 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Efficient Meshy Neural Fields for Animatable Human Avatars
Mar 23, 2023
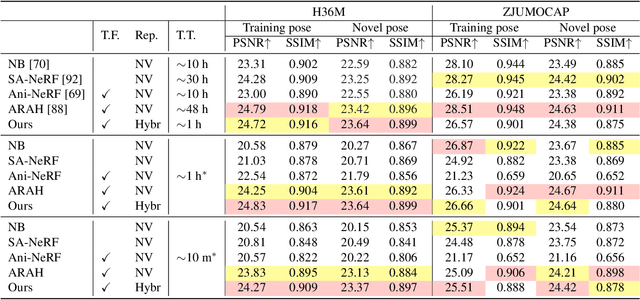
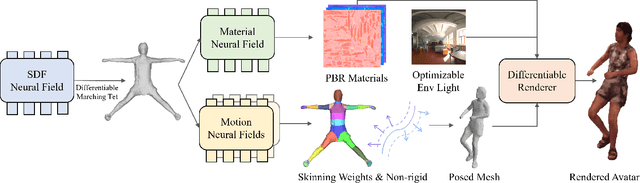
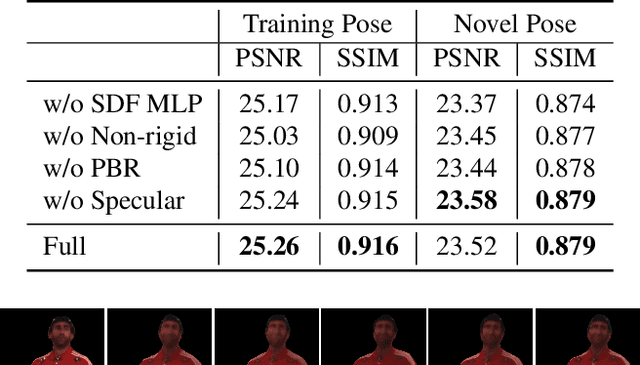

Efficiently digitizing high-fidelity animatable human avatars from videos is a challenging and active research topic. Recent volume rendering-based neural representations open a new way for human digitization with their friendly usability and photo-realistic reconstruction quality. However, they are inefficient for long optimization times and slow inference speed; their implicit nature results in entangled geometry, materials, and dynamics of humans, which are hard to edit afterward. Such drawbacks prevent their direct applicability to downstream applications, especially the prominent rasterization-based graphic ones. We present EMA, a method that Efficiently learns Meshy neural fields to reconstruct animatable human Avatars. It jointly optimizes explicit triangular canonical mesh, spatial-varying material, and motion dynamics, via inverse rendering in an end-to-end fashion. Each above component is derived from separate neural fields, relaxing the requirement of a template, or rigging. The mesh representation is highly compatible with the efficient rasterization-based renderer, thus our method only takes about an hour of training and can render in real-time. Moreover, only minutes of optimization is enough for plausible reconstruction results. The disentanglement of meshes enables direct downstream applications. Extensive experiments illustrate the very competitive performance and significant speed boost against previous methods. We also showcase applications including novel pose synthesis, material editing, and relighting. The project page: https://xk-huang.github.io/ema/.
