 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Neural Frailty Machine: Beyond proportional hazard assumption in neural survival regressions
Mar 18, 2023
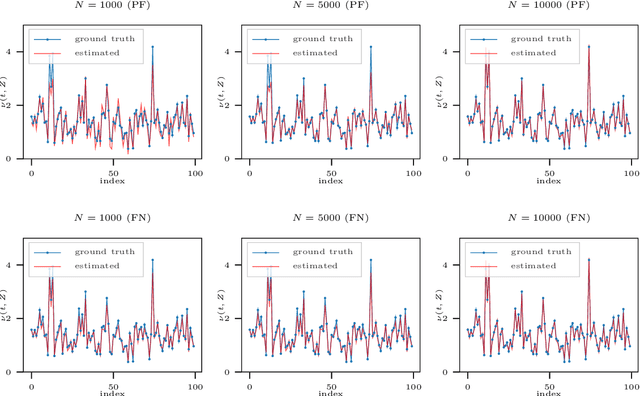
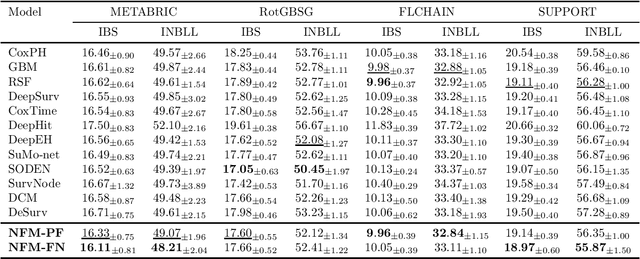
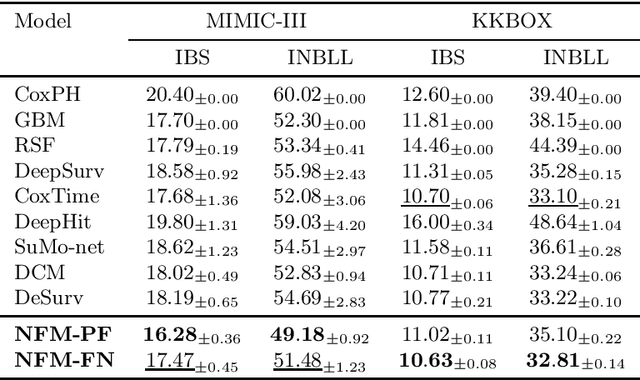
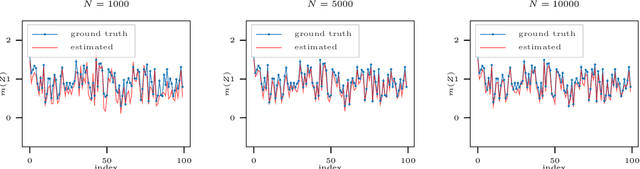
We present neural frailty machine (NFM), a powerful and flexible neural modeling framework for survival regressions. The NFM framework utilizes the classical idea of multiplicative frailty in survival analysis to capture unobserved heterogeneity among individuals, at the same time being able to leverage the strong approximation power of neural architectures for handling nonlinear covariate dependence. Two concrete models are derived under the framework that extends neural proportional hazard models and nonparametric hazard regression models. Both models allow efficient training under the likelihood objective. Theoretically, for both proposed models, we establish statistical guarantees of neural function approximation with respect to nonparametric components via characterizing their rate of convergence. Empirically, we provide synthetic experiments that verify our theoretical statements. We also conduct experimental evaluations over $6$ benchmark datasets of different scales, showing that the proposed NFM models outperform state-of-the-art survival models in terms of predictive performance. Our code is publicly availabel at https://github.com/Rorschach1989/nfm
Dynamic Time Warping based Adversarial Framework for Time-Series Domain
Jul 09, 2022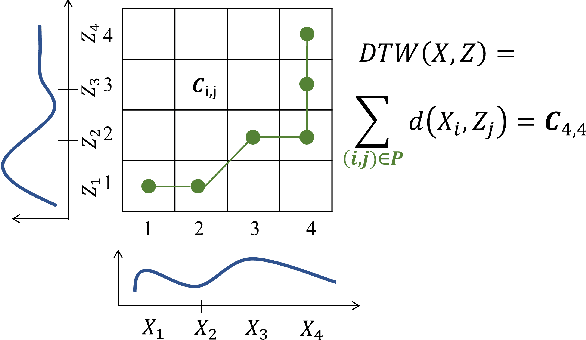
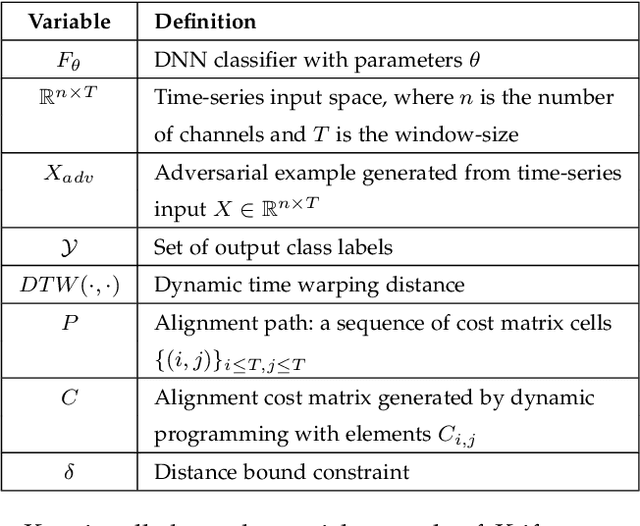
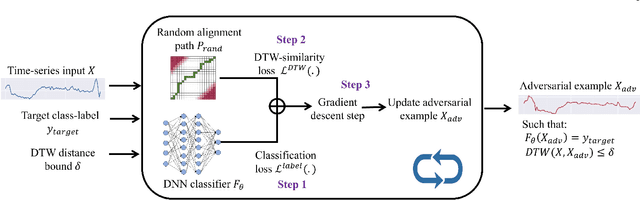
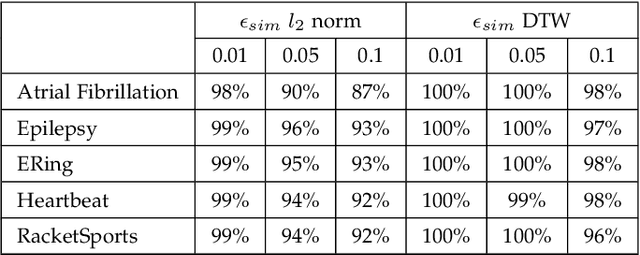
Despite the rapid progress on research in adversarial robustness of deep neural networks (DNNs), there is little principled work for the time-series domain. Since time-series data arises in diverse applications including mobile health, finance, and smart grid, it is important to verify and improve the robustness of DNNs for the time-series domain. In this paper, we propose a novel