 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
FAStEN: an efficient adaptive method for feature selection and estimation in high-dimensional functional regressions
Mar 26, 2023

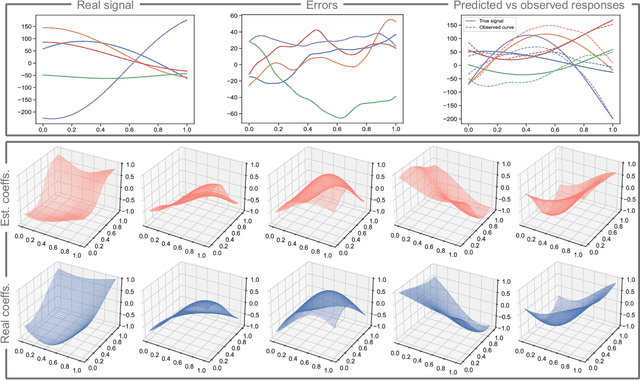
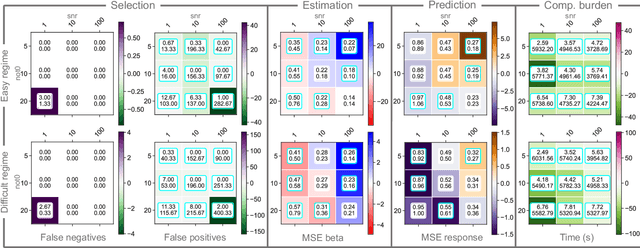
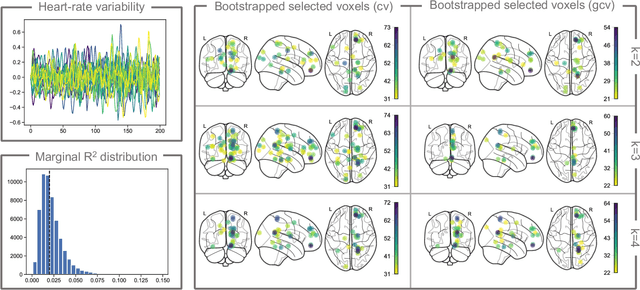
Functional regression analysis is an established tool for many contemporary scientific applications. Regression problems involving large and complex data sets are ubiquitous, and feature selection is crucial for avoiding overfitting and achieving accurate predictions. We propose a new, flexible, and ultra-efficient approach to perform feature selection in a sparse high dimensional function-on-function regression problem, and we show how to extend it to the scalar-on-function framework. Our method combines functional data, optimization, and machine learning techniques to perform feature selection and parameter estimation simultaneously. We exploit the properties of Functional Principal Components, and the sparsity inherent to the Dual Augmented Lagrangian problem to significantly reduce computational cost, and we introduce an adaptive scheme to improve selection accuracy. Through an extensive simulation study, we benchmark our approach to the best existing competitors and demonstrate a massive gain in terms of CPU time and selection performance without sacrificing the quality of the coefficients' estimation. Finally, we present an application to brain fMRI data from the AOMIC PIOP1 study.
FedFTN: Personalized Federated Learning with Deep Feature Transformation Network for Multi-institutional Low-count PET Denoising
Apr 02, 2023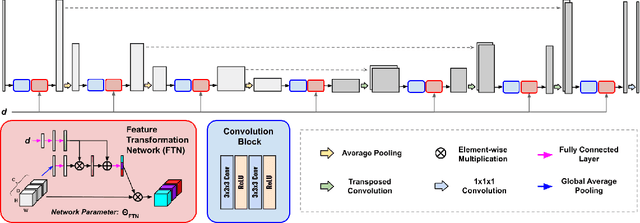

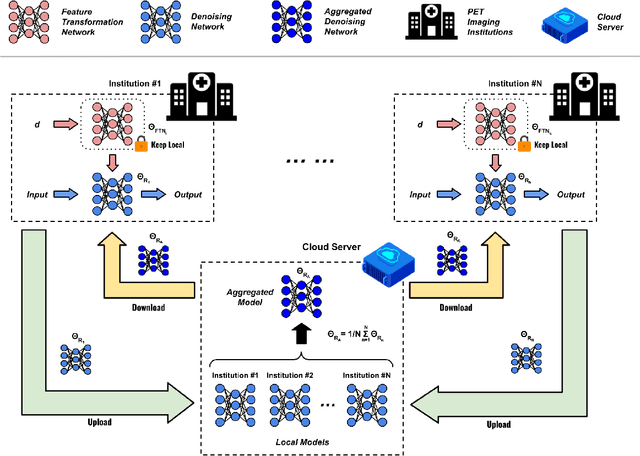

Low-count PET is an efficient way to reduce radiation exposure and acquisition time, but the reconstructed images often suffer from low signal-to-noise ratio (SNR), thus affecting diagnosis and other downstream tasks. Recent advances in deep learning have shown great potential in improving low-count PET image quality, but acquiring a large, centralized, and diverse dataset from multiple institutions for training a robust model is difficult due to privacy and security concerns of patient data. Moreover, low-count PET data at different institutions may have different data distribution, thus requiring personalized models. While previous federated learning (FL) algorithms enable multi-institution collaborative training without the need of aggregating local data, addressing the large domain shift in the application of multi-institutional low-count PET denoising remains a challenge and is still highly under-explored. In this work, we propose FedFTN, a personalized federated learning strategy that addresses these challenges. FedFTN uses a local deep feature transformation network (FTN) to modulate the feature outputs of a globally shared denoising network, enabling personalized low-count PET denoising for each institution. During the federated learning process, only the denoising network's weights are communicated and aggregated, while the FTN remains at the local institutions for feature transformation. We evaluated our method using a large-scale dataset of multi-institutional low-count PET imaging data from three medical centers located across three continents, and showed that FedFTN provides high-quality low-count PET images, outperforming previous baseline FL reconstruction methods across all low-count levels at all three institutions.
