 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
GlucoSynth: Generating Differentially-Private Synthetic Glucose Traces
Mar 02, 2023
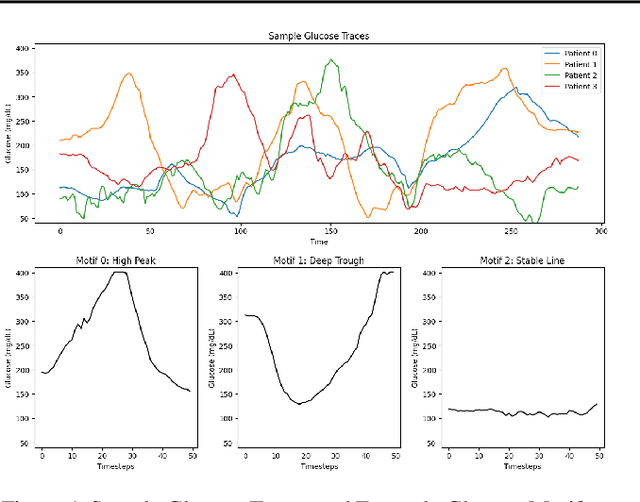
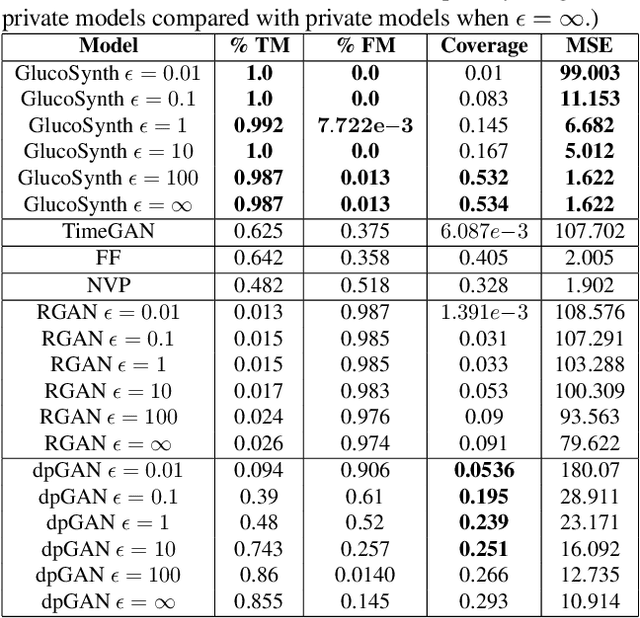
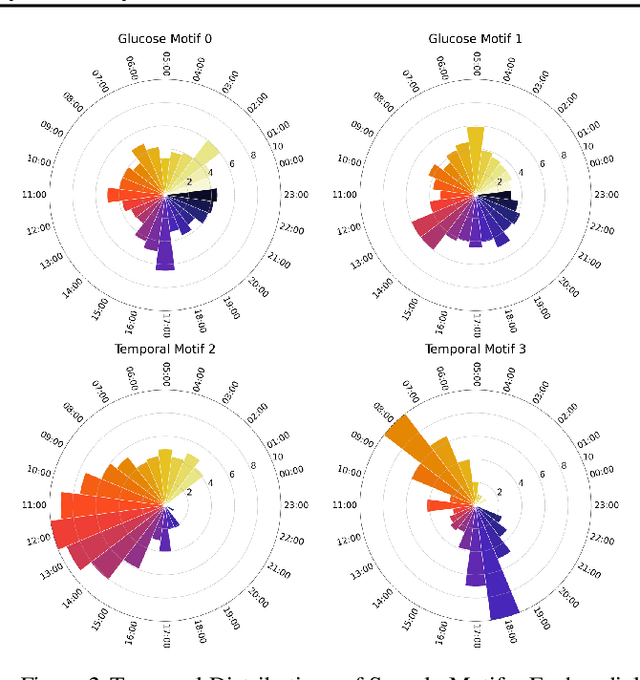
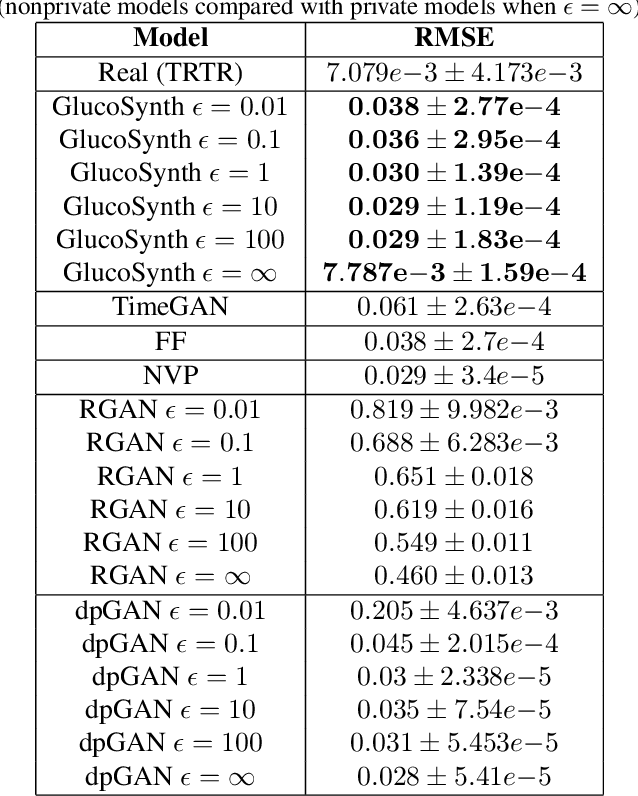
In this paper we focus on the problem of generating high-quality, private synthetic glucose traces, a task generalizable to many other time series sources. Existing methods for time series data synthesis, such as those using Generative Adversarial Networks (GANs), are not able to capture the innate characteristics of glucose data and, in terms of privacy, either do not include any formal privacy guarantees or, in order to uphold a strong formal privacy guarantee, severely degrade the utility of the synthetic data. Therefore, in this paper we present GlucoSynth, a novel privacy-preserving GAN framework to generate synthetic glucose traces. The core intuition in our approach is to conserve relationships amongst motifs (glucose events) within the traces, in addition to typical temporal dynamics. Moreover, we integrate differential privacy into the framework to provide strong formal privacy guarantees. Finally, we provide a comprehensive evaluation on the real-world utility of the data using 1.2 million glucose traces