Plug-and-Play Regulators for Image-Text Matching
Mar 23, 2023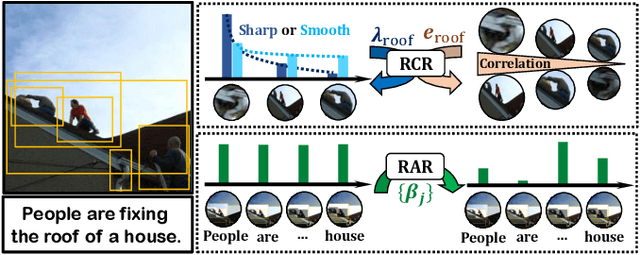
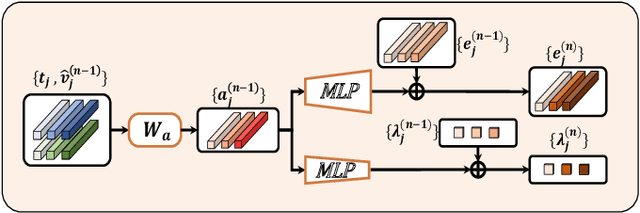
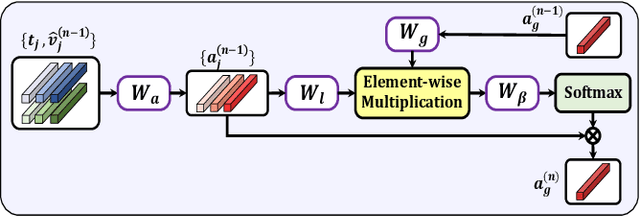
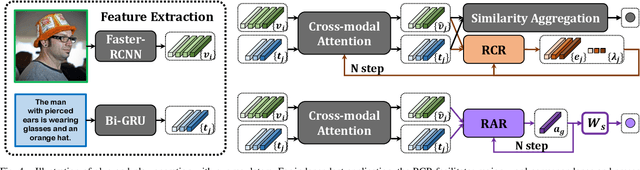
Exploiting fine-grained correspondence and visual-semantic alignments has shown great potential in image-text matching. Generally, recent approaches first employ a cross-modal attention unit to capture latent region-word interactions, and then integrate all the alignments to obtain the final similarity. However, most of them adopt one-time forward association or aggregation strategies with complex architectures or additional information, while ignoring the regulation ability of network feedback. In this paper, we develop two simple but quite effective regulators which efficiently encode the message output to automatically contextualize and aggregate cross-modal representations. Specifically, we propose (i) a Recurrent Correspondence Regulator (RCR) which facilitates the cross-modal attention unit progressively with adaptive attention factors to capture more flexible correspondence, and (ii) a Recurrent Aggregation Regulator (RAR) which adjusts the aggregation weights repeatedly to increasingly emphasize important alignments and dilute unimportant ones. Besides, it is interesting that RCR and RAR are plug-and-play: both of them can be incorporated into many frameworks based on cross-modal interaction to obtain significant benefits, and their cooperation achieves further improvements. Extensive experiments on MSCOCO and Flickr30K datasets validate that they can bring an impressive and consistent R@1 gain on multiple models, confirming the general effectiveness and generalization ability of the proposed methods. Code and pre-trained models are available at: https://github.com/Paranioar/RCAR.
Multi-Antenna Dual-Blind Deconvolution for Joint Radar-Communications via SoMAN Minimization
Mar 23, 2023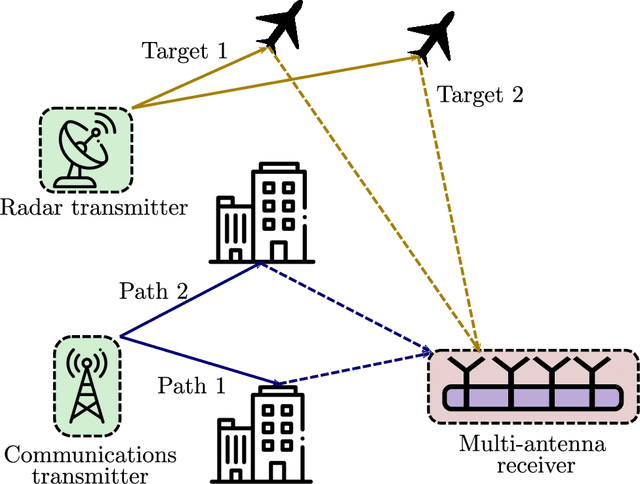
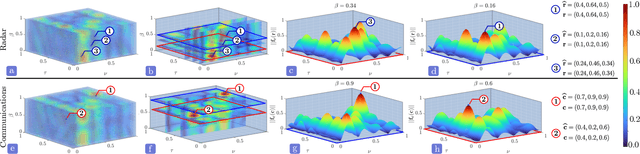
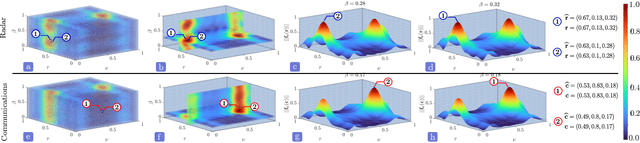
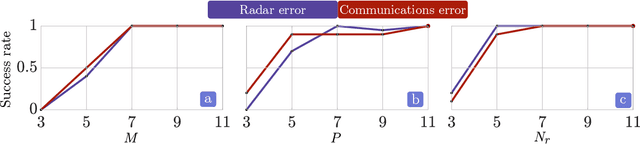
Joint radar-communications (JRC) has emerged as a promising technology for efficiently using the limited electromagnetic spectrum. In JRC applications such as secure military receivers, often the radar and communications signals are overlaid in the received signal. In these passive listening outposts, the signals and channels of both radar and communications are unknown to the receiver. The ill-posed problem of recovering all signal and channel parameters from the overlaid signal is terms