EvConv: Fast CNN Inference on Event Camera Inputs For High-Speed Robot Perception
Mar 08, 2023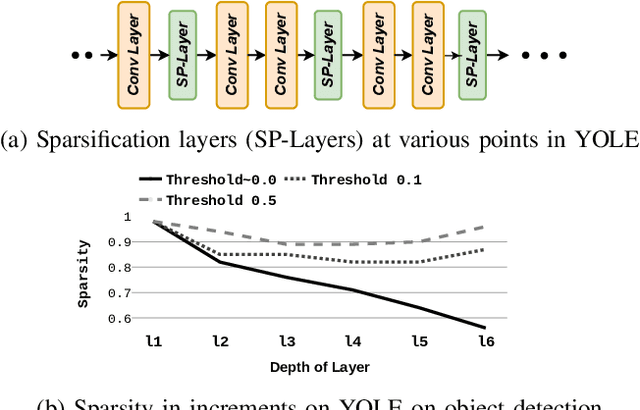
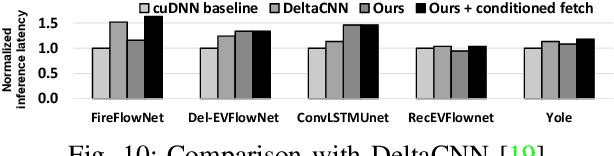
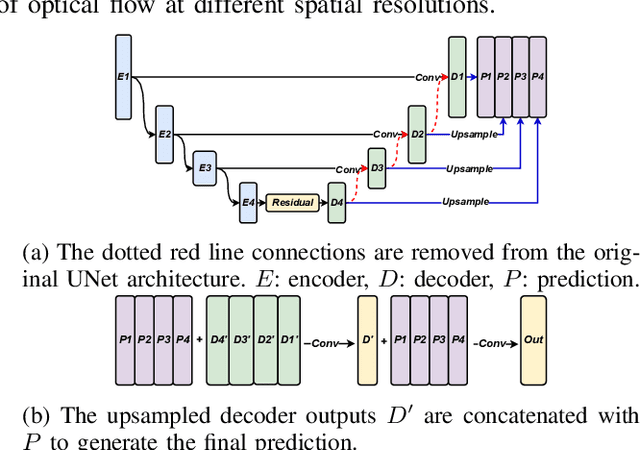
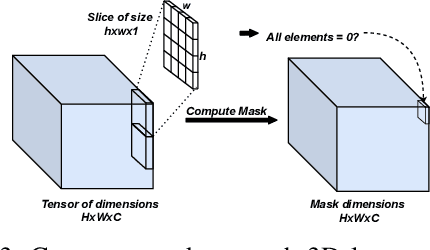
Event cameras capture visual information with a high temporal resolution and a wide dynamic range. This enables capturing visual information at fine time granularities (e.g., microseconds) in rapidly changing environments. This makes event cameras highly useful for high-speed robotics tasks involving rapid motion, such as high-speed perception, object tracking, and control. However, convolutional neural network inference on event camera streams cannot currently perform real-time inference at the high speeds at which event cameras operate - current CNN inference times are typically closer in order of magnitude to the frame rates of regular frame-based cameras. Real-time inference at event camera rates is necessary to fully leverage the high frequency and high temporal resolution that event cameras offer. This paper presents EvConv, a new approach to enable fast inference on CNNs for inputs from event cameras. We observe that consecutive inputs to the CNN from an event camera have only small differences between them. Thus, we propose to perform inference on the difference between consecutive input tensors, or the increment. This enables a significant reduction in the number of floating-point operations required (and thus the inference latency) because increments are very sparse. We design EvConv to leverage the irregular sparsity in increments from event cameras and to retain the sparsity of these increments across all layers of the network. We demonstrate a reduction in the number of floating operations required in the forward pass by up to 98%. We also demonstrate a speedup of up to 1.6X for inference using CNNs for tasks such as depth estimation, object recognition, and optical flow estimation, with almost no loss in accuracy.