SemDeDup: Data-efficient learning at web-scale through semantic deduplication
Mar 18, 2023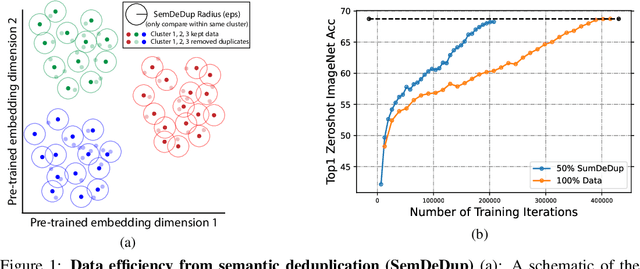
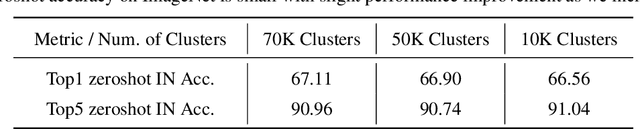


Progress in machine learning has been driven in large part by massive increases in data. However, large web-scale datasets such as LAION are largely uncurated beyond searches for exact duplicates, potentially leaving much redundancy. Here, we introduce SemDeDup, a method which leverages embeddings from pre-trained models to identify and remove semantic duplicates: data pairs which are semantically similar, but not exactly identical. Removing semantic duplicates preserves performance and speeds up learning. Analyzing a subset of LAION, we show that SemDeDup can remove 50% of the data with minimal performance loss, effectively halving training time. Moreover, performance increases out of distribution. Also, analyzing language models trained on C4, a partially curated dataset, we show that SemDeDup improves over prior approaches while providing efficiency gains. SemDeDup provides an example of how simple ways of leveraging quality embeddings can be used to make models learn faster with less data.
