 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
GANTEE: Generative Adversatial Network for Taxonomy Entering Evaluation
Mar 25, 2023
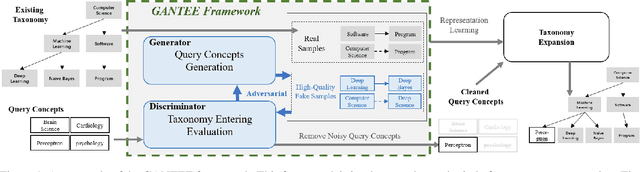
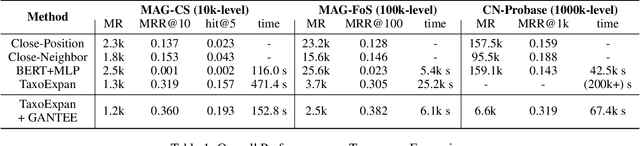
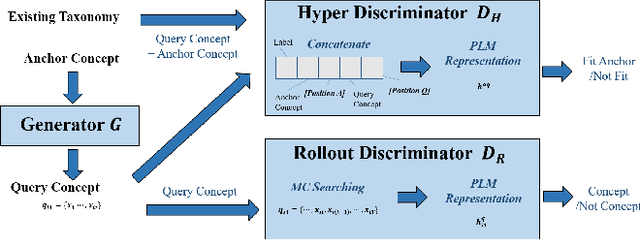
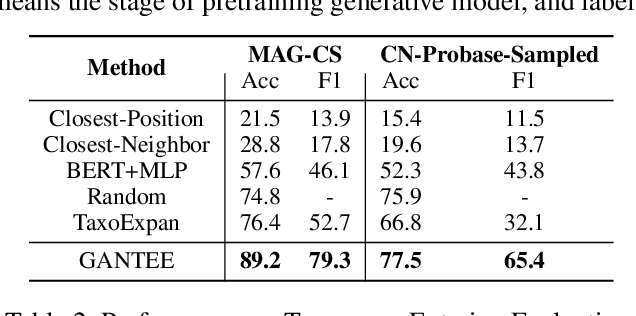
Taxonomy is formulated as directed acyclic concepts graphs or trees that support many downstream tasks. Many new coming concepts need to be added to an existing taxonomy. The traditional taxonomy expansion task aims only at finding the best position for new coming concepts in the existing taxonomy. However, they have two drawbacks when being applied to the real-scenarios. The previous methods suffer from low-efficiency since they waste much time when most of the new coming concepts are indeed noisy concepts. They also suffer from low-effectiveness since they collect training samples only from the existing taxonomy, which limits the ability of the model to mine more hypernym-hyponym relationships among real concepts. This paper proposes a pluggable framework called Generative Adversarial Network for Taxonomy Entering Evaluation (GANTEE) to alleviate these drawbacks. A generative adversarial network is designed in this framework by discriminative models to alleviate the first drawback and the generative model to alleviate the second drawback. Two discriminators are used in GANTEE to provide long-term and short-term rewards, respectively. Moreover, to further improve the efficiency, pre-trained language models are used to retrieve the representation of the concepts quickly. The experiments on three real-world large-scale datasets with two different languages show that GANTEE improves the performance of the existing taxonomy expansion methods in both effectiveness and efficiency.
