 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Model Stitching and Visualization How GAN Generators can Invert Networks in Real-Time
Feb 04, 2023
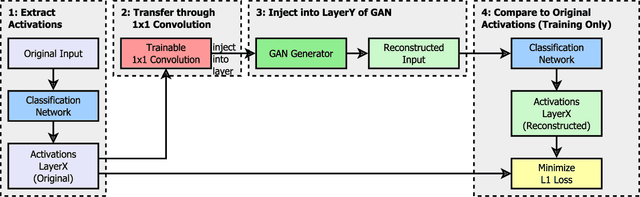
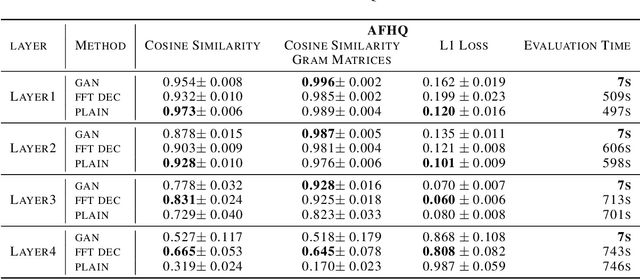
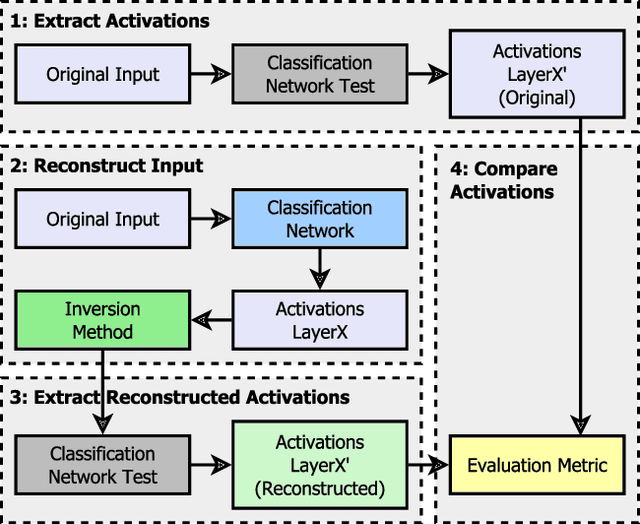

Critical applications, such as in the medical field, require the rapid provision of additional information to interpret decisions made by deep learning methods. In this work, we propose a fast and accurate method to visualize activations of classification and semantic segmentation networks by stitching them with a GAN generator utilizing convolutions. We test our approach on images of animals from the AFHQ wild dataset and real-world digital pathology scans of stained tissue samples. Our method provides comparable results to established gradient descent methods on these datasets while running about two orders of magnitude faster.
HDformer: A Higher Dimensional Transformer for Diabetes Detection Utilizing Long Range Vascular Signals
Mar 17, 2023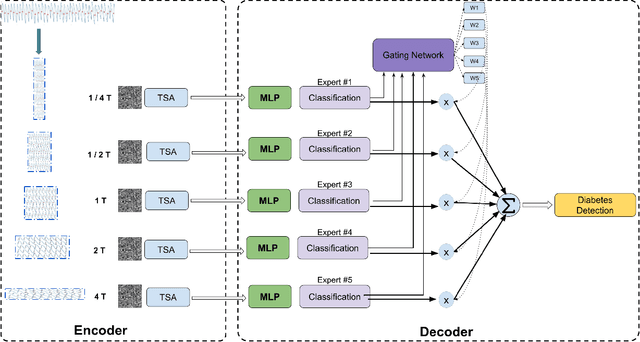
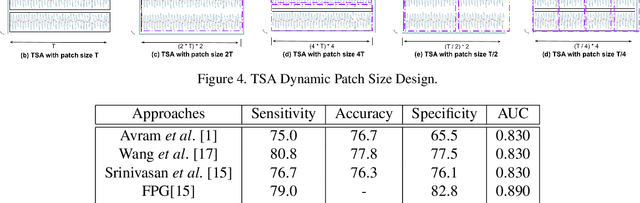
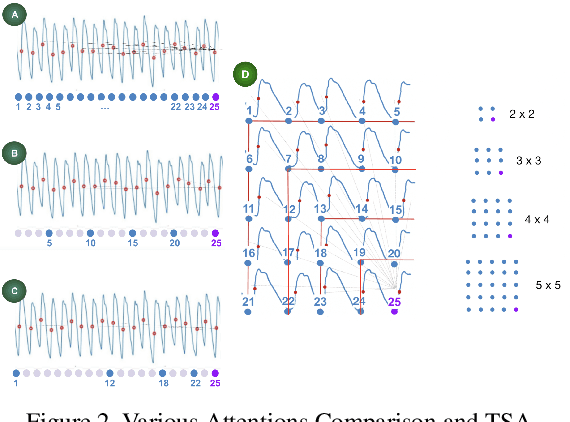
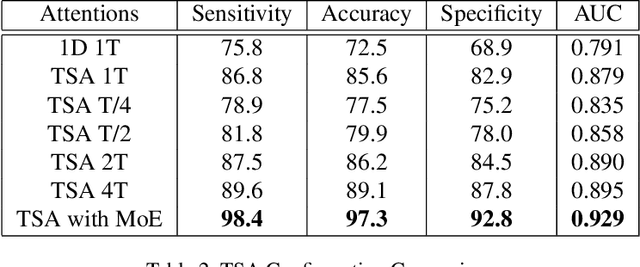
Diabetes mellitus is a worldwide concern, and early detection can help to prevent serious complications. Low-cost, non-invasive detection methods, which take cardiovascular signals into deep learning models, have emerged. However, limited accuracy constrains their clinical usage. In this paper, we present a new Transformer-based architecture, Higher Dimensional Transformer (HDformer), which takes long-range photoplethysmography (PPG) signals to detect diabetes. The long-range PPG contains broader and deeper signal contextual information compared to the less-than-one-minute PPG signals commonly utilized in existing research. To increase the capability and efficiency of processing the long range data, we propose a new attention module Time Square Attention (TSA), reducing the volume of the tokens by more than 10x, while retaining the local/global