instant level (around 1 second).
Identification of Novel Classes for Improving Few-Shot Object Detection
Mar 18, 2023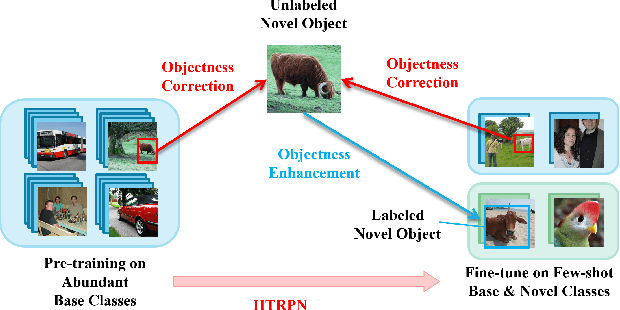
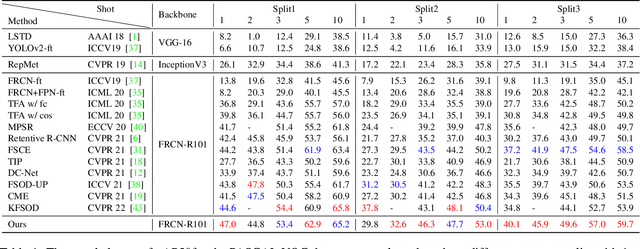

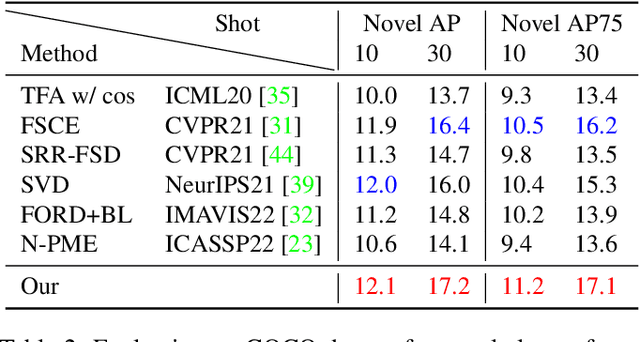
Conventional training of deep neural networks requires a large number of the annotated image which is a laborious and time-consuming task, particularly for rare objects. Few-shot object detection (FSOD) methods offer a remedy by realizing robust object detection using only a few training samples per class. An unexplored challenge for FSOD is that instances from unlabeled novel classes that do not belong to the fixed set of training classes appear in the background. These objects behave similarly to label noise, leading to FSOD performance degradation. We develop a semi-supervised algorithm to detect and then utilize these unlabeled novel objects as positive samples during training to improve FSOD performance. Specifically, we propose a hierarchical ternary classification region proposal network (HTRPN) to localize the potential unlabeled novel objects and assign them new objectness labels. Our improved hierarchical sampling strategy for the region proposal network (RPN) also boosts the perception ability of the object detection model for large objects. Our experimental results indicate that our method is effective and outperforms the existing state-of-the-art (SOTA) FSOD methods.