Autoregressive Conditional Neural Processes
Mar 25, 2023

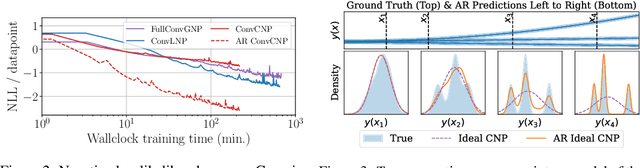
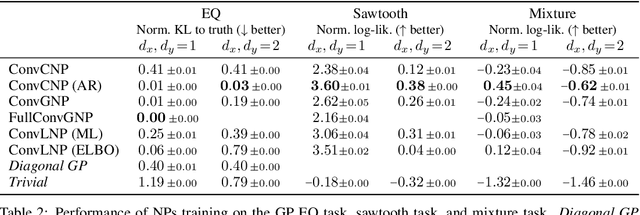
Conditional neural processes (CNPs; Garnelo et al., 2018a) are attractive meta-learning models which produce well-calibrated predictions and are trainable via a simple maximum likelihood procedure. Although CNPs have many advantages, they are unable to model dependencies in their predictions. Various works propose solutions to this, but these come at the cost of either requiring approximate inference or being limited to Gaussian predictions. In this work, we instead propose to change how CNPs are deployed at test time, without any modifications to the model or training procedure. Instead of making predictions independently for every target point, we autoregressively define a joint predictive distribution using the chain rule of probability, taking inspiration from the neural autoregressive density estimator (NADE) literature. We show that this simple procedure allows factorised Gaussian CNPs to model highly dependent, non-Gaussian predictive distributions. Perhaps surprisingly, in an extensive range of tasks with synthetic and real data, we show that CNPs in autoregressive (AR) mode not only significantly outperform non-AR CNPs, but are also competitive with more sophisticated models that are significantly more computationally expensive and challenging to train. This performance is remarkable given that AR CNPs are not trained to model joint dependencies. Our work provides an example of how ideas from neural distribution estimation can benefit neural processes, and motivates research into the AR deployment of other neural process models.
Many learning agents interacting with an agent-based market model
Mar 25, 2023
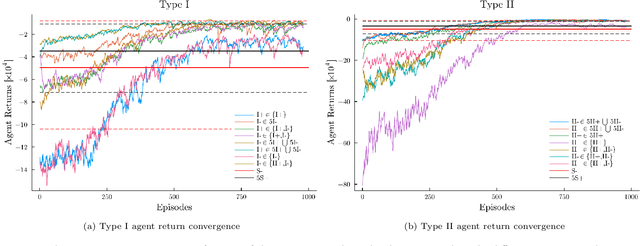
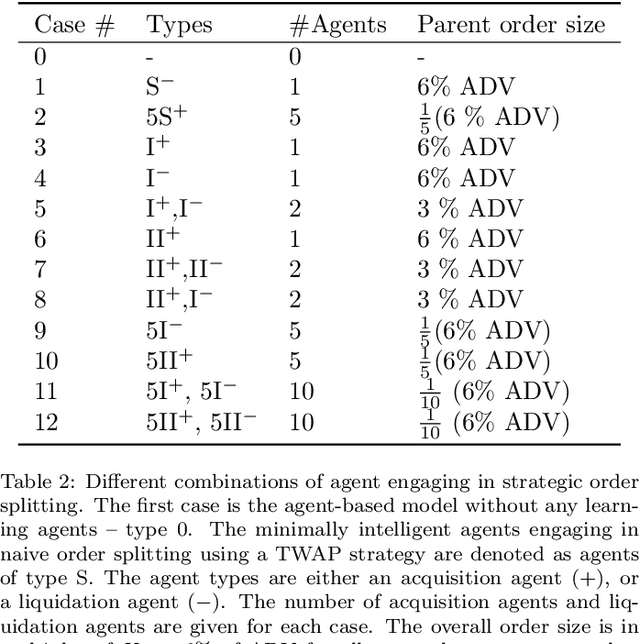
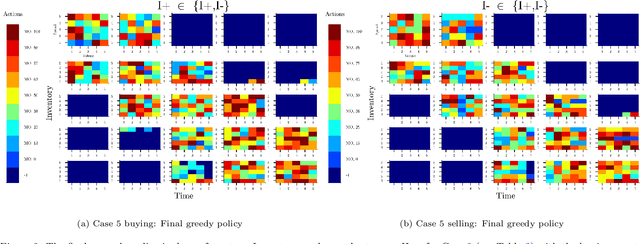
We consider the dynamics and the interactions of multiple reinforcement learning optimal execution trading agents interacting with a reactive Agent-Based Model (ABM) of a financial market in event time. The model represents a market ecology with 3-trophic levels represented by: optimal execution learning agents, minimally intelligent liquidity takers, and fast electronic liquidity providers. The optimal execution agent classes include buying and selling agents that can either use a combination of limit orders and market orders, or only trade using market orders. The reward function explicitly balances trade execution slippage against the penalty of not executing the order timeously. This work demonstrates how multiple competing learning agents impact a minimally intelligent market simulation as functions of the number of agents, the size of agents' initial orders, and the state spaces used for learning. We use phase space plots to examine the dynamics of the ABM, when various specifications of learning agents are included. Further, we examine whether the inclusion of optimal execution agents that can learn is able to produce dynamics with the same complexity as empirical data. We find that the inclusion of optimal execution agents changes the stylised facts produced by ABM to conform more with empirical data, and are a necessary inclusion for ABMs investigating market micro-structure. However, including execution agents to chartist-fundamentalist-noise ABMs is insufficient to recover the complexity observed in empirical data.