ATM Fraud Detection using Streaming Data Analytics
Mar 08, 2023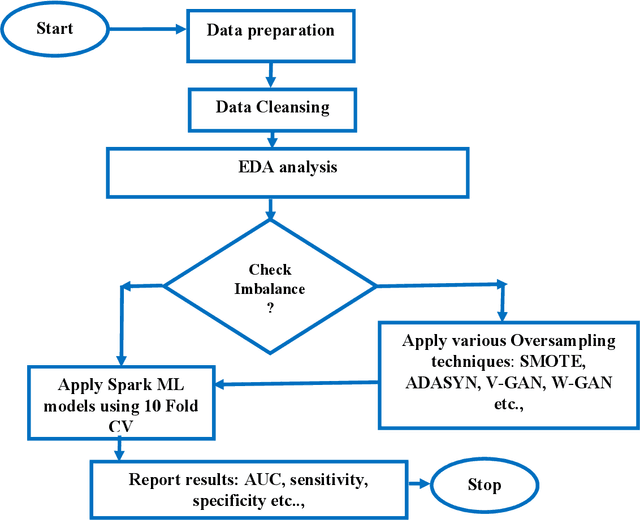
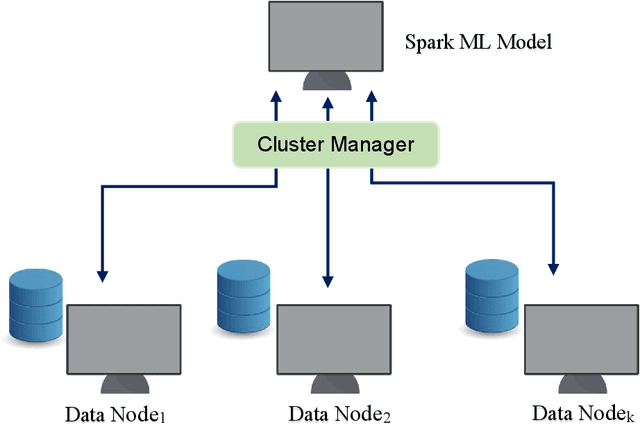

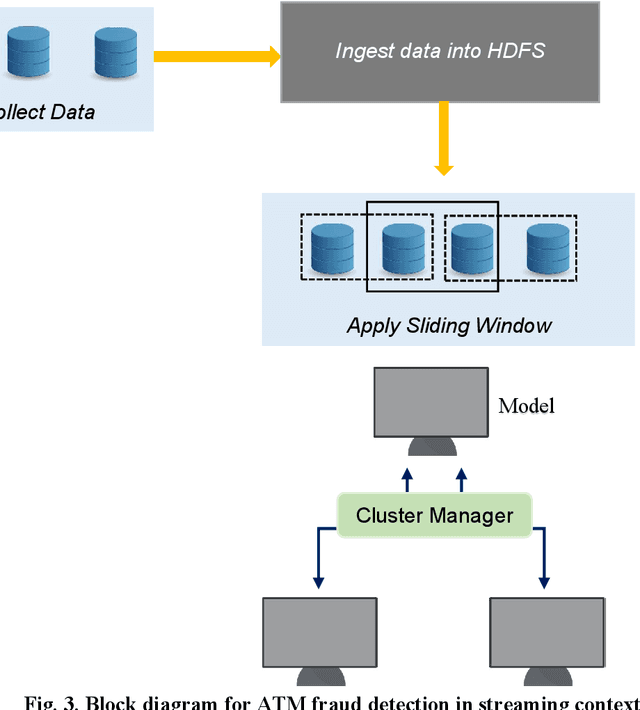
Gaining the trust and confidence of customers is the essence of the growth and success of financial institutions and organizations. Of late, the financial industry is significantly impacted by numerous instances of fraudulent activities. Further, owing to the generation of large voluminous datasets, it is highly essential that underlying framework is scalable and meet real time needs. To address this issue, in the study, we proposed ATM fraud detection in static and streaming contexts respectively. In the static context, we investigated a parallel and scalable machine learning algorithms for ATM fraud detection that is built on Spark and trained with a variety of machine learning (ML) models including Naive Bayes (NB), Logistic Regression (LR), Support Vector Machine (SVM), Decision Tree (DT), Random Forest (RF), Gradient Boosting Tree (GBT), and Multi-layer perceptron (MLP). We also employed several balancing techniques like Synthetic Minority Oversampling Technique (SMOTE) and its variants, Generative Adversarial Networks (GAN), to address the rarity in the dataset. In addition, we proposed a streaming based ATM fraud detection in the streaming context. Our sliding window based method collects ATM transactions that are performed within a specified time interval and then utilizes to train several ML models, including NB, RF, DT, and K-Nearest Neighbour (KNN). We selected these models based on their less model complexity and quicker response time. In both contexts, RF turned out to be the best model. RF obtained the best mean AUC of 0.975 in the static context and mean AUC of 0.910 in the streaming context. RF is also empirically proven to be statistically significant than the next-best performing models.