Empirical Evaluation of Data Augmentations for Biobehavioral Time Series Data with Deep Learning
Oct 13, 2022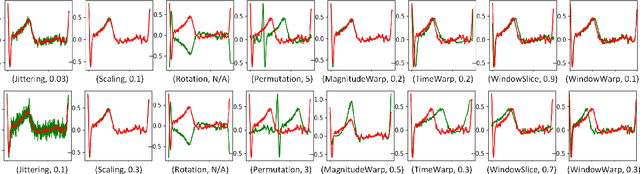
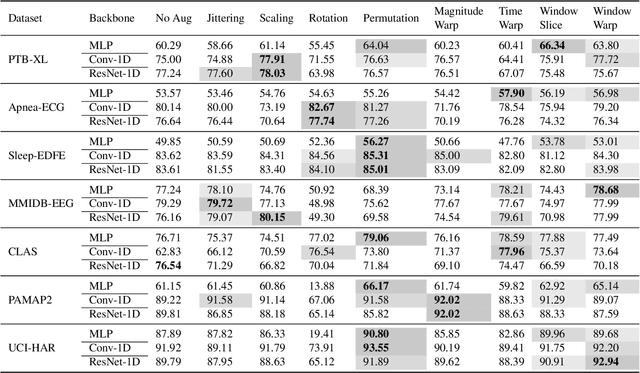
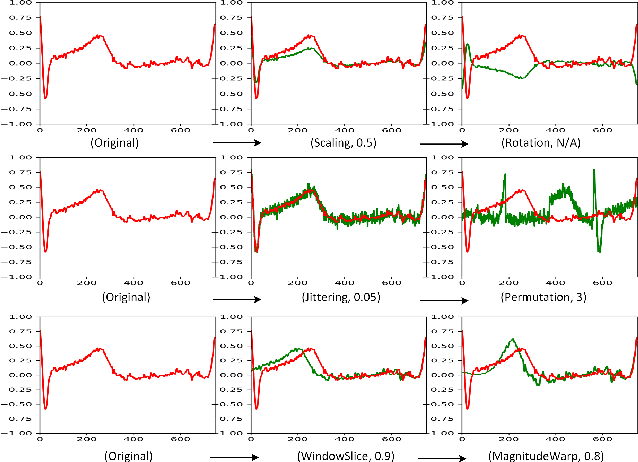
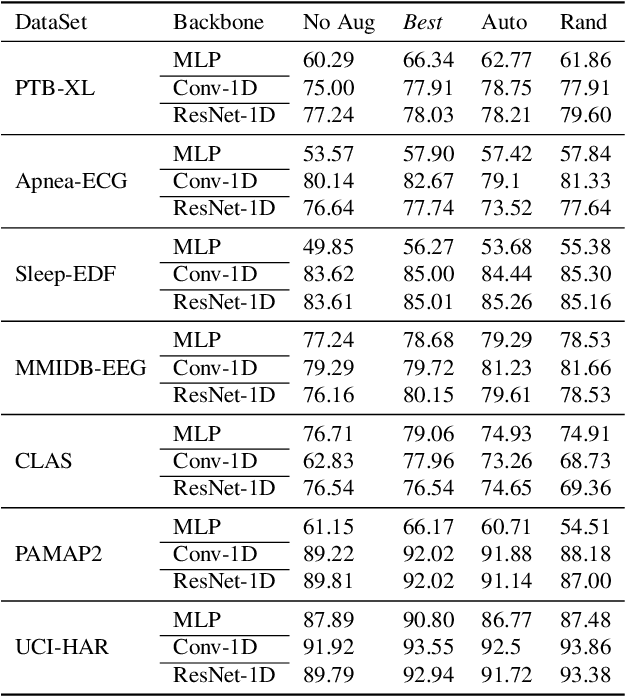
Deep learning has performed remarkably well on many tasks recently. However, the superior performance of deep models relies heavily on the availability of a large number of training data, which limits the wide adaptation of deep models on various clinical and affective computing tasks, as the labeled data are usually very limited. As an effective technique to increase the data variability and thus train deep models with better generalization, data augmentation (DA) is a critical step for the success of deep learning models on biobehavioral time series data. However, the effectiveness of various DAs for different datasets with different tasks and deep models is understudied for biobehavioral time series data. In this paper, we first systematically review eight basic DA methods for biobehavioral time series data, and evaluate the effects on seven datasets with three backbones. Next, we explore adapting more recent DA techniques (i.e., automatic augmentation, random augmentation) to biobehavioral time series data by designing a new policy architecture applicable to time series data. Last, we try to answer the question of why a DA is effective (or not) by first summarizing two desired attributes for augmentations (challenging and faithful), and then utilizing two metrics to quantitatively measure the corresponding attributes, which can guide us in the search for more effective DA for biobehavioral time series data by designing more challenging but still faithful transformations. Our code and results are available at Link.