dependencies. It converts the 1-dimensional inputs into 2-dimensional representations and groups adjacent points into a single 2D token, using the 2D Transformer models as the backbone of the encoder. It generates the dynamic patch sizes into a gated mixture-of-experts (MoE) network as decoder, which optimizes the learning on different attention areas. Extensive experimentations show that HDformer results in the state-of-the-art performance (sensitivity 98.4, accuracy 97.3, specificity 92.8, and AUC 0.929) on the standard MIMIC-III dataset, surpassing existing studies. This work is the first time to take long-range, non-invasive PPG signals via Transformer for diabetes detection, achieving a more scalable and convenient solution compared to traditional invasive approaches. The proposed HDformer can also be scaled to analyze general long-range biomedical waveforms. A wearable prototype finger-ring is designed as a proof of concept.
Inference on Causal Effects of Interventions in Time using Gaussian Processes
Oct 06, 2022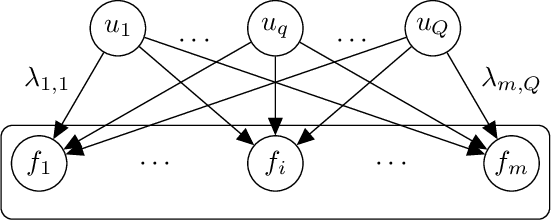
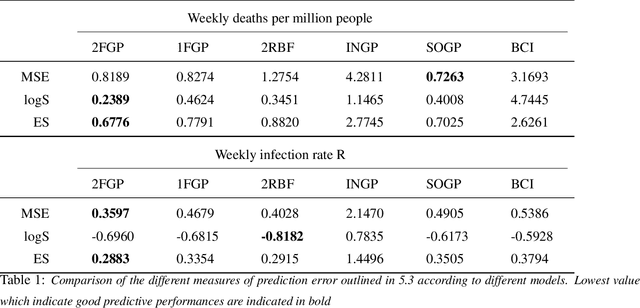
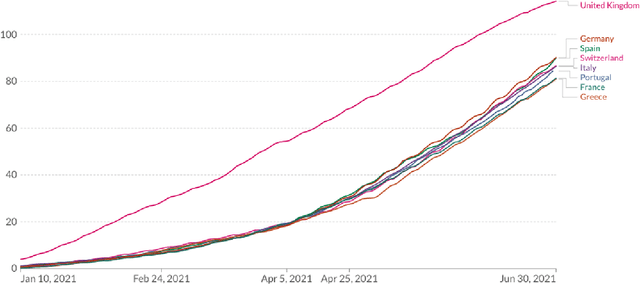
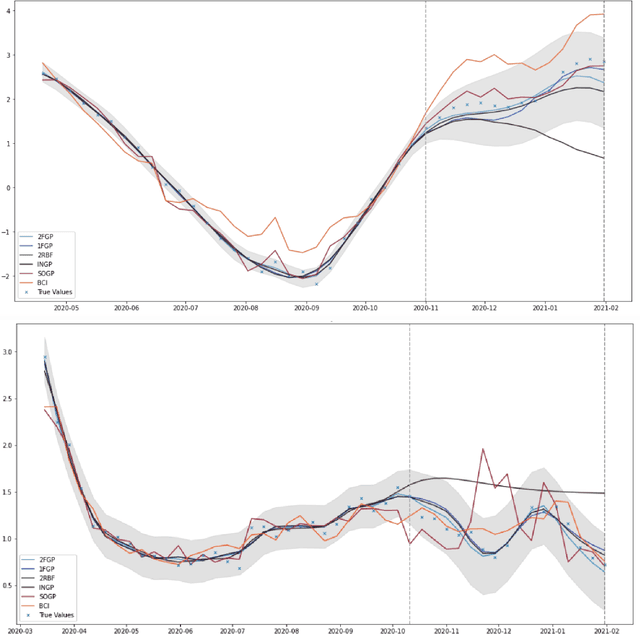
This paper focuses on drawing inference on the causal impact of an intervention at a specific time point, as manifested in an outcome variable over time. We operate on the interrupted time series framework and expand on approaches such as the synthetic control (Abadie 2003) and Bayesian structural time series (Brodersen et al 2015), by replacing the underlying dynamic linear regression model with a non-parametric formulation based on Gaussian Processes. The developed models possess a high degree of flexibility posing very little limitations on the functional form and allow to incorporate uncertainty, stemming from its estimation, under the Bayesian framework. We introduce two families of non-parametric structural time series models either operating on the trajectory of the outcome variable alone, or in a multivariate setting using multiple output Gaussian processes. The paper engages closely with a case study focusing on the impact of the accelerated UK vaccination schedule, as contrasted with the rest of Europe, to illustrate the methodology and present the implementation procedure.