framework for the time-series domain referred as {\em Dynamic Time Warping for Adversarial Robustness (DTW-AR)} using the dynamic time warping measure. Theoretical and empirical evidence is provided to demonstrate the effectiveness of DTW over the standard Euclidean distance metric employed in prior methods for the image domain. We develop a principled algorithm justified by theoretical analysis to efficiently create diverse adversarial examples using random alignment paths. Experiments on diverse real-world benchmarks show the effectiveness of DTW-AR to fool DNNs for time-series data and to improve their robustness using adversarial training. The source code of DTW-AR algorithms is available at https://github.com/tahabelkhouja/DTW-AR
Path Independent Equilibrium Models Can Better Exploit Test-Time Computation
Nov 18, 2022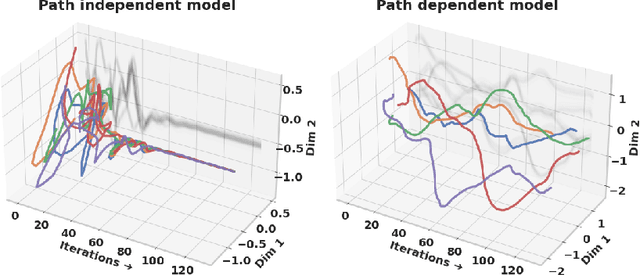

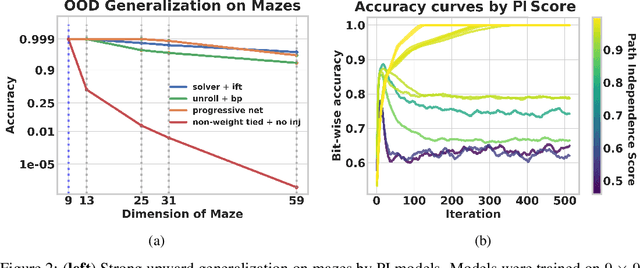
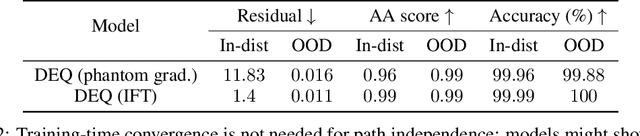
Designing networks capable of attaining better performance with an increased inference budget is important to facilitate generalization to harder problem instances. Recent efforts have shown promising results in this direction by making use of depth-wise recurrent networks. We show that a broad class of architectures named equilibrium models display strong upwards generalization, and find that stronger performance on harder examples (which require more iterations of inference to get correct) strongly correlates with the path independence of the system -- its tendency to converge to the same steady-state behaviour regardless of initialization, given enough computation. Experimental interventions made to promote path independence result in improved generalization on harder problem instances, while those that penalize it degrade this ability. Path independence analyses are also useful on a per-example basis: for equilibrium models that have good in-distribution performance, path independence on out-of-distribution samples strongly correlates with accuracy. Our results help explain why equilibrium models are capable of strong upwards generalization and motivates future work that harnesses path independence as a general modelling principle to facilitate scalable test-time usage.
