 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Synthetic ECG Signal Generation using Probabilistic Diffusion Models
Mar 16, 2023


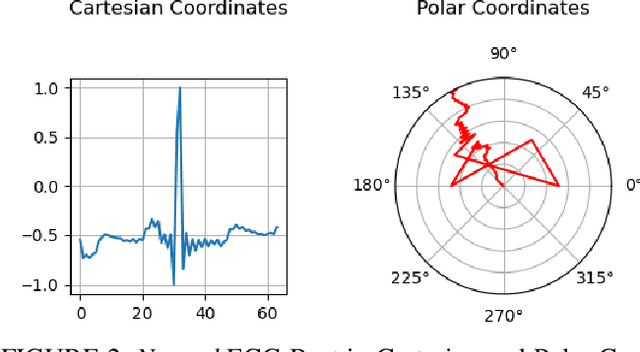
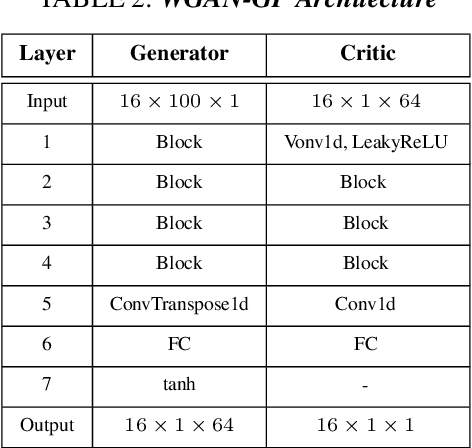
Deep learning image processing models have had remarkable success in recent years in generating high quality images. Particularly, the Improved Denoising Diffusion Probabilistic Models (DDPM) have shown superiority in image quality to the state-of-the-art generative models, which motivated us to investigate its capability in generation of the synthetic electrocardiogram (ECG) signals. In this work, synthetic ECG signals are generated by the Improved DDPM and by the Wasserstein GAN with Gradient Penalty (WGAN-GP) models and then compared. To this end, we devise a pipeline to utilize DDPM in its original $2D$ form. First, the $1D$ ECG time series data are embedded into the $2D$ space, for which we employed the Gramian Angular Summation/Difference Fields (GASF/GADF) as well as Markov Transition Fields (MTF) to generate three $2D$ matrices from each ECG time series that, which when put together, form a $3$-channel $2D$ datum. Then $2D$ DDPM is used to generate $2D$ $3$-channel synthetic ECG images. The $1$D ECG signals are created by de-embedding the $2D$ generated image files back into the $1D$ space. This work focuses on unconditional models and the generation of only \emph{Normal} ECG signals, where the Normal class from the MIT BIH Arrhythmia dataset is used as the training phase. The \emph{quality}, \emph{distribution}, and the \emph{authenticity} of the generated ECG signals by each model are compared. Our results show that, in the proposed pipeline, the WGAN-GP model is superior to DDPM by far in all the considered metrics consistently.
Learning-Based Modeling of Human-Autonomous Vehicle Interaction for Enhancing Safety in Mixed-Vehicle Platooning Control
Mar 16, 2023
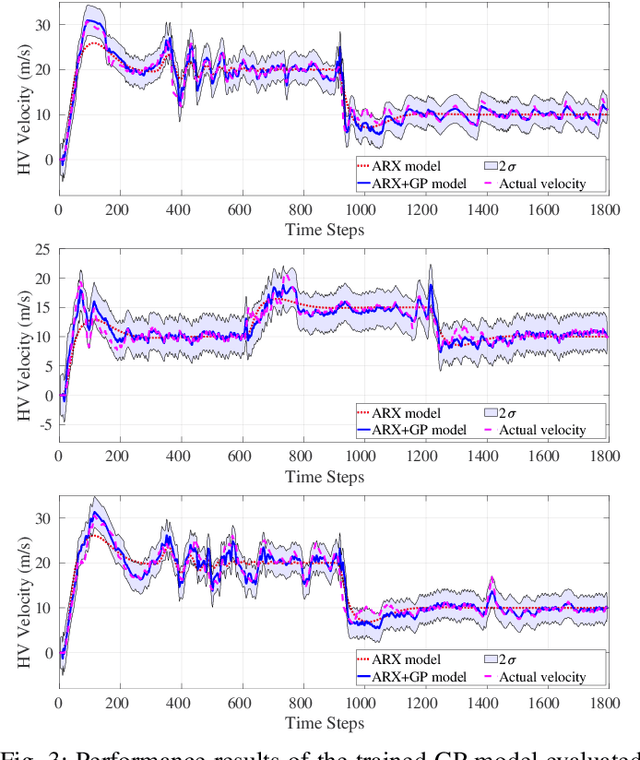
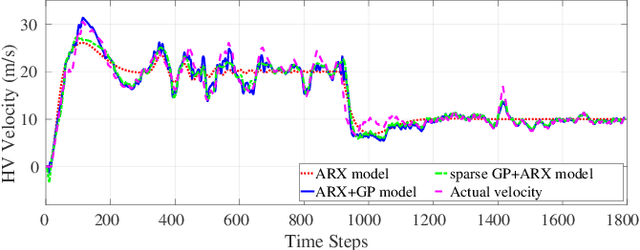
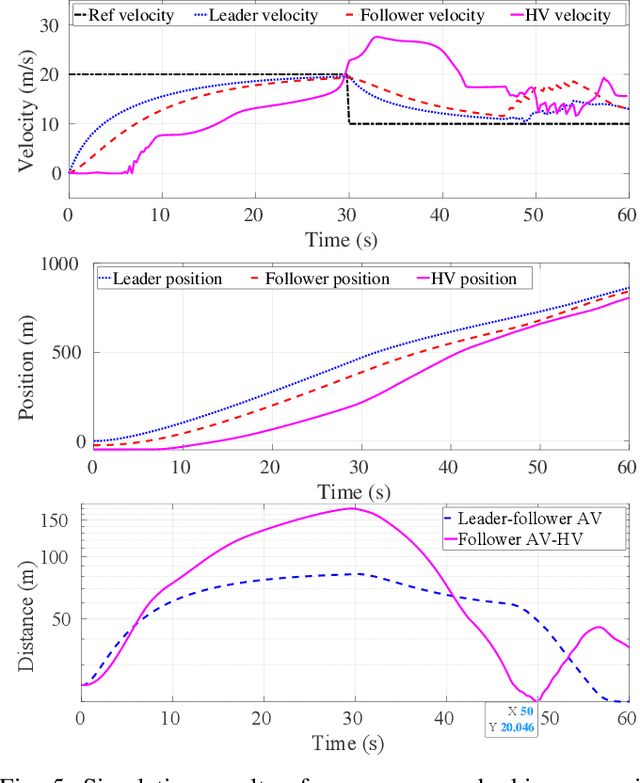