HiSSNet: Sound Event Detection and Speaker Identification via Hierarchical Prototypical Networks for Low-Resource Headphones
Mar 13, 2023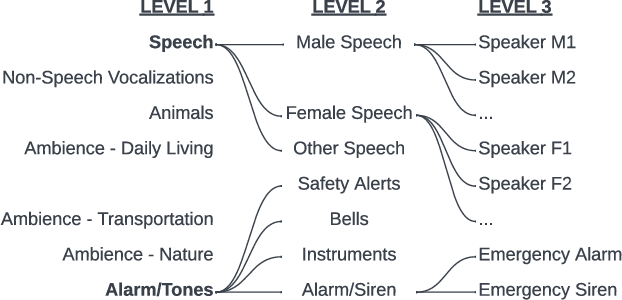
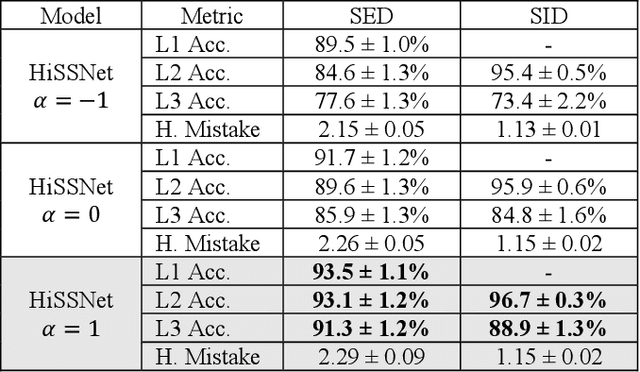
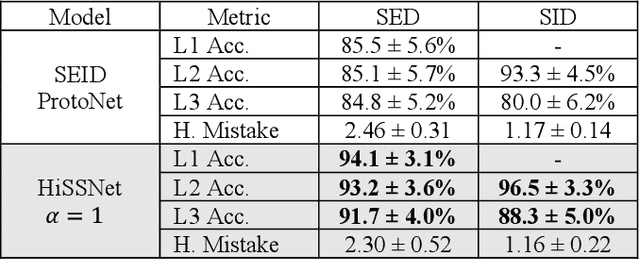
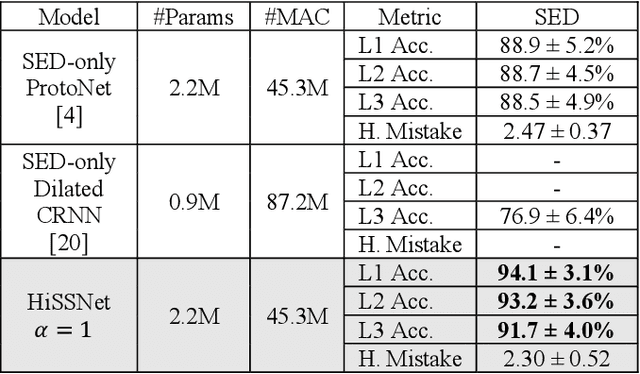
Modern noise-cancelling headphones have significantly improved users' auditory experiences by removing unwanted background noise, but they can also block out sounds that matter to users. Machine learning (ML) models for sound event detection (SED) and speaker identification (SID) can enable headphones to selectively pass through important sounds; however, implementing these models for a user-centric experience presents several unique challenges. First, most people spend limited time customizing their headphones, so the sound detection should work reasonably well out of the box. Second, the models should be able to learn over time the specific sounds that are important to users based on their implicit and explicit interactions. Finally, such models should have a small memory footprint to run on low-power headphones with limited on-chip memory. In this paper, we propose addressing these challenges using HiSSNet (Hierarchical SED and SID Network). HiSSNet is an SEID (SED and SID) model that uses a hierarchical prototypical network to detect both general and specific sounds of interest and characterize both alarm-like and speech sounds. We show that HiSSNet outperforms an SEID model trained using non-hierarchical prototypical networks by 6.9 - 8.6 percent. When compared to state-of-the-art (SOTA) models trained specifically for SED or SID alone, HiSSNet achieves similar or better performance while reducing the memory footprint required to support multiple capabilities on-device.