as dual-blind deconvolution (DBD). In this work, we investigate a more challenging version of DBD with a multi-antenna receiver. We model the radar and communications channels with a few (sparse) continuous-valued parameters such as time delays, Doppler velocities, and directions-of-arrival (DoAs). To solve this highly ill-posed DBD, we propose to minimize the sum of multivariate atomic norms (SoMAN) that depends on the unknown parameters. To this end, we devise an exact semidefinite program using theories of positive hyperoctant trigonometric polynomials (PhTP). Our theoretical analyses show that the minimum number of samples and antennas required for perfect recovery is logarithmically dependent on the maximum of the number of radar targets and communications paths rather than their sum. We show that our approach is easily generalized to include several practical issues such as gain/phase errors and additive noise. Numerical experiments show the exact parameter recovery for different JRC
Efficient Neural Architecture Search for Emotion Recognition
Mar 23, 2023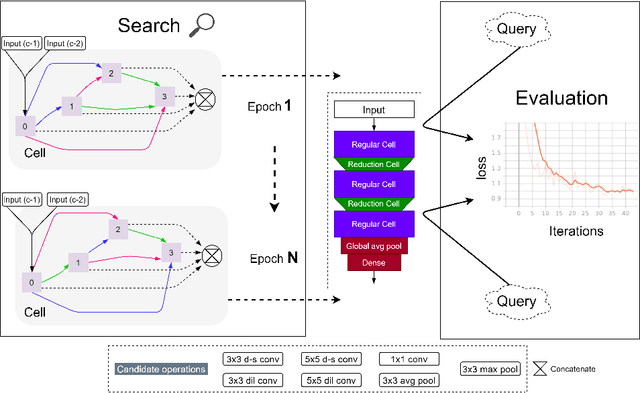
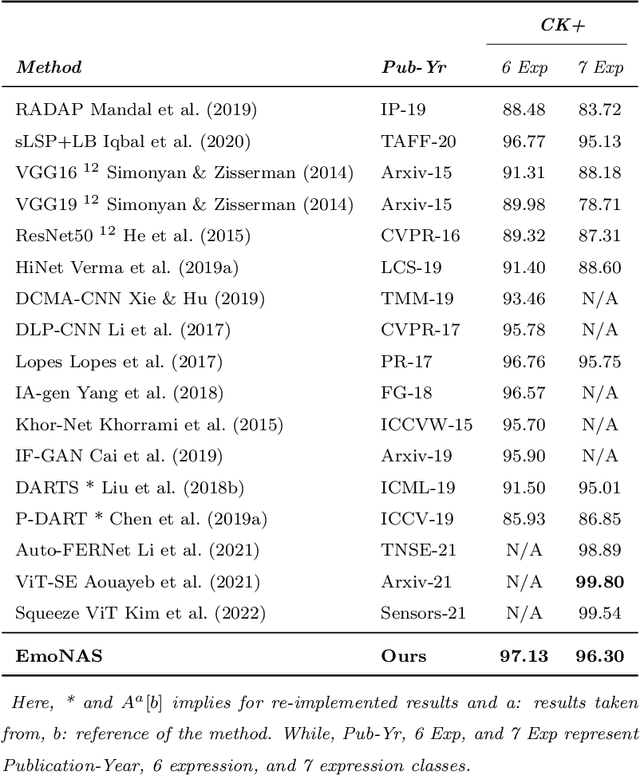

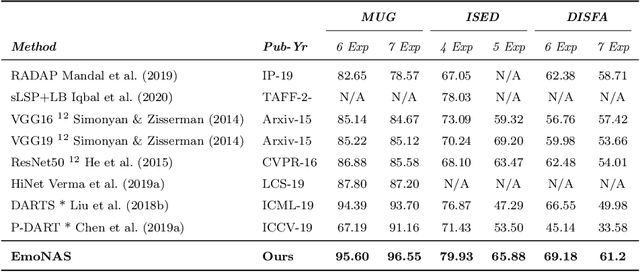
Automated human emotion recognition from facial expressions is a well-studied problem and still remains a very challenging task. Some efficient or accurate deep learning models have been presented in the literature. However, it is quite difficult to design a model that is both efficient and accurate at the same time. Moreover, identifying the minute feature variations in facial regions for both macro and micro-expressions requires expertise in network design. In this paper, we proposed to search for a highly efficient and robust neural architecture for both macro and micro-level facial expression recognition. To the best of our knowledge, this is the first attempt to design a NAS-based solution for both macro and micro-expression recognition. We produce lightweight models with a gradient-based architecture search algorithm. To maintain consistency between macro and micro-expressions, we utilize dynamic imaging and convert microexpression sequences into a single frame, preserving the spatiotemporal features in the facial regions. The EmoNAS has evaluated over 13 datasets (7 macro expression datasets: CK+, DISFA, MUG, ISED, OULU-VIS CASIA, FER2013, RAF-DB, and 6 micro-expression datasets: CASME-I, CASME-II, CAS(ME)2, SAMM, SMIC, MEGC2019 challenge). The proposed models outperform the existing state-of-the-art methods and perform very well in terms of speed and space complexity.