Dealing With Heterogeneous 3D MR Knee Images: A Federated Few-Shot Learning Method With Dual Knowledge Distillation
Mar 25, 2023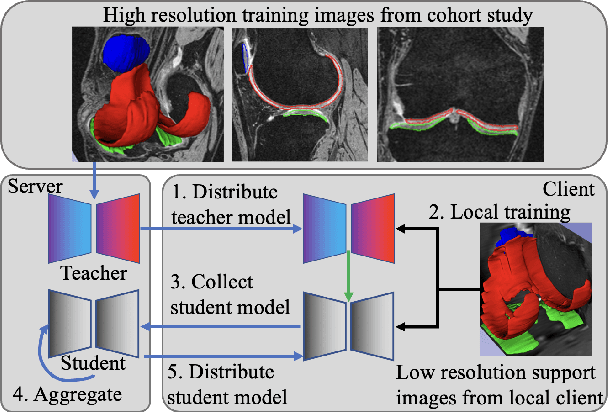

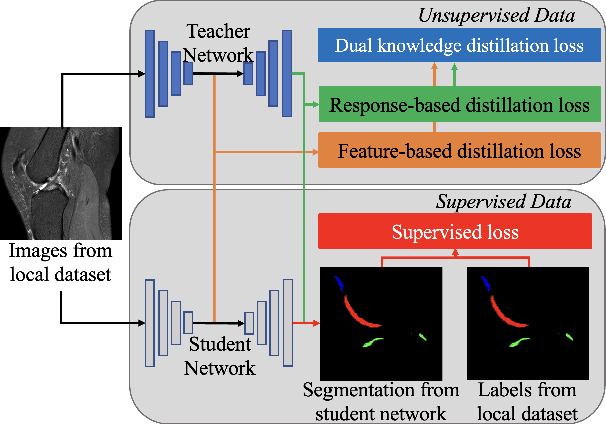
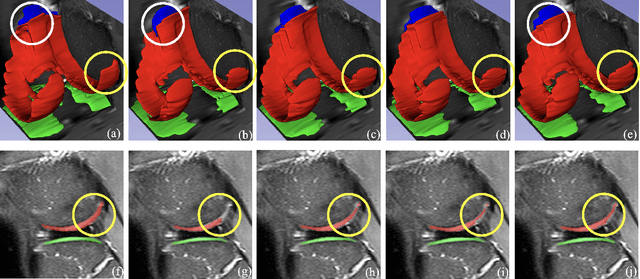
Federated Learning has gained popularity among medical institutions since it enables collaborative training between clients (e.g., hospitals) without aggregating data. However, due to the high cost associated with creating annotations, especially for large 3D image datasets, clinical institutions do not have enough supervised data for training locally. Thus, the performance of the collaborative model is subpar under limited supervision. On the other hand, large institutions have the resources to compile data repositories with high-resolution images and labels. Therefore, individual clients can utilize the knowledge acquired in the public data repositories to mitigate the shortage of private annotated images. In this paper, we propose a federated few-shot learning method with dual knowledge distillation. This method allows joint training with limited annotations across clients without jeopardizing privacy. The supervised learning of the proposed method extracts features from limited labeled data in each client, while the unsupervised data is used to distill both feature and response-based knowledge from a national data repository to further improve the accuracy of the collaborative model and reduce the communication cost. Extensive evaluations are conducted on 3D magnetic resonance knee images from a private clinical dataset. Our proposed method shows superior performance and less training time than other semi-supervised federated learning methods. Codes and additional visualization results are available at https://github.com/hexiaoxiao-cs/fedml-knee.