Unsupervised crack detection on complex stone masonry surfaces
Mar 31, 2023
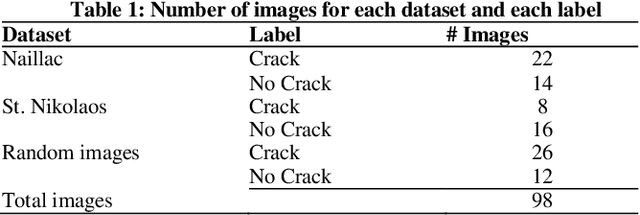
Computer vision for detecting building pathologies has interested researchers for quite some time. Vision-based crack detection is a non-destructive assessment technique, which can be useful especially for Cultural Heritage (CH) where strict regulations apply and, even simple, interventions are not permitted. Recently, shallow and deep machine learning architectures applied on various types of imagery are gaining ground. In this article a crack detection methodology for stone masonry walls is presented. In the proposed approach, crack detection is approached as an unsupervised anomaly detection problem on RGB (Red Green Blue) image patches. Towards this direction, some of the most popular state of the art CNN (Convolutional Neural Network) architectures are deployed and modified to binary classify the images or image patches by predicting a specific class for the tested imagery; 'Crack' or 'No crack', and detect and localize those cracks on the RGB imagery with high accuracy. Testing of the model was performed on various test sites and random images retrieved from the internet and collected by the authors and results suggested the high performance of specific networks compared to the rest, considering also the small numbers of epochs required for training. Those results met the accuracy delivered by more complex and computationally heavy approaches, requiring a large amount of data for training. Source code is available on GitHub https://github.com/pagraf/Crack-detection while datasets are available on Zenodo https://doi.org/10.5281/zenodo.6516913 .
$\textit{e-Uber}$: A Crowdsourcing Platform for Electric Vehicle-based Ride- and Energy-sharing
Mar 31, 2023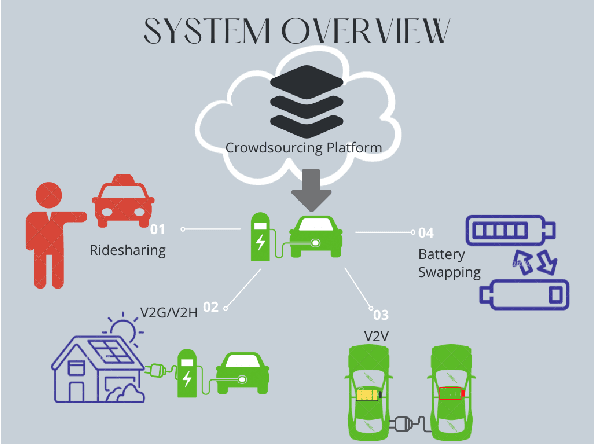
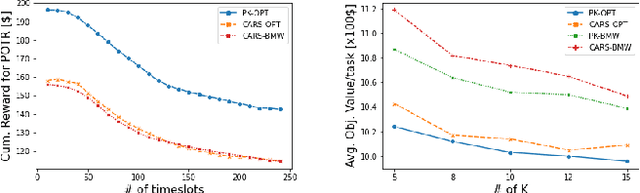
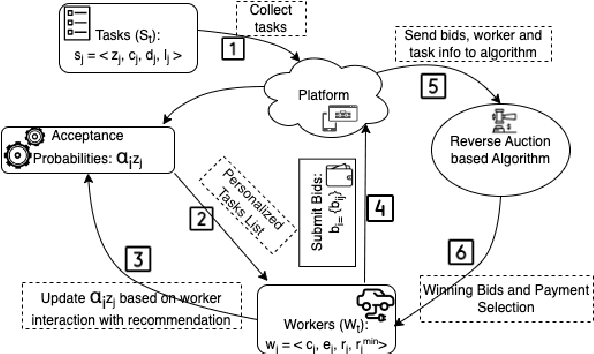