An inexact linearized proximal algorithm for a class of DC composite optimization problems and applications
Mar 29, 2023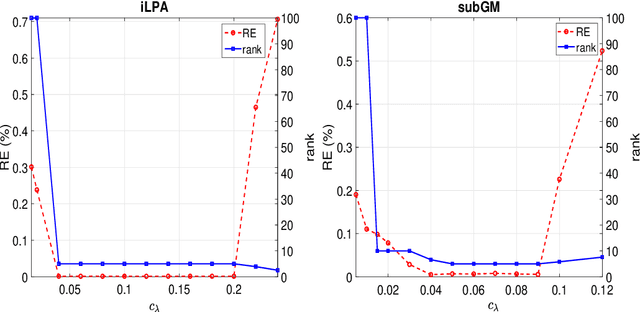
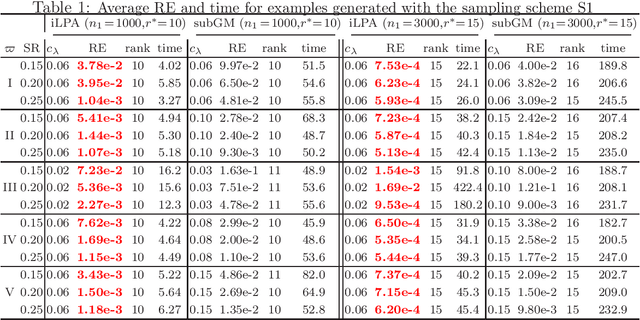
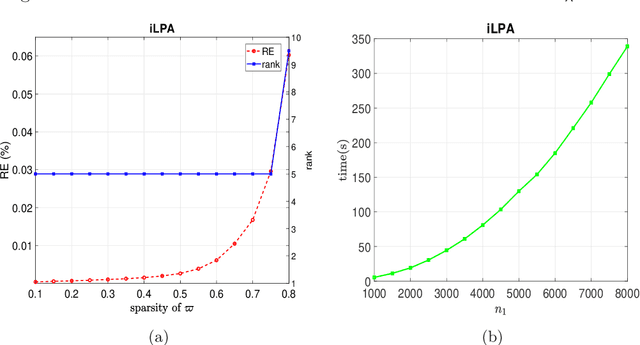
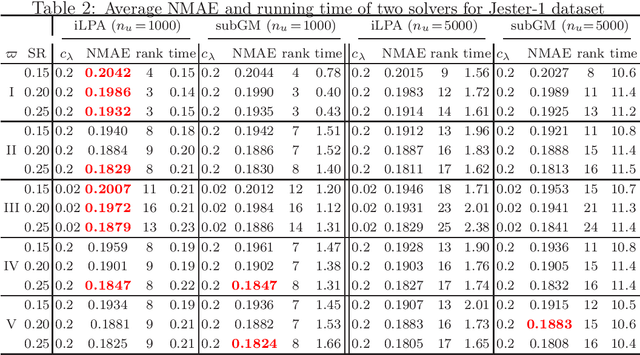
This paper is concerned with a class of DC composite optimization problems which, as an extension of the convex composite optimization problem and the DC program with nonsmooth components, often arises from robust factorization models of low-rank matrix recovery. For this class of nonconvex and nonsmooth problems, we propose an inexact linearized proximal algorithm (iLPA) which in each step computes an inexact minimizer of a strongly convex majorization constructed by the partial linearization of their objective functions. The generated iterate sequence is shown to be convergent under the Kurdyka-{\L}ojasiewicz (KL) property of a potential function, and the convergence admits a local R-linear rate if the potential function has the KL property of exponent $1/2$ at the limit point. For the latter assumption, we provide a verifiable condition by leveraging the composite structure, and clarify its relation with the regularity used for the convex composite optimization. Finally, the proposed iLPA is applied to a robust factorization model for matrix completions with outliers, DC programs with nonsmooth components, and $\ell_1$-norm exact penalty of DC constrained programs, and numerical comparison with the existing algorithms confirms the superiority of our iLPA in computing time and quality of solutions.