As autonomous vehicles (AVs) become more prevalent on public roads, they will inevitably interact with human-driven vehicles (HVs) in mixed traffic scenarios. To ensure safe interactions between AVs and HVs, it is crucial to account for the uncertain behaviors of HVs when developing control strategies for AVs. In this paper, we propose an efficient learning-based modeling approach for HVs that combines a first-principles model with a Gaussian process (GP) learning-based component. The GP model corrects the velocity prediction of the first-principles model and estimates its uncertainty. Utilizing this model, a model predictive control (MPC) strategy, referred to as GP-MPC, was designed to enhance the safe control of a mixed vehicle platoon by integrating the uncertainty assessment into the distance constraint. We compare our GP-MPC strategy with a baseline MPC that uses only the first-principles model in simulation studies. We show that our GP-MPC strategy provides more robust safe distance guarantees and enables more efficient travel behaviors (higher travel speeds) for all vehicles in the mixed platoon. Moreover, by incorporating a sparse GP technique in HV modeling and a dynamic GP prediction in MPC, we achieve an average computation time for GP-MPC at each time step that is only 5% longer than the baseline MPC, which is approximately 100 times faster than our previous work that did not use these approximations. This work demonstrates how learning-based modeling of HVs can enhance safety and efficiency in mixed traffic involving AV-HV interaction.
Improving the Diproche CNL through autoformalization via GPT-3
Mar 12, 2023The Diproche system is an automated proof checker for texts written in a controlled fragment of German, designed for didactical applications in classes introducing students to proofs for the first time. The first version of the system used a controlled natural language for which a Prolog formalization routine was written. In this paper, we explore the possibility of prompting large language models for autoformalization in the context of Diproche, with encouraging first results.