i2LQR: Iterative LQR for Iterative Tasks in Dynamic Environments
Mar 17, 2023
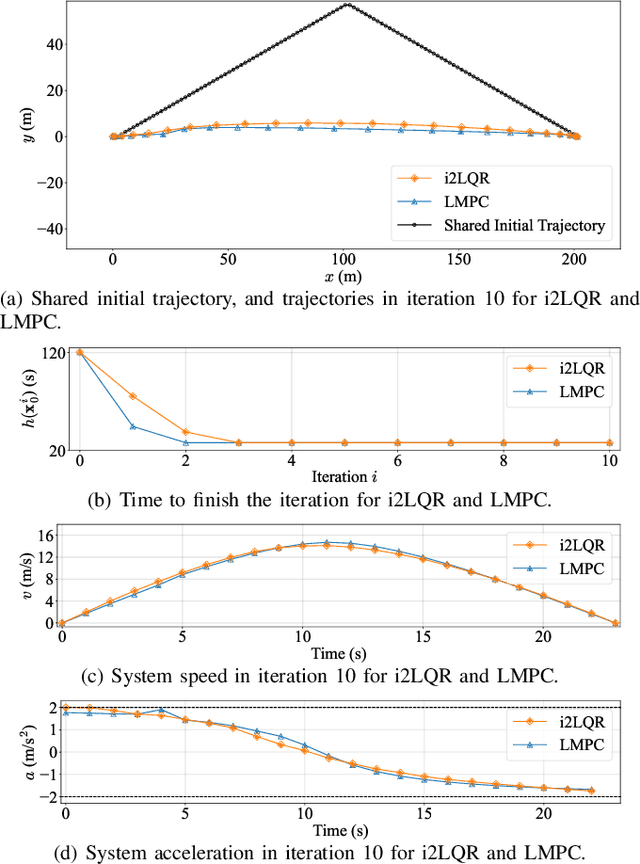
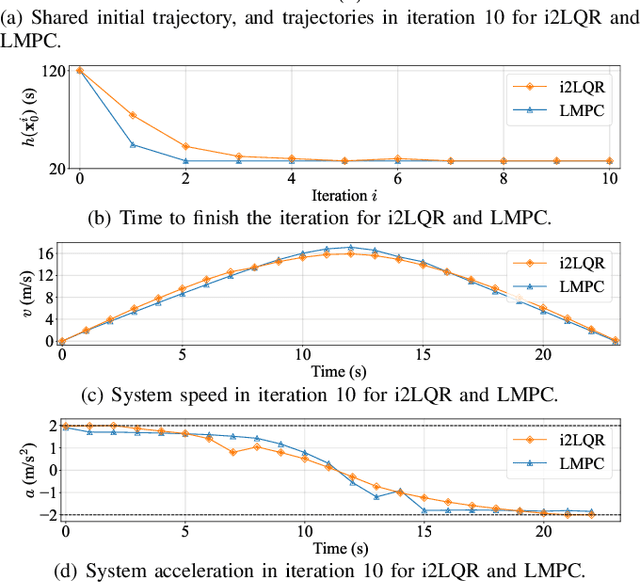
This work introduces a novel control strategy called Iterative Linear Quadratic Regulator for Iterative Tasks (i2LQR), which aims to pursue optimal performance for iterative tasks in a dynamic environment. The proposed algorithm is reference-free and utilizes historical data from previous iterations to enhance the performance of the autonomous system. Unlike existing algorithms, the i2LQR computes the optimal solution in an iterative manner at each timestamp, rendering it well-suited for iterative tasks with changing constraints at different iterations. To evaluate the performance of the proposed algorithm, we conduct numerical simulations for an iterative task aimed at minimizing completion time. The results show that i2LQR achieves the optimal performance as the state-of-the-art algorithm in static environments, and outperforms the state-of-the-art algorithm in dynamic environments with both static and dynamics obstacles.
A Survey on Orthogonal Time Frequency Space: New Delay Doppler Communications Paradigm in 6G era
Nov 23, 2022
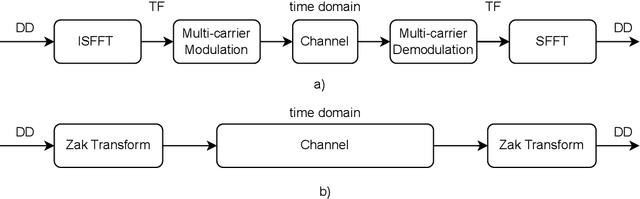
In 6G era, the space-air-ground integrated networks (SAGIN) are expected to provide global coverage and thus are required to support a wide range of emerging applications in hostile environments with high-mobility. In such scenarios, conventional orthogonal frequency division multiplexing (OFDM) modulation, which has been widely deployed in the cellular and Wi-Fi communications systems, will suffer from performance degradation due to high Doppler shift. To address this challenge, a new two-dimensional (2D) modulation scheme referred to as orthogonal time frequency space (OTFS) was proposed and has been recognized as an enabling technology for future high-mobility scenarios. In particular, OTFS modulates information in the delay-Doppler (DD) domain rather than the time-frequency (TF) domain for OFDM, providing the benefits of Doppler-resilience and delay-resilience, low signaling latency, low peak-to-average ratio (PAPR), and low-complexity implementation. Recent researches also show that the direct interaction of information and physical world in the DD domain makes OTFS an promising waveform for realizing integrated sensing and communications (ISAC). In this article, we will present a comprehensive survey of OTFS technology in 6G era, including the fundamentals, recent advances, and future works. Our aim is that this article could provide valuable references for all researchers working in the area of OTFS.