Driver Maneuver Detection and Analysis using Time Series Segmentation and Classification
Nov 10, 2022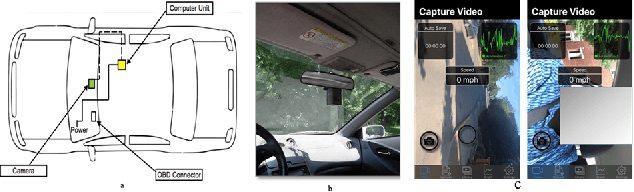

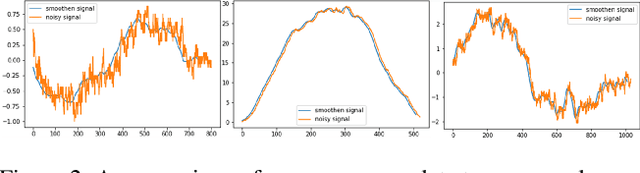

The current paper implements a methodology for automatically detecting vehicle maneuvers from vehicle telemetry data under naturalistic driving settings. Previous approaches have treated vehicle maneuver detection as a classification problem, although both time series segmentation and classification are required since input telemetry data is continuous. Our objective is to develop an end-to-end pipeline for frame-by-frame annotation of naturalistic driving studies videos into various driving events including stop and lane keeping events, lane changes, left-right turning movements, and horizontal curve maneuvers. To address the time series segmentation problem, the study developed an Energy Maximization Algorithm (EMA) capable of extracting driving events of varying durations and frequencies from continuous signal data. To reduce overfitting and false alarm rates, heuristic algorithms were used to classify events with highly variable patterns such as stops and lane-keeping. To classify segmented driving events, four machine learning models were implemented, and their accuracy and transferability were assessed over multiple data sources. The duration of events extracted by EMA were comparable to actual events, with accuracies ranging from 59.30% (left lane change) to 85.60% (lane-keeping). Additionally, the overall accuracy of the 1D-convolutional neural network model was 98.99%, followed by the Long-short-term-memory model at 97.75%, then random forest model at 97.71%, and the support vector machine model at 97.65%. These model accuracies where consistent across different data sources. The study concludes that implementing a segmentation-classification pipeline significantly improves both the accuracy for driver maneuver detection and transferability of shallow and deep ML models across diverse datasets.