WavCaps: A ChatGPT-Assisted Weakly-Labelled Audio Captioning Dataset for Audio-Language Multimodal Research
Mar 30, 2023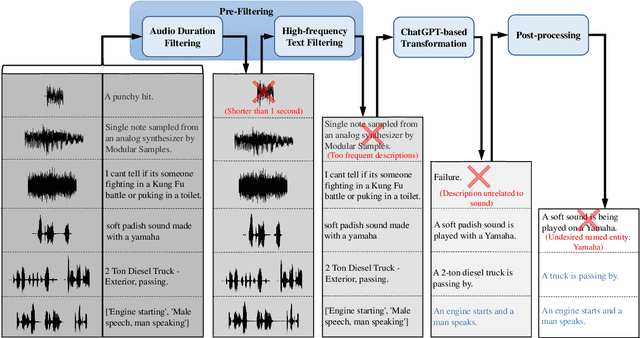
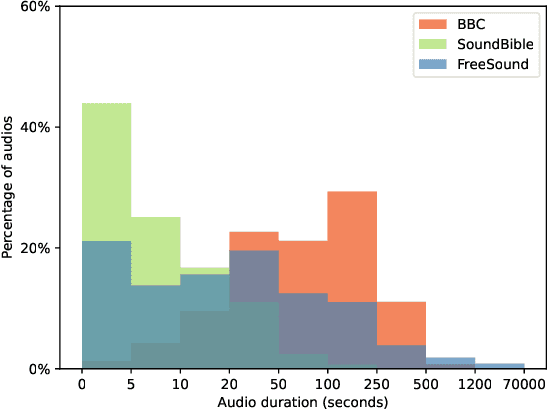

The advancement of audio-language (AL) multimodal learning tasks has been significant in recent years. However, researchers face challenges due to the costly and time-consuming collection process of existing audio-language datasets, which are limited in size. To address this data scarcity issue, we introduce WavCaps, the first large-scale weakly-labelled audio captioning dataset, comprising approximately 400k audio clips with paired captions. We sourced audio clips and their raw descriptions from web sources and a sound event detection dataset. However, the online-harvested raw descriptions are highly noisy and unsuitable for direct use in tasks such as automated audio captioning. To overcome this issue, we propose a three-stage processing pipeline for filtering noisy data and generating high-quality captions, where ChatGPT, a large language model, is leveraged to filter and transform raw descriptions automatically. We conduct a comprehensive analysis of the characteristics of WavCaps dataset and evaluate it on multiple downstream audio-language multimodal learning tasks. The systems trained on WavCaps outperform previous state-of-the-art (SOTA) models by a significant margin. Our aspiration is for the WavCaps dataset we have proposed to facilitate research in audio-language multimodal learning and demonstrate the potential of utilizing ChatGPT to enhance academic research. Our dataset and codes are available at https://github.com/XinhaoMei/WavCaps.