Deep neural operator for learning transient response of interpenetrating phase composites subject to dynamic loading
Mar 30, 2023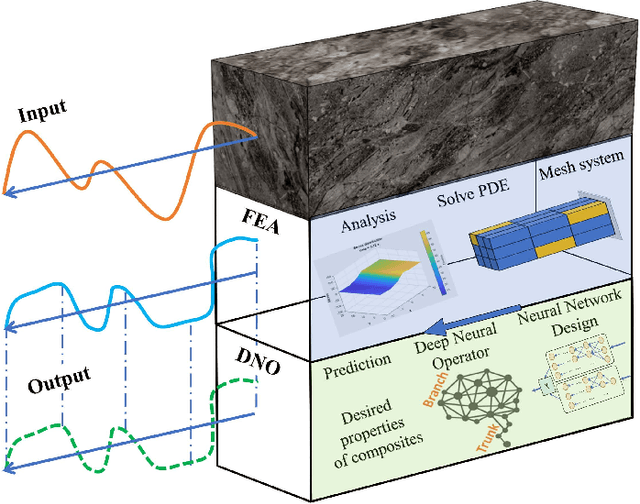
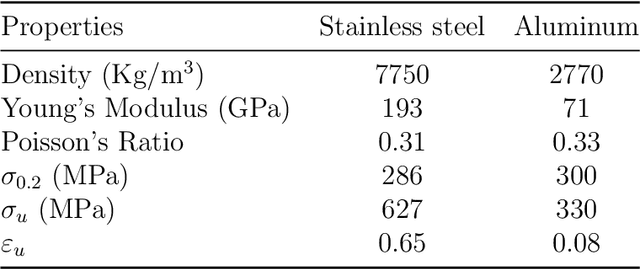
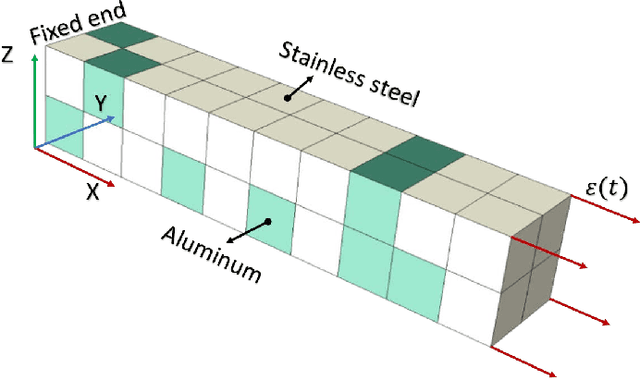
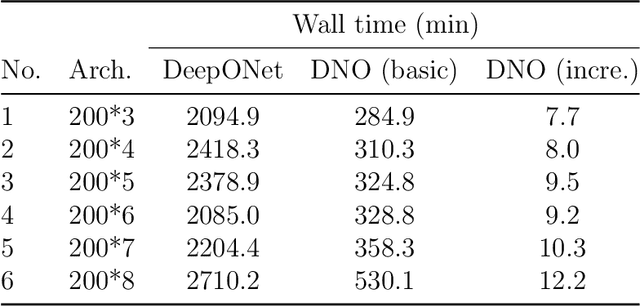
Additive manufacturing has been recognized as an industrial technological revolution for manufacturing, which allows fabrication of materials with complex three-dimensional (3D) structures directly from computer-aided design models. The mechanical properties of interpenetrating phase composites (IPCs), especially response to dynamic loading, highly depend on their 3D structures. In general, for each specified structural design, it could take hours or days to perform either finite element analysis (FEA) or experiments to test the mechanical response of IPCs to a given dynamic load. To accelerate the physics-based prediction of mechanical properties of IPCs for various structural designs, we employ a deep neural operator (DNO) to learn the transient response of IPCs under dynamic loading as surrogate of physics-based FEA models. We consider a 3D IPC beam formed by two metals with a ratio of Young's modulus of 2.7, wherein random blocks of constituent materials are used to demonstrate the generality and robustness of the DNO model. To obtain FEA results of IPC properties, 5,000 random time-dependent strain loads generated by a Gaussian process kennel are applied to the 3D IPC beam, and the reaction forces and stress fields inside the IPC beam under various loading are collected. Subsequently, the DNO model is trained using an incremental learning method with sequence-to-sequence training implemented in JAX, leading to a 100X speedup compared to widely used vanilla deep operator network models. After an offline training, the DNO model can act as surrogate of physics-based FEA to predict the transient mechanical response in terms of reaction force and stress distribution of the IPCs to various strain loads in one second at an accuracy of 98%. Also, the learned operator is able to provide extended prediction of the IPC beam subject to longer random strain loads at a reasonably well accuracy.