Quantized Phase Alignment by Discrete Phase Shifts for Reconfigurable Intelligent Surface-Assisted Communication Systems
Mar 23, 2023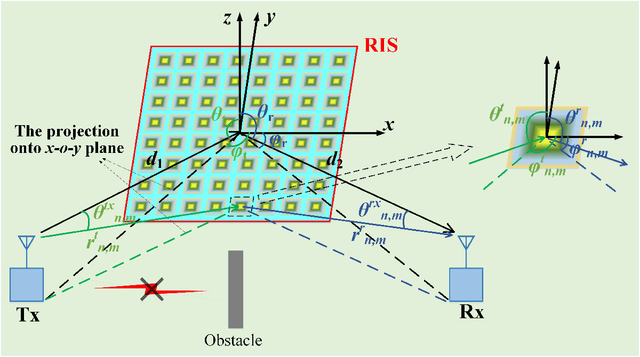
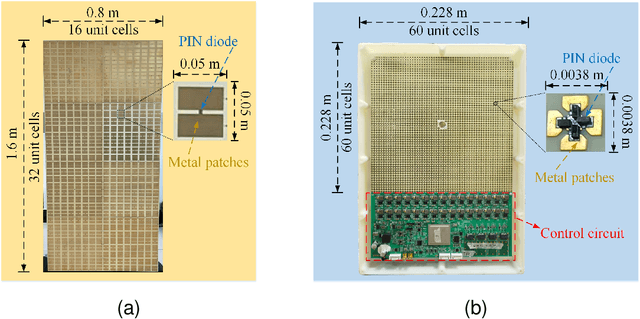
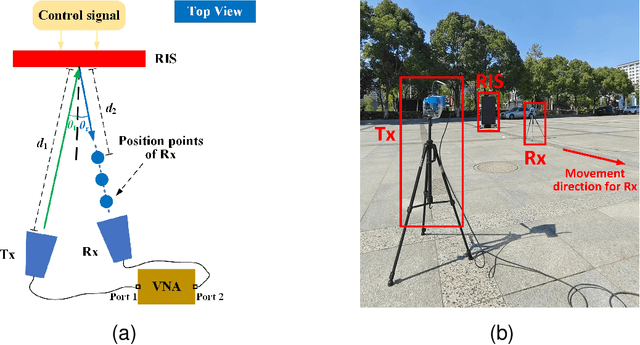
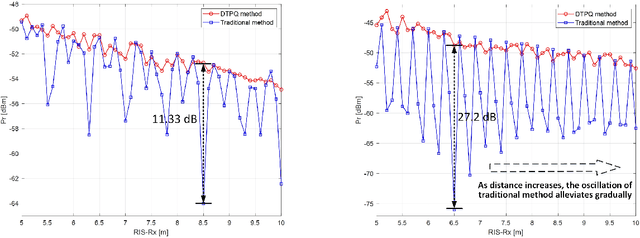
Reconfigurable intelligent surface (RIS) has aroused a surge of interest in recent years. In this paper, we investigate the joint phase alignment and phase quantization on discrete phase shift designs for RIS-assisted single-input single-output (SISO) system. Firstly, the phenomena of phase distribution in far field and near field are respectively unveiled, paving the way for discretization of phase shift for RIS. Then, aiming at aligning phases, the phase distribution law and its underlying degree-of-freedom (DoF) are characterized, serving as the guideline of phase quantization strategies. Subsequently, two phase quantization methods, dynamic threshold phase quantization (DTPQ) and equal interval phase quantization (EIPQ), are proposed to strengthen the beamforming effect of RIS. DTPQ is capable of calculating the optimal discrete phase shifts with linear complexity in the number of unit cells on RIS, whilst EIPQ is a simplified method with a constant complexity yielding sub-optimal solution. Simulation results demonstrate that both methods achieve substantial improvements on power gain, stability, and robustness over traditional quantization methods. The path loss (PL) scaling law under discrete phase shift of RIS is unveiled for the first time, with the phase shifts designed by DTPQ due to its optimality. Additionally, the field trials conducted at 2.6 GHz and 35 GHz validate the favourable performance of the proposed methods in practical communication environment.