Generating symbolic music using diffusion models
Mar 15, 2023
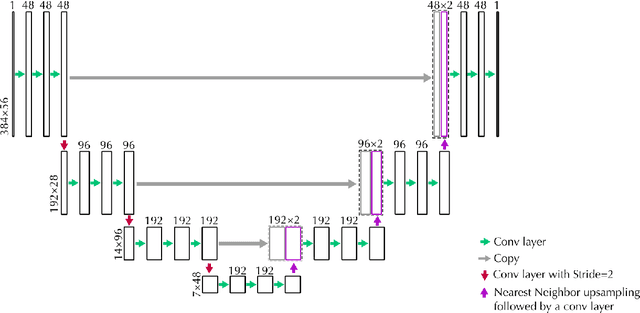


Probabilistic Denoising Diffusion models have emerged as simple yet very powerful generative models. Diffusion models unlike other generative models do not suffer from mode collapse nor require a discriminator to generate high quality samples. In this paper, we propose a diffusion model that uses a binomial prior distribution to generate piano-rolls. The paper also proposes an efficient method to train the model and generate samples. The generated music has coherence at time scales up to the length of the training piano-roll segments. We show how such a model is conditioned on the input and can be used to harmonize a given melody, complete an incomplete piano-roll or generate a variation of a given piece. The code is shared publicly to encourage the use and development of the method by the community.
Prototype Knowledge Distillation for Medical Segmentation with Missing Modality
Mar 17, 2023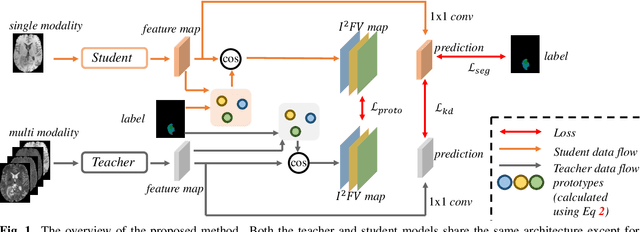
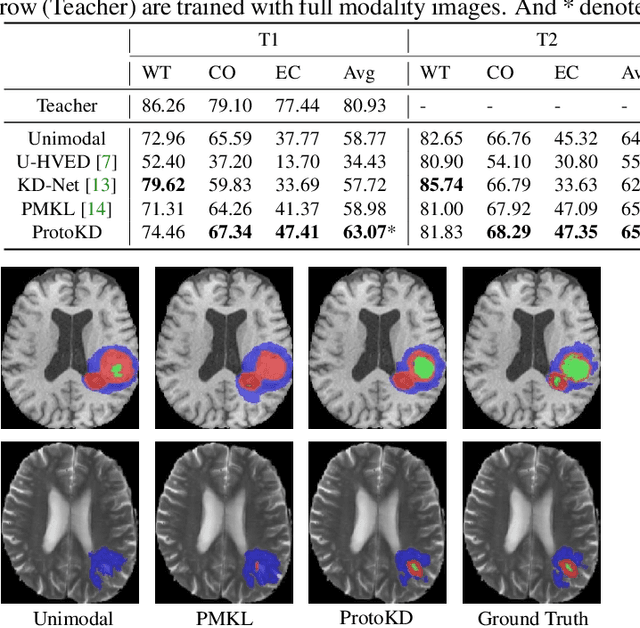
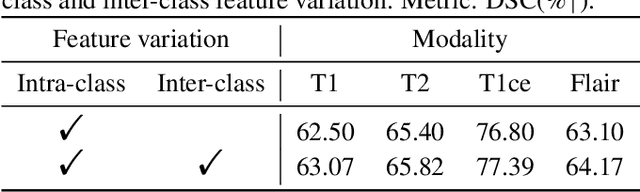
Multi-modality medical imaging is crucial in clinical treatment as it can provide complementary information for medical image segmentation. However, collecting multi-modal data in clinical is difficult due to the limitation of the scan time and other clinical situations. As such, it is clinically meaningful to develop an image segmentation paradigm to handle this missing modality problem. In this paper, we propose a prototype knowledge distillation (ProtoKD) method to tackle the challenging problem, especially for the toughest scenario when only single modal data can be accessed. Specifically, our ProtoKD can not only distillate the pixel-wise knowledge of multi-modality data to single-modality data but also transfer intra-class and inter-class feature variations, such that the student model could learn more robust feature representation from the teacher model and inference with only one single modality data. Our method achieves state-of-the-art performance on BraTS benchmark.