Q-learning Based System for Path Planning with UAV Swarms in Obstacle Environments
Mar 30, 2023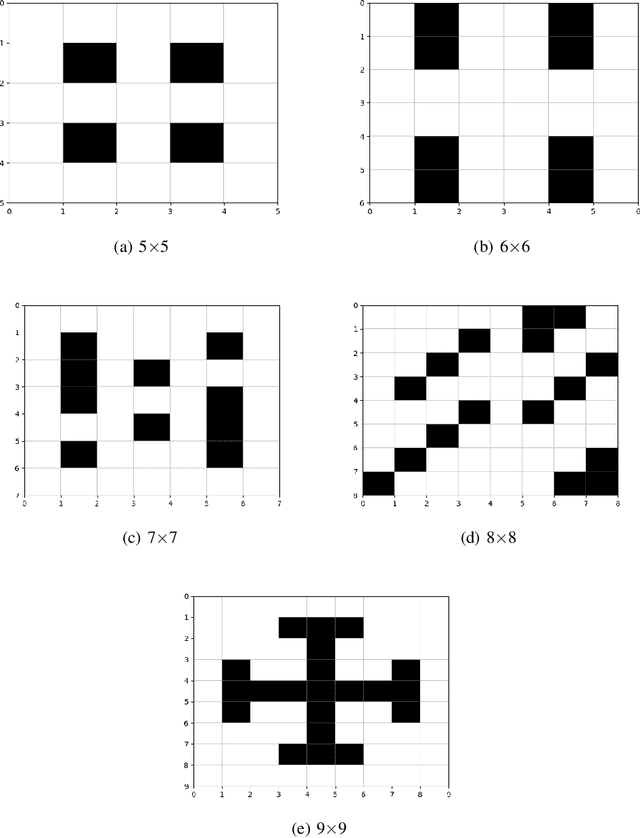

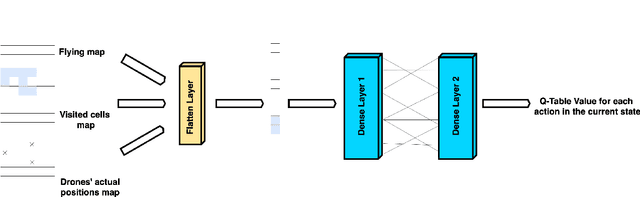
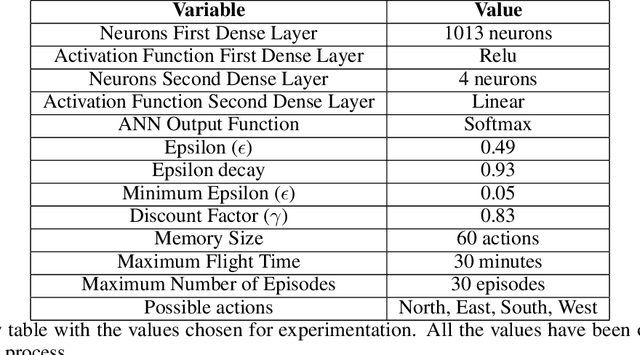
Path Planning methods for autonomous control of Unmanned Aerial Vehicle (UAV) swarms are on the rise because of all the advantages they bring. There are more and more scenarios where autonomous control of multiple UAVs is required. Most of these scenarios present a large number of obstacles, such as power lines or trees. If all UAVs can be operated autonomously, personnel expenses can be decreased. In addition, if their flight paths are optimal, energy consumption is reduced. This ensures that more battery time is left for other operations. In this paper, a Reinforcement Learning based system is proposed for solving this problem in environments with obstacles by making use of Q-Learning. This method allows a model, in this particular case an Artificial Neural Network, to self-adjust by learning from its mistakes and achievements. Regardless of the size of the map or the number of UAVs in the swarm, the goal of these paths is to ensure complete coverage of an area with fixed obstacles for tasks, like field prospecting. Setting goals or having any prior information aside from the provided map is not required. For experimentation, five maps of different sizes with different obstacles were used. The experiments were performed with different number of UAVs. For the calculation of the results, the number of actions taken by all UAVs to complete the task in each experiment is taken into account. The lower the number of actions, the shorter the path and the lower the energy consumption. The results are satisfactory, showing that the system obtains solutions in fewer movements the more UAVs there are. For a better presentation, these results have been compared to another state-of-the-art approach.