Practical self-supervised continual learning with continual fine-tuning
Mar 30, 2023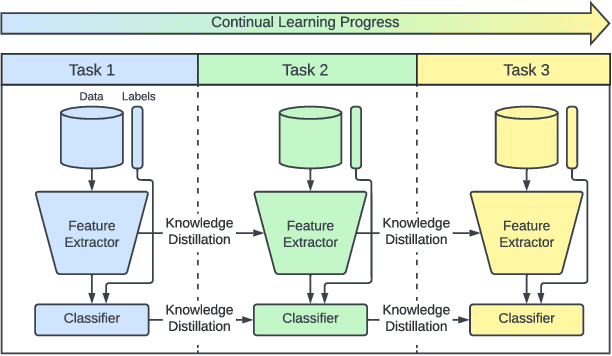
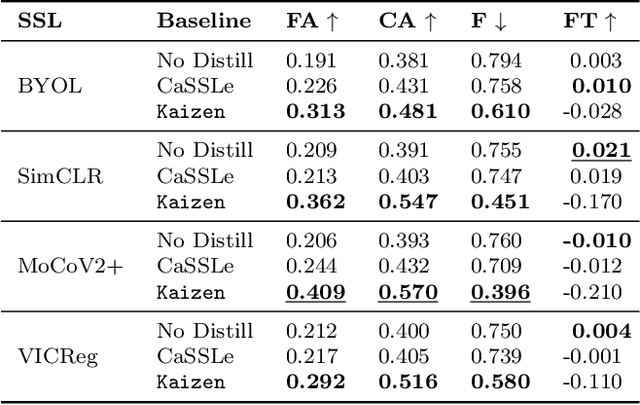
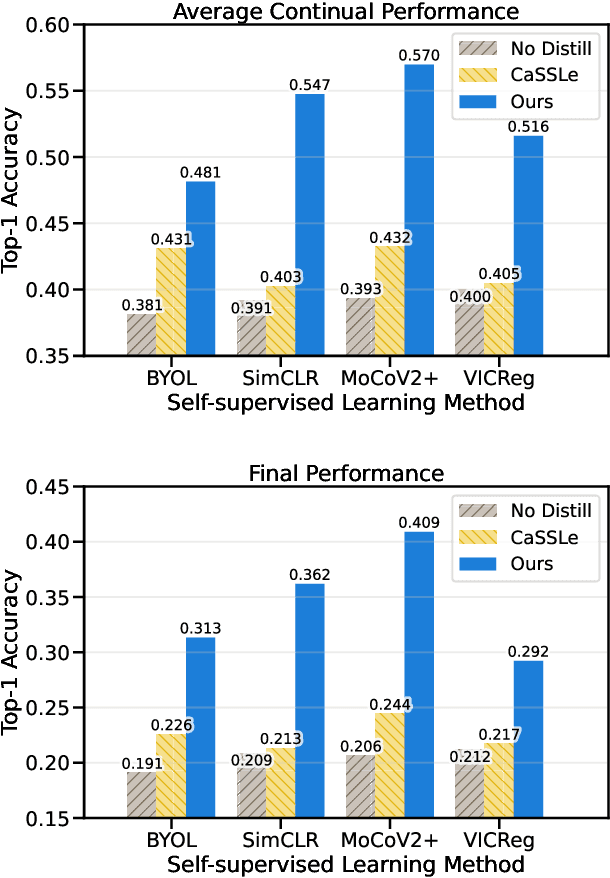
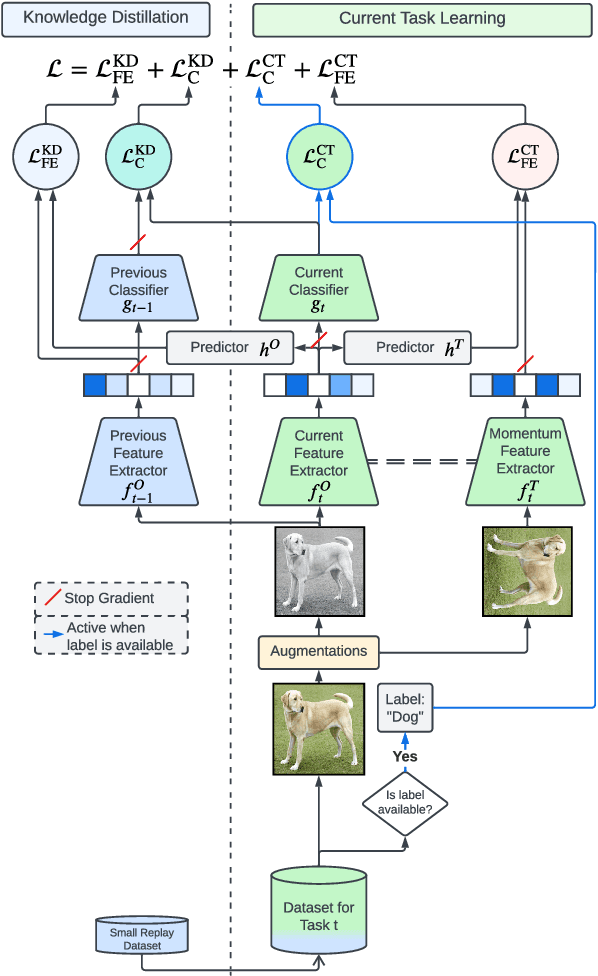
Self-supervised learning (SSL) has shown remarkable performance in computer vision tasks when trained offline. However, in a Continual Learning (CL) scenario where new data is introduced progressively, models still suffer from catastrophic forgetting. Retraining a model from scratch to adapt to newly generated data is time-consuming and inefficient. Previous approaches suggested re-purposing self-supervised objectives with knowledge distillation to mitigate forgetting across tasks, assuming that labels from all tasks are available during fine-tuning. In this paper, we generalize self-supervised continual learning in a practical setting where available labels can be leveraged in any step of the SSL process. With an increasing number of continual tasks, this offers more flexibility in the pre-training and fine-tuning phases. With Kaizen, we introduce a training architecture that is able to mitigate catastrophic forgetting for both the feature extractor and classifier with a carefully designed loss function. By using a set of comprehensive evaluation metrics reflecting different aspects of continual learning, we demonstrated that Kaizen significantly outperforms previous SSL models in competitive vision benchmarks, with up to 16.5% accuracy improvement on split CIFAR-100. Kaizen is able to balance the trade-off between knowledge retention and learning from new data with an end-to-end model, paving the way for practical deployment of continual learning systems.