BotShape: A Novel Social Bots Detection Approach via Behavioral Patterns
Mar 17, 2023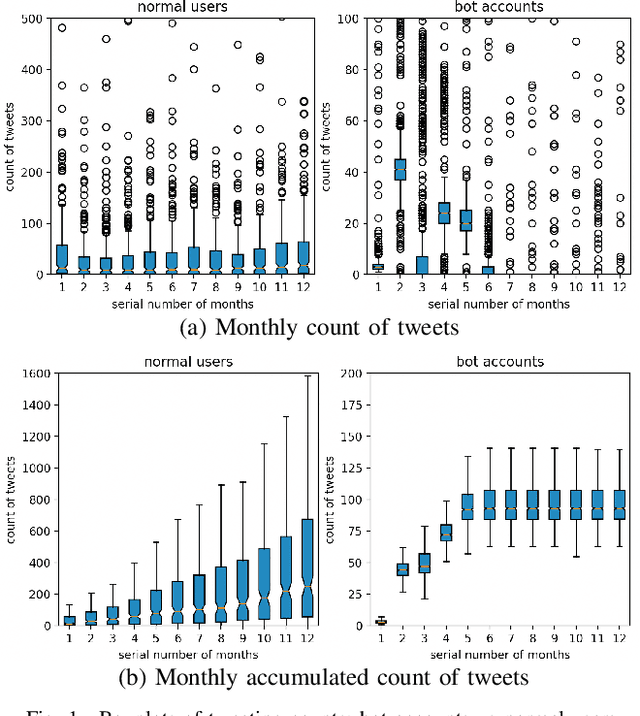
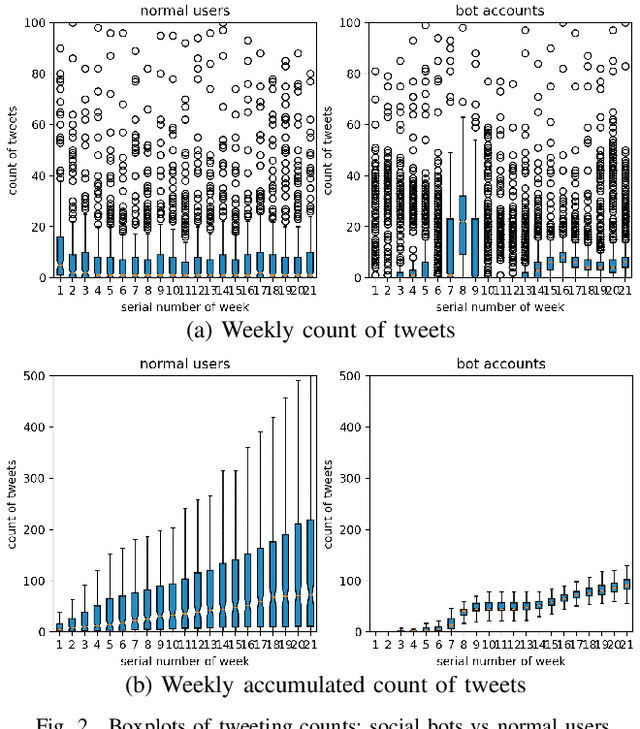
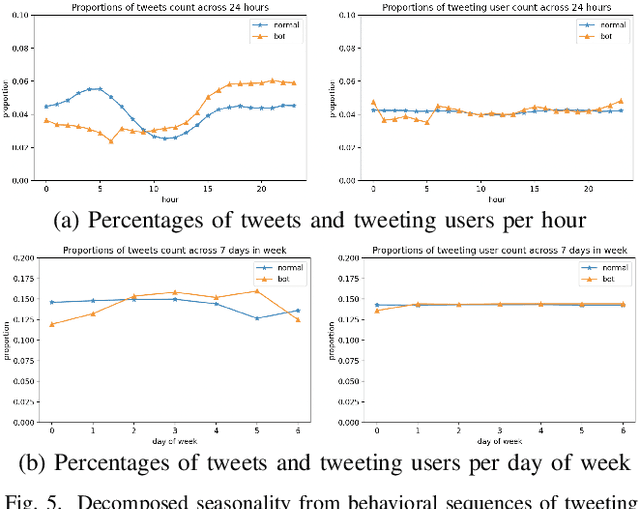
An essential topic in online social network security is how to accurately detect bot accounts and relieve their harmful impacts (e.g., misinformation, rumor, and spam) on genuine users. Based on a real-world data set, we construct behavioral sequences from raw event logs. After extracting critical characteristics from behavioral time series, we observe differences between bots and genuine users and similar patterns among bot accounts. We present a novel social bot detection system BotShape, to automatically catch behavioral sequences and characteristics as features for classifiers to detect bots. We evaluate the detection performance of our system in ground-truth instances, showing an average accuracy of 98.52% and an average f1-score of 96.65% on various types of classifiers. After comparing it with other research, we conclude that BotShape is a novel approach to profiling an account, which could improve performance for most methods by providing significant behavioral features.