SynthVSR: Scaling Up Visual Speech Recognition With Synthetic Supervision
Mar 30, 2023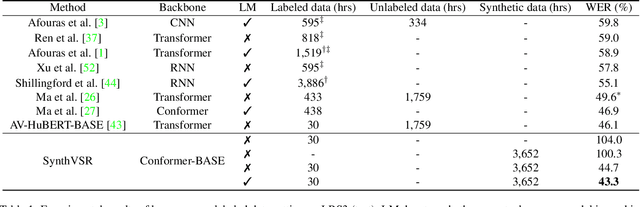
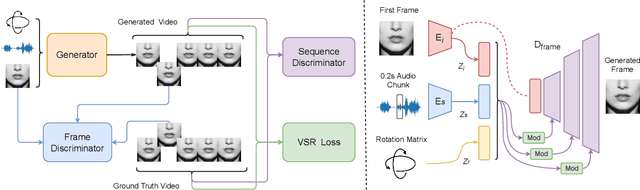
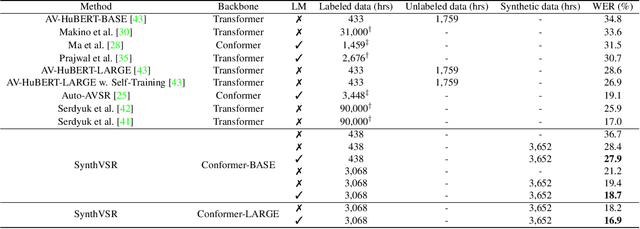

Recently reported state-of-the-art results in visual speech recognition (VSR) often rely on increasingly large amounts of video data, while the publicly available transcribed video datasets are limited in size. In this paper, for the first time, we study the potential of leveraging synthetic visual data for VSR. Our method, termed SynthVSR, substantially improves the performance of VSR systems with synthetic lip movements. The key idea behind SynthVSR is to leverage a speech-driven lip animation model that generates lip movements conditioned on the input speech. The speech-driven lip animation model is trained on an unlabeled audio-visual dataset and could be further optimized towards a pre-trained VSR model when labeled videos are available. As plenty of transcribed acoustic data and face images are available, we are able to generate large-scale synthetic data using the proposed lip animation model for semi-supervised VSR training. We evaluate the performance of our approach on the largest public VSR benchmark - Lip Reading Sentences 3 (LRS3). SynthVSR achieves a WER of 43.3% with only 30 hours of real labeled data, outperforming off-the-shelf approaches using thousands of hours of video. The WER is further reduced to 27.9% when using all 438 hours of labeled data from LRS3, which is on par with the state-of-the-art self-supervised AV-HuBERT method. Furthermore, when combined with large-scale pseudo-labeled audio-visual data SynthVSR yields a new state-of-the-art VSR WER of 16.9% using publicly available data only, surpassing the recent state-of-the-art approaches trained with 29 times more non-public machine-transcribed video data (90,000 hours). Finally, we perform extensive ablation studies to understand the effect of each component in our proposed method.