BOLT: An Automated Deep Learning Framework for Training and Deploying Large-Scale Neural Networks on Commodity CPU Hardware
Mar 30, 2023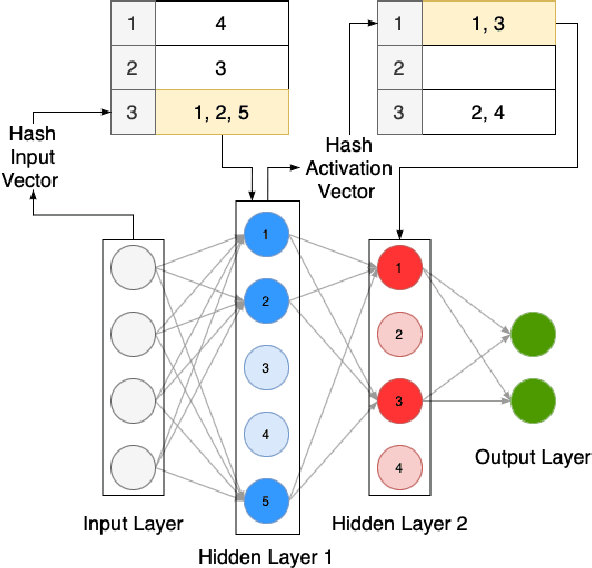
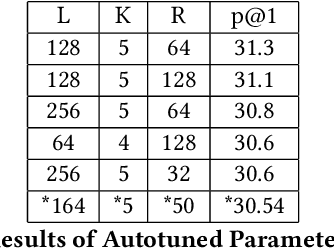
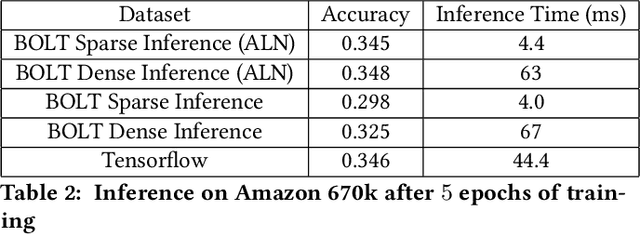
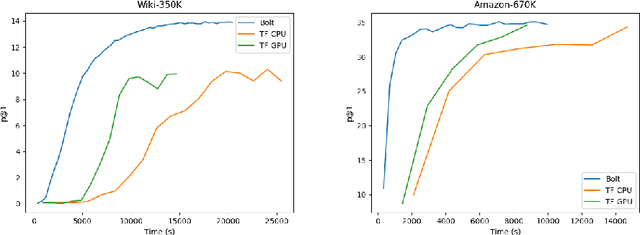
Efficient large-scale neural network training and inference on commodity CPU hardware is of immense practical significance in democratizing deep learning (DL) capabilities. Presently, the process of training massive models consisting of hundreds of millions to billions of parameters requires the extensive use of specialized hardware accelerators, such as GPUs, which are only accessible to a limited number of institutions with considerable financial resources. Moreover, there is often an alarming carbon footprint associated with training and deploying these models. In this paper, we address these challenges by introducing BOLT, a sparse deep learning library for training massive neural network models on standard CPU hardware. BOLT provides a flexible, high-level API for constructing models that will be familiar to users of existing popular DL frameworks. By automatically tuning specialized hyperparameters, BOLT also abstracts away the algorithmic details of sparse network training. We evaluate BOLT on a number of machine learning tasks drawn from recommendations, search, natural language processing, and personalization. We find that our proposed system achieves competitive performance with state-of-the-art techniques at a fraction of the cost and energy consumption and an order-of-magnitude faster inference time. BOLT has also been successfully deployed by multiple businesses to address critical problems, and we highlight one customer deployment case study in the field of e-commerce.