Reconfigurable Intelligent Surface-Aided Full-Duplex mmWave MIMO: Channel Estimation, Passive and Hybrid Beamforming
Mar 25, 2023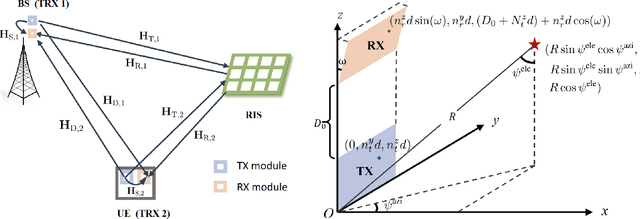
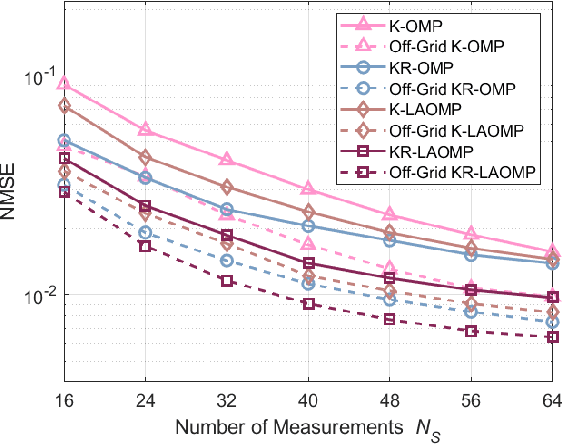
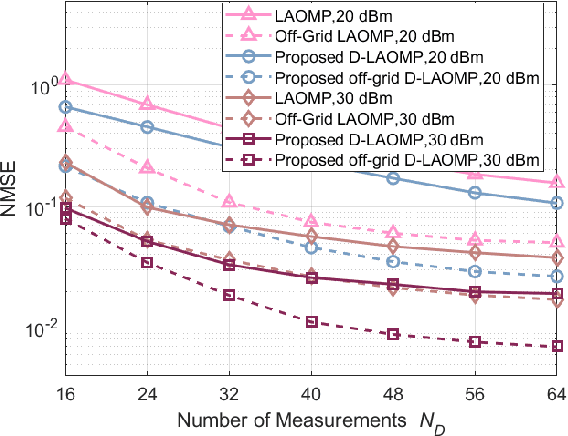
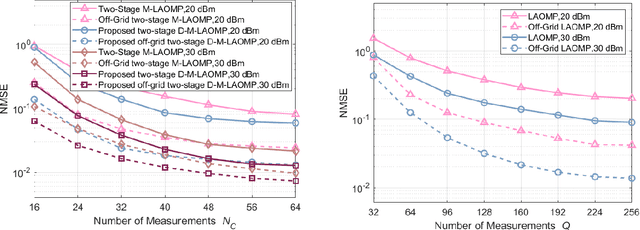
Millimeter wave (mmWave) full-duplex (FD) is a promising technique for improving capacity by maximizing the utilization of both time and the rich mmWave frequency resources. Still, it has restrictions due to FD self-interference (SI) and mmWave's limited coverage. Therefore, this study dives into FD mmWave MIMO with the assistance of reconfigurable intelligent surfaces (RIS) for capacity improvement. First, we demonstrate the angular-domain reciprocity of FD antenna arrays under the far-field planar wavefront assumption. Accordingly, a strategy for joint downlink-uplink (DL-UL) channel estimation is presented. For estimating the SI channel, the direct channel, and the cascaded channel, the Khatri-Rao product-based compressive sensing (KR-CS), distributed CS (D-CS), and two-stage multiple measurement vector-based D-CS (M-D-CS) frameworks are proposed, respectively. Additionally, we propose a passive beamforming optimization solution based on the angular-domain cascaded channel. With hybrid beamforming architectures, a novel hybrid weighted minimum mean squared error method for SI cancellation (H-WMMSE-SIC) is proposed. Simulations have revealed that joint DL-UL processing significantly improves estimation performance in comparison to separate DL/UL channel estimation. Particularly, when the interference-to-noise ratio is less than 35 dB, our proposed H-WMMSE-SIC offers spectral efficiency performance comparable to fully-digital WMMSE-SIC. Finally, the computational complexity is analyzed for our proposed methods.