Privacy-Preserving Cooperative Visible Light Positioning for Nonstationary Environment: A Federated Learning Perspective
Mar 11, 2023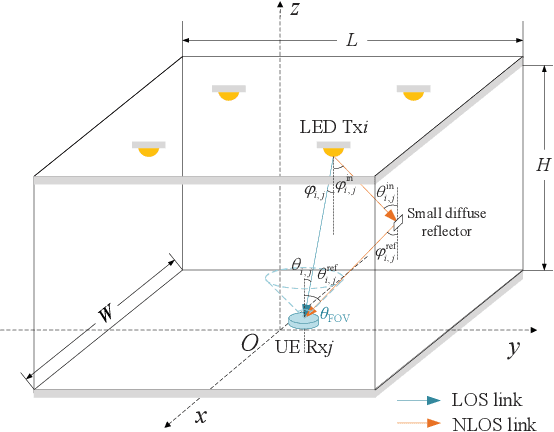
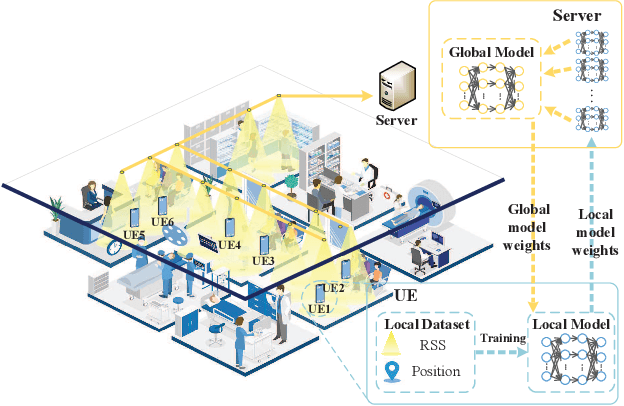
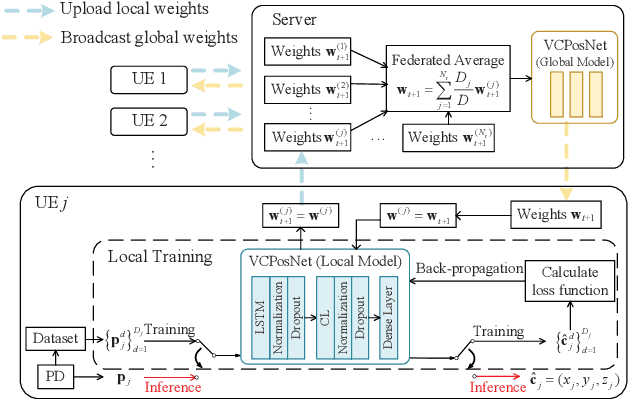
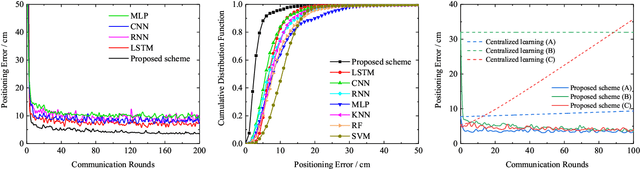
Visible light positioning (VLP) has drawn plenty of attention as a promising indoor positioning technique. However, in nonstationary environments, the performance of VLP is limited because of the highly time-varying channels. To improve the positioning accuracy and generalization capability in nonstationary environments, a cooperative VLP scheme based on federated learning (FL) is proposed in this paper. Exploiting the FL framework, a global model adaptive to environmental changes can be jointly trained by users without sharing private data of users. Moreover, a Cooperative Visible-light Positioning Network (CVPosNet) is proposed to accelerate the convergence rate and improve the positioning accuracy. Simulation results show that the proposed scheme outperforms the benchmark schemes, especially in nonstationary environments.