A Heuristic Autonomous Exploration Method Based on Environmental Information Gain During Quadrotor Flight
Feb 21, 2023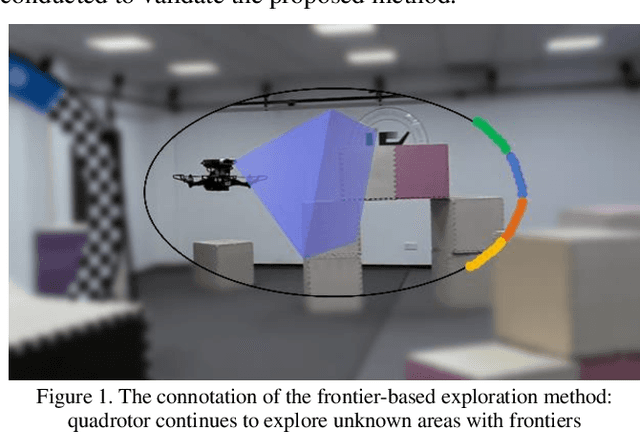
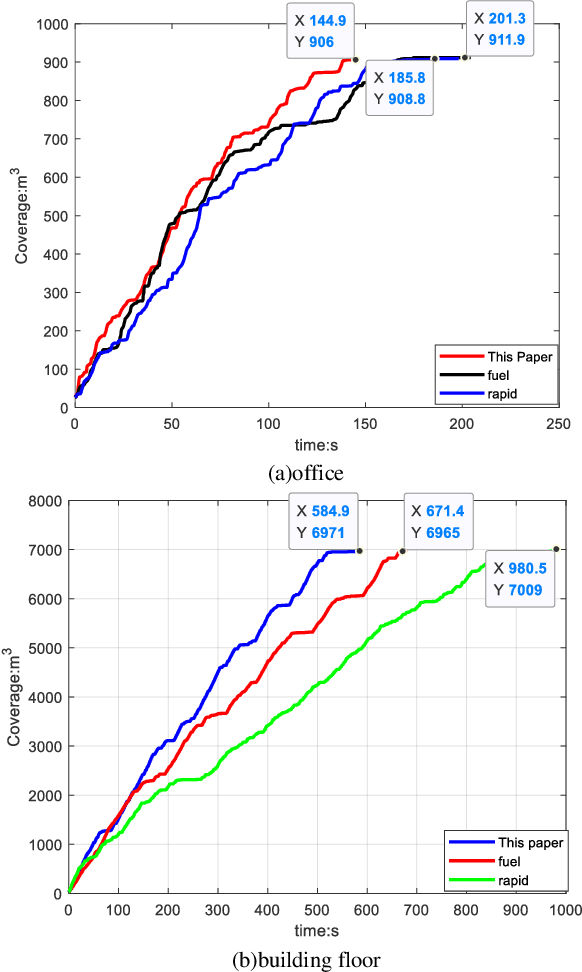

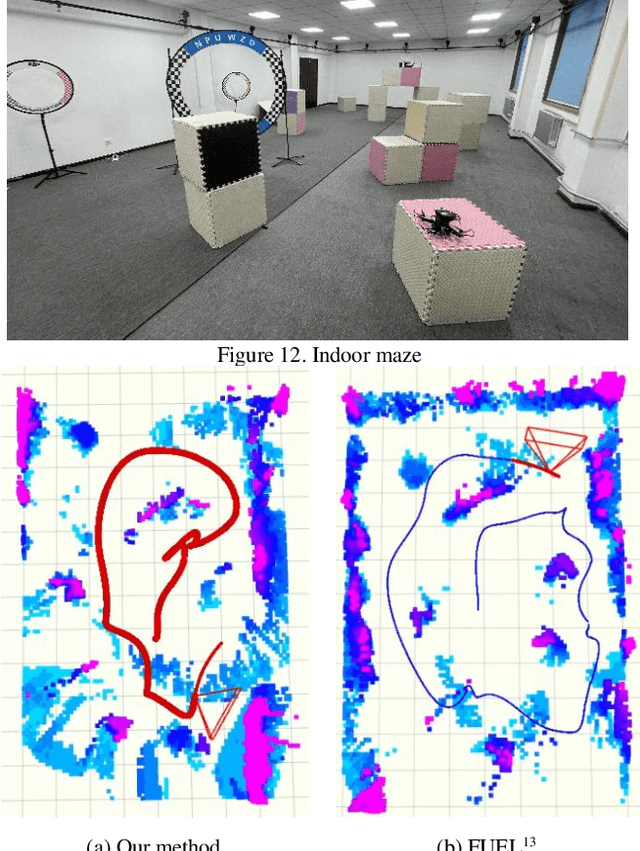
Autonomous exploration is a widely studied fundamental application in the field of quadrotors, which requires them to automatically explore unknown space to obtain complete information about the environment. The frontier-based method, which is one of the representative works on autonomous exploration, drives autonomous determination by the definition of frontier information, so that complete information about the environment is available to the quadrotor. However, existing frontier-based methods are able to accomplish the task but still suffer from inefficient exploration. How to improve the efficiency of autonomous exploration is the focus of current research. Typical problems include slow frontier generation, which affects real-time viewpoint determination, and insufficient determination methods that affect the quality of viewpoints. Therefore, to overcome these problems, this paper proposes a two-level viewpoint determination method for frontier-based autonomous exploration. Firstly, a sampling-based frontier detection method is presented for faster frontier generation, which improves the immediacy of