CAM++: A Fast and Efficient Network For Speaker Verification Using Context-Aware Masking
Mar 01, 2023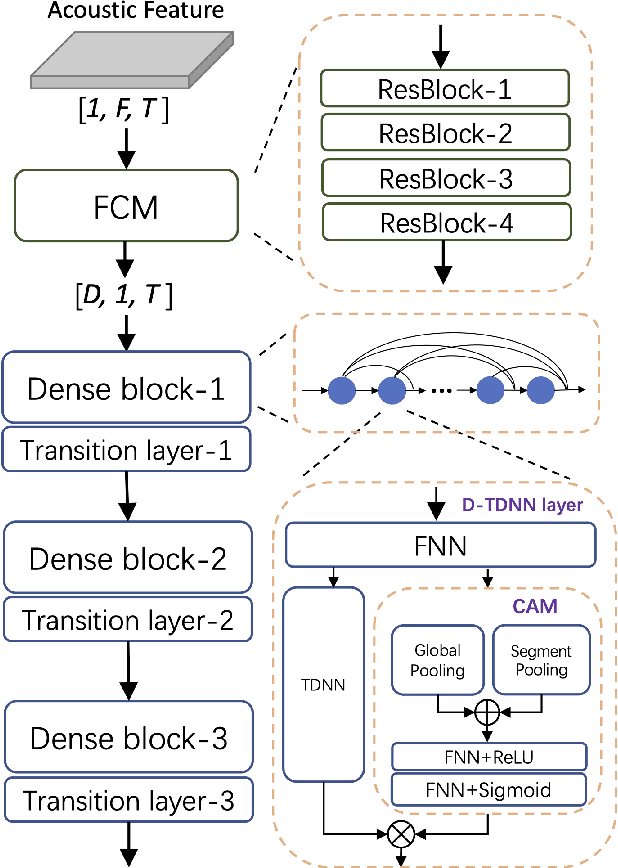
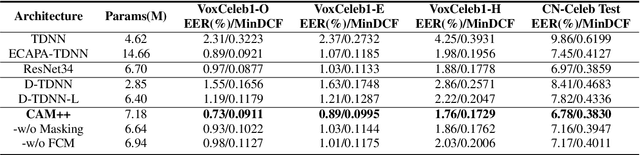
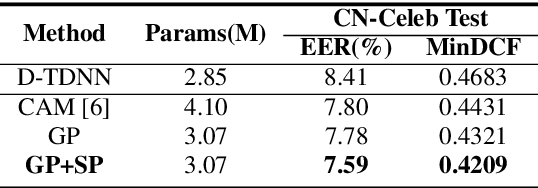

Time delay neural network (TDNN) has been proven to be efficient in learning discriminative speaker embeddings. One of its successful variant, ECAPA-TDNN, achieved state-of-the-art performance on speaker verification tasks at the cost of much higher computational complexity and slower inference speed. This makes it inadequate for scenarios with demanding inference rate and limited computational resources. We are thus interested in finding an architecture that can achieve the performance of ECAPA-TDNN and the efficiency of vanilla TDNN. In this paper, we propose an efficient network based on context-aware masking, namely CAM++, which uses densely connected time delay neural network (D-TDNN) as backbone and adopts a novel multi-granularity pooling to capture contextual information at different levels. Extensive experiments on two public benchmarks, VoxCeleb and CN-Celeb, demonstrate that the proposed architecture outperforms other mainstream speaker verification systems with lower computational cost and faster inference speed.