A Framework for History-Aware Hyperparameter Optimisation in Reinforcement Learning
Mar 09, 2023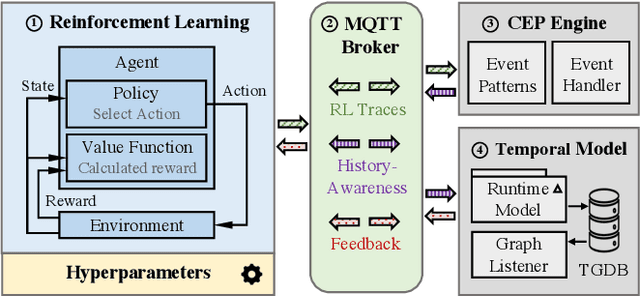
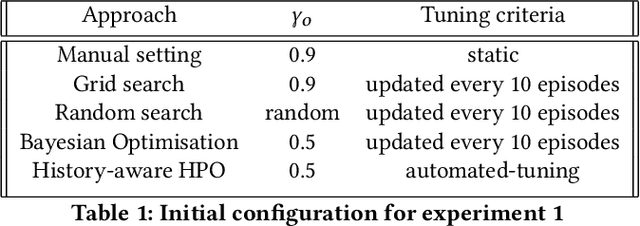
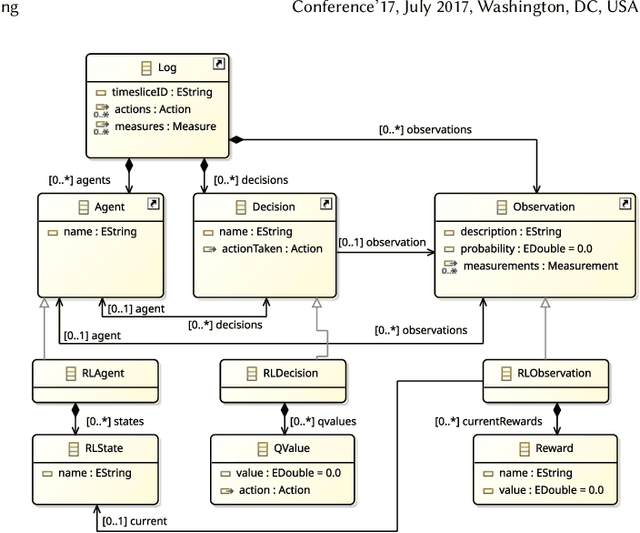
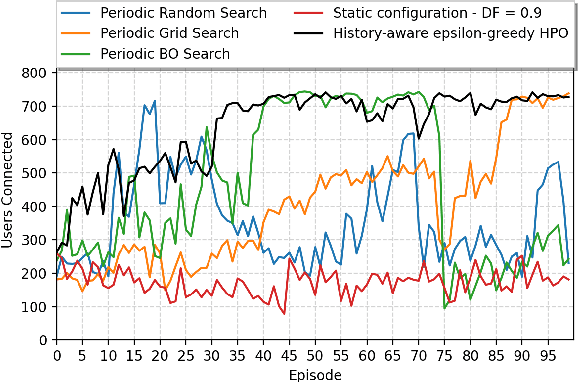
A Reinforcement Learning (RL) system depends on a set of initial conditions (hyperparameters) that affect the system's performance. However, defining a good choice of hyperparameters is a challenging problem. Hyperparameter tuning often requires manual or automated searches to find optimal values. Nonetheless, a noticeable limitation is the high cost of algorithm evaluation for complex models, making the tuning process computationally expensive and time-consuming. In this paper, we propose a framework based on integrating complex event processing and temporal models, to alleviate these trade-offs. Through this combination, it is possible to gain insights about a running RL system efficiently and unobtrusively based on data stream monitoring and to create abstract representations that allow reasoning about the historical behaviour of the RL system. The obtained knowledge is exploited to provide feedback to the RL system for optimising its hyperparameters while making effective use of parallel resources. We introduce a novel history-aware epsilon-greedy logic for hyperparameter optimisation that instead of using static hyperparameters that are kept fixed for the whole training, adjusts the hyperparameters at runtime based on the analysis of the agent's performance over time windows in a single agent's lifetime. We tested the proposed approach in a 5G mobile communications case study that uses DQN, a variant of RL, for its decision-making. Our experiments demonstrated the effects of hyperparameter tuning using history on training stability and reward values. The encouraging results show that the proposed history-aware framework significantly improved performance compared to traditional hyperparameter tuning approaches.