3DInAction: Understanding Human Actions in 3D Point Clouds
Mar 11, 2023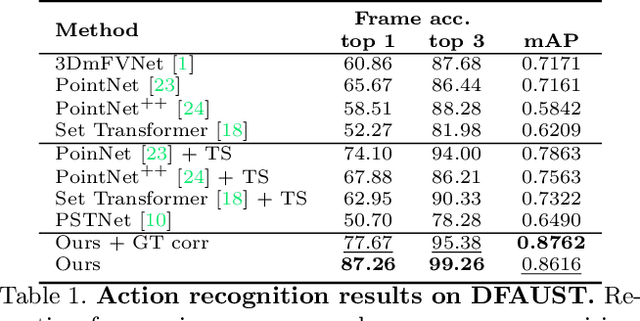
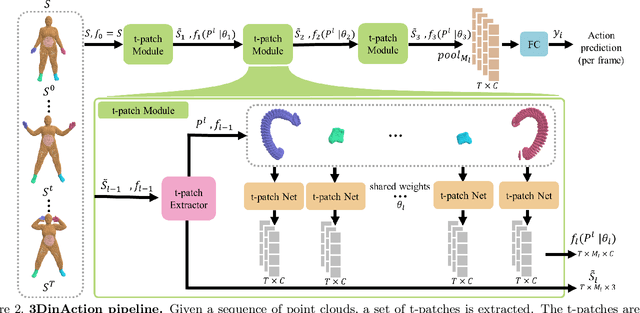
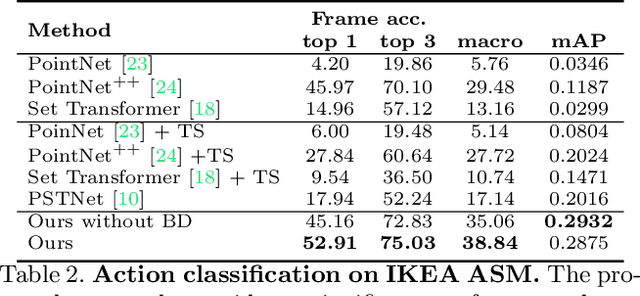
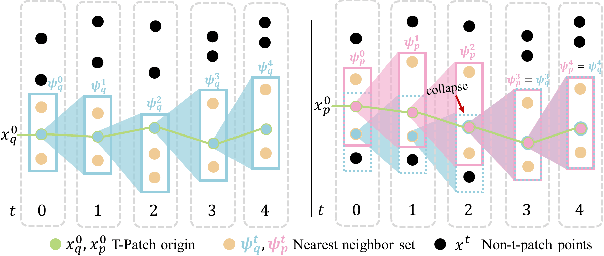
We propose a novel method for 3D point cloud action recognition. Understanding human actions in RGB videos has been widely studied in recent years, however, its 3D point cloud counterpart remains under-explored. This is mostly due to the inherent limitation of the point cloud data modality -- lack of structure, permutation invariance, and varying number of points -- which makes it difficult to learn a spatio-temporal representation. To address this limitation, we propose the 3DinAction pipeline that first estimates patches moving in time (t-patches) as a key building block, alongside a hierarchical architecture that learns an informative spatio-temporal representation. We show that our method achieves improved performance on existing datasets, including DFAUST and IKEA ASM.