CAM++: A Fast and Efficient Network For Speaker Verification Using Context-Aware Masking
Mar 01, 2023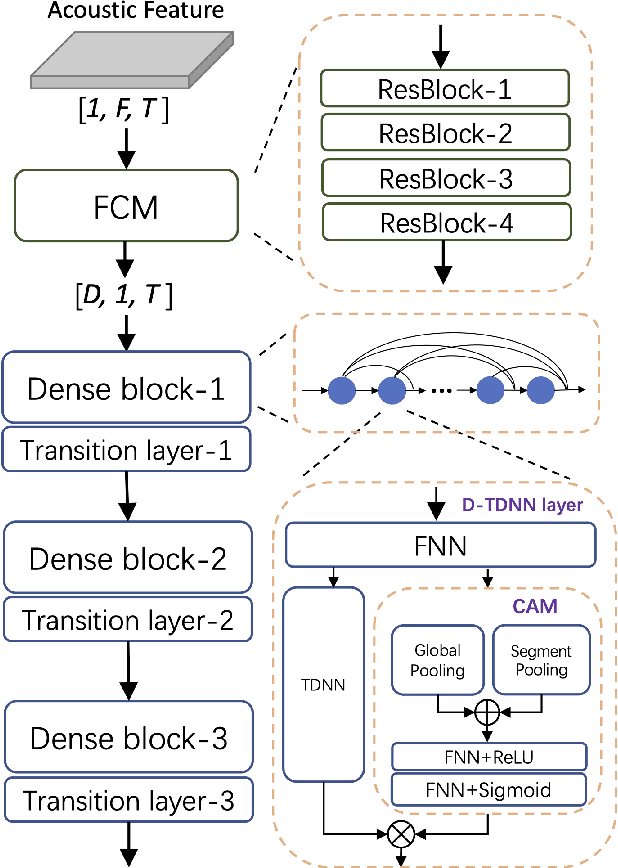
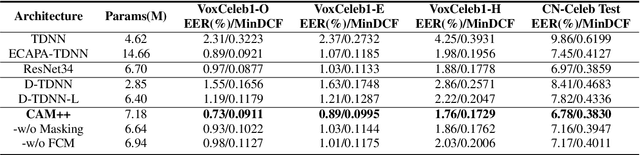
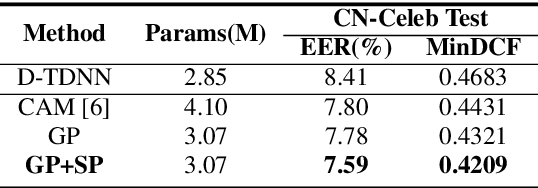

Time delay neural network (TDNN) has been proven to be efficient in learning discriminative speaker embeddings. One of its successful variant, ECAPA-TDNN, achieved state-of-the-art performance on speaker verification tasks at the cost of much higher computational complexity and slower inference speed. This makes it inadequate for scenarios with demanding inference rate and limited computational resources. We are thus interested in finding an architecture that can achieve the performance of ECAPA-TDNN and the efficiency of vanilla TDNN. In this paper, we propose an efficient network based on context-aware masking, namely CAM++, which uses densely connected time delay neural network (D-TDNN) as backbone and adopts a novel multi-granularity pooling to capture contextual information at different levels. Extensive experiments on two public benchmarks, VoxCeleb and CN-Celeb, demonstrate that the proposed architecture outperforms other mainstream speaker verification systems with lower computational cost and faster inference speed.
VLSNR:Vision-Linguistics Coordination Time Sequence-aware News Recommendation
Oct 06, 2022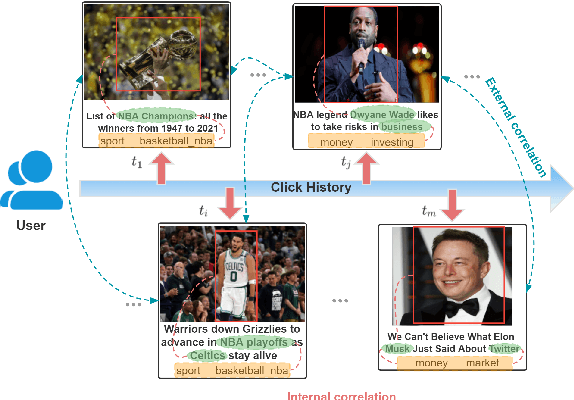

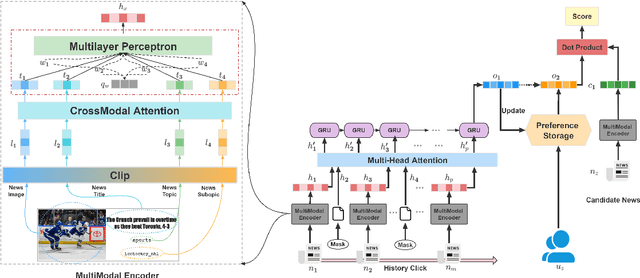
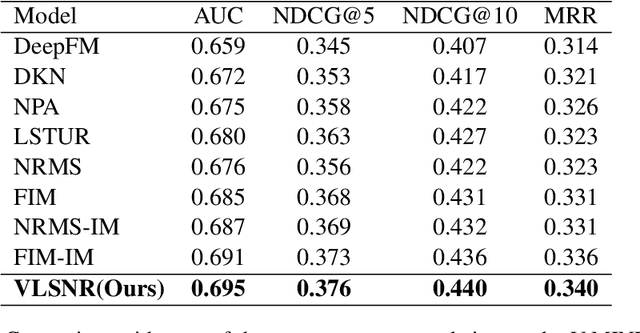
News representation and user-oriented modeling are both essential for news recommendation. Most existing methods are based on textual information but ignore the visual information and users' dynamic interests. However, compared to textual only content, multimodal semantics is beneficial for enhancing the comprehension of users' temporal and long-lasting interests. In our work, we propose a vision-linguistics coordinate time sequence news recommendation. Firstly, a pretrained multimodal encoder is applied to embed images and texts into the same feature space. Then the self-attention network is used to learn the chronological sequence. Additionally, an attentional GRU network is proposed to model user preference in terms of time adequately. Finally, the click history and user representation are embedded to calculate the ranking scores for candidate news. Furthermore, we also construct a large scale multimodal news recommendation dataset V-MIND. Experimental results show that our model outperforms baselines and achieves SOTA on our independently constructed dataset.