PoseFormerV2: Exploring Frequency Domain for Efficient and Robust 3D Human Pose Estimation
Mar 30, 2023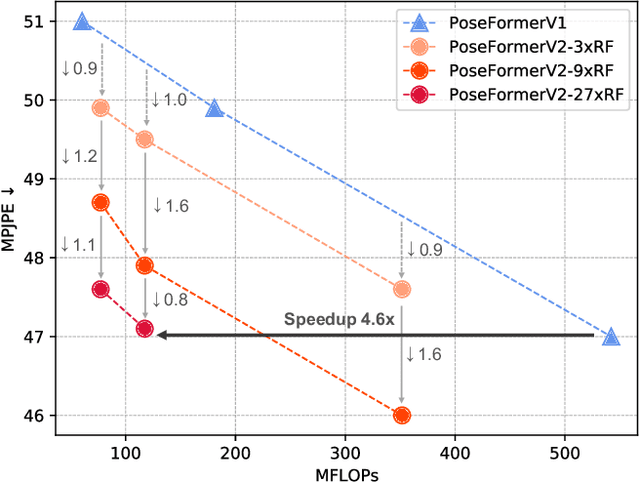
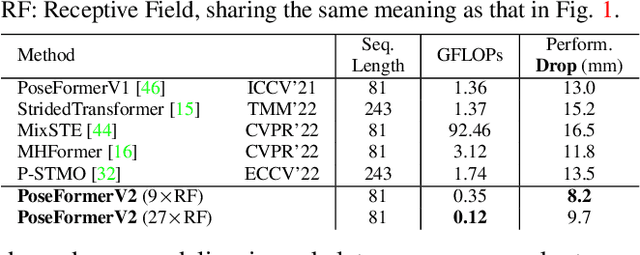
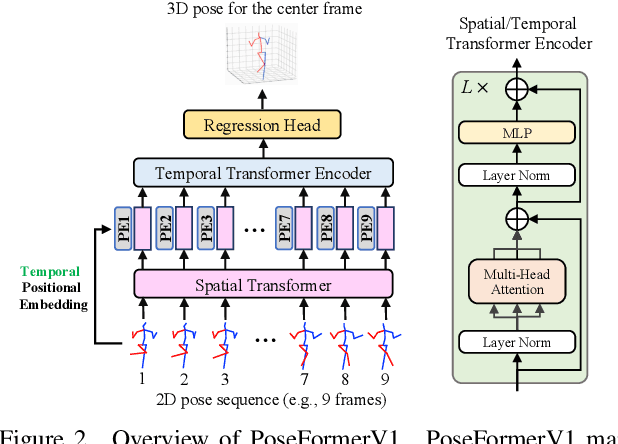
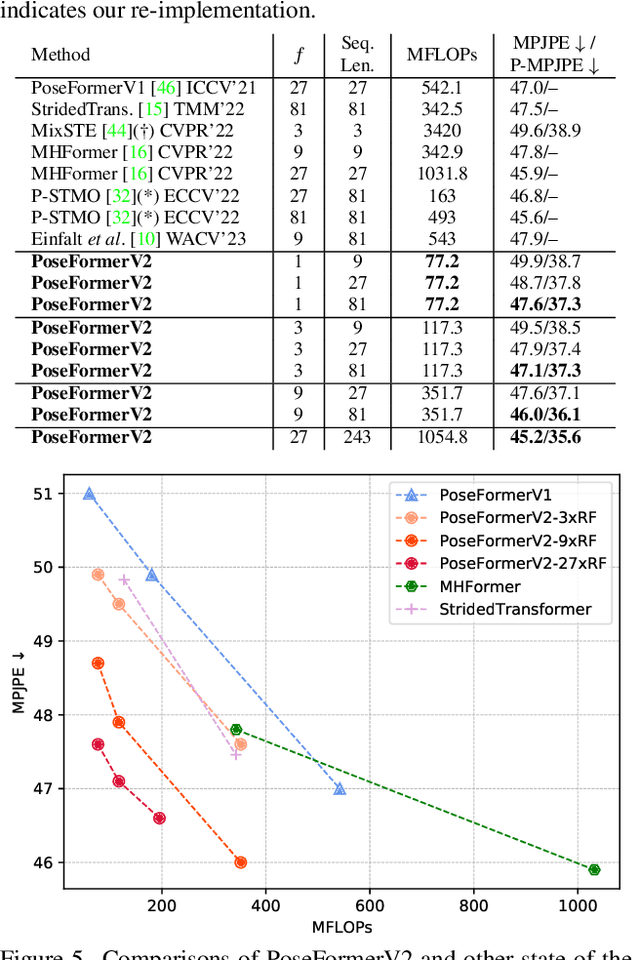
Recently, transformer-based methods have gained significant success in sequential 2D-to-3D lifting human pose estimation. As a pioneering work, PoseFormer captures spatial relations of human joints in each video frame and human dynamics across frames with cascaded transformer layers and has achieved impressive performance. However, in real scenarios, the performance of PoseFormer and its follow-ups is limited by two factors: (a) The length of the input joint sequence; (b) The quality of 2D joint detection. Existing methods typically apply self-attention to all frames of the input sequence, causing a huge computational burden when the frame number is increased to obtain advanced estimation accuracy, and they are not robust to noise naturally brought by the limited capability of 2D joint detectors. In this paper, we propose PoseFormerV2, which exploits a compact representation of lengthy skeleton sequences in the frequency domain to efficiently scale up the receptive field and boost robustness to noisy 2D joint detection. With minimum modifications to PoseFormer, the proposed method effectively fuses features both in the time domain and frequency domain, enjoying a better speed-accuracy trade-off than its precursor. Extensive experiments on two benchmark datasets (i.e., Human3.6M and MPI-INF-3DHP) demonstrate that the proposed approach significantly outperforms the original PoseFormer and other transformer-based variants. Code is released at \url{https://github.com/QitaoZhao/PoseFormerV2}.