VLSNR:Vision-Linguistics Coordination Time Sequence-aware News Recommendation
Oct 06, 2022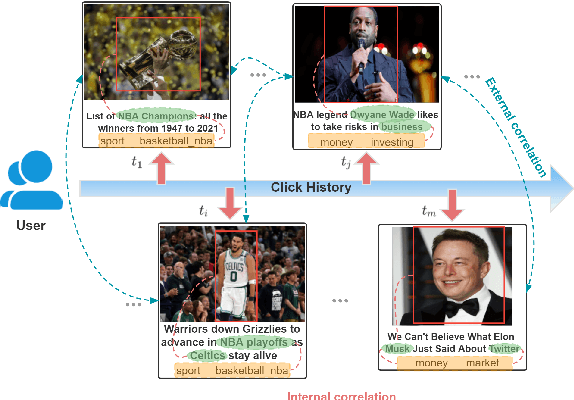

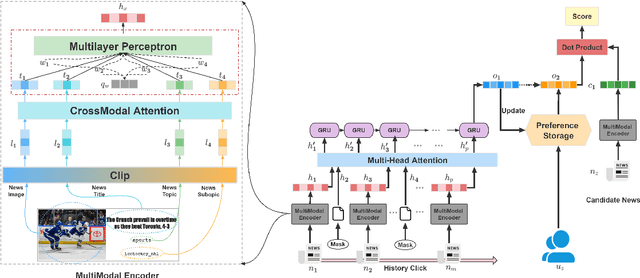
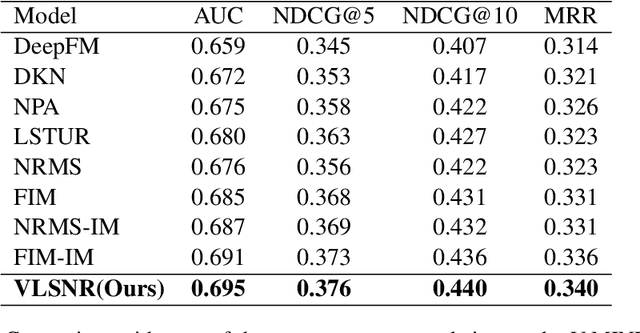
News representation and user-oriented modeling are both essential for news recommendation. Most existing methods are based on textual information but ignore the visual information and users' dynamic interests. However, compared to textual only content, multimodal semantics is beneficial for enhancing the comprehension of users' temporal and long-lasting interests. In our work, we propose a vision-linguistics coordinate time sequence news recommendation. Firstly, a pretrained multimodal encoder is applied to embed images and texts into the same feature space. Then the self-attention network is used to learn the chronological sequence. Additionally, an attentional GRU network is proposed to model user preference in terms of time adequately. Finally, the click history and user representation are embedded to calculate the ranking scores for candidate news. Furthermore, we also construct a large scale multimodal news recommendation dataset V-MIND. Experimental results show that our model outperforms baselines and achieves SOTA on our independently constructed dataset.