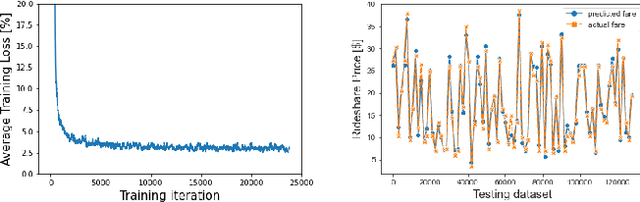
The sharing-economy-based business model has recently seen success in the transportation and accommodation sectors with companies like Uber and Airbnb. There is growing interest in applying this model to energy systems, with modalities like peer-to-peer (P2P) Energy Trading, Electric Vehicles (EV)-based Vehicle-to-Grid (V2G), Vehicle-to-Home (V2H), Vehicle-to-Vehicle (V2V), and Battery Swapping Technology (BST). In this work, we exploit the increasing diffusion of EVs to realize a crowdsourcing platform called e-Uber that jointly enables ride-sharing and energy-sharing through V2G and BST. e-Uber exploits spatial crowdsourcing, reinforcement learning, and reverse auction theory. Specifically, the platform uses reinforcement learning to understand the drivers' preferences towards different ride-sharing and energy-sharing tasks. Based on these preferences, a personalized list is recommended to each driver through CMAB-based Algorithm for task Recommendation System (CARS). Drivers bid on their preferred tasks in their list in a reverse auction fashion. Then e-Uber solves the task assignment optimization problem that minimizes cost and guarantees V2G energy requirement. We prove that this problem is NP-hard and introduce a bipartite matching-inspired heuristic, Bipartite Matching-based Winner selection (BMW), that has polynomial time complexity. Results from experiments using real data from NYC taxi trips and energy consumption show that e-Uber performs close to the optimum and finds better solutions compared to a state-of-the-art approach
Learning a Meta-Controller for Dynamic Grasping
Feb 16, 2023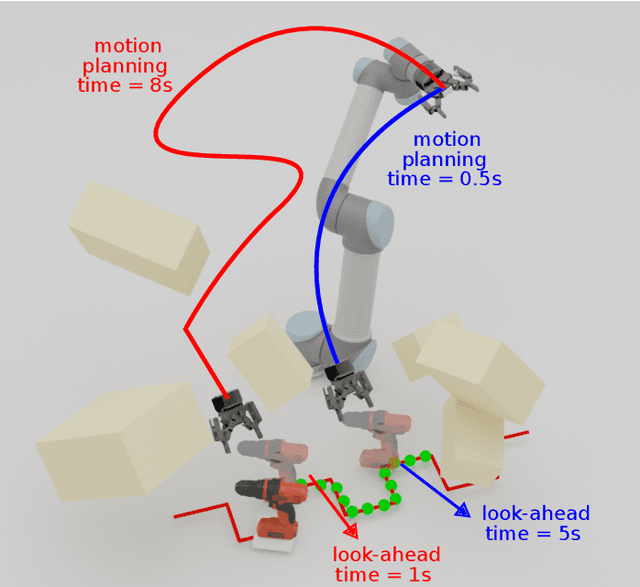
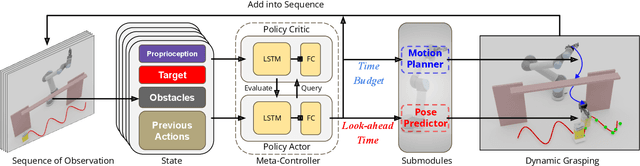
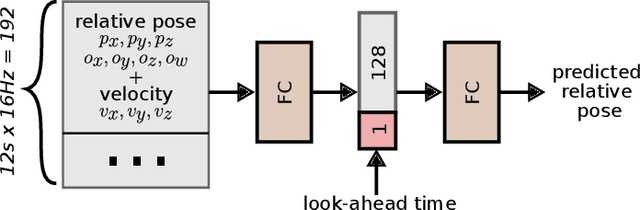
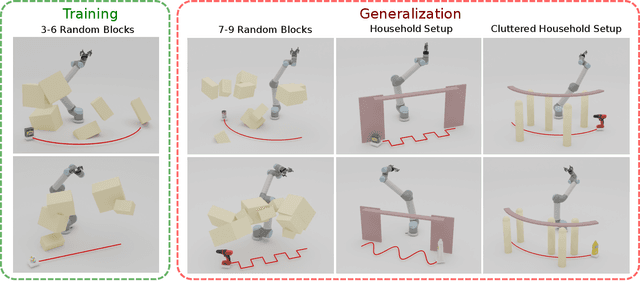