Model Stitching and Visualization How GAN Generators can Invert Networks in Real-Time
Feb 04, 2023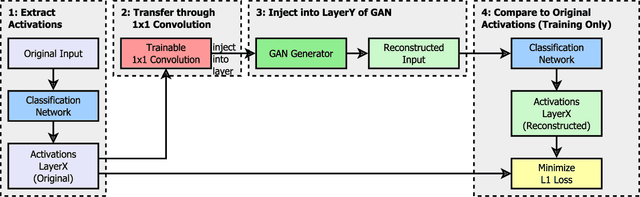
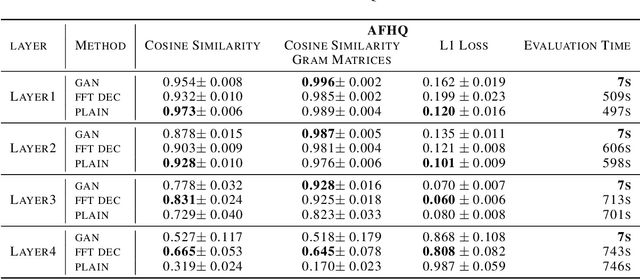
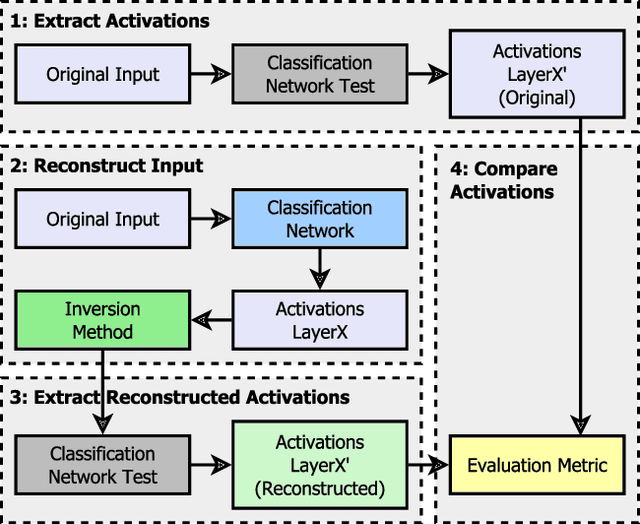

Critical applications, such as in the medical field, require the rapid provision of additional information to interpret decisions made by deep learning methods. In this work, we propose a fast and accurate method to visualize activations of classification and semantic segmentation networks by stitching them with a GAN generator utilizing convolutions. We test our approach on images of animals from the AFHQ wild dataset and real-world digital pathology scans of stained tissue samples. Our method provides comparable results to established gradient descent methods on these datasets while running about two orders of magnitude faster.