Reliable and Efficient Evaluation of Adversarial Robustness for Deep Hashing-Based Retrieval
Mar 22, 2023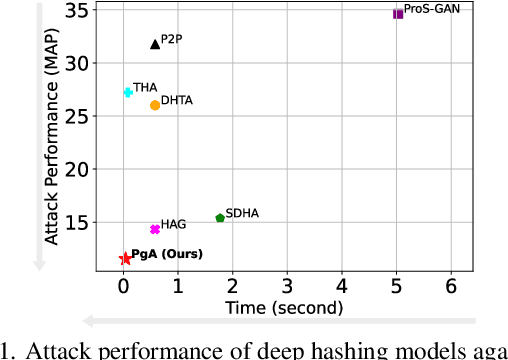
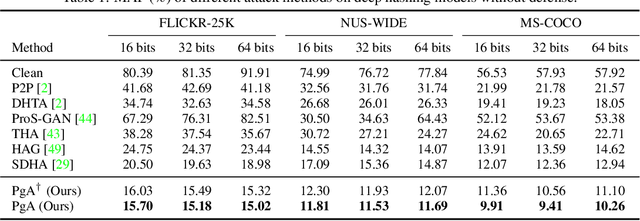
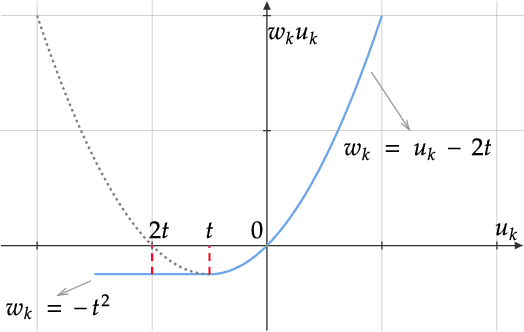
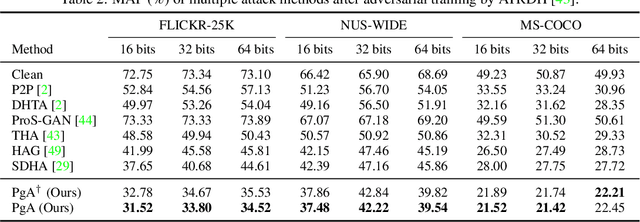
Deep hashing has been extensively applied to massive image retrieval due to its efficiency and effectiveness. Recently, several adversarial attacks have been presented to reveal the vulnerability of deep hashing models against adversarial examples. However, existing attack methods suffer from degraded performance or inefficiency because they underutilize the semantic relations between original samples or spend a lot of time learning these relations with a deep neural network. In this paper, we propose a novel Pharos-guided Attack, dubbed PgA, to evaluate the adversarial robustness of deep hashing networks reliably and efficiently. Specifically, we design pharos code to represent the semantics of the benign image, which preserves the similarity to semantically relevant samples and dissimilarity to irrelevant ones. It is proven that we can quickly calculate the pharos code via a simple math formula. Accordingly, PgA can directly conduct a reliable and efficient attack on deep hashing-based retrieval by maximizing the similarity between the hash code of the adversarial example and the pharos code. Extensive experiments on the benchmark datasets verify that the proposed algorithm outperforms the prior state-of-the-arts in both attack strength and speed.
Doppler-Division Multiplexing for MIMO OFDM Joint Sensing and Communications
Mar 22, 2023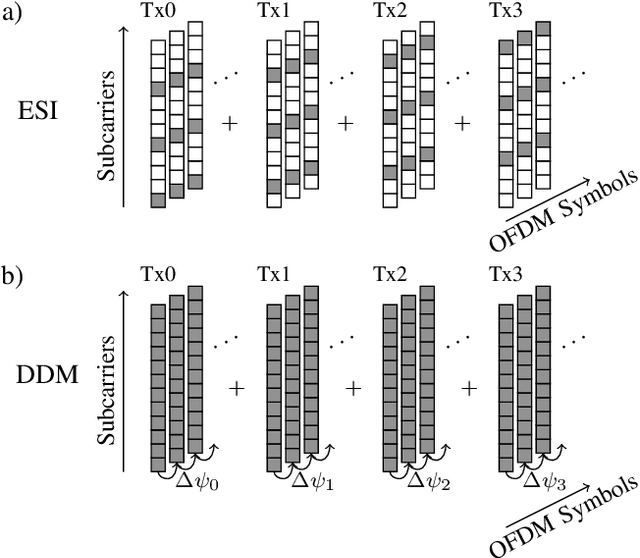
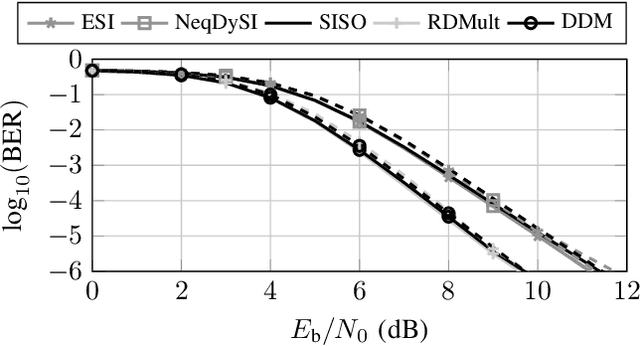
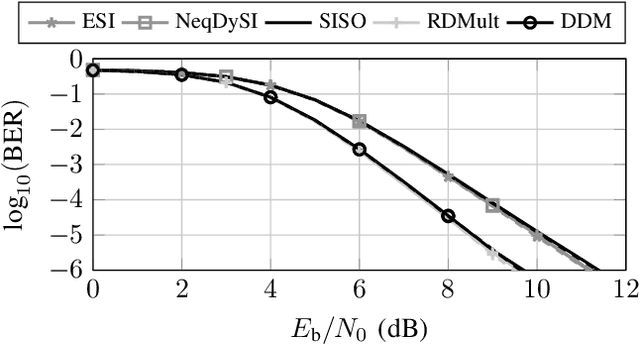
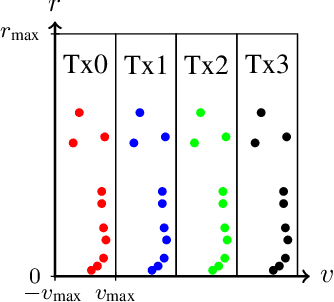
A promising waveform candidate for future joint sensing and communication systems is orthogonal frequencydivision multiplexing (OFDM). For such systems, supporting multiple transmit antennas requires multiplexing methods for the generation of orthogonal transmit signals, where equidistant subcarrier interleaving (ESI) is the most popular multiplexing method. In this work, we analyze a multiplexing method called Doppler-division multiplexing (DDM). This method applies a phase shift