Adversarial Machine Learning: A Systematic Survey of Backdoor Attack, Weight Attack and Adversarial Example
Feb 19, 2023
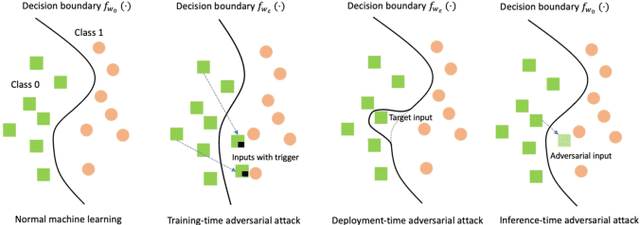
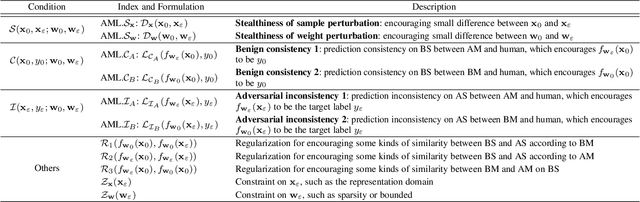
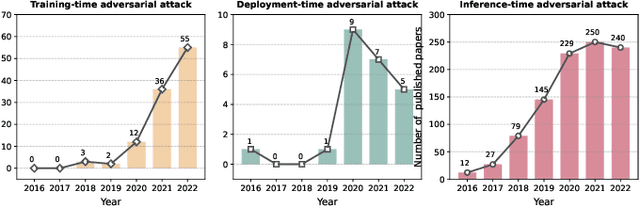
Adversarial machine learning (AML) studies the adversarial phenomenon of machine learning, which may make inconsistent or unexpected predictions with humans. Some paradigms have been recently developed to explore this adversarial phenomenon occurring at different stages of a machine learning system, such as training-time adversarial attack (i.e., backdoor attack), deployment-time adversarial attack (i.e., weight attack), and inference-time adversarial attack (i.e., adversarial example). However, although these paradigms share a common goal, their developments are almost independent, and there is still no big picture of AML. In this work, we aim to provide a unified perspective to the AML community to systematically review the overall progress of this field. We firstly provide a general definition about AML, and then propose a unified mathematical framework to covering existing attack paradigms. According to the proposed unified framework, we can not only clearly figure out the connections and differences among these paradigms, but also systematically categorize and review existing works in each paradigm.
Hardware-Aware Graph Neural Network Automated Design for Edge Computing Platforms
Mar 20, 2023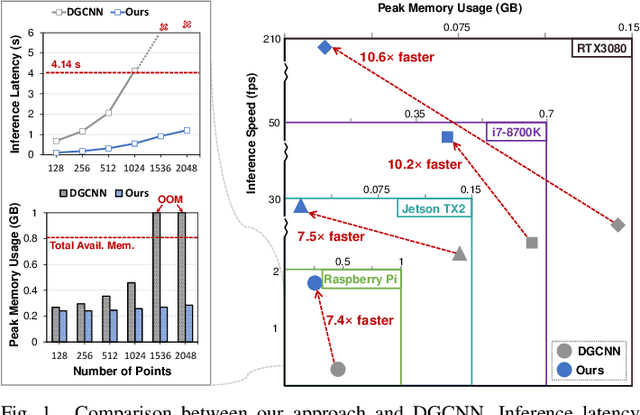
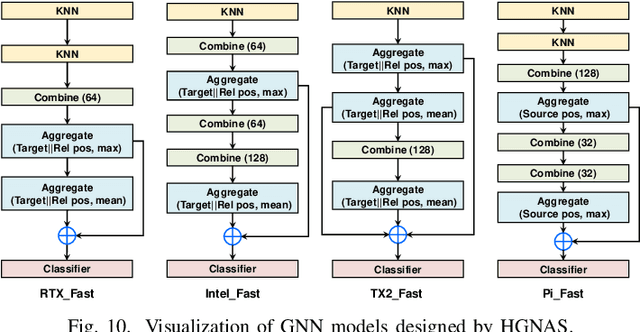
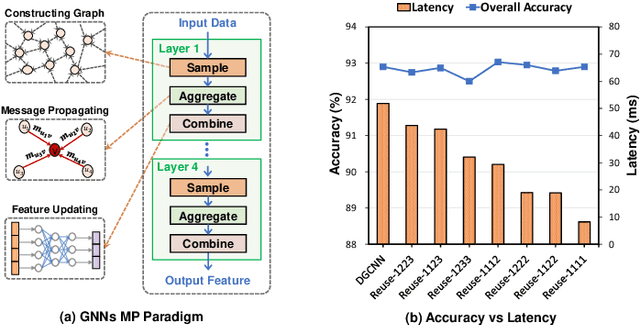
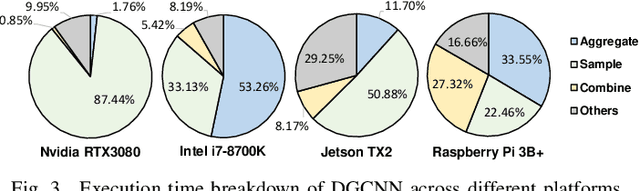
Graph neural networks (GNNs) have emerged as a popular strategy for handling non-Euclidean data due to their state-of-the-art performance. However, most of the current GNN model designs mainly focus on task accuracy, lacking in considering hardware resources limitation and real-time requirements of edge application scenarios. Comprehensive profiling of typical GNN models indicates that their execution characteristics are significantly affected across different computing platforms, which demands hardware awareness for efficient GNN designs. In this work, HGNAS is proposed