environmental representation compared to traditional traversal-based methods. Secondly, we consider the access to environmental information during flight for the first time and design an innovative heuristic evaluation function to decide on a high-quality viewpoint as the next local navigation target in each exploration iteration. We conducted extensive benchmark and real-world tests to validate our method. The results confirm that our method optimizes the frontier search time by 85%, the exploration time by around 20-30%, and the exploration path by 25-35%.
Tactile-Driven Gentle Grasping for Human-Robot Collaborative Tasks
Mar 16, 2023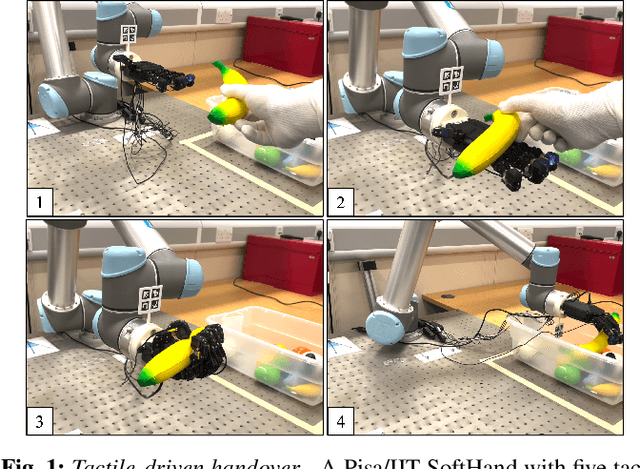
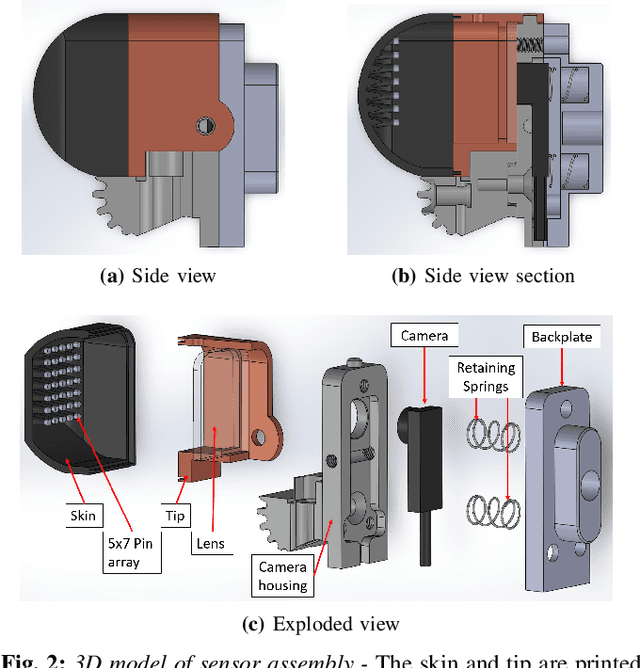
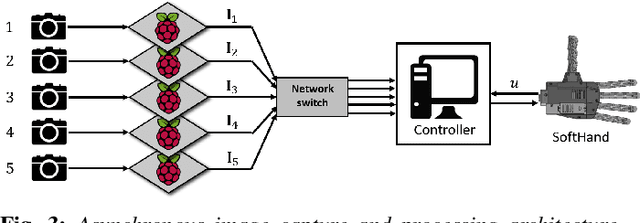
This paper presents a control scheme for force sensitive, gentle grasping with a Pisa/IIT anthropomorphic SoftHand equipped with a miniaturised version of the TacTip optical tactile sensor on all five fingertips. The tactile sensors provide high-resolution information about a grasp and how the fingers interact with held objects. We first describe a series of hardware developments for performing asynchronous sensor data acquisition and processing, resulting in a fast control loop sufficient for real-time grasp control. We then develop a novel grasp controller that uses tactile feedback from