Rotating without Seeing: Towards In-hand Dexterity through Touch
Mar 27, 2023


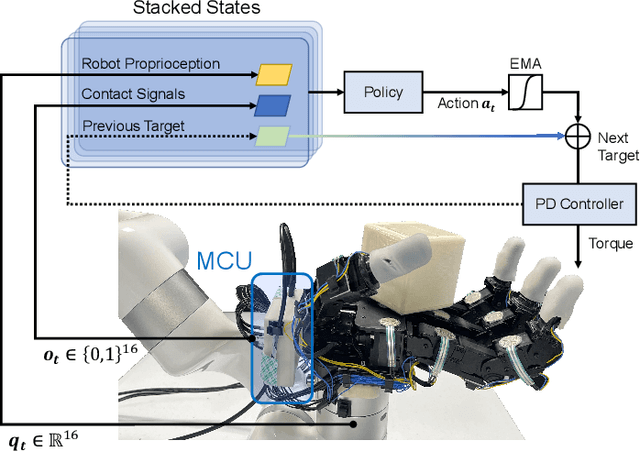
Tactile information plays a critical role in human dexterity. It reveals useful contact information that may not be inferred directly from vision. In fact, humans can even perform in-hand dexterous manipulation without using vision. Can we enable the same ability for the multi-finger robot hand? In this paper, we present Touch Dexterity, a new system that can perform in-hand object rotation using only touching without seeing the object. Instead of relying on precise tactile sensing in a small region, we introduce a new system design using dense binary force sensors (touch or no touch) overlaying one side of the whole robot hand (palm, finger links, fingertips). Such a design is low-cost, giving a larger coverage of the object, and minimizing the Sim2Real gap at the same time. We train an in-hand rotation policy using Reinforcement Learning on diverse objects in simulation. Relying on touch-only sensing, we can directly deploy the policy in a real robot hand and rotate novel objects that are not presented in training. Extensive ablations are performed on how tactile information help in-hand manipulation.Our project is available at https://touchdexterity.github.io.
Multi-Granularity Archaeological Dating of Chinese Bronze Dings Based on a Knowledge-Guided Relation Graph
Mar 27, 2023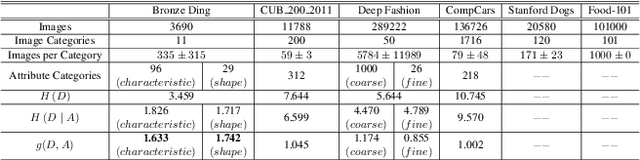

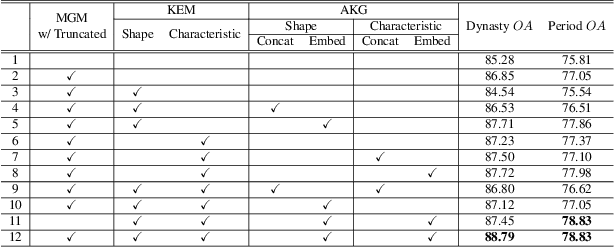
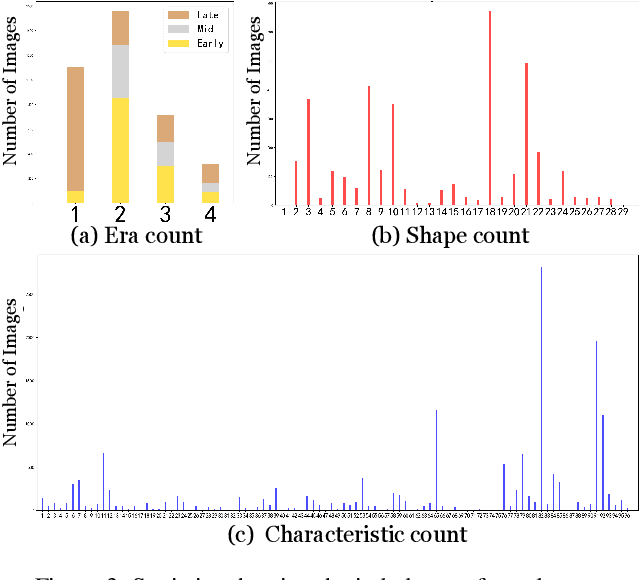
The archaeological dating of bronze dings has played a critical role in the study of ancient Chinese history. Current archaeology depends on trained experts to carry out bronze dating, which is time-consuming and labor-intensive. For such dating, in this study, we propose a learning-based approach to integrate advanced deep learning techniques and archaeological knowledge. To achieve this, we first collect a large-scale image dataset of bronze dings, which contains richer attribute information than other existing fine-grained datasets. Second, we introduce a multihead classifier and a knowledge-guided relation graph to mine the relationship between attributes and the ding era. Third, we conduct comparison experiments with various existing methods, the results of which show that our dating method achieves a state-of-the-art performance. We hope that our data and applied networks will enrich fine-grained classification research relevant to other interdisciplinary areas of expertise. The dataset and source code used are included in our supplementary materials, and will be open after submission owing to the anonymity policy. Source codes and data are available at: https://github.com/zhourixin/bronze-Ding.