Brain Diffuser: An End-to-End Brain Image to Brain Network Pipeline
Mar 11, 2023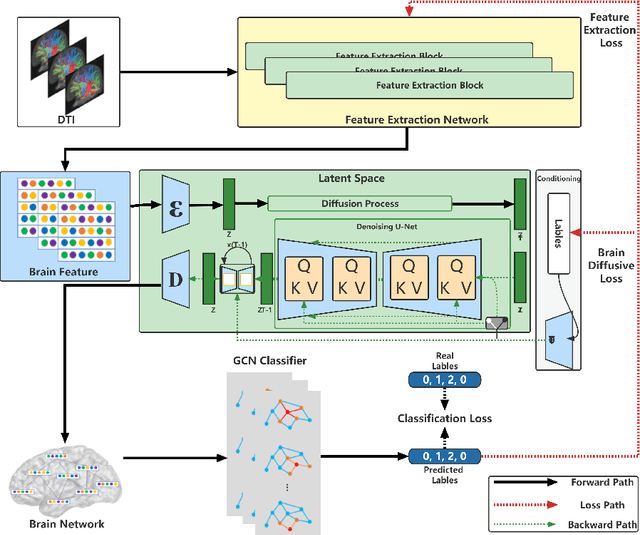
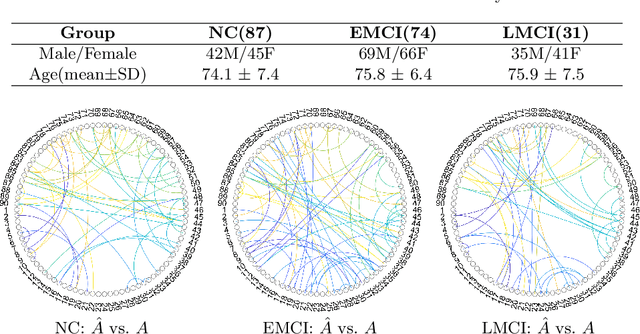

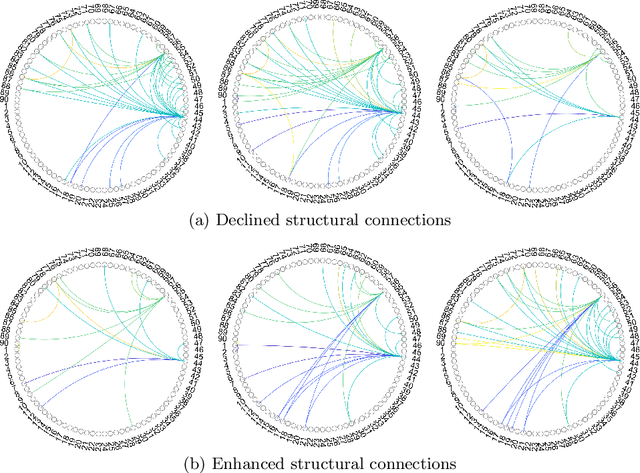
Brain network analysis is essential for diagnosing and intervention for Alzheimer's disease (AD). However, previous research relied primarily on specific time-consuming and subjective toolkits. Only few tools can obtain the structural brain networks from brain diffusion tensor images (DTI). In this paper, we propose a diffusion based end-to-end brain network generative model Brain Diffuser that directly shapes the structural brain networks from DTI. Compared to existing toolkits, Brain Diffuser exploits more structural connectivity features and disease-related information by analyzing disparities in structural brain networks across subjects. For the case of Alzheimer's disease, the proposed model performs better than the results from existing toolkits on the Alzheimer's Disease Neuroimaging Initiative (ADNI) database.
Vibration Signal Denoising Using Deep Learning
Mar 11, 2023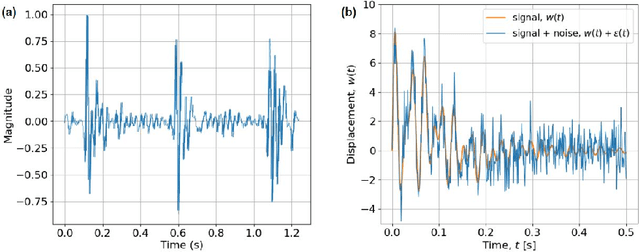
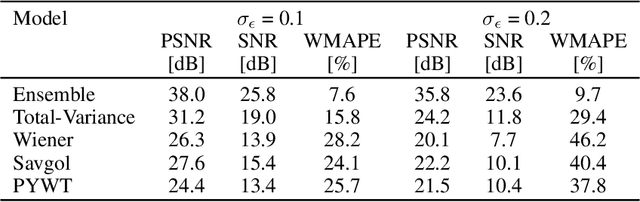
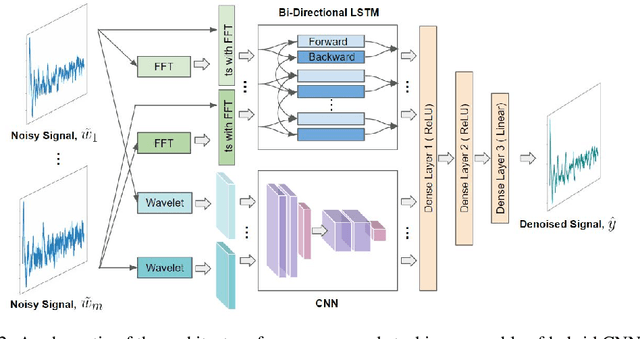
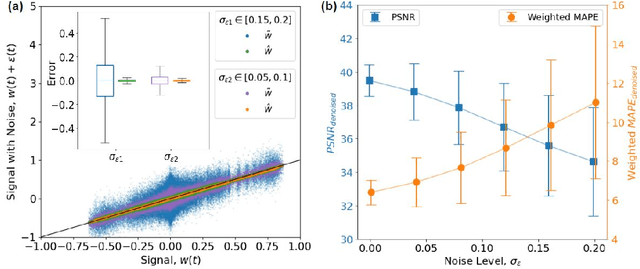
Structure vibration signals induced by footsteps are widely used for tasks like occupant identification, localization, human activity inference, structure health monitoring and so on. The vibration signals are collected as time series with amplitude values. However, the collected signals are always noisy in practice due to the influence of environmental noise, electromagnetic interference and other factors. The presence of noise affects the process of signal analysis, thus