A Mixing Time Lower Bound for a Simplified Version of BART
Oct 17, 2022
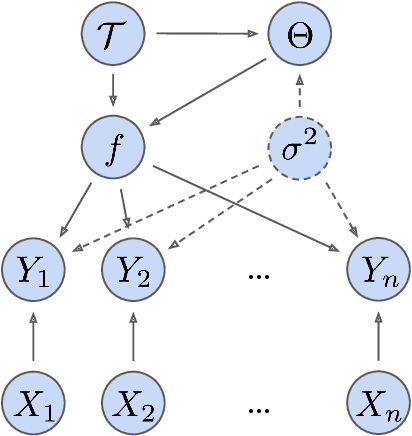

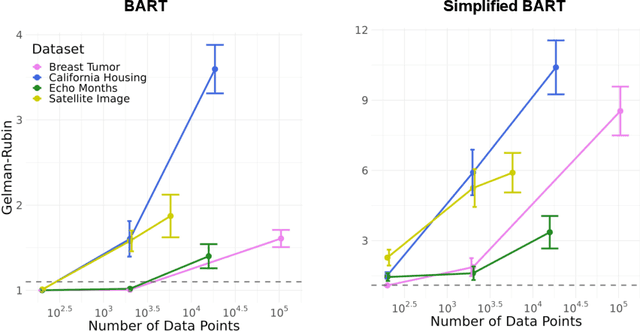
Bayesian Additive Regression Trees (BART) is a popular Bayesian non-parametric regression algorithm. The posterior is a distribution over sums of decision trees, and predictions are made by averaging approximate samples from the posterior. The combination of strong predictive performance and the ability to provide uncertainty measures has led BART to be commonly used in the social sciences, biostatistics, and causal inference. BART uses Markov Chain Monte Carlo (MCMC) to obtain approximate posterior samples over a parameterized space of sums of trees, but it has often been observed that the chains are slow to mix. In this paper, we provide the first lower bound on the mixing time for a simplified version of BART in which we reduce the sum to a single tree and use a subset of the possible moves for the MCMC proposal distribution. Our lower bound for the mixing time grows exponentially with the number of data points. Inspired by this new connection between the mixing time and the number of data points, we perform rigorous simulations on BART. We show qualitatively that BART's mixing time increases with the number of data points. The slow mixing time of the simplified BART suggests a large variation between different runs of the simplified BART algorithm and a similar large variation is known for BART in the literature. This large variation could result in a lack of stability in the models, predictions, and posterior intervals obtained from the BART MCMC samples. Our lower bound and simulations suggest increasing the number of chains with the number of data points.
Strong Baselines for Parameter Efficient Few-Shot Fine-tuning
Apr 04, 2023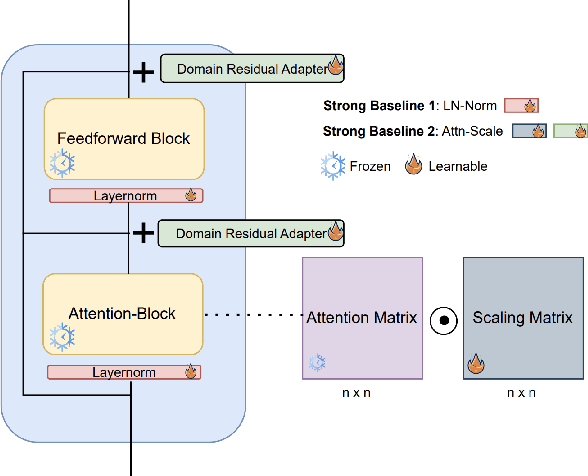
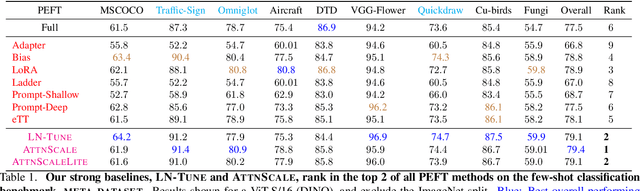
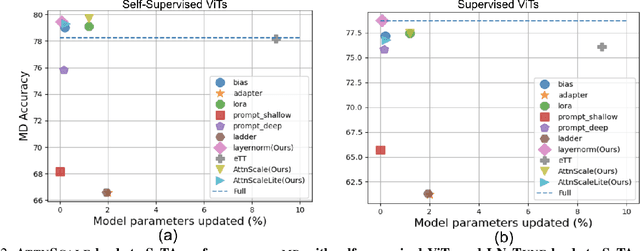
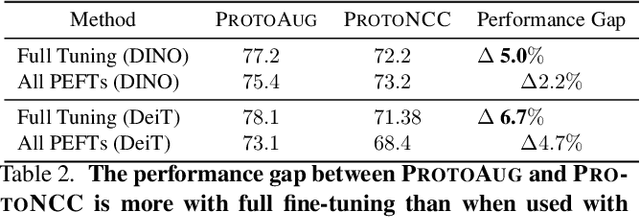