Real-Time Visual Feedback to Guide Benchmark Creation: A Human-and-Metric-in-the-Loop Workflow
Feb 09, 2023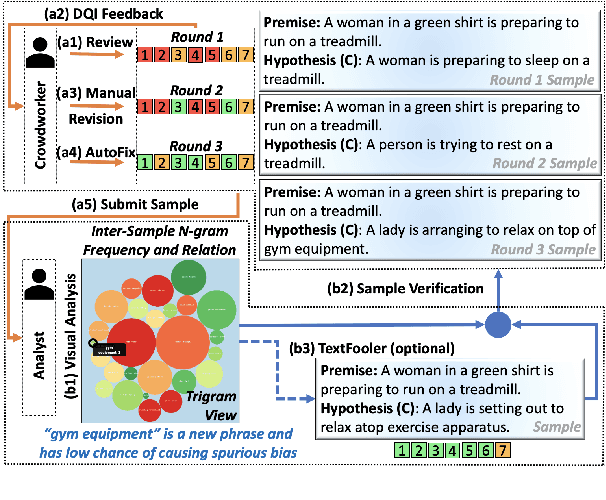

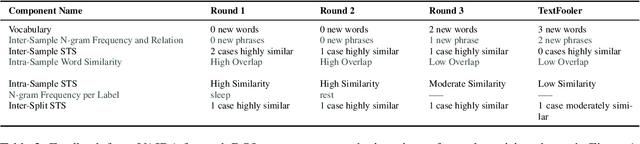
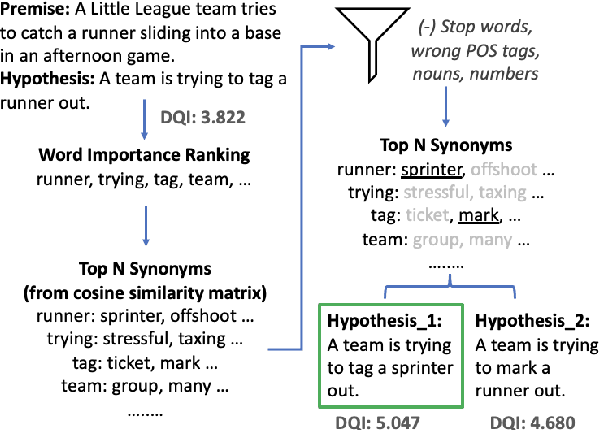
Recent research has shown that language models exploit `artifacts' in benchmarks to solve tasks, rather than truly learning them, leading to inflated model performance. In pursuit of creating better benchmarks, we propose VAIDA, a novel benchmark creation paradigm for NLP, that focuses on guiding crowdworkers, an under-explored facet of addressing benchmark idiosyncrasies. VAIDA facilitates sample correction by providing realtime visual feedback and recommendations to improve sample quality. Our approach is domain, model, task, and metric agnostic, and constitutes a paradigm shift for robust, validated, and dynamic benchmark creation via human-and-metric-in-the-loop workflows. We evaluate via expert review and a user study with NASA TLX. We find that VAIDA decreases effort, frustration, mental, and temporal demands of crowdworkers and analysts, simultaneously increasing the performance of both user groups with a 45.8% decrease in the level of artifacts in created samples. As a by product of our user study, we observe that created samples are adversarial across models, leading to decreases of 31.3% (BERT), 22.5% (RoBERTa), 14.98% (GPT-3 fewshot) in performance.