affecting the accuracy and error of the final tasks. In this paper, we mainly explore the denoising methods for footstep-induced vibration signals. We have considered different kinds of noise including stationary noises such as gaussian noises and non-stationary noises such as item-dropping vibration noise and music noises.
Practical Knowledge Distillation: Using DNNs to Beat DNNs
Mar 01, 2023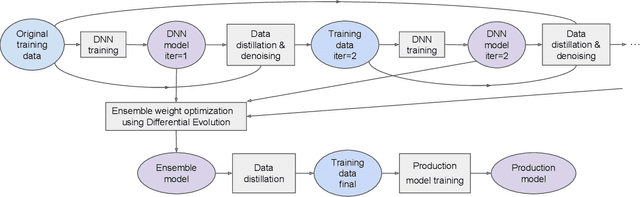
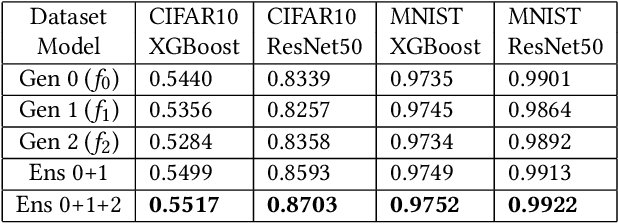
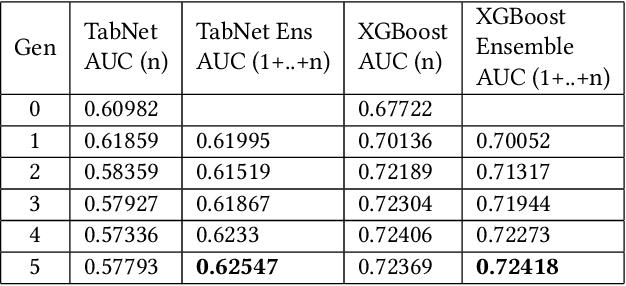

For tabular data sets, we explore data and model distillation, as well as data denoising. These techniques improve both gradient-boosting models and a specialized DNN architecture. While gradient boosting is known to outperform DNNs on tabular data, we close the gap for datasets with 100K+ rows and give DNNs an advantage on small data sets. We extend these results with input-data distillation and optimized ensembling to help DNN performance match or exceed that of gradient boosting. As a theoretical justification of our practical method, we prove its equivalence to classical cross-entropy knowledge distillation. We also qualitatively explain the superiority of DNN ensembles over XGBoost on small data sets. For an industry end-to-end real-time ML platform with 4M production inferences per second, we develop a model-training workflow based on data sampling that distills ensembles of models into a single gradient-boosting model favored for high-performance real-time inference, without performance loss. Empirical evaluation shows that the proposed combination of methods consistently improves model accuracy over prior best models across several production applications deployed worldwide.