Few-shot classification (FSC) entails learning novel classes given only a few examples per class after a pre-training (or meta-training) phase on a set of base classes. Recent works have shown that simply fine-tuning a pre-trained Vision Transformer (ViT) on new test classes is a strong approach for FSC. Fine-tuning ViTs, however, is expensive in time, compute and storage. This has motivated the design of parameter efficient fine-tuning (PEFT) methods which fine-tune only a fraction of the Transformer's parameters. While these methods have shown promise, inconsistencies in experimental conditions make it difficult to disentangle their advantage from other experimental factors including the feature extractor architecture, pre-trained initialization and fine-tuning algorithm, amongst others. In our paper, we conduct a large-scale, experimentally consistent, empirical analysis to study PEFTs for few-shot image classification. Through a battery of over 1.8k controlled experiments on large-scale few-shot benchmarks including Meta-Dataset (MD) and ORBIT, we uncover novel insights on PEFTs that cast light on their efficacy in fine-tuning ViTs for few-shot classification. Through our controlled empirical study, we have two main findings: (i) Fine-tuning just the LayerNorm parameters (which we call LN-Tune) during few-shot adaptation is an extremely strong baseline across ViTs pre-trained with both self-supervised and supervised objectives, (ii) For self-supervised ViTs, we find that simply learning a set of scaling parameters for each attention matrix (which we call AttnScale) along with a domain-residual adapter (DRA) module leads to state-of-the-art performance (while being $\sim\!$ 9$\times$ more parameter-efficient) on MD. Our extensive empirical findings set strong baselines and call for rethinking the current design of PEFT methods for FSC.
Bluetooth and WiFi Dataset for Real World RF Fingerprinting of Commercial Devices
Mar 15, 2023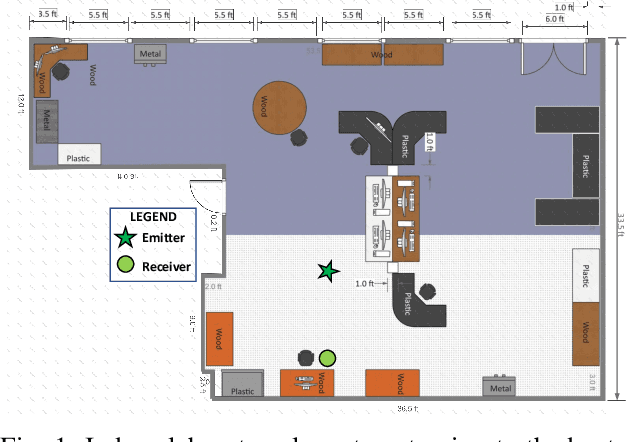
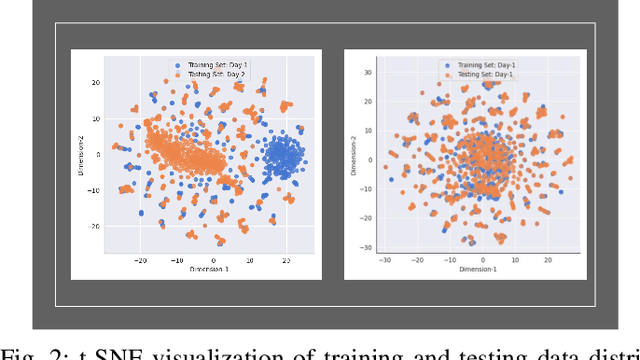
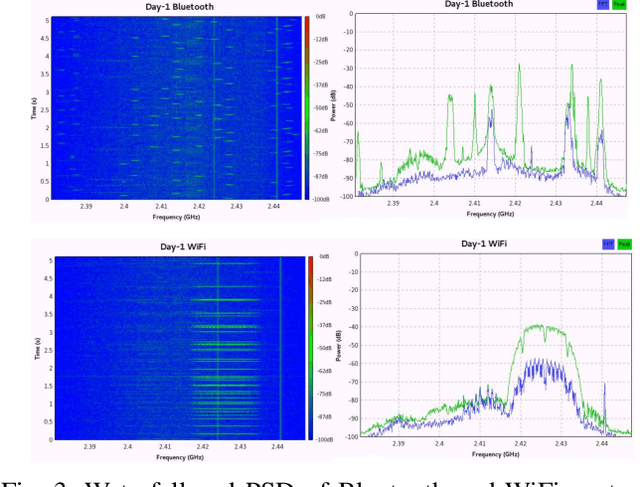
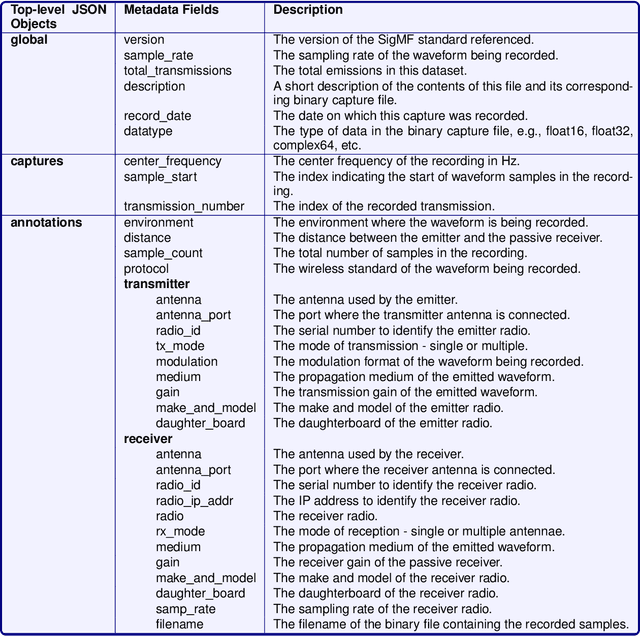