as the first Hardware-aware Graph Neural Architecture Search framework targeting resource constraint edge devices. By decoupling the GNN paradigm, HGNAS constructs a fine-grained design space and leverages an efficient multi-stage search strategy to explore optimal architectures within a few GPU hours. Moreover, HGNAS achieves hardware awareness during the GNN architecture design by leveraging a hardware performance predictor, which could balance the GNN model accuracy and efficiency corresponding to the characteristics of targeted devices. Experimental results show that HGNAS can achieve about $10.6\times$ speedup and $88.2\%$ peak memory reduction with a negligible accuracy loss compared to DGCNN on various edge devices, including Nvidia RTX3080, Jetson TX2, Intel i7-8700K and Raspberry Pi 3B+.
Large Selective Kernel Network for Remote Sensing Object Detection
Mar 20, 2023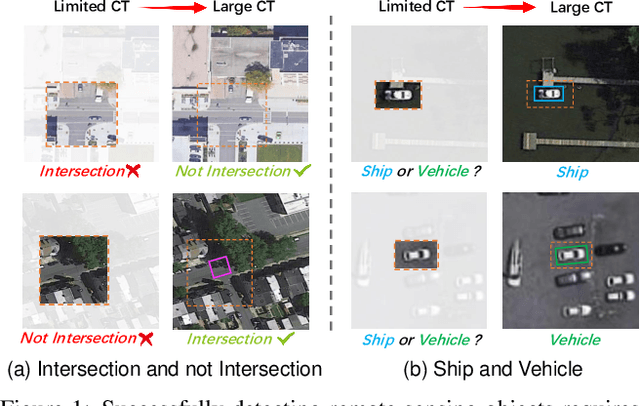
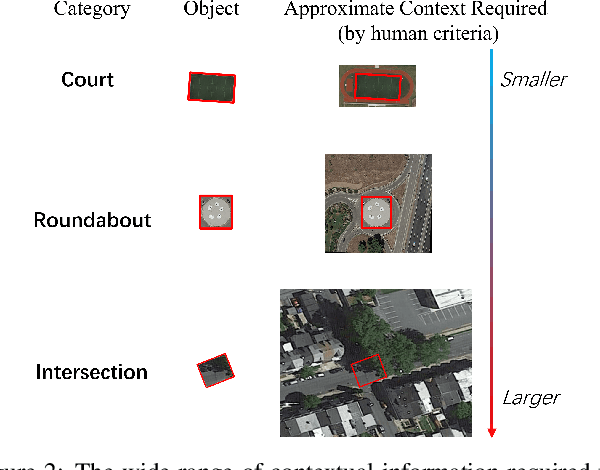


Recent research on remote sensing object detection has largely focused on improving the representation of oriented bounding boxes but has overlooked the unique prior knowledge presented in remote sensing scenarios. Such prior knowledge can be useful because tiny remote sensing objects may be mistakenly detected without referencing a sufficiently long-range context, and the long-range context required by different types of objects can vary. In this paper, we take these priors into account and propose the Large Selective Kernel Network (LSKNet). LSKNet can dynamically adjust its large spatial receptive field to better model the ranging context of various objects in remote sensing scenarios. To the best of our knowledge, this is the first time that large and selective kernel mechanisms have been explored in the field of remote sensing object detection. Without bells and whistles, LSKNet sets new state-of-the-art scores on standard benchmarks, i.e., HRSC2016 (98.46\% mAP), DOTA-v1.0 (81.85\% mAP) and FAIR1M-v1.0 (47.87\% mAP). Based on a similar technique, we rank 2nd place in 2022 the Greater Bay Area International Algorithm Competition. Code is available at https://github.com/zcablii/Large-Selective-Kernel-Network.