all five fingertip sensors simultaneously to gently and stably grasp 43 objects of varying geometry and stiffness, which is then applied to a human-to-robot handover task. These developments open the door to more advanced manipulation with underactuated hands via fast reflexive control using high-resolution tactile sensing.
Block-wise Bit-Compression of Transformer-based Models
Mar 16, 2023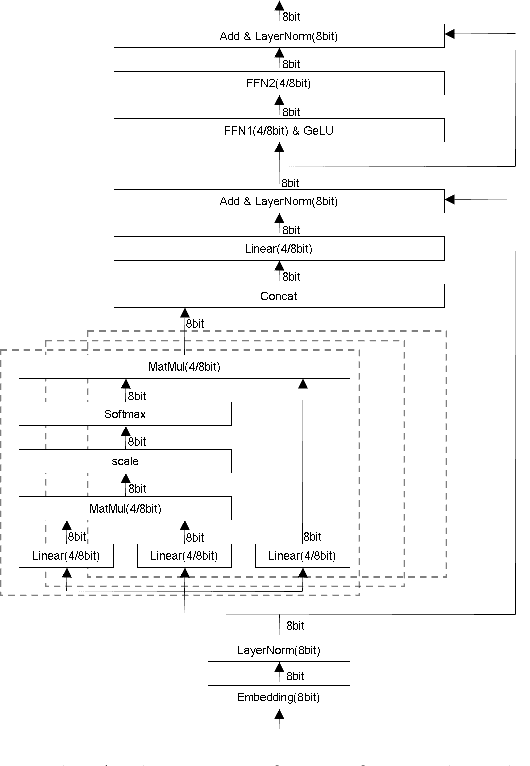


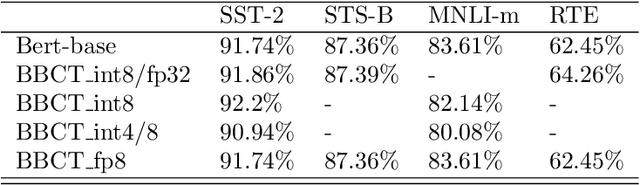
With the popularity of the recent Transformer-based models represented by BERT, GPT-3 and ChatGPT, there has been state-of-the-art performance in a range of natural language processing tasks. However, the massive computations, huge memory footprint, and thus high latency of Transformer-based models is an inevitable challenge for the cloud with high real-time requirement. To tackle the issue, we propose BBCT, a method of block-wise bit-compression for transformer without retraining. Our method achieves more fine-grained compression of the whole transformer, including embedding, matrix multiplication, GELU, softmax, layer normalization, and all the intermediate results. As a case, we compress an efficient BERT with the method of BBCT. Our benchmark test results on General Language Understanding Evaluation (GLUE) show that BBCT can achieve less than 1% accuracy drop in most tasks.