RF fingerprinting is emerging as a physical layer security scheme to identify illegitimate and/or unauthorized emitters sharing the RF spectrum. However, due to the lack of publicly accessible real-world datasets, most research focuses on generating synthetic waveforms with software-defined radios (SDRs) which are not suited for practical deployment settings. On other hand, the limited datasets that are available focus only on chipsets that generate only one kind of waveform. Commercial off-the-shelf (COTS) combo chipsets that support two wireless standards (for example WiFi and Bluetooth) over a shared dual-band antenna such as those found in laptops, adapters, wireless chargers, Raspberry Pis, among others are becoming ubiquitous in the IoT realm. Hence, to keep up with the modern IoT environment, there is a pressing need for real-world open datasets capturing emissions from these combo chipsets transmitting heterogeneous communication protocols. To this end, we capture the first known emissions from the COTS IoT chipsets transmitting WiFi and Bluetooth under two different time frames. The different time frames are essential to rigorously evaluate the generalization capability of the models. To ensure widespread use, each capture within the comprehensive 72 GB dataset is long enough (40 MSamples) to support diverse input tensor lengths and formats. Finally, the dataset also comprises emissions at varying signal powers to account for the feeble to high signal strength emissions as encountered in a real-world setting.
BundleSDF: Neural 6-DoF Tracking and 3D Reconstruction of Unknown Objects
Mar 24, 2023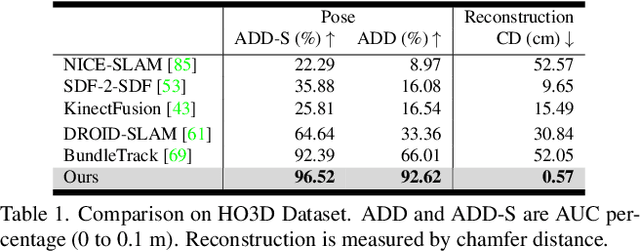
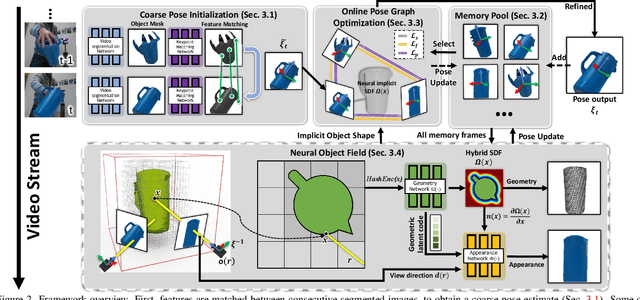
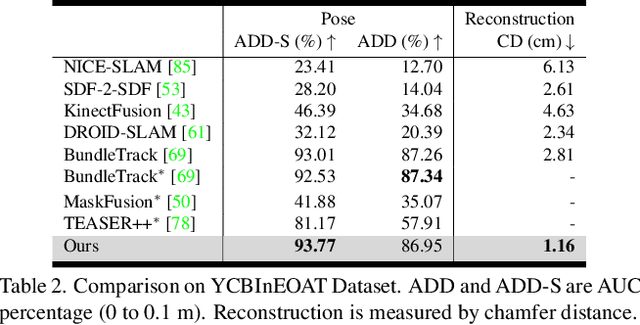
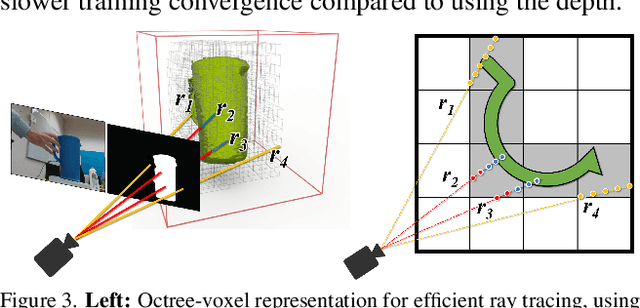
We present a near real-time method for 6-DoF tracking of an unknown object from a monocular RGBD video sequence, while simultaneously performing neural 3D reconstruction of the object. Our method works for arbitrary rigid objects, even when visual texture is largely absent. The object is assumed to be segmented in the first frame only. No