Grasping moving objects is a challenging task that combines multiple submodules such as object pose predictor, arm motion planner, etc. Each submodule operates under its own set of meta-parameters. For example, how far the pose predictor should look into the future (i.e., look-ahead time) and the maximum amount of time the motion planner can spend planning a motion (i.e., time budget). Many previous works assign fixed values to these parameters either heuristically or through grid search; however, at different moments within a single episode of dynamic grasping, the optimal values should vary depending on the current scene. In this work, we learn a meta-controller through reinforcement learning to control the look-ahead time and time budget dynamically. Our extensive experiments show that the meta-controller improves the grasping success rate (up to 12% in the most cluttered environment) and reduces grasping time, compared to the strongest baseline. Our meta-controller learns to reason about the reachable workspace and maintain the predicted pose within the reachable region. In addition, it assigns a small but sufficient time budget for the motion planner. Our method can handle different target objects, trajectories, and obstacles. Despite being trained only with 3-6 randomly generated cuboidal obstacles, our meta-controller generalizes well to 7-9 obstacles and more realistic out-of-domain household setups with unseen obstacle shapes. Video is available at https://youtu.be/CwHq77wFQqI.
Dual Arm Impact-Aware Grasping through Time-Invariant Reference Spreading Control
Dec 01, 2022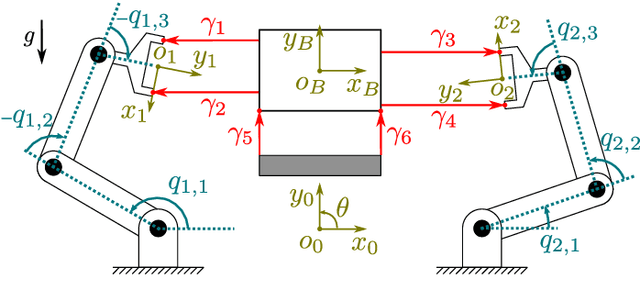
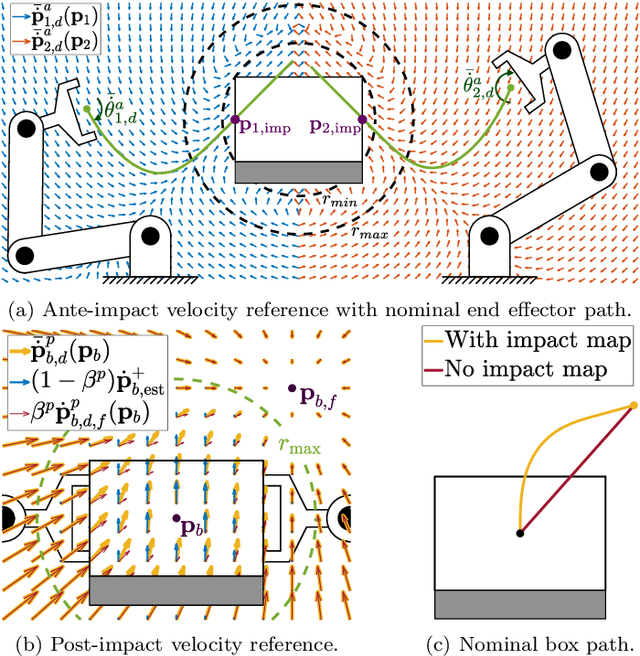
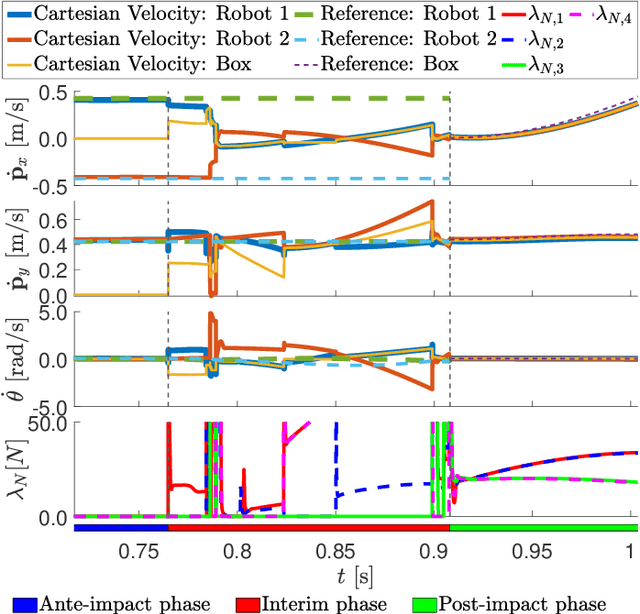
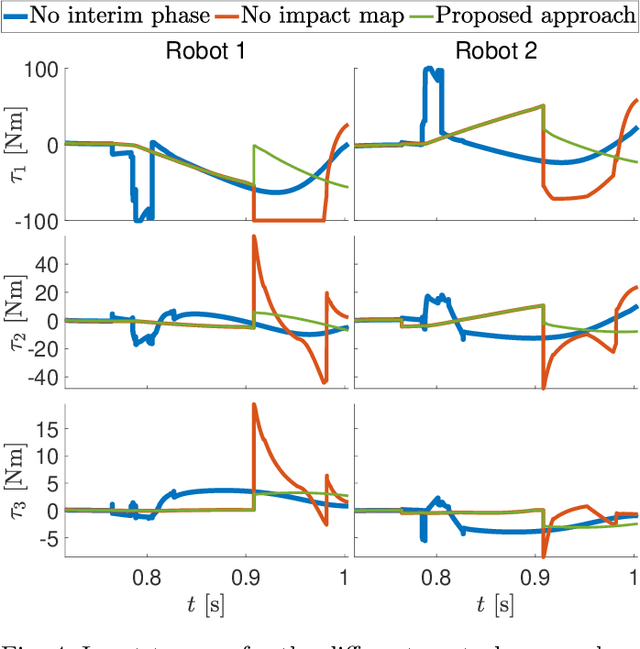