from OFDM symbol to OFDM symbol to separate signals transmitted by different Tx antennas along the velocity axis of the range-Doppler map. While general properties of DDM for the task of radar sensing are analyzed in this work, the main focus lies on the implications of DDM on the communication task. It will be shown that for DDM, the channels observed in the communication receiver are heavily timevarying, preventing any meaningful transmission of data when not taken into account. In this work, a communication system designed to combat these time-varying channels is proposed, which includes methods for data estimation, synchronization, and channel estimation. Bit error ratio (BER) simulations demonstrate the superiority of this communications system compared to a system utilizing ESI.
Resilient Output Consensus Control of Heterogeneous Multi-agent Systems against Byzantine Attacks: A Twin Layer Approach
Mar 22, 2023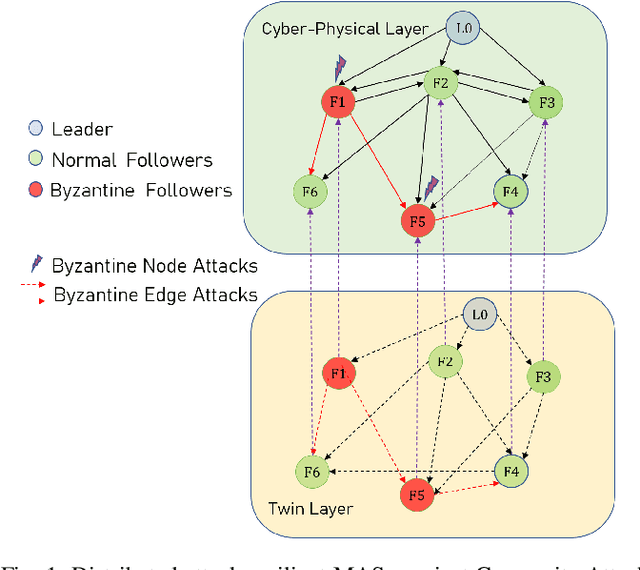
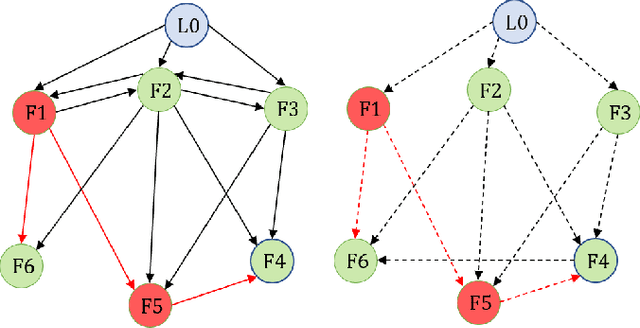
This paper studies the problem of cooperative control of heterogeneous multi-agent systems (MASs) against Byzantine attacks. The agent affected by Byzantine attacks sends different wrong values to all neighbors while applying wrong input signals for itself, which is aggressive and difficult to be defended. Inspired by the concept of Digital Twin, a new hierarchical protocol equipped with a virtual twin layer (TL) is proposed, which decouples the above problems into the defense scheme against Byzantine edge attacks on the TL and the defense scheme against Byzantine node attacks on the cyber-physical layer (CPL). On the TL, we propose a resilient topology reconfiguration strategy by adding a minimum number of key edges to improve network resilience. It is strictly proved that the control strategy is sufficient to achieve asymptotic consensus in finite time with the topology on the TL satisfying strongly $(2f+1)$-robustness. On the CPL, decentralized chattering-free controllers are proposed to guarantee the resilient output consensus for the heterogeneous MASs against Byzantine node attacks. Moreover, the obtained controller shows exponential convergence. The effectiveness and practicality of the theoretical results are verified by numerical examples.