additional information is required, and no assumption is made about the interaction agent. Key to our method is a Neural Object Field that is learned concurrently with a pose graph optimization process in order to robustly accumulate information into a consistent 3D representation capturing both geometry and appearance. A dynamic pool of posed memory frames is automatically maintained to facilitate communication between these threads. Our approach handles challenging sequences with large pose changes, partial and full occlusion, untextured surfaces, and specular highlights. We show results on HO3D, YCBInEOAT, and BEHAVE datasets, demonstrating that our method significantly outperforms existing approaches. Project page: https://bundlesdf.github.io
Cross-Attention is all you need: Real-Time Streaming Transformers for Personalised Speech Enhancement
Nov 08, 2022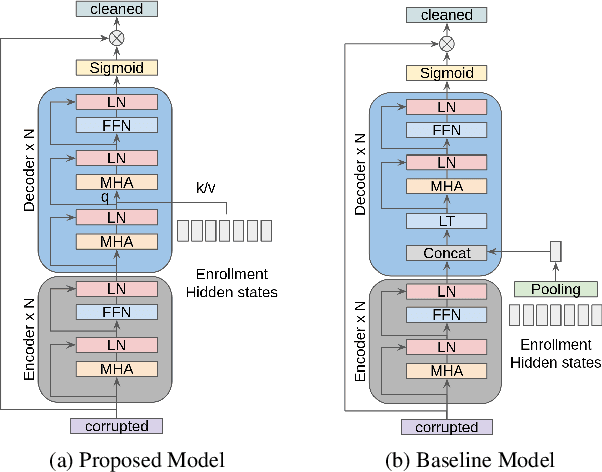
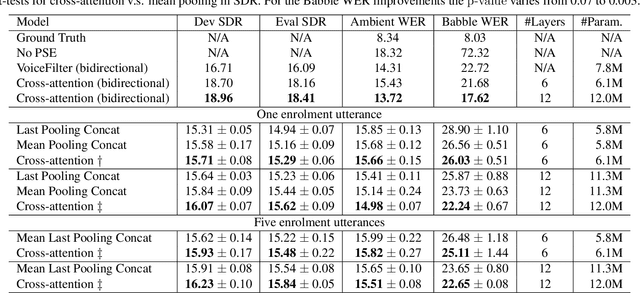
Personalised speech enhancement (PSE), which extracts only the speech of a target user and removes everything else from a recorded audio clip, can potentially improve users' experiences of audio AI modules deployed in the wild. To support a large variety of downstream audio tasks, such as real-time ASR and audio-call enhancement, a PSE solution should operate in a streaming mode, i.e., input audio cleaning should happen in real-time with a small latency and real-time factor. Personalisation is typically achieved by extracting a target speaker's voice profile from an enrolment audio, in the form of a static embedding vector, and then using it to condition the output of a PSE model. However, a fixed target speaker embedding may not be optimal under all conditions. In this work, we present a streaming Transformer-based PSE model and propose a novel cross-attention approach that gives adaptive target speaker representations. We present extensive experiments and show that our proposed cross-attention approach outperforms competitive baselines consistently, even when our model is only approximately half the size.