With the goal of increasing the speed and efficiency in robotic dual-arm manipulation, a novel control approach is presented that utilizes intentional simultaneous impacts to rapidly grasp objects. This approach uses the time-invariant reference spreading framework, in which partly-overlapping ante- and post-impact reference vector fields are used. These vector fields are coupled via the impact dynamics in proximity of the expected impact area, minimizing the otherwise large velocity errors after the impact and the corresponding large control efforts. A purely spatial task is introduced to strongly encourage the synchronization of impact times of the two arms. An interim-impact control phase provides robustness in the execution against the inevitable lack of exact impact simultaneity and the corresponding unreliable velocity error. In this interim phase, a position feedback signal is derived from the ante-impact velocity reference, which is used to enforce sustained contact in all contact points without using velocity error feedback. With an eye towards real-life implementation, the approach is formulated using a QP control framework, and is validated using numerical simulations on a realistic robot model with flexible joints and low-level torque control.
Interactive Language: Talking to Robots in Real Time
Oct 12, 2022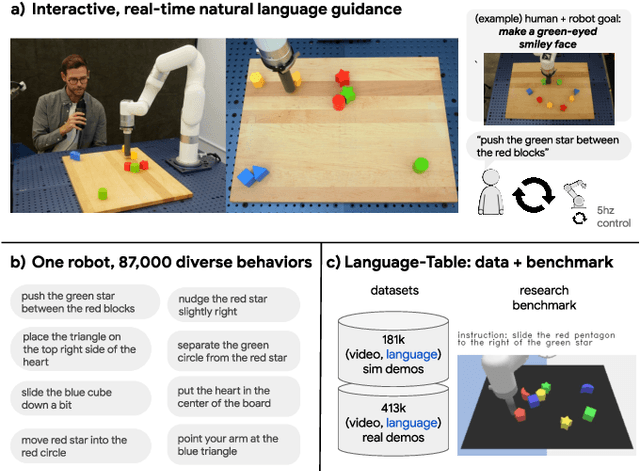
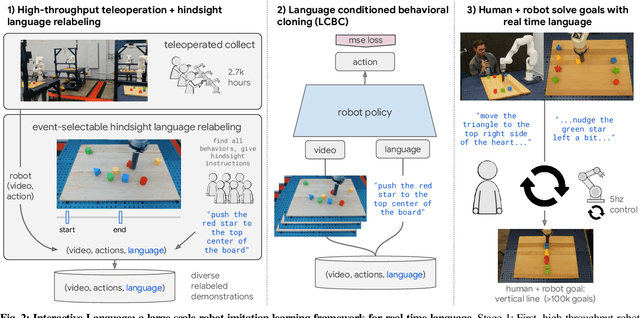
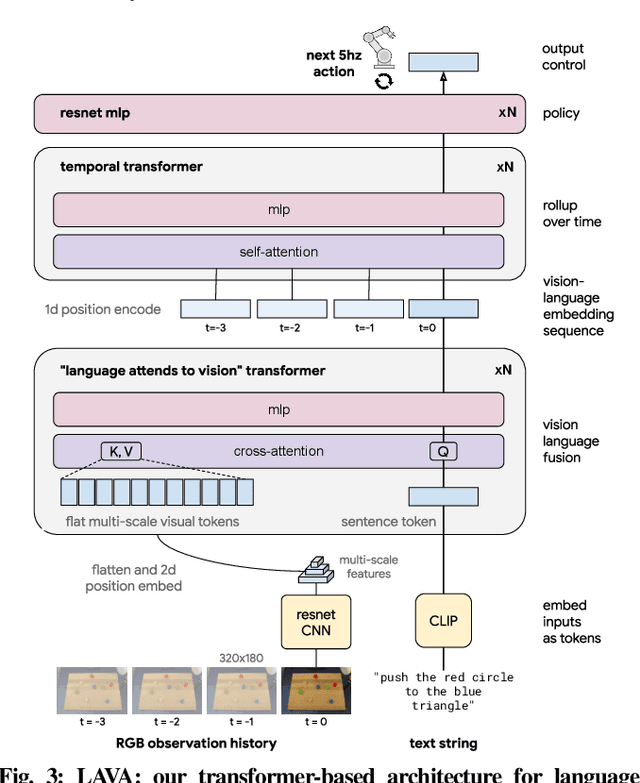

We present a framework for building interactive, real-time, natural language-instructable robots in the real world, and we open source related assets (dataset, environment, benchmark, and policies). Trained with behavioral cloning on a dataset of hundreds of thousands of language-annotated trajectories, a produced policy can proficiently execute an order of magnitude more commands than previous works: specifically we estimate a 93.5% success rate on a set of 87,000 unique natural language strings specifying raw end-to-end visuo-linguo-motor skills in the real world. We find that the same policy is capable of being guided by a human via real-time language