Low Rank Optimization for Efficient Deep Learning: Making A Balance between Compact Architecture and Fast Training
Mar 22, 2023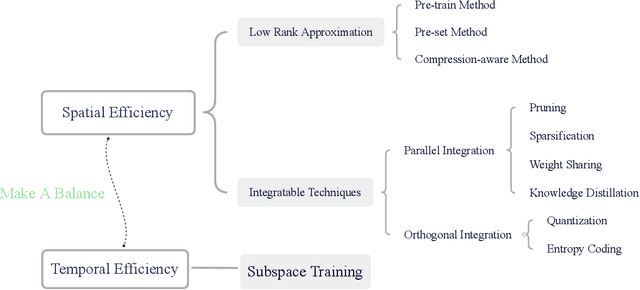
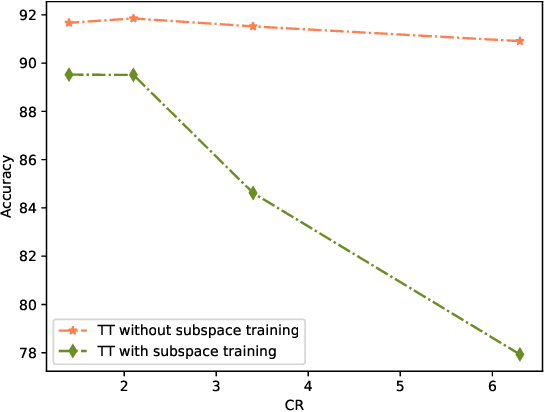
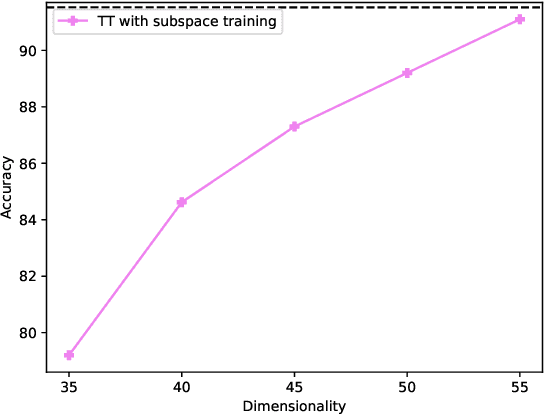
Deep neural networks have achieved great success in many data processing applications. However, the high computational complexity and storage cost makes deep learning hard to be used on resource-constrained devices, and it is not environmental-friendly with much power cost. In this paper, we focus on low-rank optimization for efficient deep learning techniques. In the space domain, deep neural networks are compressed by low rank approximation of the network parameters, which directly reduces the storage requirement with a smaller number of network parameters. In the time domain, the network parameters can be trained in a few subspaces, which enables efficient training for fast convergence. The model compression in the spatial domain is summarized into three categories as pre-train, pre-set, and compression-aware methods, respectively. With a series of integrable techniques discussed, such as sparse pruning, quantization, and entropy coding, we can ensemble them in an integration framework with lower computational complexity and storage. Besides of summary of recent technical advances, we have two findings for motivating future works: one is that the effective rank outperforms other sparse measures for network compression. The other is a spatial and temporal balance for tensorized neural networks.