to address a wide range of precise long-horizon rearrangement goals, e.g. "make a smiley face out of blocks". The dataset we release comprises nearly 600,000 language-labeled trajectories, an order of magnitude larger than prior available datasets. We hope the demonstrated results and associated assets enable further advancement of helpful, capable, natural-language-interactable robots. See videos at https://interactive-language.github.io.
Denoising Diffusion Samplers
Feb 27, 2023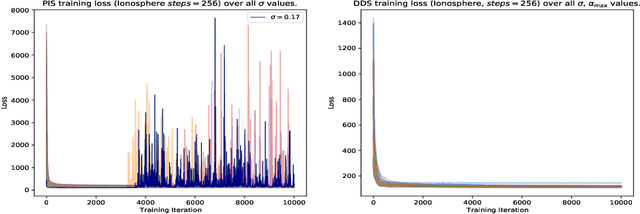

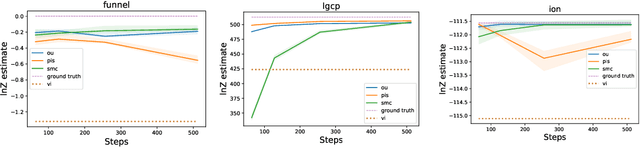

Denoising diffusion models are a popular class of generative models providing state-of-the-art results in many domains. One adds gradually noise to data using a diffusion to transform the data distribution into a Gaussian distribution. Samples from the generative model are then obtained by simulating an approximation of the time-reversal of this diffusion initialized by Gaussian samples. Practically, the intractable score terms appearing in the time-reversed process are approximated using score matching techniques. We explore here a similar idea to sample approximately from unnormalized probability density functions and estimate their normalizing constants. We consider a process where the target density diffuses towards a Gaussian. Denoising Diffusion Samplers (DDS) are obtained by approximating the corresponding time-reversal. While score matching is not applicable in this context, we can leverage many of the ideas introduced in generative modeling for Monte Carlo sampling. Existing theoretical results from denoising diffusion models also provide theoretical guarantees for DDS. We discuss the connections between DDS, optimal control and Schr\"odinger bridges and finally demonstrate DDS experimentally on a variety of challenging sampling tasks.
* In The Eleventh International Conference on Learning Representations, 2023